【操作系统三】图解网络IO+实战
- 一、计算机组成
- 二、系统中断
- 三、晶振(时间中断、分时复用)
- 四、事件中断
- 1、DMA
- 2、事件中断
- 3、网卡也会产生中断?
- 五、linux系统知识
- 1、linux下一切皆文件?
- 1.1、nc启动一个服务端,端口号8080
- 1.2、linux下一切皆文件.
- 1.3、程序有三个基本的流.
- 1.4、监听和建立链接.
- 2、linux系统文档
- 2.1、安装系统文档
- 2.2、查看第二类的系统文档。
- 2.3、知识连接
- 2.4、linux系统函数给出的,创建socket的例子
- 六、网络通信IO
- 1、什么是io?
- 2、BIO
- 2.1、bio工作流程如下。
- 2.2、bio的问题(read阻塞)
- 2.3、怎么解决bio的阻塞问题
- 3、NIO
- 4、多路复用(slect)
- 5、epoll
- 5.1、简介
- 5.2、相关函数介绍
- 5.2.1、epoll_create
- 5.2.2、eopll_ctl
- 5.2.2、eopll_wait
- 5.3、epoll的过程
- 5.4、aio和epoll
- 七、知识互联:kafka用到的三个技术点
- 1、kafka写数据为何那么快?mmap
- 2、kafka读数据为何那么快?零拷贝
- 3、kafka其实还用到了nio/epoll
- 七、知识互联:redis、ngnix
- 简介
上一章,我们讲解过了TCP/IP模型,本篇我们详细的介绍下网络通信中的io知识,包括bio、nio、slect、epoll。考虑到很多同学并非计算机专业出身,在讲解这些知识之前,我们还提前补充了计算机组成、系统中断、晶振的时间中断和事件中断等。
一、计算机组成
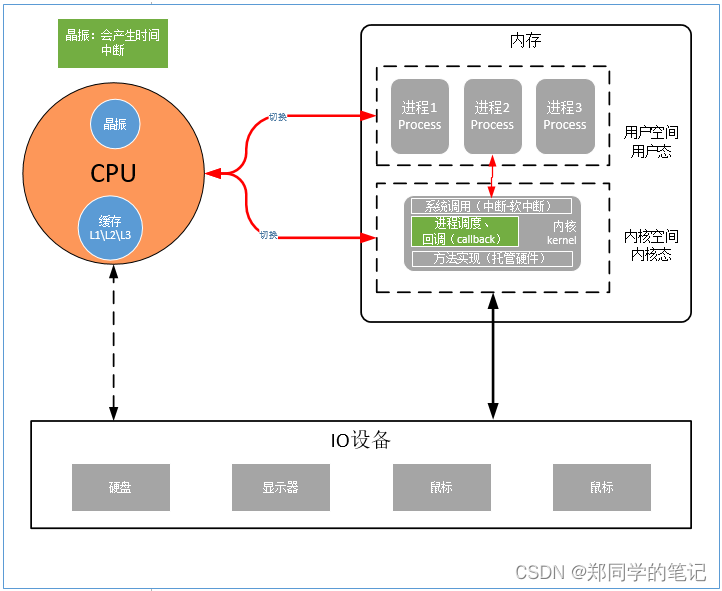
对于非计算机专业的同学,很多人并没有系统的学习过计算机操作系统和计算机网络等。比如冯诺依曼模型:中央处理器(CPU)、内存、输⼊设备、输出设备、总线。
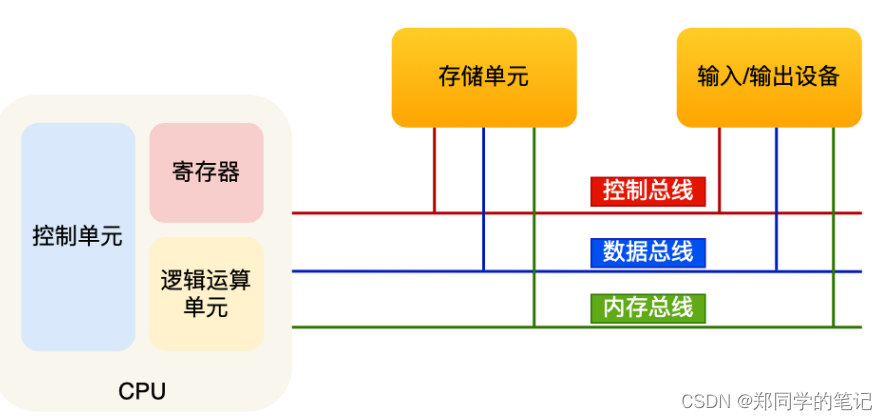
对于上图,非计算机的同学理解起来还是太抽象。我们可以简单的把计算机简单的分为:cpu、内存、io设备。(如下图)
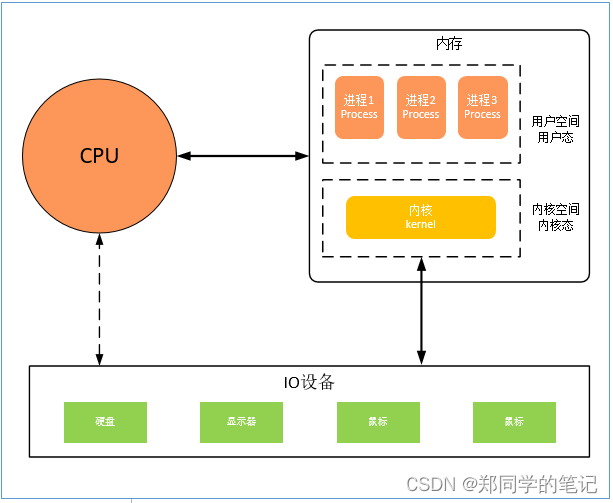
- 在开机前,计算机内存是空的。内存分为用户空间、内核空间(也叫用户态和内核态)。
- 内核也是一个程序?
开机时,首先会把计算机的内核(kernel)加载到内存中。内核进入内存中时,首先会划分一个空间,就是内核空间。
用户的进程存活在用户空间。 - 为何要有内核?
多个进程访问硬件,需要通过内核。内核托管了硬件。
二、系统中断
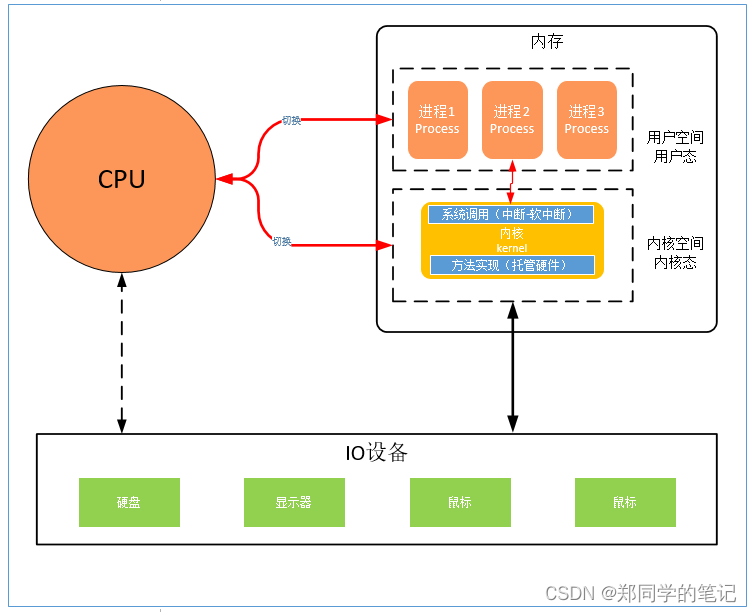
- 用户程序直接访问内核空间?
