文章目录
- 表的操作
- 表的创建
- 修改表属性(轻易不要改)
- 数据类型
- 分类
- 类型测试
- 表的增删查改
- 增加
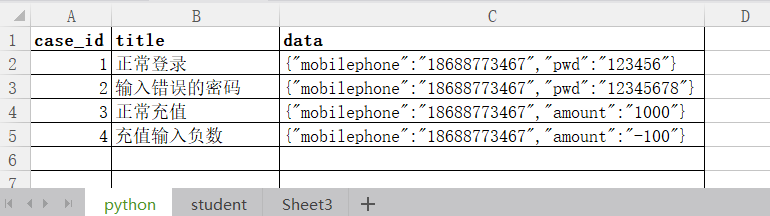
- 插入insert
- 插入否则更新
- 替换
- Retrieve(检索)查找
- select
- where条件语句的添加
- 姓孙的和孙某
- where语句无法使用别名的问题?
- 语文成绩>80并且不姓孙的同学
- (孙某)同学或者 (要求总成绩大于200并且语文成绩小于数学并且英语大于80)
- NULL不参与运算
- 按同学的QQ号进行排序,不要依赖于order by子句的默认。
- 筛选曹同学或者孙同学的数学传成绩并且降序排列
- 拿到总成绩前三名 limit的使用,所有操作都做完才进行limit进行限制
- 分页limit s,n
- Update
- Delete
- delete from
- 截断表,清空表的第二种做法
- delete 清空 vs truncate清空区别
- 插入查询结果
- 聚合函数
- group by
表的操作
表的创建
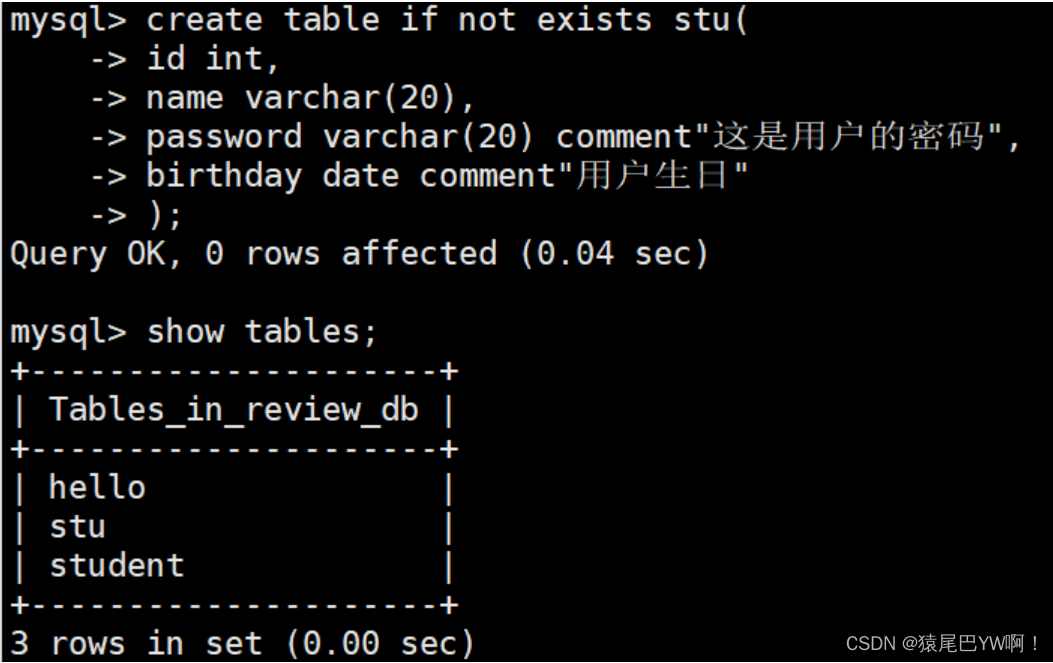
默认编码格式在my.cnf中配置。
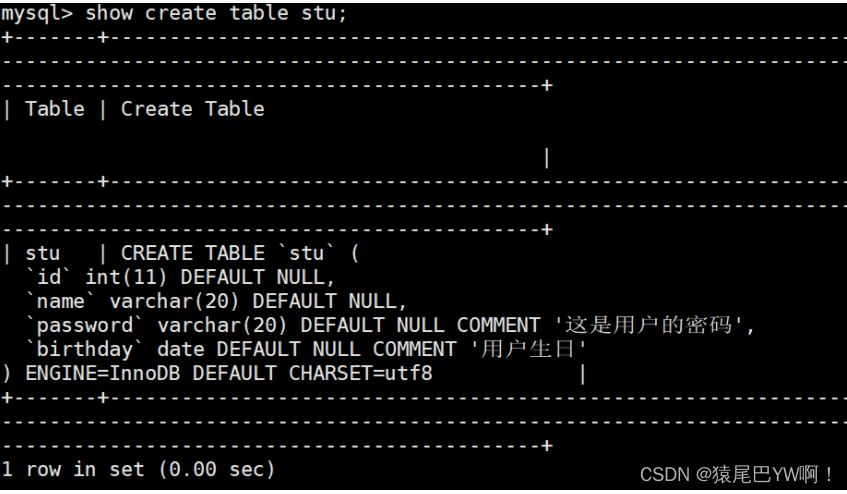
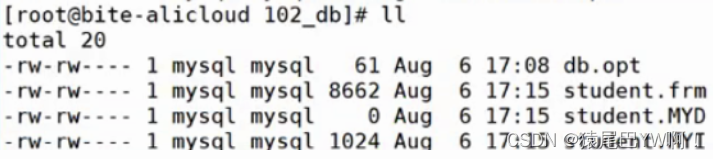
InnoDB默认是创建两个文件,而存储引擎是MyISAM时默认是三份文件。

