string 字符串
字符串类型是 Redis 最基础的数据类型,关于字符串需要特别注意:
1.⾸先Redis中所有 key 的类型都是字符串类型,⽽且其他⼏种数据结构也都是在字符串类似基础上构建的,例如 list 和 set 的元素类型是字符串类型。
2.其次,字符串类型包含⼀般格式的字符串或者类似JSON、XML格式的字符串;数字,可以是整型或者浮点型;甚⾄是⼆进制流数据,例如图片、音频、视频等。不过⼀个字符串的最大值不能超过512MB,一般不建议存储较大的图片、音频、视频等。
由于 Redis 内部存储字符串完全是按照⼆进制流的形式保存的,所以 Redis 是不处理字符集编码问题的,客⼾端传⼊的命令中使⽤的是什么字符集编码,就存储什么字符集编码。
一、string常用命令
set
将 string 类型的 value 设置到 key 中。如果 key 之前存在,则覆盖,⽆论原来的数据类型是什么。之 前关于此key的 TTL 也全部失效。
语法:
SET key value [expiration EX seconds|PX milliseconds] [NX|XX]
选项:
SET 命令⽀持多种选项来影响它的⾏为:
- EX seconds 使⽤秒作为单位设置 key 的过期时间。
- PX milliseconds 使⽤毫秒作为单位设置 key 的过期时间。
- NX 只在 key 不存在时才进⾏设置,即如果 key 之前已经存在,设置不执⾏。
- XX 只在 key 存在时才进⾏设置,即如果key 之前不存在,设置不执⾏。
下图是使用的具体示例:
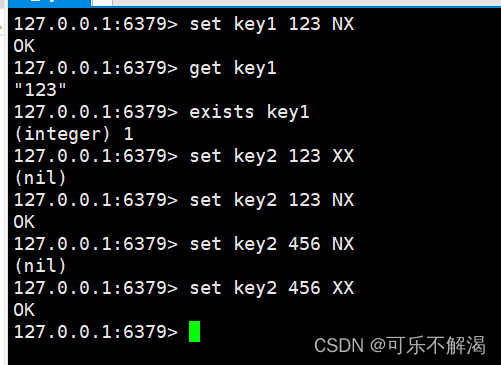
set key1 123 EX 10
等价于下面这两行
set key1 123
expire key1 10
其中NX选项相当于是元素不存在进行插入操作,XX选项是要元素存在,但是需要修改元素的值。
返回值:
1.如果设置成功,返回OK。
2.如果由于SET指定了NX或者XX但条件不满⾜,SET不会执⾏,并返回(nil)。
get
获取 key 对应的 value。如果 key 不存在,返回 nil。如果 value 的数据类型不是 string,会报错。
语法:
GET key
对于get来说只是支持字符串类型的value,如果value是其他类型,使用get获取就会出错。
当前的key3是list,用get来获取会出错,具体如下图所示:

mset/mget
mget作用:⼀次性获取多个 key 的值。如果对应的 key 不存在或者对应的数据类型不是 string,返回 nil。
语法:
MGET key [key ...]
mset作用:⼀次性设置多个 key 的值。
语法:
MSET key value [key value ...]