答:不可以。cpu有一个保护机制,开机时会划分出内核空间,受保护的。 - 用户程序如何访问硬件?
答:通过内核的系统调用。内核有一个系统调用,系统调用走的是软中断。此时,cpu会有一个从用户态到内核态的切换。内核里面,会有一些硬件的访问,封装的一些方法。而这些方法,通过中断的方式调取。(软中断)
三、晶振(时间中断、分时复用)
假如只有1个cpu,内核和系统进程间是怎么运行的?也就是说,假如一个进程不释放cpu,其他的怎么继续执行?
- cpu内有一个晶振。
- 从cpu通电开始,晶振一直在嗒嗒嗒的震动。(比如,1秒中震动1万次)
- 计算机系统是分时的,一个时间片是多久。(假如,1个时间片是1毫秒)
- 比如晶振1毫秒可以震动10次。(晶振震动10次会产生一个中断(时间中断))
- 产生中断后。
- 内核启动时,会在内核中埋一个进程调度的回调地址(callback)
- 假如进程1的时间片用完了,pia的以下就会产生一个中断。(cpu可以执行其他进程了(包括内核))
- 首先,把进程1的现场保护起来。
- 然后,调用进程调度的回调地址,知道该调用哪个进程了,
- 最后,把另外一个进程2(比如应该执行进程2了)加载起来。
- 这样就可以执行进程2了,如此反复。
备注:
- 进程间的的分时复用,依赖晶振的中断,成本较大。比如真的切换到进程2了,进程2也不一定要执行,也可能在阻塞。
- cpu不能百分百作用在业务上,有可能50%的时间都在调度上。
四、事件中断
CPU假如只有一颗,比如,同时接收网卡数据、移动鼠标
1、DMA
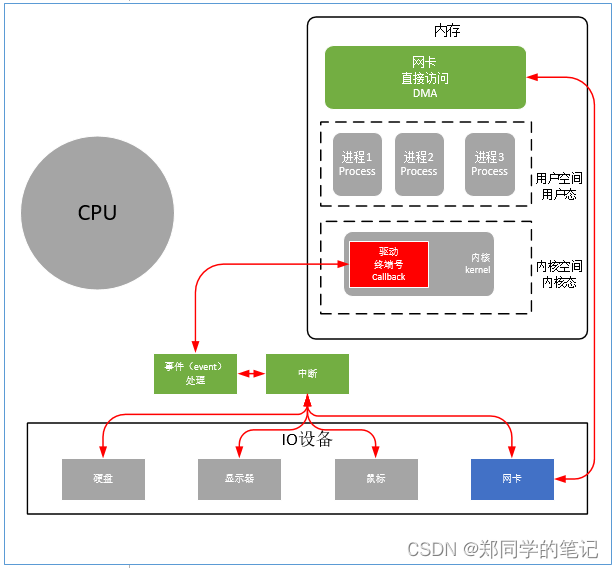
DMA,全称Direct Memory Access,即直接存储器访问。
DMA传输将数据从一个地址空间复制到另一个地址空间,提供在外设和存储器之间或者存储器和存储器之间的高速数据传输。当CPU初始化这个传输动作,传输动作本身是由DMA控制器来实现和完成的。DMA传输方式无需CPU直接控制传输,也没有中断处理方式那样保留现场和恢复现场过程,通过硬件为RAM和IO设备开辟一条直接传输数据的通道,使得CPU的效率大大提高。
2、事件中断
- 当io设备接收到数据时,会产生一个事件中断,等待cpu进行处理。
3、网卡也会产生中断?
- 网卡也会产生中断?
答:网卡也是一个io设备,也会产生中断事件。 - DMA用来干啥?
答:DMA就是内存中的一个区域,网卡的数据来了后,可以直接把数据存入DMA. - 有什么用?
答:网卡来了数据后,可以直接存入DMA,不用每次都都产生一个cpu中断。 - 为何不每次产生cpu中断?
答:cpu内存寻址的速度是纳秒,io的操作都是毫秒。
如果在cpu处理其他过程中,我们直接把数据放入dma,就可以告诉cpu,你去操作数据吧,这样cpu的效率就是纳秒。
如果中间染指了io操作,那cpu就变成了毫秒。
五、linux系统知识
1、linux下一切皆文件?
1.1、nc启动一个服务端,端口号8080
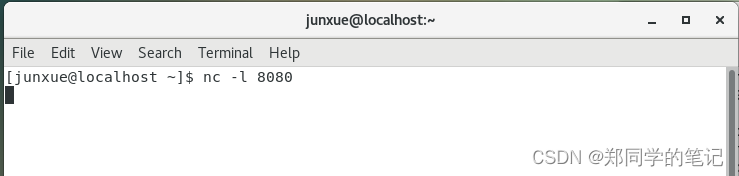
- 命令如下
nc -l 8080
-
输出如下,监听成功。
-
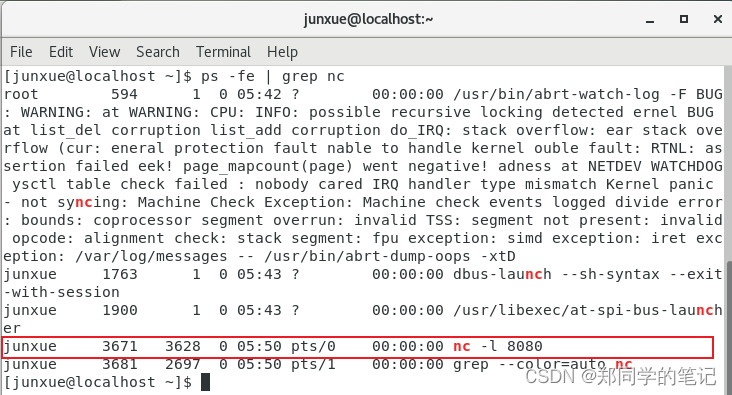
查看nc进程id,
ps -fe | grep nc
- 如下图,进程id3671
1.2、linux下一切皆文件.
- 根目录下,有一个文件夹proc。(开机才有,平时是空的)
cd /
ll
-
输出如下,有一个存放进程的文件夹proc.
