目录
一.分页查询
1.老版本的分页查询 (通过工具类BaseDao来实现)
2.利用Mybatis实现分页效果
2.1最低级版本(利用limit实现)
首先在xml定义分页需要的方法
然后在bookbiz实现方法
其次在bookbizImpl继承此方法,并且重写
最后在demo里面测试方法,并且遍历出来数据
2.2通过PageHelper插件来进行数据遍历
在Pom.xml导入插件
在Mybatis.cfg.xml配置拦截器
导入一个工具类用于完成分页实现
在bookmapper.xml中实现分页方法
在bookbiz定义接口
实现接口的方法,并且重写
最后测试方法,打印内容
二.特殊字符处理
1.mybatis中为什么要进行特殊字符处理
2.两种特殊字符处理方式的应用
2.1通过 -进行特殊字符处理
定义一个方法用于查询价格之间的区间查询
定义一个dto的方法用于特殊字符处理方式的应用
实现方法的接口,和在接口实现类重写方法
打印并且测试方法
2.2同过> <;实现特殊字符的实现
在前者的基础上注释
后面三部操作都是一样的,所以小编就直接将运行结果弄出来了
一.分页查询
关于这个,也是老生常谈的一个话题了!为什么要分页很简单,为了缓解服务器一次性查询出大量数据所带来的压力。以及更好的将数据展示出来,提高服务器的资源利用率!
1.老版本的分页查询 (通过工具类BaseDao来实现)
必须要调用executeQuery(String sql, Class<T> clz, PageBean pageBean)这个方法才能够实现分页效果,在其中
String countSQL = getCountSQL(sql);//符合条件的总记录数
String pageSQL = getPageSQL(sql, pageBean);// 符合条件的某一页数据
最后在返回指定的查询结果
2.利用Mybatis实现分页效果
2.1最低级版本(利用limit实现)
首先在xml定义分页需要的方法
select id="selectBylikesBname" resultType="com.lz.model.Book" parameterType="java.util.Map">
select
<include refid="Base_Column_List"/>
from t_mvc_book
where bname like #{bname} limit #(start),#(size)
</select>在其中 id就是方法名, paremeterType是用来存储 start,siza
然后在bookbiz实现方法
List<Book> selectBylikesBname(Map map);其次在bookbizImpl继承此方法,并且重写
@Override
public List<Book> selectBylikesBname(Map map) {
return bookMapper.selectBylikesBname(map);
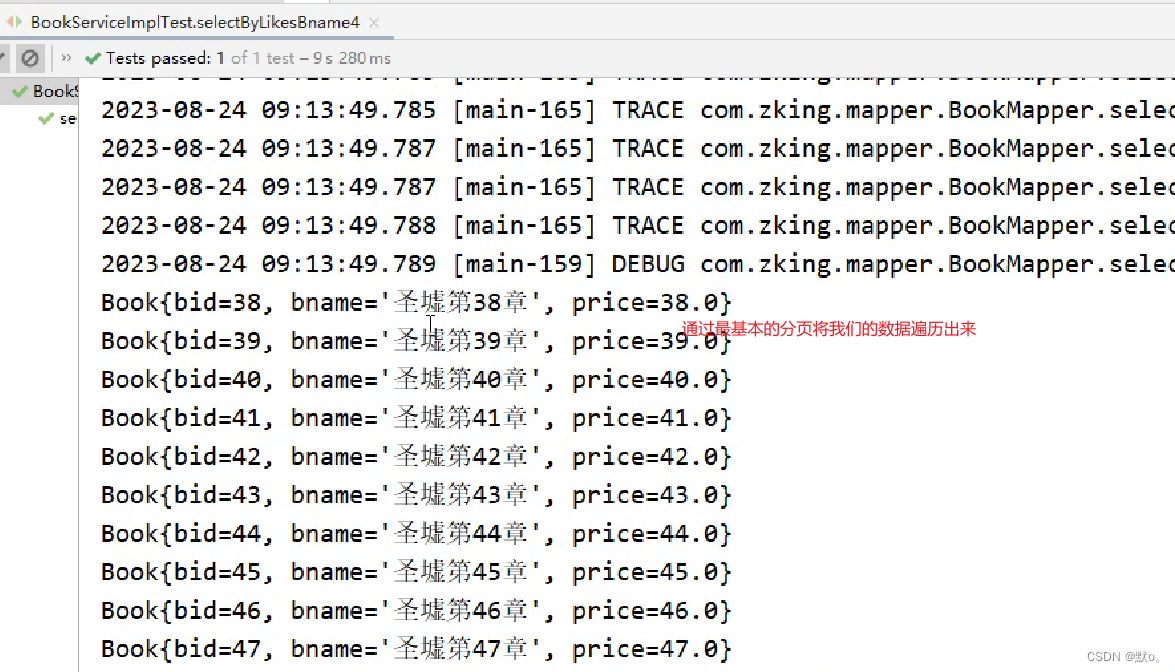
}最后在demo里面测试方法,并且遍历出来数据
@Test
public void selectByBname() {
Map map=new HashMap();
map.put("bname","%圣墟%");
map.put("start",10);
map.put("size",10);
this.bookBiz.selectBylikesBname(map).forEach(System.out::println);
