文章目录
- 前言
- 网络爬取数据部分
- 小知识点
- 利用正则表达式在字符串中提取到url(https以及http)
- 仅仅只保存字符串中的中文字符
- 爬取数据
- 生成词云
- jieba分词
- 生成词云
- 生成词云最终版代码
- 总结
前言
快期末了,有个数据挖掘的大作业需要用到python的相关知识(这太难为我这个以前主学C++的人了,不过没办法还是得学😂🚀🚀),下面是我在学习制作词云知识时总结的一些东西(本篇文章主要包含数据爬取以及词云制作),我对于python不是很熟悉,如果下面的一些知识点有哪里出问题或者有不同理解的,请一定一定要在评论区提出来,让我这个菜鸡学习学习~~/(ㄒoㄒ)/~~
网络爬取数据部分
这次期末的大作业主要是要分析俄乌冲突的内容,所以需要爬取相关网站的内容,以下是我爬取某华网的整个过程(我对于数据爬虫并不是特别熟悉,请大家多多包含)
在正式开始爬取之前,我们先来学习一些字符串的处理操作吧👇
小知识点
利用正则表达式在字符串中提取到url(https以及http)
为什么我要提取url呢,那是因为我提取的网站源代码,他就会包含很多子窗口的url,我把这些子窗口的url进行保存,最终目的就是为了读取子窗口的正文信息。
直接看运行效果吧👇
import re
def findUrl(string):
# findall() 查找匹配正则表达式的字符串
url = re.findall('https?://[a-zA-Z0-9\.\?/%-_]*', string)
return url
if __name__ == '__main__':
strTest = "url1=https://cn.bing.com sda" \
"url2 = https://baidu.com sd" \
"asdjaslkdjaskld http://taobao.com"
print(strTest)
listUrl = findUrl(strTest)
print(listUrl)
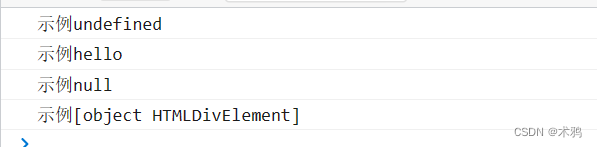
运行效果:

仅仅只保存字符串中的中文字符
核心思想:通过比对字符串中字符的unicode编码看是不是中文字符
def is_chinese(uchar):
"""判断一个unicode是否是汉字"""
if uchar >= u'\u4e00' and uchar <= u'\u9fa5':
return True
else:
return False
def format_str(content):
content.encode("UTF-8")
content_str = ''
for i in content:
if is_chinese(i):
content_str = content_str+i
return content_str
if __name__ == '__main__':
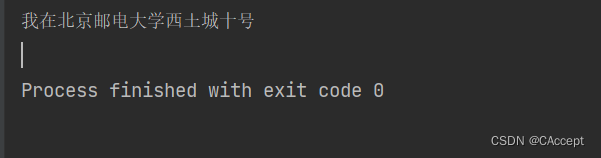
contentStr = "1231231231我在北京邮电大学西土城10十号!!!!!"
