文章目录
- 1.映射(map)
- 2.过滤(filter)
- 3.扁平映射(flatMap)
- 4.按键分区(keyBy)
- 5. 简单聚合(sum,min,max等)
- 6.归约聚合(reduce)
- 7.自定义函数
💎💎💎💎💎
更多资源链接,欢迎访问作者gitee仓库:https://gitee.com/fanggaolei/learning-notes-warehouse/tree/master

1.映射(map)
package com.fang.chapter05;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class TransformMapTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//从元素中读取数据
//3.从元素读取数据
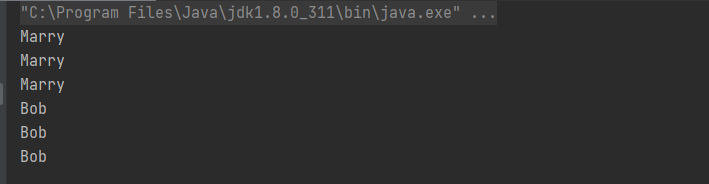
DataStreamSource<Event> stream3 = env.fromElements(
new Event("Marry", "./home", 1000L),
new Event("Bob", "./home", 1000L));
//1.使用自定义类,实现mapFunction接口
SingleOutputStreamOperator<String> map = stream3.map(new MyMapper());
//2.使用匿名了实现MapFunction接口
SingleOutputStreamOperator<String> map1 = stream3.map(new MapFunction<Event, String>() {
public String map(Event value) throws Exception{
return value.user;
}
});
//3.传入lambda表达式
SingleOutputStreamOperator<String> map2 = stream3.map(data -> data.user);
map.print();
map1.print();
map2.print();
env.execute();
}
public static class MyMapper implements MapFunction<Event,String>{
@Override
public String map(Event event) throws Exception {
return event.user;
}
}
}
2.过滤(filter)
package com.fang.chapter05;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class TransformFilterTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//从元素中读取数据
//3.从元素读取数据
DataStreamSource<Event> stream3 = env.fromElements(
new Event("Marry", "./home", 1000L),
new Event("Bob", "./home", 1000L));
//1.传入一个实现了FilterFunction的类的对象
SingleOutputStreamOperator<Event> result1 = stream3.filter(new MyFilterTest());
//2.入一个匿名类
SingleOutputStreamOperator<Event> mary = stream3.filter(new FilterFunction<Event>() {
@Override
public boolean filter(Event e) throws Exception {
return e.user.equals("Marry");
}
});
//3.传入Lambda表达式
stream3.filter(data->data.user.equals("Marry")).print();
result1.print();
mary.print();
env.execute();
}
public static class MyFilterTest implements FilterFunction<Event> {
@Override
public boolean filter(Event e) throws Exception {
return e.user.equals("Marry");
}
}
}
3.扁平映射(flatMap)
package com.fang.chapter05;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class TransFlatmapTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Event> stream = env.fromElements(
new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 2000L)
);
//1.实现FlatMapFunction接口
stream.flatMap(new MyFlatMap()).print("1");
//2.传入一个lambda表达式
stream.flatMap((Event value, Collector<String> out) -> {
if (value.user.equals("Mary")) {
out.collect(value.user);
} else if (value.user.equals("Bob")) {
out.collect(value.user);
out.collect(value.url);
}
}).returns(new TypeHint<String>() {}).print("2");
env.execute();
}
public static class MyFlatMap implements FlatMapFunction<Event, String> {
@Override
public void flatMap(Event value, Collector<String> out) throws Exception
{
if (value.user.equals("Mary")) {
out.collect(value.user);
} else if (value.user.equals("Bob")) {