当有需求要一次性要set或者get多个key时,mget或者mset消耗的资源会更少。
其中具体示例如下:
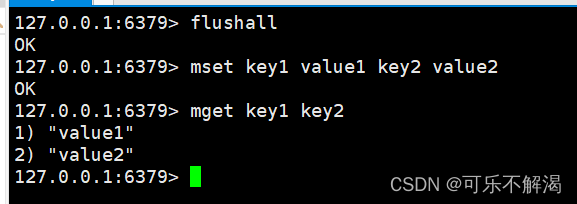
其中这里使用了一个删库命令,在公司生产环境上不要去使用,这里使用是自己的服务器用来学习所以使用它没关系。
其中 flushall 命令是用来清除 redis 上所有的数据,此操作相当于 => mysql 里的 drop database,即清除 redis 上所有的键值对都清空。
其中多次 get vs 单次 mget 流程如下:
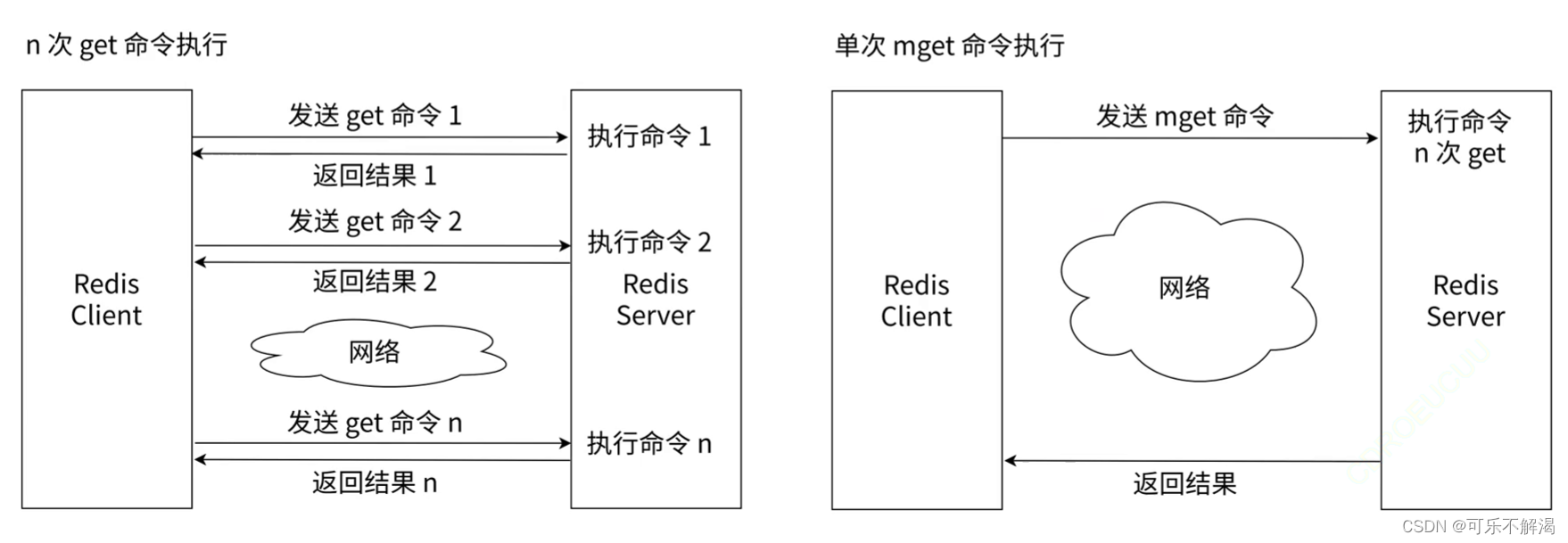
⽤ mget / mset 由于可以有效地减少了⽹络时间,所以性能相较更⾼。假设⽹络耗 时 1 毫秒,命令执⾏时间耗时 0.1毫秒,则执行时间如下表所示:
| 操作 | 时间 |
|---|---|
| 1000次 get | 1000 * 1 + 1000 * 0.1 = 1100毫秒 |
| 1次 mget 1000个键 | 1 * 1 + 1000 * 0.1 = 101毫秒 |
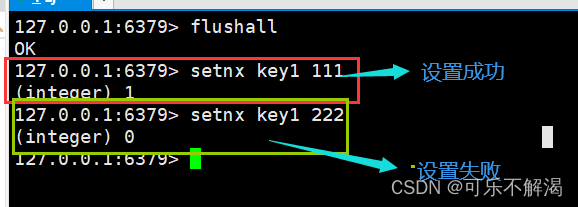
setnx
作用:设置key value但只允许在key之前不存在的情况下。
语法:SETNX key value
返回值:1表⽰设置成功。0表⽰没有设置。
incr/incrby
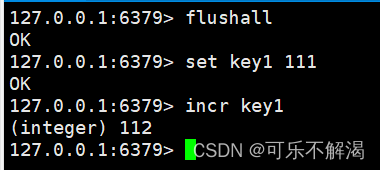
incr / incrby作用:
incr将key对应的string表⽰的数字加⼀,而incrby将key对应的string表⽰的数字加 n。如果key不存在,则视为key对应的value是0。如果key对应的string不是⼀个整型或者范围超过了64位有符号整型,则报错。
返回值:int 类型的加完后的数值。
