文章目录
- 论文详解 (High-Resolution Networks)
- Parallel Multi-Resolution Convolutions
- Repeated Multi-Resolution Fusions
- Representation Head
- 代码详解
论文:《Deep High-Resolution Representation Learning for Visual Recognition》
代码:https://github.com/HRNet.
论文详解 (High-Resolution Networks)
如下图所示,HRnet (High-Resolution Networks)由几个组件组成,包括:并行多分辨率卷积(parallel multi-resolution convolutions),重复多分辨率融合(repeated multi-resolution fusions),以及表示头(representation head)。
Parallel Multi-Resolution Convolutions
我们从一个高分辨率的卷积流作为第一阶段,逐步将高分辨率到低分辨率的流逐个添加,形成新的阶段,并将多分辨率流并行连接。因此,后一阶段并行流的分辨率由前一阶段的分辨率和一个更低的分辨率组成。
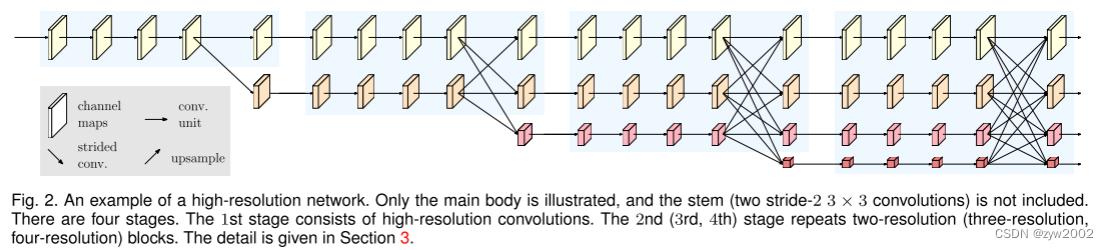
如图2所示的一个网络结构示例,包含4个并行流,逻辑如下:
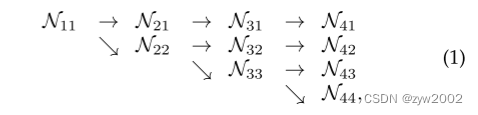
其中
N
s
r
N_{sr}
Nsr是一个在第
s
s
s个阶段,第
r
r
r 个resolution 的 sub-stream。
第一个stream的resolution index 是1,resolution index为 r r r的分辨率是
第一个stream分辨率的 1 2 r − 1 \frac{1}{2^{r-1}} 2r−11 倍。
Repeated Multi-Resolution Fusions
融合模块的目标是在多分辨率表示之间交换信息。融合模块重复几次(例如,每4个residual units 就重复一次)。

让我们看一个融合3-resolution representations的例子,如图3所示。融合2个representations 和4个representations 是很容易得到的。输入由三种representations组成: { R r i , r = 1 , 2 , 3 } \{R_r^i, r=1,2,3\} {Rri,r=1,2,3} ,其中 r r r是resolution index, 相应的output representations 是 { R r o , r = 1 , 2 , 3 } \{R_r^o,r =1,2,3\} {Rro,r=1,2,3}。每个输出表示都是三个输入的转换表示的和: R r o = f 1 r ( R 1 i ) + f 2 r ( R 2 i ) + f 3 r ( R 3 i ) \mathbf{R}_r^o=f_{1 r}\left(\mathbf{R}_1^i\right)+f_{2 r}\left(\mathbf{R}_2^i\right)+f_{3 r}\left(\mathbf{R}_3^i\right) Rro=f1r(R1i)+f2r(R2i)+f3r(R3i)。 跨阶段(从阶段3到阶段4)的融合有一个额外的输出: R 4 o = f 14 ( R 1 i ) + f 24 ( R 2 i ) + f 34 ( R 3 i ) \mathbf{R}_4^o=f_{14}\left(\mathbf{R}_1^i\right)+f_{24}\left(\mathbf{R}_2^i\right)+f_{34}\left(\mathbf{R}_3^i\right) R4o=f14(R1i)+f24(R2i)+f34(R3i)。
变换函数 f x r ( . ) f_{xr}(.) fxr(.)的选择取决于输入分辨率指数 x x x和输出分辨率指数 r r r。如果 x = r , f x r ( R ) = R x=r,f_{xr}(R)=R x=r,fxr(R)=R。
如果 x < r , f x r ( R ) x<r,f_{xr}(R) x<r,fxr(R) 对输入的representations R R R 通过 r − x r-x r−x个stride=2的3x3的卷积进行下采样。
如果 x > r x>r x>r, f x r ( R ) f_{xr}(R) fxr(R)通过bilinear upsampling进行上采样,并连接着一个1x1的卷积对通道数进行对齐。
Representation Head
我们有三种representations head,如图4所示,分别称为HRNetV1、HRNetV2和HRNetV1p。
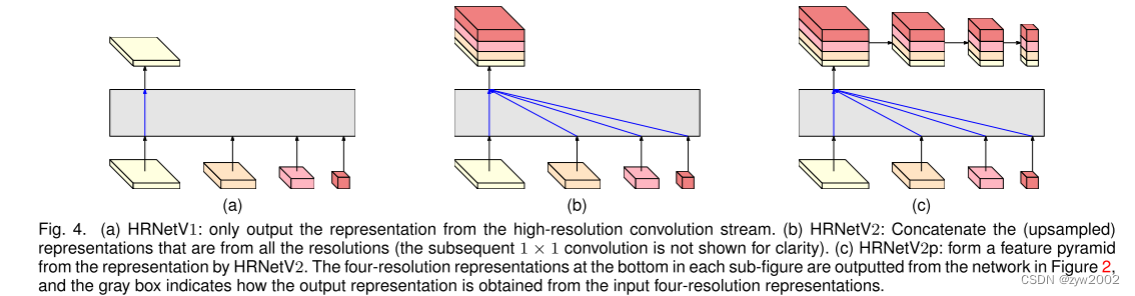
- HRNetV1
输出仅是来自high-resolution stream的表示。其他三个表示将被忽略。如图4 (a)所示。
- HRNetV2
我们通过bilinear upsampling对低分辨率表示进行缩放,而不改变高分辨率的通道数,并将四种表示连接起来,然后进行1 × 1卷积来混合这四种表示。如图4 (b)所示。
- HRNetV2p
我们通过将HRNetV2的高分辨率表示输出向下采样到多个级别来构建多级表示。图4 ©描述了这一点。
在本文中,我们将展示HRNetV1用于人体姿态估计,HRNetV2用于语义分割,HRNetV2p用于目标检测的结果。
代码详解
描述网络结构的核心代码文件在lib/models/seg_hrnet.py 文件中。
下面将详细解读该文件中的代码。
conv3x3
定义了一个3x3的卷积,当stride=1时,输出大小不变。
def conv3x3(in_planes, out_planes, stride=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1, bias=False) # 当stride默认为1时,输出大小不变