out.collect(value.user);
out.collect(value.url);
}
}
}
}
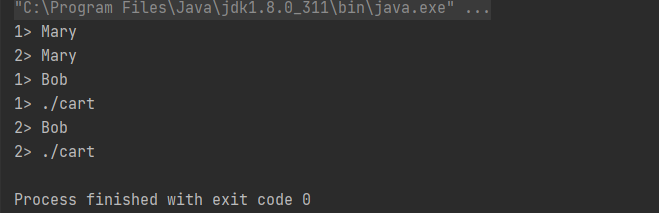
4.按键分区(keyBy)
keyBy 是聚合前必须要用到的一个算子。keyBy 通过指定键(key),可以将一条流从逻辑上划分成不同的分区(partitions)。这里所说的分区,其实就是并行处理的子任务,也就对应着任务槽(task slot)。
基于不同的 key,流中的数据将被分配到不同的分区中去,这样一来,所有具有相同的 key 的数据,都将被发往同一个分区,那么下一步算子操作就将会在同一个 slot中进行处理了。
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class TransKeyByTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Event> stream = env.fromElements(
new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 2000L)
);
// 使用 Lambda 表达式进行分组
KeyedStream<Event, String> keyedStream = stream.keyBy(e -> e.user);
// 使用匿名类实现 KeySelector
KeyedStream<Event, String> keyedStream1 = stream.keyBy(new
KeySelector<Event, String>() {
@Override
public String getKey(Event e) throws Exception {
return e.user;
}
});
env.execute();
}
}
5. 简单聚合(sum,min,max等)
⚫ sum():在输入流上,对指定的字段做叠加求和的操作。
⚫ min():在输入流上,对指定的字段求最小值。
⚫ max():在输入流上,对指定的字段求最大值。
⚫ minBy():与 min()类似,在输入流上针对指定字段求最小值。不同的是,min()只计算指定字段的最小值,其他字段会保留最初第一个数据的值;而 minBy()则会返回包含字段最小值的整条数据。
⚫ maxBy():与 max()类似,在输入流上针对指定字段求最大值。两者区别与min()/minBy()完全一致
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class TransTupleAggreationTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Tuple2<String, Integer>> stream = env.fromElements(
Tuple2.of("a", 1),
Tuple2.of("a", 3),
Tuple2.of("b", 3),
Tuple2.of("b", 4)
);
stream.keyBy(r -> r.f0).sum(1).print();
stream.keyBy(r -> r.f0).sum("f1").print();
stream.keyBy(r -> r.f0).max(1).print();
stream.keyBy(r -> r.f0).max("f1").print();
stream.keyBy(r -> r.f0).min(1).print();
stream.keyBy(r -> r.f0).min("f1").print();
stream.keyBy(r -> r.f0).maxBy(1).print();
stream.keyBy(r -> r.f0).maxBy("f1").print();
stream.keyBy(r -> r.f0).minBy(1).print();
stream.keyBy(r -> r.f0).minBy("f1").print();
env.execute();
}
}
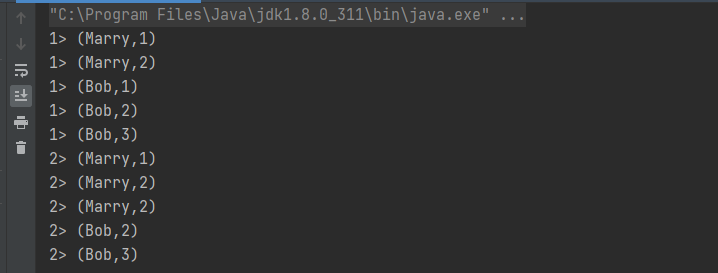
6.归约聚合(reduce)
如果说简单聚合是对一些特定统计需求的实现,那么 reduce 算子就是一个一般化的聚合统计操作了。从大名鼎鼎的 MapReduce 开始,我们对 reduce 操作就不陌生:它可以对已有的数据进行归约处理,把每一个新输入的数据和当前已经归约出来的值,再做一个聚合计算。
package com.fang.chapter05;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class TransformReduceTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//从元素读取数据
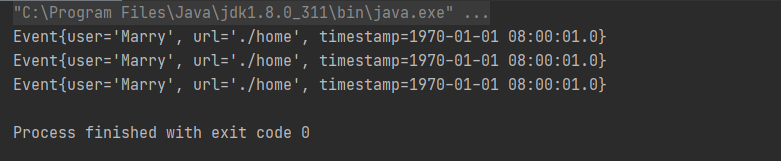
DataStreamSource<Event> stream3 = env.fromElements(
new Event("Marry", "./home", 1000L),
new Event("Marry", "./home", 1200L),
new Event("Bob", "./prod?id=1", 1000L),
new Event("Bob", "./home", 3500L),
new Event("Bob", "./prod?id=2", 3200L)
);
//1.统计每个用户的访问频次
SingleOutputStreamOperator<Tuple2<String, Long>> clicksByUser = stream3.map(new MapFunction<Event, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> map(Event value) throws Exception {
return Tuple2.of(value.user, 1L);
}
}).keyBy(data -> data.f0).reduce(new ReduceFunction<Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> reduce(Tuple2<String, Long> value1, Tuple2<String, Long> value2) throws Exception {
return Tuple2.of(value1.f0, value1.f1 + value2.f1);
}
});