其中此时key对应的 value 必须得是整数~~
下面以incr为例:
当value不是整数或者value超出范围时会出错
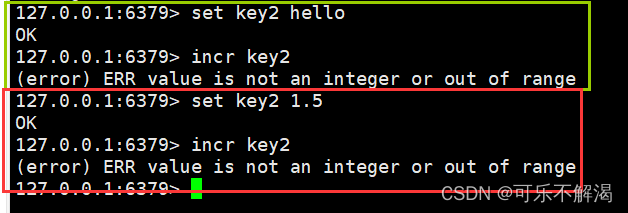
注意:
当incr / incrby操作的key不存在时,就会把这个key的value当做0来使用
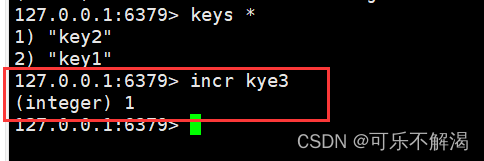
decr/decrby
decr / decrby作用:将 key 对应的 string 表⽰的数字减⼀,而decrby将key对应的string表⽰的数字减 n。如果 key 不存在,则视为 key 对应的 value 是 0。如果 key 对 应的 string 不是⼀个整型或者范围超过了 64 位有符号整型,则报错。
返回值:int 类型的减完后的数值。
decr / decrby规则与incr / incrby是一致的,都必须为整数。
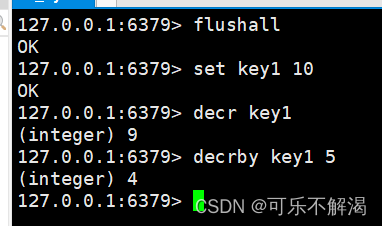
decr/decrby与incr/incrby一样
-
当操作的key不存在时,就会把这个key的value当做0来使用
-
当value不是整数或者value超出范围时会出错
incrbyfloat
将 key 对应的 string 表⽰的加上对应的值,且是用双精度浮点数计算的。
1.如果对应的值是负数,则视为减去对应的值。
2.如果 key 不存在,则视为 key 对应的 value 是 0。
3.如果 key 对应的不是 string,或者不是⼀个浮点数,则报 错。允许采⽤科学计数法表⽰浮点数
语法:INCRBYFLOAT key increment
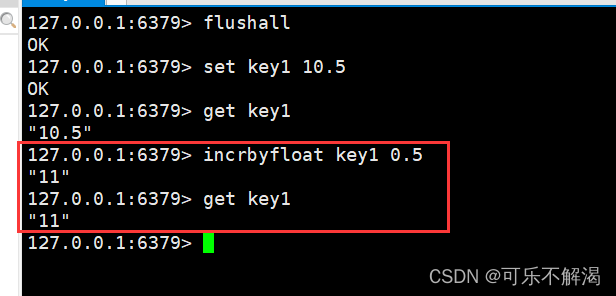
总结作用如下:
| 命令 | 功能 |
|---|---|