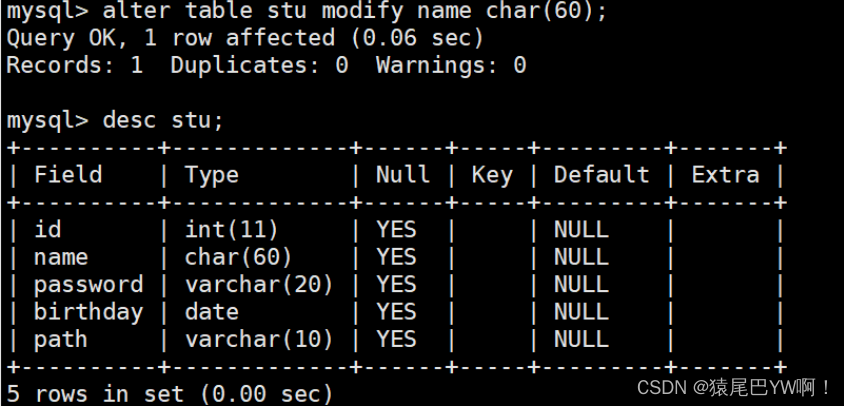
修改表属性(轻易不要改)
影响上层数据读取顺序。
- modify
- add
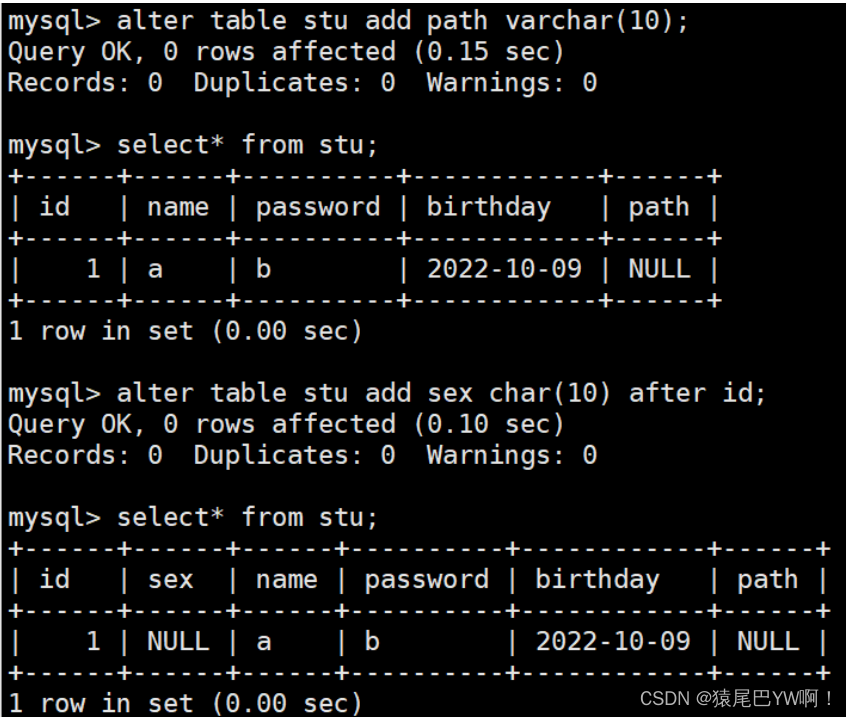
-
drop
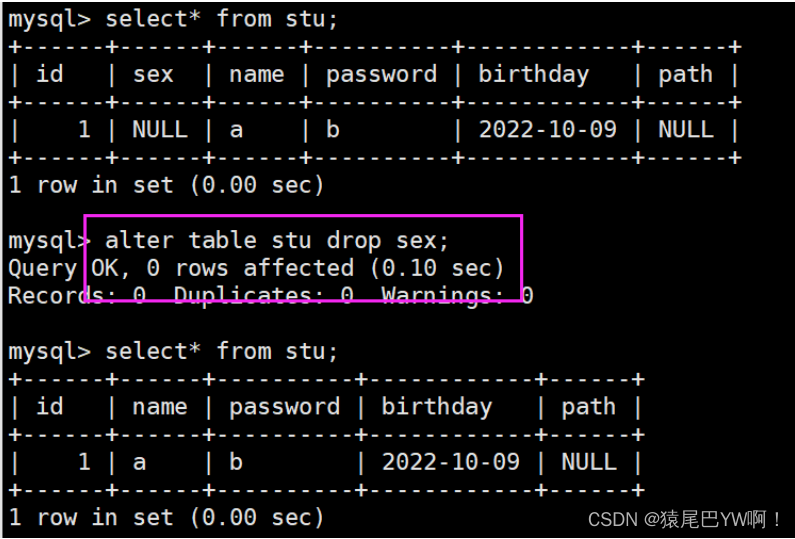
-
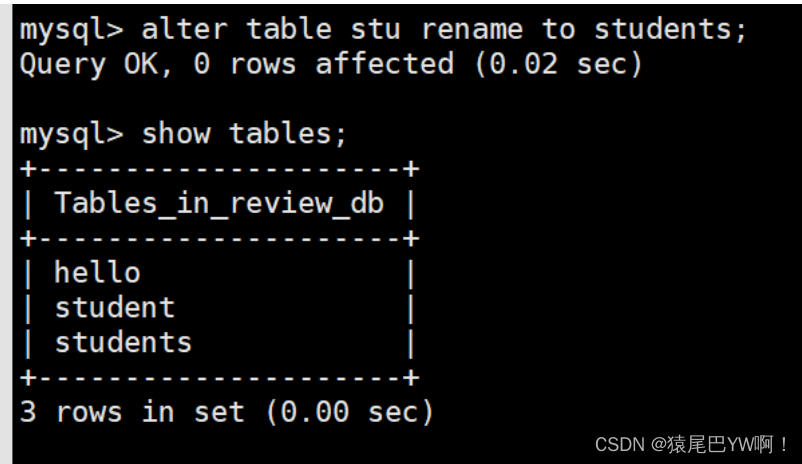
rename修改表名
