文章目录
- 1. redis单线程为啥会这么快
- 2. redis数据类型和底层存储结构
- 2.1 string类型
- 2.1.1 SDS
- 2.2 hash类型
- 2.3 list类型
- 2.4 set类型(集合)
- 2.5 zset类型(有序集合)
- 2.6 ziplist压缩列表
- 2.7 listpack
- 2.8 quicklist-快速列表
- 2.9 skiplist 跳表
- 3. redis高可用方案(集群策略)
- 4. redis淘汰key算法
- 5. redis过期key删除策略
- 6. redis分布式锁
- 7. redis数据持久化
- 8. redis如何配置key的过期时间,实现原理
- 9. redis主从复制原理
- 10. redis高并发问题
- 11. 热点数据缓存重建问题
1. redis单线程为啥会这么快
- 基于内存操作,一条命令几十纳秒
- 单线程,减少线程切换
- 使用io多路复用技术
- 使用高效的数据存储结构,链表和数组
2. redis数据类型和底层存储结构
参考: Redis的五种数据结构的底层实现原理
type数据类型,对应的是value五种数据类型。
字符串:REDIS_STRING;
哈希:REDIS_HASH;
列表:REDIS_LIST;
集合:REDIS_SET;
有序集合:REDIS_ZSET
encoding类型如下图

String类型的编码方式,即encoding有三种:int、embstr、raw。
value的值是整数,encoding为int,没有对应底层数据结构;
value长度小于32,encoding为embstr,长度大于,32编码为raw,embstr和raw都使用SDS数据结构存储。
2.1 string类型
By default, a single Redis string can be a maximum of 512 MB.
2.1.1 SDS
参考: Redis 源码解读——sds

sds优势
- 提升性能,sds直接使用len字段获取长度,时间复杂度是o(1), c语言中获取字符串长度是遍历,直到遇到‘\0’,时间复杂度是o(n)
- 保证二进制安全,sds遇到‘\0’不会结束,c语言字符串遇到‘\0’结束
- 减少内存再分配次数, sds修改字符串不一定会重新分配内存,采用的是空间与分配和惰性空间释放策略来避免内存再分配,len小于1M,会分配2len(str)的空间,修改时,空间够则不进行分配,不够则再分配2len(总str), 修改后字符串长度大于1M,则再分配1m的未使用空间, 当c语言修改字符串,会进行内存再分配策略
参考: redis字符串实现,空间与分配,sds和c区别 - 兼容c函数, 用于字符串比较,strcmp(sds_str->buf, buf),buf属性为一个字符数组,,最后一个保存空字符’\0’,空字符不算进len中
- 杜绝缓冲区溢出

参考:理解Redis设计与实现(一):简单动态字符串(SDS)
2.2 hash类型
listpack 和hash表
2.3 list类型

quicklist
2.4 set类型(集合)
intset和哈希表
参考: Redis之intset(整数集合)
2.5 zset类型(有序集合)
listpack和skiplist
2.6 ziplist压缩列表
是经过特殊编码的可以存储字符串或整数的双向链表
参考 : Redis Ziplist(压缩列表)
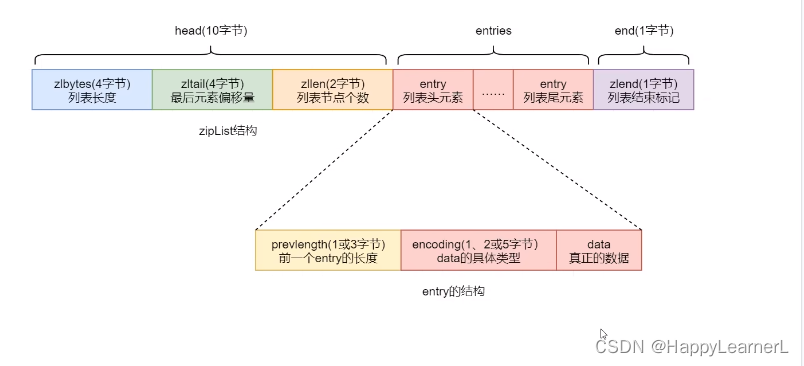
- zlbytes:记录整个ziplist的大小。
- zltail:ziplist开始指针与最后一个entry之间的偏移量,通过该偏移量可以获得最后一个entry。
- zllen:entry数量。
- entry:存储具体数据的节点。
- zlend:ziplist结尾标识。
ziplist会导致级联更新,降低性能
2.7 listpack
与ziplist类似
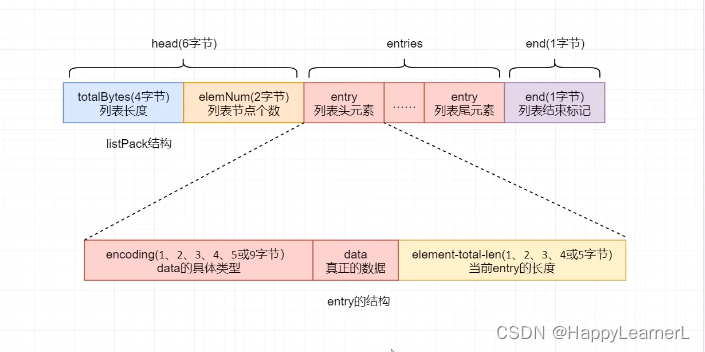
2.8 quicklist-快速列表
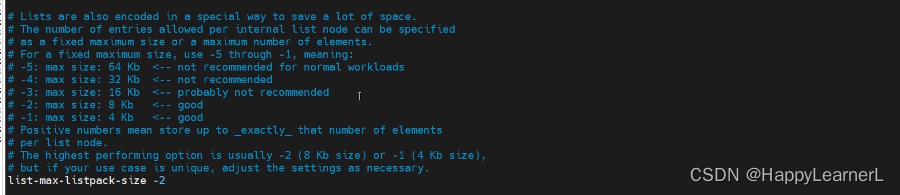
- -2 表示zlbytes 最大8k

typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count; /* total count of all entries in all listpacks */
unsigned long len; /* number of quicklistNodes */
signed int fill : QL_FILL_BITS; /* fill factor for individual nodes */
unsigned int compress : QL_COMP_BITS; /* depth of end nodes not to compress;0=off */
unsigned int bookmark_count: QL_BM_BITS;
quicklistBookmark bookmarks[];
} quicklist;
- 检索(遍历 zlen 的和 与index比较)
- 插入数据, 先检索,再插入,插入数据时需要判断插入数据的大小
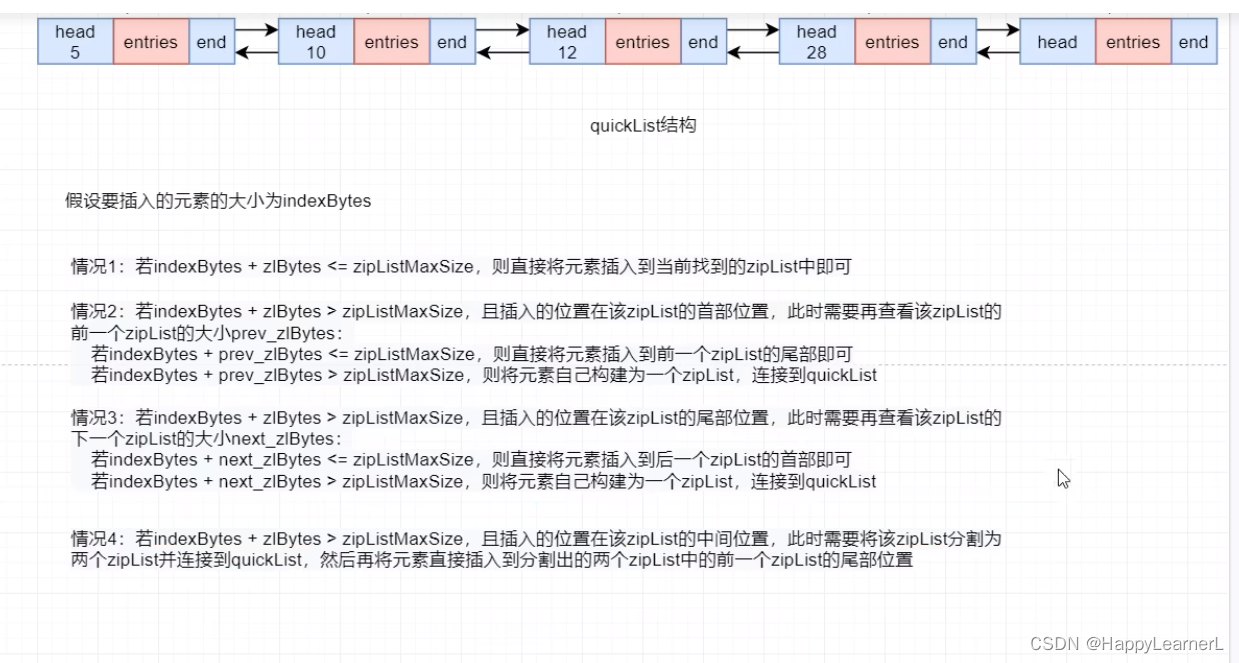
- 删除元素
如果删除后ziplist 没有元素,则需要吧该ziplist也从链表中移除
2.9 skiplist 跳表
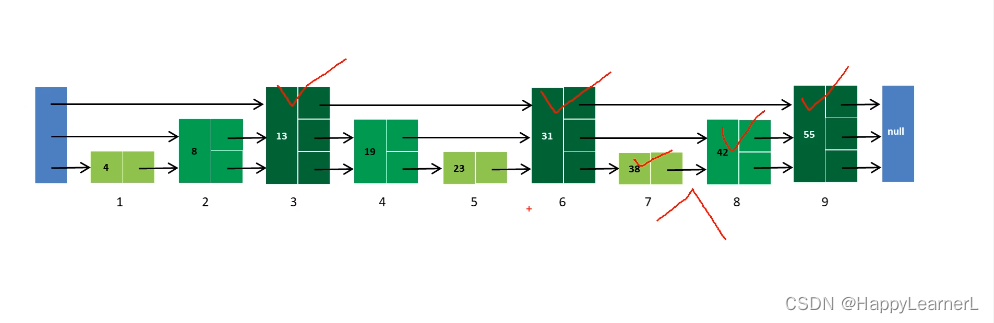
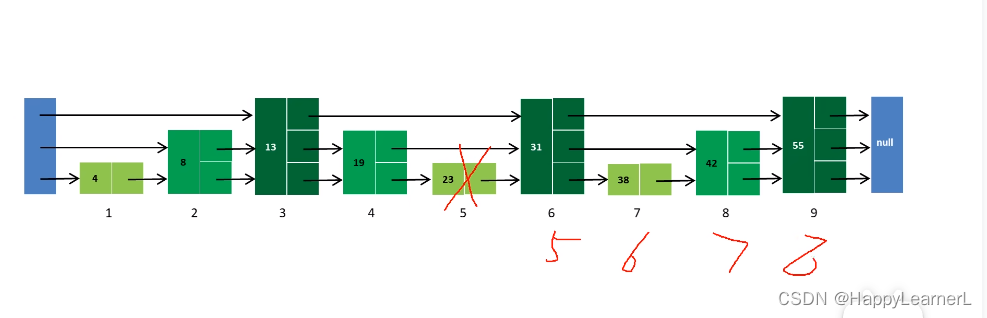
优点:查询快
缺点:节点增或删除之后需要更新层级结构,采用随机化的层级结构解决此问题
参考:Redis源码解析:数据结构详解-skiplist
3. redis高可用方案(集群策略)