| incr | 针对 value +1 |
| incrby | 针对 value + n |
| decr | 针对 value - 1 |
| decrby | 针对 value - n |
| incrbyfloat | 针对 value +/- 小数 |
二、其他命令
append
作用:如果 key 已经存在并且是⼀个string,命令会将 value 追加到原有 string 的后边。如果 key 不存在, 则效果等同于 SET 命令。
语法:
APPEND KEY VALUE
返回值:追加完成之后string的⻓度,单位是字节。
下面是具体示例,首先set一个key1,并让key1的value后追加另一串字符串,具体如下图所示:
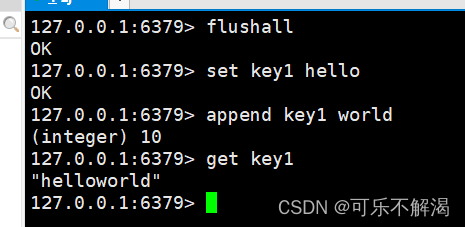
若当 key 不存在时,相当于在空字符串后追加
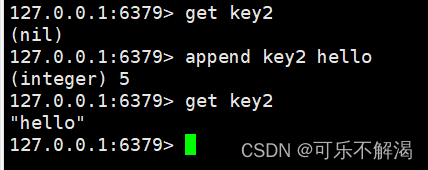
当输入的是中文时,由于此时是在终端 xshell 上,是以utf-8编码直接写入的,那么直接存入的就是十六进制存储utf-8编码值。
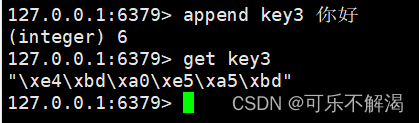
操作linux的时候,千万注意,不要乱按 ctrl + s
ctrl + s在 xshell 中的作用是“冻结当前画面”
ctrl + q 解除冻结
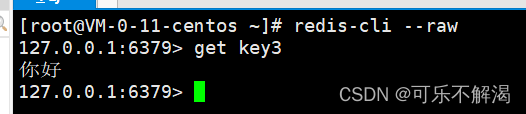
如果想把汉字的原始显示出来,在启动redis客户端的时候,加上一个–raw这样的选项就可以使redis客户端能够自动的把二进制数据尝试翻译。
此时就可以看到数据汉字本身
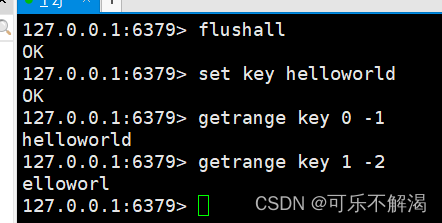
getrange