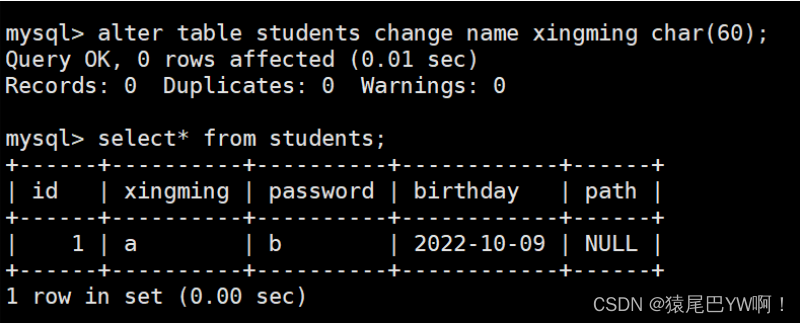
- change改列名,名字不离类型
数据类型
- 为什么要有数据类型的区分?
决定开辟空间的大小,类型也是一种约束。
分类
类型测试
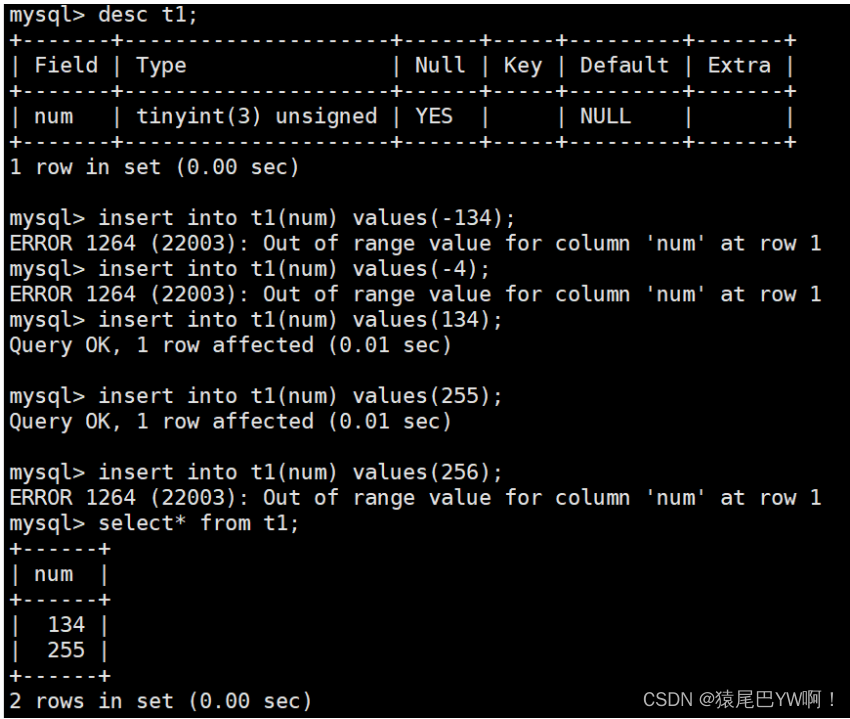
插入时如果数据越界(插入不符合对应数据类型范围的数据),SQL直接中止。在C、C++中char c =1234;会发生截断不会报错,这就是类型直接约束了SQL的执行。所以数据类型本质就是一种约束,约束越严格,数据越规整。

