RDD
引出问题
Spark是如何将多台机器上的数据通过一个类型来关联实现的?
答:通过RDD类型来实现关联
一、RDD简介
RDD(Resilient Distributed Dataset):弹性分布式数据集
RDD的本质: 一个抽象的逻辑上的数据集合的概念,类似于Python中的list,但RDD是分布式的
- Python中的list:数据只存在于list构建的节点
- Spark中的RDD:数据是分布式存储在多台节点上的
RDD的功能:实现分布式的数据存储,是一个对应多个物理分区的数据集合,每个分区的数据可以存储在不同的节点上
- RDD本质上是一个逻辑的概念,代表多台机器上的多个分区的数据
- RDD就类似于HDFS中的文件,RDD的分区就类似于HDFS中的Block块
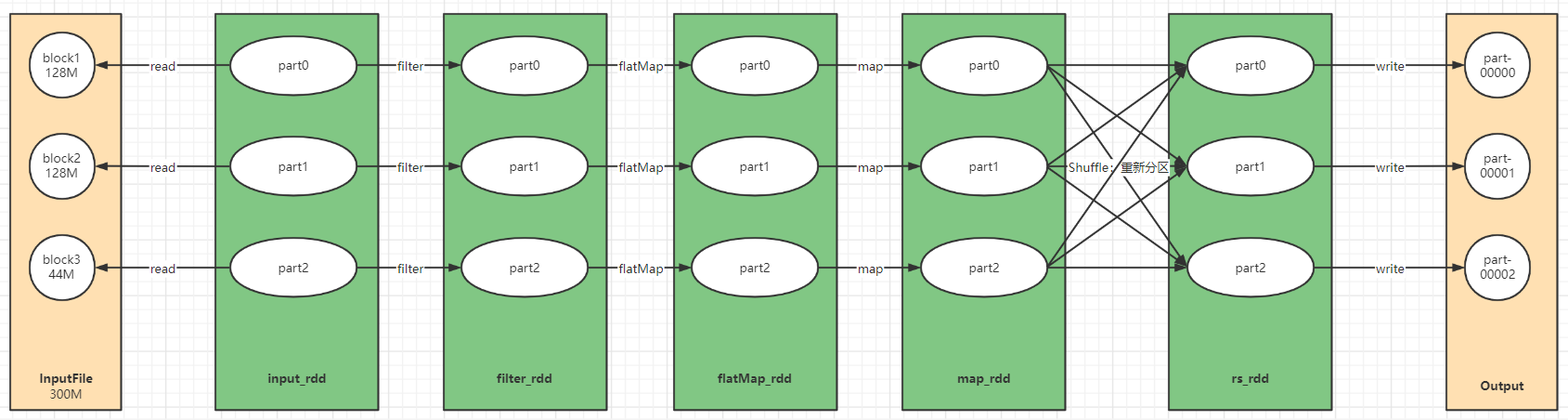
代码演示
# step1:读取数据
input_rdd = sc.textFile("hdfs://node1:8020/spark/wordcount/input")
# step2:转换数据
rs_rdd = input_rdd \
.filter(lambda line : len(line.strip()) > 0) \
.flatMap(lambda line : re.split("\\s+",line.strip()))\
.map(lambda word : (word,1)) \
.reduceByKey(lambda tmp,item : tmp+item)
filter_rdd = input_rdd.filter
flatMap_rdd = filter_rdd.flatMap
# step3:输出结果
rs_rdd.saveAsTextFile("hdfs://node1:8020/spark/wordcount/output")
filter_rdd.foreach(lambda x: print(x))