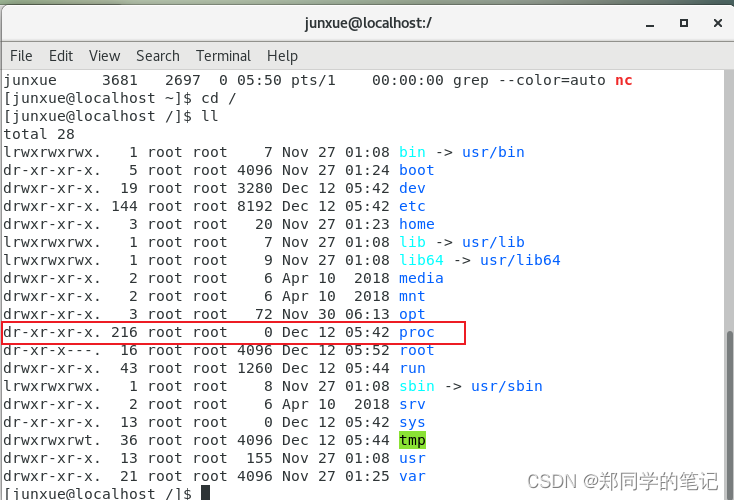
-
进入proc目录,找到进程id为3671的文件夹,如下图
cd proc
ls
- 输出如下,proc里面存的是所有的进程。
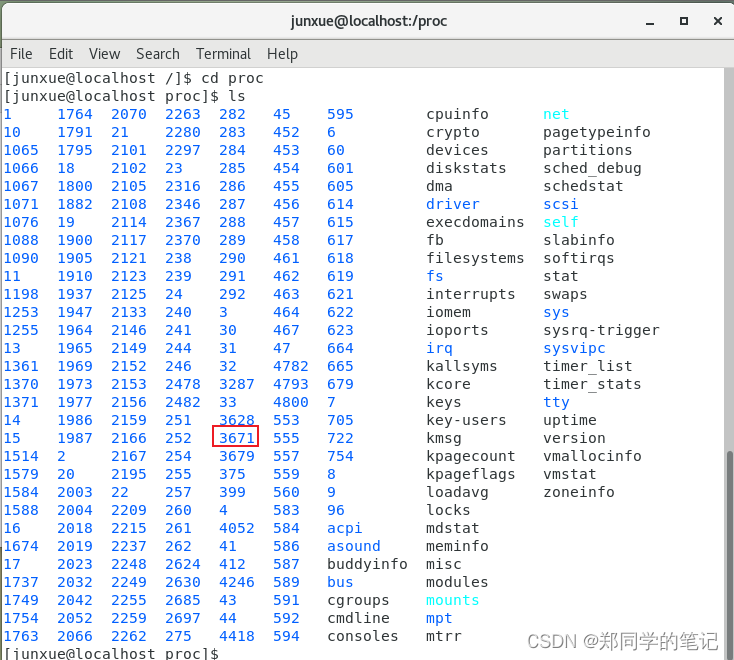
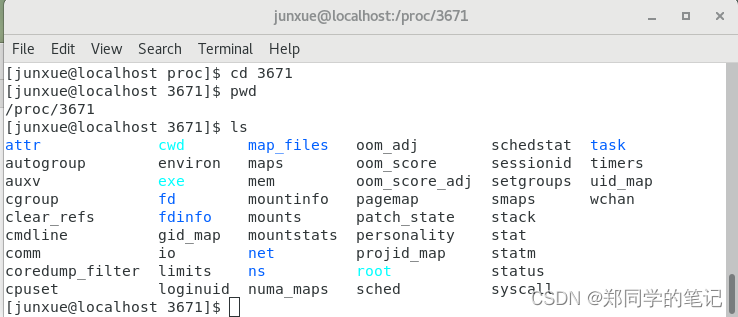
- 进入进程3671的文件夹。进程抽象成了文件。
cd 3671
pwd
ls
- 输出如下
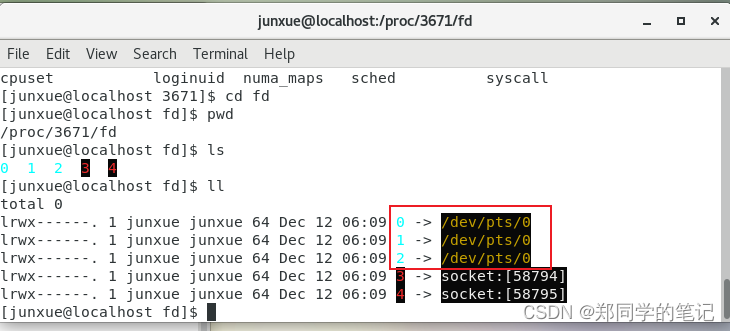
1.3、程序有三个基本的流.
一个程序有三个基本的流:输入流、输出流、错误流。1、2、3是文件描述符。
- 0:输入流
- 1:输出流
- 2:错误流
- 3:socket的监听的文件描述符。
cd fd
pwd
ll
- 输出如下
备注:今天就写到这里吧,后面的会基于此继续写。后面的nc的进程号可能会变。
1.4、监听和建立链接.
分别启动3个shell
1、使用nc启动一个服务端
nc -l 8080
2、使用nc启动一个客户端,和服务端建立链接,(如下图,分配的随机端口号为58438)
nc localhost 8080
3、查看建立的链接
netstat -natp
-
输出如下

-
查看客户端进程的fd目录如下
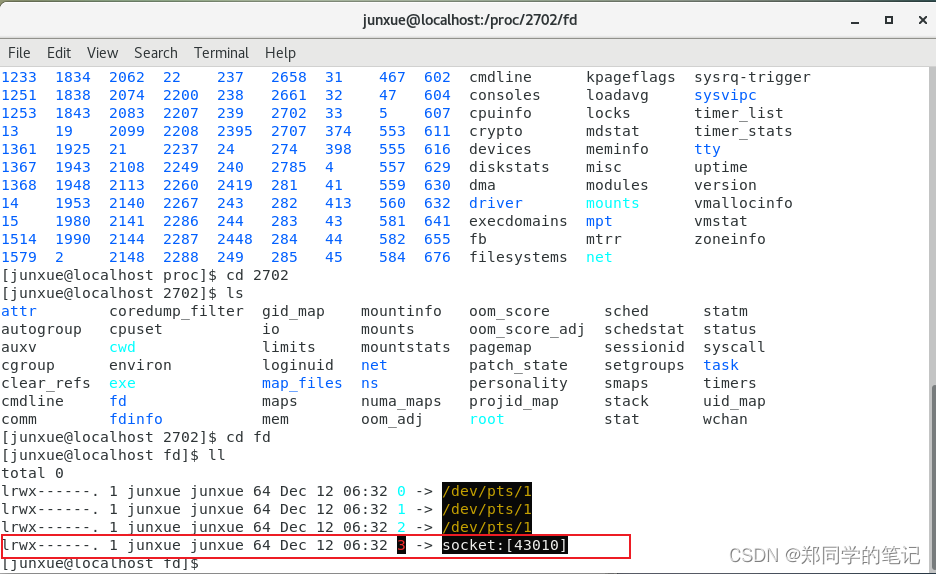
-
问题:为何服务端下的fd有2个socket,而客户端下有1个socket.