表的增删查改
CURT:create,Retrieve(读取),Update,Delete
增加
插入insert
单行全列插入,可以省略列名。如果是局部性插入必须得写,否则并不知道你要局部插入给谁。


也可以连续插入很多指定列:

插入否则更新
如果代码插入出现主键冲突,冲突了不要报错,而是做出对应主键的内容更新,提示是2行被更影响(冲突并且修改了)。如果没有出现过就新增(1行被影响)。如果是0行被影响,就是告诉冲突了,我也给你改成你写的了,就别一直重复操作了。(网站个人信息内容更新,就只需要一条语句了)


替换
repalce,出现冲突了就给你替换了,原来的整行删除,然后id自增长(主键建表的饿的时候设置的自增属性,如果没有,添加语句的时候要加上)。

Retrieve(检索)查找
select
不影响原始数据
-
指定列查询,按照你的语句中属性的顺序给你表格。

-
可计算的表达式结果添加到最后。

-
对查询结果进行操作,不影响原值。

- 总分:重命名。只会对筛选结果进行处理。as可以省略,就是起别名而已。


- 筛选不出现重复的成绩,保证整行都一样才能够都删了,如果加上id不同就不能删。

- 分数排序:筛选完毕的数据是默认是升序asc(ascending order),降序是desc(descending order)。

where条件语句的添加
按照条件筛选。MySQL等于是=一个就行。

- 字符串相等

- NULL本身是不能用=比较的,必须用<=> IS NULL,<>是不等于NULL IS NOT NULL。
空串是有值的代表的是0,NULL是没有值的,二者是有区别的。

-
引号里面不写,默认是空,但是不是NULL(没有值)

-
<> 就是!=

-
between and ,是一个闭区间

-
IN()

姓孙的和孙某
LIKE();select name from where name like "孙_";

where语句无法使用别名的问题?

