Prometheus
- 一、Prometheus 概念
- 1. Prometheus 概述
- 2. Prometheus 的监控数据
- 3. Prometheus 的特点
- 4. Prometheus 和 zabbix 区别
- 5. Prometheus 的生态组件
- 5.1 Prometheus server
- 5.2 Client Library
- 5.3 Exporters
- 5.4 Service Discovery
- 5.5 Alertmanager
- 5.6 Pushgateway
- 5.7 Grafana
- 6. Prometheus 的工作模式
- 7. Prometheus 的工作流程
- 8. Prometheus 的局限性
- 二、部署配置及监控
- 1. 部署 Prometheus
- Prometheust Server 端安装和相关配置
- 2. 部署 Exporters
- 3. 监控 MySQL 配置示例
- 3.1 在 MySQL 服务器上操作
- 3.2 在 Prometheus 服务器上操作
- 4. 监控 Nginx 配置示例
- 4.1 在 Nginx 服务器上操作
- 4.2 在 Prometheus 服务器上操作
- 总结
- 1. 常用监控系统
- 2. Zabbix 和 Prometheus 的区别? 如何选择?
- 3. Prometheus 的概念
- 4. Prometheus 的生态组件
- 5. Prometheus 工作过程
- 6. Prometheus 数据采集配置
一、Prometheus 概念
1. Prometheus 概述
Prometheus 是一个开源的服务监控系统和时序数据库,其提供了通用的数据模型和快捷数据采集、存储和查询接口。它的核心组件 Prometheus server 会定期从静态配置的监控目标或者基于服务发现自动配置的目标中进行拉取数据,新拉取到的数据会持久化到存储设备当中。
Prometheus 官网地址:https://prometheus.io
Prometheus github 地址:https://github.com/prometheus
每个被监控的主机都可以通过专用的 exporter 程序提供输出监控数据的接口,它会在目标处收集监控数据,并暴露出一个 HTTP 接口供 Prometheus server 查询,Prometheus 通过基于 HTTP 的 pull 的方式来周期性的采集数据。
如果存在告警规则,则抓取到数据之后会根据规则进行计算,满足告警条件则会生成告警,并发送到 Alertmanager 完成告警的汇总和分发。
当被监控的目标有主动推送数据的需求时,可以以 Pushgateway 组件进行接收并临时存储数据,然后等待 Prometheus server 完成数据的采集。
任何被监控的目标都需要事先纳入到监控系统中才能进行时序数据采集、存储、告警和展示,监控目标可以通过配置信息以静态形式指定,也可以让 Prometheus 通过服务发现的机制进行动态管理。
Prometheus 能够直接把 API Server 作为服务发现系统使用,进而动态发现和监控集群中的所有可被监控的对象。
2. Prometheus 的监控数据
TSDB 作为 Prometheus 的存储引擎完美契合了监控数据的应用场景
- 存储的数据量级十分庞大。
- 大部分时间都是写入操作。
- 写入操作几乎是顺序添加,大多数时候数据都以时间排序。
- 很少更新数据,大多数情况在数据被采集到数秒或者数分钟后就会被写入数据库。
- 删除操作一般为区块删除,选定开始的历史时间并指定后续的区块。很少单独删除某个时间或者分开的随机时间的数据。
- 基本数据大,一般超过内存大小。一般选取的只是其一小部分且没有规律,缓存几乎不起任何作用。
- 读操作是十分典型的升序或者降序的顺序读。
- 高并发的读操作十分常见。
3. Prometheus 的特点
- 多维数据模型:由度量名称和键值对标识的时间序列数据。时间序列数据就是按照时间顺序记录系统、设备状态变化的数据,每个数据称为一个样本;服务器指标数据、应用程序性能监控数据、网络数据等都是时序数据。
- 内置时间序列(Time Series)数据库:Prometheus ;外置的远端存储通常会用:InfluxDB、OpenTSDB 等。
- promQL 一种灵活的查询语言,可以利用多维数据完成复杂查询。
- 基于 HTTP 的 pull(拉取)方式采集时间序列数据(监控指标数据)。
- 同时支持 PushGateway 组件收集数据。
- 通过静态配置或服务发现发现目标。
- 支持作为数据源接入 Grafana 。
4. Prometheus 和 zabbix 区别
| 发行版本 | 开发语言 | 性能 | 社区支持 | 容器支持 | 企业使用 | 部署难度 | |
|---|---|---|---|---|---|---|---|
| Prometheus | 2016 | go | 支持万为单位 | 相对不如zabbix,但人数与日俱增 | 不仅支持swarmm原生集群,还支持Kubernetes容器集群解决方案,是目前容器监控最好解决方案。 | 基本上使用kubernetes与容器的企业,prometheus是最好的选择。 | 只有一个核心server组件,一条命令便可以启动 |
| zabbix | 2012 | c+php | 上限约10000节点 | 应用广泛,支持较成熟,遇到的问题都能搜索到 | Zabbix出现的比较早,当时容器还没有诞生,自然对容器的支持也比较差。 | 在传统监控系统中,尤其在服务器相关监控方面,占据绝对优势。 | 多种系统,多种监控信息采集方式。 |
5. Prometheus 的生态组件
Prometheus 负责时序型指标数据的采集及存储,但数据的分析、聚合及直观展示以及告警等功能并非由 Prometheus Server 所负责。
Prometheus 生态圈中包含了多个组件,其中部分组件可选:
5.1 Prometheus server
服务核心组件,采用 pull 方式采集监控数据,通过 http 协议传输;存储时间序列数据;基于“告警规则”生成告警通知。