BasicBlock
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.relu = nn.ReLU(inplace=relu_inplace)
self.conv2 = conv3x3(planes, planes)
self.bn2 = BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.downsample = downsample
self.stride = stride
def forward(self, x): # x: [b,inplanes,h,w]
residual = x
out = self.conv1(x) # [b,planes,h,w] 3x3,stride=?,大小可能改变
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out) # [b,planes,h,w] 3x3 stride=1, 大小不变
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x) # 可能进行下采样操作
out = out + residual # 残差连接
out = self.relu(out)
return out
Bottleneck
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn2 = BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.conv3 = nn.Conv2d(planes, planes * self.expansion, kernel_size=1,
bias=False)
self.bn3 = BatchNorm2d(planes * self.expansion,
momentum=BN_MOMENTUM)
self.relu = nn.ReLU(inplace=relu_inplace)
self.downsample = downsample
self.stride = stride
def forward(self, x): # x: [b,inplanes,h,w]
residual = x
out = self.conv1(x) # [b,planes,h,w] 1x1 大小不变
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)# [b,planes,h,w] 3x3,stride=? 大小可能改变
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)# [b,planes*expansion,h,w] 1x1 大小不变
out = self.bn3(out)
if self.downsample is not None: # 可能进行下采样
residual = self.downsample(x)
out = out + residual # 残差连接
out = self.relu(out)
return out
blocks_dict = {
'BASIC': BasicBlock,
'BOTTLENECK': Bottleneck
}
HighResolutionModule
# 多分辨率模块
class HighResolutionModule(nn.Module):
def __init__(self, num_branches, blocks, num_blocks, num_inchannels,
num_channels, fuse_method, multi_scale_output=True):
super(HighResolutionModule, self).__init__()
# 首先检查分支数量是否正确
self._check_branches(
num_branches, blocks, num_blocks, num_inchannels, num_channels)
self.num_inchannels = num_inchannels
self.fuse_method = fuse_method
self.num_branches = num_branches
self.multi_scale_output = multi_scale_output
# 创建分支
self.branches = self._make_branches(
num_branches, blocks, num_blocks, num_channels)
# 创建融合层
self.fuse_layers = self._make_fuse_layers()
self.relu = nn.ReLU(inplace=relu_inplace)
# 检查分支数是否和num_blocks、num_channels、num_inchannels 数量相等,如果不等则报错
def _check_branches(self, num_branches, blocks, num_blocks,
num_inchannels, num_channels):
if num_branches != len(num_blocks):
error_msg = 'NUM_BRANCHES({}) <> NUM_BLOCKS({})'.format(
num_branches, len(num_blocks))
logger.error(error_msg)
raise ValueError(error_msg)
if num_branches != len(num_channels):
error_msg = 'NUM_BRANCHES({}) <> NUM_CHANNELS({})'.format(
num_branches, len(num_channels))
logger.error(error_msg)
raise ValueError(error_msg)
if num_branches != len(num_inchannels):