} 
2.2通过PageHelper插件来进行数据遍历
在Pom.xml导入插件
<dependency> <groupId>com.github.pagehelper</groupId> <artifactId>pagehelper</artifactId> <version>5.1.2</version> </dependency>在Mybatis.cfg.xml配置拦截器
<plugins>
<!-- 配置分页插件PageHelper, 4.0.0以后的版本支持自动识别使用的数据库 -->
<plugin interceptor="com.github.pagehelper.PageInterceptor">
</plugin>
</plugins>
导入一个工具类用于完成分页实现
package com.lz.utils;
import javax.servlet.http.HttpServletRequest;
import java.io.Serializable;
import java.util.Map;
public class PageBean implements Serializable {
private static final long serialVersionUID = 2422581023658455731L;
//页码
private int page=1;
//每页显示记录数
private int rows=10;
//总记录数
private int total=0;
//是否分页
private boolean isPagination=true;
//上一次的请求路径
private String url;
//获取所有的请求参数
private Map<String,String[]> map;
public PageBean() {
super();
}
//设置请求参数
public void setRequest(HttpServletRequest req) {
String page=req.getParameter("page");
String rows=req.getParameter("rows");
String pagination=req.getParameter("pagination");
this.setPage(page);
this.setRows(rows);
this.setPagination(pagination);
this.url=req.getContextPath()+req.getServletPath();
this.map=req.getParameterMap();
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public Map<String, String[]> getMap() {
return map;
}
public void setMap(Map<String, String[]> map) {
this.map = map;
}
public int getPage() {
return page;
}
public void setPage(int page) {
this.page = page;
}
public void setPage(String page) {
if(null!=page&&!"".equals(page.trim()))
this.page = Integer.parseInt(page);
}