Prometheus server 由三个部分组成:Retrieval,Storage,PromQL
- Retrieval:负责在活跃的 target 主机上抓取监控指标数据。
- Storage:存储,主要是把采集到的数据存储到磁盘中。默认为 15 天。
- PromQL:是 Prometheus 提供的查询语言模块。
5.2 Client Library
客户端库,目的在于为那些期望原生提供 Instrumentation 功能的应用程序提供便捷的开发途径,用于基于应用程序内建的测量系统。
5.3 Exporters
Exporters指标暴露器,负责收集不支持内建 Instrumentation 的应用程序或服务的性能指标数据,并通过 HTTP 接口供 Prometheus Server 获取。
换句话说,Exporter 负责从目标应用程序上采集和聚合原始格式的数据,并转换或聚合为 Prometheus 格式的指标向外暴露。
常用的 Exporters:
Node-Exporter:用于收集服务器节点的物理指标状态数据,如平均负载、CPU、内存、磁盘、网络等资源信息的指标数据,需要部署到所有运算节点。
指标详细介绍:https://github.com/prometheus/node_exporter
mysqld-exporter/nginx-exporter
Kube-State-Metrics:为 Prometheus 采集 K8S 资源数据的 exporter,通过监听 APIServer 收集 kubernetes 集群内资源对象的状态指标数据,例如 pod、deployment、service 等等。同时它也提供自己的数据,主要是资源采集个数和采集发生的异常次数统计。
需要注意的是 kube-state-metrics 只是简单的提供一个 metrics 数据,并不会存储这些指标数据,所以可以使用 Prometheus 来抓取这些数据然后存储, 主要关注的是业务相关的一些元数据,比如 Deployment、Pod、副本状态等;调度了多少个 replicas ?现在可用的有几个?多少个 Pod 是 running/stopped/terminated 状态?Pod 重启了多少次?有多少 job 在运行中。
cAdvisor:用来监控容器内部使用资源的信息,比如 CPU、内存、网络I/O、磁盘I/O 。
blackbox-exporter:监控业务容器存活性。
5.4 Service Discovery
服务发现,用于动态发现待监控的 Target,Prometheus 支持多种服务发现机制:文件、DNS、Consul、Kubernetes 等等。 服务发现可通过第三方提供的接口,Prometheus 查询到需要监控的 Target 列表,然后轮询这些 Target 获取监控数据。该组件目前由 Prometheus Server 内建支持
5.5 Alertmanager
Alertmanagers是一个独立的告警模块,从 Prometheus server 端接收到 “告警通知” 后,会进行去重、分组,并路由到相应的接收方,发出报警, 常见的接收方式有:电子邮件、钉钉、企业微信等。
Prometheus Server 仅负责生成告警指示,具体的告警行为由另一个独立的应用程序 AlertManager 负责;告警指示由 Prometheus Server 基于用户提供的告警规则周期性计算生成,Alertmanager 接收到 Prometheus Server 发来的告警指示后,基于用户定义的告警路由向告警接收人发送告警信息。
5.6 Pushgateway
类似一个中转站,Prometheus 的 server 端只会使用 pull 方式拉取数据,但是某些节点因为某些原因只能使用 push 方式推送数据, 那么它就是用来接收 push 而来的数据并暴露给 Prometheus 的 server 拉取的中转站。
可以理解成目标主机可以上报短期任务的数据到 Pushgateway,然后 Prometheus server 统一从 Pushgateway 拉取数据。
5.7 Grafana
Grafana是一个跨平台的开源的度量分析和可视化工具,可以将采集的数据可视化的展示,并及时通知给告警接收方。其官方库中具有丰富的仪表盘插件。
6. Prometheus 的工作模式
- Prometheus Server 基于服务发现(Service Discovery)机制或静态配置获取要监视的目标(Target),并通过每个目标上的指标 exporter 来采集(Scrape)指标数据;
- Prometheus Server 内置了一个基于文件的时间序列存储来持久存储指标数据,用户可使用 PromQL 接口来检索数据,也能够按需将告警需求发往 Alertmanager 完成告警内容发送;
- 一些短期运行的作业的生命周期过短,难以有效地将必要的指标数据供给到 Server 端,它们一般会采用推送(Push)方式输出指标数据, Prometheus 借助于 Pushgateway 接收这些推送的数据,进而由 Server 端进行抓取
7. Prometheus 的工作流程
(1)Prometheus 以 Prometheus Server 为核心,用于收集和存储时间序列数据。Prometheus Server 从监控目标中通过 pull 方式拉取指标数据,或通过 pushgateway 把采集的数据拉取到 Prometheus server 中。
(2)Prometheus server 把采集到的监控指标数据通过 TSDB 存储到本地 HDD/SSD 中。
(3)Prometheus 采集的监控指标数据按时间序列存储,通过配置报警规则,把触发的告警通知发送到 Alertmanager。
(4)Alertmanager 通过配置报警接收方,发送报警到邮件、钉钉或者企业微信等。
(5)Prometheus 自带的 Web UI 界面提供 PromQL 查询语言,可查询监控数据。
(6)Grafana 可接入 Prometheus 数据源,把监控数据以图形化形式展示出。