error_msg = 'NUM_BRANCHES({}) <> NUM_INCHANNELS({})'.format(
num_branches, len(num_inchannels))
logger.error(error_msg)
raise ValueError(error_msg)
'''
功能: 创建一个分支
branch_index: 分支的索引
block: 基本卷积模块
num_block: 一个列表,num_block[branch_index]表示当前分支的block个数
num_channels: 一个列表,num_channels[branch_index] 表示当前分支的输出通道数
num_inchannels: 一个列表,num_inchannles[branch_index] 表示当前分支的输入通道数
'''
def _make_one_branch(self, branch_index, block, num_blocks, num_channels,
stride=1):
downsample = None
# 如果步长不为1 或者 输入通道数不等于扩张后的通道数
if stride != 1 or \
self.num_inchannels[branch_index] != num_channels[branch_index] * block.expansion:
# 定义降采样
downsample = nn.Sequential(
# 1x1的卷积扩张通道数
# 通道数:num_inchannels[branch_index]->num_channels[branch_index] * block.expansion
nn.Conv2d(self.num_inchannels[branch_index],
num_channels[branch_index] * block.expansion,
kernel_size=1, stride=stride, bias=False),
# BN
BatchNorm2d(num_channels[branch_index] * block.expansion,
momentum=BN_MOMENTUM),
)
# 在Layers中添加一个Block (有刚才定义的downsample)
layers = []
layers.append(block(self.num_inchannels[branch_index],
num_channels[branch_index], stride, downsample))
# 更新:当前分支的 输入通道数=输出通道数*expansion
self.num_inchannels[branch_index] = \
num_channels[branch_index] * block.expansion
# 遍历当前分支的所有block, 并添加到layers中
for i in range(1, num_blocks[branch_index]):
layers.append(block(self.num_inchannels[branch_index],
num_channels[branch_index]))
return nn.Sequential(*layers) # 返回新创建分支的所有layers
# 创建所有的分支
def _make_branches(self, num_branches, block, num_blocks, num_channels):
branches = []
# 创建num_branches 个分支
for i in range(num_branches):
branches.append(
self._make_one_branch(i, block, num_blocks, num_channels))
return nn.ModuleList(branches)
# 返回一个ModelList,包含num_branches个分支,每个分支又包含num_block个模块
# 创建一个fuse层
def _make_fuse_layers(self):
# 如果分支数是1,则不需要进行融合
if self.num_branches == 1:
return None
num_branches = self.num_branches
num_inchannels = self.num_inchannels
fuse_layers = []
# 如果是多尺度的输出,则遍历num_branches个。否则遍历1次。
# i 表示输出分辨率 r
for i in range(num_branches if self.multi_scale_output else 1):
fuse_layer = []
# j表示输入分辨率 x
for j in range(num_branches):
# 如果输入分辨率x大于输出分辨率r
if j > i:
fuse_layer.append(nn.Sequential(
# 1x1的卷积,将通道数变成 输出分辨率的通道数
nn.Conv2d(num_inchannels[j],
num_inchannels[i],
1,
1,
0,
bias=False),
# BN
BatchNorm2d(num_inchannels[i], momentum=BN_MOMENTUM)))
# 如果输入分辨率x等于输出分辨率r
elif j == i:
fuse_layer.append(None) # 则不做任何操作,恒等映射
# 如果输入分辨率x小于输出分辨率r
else:
conv3x3s = [] # 3x3的卷积
for k in range(i-j): # 则通过r-x个 stride=2 的3x3的卷积
if k == i - j - 1: # 如果是最后一个3x3的卷积
num_outchannels_conv3x3 = num_inchannels[i] # 则输出通道数等于输出分辨率的通道数
conv3x3s.append(nn.Sequential(
# 3x3, stride=2,pad =1 大小缩小2倍
nn.Conv2d(num_inchannels[j],
num_outchannels_conv3x3,