formatStr = format_str(contentStr)
print(formatStr)
运行效果:
爬取数据
通过f12我们可以发现网页的请求方式是Ajax请求
如何判断是否是Ajax请求👇
- 当我们将滚动条往下拉后,看到滚动条越来越短(
整个网页的数据增多了,观察f12的Network慢慢的它会添加一些东西),但是整体的页面没有刷新 - f12的
element存在的一些"元素"(比如我们的图片名字),而当我们去f12的source中是找不到该"元素"的
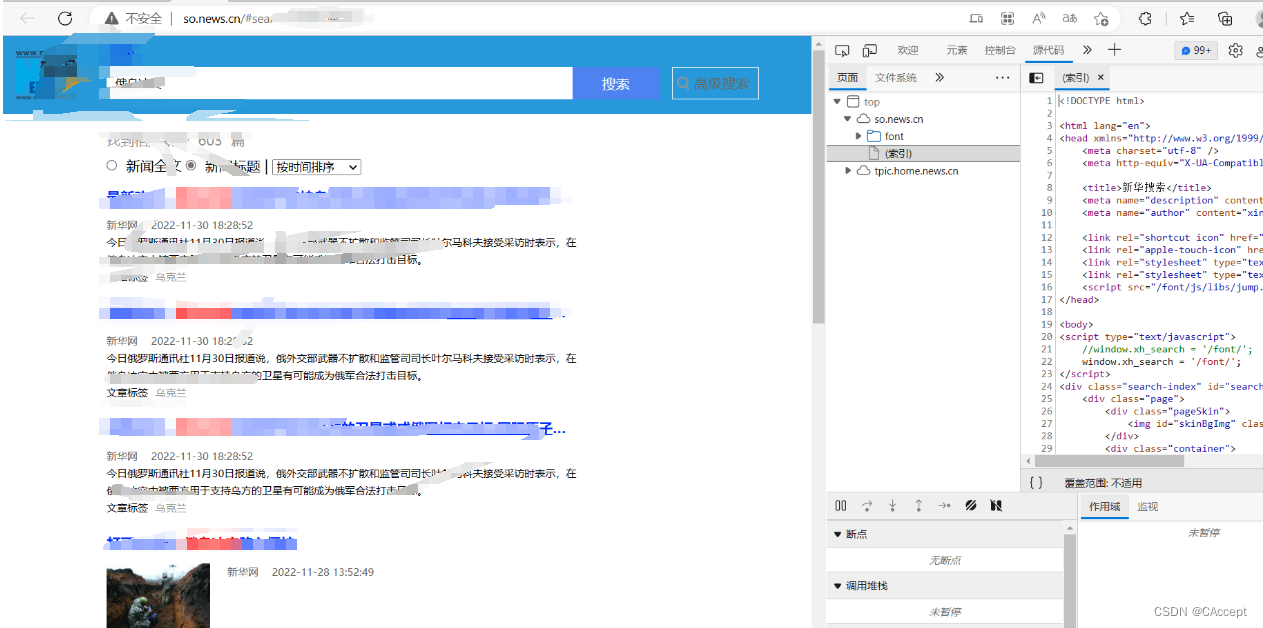
我们拿到Ajax的url,观察其规律
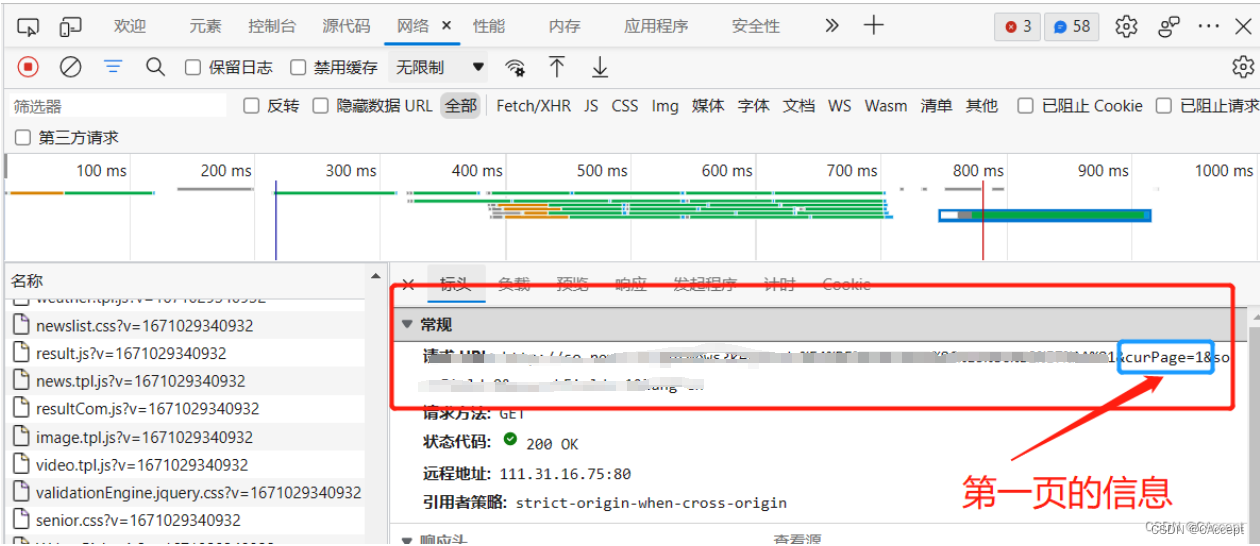
所以我这决定爬取数据的步骤是:
- 爬取10个页面的信息,将其中
子窗口(单独的新闻)的网址进行记录保存 - 对子窗口网址进行爬取,将新闻的
正文部分进行爬取(采用BeautifulSoup进行数据解析) - 将爬取到的正文部分进行处理(去除’ ',“\r”,“\n”…),然后将字符串全部保存到一个文件中
代码:
import requests
from lxml import etree
import re
from bs4 import BeautifulSoup
import jieba
from wordcloud import WordCloud
def is_chinese(uchar):
"""判断一个unicode是否是汉字"""
if uchar >= u'\u4e00' and uchar <= u'\u9fa5':
return True
else:
return False
def format_str(content):
content.encode("UTF-8")
content_str = ''
for i in content:
if is_chinese(i):
content_str = content_str+i
return content_str