-
按照条件筛选数据
-
按照要求计算数据
where语句是在之前就要执行的,用条件查询筛选你要计算的数据,这时你还没起别名呢,所以找不到,并且是不能在where筛选条件的时候用as起别名的。
order by是你要排序的数据已经计算完成了,此时你的数据已经根据条件将数据全部筛选完了,你就可以起别名了,而排序的本质是计算(数值计算+逻辑计算)。
所以,MySQL各个子句的执行顺序要注意。
语文成绩>80并且不姓孙的同学
select name ,chinese from exam_result where chinese>80 and name not like"孙%";

(孙某)同学或者 (要求总成绩大于200并且语文成绩小于数学并且英语大于80)
select name ,chinese,math,english from exam_result where (name like "孙%") or (chinese+english+math >200 and chinese<math and english>80);
NULL不参与运算
考0分和缺考并不是一回事,= + -

按同学的QQ号进行排序,不要依赖于order by子句的默认。
字符串排序
select name ,qq from students order by qq desc;

NULL虽然是不参与运算,也得放个地方,就放在最前面了,视为最小值。一直缺考的总成绩肯定按照降序之后排后面。
-
order by 是先拍左边,在左边成立的情况下再排右边。因为是对整列排序,所以不能只对其中一个属性排序。
-
where和orderby的结合版

筛选曹同学或者孙同学的数学传成绩并且降序排列
select name,math from exam_result where name like "孙%" or name like "曹%" order by math desc;
拿到总成绩前三名 limit的使用,所有操作都做完才进行limit进行限制
select name,english+math +chinese total from exam_result order by total desc limit 3;
limit要永远放在最后。

分页limit s,n
第s个由n个数据行组成的数据块实现分页操作。

- offset n:从0开始进行以n位偏移量的显示

Update
不用where语句进行控制,就会将整个列表都进行更新。
将孙悟空的数学成绩改为80
update exam_result set math =80 where name ="孙悟空";
更改两个用,连接。
update exam_result set math =60,chinese=70 where name="曹孟德";
将总成绩倒数三名的同学数学加上30分(set)
update exam_result set math =math +30 where order by math+english+chinese asc limit 3;
将所有同学的语文成绩更新为原来的两倍
update exam_result set chinese =chinese * 2 where 1=1;
所有的update基本都得加上where 。最好加上。
Delete
删除孙悟空的考试成绩
delete from exam_result where name ="孙悟空";
删除整张表里面的数据不是删表(drop)
delete from
delete from for_delete(要删除的表的名字);
存在aotu_increment自增的数字仍然存在,自增到下一个要添加的地方的下标。
注意:删完之后仍然是5这个IP值开始添加。
截断表,清空表的第二种做法
truncate table for_delete;
注意:把auto_increment 也给删了,下次插入就从1开始了。
delete 清空 vs truncate清空区别
日志:MySQL日志要承担功能要求
bin log (几乎所有的SQL操作,mysqld服务器都会给你记录下来,可以用来进行多主机同步增量备份,另一台主机把操作重新跑一遍)历史命令都放在binlog中。备份的是这些操作,而不是将数据进行备份。
redo log (MySQL数据持久化和crash-safe功能),我们所有的操作都是在内存中进行的,然后刷新到磁盘。避免mysql崩溃而内存中数据还没刷新到磁盘中,丢了能找。
undo log(在事务中承担回滚的日志,数据操作恢复功能)
delete会更新日志,truncate是不会更新日志的,操作就不会记录下来了。
插入查询结果
删掉表中重复数据,保留一条数据。
将数据筛选出来插入到另一个一样表结构的表中。


重命名rename to 就行了,不要删除掉原来的表。

聚合函数
更强调的是一列。
统计函数count();
select count(*) 人数 from students;
select count (qq)from students;
select count(distinct math )from students;去重效果加上

统计数学成绩总分
select sum(math)from students ;
聚合的是筛选出来的结果。
数学平均成绩:
AVG
select avg(math)from exam_result;
MAX
select max(english)from exam_result;
group by
可以对指定的列进行分组查询。将数据库scott进行导入到mysql中,也是一种数据恢复手段
source ./scott_data.sql;
- 如何显示每个部门的平均工资和最高工资(库是提供好的)
需要先对员工根据部门进行分组group by之后再进行聚合求值,注意先后顺序。先group by,然后再对每一组计算。

-
显示每个部门的各种岗位的平均工资和最低工资。
select deptno,job,avg(sal) 平均工资,min(sal) 最低工资 from emp group by deptno,job;

-
显示平均工资低于2000的部门和他的平均工资
where语句的执行会高于group by,所以不能用where挑选groupby之后的表中数据。
对分组进行筛选要用having ,就是优先级 低于groupby然后作用和where一样。

where和having的区别
二者的执行次序不同。where是先与groupby过滤表中数据的,having是在groupby之后过滤分组数据的。所以他俩是不冲突的.