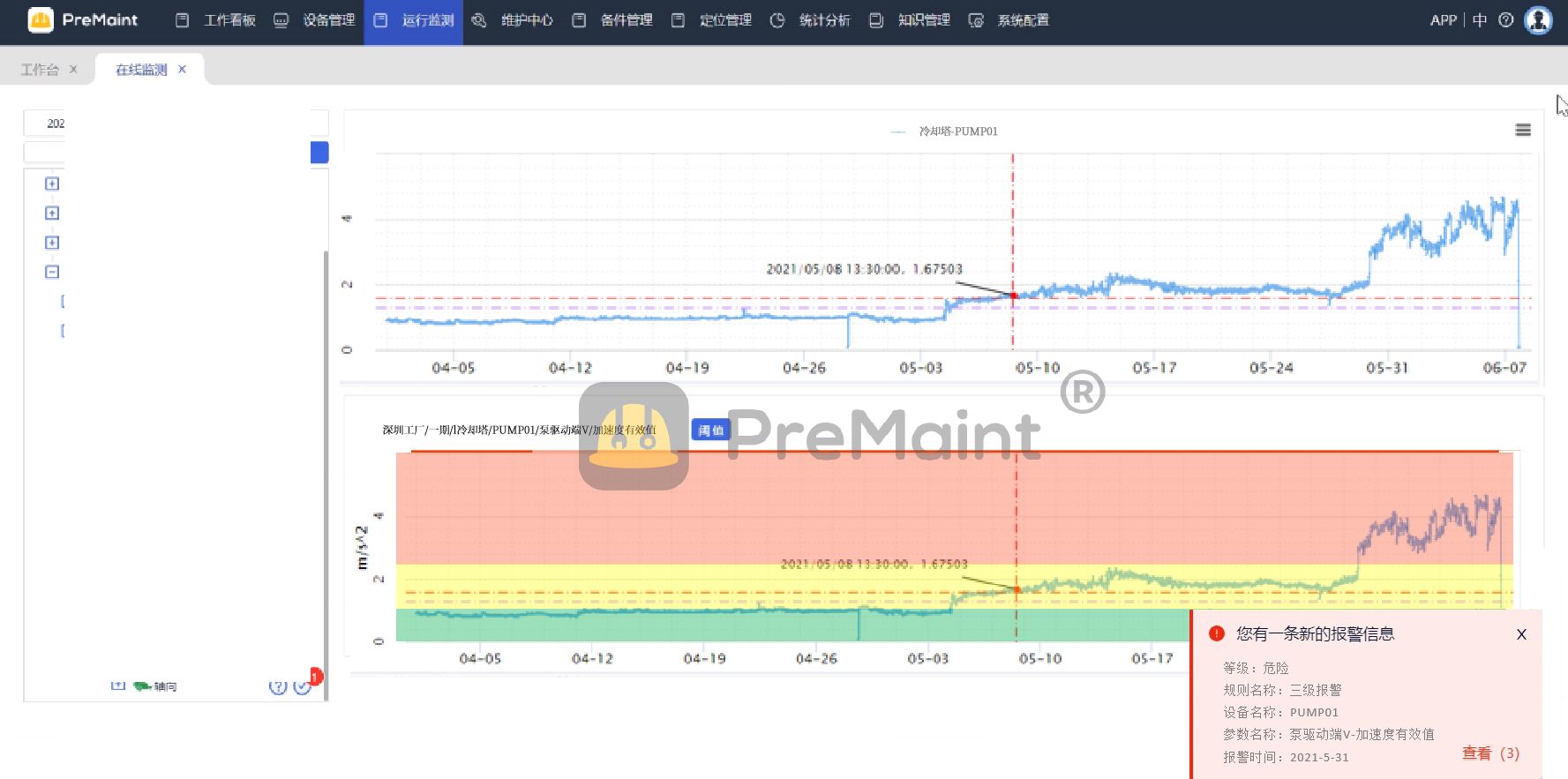
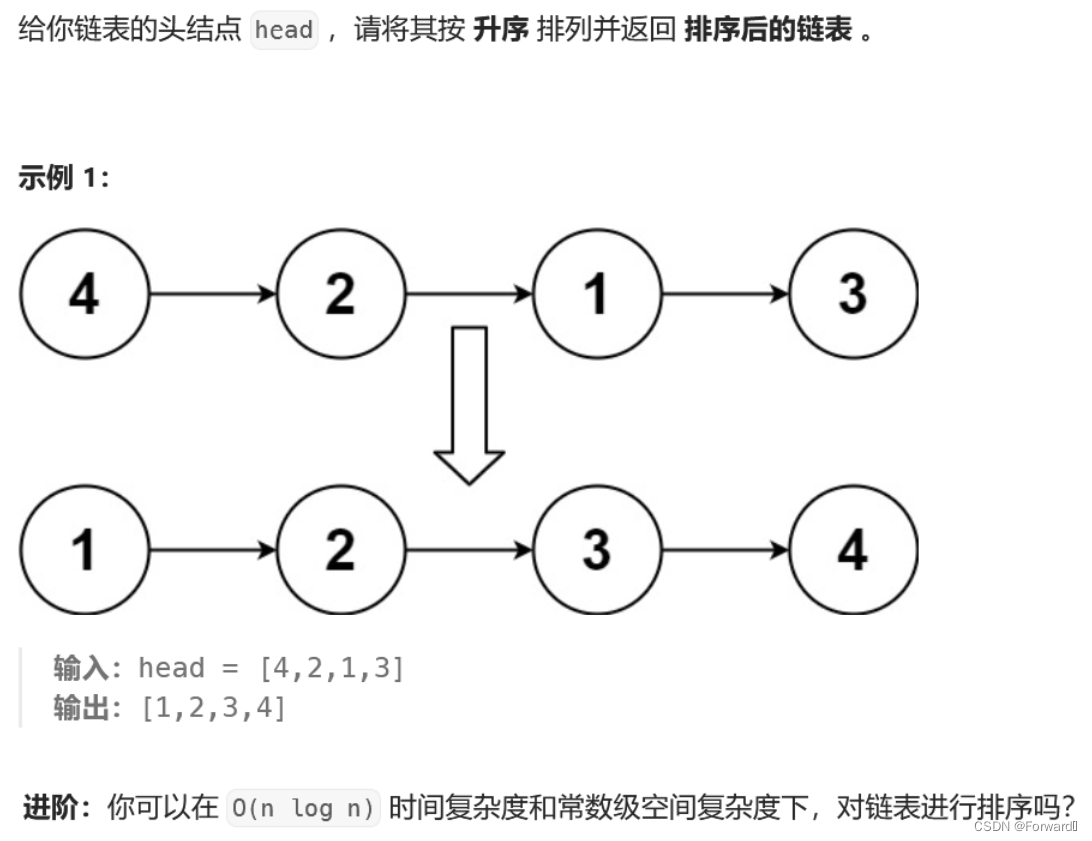
排序链表(递归 + 迭代)
题目链接
注:本体的解法建立在归并排序的基础之上,如果对这一排序还不太了解,建议看看:
👉归并排序
👉八大排序算法详解
👉合并两个有序链表
既然采用递归排序来解决这道题,那么我们就要采用分治的思想
分治法(Divide and Conquer)是一种解决问题的算法设计策略,它将一个大的问题分解为若干个小的子问题,逐步解决这些子问题,并将它们的解合并成一个大问题的解
同理,我们将排序一整串长链表的问题分解为若干个简单的子问题,而这些简单的子问题就是对链表的单个元素进行成对处理:两个长度为1的链表可以合成一个长度为2的有序链表,两个长度为2的链表可以合成一个长度为4的链表,以此类推,直到得到完整的有序链表。
而递归排序有递归和迭代两种实现方式,接下来我们分别进行分析:
递归(自顶向下)
自顶向下归并排序: 自顶向下归并排序是一种递归的实现方式。它的基本思想是将原始数组递归地分成两半,然后分别对这两半进行排序,最后将排好序的子数组合并成一个有序数组。整个过程可以看作是自顶向下地将问题逐步分解并解决的过程。
步骤:
- 将原始链表分成两半。
- 递归地对这两半链表进行排序(继续分割并排序)。
- 合并两个排好序的子链表,得到一个完整的有序链表。
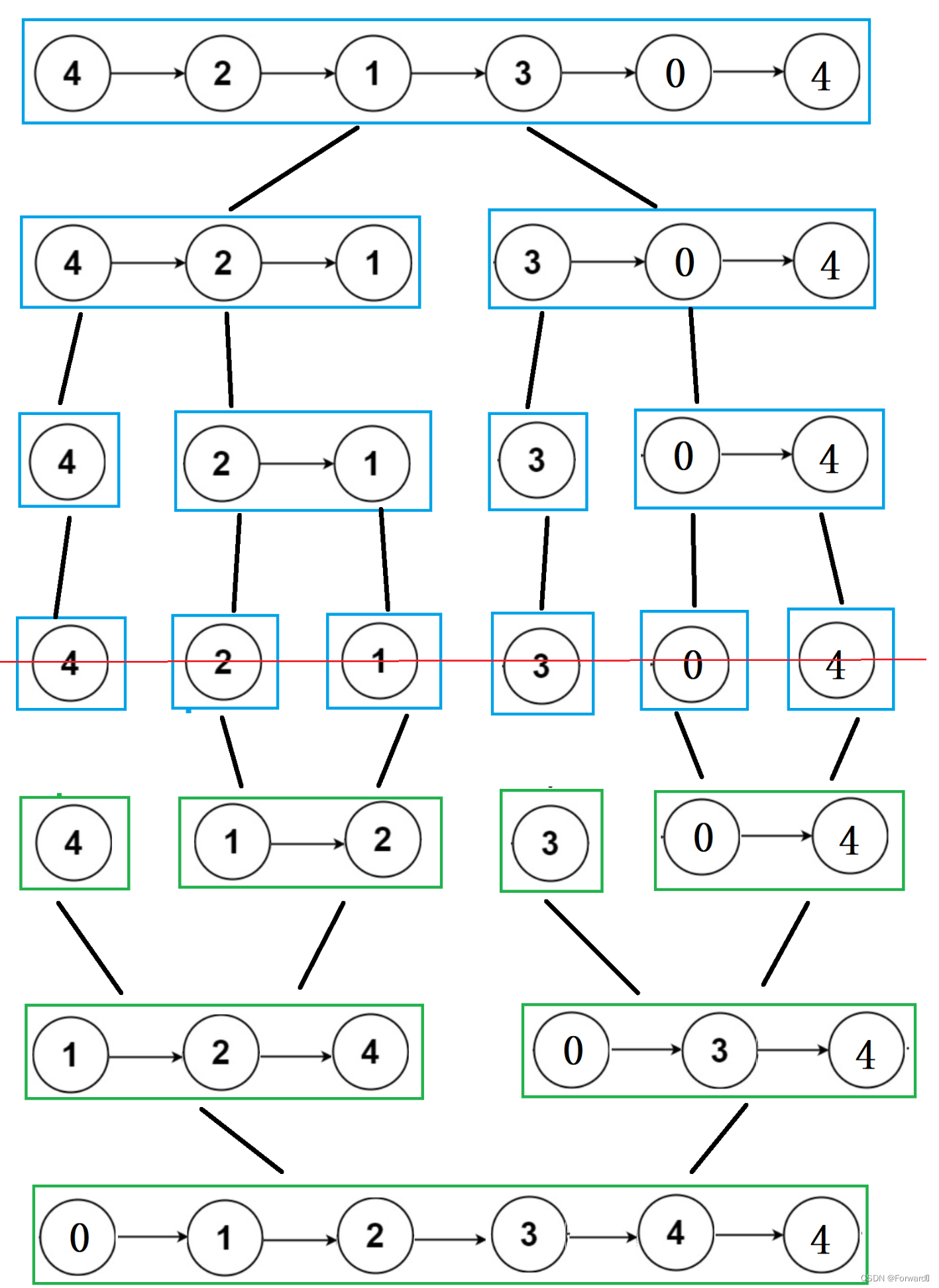
如图所示:
实现代码
//合并两个有序链表
struct ListNode* merge(struct ListNode* headA, struct ListNode* headB)
{
if (headA == NULL || headB == NULL)
return headA == NULL ? headB : headA;
struct ListNode* newHead = (struct ListNode*)malloc(sizeof(struct ListNode));
struct ListNode* cur = newHead;
struct ListNode* cur1 = headA;
struct ListNode* cur2 = headB;
while (cur1 && cur2)
{
if (cur1->val < cur2->val)
{
