MAE:Masked Autoencoders Are Scalable Vision Learners
Self-Supervised Learning
- step1:先用无标签数据集,把参数从一张白纸训练到初步预训练模型,可以得到数据的 Visual Representation
- step2:再从初步成型,根据你下游任务 Downstream Tasks的不同去用带标签的数据集把参数训练到完全成型。注意这是2个阶段。
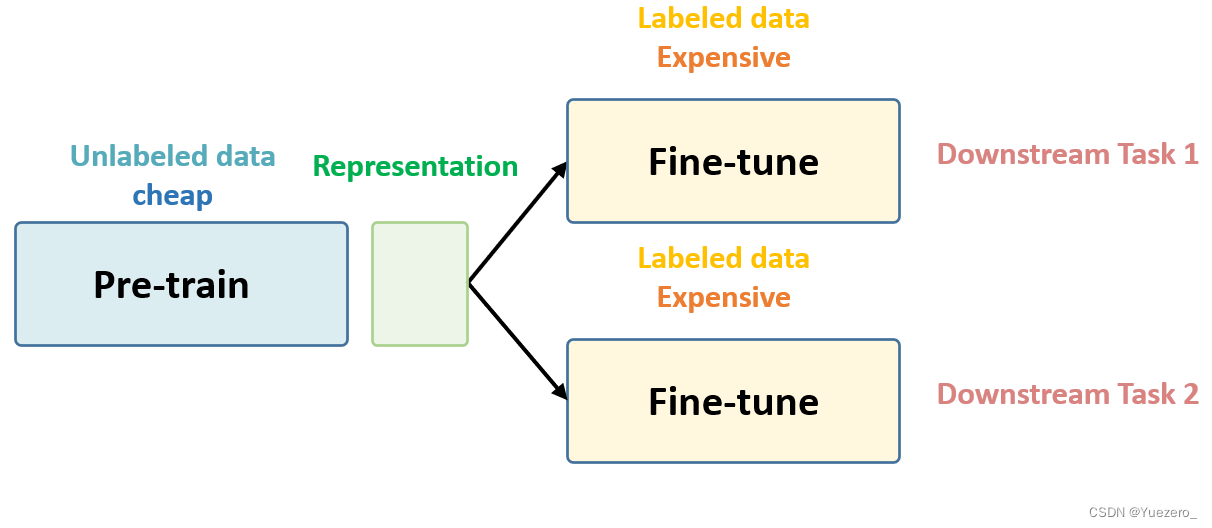
第一个阶段不涉及任何下游任务,就是拿着一堆无标签的数据去预训练,没有特定的任务,这个话用官方语言表达叫做:in a task-agnostic way。
第二个阶段涉及下游任务,就是拿着一堆带标签的数据去在下游任务上 Fine-tune,这个话用官方语言表达叫做:in a task-specific way。
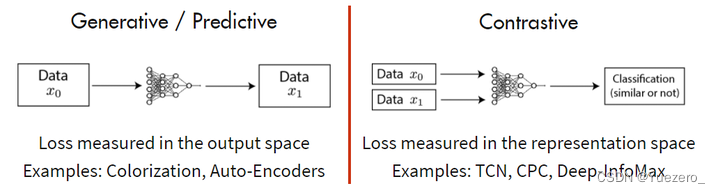
Self-Supervised Learning 不仅是在NLP领域,在CV, 语音领域也有很多经典的工作,如下图2所示。它可以分成3类:Data Centric, Prediction (也叫 Generative) 和 Contrastive。

其中的主流就是基于 Generative 的方法和基于 Contrative 的方法。如下图所示这里简单介绍下。
- 基于 Generative 的方法主要关注的
重建误差,比如对于 NLP 任务而言,一个句子中间盖住一个 token,让模型去预测,令得到的预测结果与真实的 token 之间的误差作为损失。如Diffusion、VAE等。 - 基于 Contrastive 的方法不要求模型能够重建原始输入,而是希望模型能够
在特征空间上对不同的输入进行分辨。如SimCLR等
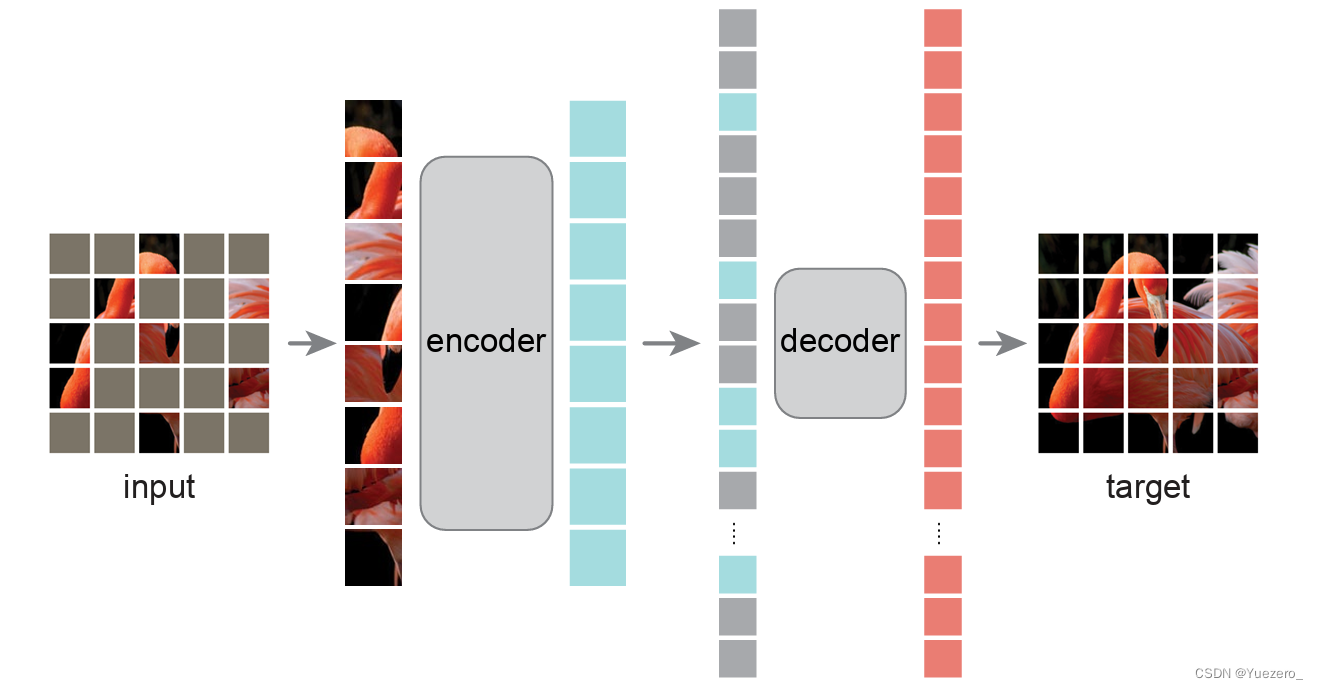
1. Masked AutoEncoders (MAE) 原理架构
掩码自编码器 (masked autoencoders (MAE)) 要做的事情还是通过自监督学习将被masked抹去的图像块补充上。属于 Generative (Predictive) pre-training 的类型。这种类型自监督学习的另一个著名的例子就是 BERT。
对于 BERT 模型而言,一个 sentence 中间盖住一些 tokens,让模型去预测,令得到的预测结果与真实的 tokens 之间的误差作为损失。它告诉了我们直接 reconstruct sentence 也可以做到很 work。
对于 MAE 模型而言,一个 image 中间盖住一些 patches,让模型去预测,令得到的预测结果与真实的 image patches 之间的误差作为损失。它告诉了我们直接 reconstruct image 原图也可以做到很 work。