8. Prometheus 的局限性
- Prometheus 是一款指标监控系统,不适合存储事件及日志等;它更多地展示的是趋势性的监控,而非精准数据;
- Prometheus 认为只有最近的监控数据才有查询的需要,其本地存储的设计初衷只是保存短期(例如一个月)数据,因而不支持针对大量的历史数据进行存储;若需要存储长期的历史数据,建议基于远端存储机制将数据保存于 InfluxDB 或 OpenTSDB 等系统中;
- Prometheus 的集群机制成熟度不高,可基于 Thanos 或 Cortex 实现 Prometheus 集群的高可用及联邦集群。
二、部署配置及监控
1. 部署 Prometheus
Prometheust Server 端安装和相关配置
上传 prometheus-2.35.0.linux-amd64.tar.gz 到 /opt 目录中,并解压
systemctl stop firewalld
setenforce 0
cd /opt/
tar xf prometheus-2.45.0.linux-amd64.tar.gz
mv prometheus-2.35.0.linux-amd64 /usr/local/prometheus

cat /usr/local/prometheus/prometheus.yml | grep -v "^#"
global: #用于prometheus的全局配置,比如采集间隔,抓取超时时间等
scrape_interval: 15s #采集目标主机监控数据的时间间隔,默认为1m
evaluation_interval: 15s #触发告警生成alert的时间间隔,默认是1m
# scrape_timeout is set to the global default (10s).
scrape_timeout: 10s #数据采集超时时间,默认10s
alerting: #用于alertmanager实例的配置,支持静态配置和动态服务发现的机制
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
rule_files: #用于加载告警规则相关的文件路径的配置,可以使用文件名通配机制
# - "first_rules.yml"
# - "second_rules.yml"
scrape_configs: #用于采集时序数据源的配置
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus" #每个被监控实例的集合用job_name命名,支持静态配置(static_configs)和动态服务发现的机制(*_sd_configs)
# metrics_path defaults to '/metrics'
metrics_path: '/metrics' #指标数据采集路径,默认为 /metrics
# scheme defaults to 'http'.
static_configs: #静态目标配置,固定从某个target拉取数据
- targets: ["localhost:9090"]