cur->next = cur1;
cur1 = cur1->next;
}
else
{
cur->next = cur2;
cur2 = cur2->next;
}
cur = cur->next;
}
cur->next = cur1 == NULL ? cur2 : cur1;
struct ListNode* ret = newHead->next;
free(newHead);
return ret;
}
struct ListNode* sortList(struct ListNode* head){
if (head == NULL || head->next == NULL)
return head;
//利用双指针找到链表的中间节点
struct ListNode* left = NULL;
struct ListNode* mid = head;
struct ListNode* right = head;
while (right && right->next)
{
left = mid;
mid = mid->next;
right = right->next->next;
}
left->next = NULL; //从中间节点出断开,得到两个子链表
//对子链表不断地进行递归分割,直到分割为不可分割的子链表(一个元素),在进行合并
return merge(sortList(head), sortList(mid));
}
为加深理解,我们以上个例子为例,分析整个递归过程(序号为执行顺序):
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YV28dJZT-1692709107509)(C:/Users/HUASHUO/AppData/Roaming/Typora/typora-user-images/image-20230822175144390.png)]](https://img-blog.csdnimg.cn/cd882318f1f0417fbae75e4596644913.png)
迭代(自底向上)
自底向上归并排序是一种迭代的实现方式。它的基本思想是先将原始数组中的每个元素看作是一个独立的有序数组,然后从底层开始两两合并这些小的有序数组,直到合并成一个完整的有序数组。
步骤:
- 将原始链表中的每个元素看作是一个有序链表。
- 从底层开始,将相邻的两个小的有序链表合并成更大的有序链表。