MAE架构:Mask 掉输入图像的随机的 patches 并重建它们。它基于两个核心理念:研究人员开发了一个非对称编码器 - 解码器架构,其中Encoder编码器只对可见的 patch 子集进行操作 (即没有被 mask 掉的 token),Decoder解码器可以从潜在表征和被 masked 掉的 token 重建原始图像。Decoder 的架构可以是十分轻量化的模型,且具体的架构对模型性能影响很大。研究人员进一步发现,Mask 掉大部分输入图像 (例如 75%)会产生重要且有意义 的自监督任务。
MAE 方法严格来讲属于一种去噪自编码器 (Denoising Auto-Encoders (DAE)),去噪自动编码器是一类自动编码器,它破坏输入信号,并学会重构原始的、未被破坏的信号。MAE 的 Encoder 和 Decoder 结构不同,是非对称式的。Encoder 将输入编码为 latent representation,而 Decoder 将从 latent representation 重建原始信号。
MAE 和 ViT 的做法一致,将图像划分成规则的,不重叠的 patches。然后按照均匀分布不重复地选择一些 patches 并且 mask 掉剩余的 patches。作者采用的 mask ratio 足够高,因此大大减小了 patches 的冗余信息,使得在这种情况下重建 images 不那么容易。(Hard Sample思想,增大loss加速收敛)
算法流程:
-
首先将input image切分为patches,执行mask操作,然后只把可见的patches送入encoder中,再将encoder的输出(latent representations)以及mask tokens作为轻量级decoder的输入,decoder重构整张image
-
编码器: 编码器实际上就是ViT,将input image切分为不重叠的patches之后,执行linear projection,再加上positional embeddings (the sine-cosine version) ,然后送入transformer blocks
-
解码器: 同样使用ViT,将mask tokens和encoded visible patches作为输入,加上位置编码 (the sine-cosine version) 。decoder的最后一层是linear projection,输出通道数量和一个patch内的pixel数量相同(方便重构),然后再reshape,重构image。损失函数使用MSE,损失函数只对masked patches计算(和BERT相同)。同时作者也尝试了normalization的方式,即计算一个patch内像素值的均值和标准差,然后对patch执行normalization,此时encoder的重构任务发生了一些变化,需要重构normalized pixel values,实验表明这种方式效果更好一点
-
MAE中decoder的设计并不重要,因为预训练结束之后,只保留encoder,decoder只需要完成预训练时的图像重构任务。但是作者也表示decoder决定了latent representations的语义级别
为什么 BERT (2018) 提出这么久以后,直到 BEIT (2021.6) 和 MAE (2021.11) 之前,一直在 CV 领域都没有一个很类似的 CV BERT 出现?