配置系统启动文件,启动 Prometheust
cat > /usr/lib/systemd/system/prometheus.service <<'EOF'
[Unit]
Description=Prometheus Server
Documentation=https://prometheus.io
After=network.target
[Service]
Type=simple
ExecStart=/usr/local/prometheus/prometheus \
--config.file=/usr/local/prometheus/prometheus.yml \
--storage.tsdb.path=/usr/local/prometheus/data/ \
--storage.tsdb.retention=15d \
--web.enable-lifecycle
ExecReload=/bin/kill -HUP $MAINPID
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF

启动
systemctl start prometheus
systemctl enable prometheus
netstat -natp | grep :9090

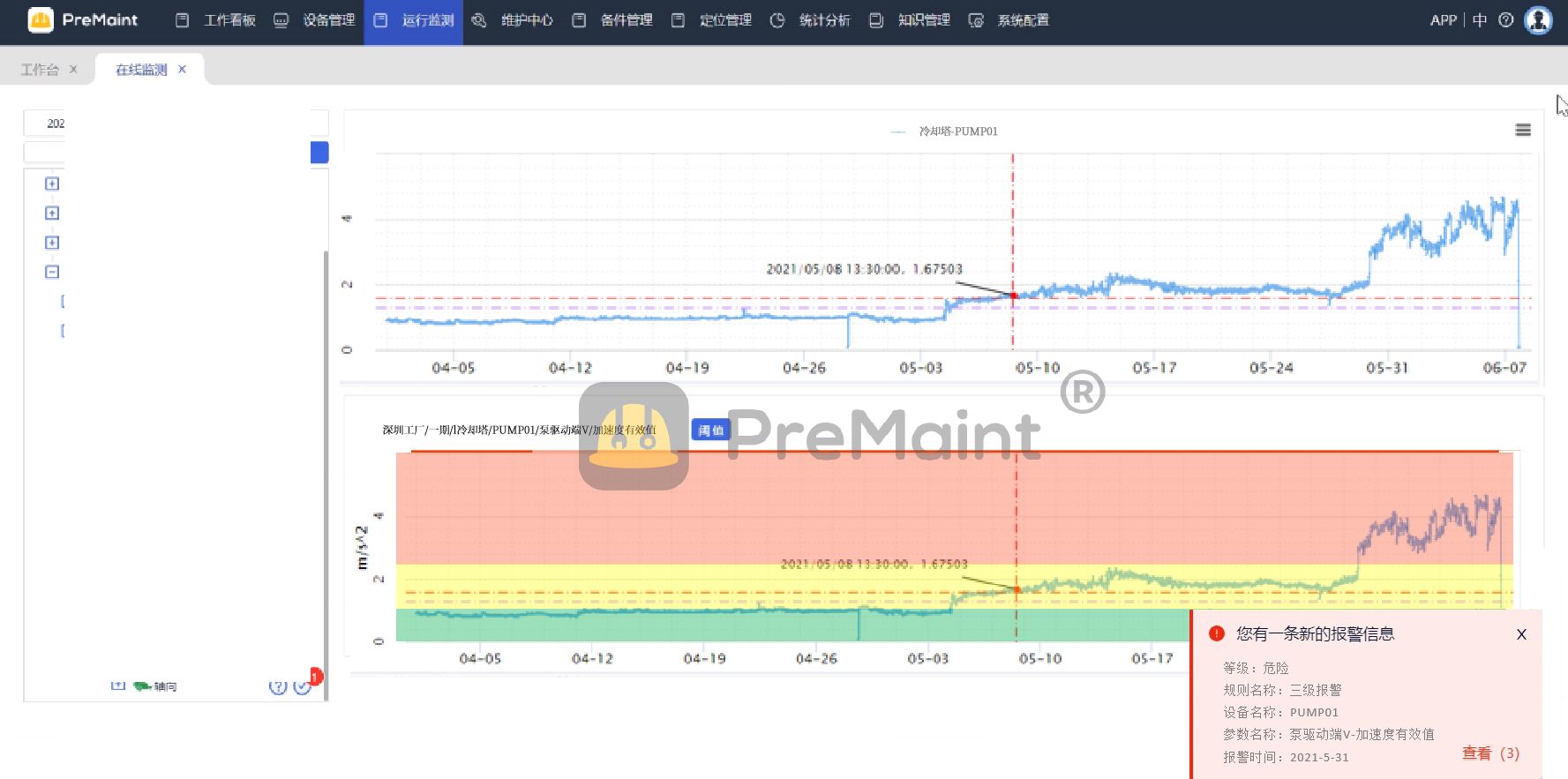
浏览器访问:http://192.168.145.14:9090 ,访问到 Prometheus 的 Web UI 界面
点击页面的 Status -> Targets,如看到 Target 状态都为 UP,说明 Prometheus 能正常采集到数据
http://192.168.145.14:9090/metrics ,可以看到 Prometheus 采集到自己的指标数据,其中 Help 字段用于解释当前指标的含义,Type 字段用于说明数据的类型


