作为存储业务的一个重要组成部分,block IO是非易失存储的唯一路径,它的生命历程每个阶段都直接关乎我们手机的性能、功耗、甚至寿命。本文试图通过block IO的产生、调度、下发、返回的4个阶段,阐述一个block IO的生命历程。
一、什么是块设备和块设备层

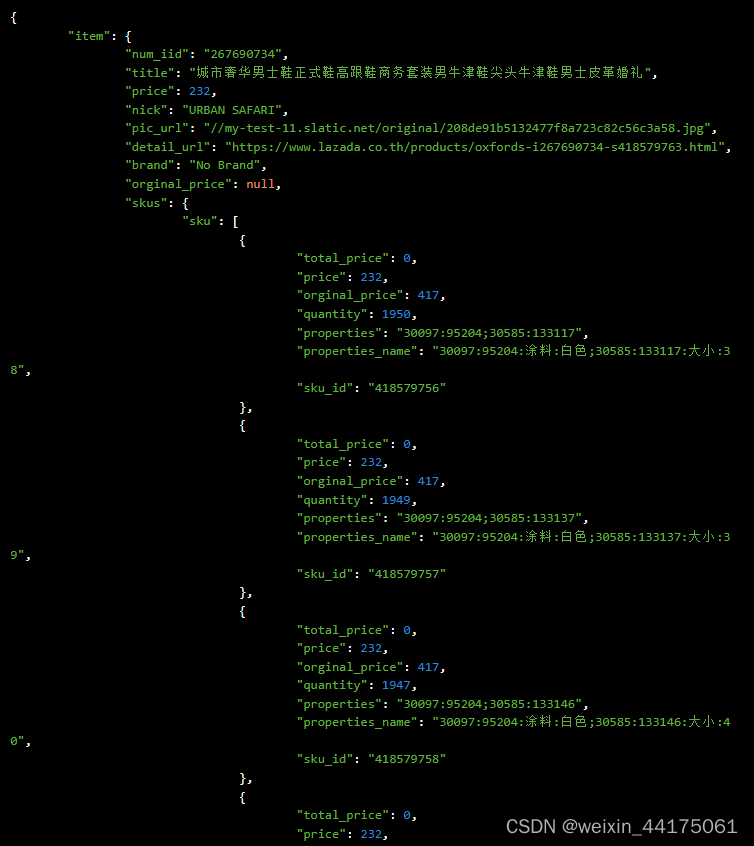
从计算机诞生开始,就有了IO设备,IO设备大致分为两类,块设备和字符设备,块设备的2个重要特性就是:块存储和可寻址。而块设备层,就是通过组织管理,使得向块设备下发的请求能够高效合理的完成的一种软件逻辑层。如上图所示,在传统的磁盘结构中,减少吊杆/磁头的移动(机械动作),容易找到目标地址,就能提升IO性能。
块设备层在整个存储栈中的位置如下图所示,上承文件系统,下接具体的块设备驱动(UFS,EMMC驱动):

通过blktrace这个开源工具可以用来分析IO轨迹和性能,从AQGP开始创建线程的plug,再到后面的AQM完成了线程内部plug的merge合并,最后IUDC完成了线程内部plug的下发和返回。

二、 block IO的产生
大到手机里面每一个应用程序的打开,小到很多人学生时代写过的一个C语言程序,都会伴随block IO的产生。究其本质,只要调用了libc库中的open, read, close,write, fsync, sync这些库函数,都可能产生blockIO。
1. 用户态常用文件操作


2.文件系统IO~预读

3.文件系统IO~脏页回写

4.文件系统IO~fsync & sync

5.文件系统IO~dm设备写
通过下面的命令获取dm设备(253:26)的轨迹:
./blktrace -d /dev/block/dm-26 -o - |./blkparse -i -

由于dm设备到真实的物理设备,有一层映射,对于同一个逻辑地址8898352通过下面的命令获取针对这个逻辑地址的block IO在其映射的物理设备(259:41)的轨迹,在物理设备中,块地址经过remap从8898352变成了33294128。
./blktrace -d /dev/block/sdc57 -o - | ./blkparse -i -

这里以verity类型的dm设备为例,其block io的产生路径:

6.direct-IO的产生路径
上面的预读,脏页回写,sync操作,都是经过了page cache,有些跑分软件如androbench不会经过page cache,更关注直接的底层存储性能,会采用direct-IO的方式。下图是direct-IO的block IO产生路径。

资料直通车:Linux内核源码技术学习路线+视频教程内核源码
学习直通车:Linux内核源码内存调优文件系统进程管理设备驱动/网络协议栈
三、block IO的调度
http://1.IO调度整体框架
调度在我们日常生活中会经常遇到,如电梯,或者打车司机派单拼车,错峰吃饭,错峰上下班等,都是为了更好的整体性能和能耗。


前面列举了一些block IO的产生场景,当这些IO产生后,为了更好的整体性能和能耗,它们也需要合适的调度机制。从IO产生后,经过软队列,调度器,硬队列,最终完成派发。

2.关键数据结构bio,request,page,sector的关系
一个或多个bio最后合并为一个request,每个request作为面向存储器件驱动的直接数据结构,里面携带了内存页虚拟地址和存储介质逻辑地址,它是易失介质和非易失介质进行数据交互的桥梁。
每个bio里面包含了一个bio_vec数组,每个数组元素指向一个内存page。
每个bio里面包含了一个bvec_iter,包含了这个io指向的存储介质的sector。
内存page没有连续的要求,但是存储介质的sector必须是首尾相连的,因为在驱动代码中,sglist可以包含多个离散点,而存储介质中的sector地址不连续,那么就会导致磁头反复调整,极大降低性能。而sglist由于是内存总线寻址访问,不存在性能的问题。在flash介质,虽然不涉及磁头调整,但如果不连续,编程速度也会大大降低。