- CV 和 NLP 主流架构不同:直到 ViT (2020.12) 出现之前,CV 的主流架构一直是以卷积网络为主,NLP 的主流架构一直是以 Transformer 为主。卷积核作用在一个个的 grid 上面,直观来讲没法产生像 Transformer 一样的 token 的概念,也就是说如果我们只使用卷积网络,那么 image token 概念的建立就不那么直观。所以,像 Transformer 那样在 token 的基础上进行自监督学习就不太适用,这是第一个难点。
- 语言和图片 (视频) 的信息密度不同:语言是人类造就的信号,它 highly semantic , information-dense。而图片 (视频) 是自然产生的信号,它 heavy spatial redundancy。即挡住图片的一部分 patches,可以很容易地通过看它周围的 patches 而想象出它的样子来。所以,语言和图像,一个信息密度高,一个信息密度低,这是第二个难点。解决的办法是什么呢?作者提出了一个简单的策略:即挡住图片的 patches 的比例高一些。比如之前你挡住一张图片的 30% 的 patches,能够轻松通过周围的 patches 预测出来;那现在如果挡住图片的 90% 的 patches,还能够轻松通过周围的 patches 预测出来吗?
- AutoEncoder 里面的 Decoder 部分 (就是将映射得到的中间特征重建为 input 的模块) 在 CV 和 NLP 中充当的角色不同:在 CV 领域,Decoder 的作用是重建 image pixels,所以 Decoder 的输出语义级别很低。在 NLP 领域,Decoder 的作用是重建 sentence words ,所以 Decoder 的输出语义级别很丰富。
1.1 MAE Encoder
MAE Encoder 采用 ViT 架构,但只会作用于 unmasked images。和 ViT 思路一样,MAE Encoder 会先通过 Linear Projection 编码图片,再加上位置编码,随后送入一堆连续的 Transformer Block 里面。但是编码器只对整个图片 patches 集合的一个小子集 (例如25%)进行操作,而删除 masked patches。这里和 BERT 做法不一样,BERT 使用对于 mask 掉的部分使用特殊字符,而 MAE 不使用掩码标记。
1.2 MAE Decoder
MAE Decoder 采用 Transformer 架构,输入整个图片 patches 集合,不光是 unmasked tokens (图4中蓝色色块),还有被 mask 掉的部分 (图4中灰色色块)。每个 mask tokens 都是一个共享的、学习的向量,它指示了这里有一个待预测的 tokens。作者还将位置嵌入添加到这个完整 image patch 集合中的所有 tokens 中,位置编码表示每个 patches 在图像中的位置的信息。
MAE Decoder 仅用于预训练期间执行图像重建任务。因为自监督学习的特点就是只用最后预训练好的 Encoder 完成分类任务。因此,可以灵活设计与编码器设计无关的解码器结构。作者用比编码器更窄更浅的很小的解码器做实验。 在这种非对称的设计下,tokens 就可以由轻量级解码器处理,这大大缩短了预训练的时间。
1.3 自监督学习目标函数 Reconstruction Target
Decoder 的最后一层是一个 Linear Projection 层,其输出的 channel 数等于图像的像素 (pixel) 数。所以 Decoder 的输出会进一步 reshape 成图像的形状。损失函数就是 MSE Loss,即直接让 reconstructed image 和 input image 的距离越接近越好。
作者还尝试了另外一种损失函数,就是先计算出每个 patch 的像素值的 mean 和 deviation,并使用它们去归一化这个 patch 的每个像素值。最后再使用归一化的像素值进行 MSE Loss 计算。但是发现这样做的效果比直接 MSE Loss 好。
1.4 具体实现
MAE 的具体实现方法是:
- 首先通过 Linear Projection 和位置编码得到 image tokens。
- 随机 shuffle 这些 tokens,按照 masking ratio 扔掉最后的一部分。
- 把 unmasked patches 输出到 Encoder 中,得到这些 tokens 的表征。