- 逐步合并相邻的有序链表,直到合并成一个完整的有序链表。
如图:
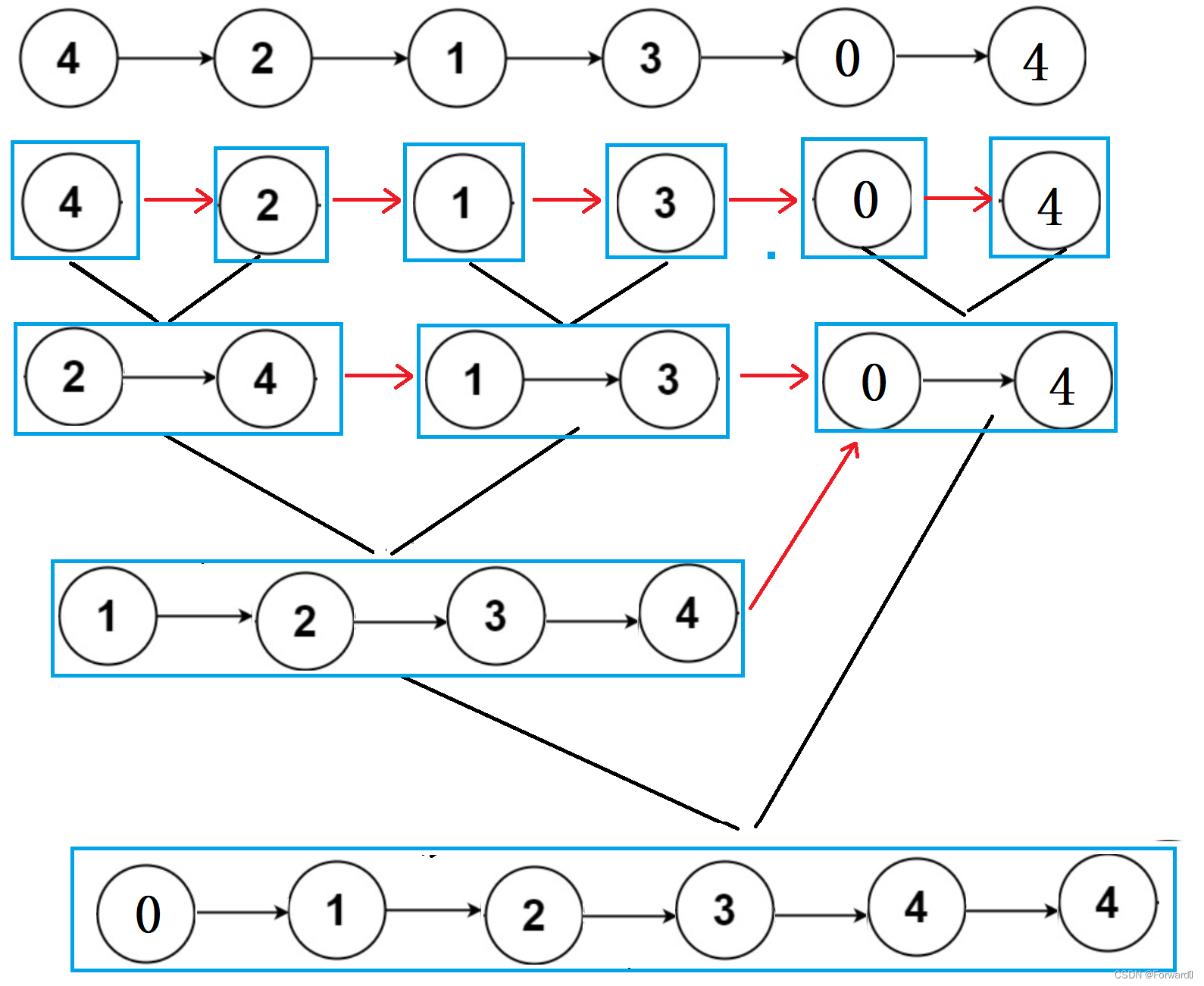
虽然迭代发较递归法容易理解许多,但是代码却复杂了不止一点点,下面我们来仔细分析:
-
由于链表的排序可能会改变原链表的头部,因此我们要定义一个哨兵位
newHead来确定链表的头部 -
第一次要合并两个长度为1的子链表,第二次要合并两个长度为2的子链表…………,因此我们要用一个计数器
subLength来记录每次循环合并的子链表长度,而为了确定循环终止条件,我们要求出整个链表的长度length
int length = 0;
struct ListNode* cur = head;
while (cur) //求出链表长度
{
length++;
cur = cur->next;
}
//定义哨兵位头节点
struct ListNode* newHead = (struct ListNode*)malloc(sizeof(struct ListNode));
newHead->next = head;
//开始合并
for (int subLength = 1; subLength < length; subLength *= 2)
{………………}
-
对于每一个
subLength,我们都需要一个cur,这个cur用来:遍历整个链表,同时确保其移动的步数为sublength - 1,不断找到需要合并的两个子链表,同时还要一个指针prev用来链接合并后返回的指针。for (int subLength = 1; subLength < length; subLength *= 2) { //对于每一个subLength,cur都从第一个有效节点开始确定要合并的子链表 cur = newHead->next; struct ListNode* prev = newHead; while (cur) { struct ListNode* head1 = cur; //第一个子链表的头即为cur的起点 for (int i = 1; i < subLength && cur->next != NULL; i++) cur = cur->next; //确定第一个子链表的范围后断开和之后的节点的链接,cur向后移 struct ListNode* temp = cur->next; cur->next = NULL; cur = temp; //如果cur后移后不为空,说明存在第二条子链表,可以合并 