def Find(string):
# findall() 查找匹配正则表达式的字符串
url = re.findall('https?://[a-zA-Z0-9\.\?/%-_]*', string)
return url
def getUrl(string):
resp2 = requests.get(string)
return Find(resp2.text)
def getData(string):
data = set()
resp = requests.get(string)
resp.encoding = "utf-8"
# 使用lxml解析器解析html
bs = BeautifulSoup(resp.text, "lxml")
# 将换行符,空格以及回车进行去除
stringTitle = bs.title.text.replace(" ","").replace("\n","").replace("\r","")
stringTitle = format_str(stringTitle)
data.add(stringTitle)
for item in bs.select("#DH-PLAYERID"):
stringTitle1 = item.text.replace(" ","").replace("\n", "").replace("\r","")
stringTitle1 = format_str(stringTitle1)
data.add(stringTitle1)
for item in bs.select("#detail"):
stringTitle2 = item.text.replace(" ","").replace("\n", "").replace("\r","")
stringTitle2 = format_str(stringTitle2)
data.add(stringTitle2)
# for item in data:
# print(item)
return data
if __name__ == '__main__':
news_data = set()
m_urlList = []
strNews = ""
# 获取新华网疫情模块的前20页疫情新闻
for i in range(20):
url = "http://so.news.cn/getNews?keyword=" \
"%E4%BF%84%E4%B9%8C%E5%86%B2%E7%AA%81&curPage="+str(i+1)+"&sortField=0&searchFields=1&lang=cn"
m_urlList = m_urlList+getUrl(url)
for url in m_urlList:
news_data=news_data|getData(url)
# 将列表中的字符串合并到一个字符串中
for item in news_data:
#print(item)
strNews = strNews+item
# 爬取到的数据进行保存
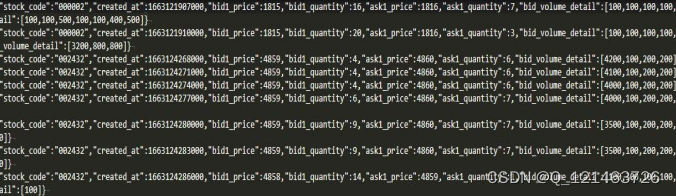
with open('新华网爬到的数据.txt', 'w', encoding='utf-8') as f:
f.write(strNews)
f.close()
运行结果:

生成词云
生成词云部分步骤分为:
- 将刚刚爬取下来的文本文件进行分词(在这使用jieba分词)
- 生成词云
jieba分词
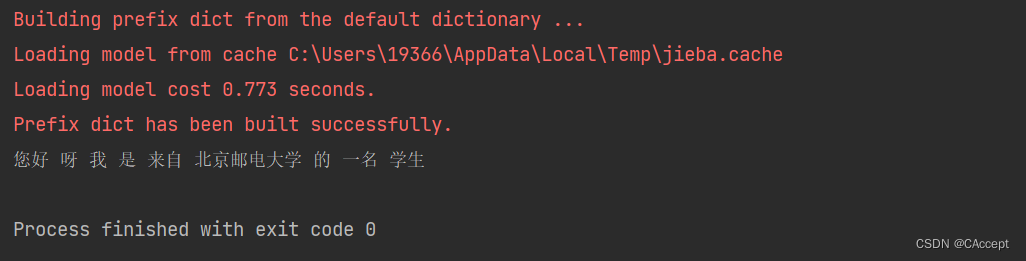
import jieba
text = "您好呀我是来自北京邮电大学的一名学生"
#print(text)
# 1.结巴中文分词,生成字符串,默认精确模式
cut_text = jieba.cut(text)
# 2.必须给个符号分隔开分词结果来形成字符串,才可以打印和分词
result = " ".join(cut_text)
print(result)
运行结果:
生成词云
生成词云的步骤:
- 读取之前网络爬虫爬取的数据文件,并将其分词生成分词结果result
- 将本地的字体文件拷贝到代码的同级目录
(需要有字体文件要不然后面生成的词云可能会是"框框") - 生成词云
1.将本地的字体文件拷贝到代码同级目录
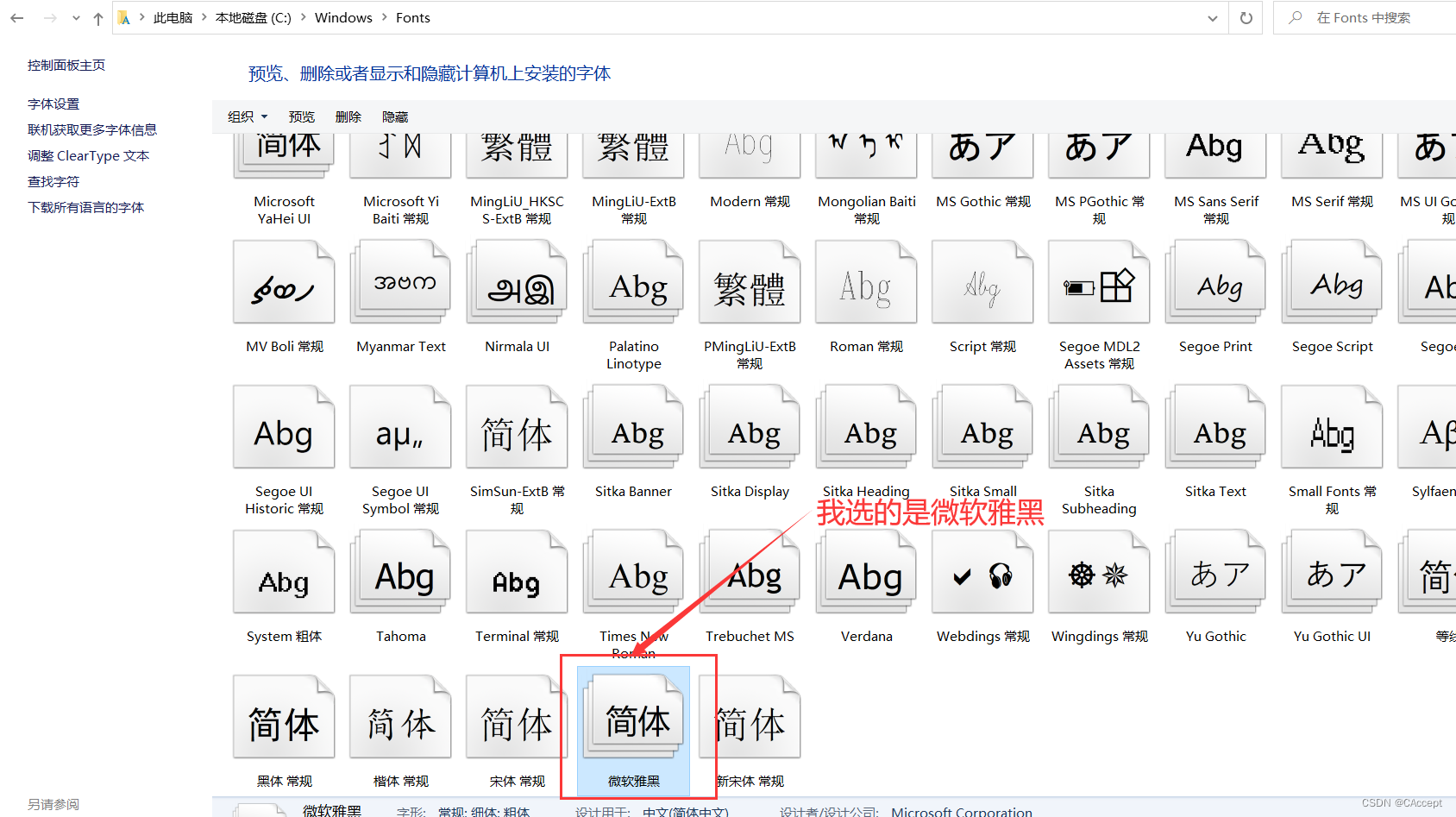
拷贝到代码同级目录下会有这三个文件,用第一个就行(看后面操作)

2.生成词云
直接看代码吧,注释都在代码里面了👇
代码
import matplotlib.pyplot as plt
import jieba
from wordcloud import WordCloud
text = "您好您好您好呀我是来自北京邮电大学的一名学生"
#print(text)
# 1.结巴中文分词,生成字符串,默认精确模式
cut_text = jieba.cut(text)
# 2.必须给个符号分隔开分词结果来形成字符串,才可以打印和分词
result = " ".join(cut_text)
print(result)
wc = WordCloud(
# 设置字体,不指定就会出现乱码
# 设置背景色
background_color='white',
# 设置背景宽
width=500,
# 设置背景高
height=350,
# 最大字体
max_font_size=50,
# 最小字体
min_font_size=10,
mode='RGBA',
font_path = "msyh.ttc" # 字体信息
#colormap='pink'
)
# 产生词云
wc.generate(result)
# 3.显示图片
# 指定所绘图名称
plt.figure("jay")
# 以图片的形式显示词云
plt.imshow(wc)
# 关闭图像坐标系
plt.axis("off")
plt.show()
运行效果:
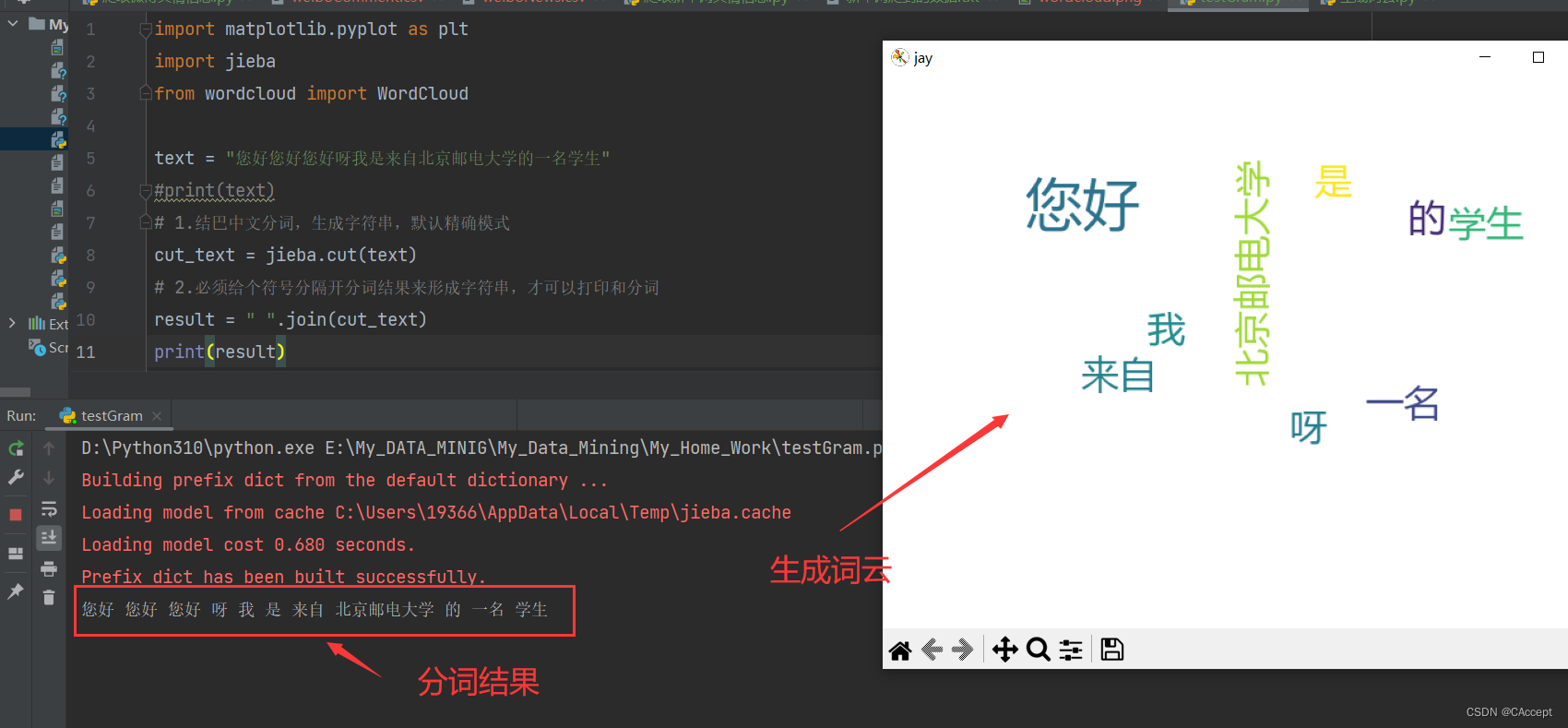
生成词云最终版代码
这里也没啥好说的,该说的知识点前面都已经说完了,下面直接看代码吧
