局部变量为什么是线程安全的
Hi,我是阿昌,今天学习记录的是关于局部变量为什么是线程安全的。
一遍一遍重复再重复地讲到,多个线程同时访问共享变量的时候,会导致并发问题。
那在 Java 语言里,是不是所有变量都是共享变量呢?
工作中发现不少会给方法里面的局部变量设置同步,显然这些并没有把共享变量搞清楚。那 Java 方法里面的局部变量是否存在并发问题呢?
下面就先结合一个例子剖析下这个问题。比如,下面代码里的 fibonacci() 这个方法,会根据传入的参数 n ,返回 1 到 n 的斐波那契数列,斐波那契数列类似这样: 1、1、2、3、5、8、13、21、34……第 1 项和第 2 项是 1,从第 3 项开始,每一项都等于前两项之和。
在这个方法里面,有个局部变量:
数组 r 用来保存数列的结果,每次计算完一项,都会更新数组 r 对应位置中的值。
思考这样一个问题,当多个线程调用 fibonacci() 这个方法的时候,数组 r 是否存在数据竞争(Data Race)呢?
// 返回斐波那契数列
int[] fibonacci(int n) {
// 创建结果数组
int[] r = new int[n];
// 初始化第一、第二个数
r[0] = r[1] = 1; // ①
// 计算2..n
for(int i = 2; i < n; i++) {
r[i] = r[i-2] + r[i-1];
}
return r;
}
可以在大脑里模拟一下多个线程调用 fibonacci() 方法的情景,假设多个线程执行到 ① 处,多个线程都要对数组 r 的第 1 项和第 2 项赋值,这里看上去感觉是存在数据竞争的,不过感觉再次欺骗了你。
其实很多人也是知道局部变量不存在数据竞争的,但是至于原因嘛,就说不清楚了。
那它背后的原因到底是怎样的呢?要弄清楚这个,需要一点编译原理的知识。
在 CPU 层面,是没有方法概念的,CPU 的眼里,只有一条条的指令。
编译程序,负责把高级语言里的方法转换成一条条的指令。
所以可以站在编译器实现者的角度来思考“怎么完成方法到指令的转换”。
二、方法是如何被执行的
高级语言里的普通语句,例如上面的r[i] = r[i-2] + r[i-1];
翻译成 CPU 的指令相对简单,可方法的调用就比较复杂了。
例如下面这三行代码:第 1 行,声明一个 int 变量 a;第 2 行,调用方法 fibonacci(a);第 3 行,将 b 赋值给 c。
int a = 7;
int[] b = fibonacci(a);
int[] c = b;
当调用 fibonacci(a) 的时候,CPU 要先找到方法 fibonacci() 的地址,然后跳转到这个地址去执行代码,最后 CPU 执行完方法 fibonacci() 之后,要能够返回。
首先找到调用方法的下一条语句的地址:
也就是int[] c=b;的地址,再跳转到这个地址去执行。
参考下面这个图。

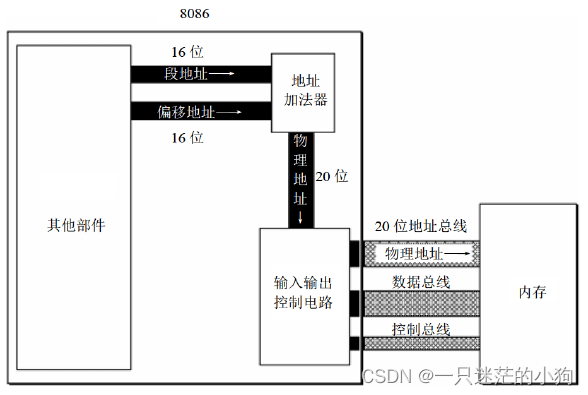
到这里,方法调用的过程想必你已经清楚了,但是还有一个很重要的问题,“CPU 去哪里找到调用方法的参数和返回地址?