if (cur) { struct ListNode* head2 = cur; //第二个子链表的头即为cur的起点 for (int i = 1; i < subLength && cur->next != NULL; i++) cur = cur->next; //确定第二条子链表的范围后断开和之后的节点的链接,同时cur后移 temp = cur->next; cur->next = NULL; cur = temp; //找到两条子链表的头后开始合并 struct ListNode* merged = merge(head1, head2); prev->next = merged; //用prev进行连接 //prev移动到部分有序链表的末尾,用来之后的链接 while (prev->next) prev = prev->next; prev->next = temp; //为防止访问不到剩余节点,prev要链接到还未排序的节点 } } }
实现代码
//合并两个有序链表
struct ListNode* merge(struct ListNode* headA, struct ListNode* headB)
{
if (headA == NULL || headB == NULL)
return headA == NULL ? headB : headA;
struct ListNode* newHead = (struct ListNode*)malloc(sizeof(struct ListNode));
struct ListNode* cur = newHead;
struct ListNode* cur1 = headA;
struct ListNode* cur2 = headB;
while (cur1 && cur2)
{
if (cur1->val < cur2->val)
{
cur->next = cur1;
cur1 = cur1->next;
}
else
{
cur->next = cur2;
cur2 = cur2->next;
}
cur = cur->next;
}
cur->next = cur1 == NULL ? cur2 : cur1;
struct ListNode* ret = newHead->next;
free(newHead);
return ret;
}
