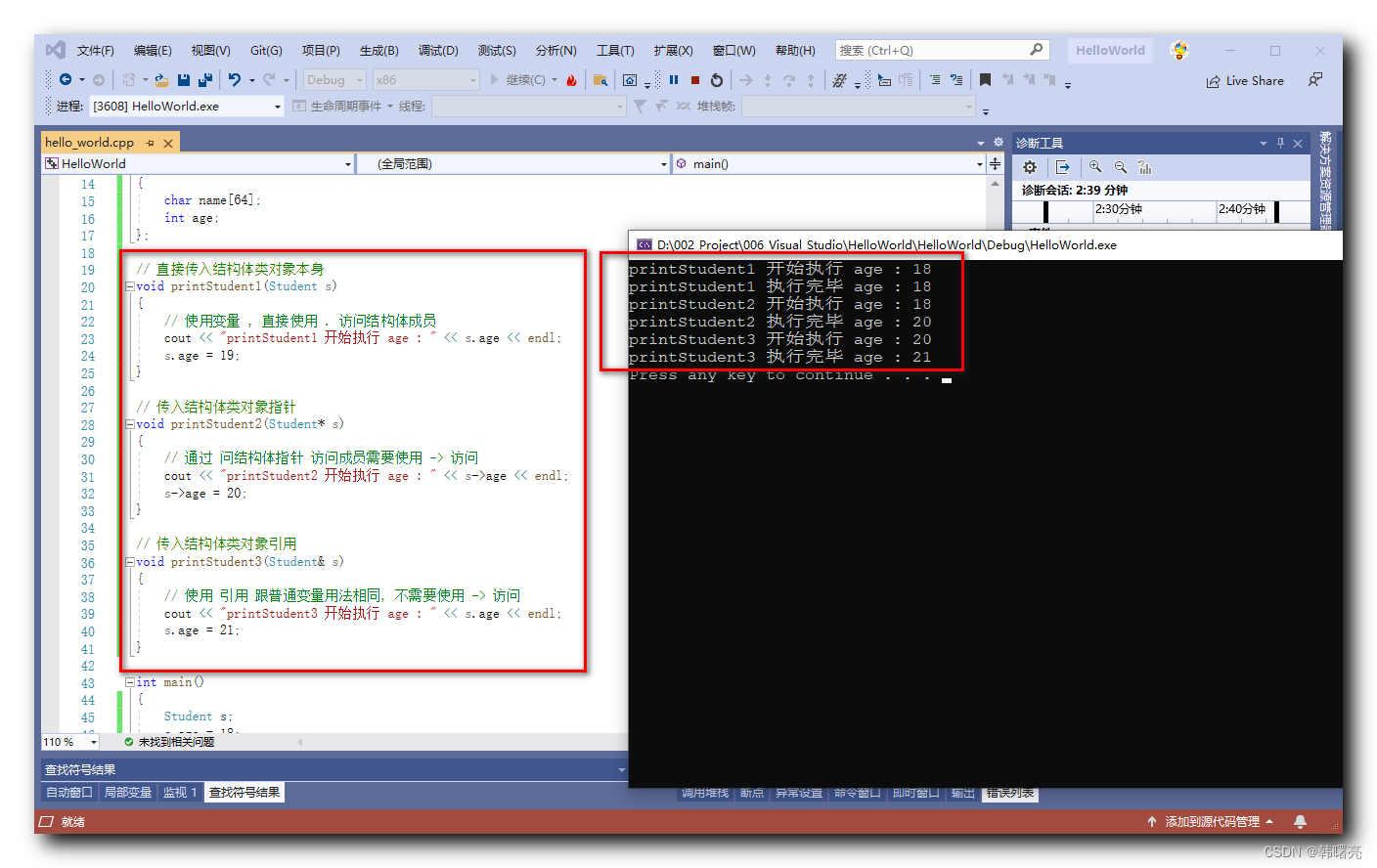
1.继承性、多态性、封装性。
2.C++本身是属于编译型语言。
什么叫编译型语言呢?程序在执行之前需要一个专门的编译过程,把程序编译成二进制文件(可执行文件),执行的时候,不需要重新翻译,直接使用编译的结果就行了。
相对于编译型语言,还有解释型语言。解释型语言编写的程序不进行预先编译,以文本方式存储程序代码。但是,在执行程序的时候,解释型语言必须先解释再执行。
显然,编译型语言执行速度快,因为它不需要解释。而像Lua等语言,就属于解释型语言。
3.命名空间简介
命名空间就是为了防止名字冲突而引入的一种机制。系统中可以定义多个命名空间,每个命名空间都有自己的名字,不可以同名。可以把命名空间看成一个作用域,这个命名空间里定义的函数与另外一个命名空间里定义的函数,即便同名,也互不影响(因为命名空间名不同)。
(1)命名空间定义:

(2)命名空间定义可以不连续,可以写在不同的位置,甚至写在不同的源文件中。如果以往没有定义该命名空间,那么这就相当于定义了一个命名空间,如果以往已经定义了该命名空间,那这就相当于打开已经存在的命名空间并为其添加内容。
(3)外界访问某个命名空间中的实体的方法:访问格式如下,其中两个冒号叫“作用域运算符”:

看看如下范例,现在希望在main函数中调用命名空间NMZhangSan中的radius函数:
//MyProject.cpp源文件代码如下
namespace NMZhangSan //定义命名空间
{
void radius(){
printf("MZhangSan::radius函数被执行\n");
}
}
int main() //主函数
{
NMZhangSan::radius(); //调用MZhangSan命名空间下的radius函数
}
现在将MyProject2.cpp加入到当前项目中来:
namespace NMLiSi
{
void radius()
{
printf("NMLiSi::radius函数被执行.\n");
}
}
此时,希望也在main函数中调用NMLiSi命名空间下的radius函数,于是在main函数中增加如下代码:
NMLiSi::radius();
但是,编译出错,无法调用成功,系统不认识NMLiSi命名空间下的radius函数。为什么?
· 在main中调用NMZhangSan::radius之所以成功,是因为该函数和main函数处于同一个文件(MyProject.cpp)中。
· 但是NMLiSi::radius函数却在MyProject2.cpp文件中,所以main中调用NMLiSi::radius会失败(因为缺少该函数的声明)。
为了能够调用成功NMLiSi::radius,就需要对源代码进行细致认真的组织,组织得好,看起来和用起来就都方便,也能够体现出开发者的整体开发素质,所以,请读者一定要重视源代码的组织。该如何进行源代码的组织呢?
(1)把函数声明,包括以后学习类,要把类的定义等内容放到一个头文件中。这里新建立一个MyProject2.h的头文件,内容如下:
namespace NMLiSi
{
void radius(); //函数声明
}
(2)在MyProject.cpp文件开头增加如下代码把MyProject2.h这个头文件包含进来:
#include "MyProject2.h"
再次编译链接整个项目,成功,并能够正确执行。
(3)现在在main函数中可以成功调用NMLiSi::radius函数,但是每次调用都要在函数名之前写NMLiSi::前缀,感觉比较多余。是否可以简化书写,当然是可以的,通过using namespace来声明NMLiSi这个命名空间,声明后,调用NMLiSi命名空间中的函数就不再需要使用NMLiSi::前缀了。usingnamespace的使用格式如下:

现在在MyProject.cpp源文件中的main函数之前加入如下代码:
using namespace NMLiSi; //声明NMLiSi命名空间
此时,把main函数中的“NMLiSi::radius();”修改为“radius();”,发现也能正确地调用NMLiSi命名空间中的radius函数。
(4)试想,现在在“usingnamespaceNMLiSi;”代码行的下面增加如下代码行,会出现什么情况呢?
using namespace NMZhangSan; //声明NMZhangSan命名空间
此时编译代码,就会报错,报错的源头是main函数中的“radius();”代码行。因为在NMZhangSan命名空间和NMLiSi命名空间中都包含radius函数,而通过usingnamespace既声明了NMLiSi命名空间又声明了NMZhangSan命名空间,此时,系统就无法分辨出到底调用NMLiSi命名空间中的radius函数还是NMZhangSan命名空间中的radius函数。所以,①要么不要同时声明两个命名空间;②要么不同命名空间中的函数不要同名;③要么调用radius函数时增加诸如“NMLiSi::”前缀。
基本输入/输出精解
C++中输入/输出用的标准库是iostream库(输入/输出流)。什么叫流?流就是一个字符序列。
基本输出 std::cout
(1)std:这是标准库中定义的一个命名空间,请读者记住这个名字。
(2)cout:是一个对象,一个与iostream相关的对象。cout对象被称为“标准输出”,一般用于向屏幕输出一些内容,索性把cout当成屏幕也是可以的。
std::endl是一个函数模板名,相当于函数指针,建议暂时理解成函数,以后会详细讲解函数模板。有两点可以总结一下:
(1)一般来讲,能看到std::endl的地方都有std::cout的身影。
(2)std::endl一般都在语句的末尾,有两个作用。
· 输出换行符\n。
· 刷新输出缓冲区,调用flush(理解成函数)强制输出缓冲区中所有数据(也叫刷新输出流,目的就是显示到屏幕),然后把缓冲区中数据清除。
什么叫输出缓冲区?可以理解成一段内存,使用std::cout输出的时候实际上是往输出缓冲区中输出内容。那么输出缓冲区什么时候把内容输出到屏幕上呢?有如下几种情况:
(1)缓冲区满了。
(2)程序执行到main函数中的return,要正常结束了。
(3)使用std::endl了,因为使用后会调用flush()。
(4)系统不太忙的时候,会查看缓冲区内容,发现新内容就正常输出。所以有时使用std::cout时,语句行末尾是否增加std::endl都能将信息正常且立即输出到屏幕。
(5)可能还有其他情况,这里不做进一步探讨。
读者可能还有一个疑问,为什么要有这个输出缓冲区?用std::cout直接输出信息到屏幕时,缓冲区的作用体现的不太明显,那如果是输出信息到一个文件中,那么输出缓冲区作用就明显了,总不能输出一个字符,就写一次文件,因为文件是保存在硬盘上,速度和内存比实在是慢太多了,所以很有必要将数据临时保存到输出缓冲区,然后一次性地将这些数据写入硬盘。
基本输入
cin也是一个对象,被称为“标准输入”。在C语言部分曾经讲过scanf函数,用于从键盘输入一些数据,在C++中,cin对象同样能够做这件事。



![[oneAPI] 基于BERT预训练模型的英文文本蕴含任务](https://img-blog.csdnimg.cn/4affc2f77e684260aeedb0e0a5e1d888.png)