作用:返回 key 对应的 string 的⼦串,由 start 和 end 确定(左闭右闭)。可以使⽤负数表示倒数。-1 代表倒数第⼀个字符,-2 代表倒数第⼆个,其他的与此类似。超过范围的偏移量会根据 string 的⻓度调整成正确的值。
相当于c++中的 std::string 中的 substring,用来获取子串。
注意:
1. getrange,是闭区间,即前闭后闭,这点与c++中的std::string中的substring不同
2.且getrange的下标是可以支持负数的,即 -1代表的是倒数第一个元素,下标为 len - 1 的元素
语法:GETRANGE key start end
如果字符串中保存的是汉字,此时进行子串切分,很可能切出来的就不是完整的汉字了~~
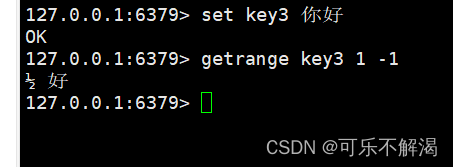
setrange
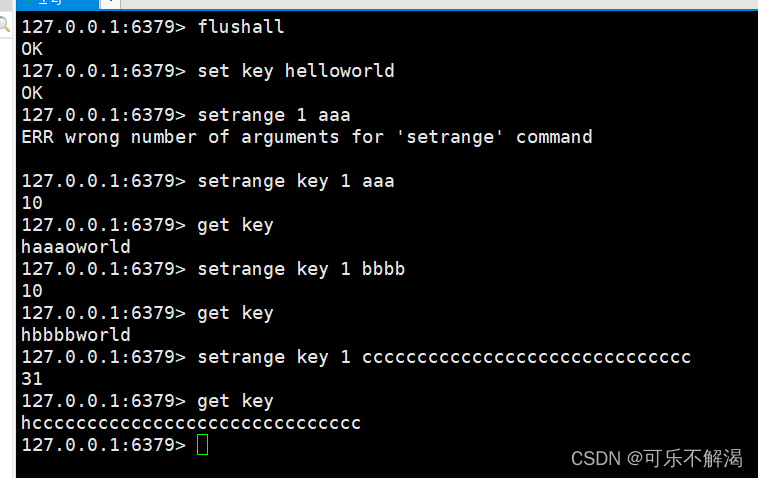
作用:修改字符串的⼀部分,从指定的偏移位置开始,替换多长看要替换的value的长度。
语法:SETRANGE key offset value
返回值:替换后的 string 的⻓度。
当key不存在时,setrange针对不存在的key也是可以操作的,不过会把offset之前的内容填充成0x00
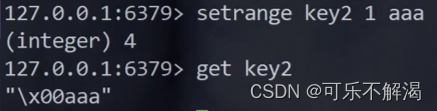
其中这里凭空生成了一个字节,这个字节里的内容就是0x00,aaa就被追加到 0x00的后面了

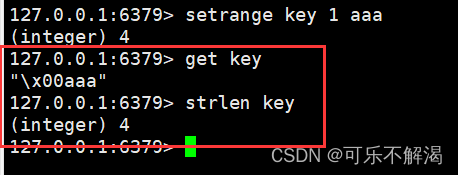
strlen
作用:获取到字符串的长度,单位是字节
语法:STRLEN key
字符串类型命令总结表
| 命令 | 执行效果 |
|---|---|
| SET key value | 设置 key 的值是value |
| get key | 获取 key 的值 |