struct ListNode* sortList(struct ListNode* head){
if (head == NULL || head->next == NULL)
return head;
//求链表长度
int length = 0;
struct ListNode* cur = head;
while (cur)
{
length++;
cur = cur->next;
}
//开始排序
struct ListNode* newHead = (struct ListNode*)malloc(sizeof(struct ListNode));
newHead->next = head;
for (int subLength = 1; subLength < length; subLength *= 2)
{
cur = newHead->next;
struct ListNode* prev = newHead;
while (cur)
{
struct ListNode* head1 = cur;
for (int i = 1; i < subLength && cur->next != NULL; i++)
cur = cur->next;
struct ListNode* temp = cur->next;
cur->next = NULL;
cur = temp;
if (cur)
{
struct ListNode* head2 = cur;
for (int i = 1; i < subLength && cur->next != NULL; i++)
cur = cur->next;
temp = cur->next;
cur->next = NULL;
cur = temp;
struct ListNode* merged = merge(head1, head2);
prev->next = merged;
while (prev->next)
prev = prev->next;
prev->next = temp;
}
}
}
//释放哨兵位,并返回结果
struct ListNode* ret = newHead->next;
free(newHead);
return ret;
}
![[oneAPI] 基于BERT预训练模型的英文文本蕴含任务](https://img-blog.csdnimg.cn/4affc2f77e684260aeedb0e0a5e1d888.png)