目录
1.简介
2.Coordinate Attention
2.2 Coordinate Attention生成
3.YOLOv5改进
3.1common.py构建CoordAtt模块。
3.2 yolo.py中注册CoordAtt模块
3.3 yaml文件配置
1.简介
最近对移动网络设计的研究已经证明了通道注意力(例如,Squeeze-and-Excitation attention)对于提升模型性能的显着有效性,但他们通常忽略了位置信息,这对于生成空间选择性注意力图很重要。在本文中,我们通过将位置信息嵌入到通道注意力中来为移动网络提出一种新的注意力机制,我们称之为“坐标注意力”。与通过 2D 全局池化将特征张量转换为单个特征向量的通道注意力不同,坐标注意力将通道注意力分解为两个一维特征编码过程,分别沿两个空间方向聚合特征。通过这种方式,可以沿一个空间方向捕获远程依赖关系,同时可以沿另一个空间方向保留精确的位置信息。然后将得到的特征图单独编码成一对方向感知和位置敏感的注意力图,这些图可以互补地应用于输入特征图以增强感兴趣对象的表示。我们的坐标注意力很简单,可以灵活地插入到经典的移动网络中,例如 MobileNetV2、MobileNeXt 和 EfficientNet,几乎没有计算开销。大量实验表明,我们的坐标注意力不仅有利于 ImageNet 分类,而且更有趣的是,在下游任务中表现更好,例如对象检测和语义分割
注意力机制用于告诉模型“what”和“where”,已被广泛研究和广泛部署,以提高现代深度神经网络的性能。 然而,它们在移动网络(模型大小有限)上的应用明显落后于大型网络,这主要是因为大多数注意力机制带来的计算开销对于移动网络来说是负担不起的。
考虑到移动网络计算能力的限制,迄今为止,移动网络最流行的注意力机制仍然是 Squeeze-andExcitation (SE) attention。 它在2D全局池化的帮助下计算通道注意力,并以相当低的计算成本提供显着的性能提升。 然而,SE注意力只考虑编码通道间信息而忽略了位置信息的重要性,这对于在视觉任务中捕获对象结构至关重要。 后来的工作,如BAM和CBAM,试图通过减少输入张量的通道维度,然后使用卷积计算空间注意力来利用位置信息,如图 2(b) 所示。 然而,卷积只能捕获局部关系,而无法对视觉任务必不可少的远程依赖进行建模。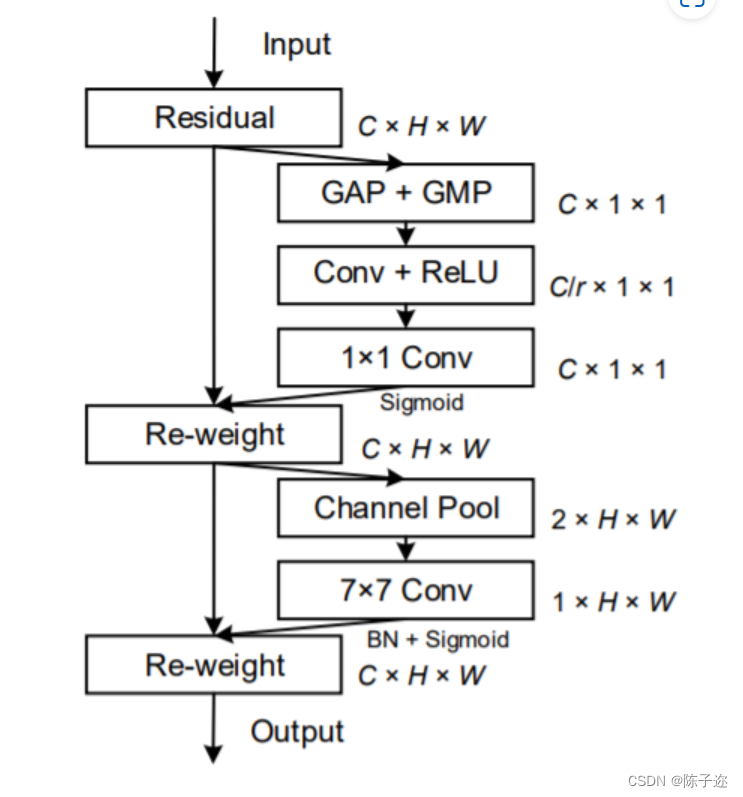
2.Coordinate Attention
一个coordinate attention块可以被看作是一个计算单元,旨在增强Mobile Network中特征的表达能力。
Coordinate Attention通过精确的位置信息对通道关系和长期依赖性进行编码,具体操作分为Coordinate信息嵌入和Coordinate Attention生成2个步骤。
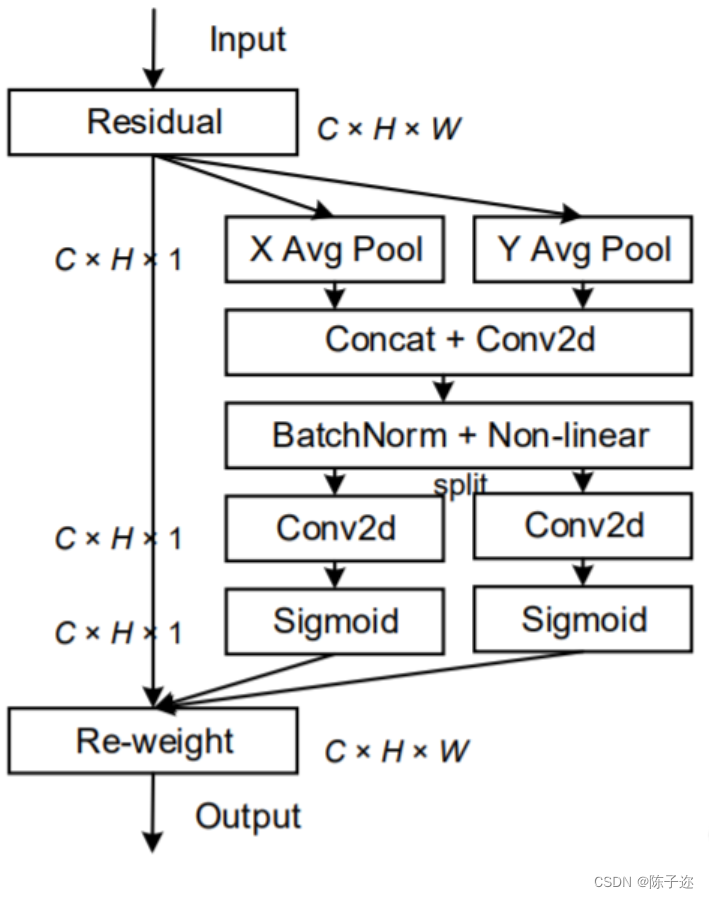
2.1 Coordinate信息嵌入
全局池化方法通常用于通道注意编码空间信息的全局编码,但由于它将全局空间信息压缩到通道描述符中,导致难以保存位置信息。为了促使注意力模块能够捕捉具有精确位置信息的远程空间交互,本文按照以下公式分解了全局池化,转化为一对一维特征编码操作:
具体来说,给定输入X ,首先使用尺寸为(H,1)或(1,W)的pooling kernel分别沿着水平坐标和垂直坐标对每个通道进行编码。因此,高度为h的第c通道的输出可以表示为:
同样,宽度为w的第c通道的输出可以写成:
上述2种变换分别沿两个空间方向聚合特征,得到一对方向感知的特征图。这与在通道注意力方法中产生单一的特征向量的SE Block非常不同。这2种转换也允许注意力模块捕捉到沿着一个空间方向的长期依赖关系,并保存沿着另一个空间方向的精确位置信息,这有助于网络更准确地定位感兴趣的目标。
2.2 Coordinate Attention生成
通过3.2.1所述,本文方法可以通过上述的变换可以很好的获得全局感受野并编码精确的位置信息。为了利用由此产生的表征,作者提出了第2个转换,称为Coordinate Attention生成。这里作者的设计主要参考了以下3个标准:
首先,对于Mobile环境中的应用来说,新的转换应该尽可能地简单;
其次,它可以充分利用捕获到的位置信息,使感兴趣的区域能够被准确地捕获;
最后,它还应该能够有效地捕捉通道间的关系。
通过信息嵌入中的变换后,该部分将上面的变换进行concatenate操作,然后使用 卷积变换函数 对其进行变换操作: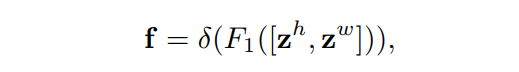
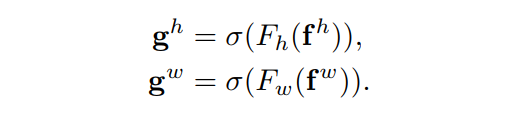
最后,Coordinate Attention Block的输出Y可以写成:
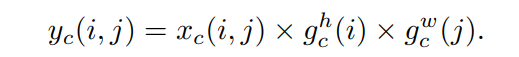
与其他Attention进行比较

3.YOLOv5改进
3.1common.py构建CoordAtt模块。
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class CoordAtt(nn.Module):
def __init__(self, inp, oup, reduction=32):
super(CoordAtt, self).__init__()
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n,c,h,w = x.size()
x_h = self.pool_h(x)
x_w = self.pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
out = identity * a_w * a_h
return out 3.2 yolo.py中注册CoordAtt模块
if m in [Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv, BottleneckCSP,
CoordAtt,CrossConv,C3,CTR3,C3TR,C3SPP, C3Ghost]:3.3 yaml文件配置
# YOLOv5 🚀, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth iscyy multiple
width_multiple: 0.50 # layer channel iscyy multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[-1, 1, CA, [1024]],
[[17, 20, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]