3, 2, 1, bias=False),
# BN
BatchNorm2d(num_outchannels_conv3x3,
momentum=BN_MOMENTUM)))
else: # 如果不是最后一个3x3的卷积
num_outchannels_conv3x3 = num_inchannels[j] # 则输出通道数是输入分辨率的通道数
conv3x3s.append(nn.Sequential(
# 3x3, stride=2,pad =1 大小缩小2倍
nn.Conv2d(num_inchannels[j],
num_outchannels_conv3x3,
3, 2, 1, bias=False),
# BN
BatchNorm2d(num_outchannels_conv3x3,
momentum=BN_MOMENTUM),
nn.ReLU(inplace=relu_inplace)))
fuse_layer.append(nn.Sequential(*conv3x3s))
fuse_layers.append(nn.ModuleList(fuse_layer))
return nn.ModuleList(fuse_layers)
def get_num_inchannels(self): # 获取输入通道数
return self.num_inchannels
def forward(self, x): # 前向传播
# 如果只有一个分支
if self.num_branches == 1:
return [self.branches[0](x[0])]
# 如果有多个分支
for i in range(self.num_branches):
x[i] = self.branches[i](x[i]) # 把x[i] 输入到第i个分支中
# 得到的x[i]分别是i个分支的输出
x_fuse = []
# i 表示输出分辨率的index
for i in range(len(self.fuse_layers)): # 遍历所有的fuse_layer
# 初始化:对于输出分辨率i的输出 y
# 用输入分辨率索引为0进行初始化 x[0]/fuse_layers[i][0](x[0])
# 这样做的目的是因为多个分支的输出是相加的
y = x[0] if i == 0 else self.fuse_layers[i][0](x[0])
# j: 表示输入分辨率的index
for j in range(1, self.num_branches):
# 如果输入分辨率=输出分辨率,则直接进行恒等映射
if i == j:
y = y + x[j]
# 输入分辨率 < 输出分辨率 (分辨率index大的,实际的图片分辨率小)
elif j > i:
width_output = x[i].shape[-1] # 输出分辨率的宽
height_output = x[i].shape[-2] # 输出分辨率的高
y = y + F.interpolate( # interpolate 上采样
self.fuse_layers[i][j](x[j]), # 1x1的卷积改变通道数
size=[height_output, width_output],
mode='bilinear', align_corners=ALIGN_CORNERS)
# 输入分辨率 > 输出分辨率
else:
y = y + self.fuse_layers[i][j](x[j]) # 3x3的卷积,stride=2 进行降采样
x_fuse.append(self.relu(y))
return x_fuse
HighResolutionNet
# 多分辨率网络
class HighResolutionNet(nn.Module):
def __init__(self, config, **kwargs):
global ALIGN_CORNERS
extra = config.MODEL.EXTRA
super(HighResolutionNet, self).__init__()
ALIGN_CORNERS = config.MODEL.ALIGN_CORNERS
# stem net
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=2, padding=1,
bias=False)
self.bn1 = BatchNorm2d(64, momentum=BN_MOMENTUM)
self.conv2 = nn.Conv2d(64, 64, kernel_size=3, stride=2, padding=1,
bias=False)
self.bn2 = BatchNorm2d(64, momentum=BN_MOMENTUM)
self.relu = nn.ReLU(inplace=relu_inplace)
# 以HRNet48中的数据为例子
'''stage 1'''
self.stage1_cfg = extra['STAGE1']
num_channels = self.stage1_cfg['NUM_CHANNELS'][0] # 输出通道数 64
block = blocks_dict[self.stage1_cfg['BLOCK']] # BottleNeck
num_blocks = self.stage1_cfg['NUM_BLOCKS'][0] # 4
# Bottleneck, in_ch=64, out_ch= 64, numblocks=4, stride=1
self.layer1 = self._make_layer(block, 64, num_channels, num_blocks) # [b,4*64,h,w]
stage1_out_channel = block.expansion*num_channels # 64*4
'''stage 2'''
self.stage2_cfg = extra['STAGE2']
num_channels = self.stage2_cfg['NUM_CHANNELS'] # [48, 96]
