前提:使用《MySql006——检索数据:基础select语句》中创建的products表
一、GROUP BY子句基础用法
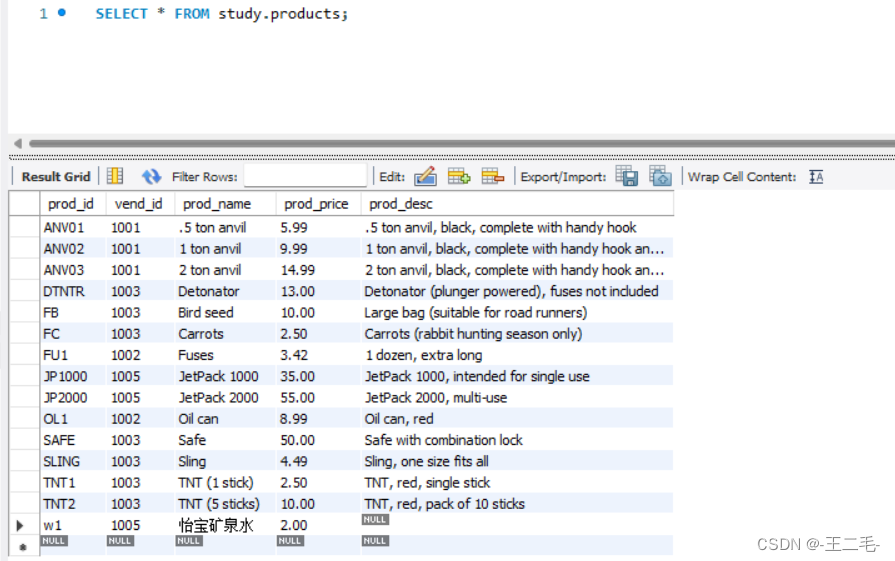
SELECT
vend_id, COUNT(*) AS num_prods
FROM
study.products
GROUP BY vend_id;
上面的SELECT语句指定了两个列,vend_id包含产品供应商的ID,num_prods为计算字段(用COUNT(*)函数建立)。GROUP BY子句指
示MySQL按vend_id排序并分组数据。这导致对每个vend_id而不是整个表计算num_prods一次。从输出中可以看到,供应商1001有3个产品,供应商1002有2个产品,供应商1003有7个产品,而供应商1005有3个产品。
注意:GROUP BY子句必须出现在WHERE子句之后,ORDER BY子句之前。
二、过滤分组
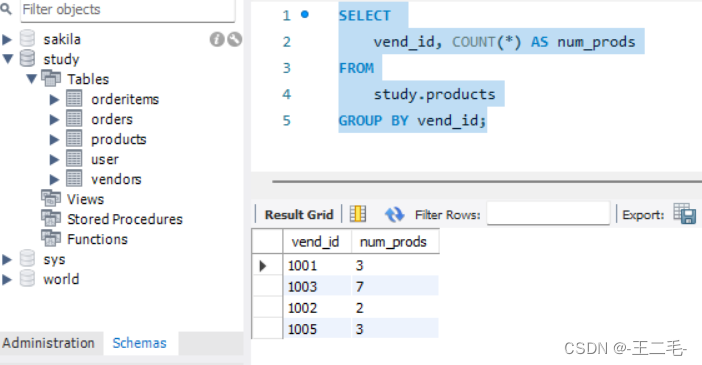
2.1、准备工作:在study库中创建表orders(订单表),并插入数据
#####################
# Create orders table
#####################
CREATE TABLE orders
(
order_num int NOT NULL AUTO_INCREMENT,
order_date datetime NOT NULL ,
cust_id int NOT NULL ,
PRIMARY KEY (order_num)
) ENGINE=InnoDB;
#######################
# Populate orders table
#######################
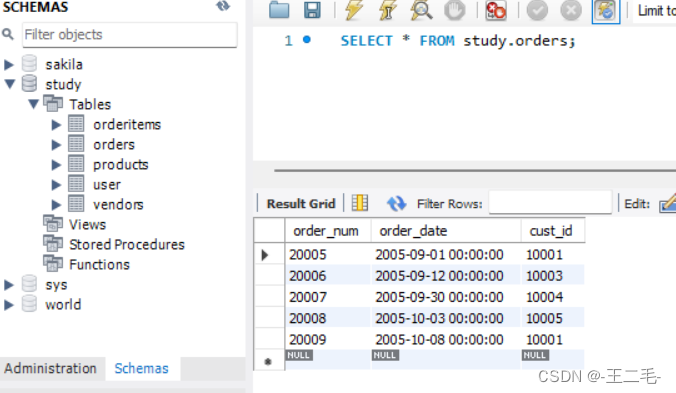
INSERT INTO orders(order_num, order_date, cust_id)
VALUES(20005, '2005-09-01', 10001);
INSERT INTO orders(order_num, order_date, cust_id)
VALUES(20006, '2005-09-12', 10003);
INSERT INTO orders(order_num, order_date, cust_id)
VALUES(20007, '2005-09-30', 10004);
INSERT INTO orders(order_num, order_date, cust_id)
VALUES(20008, '2005-10-03', 10005);
INSERT INTO orders(order_num, order_date, cust_id)
VALUES(20009, '2005-10-08', 10001);
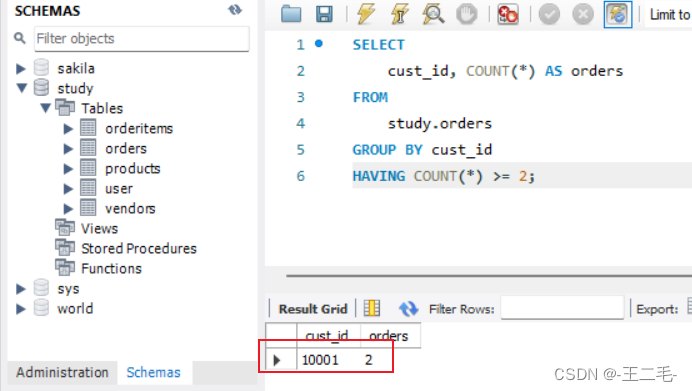
2.2、例子1:想要列出至少有两个订单的所有顾客。
SELECT
cust_id, COUNT(*) AS orders
FROM
study.orders
GROUP BY cust_id -- 使用GROUP BY,根据cust_id将相同顾客信息,分成一组
HAVING COUNT(*) >= 2; -- 使用HAVING和COUNT()选出订单数大于等于2 的顾客信息