二、RDD的五大特性
特性一:每个RDD都由一系列的分区构成
举例说明:
将[1,2,3,4,5,6,7,8,9]构建成RDD类型,得到RDD1:RDD[int]
- part0:1 2 3:node1
- part1:4 5 6:node2
- part2:7 8 9 : node3
特性二:RDD的计算操作本质上是对RDD每个分区的并行计算
RDD2 = RDD1.map(lambda x: x*2)
逻辑代码中可以通过调用算子对RDD进行转换操作
物理上真正执行的时候,会对这个RDD每个分区进行并行处理
举例说明:
RDD1 = sc.textFile(文件)
- part0:1 2 3:node1
- part1:4 5 6:node2
- part2:7 8 9:node3
RDD2 = RDD1.map(lambda x: x*2)
- part0:1 2 3:node1 -> task0 -> part0:2 4 6
- part1:4 5 6:node2 -> task1 -> part1:8 10 12
- part2:7 8 9:node3 -> task2 -> part2:14 16 18
特性三:每个RDD都会保存与其他RDD之间的依赖关系(血缘关系)
RDD数据的计算是在内存中进行,如果因为事故导致内存溢出,Spark需要通过血缘关系保证RDD数据不丢失
血缘关系:Spark记录所有数据每一步的来源,当任何一个步骤中数据丢失的时候,都可以根据来源重新构建
举例说明:
# 读取数据放入内存中
RDD1 = sc.textFile(文件)
- part0:1 2 3:node1
- part1:4 5 6:node2
- part2:7 8 9:node3
# 对内存中RDD1的数据进行转换
RDD2 = RDD1.map(lambda x: x*2)
- part0:1 2 3:node1 -> task0 -> part0:2 4 6