block = blocks_dict[self.stage2_cfg['BLOCK']] # Basic
num_channels = [
num_channels[i] * block.expansion for i in range(len(num_channels))]
# num_channels=[48*4,96*4]
self.transition1 = self._make_transition_layer(
[stage1_out_channel], num_channels) # (64*4,[48*4,96*4])
self.stage2, pre_stage_channels = self._make_stage(
self.stage2_cfg, num_channels)
'''stage 3'''
self.stage3_cfg = extra['STAGE3']
num_channels = self.stage3_cfg['NUM_CHANNELS']
block = blocks_dict[self.stage3_cfg['BLOCK']]
num_channels = [
num_channels[i] * block.expansion for i in range(len(num_channels))]
self.transition2 = self._make_transition_layer(
pre_stage_channels, num_channels)
self.stage3, pre_stage_channels = self._make_stage(
self.stage3_cfg, num_channels)
'''stage 4'''
self.stage4_cfg = extra['STAGE4']
num_channels = self.stage4_cfg['NUM_CHANNELS']
block = blocks_dict[self.stage4_cfg['BLOCK']]
num_channels = [
num_channels[i] * block.expansion for i in range(len(num_channels))]
self.transition3 = self._make_transition_layer(
pre_stage_channels, num_channels)
self.stage4, pre_stage_channels = self._make_stage(
self.stage4_cfg, num_channels, multi_scale_output=True)
last_inp_channels = np.int(np.sum(pre_stage_channels))
self.last_layer = nn.Sequential(
# 1x1 stride=1 大小不变
nn.Conv2d(
in_channels=last_inp_channels,
out_channels=last_inp_channels,
kernel_size=1,
stride=1,
padding=0),
BatchNorm2d(last_inp_channels, momentum=BN_MOMENTUM),
nn.ReLU(inplace=relu_inplace),
nn.Conv2d(
in_channels=last_inp_channels,
out_channels=config.DATASET.NUM_CLASSES,
kernel_size=extra.FINAL_CONV_KERNEL,
stride=1,
padding=1 if extra.FINAL_CONV_KERNEL == 3 else 0)
)
'''
功能: 生成转换层
num_channels_pre_layer: 上一层的通道数的列表
num_channels_cur_layer: 当前层的通道数的列表
'''
def _make_transition_layer(
self, num_channels_pre_layer, num_channels_cur_layer):
num_branches_cur = len(num_channels_cur_layer) # 当前层的分支数
num_branches_pre = len(num_channels_pre_layer) # 上一层的分支数
transition_layers = []
# i: 当前层的分支索引
for i in range(num_branches_cur):
# 当前层的分支索引<= 上一层的分支数
if i < num_branches_pre:
# 对于相同分支:当前层通道数和上一层的通道数不相等
if num_channels_cur_layer[i] != num_channels_pre_layer[i]:
transition_layers.append(nn.Sequential(
# 转换通道数,大小不变
nn.Conv2d(num_channels_pre_layer[i],
num_channels_cur_layer[i],
3,
1,
1,
bias=False),
BatchNorm2d(
num_channels_cur_layer[i], momentum=BN_MOMENTUM),
nn.ReLU(inplace=relu_inplace)))
# 对于相同分支:当前层通道数和上一层的通道数相等
else:
transition_layers.append(None) # 则不需要转换,直接映射
# 当前层的分支索引(i)> 上一层的分支数(num_branches_pre)
else:
conv3x3s = []
for j in range(i+1-num_branches_pre): # j:[0,1,...,i-num_branches_pre]
# 输入通道是上一层最后一个分支的输出通道
inchannels = num_channels_pre_layer[-1]
# 输出通道是当前层的输出通道
outchannels = num_channels_cur_layer[i] \