import matplotlib.pyplot as plt
import jieba
from wordcloud import WordCloud
# 1.读入txt文本数据
f = open('新华网爬到的数据.txt','r',encoding = 'utf-8')
text = f.read()
f.close
# 2.结巴中文分词,生成字符串,默认精确模式,如果不通过分词,无法直接生成正确的中文词云
cut_text = jieba.cut(text)
# 必须给个符号分隔开分词结果来形成字符串,否则不能绘制词云
result = " ".join(cut_text)
# 3.生成词云图,这里需要注意的是WordCloud默认不支持中文,所以这里需已下载好的中文字库
# 无自定义背景图:需要指定生成词云图的像素大小,默认背景颜色为黑色,统一文字颜色:mode='RGBA'和colormap='pink'
wc = WordCloud(
# 设置字体,不指定就会出现乱码
# 设置背景色
background_color='white',
# 设置背景宽
width=500,
# 设置背景高
height=350,
# 最大字体
max_font_size=50,
# 最小字体
min_font_size=10,
mode='RGBA',
font_path = "msyh.ttc" # 我们刚刚copy来的字体文件
#colormap='pink'
)
# 产生词云
wc.generate(result)
# 4.显示图片
# 指定所绘图名称
plt.figure("jay")
# 以图片的形式显示词云
plt.imshow(wc)
# 关闭图像坐标系
plt.axis("off")
plt.show()
运行结果(我还是打码吧):

总结
谢谢大家能够看到这,真心希望对您有所帮助,我学python的时间也不长,如果同学们对于本文的一些知识点或者一些概念存在疑问或者是不同理解欢迎在评论区中提出来,让我也可以学习学习,谢谢大家🚀🚀