- part1:4 5 6:node2 -> task1 -> part1:8 10 12
- part2:7 8 9:node3 -> task2 -> part2:14 16 18
RDD2.foreach(lambda x: print(x)) # 打印过程中,某个分区的数据丢失
RDD2.saveAsTextFile(path)
# 此时RDD2记录了是如何通过RDD1得到的,RDD1记录了自己的数据是如何得到的
# 如果打印过程中,某个分区的数据丢失
# RDD2可以通过RDD1调用map算子得到的,DD1可以通过SparkContext读取文件得到的
特性四(可选):对于KV类型的RDD,在经过Shuffle时,可以自定义分区规则
Shuffle过程中:根据Key进行分区
Spark中提供了两种默认的分区器:HashPartitioner、RangePartitioner
- HashPartitioner:最常用的,大多数分布式计算引擎默认的分区器都是Hash
- 优点:相同的Key一定会进入同一个分区,用于实现分组
- 缺点:数据分配不均衡,容易导致数据倾斜 select …… from table distribute by rand()
- 算子:reduceByKey、groupByKey、repartition
- RangePartitioner:特殊,Spark专门为排序准备的一个分区器
- 只用于Spark的排序过程中,用于实现多个分区的情况下全局有序
Spark允许KV类型的RDD在经过Shuffle时,使用自己开发的分区器来干预分区规则
特性五(可选):Driver调度分配Task给Executor运行时可以计算最优分配路径和最优计算位置
思想:移动存储不如移动计算。计算过程中要避免了大量数据在网络中传输,影响性能
Driver分配Task给Executor运行,怎么分配性能最好?