答:因为服务端除了建立链接,还需要监听,所以需要两个文件描述符。
2、linux系统文档
2.1、安装系统文档
yum instal man-pages
2.2、查看第二类的系统文档。
- 系统文档一共有8类。第二类是系统调用。
- 我们查看第二类的系统文档中的socket
man 2 socket
- 输出如下图,系统调用是提供的c的调用方式。
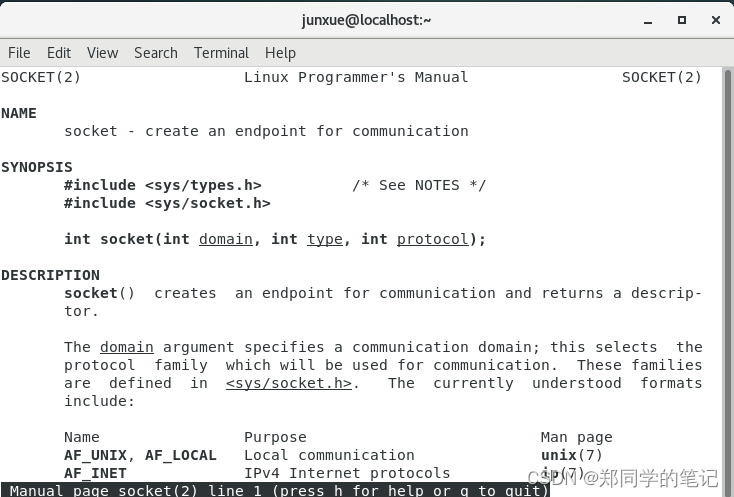
上面的图片往下拉下,可以看到,socket返回一个文件描述符。
RETURN VALUE
On success, a file descriptor for the new socket is returned. On
error, -1 is returned, and errno is set appropriately.
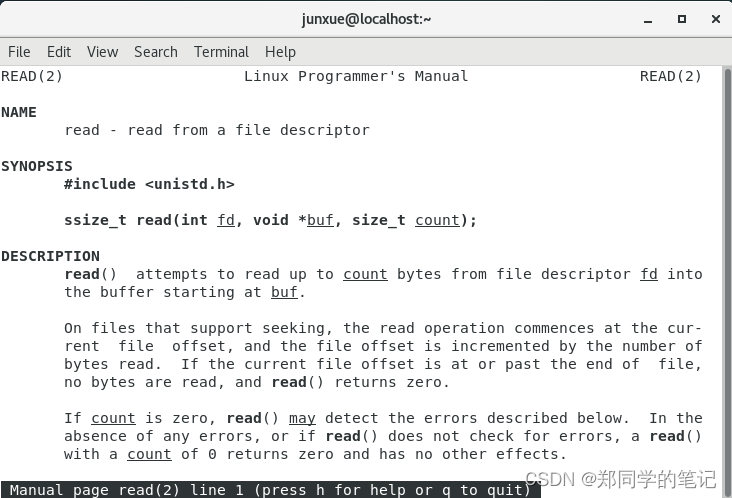
我们获取socket的文件描述符干嘛呢?其实拿到文件描述符就可以操作了。比如使用read函数读文件描述符。
man 2 read
- 输出如下
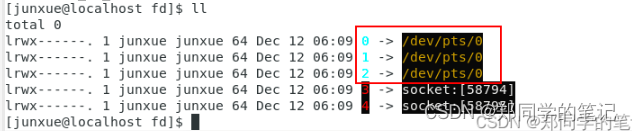
2.3、知识连接
socket返回的文件描述符,也是我们在1、linux下一切皆文件,中看到的,fd目录下的3和4。
所有 io抽象成了文件描述符。
2.4、linux系统函数给出的,创建socket的例子
在函数bind中,有完整的创建socket服务端的例子。
man 2 bind
输出中,有一个examle,从中看到,服务端socket流程,如下
- 创建套接字(socket)
- 绑定端口号(bind)
- 监听(listen)
- 接收数据(accept)
EXAMPLE
An example of the use of bind() with Internet domain sockets can be
found in getaddrinfo(3).
The following example shows how to bind a stream socket in the UNIX
(AF_UNIX) domain, and accept connections:
#include <sys/socket.h>
#include <sys/un.h>
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#define MY_SOCK_PATH "/somepath"
#define LISTEN_BACKLOG 50
#define handle_error(msg) \
do { perror(msg); exit(EXIT_FAILURE); } while (0)
int
main(int argc, char *argv[])
{
int sfd, cfd;
struct sockaddr_un my_addr, peer_addr;
socklen_t peer_addr_size;
sfd = socket(AF_UNIX, SOCK_STREAM, 0);
if (sfd == -1)
handle_error("socket");
memset(&my_addr, 0, sizeof(struct sockaddr_un));
/* Clear structure */
my_addr.sun_family = AF_UNIX;
strncpy(my_addr.sun_path, MY_SOCK_PATH,
sizeof(my_addr.sun_path) - 1);
if (bind(sfd, (struct sockaddr *) &my_addr,
sizeof(struct sockaddr_un)) == -1)
handle_error("bind");