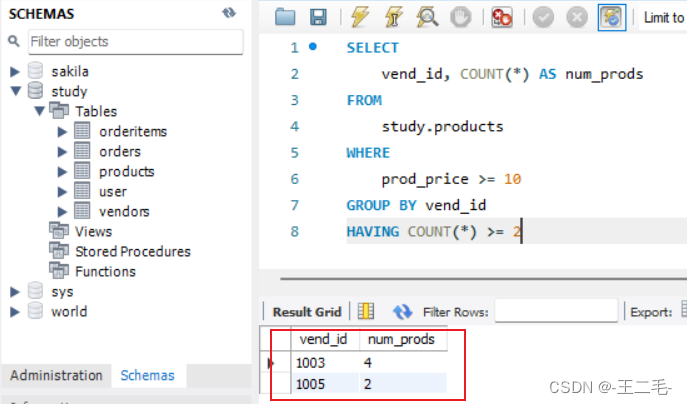
2.3、例子2,它列出具有2个(含)以上、价格为10(含)以上的产品的供应商
SELECT
vend_id, COUNT(*) AS num_prods
FROM
study.products
WHERE
prod_price >= 10 --价格要大于等于10
GROUP BY vend_id -- 根据vend_id分组
HAVING COUNT(*) >= 2 -- 只选择分组中数据大于等于2条的
# 即:根据vend_id分组,只选择分组中数据大于等于2条,且价格大于等于10的数据
三、分组GROUP BY和排序ORDER BY区别
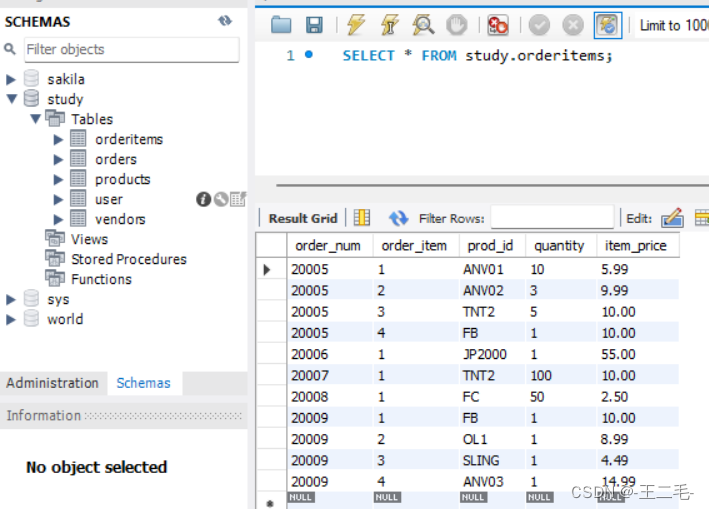
3.1、准备工作:在study库中创建表orderitems(订单详细表),并插入数据
#########################
# Create orderitems table
#########################
CREATE TABLE orderitems
(
order_num int NOT NULL ,
order_item int NOT NULL ,
prod_id char(10) NOT NULL ,
quantity int NOT NULL ,
item_price decimal(8,2) NOT NULL ,
PRIMARY KEY (order_num, order_item)
) ENGINE=InnoDB;
###########################
# Populate orderitems table
###########################
INSERT INTO orderitems(order_num, order_item, prod_id, quantity, item_price)
VALUES(20005, 1, 'ANV01', 10, 5.99);
INSERT INTO orderitems(order_num, order_item, prod_id, quantity, item_price)
VALUES(20005, 2, 'ANV02', 3, 9.99);
INSERT INTO orderitems(order_num, order_item, prod_id, quantity, item_price)
VALUES(20005, 3, 'TNT2', 5, 10);
INSERT INTO orderitems(order_num, order_item, prod_id, quantity, item_price)
VALUES(20005, 4, 'FB', 1, 10);
INSERT INTO orderitems(order_num, order_item, prod_id, quantity, item_price)
VALUES(20006, 1, 'JP2000', 1, 55);
INSERT INTO orderitems(order_num, order_item, prod_id, quantity, item_price)
VALUES(20007, 1, 'TNT2', 100, 10);