| del key [key …] | 删除指定的 key |
| mset key value [key value …] | 批量设置指定的 key 和 value |
| mget key [key …] | 批量获取 key的值 |
| incr key | 指定的 key 的值 +1 |
| decr key | 指定的 key 的值 -1 |
| incrby key n | 指定的 key 的值 +n |
| decrby key n | 指定的 key 的值 -n |
| incrbyfloat key n | 指定的 key 的值 +n |
| append key value | 指定的 key 的值追加 value |
| strlen key | 获取指定 key 的值的长度 |
| setrange key offset value | 修改指定 key 的 offset 偏移量位置开始的部分值 |
| getrange key start end | 获取指定 key 的从 start 到 end 的部分值 |
三、string 内部编码
字符串类型的内部编码有 3 种,具体如下:
- int:8个字节的⻓整型。
- embstr:小于等于 39 个字节的字符串。
- raw:大于39 个字节的字符串。
Redis 会根据当前值的类型和⻓度动态决定使⽤哪种内部编码实现。
其中 embstr 和 raw 编码和在windows环境下visual studio系列的编译器中,windows中的c++代码中的 std::string 版本也是这种采取这种模式,若字符串长度很短,则存入定长的字符数组中(对应的就是embstr),过长则使用new来动态申请一大块 char 类型的内存来存储字符串(对应的就是raw)。
其中我们可以使用 object encoding key来查看key的内部编码方式