//2.选取当前最活跃的用户
SingleOutputStreamOperator<Tuple2<String, Long>> result = clicksByUser.keyBy(data -> "key").reduce(new ReduceFunction<Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> reduce(Tuple2<String, Long> value1, Tuple2<String, Long> value2) throws Exception {
return value1.f1 > value2.f1 ? value1 : value2;
}
});
clicksByUser.print("1");
result.print("2");
env.execute();
}
}
7.自定义函数
1.函数类(Function Classes)
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class TransFunctionUDFTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Event> clicks = env.fromElements(
new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 2000L)
);
DataStream<Event> stream = clicks.filter(new FlinkFilter());
stream.print();
env.execute();
}
public static class FlinkFilter implements FilterFunction<Event> {
public boolean filter(Event value) throws Exception {
return value.url.contains("home");
}
}
}
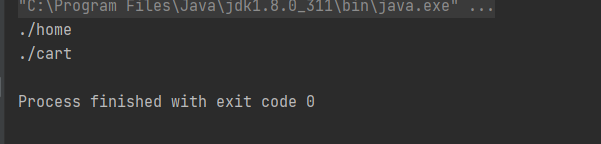
2.匿名函数(Lambda)
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class TransFunctionLambdaTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Event> clicks = env.fromElements(
new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 2000L)
);
//map 函数使用 Lambda 表达式,返回简单类型,不需要进行类型声明
DataStream<String> stream1 = clicks.map(event -> event.url);
stream1.print();
env.execute();
}
}
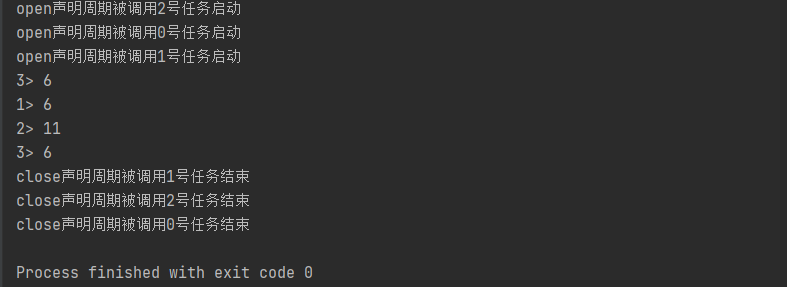
3.富函数类(Rich Function Classes)
“富函数类”也是 DataStream API 提供的一个函数类的接口,所有的 Flink 函数类都有其Rich 版本。富函数类一般是以抽象类的形式出现的。例如:RichMapFunction、RichFilterFunction、RichReduceFunction 等。
富函数类可以获取运行环境的上下文,并拥有一些生命周期方法,所以可以实现更复杂的功能
Rich Function 有生命周期的概念。典型的生命周期方法有:
⚫ open()方法,是 Rich Function 的初始化方法,也就是会开启一个算子的生命周期。当一个算子的实际工作方法例如 map()或者 filter()方法被调用之前,open()会首先被调用。所以像文件 IO 的创建,数据库连接的创建,配置文件的读取等等这样一次性的工作,都适合在 open()方法中完成。。
⚫ close()方法,是生命周期中的最后一个调用的方法,类似于解构方法。一般用来做一些清理工作。
需要注意的是,这里的生命周期方法,对于一个并行子任务来说只会调用一次;而对应的,实际工作方法,例如 RichMapFunction 中的 map(),在每条数据到来后都会触发一次调用。
package com.fang.chapter05;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class RichFunctionTest {
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(3);
DataStreamSource<Event> clicks = env.fromElements(
new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 2000L),
new Event("Alice", "./prod?id=1", 5 * 1000L),
new Event("Cary", "./home", 60 * 1000L)
);
clicks.map(new MyRichMapper()).print();
env.execute();
}
//实现一个自定义的复函数类
public static class MyRichMapper extends RichMapFunction<Event,Integer>{
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
System.out.println("open声明周期被调用"+getRuntimeContext().getIndexOfThisSubtask()+"号任务启动");
}
@Override
public Integer map(Event value) throws Exception {
return value.url.length();
}
@Override
public void close() throws Exception {
super.close();
System.out.println("close声明周期被调用"+getRuntimeContext().getIndexOfThisSubtask()+"号任务结束");
}
}
}




![[附源码]Node.js计算机毕业设计高校就业管理信息系统Express](https://img-blog.csdnimg.cn/f7d0d23cf3544a6f9f6edf39f41cbba6.png)