文章目录
- 一.kafka
- 1.kafka的概念
- 2.Kafka的特性
- 3.工作原理
- 4.文件存储
- 5.消息模式
- 5.1点到点
- 5.2订阅模式
- 6.基础架构
一.kafka
1.kafka的概念
Kafka是最初由Linkedin公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于hadoop的批处理系统、低延迟的实时系统、storm/Spark流式处理引擎,web/nginx日志、访问日志,消息服务等等,用scala语言编写,Linkedin于2010年贡献给了Apache基金会并成为顶级开源 项目。
2.Kafka的特性
高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒
可扩展性:kafka集群支持热扩展
持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
高并发:支持数千个客户端同时读写
3.工作原理
Kafka中消息是以topic进行分类的,Producer生产消息,Consumer消费消息,都是面向topic的。
Topic是逻辑上的改变,Partition是物理上的概念,每个Partition对应着一个log文件,该log文件中存储的就是producer生产的数据
Producer生产的数据会被不断的追加到该log文件的末端,且每条数据都有自己的offset,consumer组中的每个consumer,都会实时记录自己消费到了哪个offset,以便出错恢复的时候,可以从上次的位置继续消费
4.文件存储
Kafka文件存储也是通过本地落盘的方式存储的,主要是通过相应的log与index等文件保存具体的消息文件。
生产者不断的向log文件追加消息文件,为了防止log文件过大导致定位效率低下,Kafka的log文件以1G为一个分界点,当.log文件大小超过1G的时候,此时会创建一个新的.log文件,同时为了快速定位大文件中消息位置,Kafka采取了分片和索引的机制来加速定位。
在kafka的存储log的地方,即文件的地方,会存在消费的偏移量以及具体的分区信息,分区信息的话主要包括.index和.log文件组成,
5.消息模式
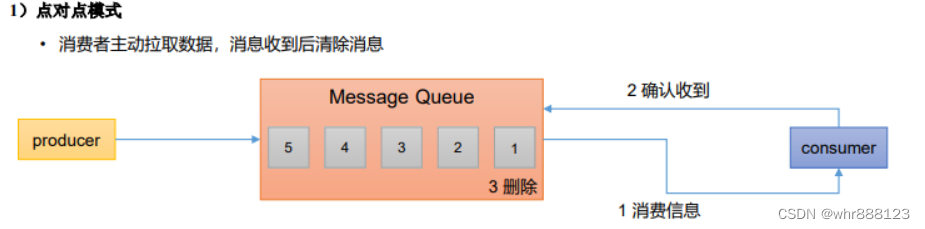
5.1点到点
消费者主动拉取数据,消息收到后清除消息
5.2订阅模式
可以有多个topic
消费者消费数据后,不删除数据
每个消费者相互独立,都可以消费到数据
6.基础架构
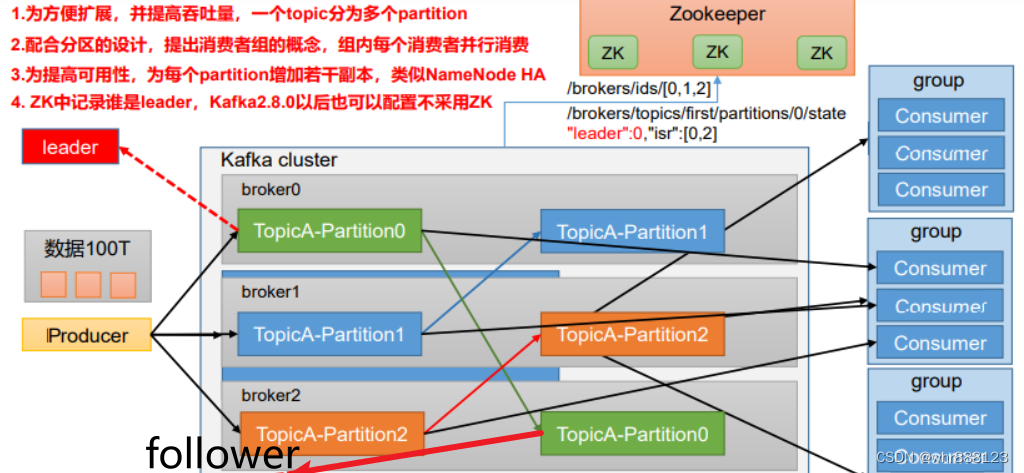
(1)Producer:消息生产者,就是向 Kafka broker 发消息的客户端。
(2)Consumer:消息消费者,向 Kafka broker 取消息的客户端。
(3)Consumer Group(CG):消费者组,由多个 consumer 组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
(4)Broker:一台 Kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个broker 可以容纳多个 topic。
(5)Topic:可以理解为一个队列,生产者和消费者面向的都是一个 topic。
(6)Partition:为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器)上,一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列。
(7)Replica:副本。一个 topic 的每个分区都有若干个副本,一个 Leader 和若干个Follower。
(8)Leader:每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是 Leader。
(9)Follower:每个分区多个副本中的“从”,实时从 Leader 中同步数据,保持和
Leader 数据的同步。Leader 发生故障时,某个 Follower 会成为新的 Leader