2. 部署 Exporters
上传 node_exporter-1.3.1.linux-amd64.tar.gz 到 /opt 目录中,并解压
cd /opt/
tar xf node_exporter-1.3.1.linux-amd64.tar.gz
mv node_exporter-1.3.1.linux-amd64/node_exporter /usr/local/bin

scp -r node_exporter 192.168.145.12:`pwd`
scp -r node_exporter 192.168.145.13:`pwd`

配置启动文件
cat > /usr/lib/systemd/system/node_exporter.service <<'EOF'
[Unit]
Description=node_exporter
Documentation=https://prometheus.io/
After=network.target
[Service]
Type=simple
ExecStart=/usr/local/bin/node_exporter \
--collector.ntp \
--collector.mountstats \
--collector.systemd \
--collector.tcpstat
ExecReload=/bin/kill -HUP $MAINPID
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF

启动
systemctl start node_exporter
systemctl enable node_exporter
netstat -natp | grep :9100

scp node_exporter.service 192.168.145.12:`pwd`
scp node_exporter.service 192.168.145.13:`pwd`

#node节点操作
systemctl start node_exporter
systemctl enable node_exporter
netstat -natp | grep :9100


浏览器访问:http://192.168.145.14:9100/metrics ,可以看到 Node Exporter 采集到的指标数据

常用的各指标:
node_cpu_seconds_totalnode_memory_MemTotal_bytesnode_filesystem_size_bytes{mount_point=PATH}node_system_unit_state{name=}node_vmstat_pswpin:系统每秒从磁盘读到内存的字节数node_vmstat_pswpout:系统每秒钟从内存写到磁盘的字节数
更多指标介绍:https://github.com/prometheus/node_exporter
修改 prometheus 配置文件,加入到 prometheus 监控中
vim /usr/local/prometheus/prometheus.yml
#在尾部增加如下内容
- job_name: nodes
metrics_path: "/metrics"
static_configs:
- targets:
- 192.168.145.14:9100
- 192.168.145.12:9100
- 192.168.145.13:9100
labels:
service: kubernetes

重新载入配置
curl -X POST http://192.168.145.14:9090/-/reload 或 systemctl reload prometheus
浏览器查看 Prometheus 页面的 Status -> Targets

3. 监控 MySQL 配置示例
3.1 在 MySQL 服务器上操作
上传 mysqld_exporter-0.14.0.linux-amd64.tar.gz 到 /opt 目录中,并解压
cd /opt/
tar xf mysqld_exporter-0.14.0.linux-amd64.tar.gz
mv mysqld_exporter-0.14.0.linux-amd64/mysqld_exporter /usr/local/bin/

配置启动文件
cat > /usr/lib/systemd/system/mysqld_exporter.service <<'EOF'
[Unit]
Description=mysqld_exporter
Documentation=https://prometheus.io/
After=network.target
[Service]
Type=simple
ExecStart=/usr/local/bin/mysqld_exporter --config.my-cnf=/etc/my.cnf
ExecReload=/bin/kill -HUP $MAINPID
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF

修改 MySQL 配置文件
vim /etc/my.cnf
[client]
......
host=localhost
user=exporter
password=abc123