3.bio -> request
一个bio经历split,plug merge,电梯merge,最后获取merge到一个已有的request或者获取一个全新的request。

4.block IO所在dev的remap
为了更好的理解block IO的remap,merge操作,这里说一下块设备和分区表的概念。每个设备(比如LU0,LU1)都有一个gendisk的结构体,但是一个LU(Logical Unit)经常会被分割为多个分区。gendisk包含了这个设备的分区表,对于每个被分割的分区,都可以独立挂载自己的文件系统,并在文件系统内从0开始寻址。当形成IO下发到器件时,由于对于器件内部的地址管理是以LU为单位,因此,就需要通过找到先找到改分区在分区表中的偏移,再加上文件系统内部的偏移,才构成面向LU的寻址逻辑地址。


5.bio的split
一个bio有自己可以承受着的最大数据量,如果超过,则会被拆分,下图是512KB为边界的一个拆分示意图。

6. bio的merge
bio会尝试在本线程自身plug中merge一次,如果没有merge成功,则继续尝试本队列对应的电梯队列里面进行merge,对于mq(multiqueue),也可以在soft-queue里面尝试merge。

7.线程的plug和unplug
Merge和plug都是蓄流,减少请求向存储器件下发的频率,plug的等待也会增加merge的机会,结伴而行才能提升整体IO性能。在schedule, io_schedule,或线程显性调用blk_finish_plug的时候,才会开闸。

8. 电梯调度算法
每个队列可以配置一个io scheduler,即IO调度器,常见的有noop, deadline, cfq等,电梯调度进一步把request请求进行合并和排序,根据所选择的算法(根据时间片,进程优先级,同步异步等因素),决定下一个dispatch的request请求。

9. queues之间的关系
Linux块设备层已逐步切换到multiqueue , Linux5.0以后单队列代码已被完全移除。multiqueue核心思路是为每个CPU分配一个软件队列,为存储设备的每个硬件队列分配一个硬件派发队列,大大减少锁竞争。在整个block IO的生命历程中,有3个常见的队列类型,分别是: request_queue, blk_mq_ctx, blk_mq_hw_ctx。每个块设备有1个request_queue,包含设备相关的队列属性,可以理解为队列大管家。

每个块设备有1个或者多个硬队列,用于面向底层驱动,如tag的管理。request_queue,blk_mq_ctx,blk_mq_hw_ctx之间可以相互遍历。


四、 block IO的下发
1.生产者和消费者模型
经历过漫长的产生,调度环节,一个request终于开始向器件下发了。这里以常见的生产者消费者模型抽象一下,每个设备都有自己的生产者队列(电梯队列,software queue),但消费者队列(hardwardqueue)却可能是共享的,在单硬件队列场景中(当前UFS,eMMC)。

2. scsi子系统和ufs设备
ufs设备采用了scsi协议定义的通用的命令集(读,写,unmap等),以及scsi子系统通用的异常处理等各种流程,所以ufs驱动在初始化后注册到scsi子系统里面,作为一个scsi设备。

前面看到的sdc,sdc1,sdc2就是在上面的sd_probe函数中完成的。

sd_probe中同时也会解析出这个设备对应的分区表,并且把这个设备对应的每个分区添加到块设备里面。
3. scsi设备的关键结构
每个scsi_device共用一个host,通过这个host可以找到所有的scsi设备。
Ufs注册的scsi设备scsi_device中,所有的scsi_device共用一个hostdata,即ufs_hba。
不同scsi_device有自己的request_queue。
另外1个scsi_device对应1个LU,如下图的W-LUN和LUN属于不同的scsi_device。
以某平台的6个scsi_device(3个LUN+3个W-LUN)为例,其数据结构对应关系:


4. IO的获取和下发
作为消费者,从生产者中获取request请求,这个获取的过程会有个优先级排序,先从哪个链表里面获取,取决于不同的策略。

5. mmc和ufs底层驱动对接
每个块设备在生成时,会设置自己的request_queue及其属性,回调函数,比如mmc和ufs设备分别设定了mmc_request_fn和scsi_request_fn作为这个request_queue的request_fn,从而实现了block层和设备驱动层的解耦。

6. scsi_device busy等异常路径处理
请求进入到scsi层时,会对scsi target和scsi host的各种状态进行判断,检查其是否满足下发的条件。当出现IO出现异常时,从block层的timeout回调开始,调用到scsi层,进一步再调到ufs驱动层的异常处理函数,如ufshcd_abort,ufshcd_eh_device_reset_handler。

五、 block IO的返回
1. 控制器的硬中断
存储器件处理完request请求后,由controller向GIC上报中断,进入中断上半部处理,再到softirq的raise,整体流程如下。有些request请求指定了某个cpu,这里会涉及当前上半部接受中断cpu和其指定cpu之间的cache共享问题,如果共享,即便两者不同,也会在当前上半部接受所在cpu触发当前cpu的softirq,主要是考虑性能问题。

2. 软中断

3. 文件系统回调
每个进程在下发IO请求后,会把自己置于wait队列,当IO请求返回时,通过自下而上的层层回调,最后调到wait_on_page_locked把当前page的waiter进程唤醒,从而完成了整个block IO的生命历程。

六、总结
性能问题中经常会遇到某个进程iowait时间过长的问题,那么这个时间的究竟是怎么统计的,涵盖了哪个范围?从cpu角度看,就是该进程被dequeue到被重新enqueue的时间范围。从block IO角度看,就是涵盖了该进程所发起的整个block IO的生命历程的时间范围。通过这个blockIO的4个生命历程阶段,可以进一步细化了解iowait这种耗时的分布。

原文作者:内核工匠