public int getRows() {
return rows;
}
public void setRows(int rows) {
this.rows = rows;
}
public void setRows(String rows) {
if(null!=rows&&!"".equals(rows.trim()))
this.rows = Integer.parseInt(rows);
}
public int getTotal() {
return total;
}
public void setTotal(int total) {
this.total = total;
}
public void setTotal(String total) {
this.total = Integer.parseInt(total);
}
public boolean isPagination() {
return isPagination;
}
public void setPagination(boolean isPagination) {
this.isPagination = isPagination;
}
public void setPagination(String isPagination) {
if(null!=isPagination&&!"".equals(isPagination.trim()))
this.isPagination = Boolean.parseBoolean(isPagination);
}
/**
* 获取分页起始标记位置
* @return
*/
public int getStartIndex() {
//(当前页码-1)*显示记录数
return (this.getPage()-1)*this.rows;
}
/**
* 末页
* @return
*/
public int getMaxPage() {
int totalpage=this.total/this.rows;
if(this.total%this.rows!=0)
totalpage++;
return totalpage;
}
/**
* 下一页
* @return
*/
public int getNextPage() {
int nextPage=this.page+1;
if(this.page>=this.getMaxPage())
nextPage=this.getMaxPage();
return nextPage;
}
/**
* 上一页
* @return
*/
public int getPreivousPage() {
int previousPage=this.page-1;
if(previousPage<1)
previousPage=1;
return previousPage;
}
@Override
public String toString() {
return "PageBean [page=" + page + ", rows=" + rows + ", total=" + total + ", isPagination=" + isPagination
+ "]";
}
}
在bookmapper.xml中实现分页方法
<select id="like4" resultType="com.lz.model.Book" parameterType="java.lang.String">
select
<include refid="Base_Column_List" />