”如果你熟悉 CPU 的工作原理,应该会立刻想到:通过 CPU 的堆栈寄存器。
CPU 支持一种栈结构,栈一定很熟悉了,就像手枪的弹夹,先入后出。
因为这个栈是和方法调用相关的,因此经常被称为调用栈。
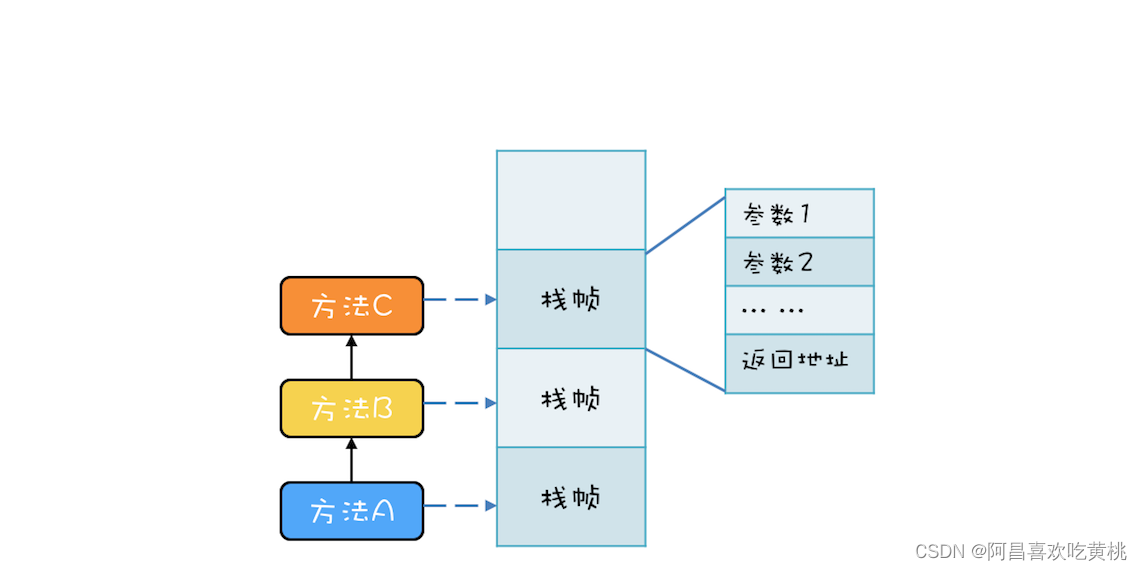
例如,有三个方法 A、B、C,他们的调用关系是 A->B->C(A 调用 B,B 调用 C),在运行时,会构建出下面这样的调用栈。
每个方法在调用栈里都有自己的独立空间,称为栈帧,每个栈帧里都有对应方法需要的参数和返回地址。
当调用方法时,会创建新的栈帧,并压入调用栈;
当方法返回时,对应的栈帧就会被自动弹出。也就是说,栈帧和方法是同生共死的。
利用栈结构来支持方法调用这个方案非常普遍,以至于 CPU 里内置了栈寄存器。
虽然各家编程语言定义的方法千奇百怪,但是方法的内部执行原理却是出奇的一致:都是靠栈结构解决的。
Java 语言虽然是靠虚拟机解释执行的,但是方法的调用也是利用栈结构解决的。
三、局部变量存哪里?
已经知道了方法间的调用在 CPU 眼里是怎么执行的,但还有一个关键问题:
方法内的局部变量存哪里?局部变量的作用域是方法内部,也就是说当方法执行完,局部变量就没用了,局部变量应该和方法同生共死。
此时应该会想到调用栈的栈帧,调用栈的栈帧就是和方法同生共死的,所以局部变量放到调用栈里那儿是相当的合理。
事实上,的确是这样的,局部变量就是放到了调用栈里。
于是调用栈的结构就变成了下图这样。
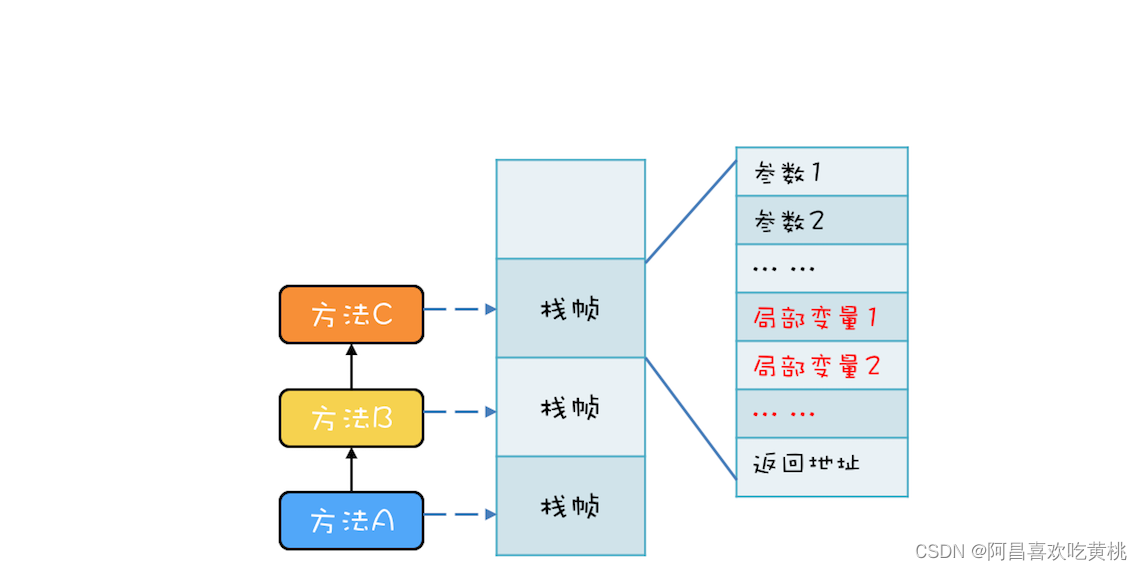
这个结论相信很多人都知道,因为学 Java 语言的时候,基本所有的教材都会告诉你 new 出来的对象是在堆里,局部变量是在栈里,只不过很多人并不清楚堆和栈的区别,以及为什么要区分堆和栈。
局部变量是和方法同生共死的,一个变量如果想跨越方法的边界,就必须创建在堆里。
四、调用栈与线程
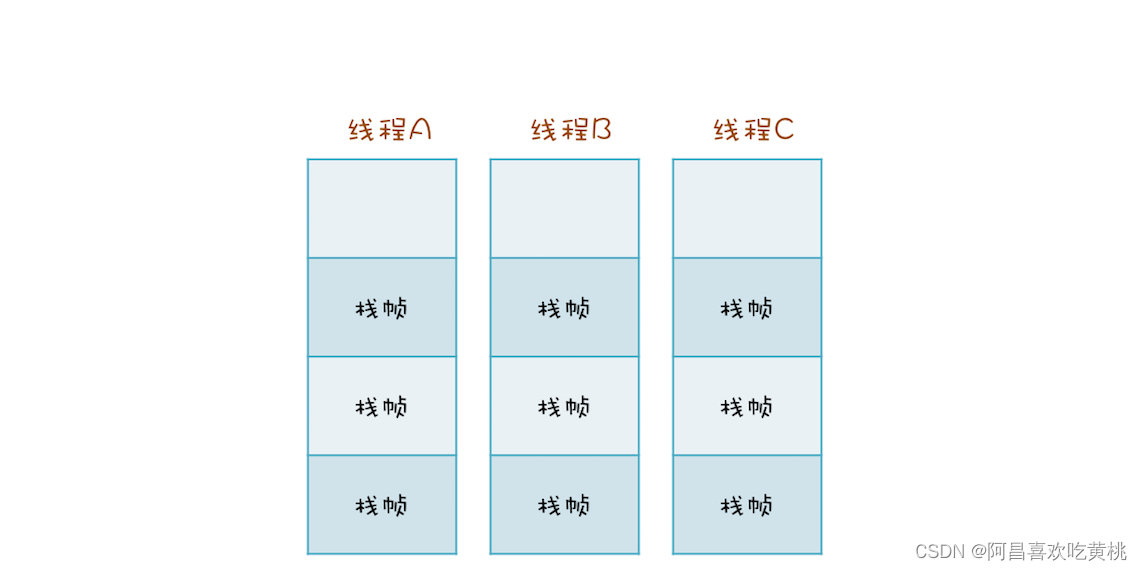
两个线程可以同时用不同的参数调用相同的方法,那调用栈和线程之间是什么关系呢?答案是:每个线程都有自己独立的调用栈。
因为如果不是这样,那两个线程就互相干扰了。
如下面这幅图所示,线程 A、B、C 每个线程都有自己独立的调用栈。