if (listen(sfd, LISTEN_BACKLOG) == -1)
handle_error("listen");
/* Now we can accept incoming connections one
at a time using accept(2) */
peer_addr_size = sizeof(struct sockaddr_un);
cfd = accept(sfd, (struct sockaddr *) &peer_addr,
&peer_addr_size);
if (cfd == -1)
handle_error("accept");
/* Code to deal with incoming connection(s)... */
/* When no longer required, the socket pathname, MY_SOCK_PATH
should be deleted using unlink(2) or remove(3) */
}
六、网络通信IO
1、什么是io?
i就是input,输入,o就是output,输出,合起来就是以流为基本的输入输出。
2、BIO
同步阻塞I/O处理(也就是BIO,Blocking I/O):
当客户端有请求到服务端的时候,服务端就会开启一个线程进行处理,当有多个请求进入时,就会开启多个线程分别处理对应的请求。
2.1、bio工作流程如下。
- 第一步:建立socket链接、绑定端口号、监听。
- 第二部:接收客户端的链接。
- 第三步:接收客户端的数据。
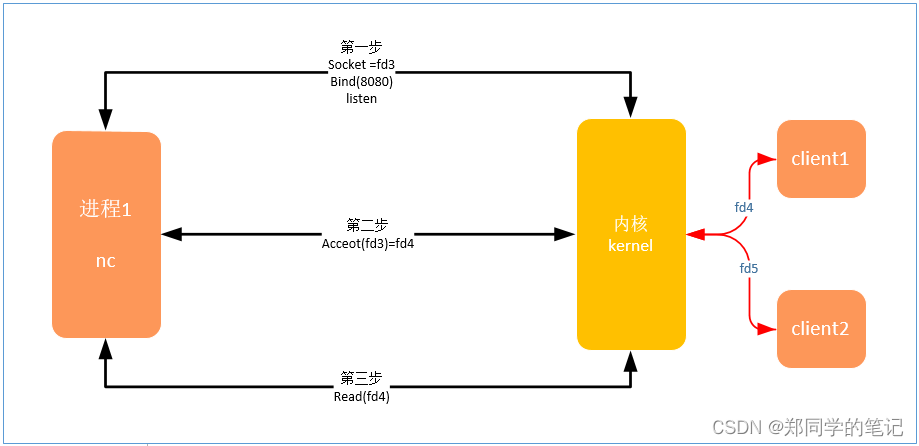
2.2、bio的问题(read阻塞)
- 如下图,当有新的客户端fd过来链接时。
- 从1.1bio的流程可知,bio的read存在阻塞。
2.3、怎么解决bio的阻塞问题
- 方案一:多线程。
抛出一个线程,专门读。如上图,分别读fd4和fd5。
方案一的缺点:10万个链接,对接10万个线程。
-
痛点:线程链接1对1.(因为阻塞)
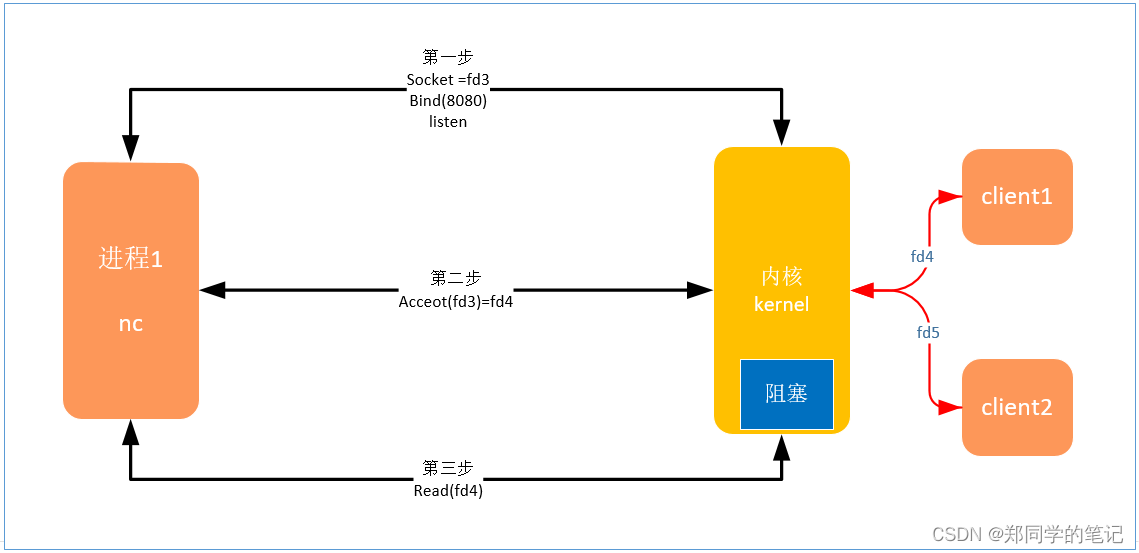
-
方案二:NIO
可以让读文件描述符,变成非阻塞的。读不到数据时,继续往后走。
不用抛出那么多线程了。
3、NIO
- NIO:同步非阻塞式IO,(non-blocking IO、or java中也指的new IO)
- read时没有数据时返回一个错误。不阻塞了。
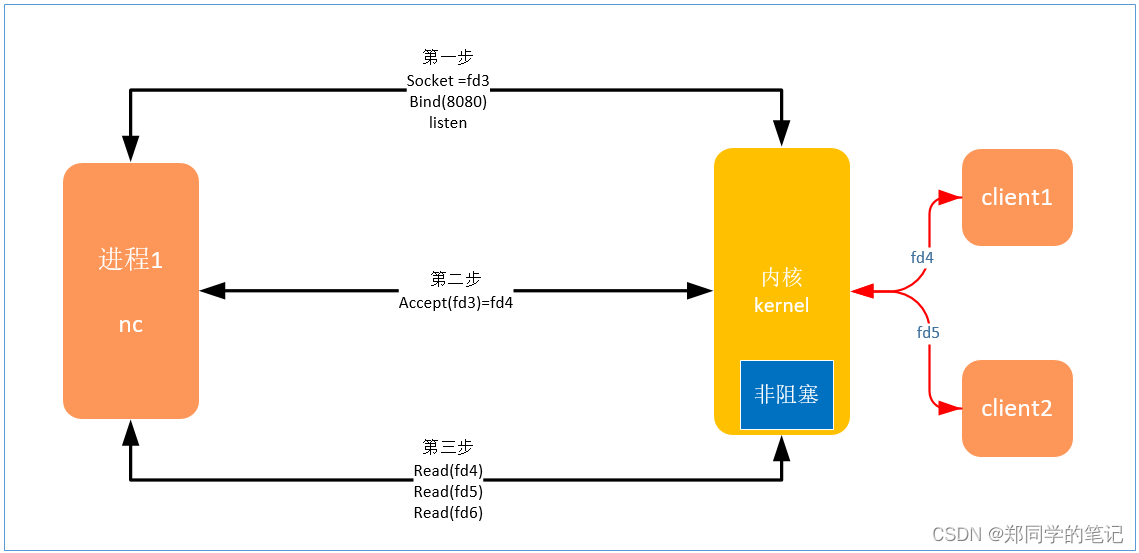
优点:
- 1、10完个链接不需要发出10万个线程了。一个线程就可以搞定了。(或者把接受和工作抛出两个线程)
- 2、减少了cpu在几千几万个线程间的切换的事情了。
- 3、cpu的利用率高了。
问题:
- 1、每次read,都需要把cpu从用户状态,切换到内核状态。
- 2、用户态和内核态切换,有些频繁。(假如有10万个链接,会有10万次的read,10万次的内核态和用户态的切换,假如这其中只有1个客户端发来了数据,那么会有99999次的read的浪费,也就是99999次内核态和用户态切换的浪费)
- read的时间复杂度——O(n) ,时间复杂度n。其中n=10万。
怎么解决?
- 多路复用
4、多路复用(slect)
- 查看多路复用,系统调用的方法。
- slect可以拿到10万个文件描述符中,真正有数据的文件描述符。
man 2 slect
- 多路复用的流程图如下
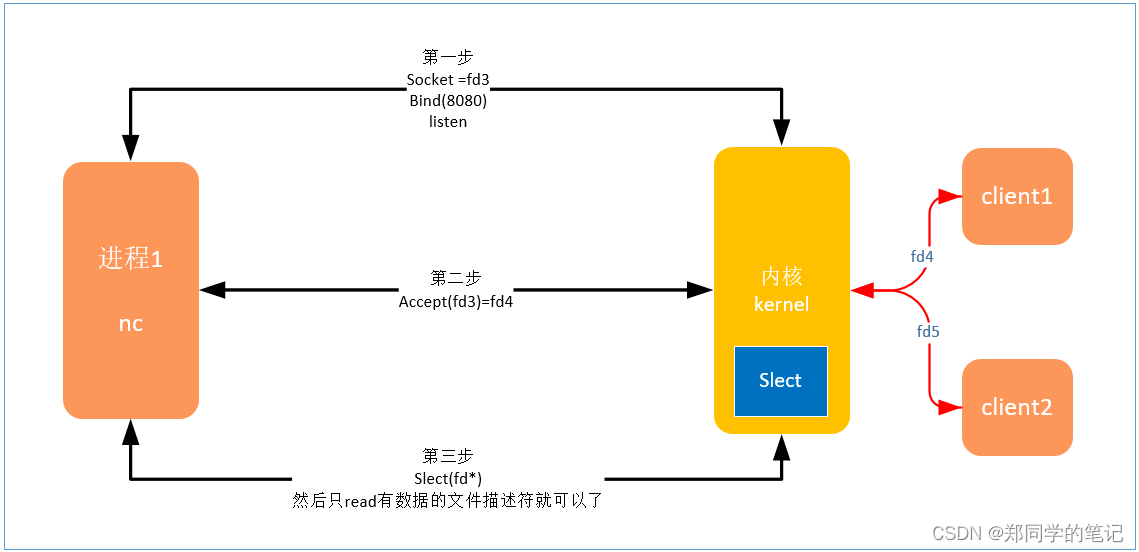
优点:
- slect调用了一次,就知道哪些文件描述符需要读。(比如5个)
- 这样,我们调用5次read就可以了。
- 把10万次的循环,压到了内核里面使用。
- 真正的意义:没有那10万次的内核态和用户态的切换了。
- read的时间复杂度——o(5),假如只有5个文件描述符需要读。
slect有什么弊端?