授权 exporter 用户
mysql -uroot -pabc123
GRANT PROCESS, REPLICATION CLIENT, SELECT ON *.* TO 'exporter'@'localhost' IDENTIFIED BY 'abc123';

重启服务
systemctl restart mysqld
systemctl start mysqld_exporter
systemctl enable mysqld_exporter
netstat -natp | grep :9104

3.2 在 Prometheus 服务器上操作
修改 prometheus 配置文件,加入到 prometheus 监控中
vim /usr/local/prometheus/prometheus.yml
#在尾部增加如下内容
- job_name: mysqld
metrics_path: "/metrics"
static_configs:
- targets:
- 192.168.145.15:9104
labels:
service: mysqld

重新载入配置
curl -X POST http://192.168.80.30:9090/-/reload 或 systemctl reload prometheus
浏览器查看 Prometheus 页面的 Status -> Targets

4. 监控 Nginx 配置示例
4.1 在 Nginx 服务器上操作
下载 nginx-exporter 地址:https://github.com/hnlq715/nginx-vts-exporter/releases/download/v0.10.3/nginx-vts-exporter-0.10.3.linux-amd64.tar.gz
下载 nginx 地址:http://nginx.org/download/
下载 nginx 插件地址:https://github.com/vozlt/nginx-module-vts/tags
解压 nginx 插件
cd /opt
tar xf nginx-module-vts-0.1.18.tar.gz
mv nginx-module-vts-0.1.18 /usr/local/nginx-module-vts

安装 Nginx
yum -y install pcre-devel zlib-devel openssl-devel gcc gcc-c++ make
useradd -M -s /sbin/nologin nginx
cd /opt
tar xf nginx-1.24.0.tar.gz
cd nginx-1.24.0/
./configure --prefix=/usr/local/nginx \
--user=nginx \
--group=nginx \
--with-http_stub_status_module \
--with-http_ssl_module \
--add-module=/usr/local/nginx-module-vts
make & make install

修改 nginx 配置文件,启动 nginx
vim /usr/local/nginx/conf/nginx.conf
http {
vhost_traffic_status_zone; #添加
vhost_traffic_status_filter_by_host on; #添加,开启此功能,在 Nginx 配置有多个 server_name 的情况下,会根据不同的 server_name 进行流量的统计,否则默认会把流量全部计算到第一个 server_name 上
......
server {
......
}
server {
vhost_traffic_status off; #在不想统计流量的 server 区域,可禁用 vhost_traffic_status
listen 8080;
allow 127.0.0.1;
allow 192.168.145.14; #设置为 prometheus 的 ip 地址
location /nginx-status {
stub_status on;
access_log off;
}
location /status {
vhost_traffic_status_display;
vhost_traffic_status_display_format html;
}
}
}
#假如 nginx 没有规范配置 server_name 或者无需进行监控的 server 上,那么建议在此 vhost 上禁用统计监控功能。否则会出现 127.0.0.1、hostname 等的域名监控信息。

ln -s /usr/local/nginx/sbin/nginx /usr/local/sbin/
nginx -t
cat > /lib/systemd/system/nginx.service <<'EOF'
[Unit]
Description=nginx
After=network.target
[Service]
Type=forking
PIDFile=/usr/local/nginx/logs/nginx.pid
ExecStart=/usr/local/nginx/sbin/nginx
ExecReload=/bin/kill -s HUP $MAINPID
ExecStop=/bin/kill -s QUIT $MAINPID
PrivateTmp=true
[Install]
WantedBy=multi-user.target
EOF
systemctl start nginx
systemctl enable nginx

浏览器访问:http://192.168.145.16:8080/status ,可以看到 Nginx Vhost Traffic Status 的页面信息

解压 nginx-exporter,启动 nginx-exporter
cd /opt/
tar -zxvf nginx-vts-exporter-0.10.3.linux-amd64.tar.gz
mv nginx-vts-exporter-0.10.3.linux-amd64/nginx-vts-exporter /usr/local/bin/
cat > /usr/lib/systemd/system/nginx-exporter.service <<'EOF'
[Unit]
Description=nginx-exporter
Documentation=https://prometheus.io/
After=network.target
[Service]
Type=simple
ExecStart=/usr/local/bin/nginx-vts-exporter -nginx.scrape_uri=http://localhost:8080/status/format/json
ExecReload=/bin/kill -HUP $MAINPID
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
systemctl start nginx-exporter
systemctl enable nginx-exporter
netstat -natp | grep :9913

