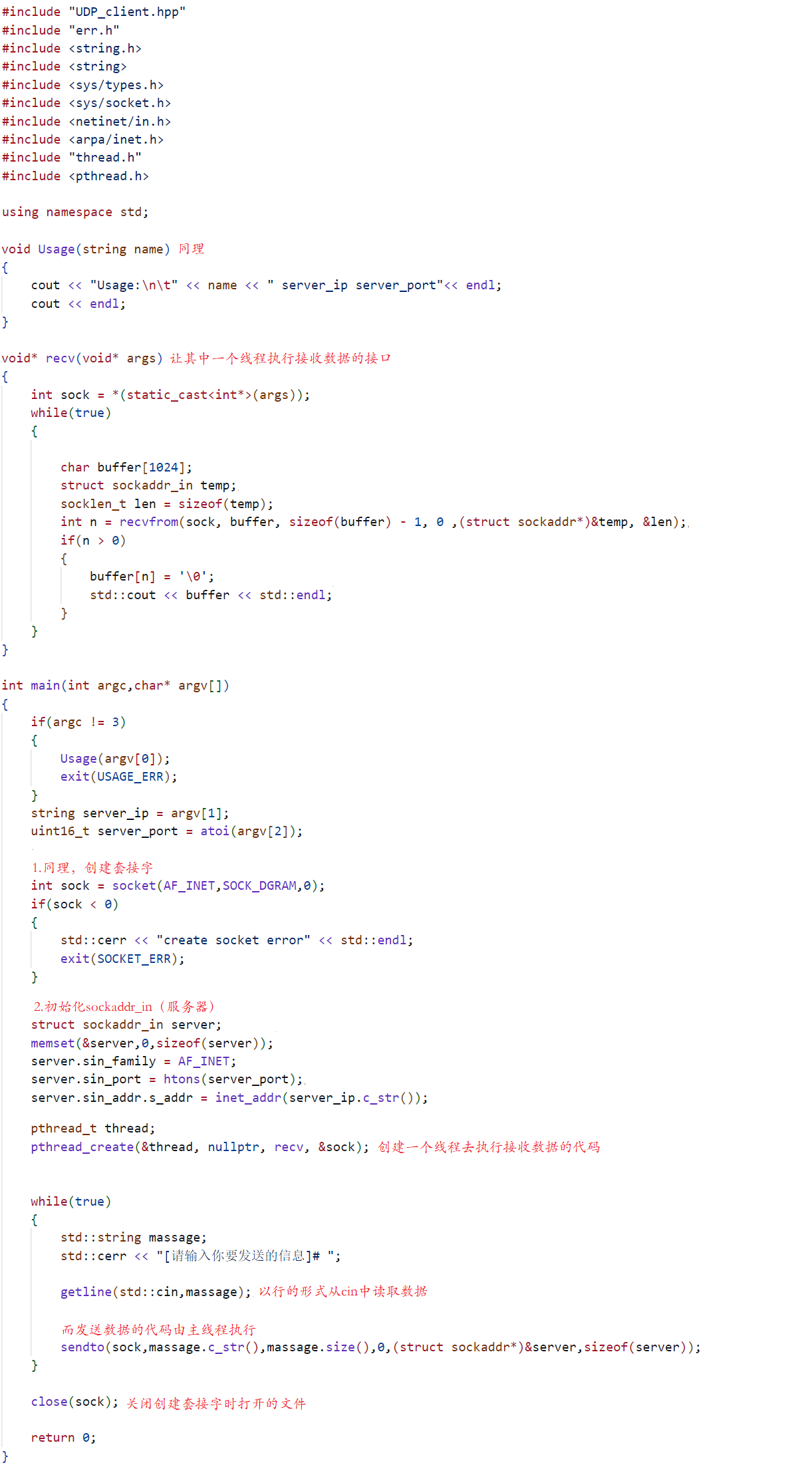
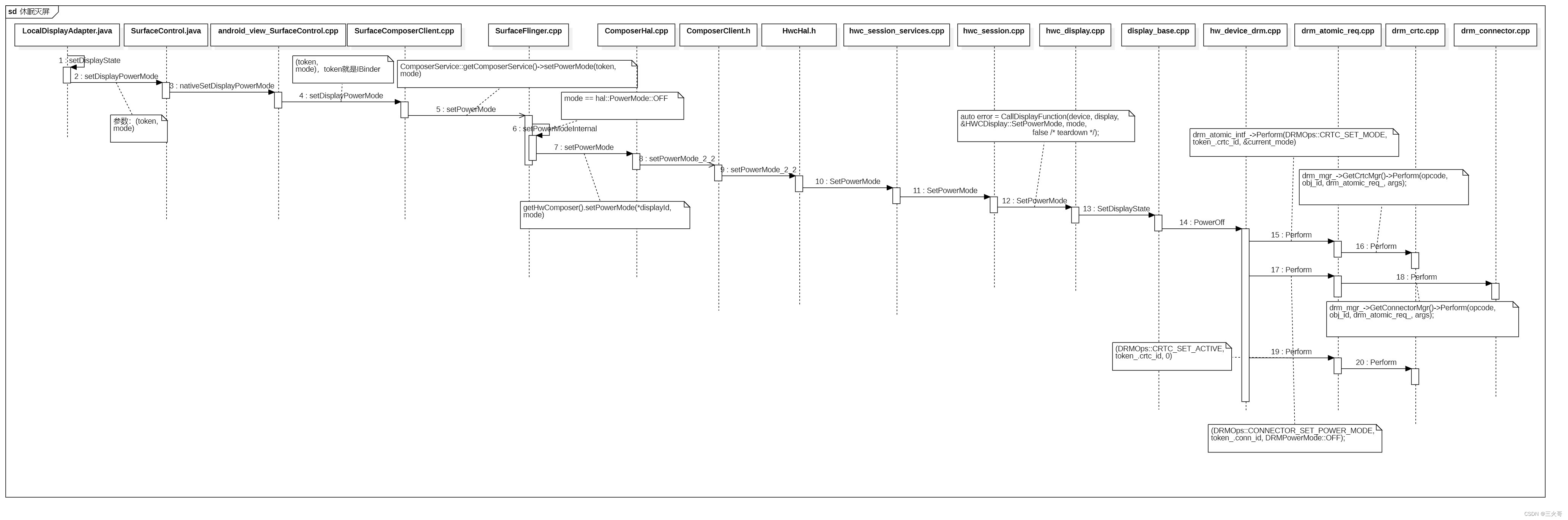
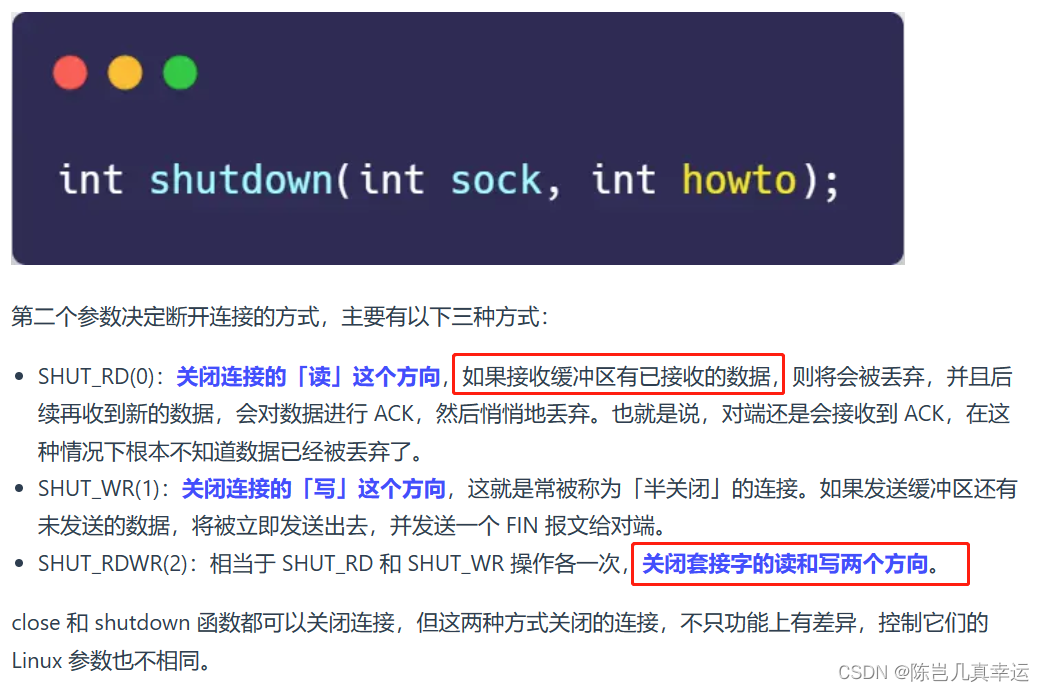
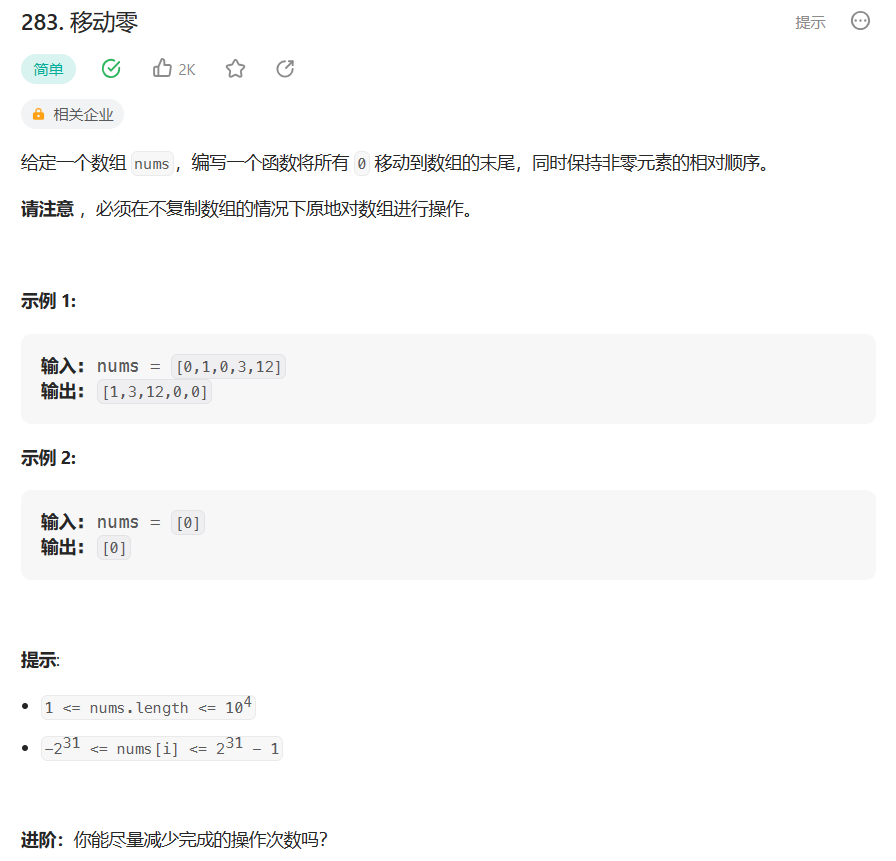
在计算机科学中,数据的压缩与编码一直是重要的研究领域。哈夫曼编码(Huffman Coding)作为一种常用的数据压缩方法,以其高效的压缩率和广泛的应用而闻名。本文将介绍哈夫曼编码的原理、构建过程以及代码实现,并通过符号展示哈夫曼树的构建过程,以帮助读者深入理解这一优秀的编码方案。
哈夫曼树![]() http://t.csdn.cn/7yEWa
http://t.csdn.cn/7yEWa
二叉树原理![]() https://blog.csdn.net/qq_45467165/article/details/132463936?spm=1001.2014.3001.5501
https://blog.csdn.net/qq_45467165/article/details/132463936?spm=1001.2014.3001.5501
哈夫曼编码原理
哈夫曼编码的核心思想是通过将出现频率较高的字符用较短的二进制编码表示,从而实现对数据的高效压缩。这种编码方式的关键在于构建哈夫曼树,一棵特殊的二叉树,其中叶节点代表字符,其路径上的二进制编码即为字符的编码。构建过程分为以下几个步骤:
- 统计每个字符的出现频率,将字符与频率配对,形成字符频率表。