- 1、没循环fd*,需要把10万次的文件描述符传给内核。
- 2、内核每次都需要循环10万次,找哪些文件描述符需要读。
解决方案
- 1、epoll
5、epoll
5.1、简介
- 如《四、事件中断》介绍,io接收到数据后,就会产生一个中断,且放到了内存dma中了。内核只需要看下io数据属于哪个fd的,然后通知给程序就可以了。
- 这样就是,内核被动的通过中断事件消耗这个事情。而不是主动的便利10万次。
查看epoll
man 7 epoll
- 输出如下(可以看到,epoll属于7类,如果我们使用,需要调用3个二类系统调用的接口epoll_create、epoll_ctl、epoll_wait)
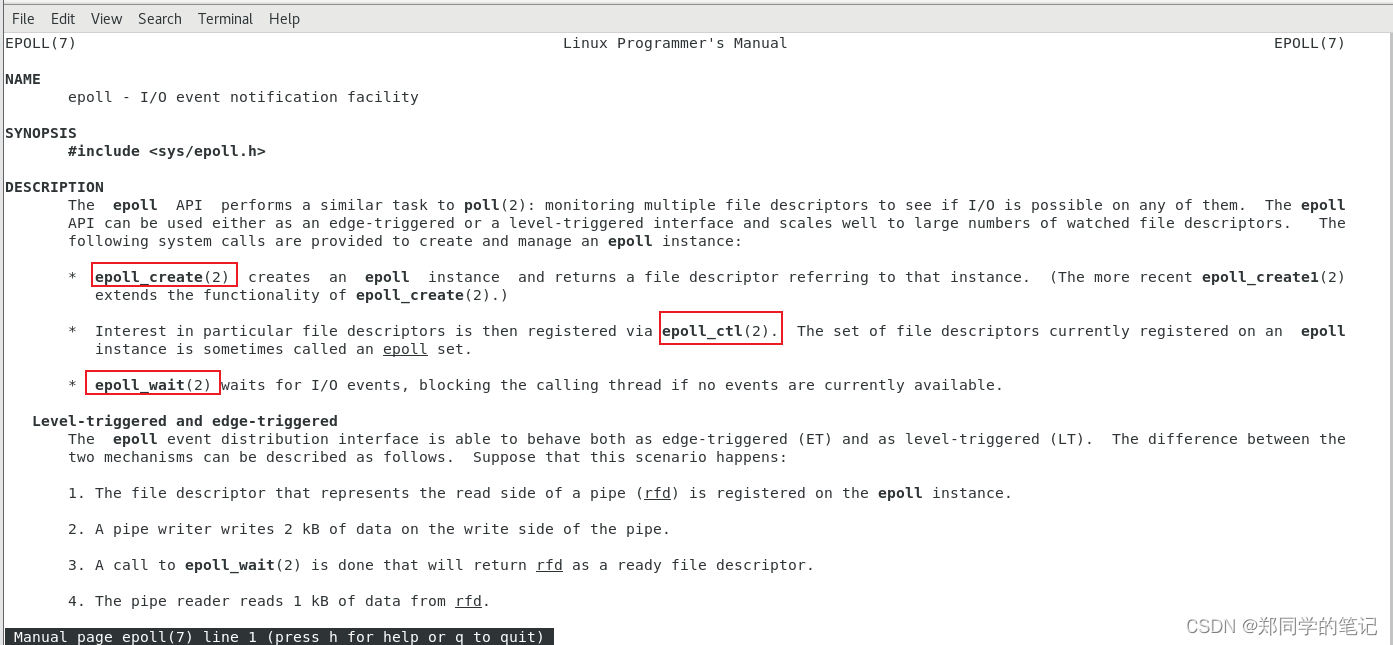
5.2、相关函数介绍
5.2.1、epoll_create
man 2 epoll_create
- 可以看到这个函数的返回值是一个文件描述符,代表内核的一个空间。
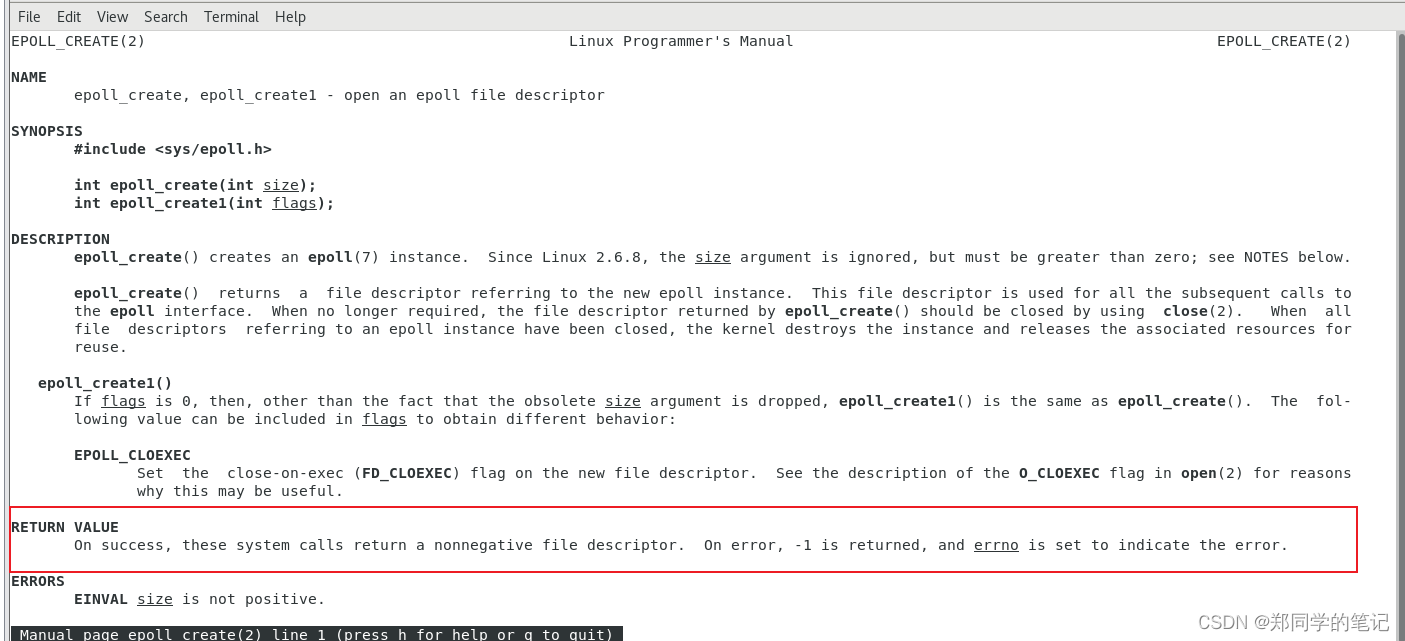
- 这样你就可以把所有的文件描述符放到内核的这个空间中了。
- 怎么把所有的文件描述符放进去?