整型类型示例如下:
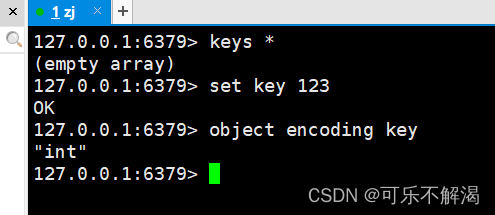
短字符串示例如下:
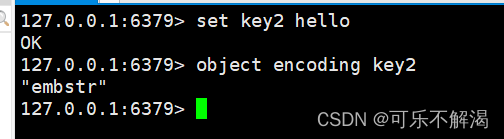
⻓字符串示例如下:

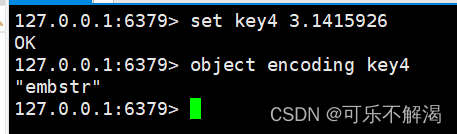
注意:
当value是小数时,redis 其内部本质是用字符串存储的。
使用场景
缓存功能
下图是比较典型的缓存使用场景,其中 Redis 作为缓冲层,MySQL 作为存储层,绝⼤部分请求的数据都是从 Redis 中获取。由于 Redis 具有支撑高并发的特性,所以缓存通常能起到加速读写和降低后端压力的作用。
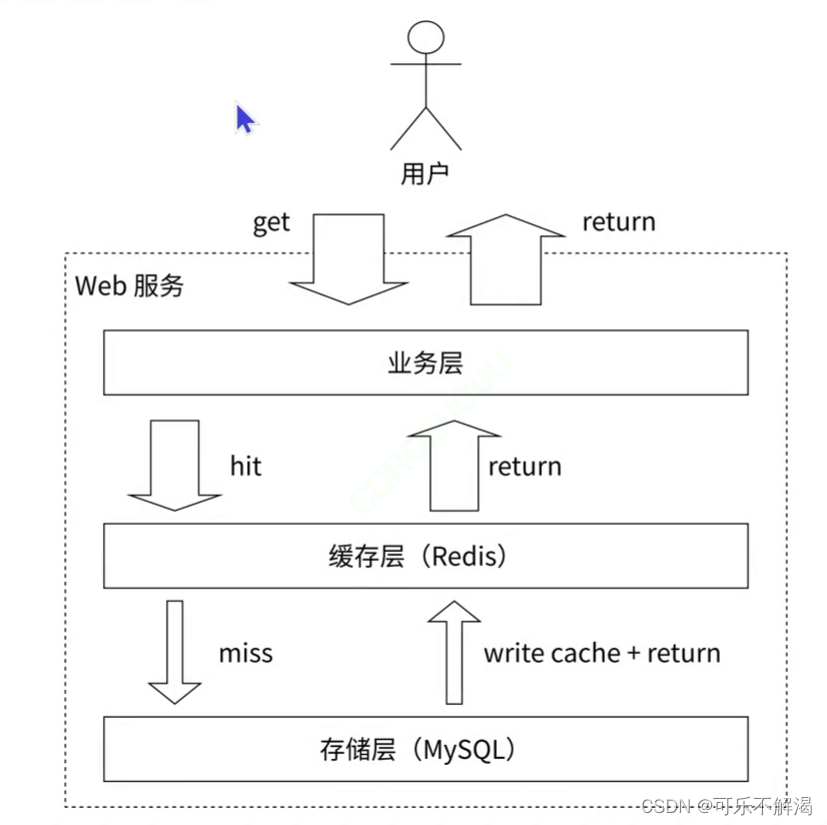
其中整体的思路如下:
在业务层,应用服务器访问数据时,先进入 redis 中查询。
如果 redis 中数据已经存在了,就直接从 redis 中取出数据并交给应用服务器,随后就不再继续访问mysql数据库了。
如果 redis中数据不存在,在读取mysql,把读取到的结果,返回给应用服务器,同时把这个数据写入到 redis缓存中。
注意事项:
与MySQL等关系型数据库不同的是,Redis没有表、字段这种命名空间,⽽且也没有对键名有强制要求(除了不能使⽤⼀些特殊字符)。但设计合理的键名,有利于防⽌键冲突和项⽬的可维护性,⽐较推荐的⽅式是使⽤"业务名:对象名:唯⼀标识:属性"作为键名。例如MySQL的数据库名为vs,⽤⼾表名为user_info,那么对应的键可以使用"vs:user_info:6379"、“vs:user_info:6379:name"来表⽰,如果当前Redis只会被⼀个业务使⽤,可以省略业务名"vs:”。如果键名过程,则可以使⽤团队内部都认同的缩写替代,例如"user:6379:friends:messages:5217"可以被"u:6379:fr : m :5217"代替。毕竟键名过⻓,还是会导致Redis的性能明显下降的。