from t_mvc_book
where bname like concat ('%', #{bname},'%')
</select>在bookbiz定义接口
List<Book>like4(String bname, PageBean pageBean);实现接口的方法,并且重写
@Override
public List<Book> like4(String bname,PageBean pageBean) {
if(pageBean != null && pageBean.isPagination()){
PageHelper.startPage(pageBean.getPage(),pageBean.getRows());
}
List<Book> list = bookMapper.like4(bname);
if(pageBean != null && pageBean.isPagination()){
PageInfo pageInfo = new PageInfo(list);
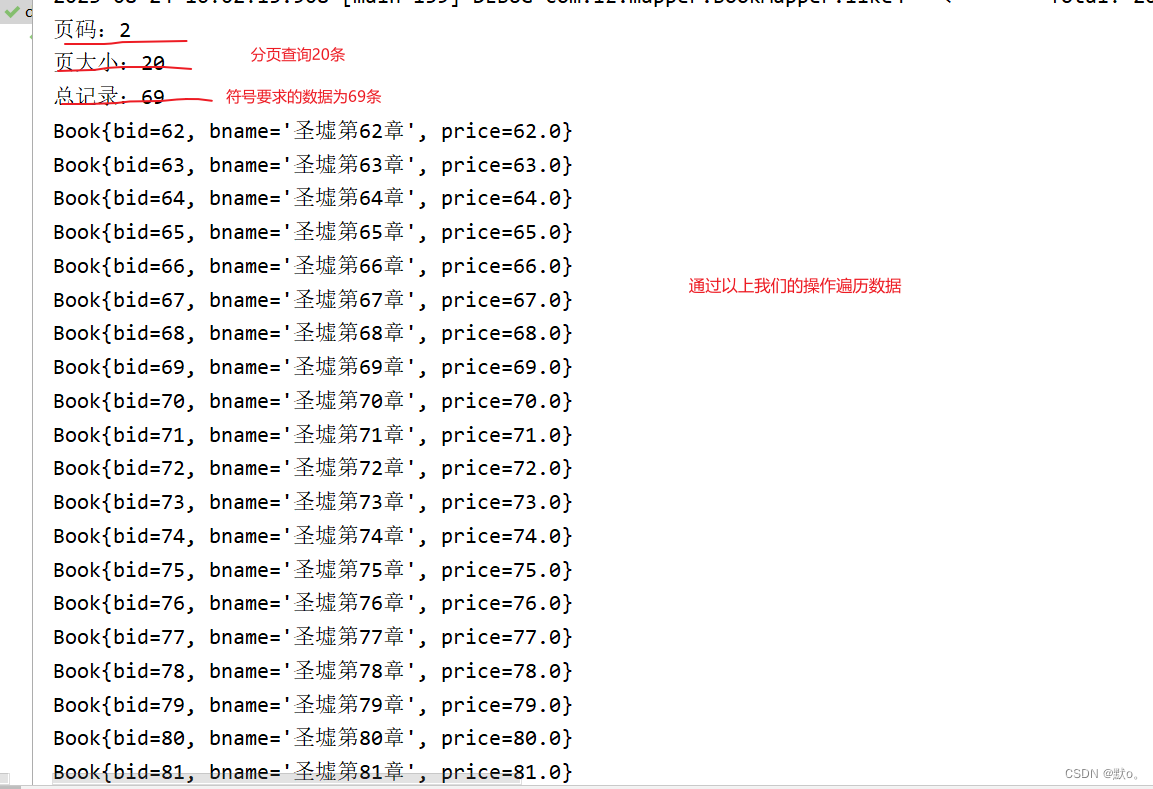
System.out.println("页码:"+pageInfo.getPageNum());
System.out.println("页大小:"+pageInfo.getPageSize());
System.out.println("总记录:"+pageInfo.getTotal());
pageBean.setTotal((int)pageInfo.getTotal());
}
return list ;
}最后测试方法,打印内容
@Test
public void testlike4() {
PageBean pageBean=new PageBean();
pageBean.setPage(2);
pageBean.setRows(20);
this.bookBiz.like4("圣墟",pageBean).forEach(System.out::println);
}
二.特殊字符处理
任何一些技术的出现都是为了解决一个问题而出现的而 MyBatis 中进行特殊字符处理的主要目的是:确保 SQL 查询的安全性和正确性
1.mybatis中为什么要进行特殊字符处理
-
防止 SQL 注入:SQL 注入是一种常见的安全漏洞,攻击者可以通过在输入中插入恶意的 SQL 代码来执行未经授权的操作。使用特殊字符处理可以帮助防止这种攻击。例如,对于查询语句中的参数,MyBatis 会自动转义特殊字符,以确保它们被当作数据而不是 SQL 代码。
-
处理特殊字符:有时候,SQL 查询需要处理包含特殊字符的数据。例如,当查询包含引号或其他特殊字符时,需要对其进行适当的转义,以避免语法错误。通过特殊字符处理,MyBatis 可以正确处理这些情况,并生成正确的 SQL 查询语句。
-
保护数据库的完整性:特殊字符处理还可以保护数据库的完整性。在某些情况下,用户输入的数据可能包含特殊字符,如果没有进行处理,可能导致 SQL 查询语句出错或破坏数据库数据。通过特殊字符处理,可以确保输入的数据正确地传递给数据库,从而保护数据库的完整性。
因此,对于安全性和数据完整性的考虑,进行特殊字符处理是非常重要的。MyBatis 提供了多种方式来处理特殊字符,包括转义字符、预编译语句参数化以及内置函数或插件等。使用这些方法可以有效地确保 SQL 查询的正确性和安全性。
2.两种特殊字符处理方式的应用
在实现之前要科普几个知识点
poji entity model :专门用来原来描述数据库的实体