- 主从集群-1主多从
- 主从+哨兵
- 多主多从模式
参考:4 种 Redis 集群方案介绍 + 优缺点对比
4. redis淘汰key算法
LRU(least recently used) 和LFU(least frequently used)
5. redis过期key删除策略
惰性过期-只有访问到了才回去检查是否过期,过期则删掉
定期过期- 隔一定时间扫描一定数量的key,删除过期的
6. redis分布式锁
- 一文搞定Redis分布式锁的实现和原理
- Redis实现分布式锁的7种方案,及正确使用姿势!
- Redis实现分布式锁
7. redis数据持久化
rdb和aof
- Redis 数据持久化
- redis7.0.5数据持久化(RDB和AOF)
- 深度好文:Redis持久化
- redis的两种持久化方式
8. redis如何配置key的过期时间,实现原理
expire
setex
惰性过期-只有访问到了才回去检查是否过期,过期则删掉
定期过期- 隔一定时间扫描一定数量的key,删除过期的, 平衡执行频率和执行时长,会遍历每个database(默认16个), 检查当前数据库中执行的key(默认20个), 随机抽查key, 过期就删除
9. redis主从复制原理
- Redis主从复制
- Redis 主从复制1
10. redis高并发问题
redis高并发问题以及解决方案
11. 热点数据缓存重建问题
双重检测锁
分布式锁(针对不同的key设置不同的锁)





![[Java]图论进阶--最小生成树算法](https://img-blog.csdnimg.cn/eafbaf0027424319ac519b13f98f3639.png)