计数功能
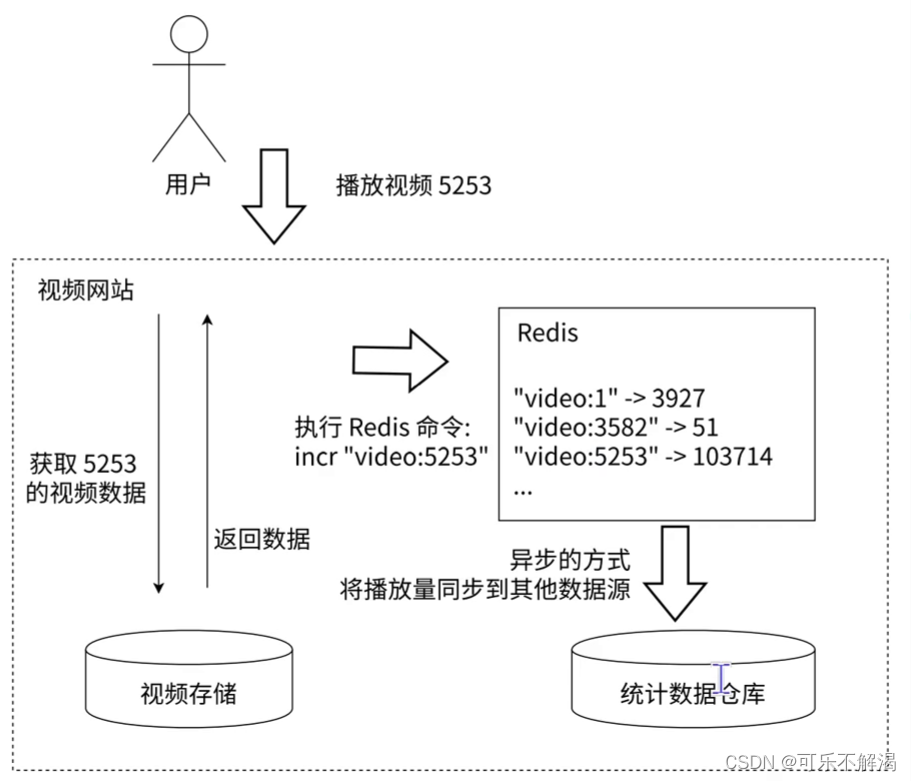
许多应用都会使用 Redis 作为计数的基础⼯具,它可以实现快速计数、查询缓存的功能,同时数据可以异步处理或者落地到其他数据源。如下图所示,例如视频⽹站的视频播放次数可以使用 Redis 来完成,例如用户每播放⼀次视频,相应的视频播放数就会⾃增1。
共享会话
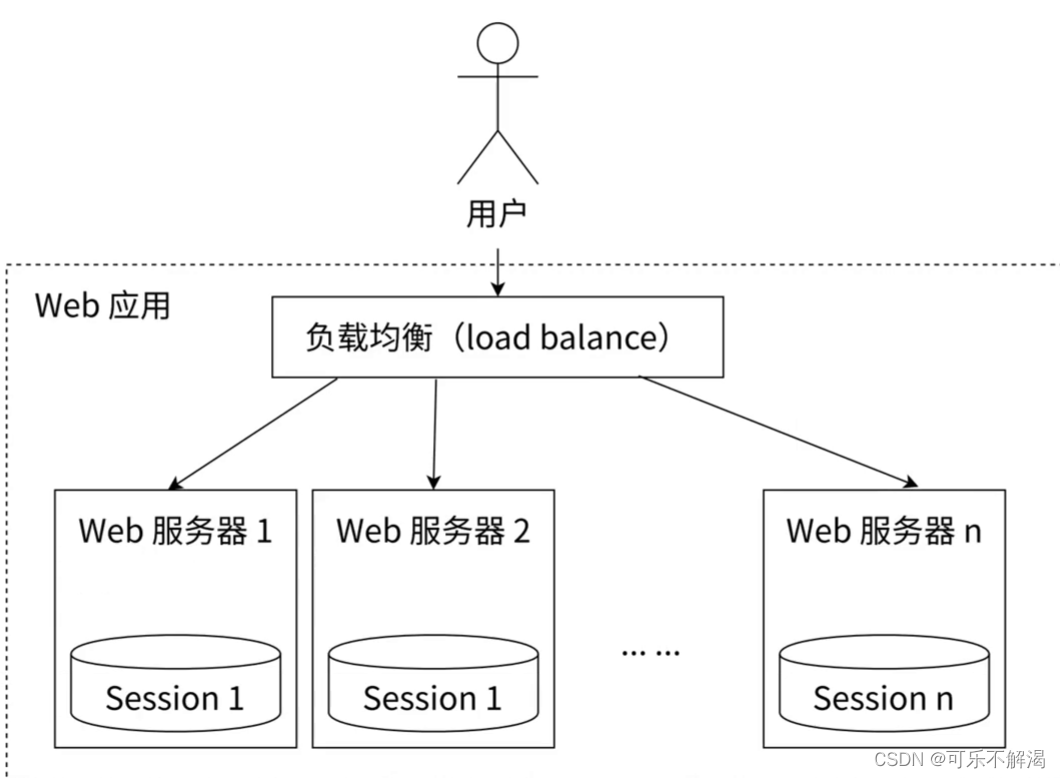
如下图所示,⼀个分布式 Web 服务将用户的 Session 信息(例如用户登录信息)保存在各⾃的服务器中,但这样会造成⼀个问题:由于负载均衡的考虑,分布式服务会将用户的访问请求均衡到不同的服务器上,并且通常⽆法保证用户每次请求都会被均衡到同⼀台服务器上,这样当用户刷新⼀次访问是可能会发现需要重新登录,这个问题是用户无法容忍的。
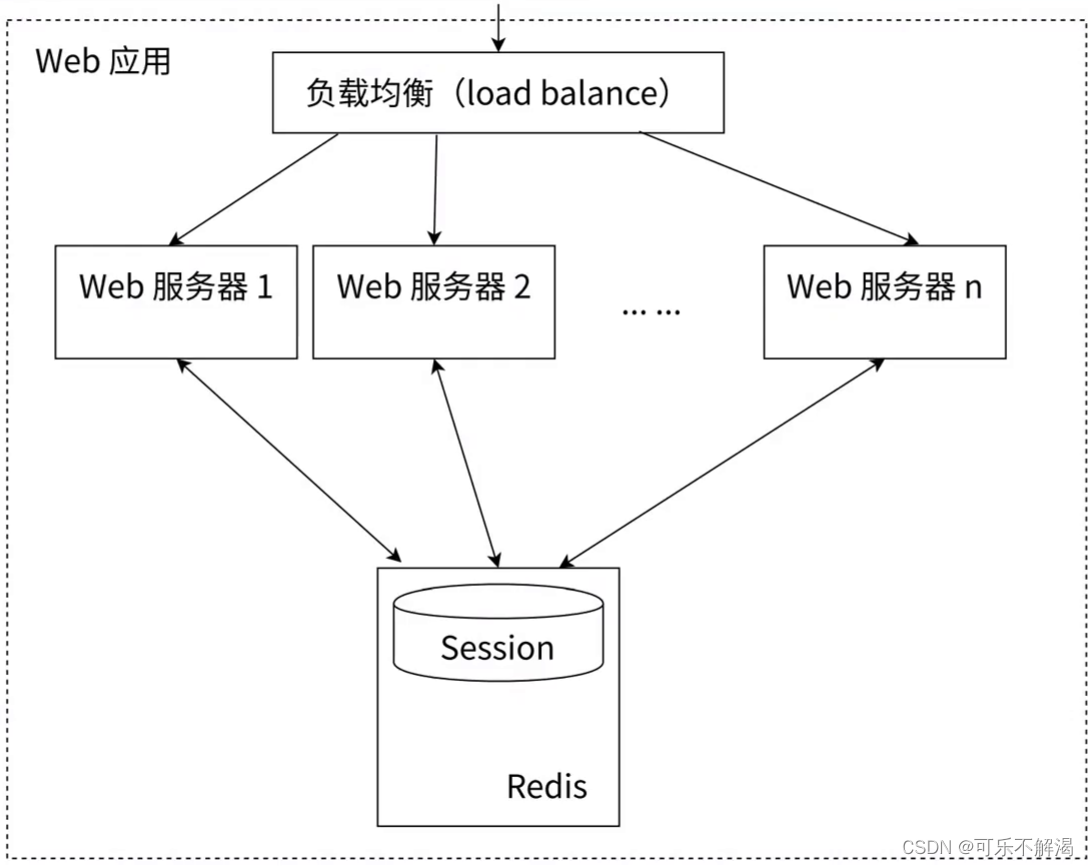
为了解决这个问题,可以使⽤ Redis 将用户的 Session 信息进⾏集中管理,如下图所示,在这种模式下,只要保证 Redis 是高可用和可扩展性的,无论用户被均衡到哪台 Web 服务器上,都集中从 Redis 中查询、更新 Session 信息。
手机验证码
很多应用出于安全考虑,会在每次进行登录时,让用户输⼊手机号并且配合给手机发送验证码,然后让用户再次输⼊收到的验证码并进⾏验证,从而确定是否是用户本⼈。为了短信接⼝不会频繁访问,会限制用户每分钟获取验证码的频率,例如⼀分钟不能超过 5 次,或者每次获取验证必须间隔30s,那么就可以使用 redis,并将对应的 key 设置过期时间和 value 的值来判断间隔时间或者是次数。