- 将字符频率表中的每个字符看作一个独立的节点,并按照频率构建初始森林。
- 从森林中选取两个频率最低的节点合并,构建一棵新的二叉树,其根节点的频率为这两个节点频率之和。
- 重复步骤3,直到森林中只剩下一棵树,即哈夫曼树。
- 在哈夫曼树中,从根节点到每个叶节点的路径上的分支可以分别表示为0和1,形成字符的二进制编码。
哈夫曼树的构建过程
现在,让我们通过符号来展示哈夫曼树的构建过程。考虑以下字符及其出现频率:
| 字符 | 频率 |
|---|---|
| A | 5 |
| B | 9 |
| C | 12 |
| D | 13 |
| E | 16 |
| F | 45 |
- 我们将按照上述步骤逐步构建哈夫曼树:
- 首先,将每个字符看作独立的节点,并按照频率构建初始森林。
-
A(5) B(9) C(12) D(13) E(16) F(45) - 选取频率最低的两个节点 A(5) 和 B(9),合并它们构建新节点 AB(14)。
-
AB(14) C(12) D(13) E(16) F(45) - 继续选取频率最低的两个节点 AB(14) 和 C(12),合并它们构建新节点 ABC(26)。
-
ABC(26) D(13) E(16) F(45) - 重复上述步骤,合并节点 ABC(26) 和 D(13),构建新节点 ABCD(39)。
-
ABCD(39) E(16) F(45) - 合并节点 ABCD(39) 和 E(16),构建根节点。
ABCDE(55)
/ \
ABCD(39) E(16)
/ \
A(5) B(9)