答:通过epoll_ctl
5.2.2、eopll_ctl
man 2 epoll_ctl
- 可以看到,把客户端来的文件描述符,放到epoll_create创建的空间中,及时来了10万了链接,我们只放一次就可以了。
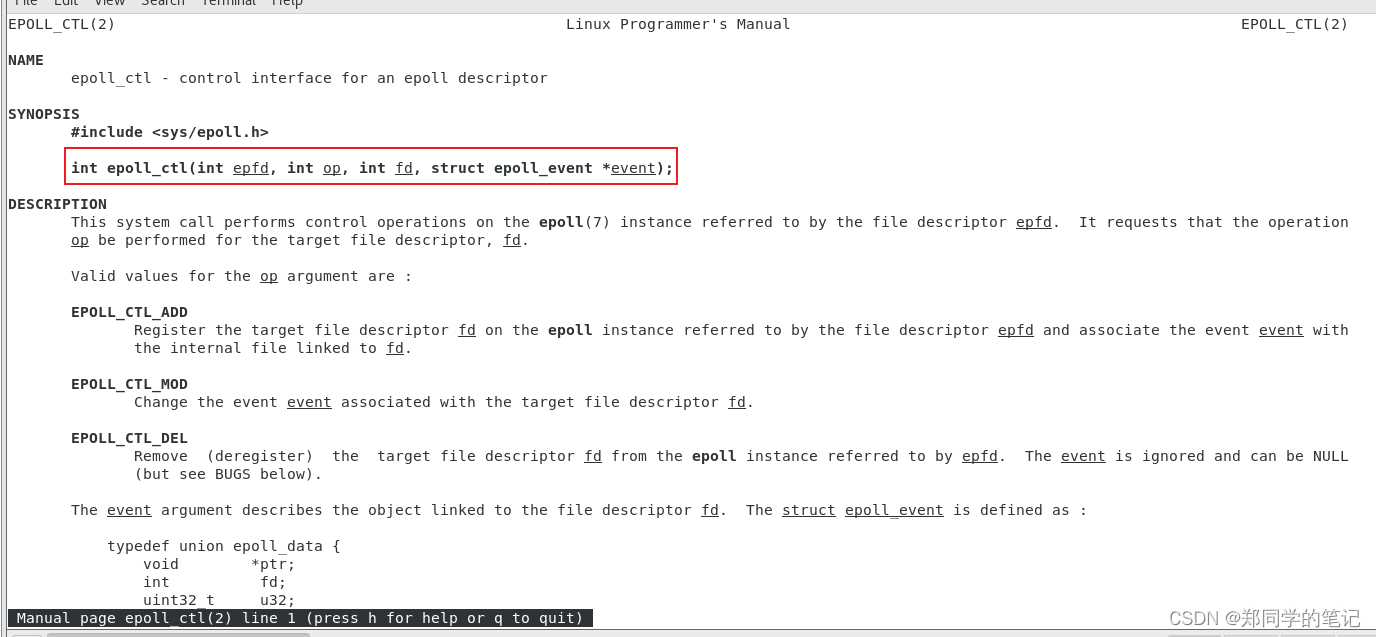
- 我们怎么知道那些客户端的数据到了呢?
答:使用epoll_wait
5.2.2、eopll_wait
man 2 epoll_wait
-
可以看到,假如我们设置了8个文件描述符的结构体,那么当io数据来了8个后,我们就可以产生一个中断事件。
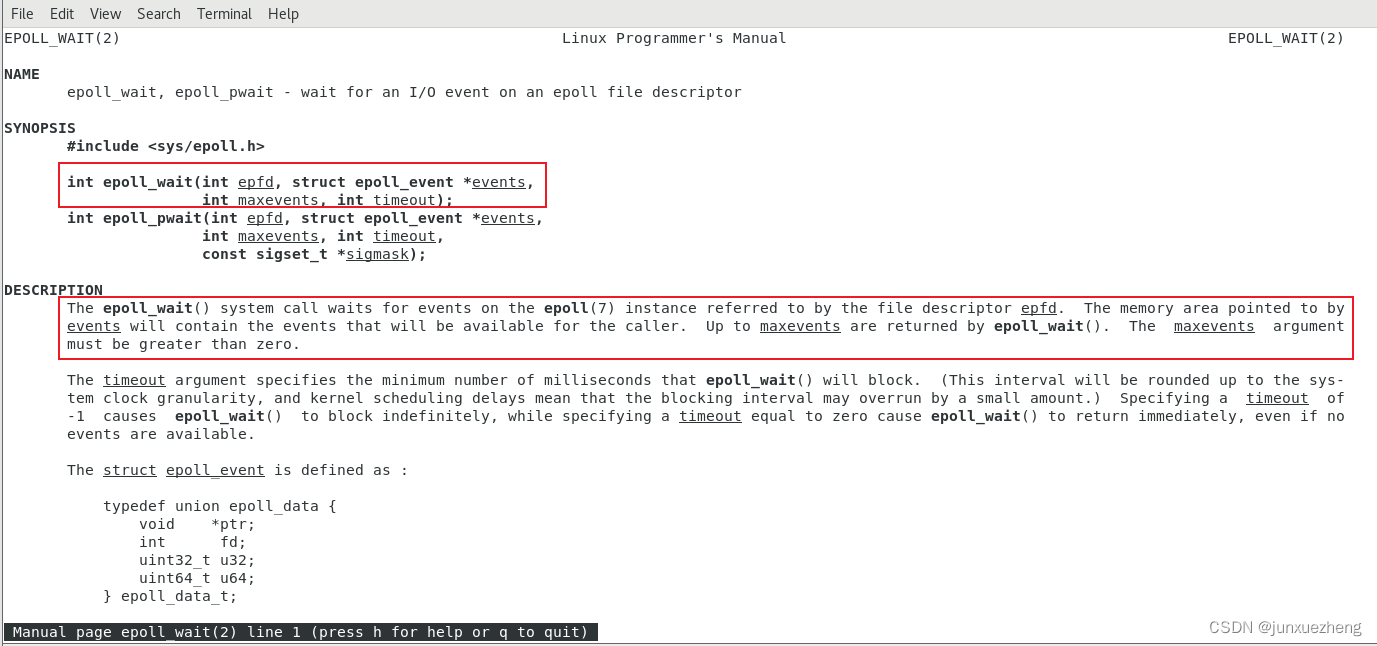
-
epoll vs mmap
问:epoll有使用mmap吗?
答:前期epoll有用mmap,后面epoll没有用mmap
5.3、epoll的过程
前提:已经创建了socket监听,并绑定了端口号,获得了文件描述符fd3.