- 把 Encoder 的输出,结合 masked tokens (可学习的向量),执行 unshuffle操作恢复顺序,再一起输入到 Decoder 中。
- shuffle 和 unshuffle 操作的时间开销可忽略不计。
MAE的优势
(1)Scalable:encoder只操作可见patches,把mask tokens给本身参数就不多的decoder去运算,大大降低了计算量,尤其当mask的比例很高的时候,大大减少了预训练时间,让MAE可以很轻松的scale到更大的模型上(enabling us to easily scale MAE to large models),并且通过实验发现随着模型增大,效果越来越好
(2)高容量且泛华性能好(very high-capacity models that generalize well):使用MAE预训练方法,可以训练很大的model,比如ViT-Large/Huge,当把预训练好的ViT-Huge迁移到下游任务时,模型表现非常好,甚至超过了使用监督预训练的相同模型(achieves better results than its supervised pre-training counterparts),这说明MAE预训练学习到的表示可以很好的泛化到下游任务(these pre-trained representations generalize well to various downstream task)
2. 实验分析
在ImageNet-1K上自监督预训练,使用标准ViT结构,预训练后,使用encoder进行微调和linear probing,因为是用于图像分类,所以类似于ViT,在输入加一个class token(an auxiliary dummy token),实验结果表明使用average pooling可以达到相同的效果
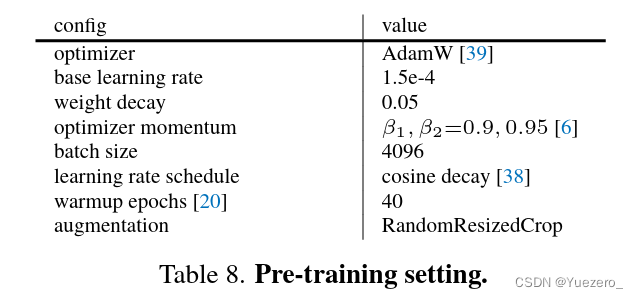
(1)预训练阶段
没有使用color jittering(数据增强的方式之一)、drop path(dropout的变体)、gradient clip(设置阈值预防梯度爆炸/消失)。是ViT官方代码相同,使用xavier uniform初始化所有Transformer blocks。使用linear learning rate scaling rule
(2)端到端微调
使用layer-wise learning rate decay

(3)linear probing
训练设置参考MoCov3,linear probing和端到端微调有很大不同,regularization对linear probing来说可能会损失模型性能,因此和MoCov3中一样,舍弃了一些regularization strategies

(4)部分微调(partial fine-tune):
linear probing缺少非线性建模能力(it misses the opportunity of pursuing strong but non-linear features—which is indeed a strength of deep learning),partial fine-tune 只微调encoder最后个layers,其超参数等设置和微调时相同的(table 9),除了调整了fine-tunning epochs
四个阶段均计算top-1 accuracy(224x224),使用ViT-Large作为baseline,进行ablation study。对比ViT-Large 从头训练(200 epochs)和微调(50 epochs)两种方式,可以发现train from scratch效果并不如微调
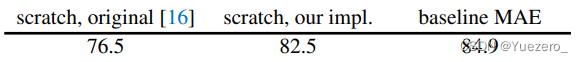
用 MAE 做 pre-training 只需 ImageNet-1k 就能达到 87.8% 的 Top-1 准确度,超过了所有在 ImageNet-21k pre-training 的 ViT 变体模型。而从方法上看,MAE 选择直接重建原图的元素,而且证明了其可行性,改变了人们的认知,又几乎可以覆盖 CV 里所有的识别类任务,看起来像是开启了一个新的方向。直接重建原图的元素是非常重要的,因为通过这个形式,作者就用最最直观的方式完成了 MIM 任务,使得 MIM的潜力逐步被证实。从 MLM 到 MIM 的过渡已被证明,由此观之比肩 GPT3 的 CV 预训练大模型已不远矣。