答:尽量将Task分配到对应处理的数据所在的节点的Executor中运行
- PROCESS_LOCAL:Task直接运行在数据所在的Executor中
- NODE_LOCAL:Task分配在与数据同机器的其他Executor中
- RACK_LOCAL:Task分配在于数据同机架的不同机器的Executor中
- NO_PREF:不做最优配置
举例说明:
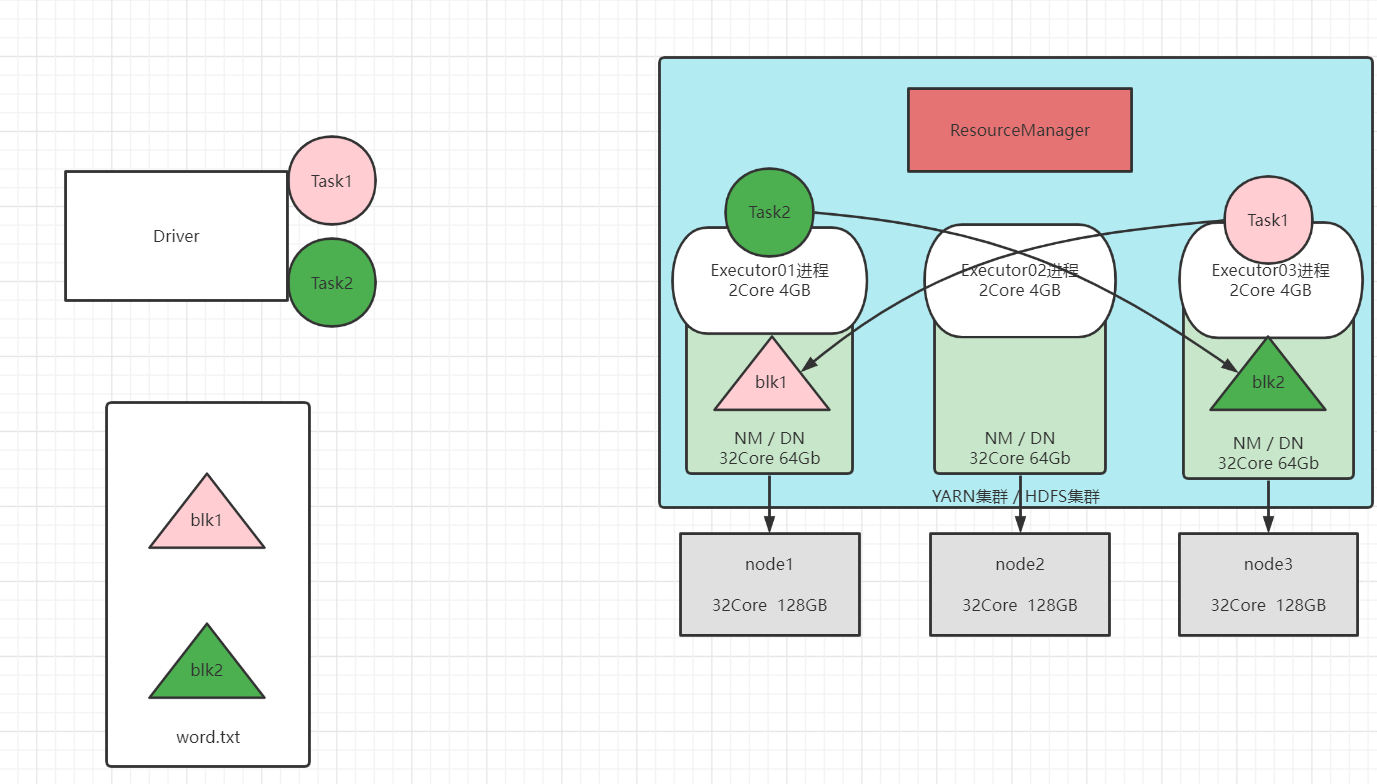
① 如果将将Task随机分配,会导致每个Task都要通过网络到别的机器上下载数据到自己机器的内存中才能计算,影响性能
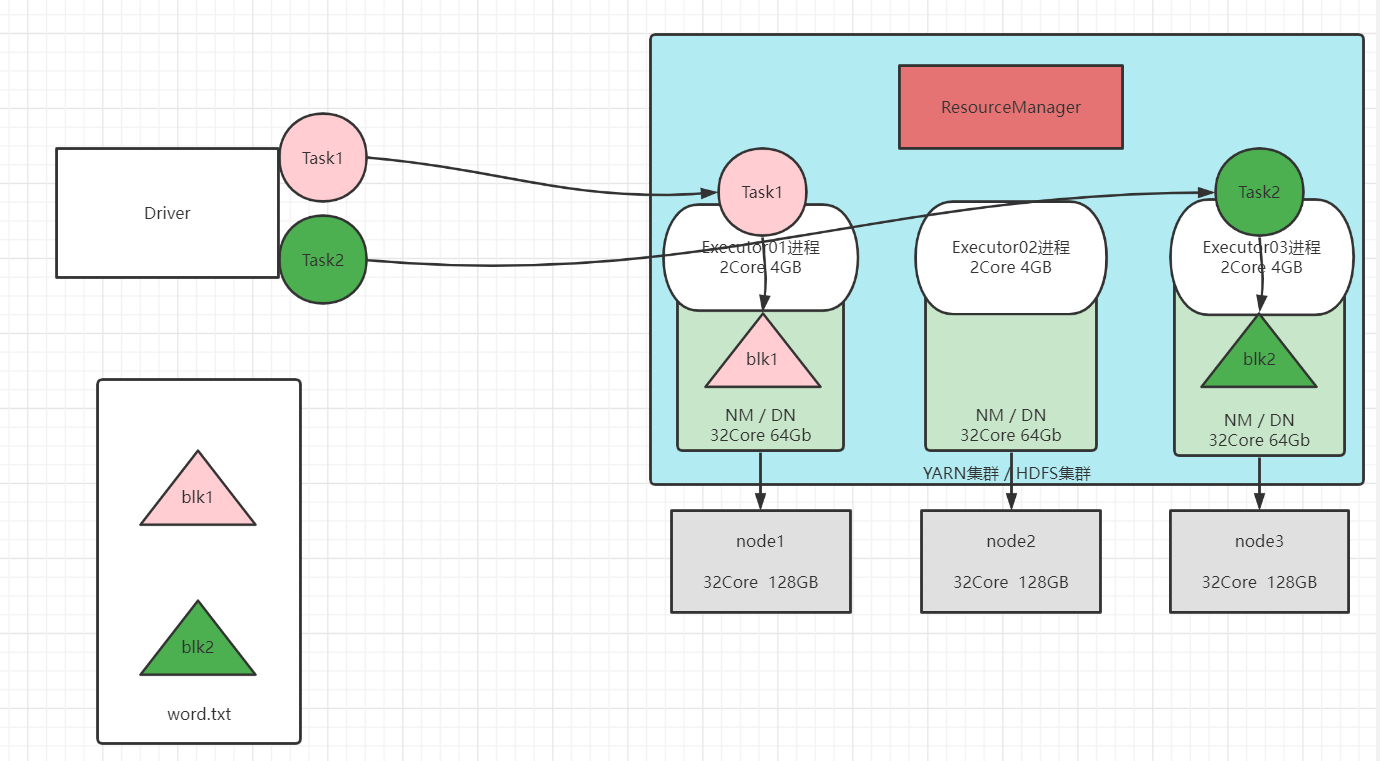
② 使用最优路径方案:Task就在数据所在的机器运行,效率是最高的
三、RDD的构建
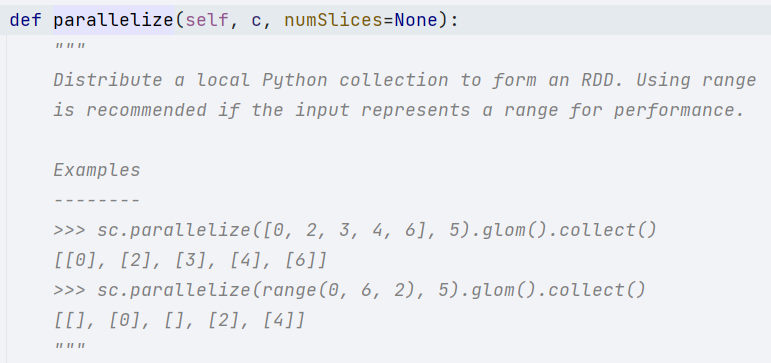
① 并行化一个已存在的集合:sc.parallelize(列表,分区个数)
② 读取外部存储系统数据源:sc.textFile(文件,最小分区个数)
四、RDD的分区规则
读取数据
① sc.parallelize(列表,分区个数)
- 无指定分区:由spark.default.parallelism参数值决定
- 指定分区:指定几个,就是几个分区
② sc.textFile(文件,最小分区个数)
- 无指定分区:spark.default.parallelism和 2 取最小值,得到最小分区数,最终也是根据文件大小来
- 指定分区:指定的是最小分区数,具体的分区数可以根据HDFS分片规则来
-
- minPartitions = 2
-
- 文件:100M => 2个分区
-
- 文件:300M => 3个分区
处理数据
默认:子RDD的分区数 = 父RDD的分区数
- 特殊:允许通过调用算子进行修改:repartition、coalesce、reduceByKey等