INSERT INTO orderitems(order_num, order_item, prod_id, quantity, item_price)
VALUES(20008, 1, 'FC', 50, 2.50);
INSERT INTO orderitems(order_num, order_item, prod_id, quantity, item_price)
VALUES(20009, 1, 'FB', 1, 10);
INSERT INTO orderitems(order_num, order_item, prod_id, quantity, item_price)
VALUES(20009, 2, 'OL1', 1, 8.99);
INSERT INTO orderitems(order_num, order_item, prod_id, quantity, item_price)
VALUES(20009, 3, 'SLING', 1, 4.49);
INSERT INTO orderitems(order_num, order_item, prod_id, quantity, item_price)
VALUES(20009, 4, 'ANV03', 1, 14.99);
直接上例子
3.2、例子
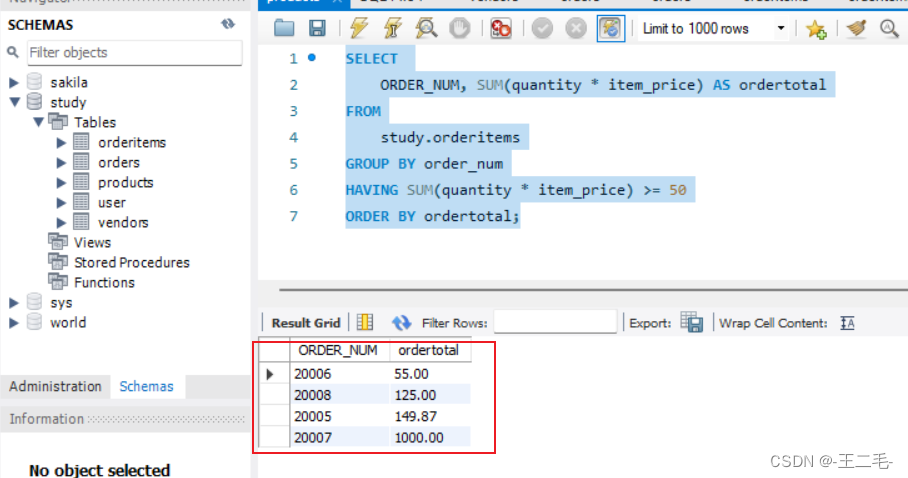
它检索总计订单价格大于等于50的订单的订单号和总计订单价格,并按总计订单价格排序输出。
SELECT
ORDER_NUM, SUM(quantity * item_price) AS ordertotal
FROM
study.orderitems
GROUP BY order_num
HAVING SUM(quantity * item_price) >= 50
ORDER BY ordertotal;
在这个例子中,GROUP BY子句用来按订单号(order_num列)分组数据,以便SUM(*)函数能够返回总计订单价格。HAVING子句过滤数据,使得只返回总计订单价格大于等于50的订单。最后,用ORDER BY子句排序输出。
四、SELECT子句顺序
下面回顾一下SELECT语句中子句的顺序
=================================================================
子 句 说 明 是否必须使用
=================================================================
SELECT 要返回的列或表达式 是
FROM 从中检索数据的表 仅在从表选择数据时使用
WHERE 行级过滤 否
GROUP BY 分组说明 仅在按组计算聚集时使用
HAVING 组级过滤 否
ORDER BY 输出排序顺序 否
LIMIT 要检索的行数 否
=================================================================
与君共享
👉👉👉👉👉最后,有兴趣的小伙伴可以点击下面链接,这里有我整理的MySQL学习博客内容,谢谢~ 🌹🌹🌹🌹🌹
《MySQL数据库学习》


![[oneAPI] 基于BERT预训练模型的英文文本蕴含任务](https://img-blog.csdnimg.cn/4affc2f77e684260aeedb0e0a5e1d888.png)