4.2 在 Prometheus 服务器上操作
修改 prometheus 配置文件,加入到 prometheus 监控中
vim /usr/local/prometheus/prometheus.yml
#在尾部增加如下内容
- job_name: nginx
metrics_path: "/metrics"
static_configs:
- targets:
- 192.168.145.16:9913
labels:
service: nginx

重新载入配置
curl -X POST http://192.168.80.30:9090/-/reload 或 systemctl reload prometheus
浏览器查看 Prometheus 页面的 Status -> Targets

总结
1. 常用监控系统
老牌传统的:Zabbix Nagios Cacti
新一代的:Prometheus 夜莺
2. Zabbix 和 Prometheus 的区别? 如何选择?
Zabbix:更适用于传统业务架构的物理机、虚拟机环境的监控,对容器环境的支持较差;
主要采用的是关系型数据库,会随着监控的节点数量增加,数据库的压力也会变大,监控数据的查询会变得很慢;
比Prometheus更弱一些,支持的集群规模通常在2000节点以内。
Prometheus:支持kubernetes容器集群的监控,是目前容器监控最好的解决方案;
采用时序数据库,大大的节省了存储空间,并且提升了查询效率;
支持的监控集群规模更大,通常超过2000哥节点的检控官建议直接选择Prometheus。
3. Prometheus 的概念
Prometheus 是一个开源的监控系统/时间序列数据库,数据模型是 度量名称{键值对标识} 的时间序列数据格式
4. Prometheus 的生态组件
1)prometheus server:Prometheus服务的核心组件;通过http pull拉取的方式采集监控指标数据(时间序列数据);作为时序数据库持久化存储监控指标数据;
根据告警规则生成告警通知发送给alertmanager;内建service discovery动态服务发现功能(支持文件、DNS、consul、K8S等自动发现方式)
2)exporter:指标暴露器,用于在原生不支持prometheus直接采集监控指标数据的系统或应用中收集监控指标数据并转换格式暴露端口给proetheus server拉取采集
node-exporter、kube-state-metrics、cADvisor、blackbox-exporter、nginx/mysqld/redis-exporter
3)alertmanager:接收prometheus server发来的告警通知,负责对告警通知去重、分组,并路由给接收人(邮件、钉钉、企业微信等方式)
4)pushgateway:作为中转站,接收一些短时任务或只会推送数据的任务发来的监控指标数据,用于临时存储指标数据并统一给proetheus server拉取采集
5)grafana:外置的监控数据展示平台,通过实验promQL查询prometheus的数据源,以图形化形式展示
5. Prometheus 工作过程
1)prometheus server通过http pull的方式从target监控目标(exporter/pushgateway暴露的端口)拉取监控指标数据
2)prometheus server将采集到的监控指标数据通过时序数据库持久化存储在本地磁盘或者外置存储中
3)prometheus server将采集到的监控指标数据跟本地配置的告警规则进行比对,会把触发的告警通知发送给alertmanager
4)alertmanager配置报警路由,可通过邮件/钉钉/企业微信等方法发送给接收人
5)prometheus支持是原生的web UI或grafana通过promQL查询prometheus的数据源,以图形化形式展示
prometheus 支持使用 influxdb/openTSDB 作为远程外置存储,实现存储长期的历史数据
prometheus 可基于 thanos 实现 prometheus 集群的高可用(在K8S上部署,通过边车模式与prometheus部署在同一个Pod里共享存储数据
6. Prometheus 数据采集配置
scrape_configs:
- job_name: #定义监控任务的名称
metrics_path: #指定获取监控指标数据的路径,一般为 /metrics
scheme: #指定连接监控目标的协议,http 或 https
static_configs: #定义静态配置的监控目标
- targets:
- <IP1>:<EXPORTER_PORT>
- <IP2>:<EXPORTER_PORT>
![[oneAPI] 基于BERT预训练模型的英文文本蕴含任务](https://img-blog.csdnimg.cn/4affc2f77e684260aeedb0e0a5e1d888.png)