- 第一步:创建epoll,获取内核空间的一个文件描述符,fd1,
- 第二步:把监听的文件描述符fd3,加入到第一步创建的空间中。埋下接收链接的事件。
- 第三步:等待链接,
- 第四步:若收到了链接fd8,。
- 第五步:把收到的客户端链接的描述符fd8,加入到epoll_create创建的空间中,埋下读数据的事件。
- 第六步:若fd8收到了数据,就会把数据放到dma中,并会产生事件中断。
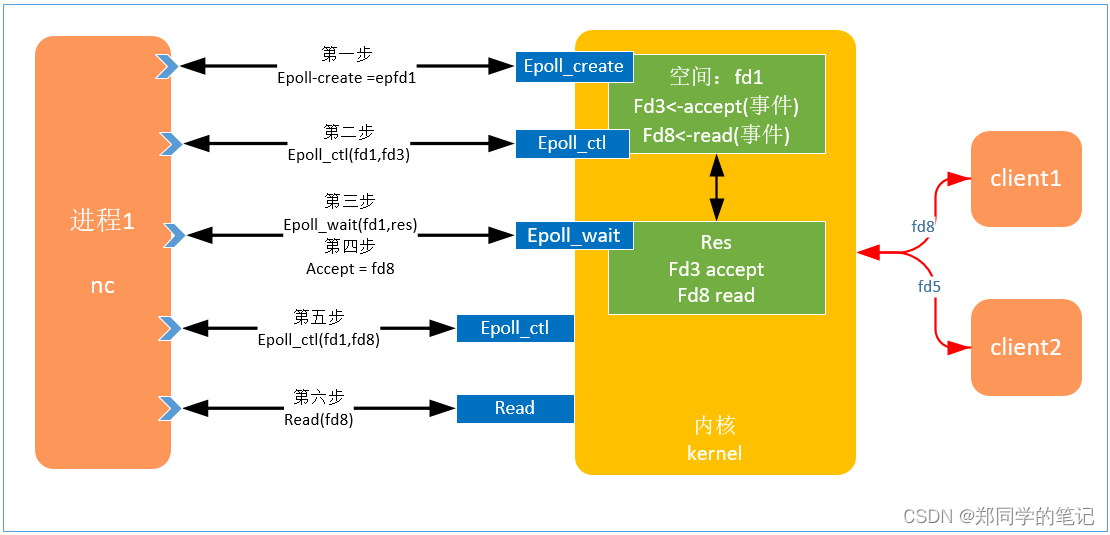
备注:
- 循环的去epoll_wailt。
- 相当于基于event的多路复用。
- epoll只拿到了event,读数据还是要调用read.
- 网卡把数据放到了dma,我们通过事件知道了里面有数据。仅仅把这个事件告诉了你,wait得到了事件。真正操作数据还是要读内核。
优点
- 压榨计算资源到极致。
5.4、aio和epoll
- aio:异步非阻塞,通过回调处理,没有read。(目前非内核提供)
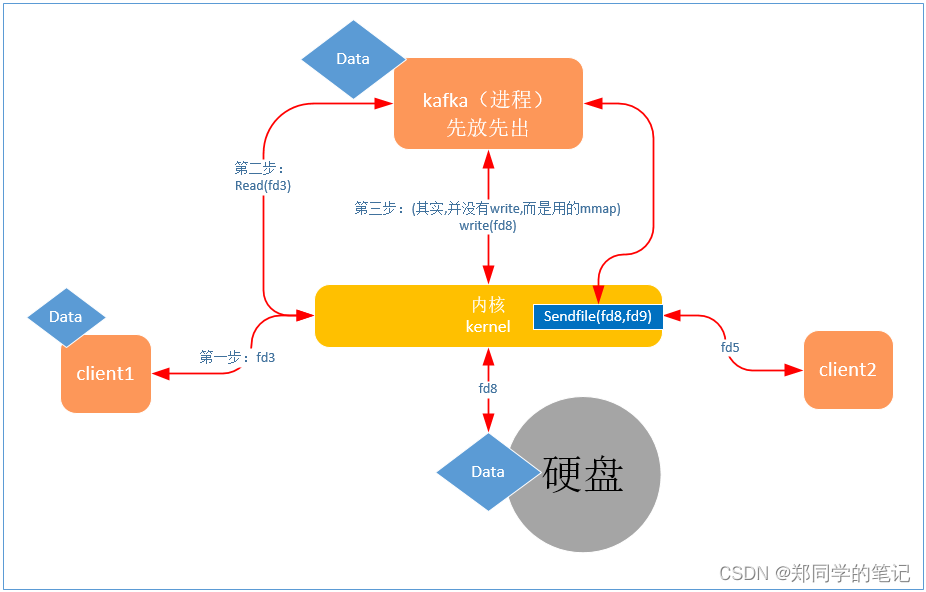
七、知识互联:kafka用到的三个技术点
kafka我们之前介绍过,其实就是mq.(消息队列)
- kafka整个过程
- 第一步:客户端的数据到内核。
- 第二部:kafka进程读取数据。
- 第三步:kafka把数据存入硬盘
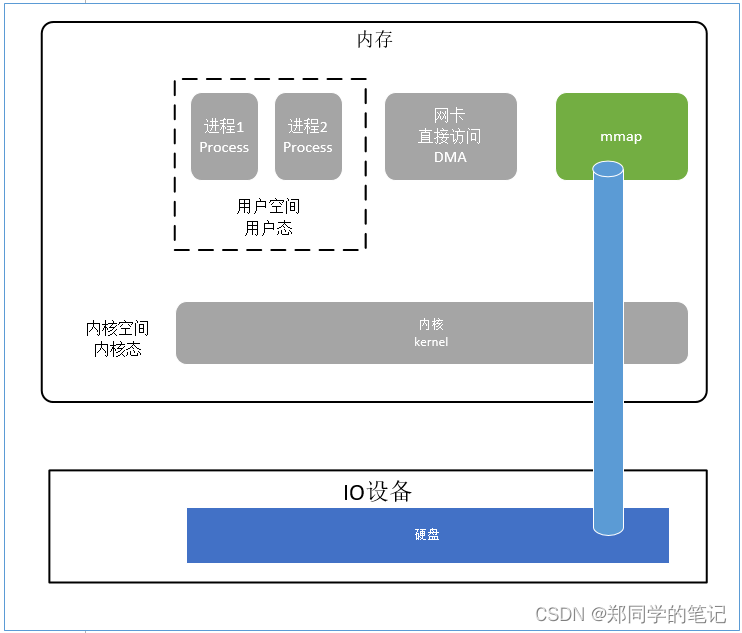
1、kafka写数据为何那么快?mmap
mmap 即 memory map,也就是内存映射
- 实现这样的映射关系后,进程就可以采用指针的方式读写操作这一段内存,而系统会自动回写脏页面到对应的文件磁盘上,即完成了对文件的操作而不必再调用 read、write 等系统调用函数。相反,内核空间对这段区域的修改也直接反映用户空间,从而可以实现不同进程间的文件共享。
- 问:kafka写数据为何那么快?
答:因为写数据采用了mmap,写数据不用系统调用write,写到内存的同时,就同时写到了内核和硬盘里面。少了一次系统调用write的过程。
其他: - kafka配置文件,有个segment01 1G,共享内存就是1个G.硬盘和内核的空间也是1个G.
- 如果segment01满了后,会再次创建segment02 ,也是1个G。
2、kafka读数据为何那么快?零拷贝
- sendfile是在内核中实现的,不需要拷贝了。
- 表示在两个文件描述符之间传输数据,它是在操作系统内核中操作的,避免了数据从内核缓冲区和用户缓冲区之间的拷贝操作,因此可以使用它来实现零拷贝。
3、kafka其实还用到了nio/epoll
- nio和epoll参考之前的介绍。
七、知识互联:redis、ngnix
- redis底层用的是epoll、单线程。
- ngnix底层用的也是epoll、还有零拷贝(sendfile)


![[附源码]Python计算机毕业设计高校互联网班级管理系统Django(程序+LW)](https://img-blog.csdnimg.cn/9a4e835b35dd4808bcc579afe3d882f0.png)
![[附源码]Nodejs计算机毕业设计基于的开放式实验室预约系统Express(程序+LW)](https://img-blog.csdnimg.cn/511c7993069e462487625c6790547362.png)