我们可以清楚地看到哈夫曼树是如何逐步构建起来的。树的构建过程中,频率较低的字符会逐渐被合并,形成树的内部节点,而频率较高的字符则位于叶节点,其编码路径较短,实现了高效的编码方案。
代码实现
这里笔者用python写了一个用于构建哈夫曼树和生成字符的编码:
from heapq import heappush, heappop, heapify
class HuffmanNode:
def __init__(self, char, freq):
self.char = char
self.freq = freq
self.left = None
self.right = None
def __lt__(self, other):
return self.freq < other.freq
def build_huffman_tree(freq_table):
heap = [HuffmanNode(char, freq) for char, freq in freq_table.items()]
heapify(heap)
while len(heap) > 1:
left = heappop(heap)
right = heappop(heap)
merged = HuffmanNode(None, left.freq + right.freq)
merged.left = left
merged.right = right
heappush(heap, merged)
return heap[0]
def generate_huffman_codes(root, prefix="", code_table={}):
if root is not None:
if root.char is not None:
code_table[root.char] = prefix
generate_huffman_codes(root.left, prefix + "0", code_table)
generate_huffman_codes(root.right, prefix + "1", code_table)
# 统计字符频率
frequency_table = {'A': 5, 'B': 9, 'C': 12, 'D': 13, 'E': 16, 'F': 45}
# 构建哈夫曼树
huffman_tree = build_huffman_tree(frequency_table)
# 生成哈夫曼编码
huffman_codes = {}
generate_huffman_codes(huffman_tree, code_table=huffman_codes)
print("字符\t频率\t哈夫曼编码")
for char, freq in frequency_table.items():
print(f"{char}\t{freq}\t{huffman_codes[char]}")
这段代码首先构建了一个简单的哈夫曼树,然后根据哈夫曼树生成了字符的编码。运行代码,你将看到每个字符及其频率和对应的哈夫曼编码。
结论
哈夫曼编码作为一种高效的数据压缩方案,通过构建特殊的二叉树实现了对字符的编码,将出现频率较高的字符用较短的二进制编码表示,实现了数据的高效压缩。。