vo :view object 视图 对象 :专门 用了展示 java.utils.Map
dto :接受参数的
2.1通过 <![CDATA[ ]]>-进行特殊字符处理
定义一个方法用于查询价格之间的区间查询
<select id="queryMaxMin" resultType="com.lz.model.Book" parameterType="com.lz.dto.BookDto">
select
<include refid="Base_Column_List" />
from t_mvc_book
where <![CDATA[
price <#{max} and price >#{min`}
]]>
</select>定义一个dto的方法用于特殊字符处理方式的应用
package com.lz.dto;
import com.lz.model.Book;
/**
* @author lz
* @create 2023-08-24 16:14
*/
public class BookDto extends Book {
private float min;
private float max;
public float getMin() {
return min;
}
public void setMin(float min) {
this.min = min;
}
public float getMax() {
return max;
}
public void setMax(float max) {
this.max = max;
}
@Override
public String toString() {
return "BookDto{" +
"min=" + min +
", max=" + max +
'}';
}
}
实现方法的接口,和在接口实现类重写方法
List<Book>queryMaxMin(BookDto bookDto); @Override
public List<Book> queryMaxMin(BookDto bookDto) {
return bookMapper.queryMaxMin(bookDto);
}
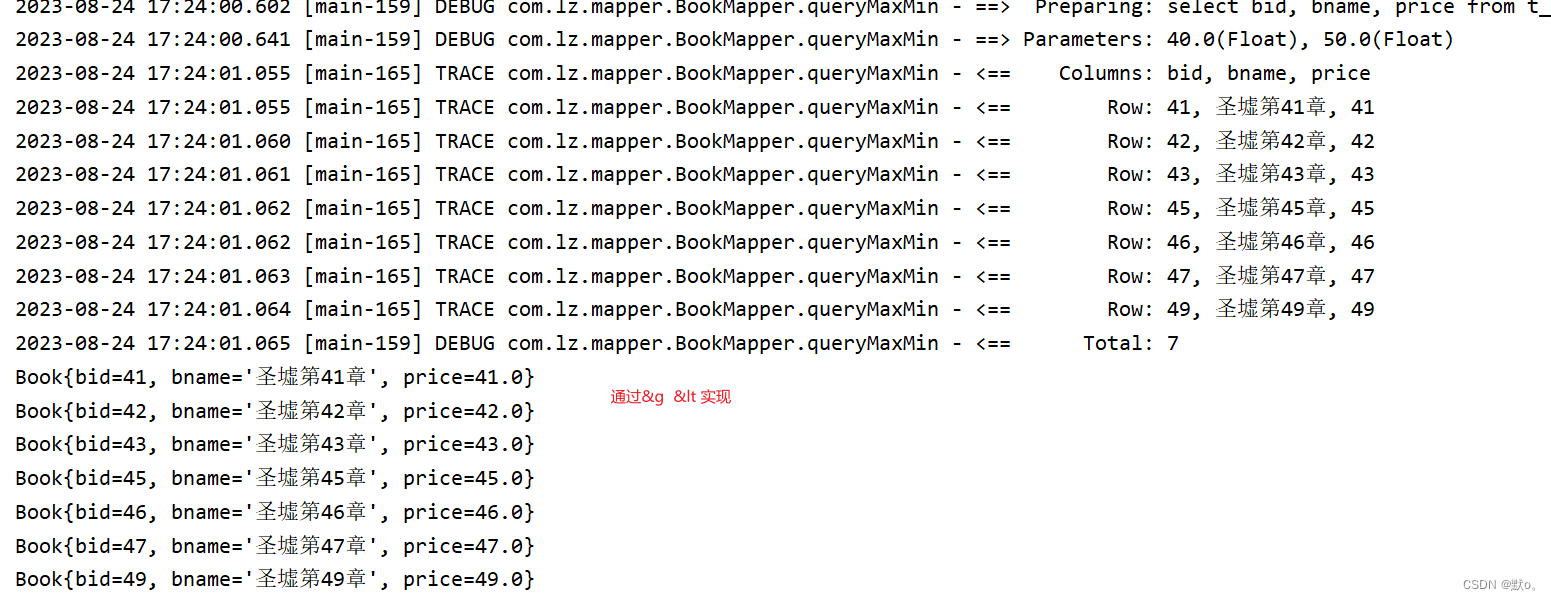
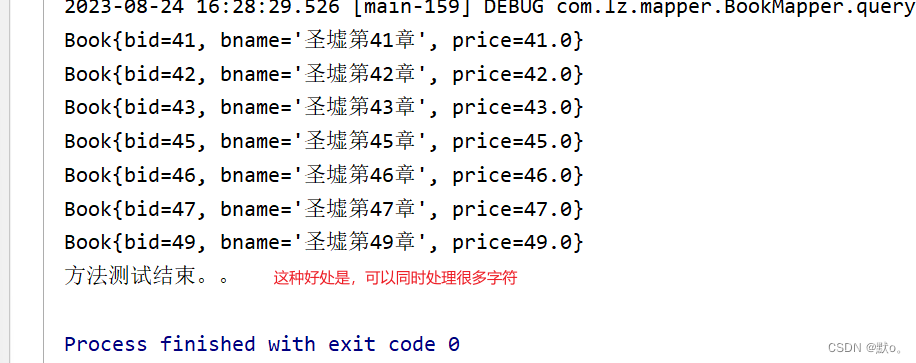
打印并且测试方法
@Test
public void queryMaxMin() {
BookDto bookDto=new BookDto();
bookDto.setMax(50);
bookDto.setMin(40);
this.bookBiz.queryMaxMin(bookDto).forEach(System.out::println);
}
2.2同过> <;实现特殊字符的实现
在前者的基础上注释
select id="queryMaxMin" resultType="com.lz.model.Book" parameterType="com.lz.dto.BookDto">
select
<include refid="Base_Column_List" />
from t_mvc_book
WHERE price > #{min} and price < #{max}
<!-- where <![CDATA[
price <#{max} and price >#{min}
]]>-->
</select>后面三部操作都是一样的,所以小编就直接将运行结果弄出来了