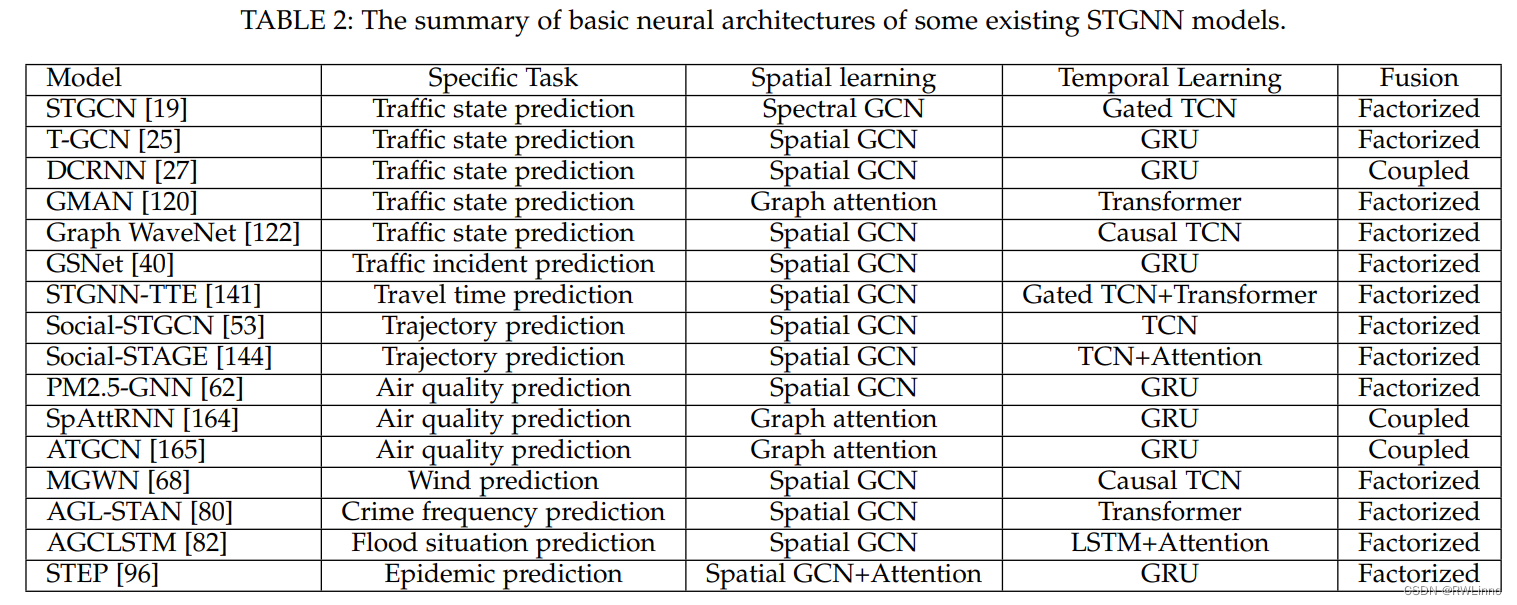
工地安全帽识别闸机联动开关系统通过yolov7系列网络模型深度学习算法,工地安全帽识别闸机联动开关算法对施工人员的人脸、安全帽和反光衣进行识别,判断是否符合安全要求。只有当人脸识别成功且安全帽、反光衣齐全时,闸机才会打开允许施工人员进入。目标检测架构分为两种,一种是two-stage,一种是one-stage,区别就在于 two-stage 有region proposal过程,类似于一种海选过程,网络会根据候选区域生成位置和类别,而one-stage直接从图片生成位置和类别。今天提到的 YOLO就是一种 one-stage方法。YOLO是You Only Look Once的缩写,意思是神经网络只需要看一次图片,就能输出结果。
Yolo算法采用一个单独的CNN模型实现end-to-end的目标检测,整个系统如图5所示:首先将输入图片resize到448x448,然后送入CNN网络,最后处理网络预测结果得到检测的目标。相比R-CNN算法,其是一个统一的框架,其速度更快,而且Yolo的训练过程也是end-to-end的。很多人可能将Yolo的置信度看成边界框是否含有目标的概率,但是其实它是两个因子的乘积,预测框的准确度也反映在里面。边界框的大小与位置可以用4个值来表征:(x,y,w,h)(x,y,w,h),其中(x,y)(x,y)是边界框的中心坐标,而ww和hh是边界框的宽与高。还有一点要注意,中心坐标的预测值(x,y)(x,y)是相对于每个单元格左上角坐标点的偏移值,并且单位是相对于单元格大小的,单元格的坐标定义如图6所示。而边界框的ww和hh预测值是相对于整个图片的宽与高的比例,这样理论上4个元素的大小应该在[0,1][0,1]范围。这样,每个边界框的预测值实际上包含5个元素:(x,y,w,h,c)(x,y,w,h,c),其中前4个表征边界框的大小与位置,而最后一个值是置信度。
YOLOv7 的策略是使用组卷积来扩展计算块的通道和基数。研究者将对计算层的所有计算块应用相同的组参数和通道乘数。然后,每个计算块计算出的特征图会根据设置的组参数 g 被打乱成 g 个组,再将它们连接在一起。此时,每组特征图的通道数将与原始架构中的通道数相同。最后,该方法添加 g 组特征图来执行 merge cardinality。除了保持原有的 ELAN 设计架构,E-ELAN 还可以引导不同组的计算块学习更多样化的特征。

Adapter接口定义了如下方法:
public abstract void registerDataSetObserver (DataSetObserver observer)
Adapter表示一个数据源,这个数据源是有可能发生变化的,比如增加了数据、删除了数据、修改了数据,当数据发生变化的时候,它要通知相应的AdapterView做出相应的改变。为了实现这个功能,Adapter使用了观察者模式,Adapter本身相当于被观察的对象,AdapterView相当于观察者,通过调用registerDataSetObserver方法,给Adapter注册观察者。
public abstract void unregisterDataSetObserver (DataSetObserver observer)
通过调用unregisterDataSetObserver方法,反注册观察者。
public abstract int getCount () 返回Adapter中数据的数量。
public abstract Object getItem (int position)
Adapter中的数据类似于数组,里面每一项就是对应一条数据,每条数据都有一个索引位置,即position,根据position可以获取Adapter中对应的数据项。
public abstract long getItemId (int position)
获取指定position数据项的id,通常情况下会将position作为id。在Adapter中,相对来说,position使用比id使用频率更高。
public abstract boolean hasStableIds ()
hasStableIds表示当数据源发生了变化的时候,原有数据项的id会不会发生变化,如果返回true表示Id不变,返回false表示可能会变化。Android所提供的Adapter的子类(包括直接子类和间接子类)的hasStableIds方法都返回false。
public abstract View getView (int position, View convertView, ViewGroup parent)
getView是Adapter中一个很重要的方法,该方法会根据数据项的索引为AdapterView创建对应的UI项。






![【C++题解】[NOIP2018]龙虎斗](https://img-blog.csdnimg.cn/img_convert/2ab72ad23f99ae8b38e39a25338499ef.png)