现在,让回过头来再看篇首的问题:
Java 方法里面的局部变量是否存在并发问题?一点问题都没有。
因为每个线程都有自己的调用栈,局部变量保存在线程各自的调用栈里面,不会共享,所以自然也就没有并发问题。再次重申一遍:没有共享,就没有伤害。
五、线程封闭
方法里的局部变量,因为不会和其他线程共享,所以没有并发问题,思路很好,已经成为解决并发问题的一个重要技术,同时还有个响当当的名字叫做线程封闭,比较官方的解释是:仅在单线程内访问数据。
由于不存在共享,所以即便不同步也不会有并发问题,性能杠杠的。
采用线程封闭技术的案例非常多,例如从数据库连接池里获取的连接 Connection,在 JDBC 规范里并没有要求这个 Connection 必须是线程安全的。
数据库连接池通过线程封闭技术,保证一个 Connection 一旦被一个线程获取之后,在这个线程关闭 Connection 之前的这段时间里,不会再分配给其他线程,从而保证了 Connection 不会有并发问题。
六、总结
调用栈是一个通用的计算机概念,所有的编程语言都会涉及到,Java 调用栈相关的知识,并没有花费很大的力气去深究,但是靠着那点 C 语言的知识,稍微思考一下,基本上也就推断出来了。
递归调用太深,可能导致栈溢出。
原因是什么?有哪些解决方案呢?
栈溢出原因:
因为每调用一个方法就会在栈上创建一个栈帧,方法调用结束后就会弹出该栈帧,而栈的大小不是无限的,所以递归调用次数过多的话就会导致栈溢出。
而递归调用的特点是每递归一次,就要创建一个新的栈帧,而且还要保留之前的环境(栈帧),直到遇到结束条件。
所以递归调用一定要明确好结束条件,不要出现死循环,而且要避免栈太深。
解决方法:
- 简单粗暴,
不要使用递归,使用循环替代。缺点:代码逻辑不够清晰; 限制递归次数;- 使用
尾递归,尾递归是指在方法返回时只调用自己本身,且不能包含表达式。编译器或解释器会把尾递归做优化,使递归方法不论调用多少次,都只占用一个栈帧,所以不会出现栈溢出。然鹅,Java没有尾递归优化。




![[附源码]Python计算机毕业设计SSM基于java旅游信息分享网站(程序+LW)](https://img-blog.csdnimg.cn/bcf5916bca2a44e68b7008f457011cdb.png)