if j == i-num_branches_pre else inchannels
conv3x3s.append(nn.Sequential(
# stride=2 大小变小
nn.Conv2d(
inchannels, outchannels, 3, 2, 1, bias=False),
BatchNorm2d(outchannels, momentum=BN_MOMENTUM),
nn.ReLU(inplace=relu_inplace)))
transition_layers.append(nn.Sequential(*conv3x3s))
return nn.ModuleList(transition_layers)
'''
功能: 创建一个分支
block : 类型 例如Bottleneck(expansion =4) 或 BasicBlock(expansion =1)
inplanes: 输入通道数
planes: 输出通道数
blocks: block的个数
'''
def _make_layer(self, block, inplanes, planes, blocks, stride=1):
downsample = None
# 定义降采样
# 如果stride 不为1 或者 输入通道数 不等于 输出通道数*扩张率
if stride != 1 or inplanes != planes * block.expansion:
downsample = nn.Sequential(
# 通过1x1的卷积改变通道数
# 通过stride 改变大小
nn.Conv2d(inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
BatchNorm2d(planes * block.expansion, momentum=BN_MOMENTUM),
)
layers = []
layers.append(block(inplanes, planes, stride, downsample))
'''
当stride不为1时:
========
如果block的类型是Basic Block: (expansion = 1)
-------第一个block
输入x: [b,inplanes,h,w]
conv1 (3x3,stride=?,out_ch=planes) 输出大小可能改变
conv2 (3x3,stride=1,out_ch=planes) 输出大小不变
downsample(x) :
Conv2d (1x1, stride=? out_ch=planes) 输出大小可能改变
输出y=conv2 + downspaple(x)
大小:根据stride变化
通道数:planes
--------剩下的block
inplanes变成planes
然后通过(blocks-1)个block
大小:stride=1 不变
通道数:planes
*******总结
大小:根据stride变化
通道数:planes
========
如果block的类型是BottleNeck: (expension =4 )
--------第一个Block
输入x: [b,inplanes,h,w]
conv1 (1x1,stride=1,out_ch=planes) 大小不变
conv2 (3x3,stride=?,out_ch=planes) 大小可能改变
conv3 (1x1,stride=1,out_ch=planes*expansion) 大小不变
downsample (x):
Conv2d (1x1, stride=? out_ch=planes*expansion) 输出大小可能改变
输出y=conv3 + downspaple(x)
大小:根据stride 变化
通道:planes*expansion
--------剩下的Block
inplanes变成planes*expansion
然后通过(blocks-1)个block ,对于每一个block
stride=1 -> 大小固定不变
通道数:planes * expansion =4* planes
********总结
大小:根据stride变化
通道数:planes*expansion
'''
inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(inplanes, planes))
return nn.Sequential(*layers)
'''
功能: 创建一个stage
'''
def _make_stage(self, layer_config, num_inchannels,
multi_scale_output=True):
num_modules = layer_config['NUM_MODULES']
num_branches = layer_config['NUM_BRANCHES']
num_blocks = layer_config['NUM_BLOCKS']
num_channels = layer_config['NUM_CHANNELS']
block = blocks_dict[layer_config['BLOCK']]
fuse_method = layer_config['FUSE_METHOD']
modules = []
# 4个stage的modules的数量分别是:1,1,4,3
for i in range(num_modules):
# 只在最后一个module中使用multi_scale_output
if not multi_scale_output and i == num_modules - 1:
reset_multi_scale_output = False
else:
reset_multi_scale_output = True
# 每一个module中都是一个 HighResolutionModule
modules.append(
HighResolutionModule(num_branches,
block,
num_blocks,
num_inchannels,
num_channels,
fuse_method,
reset_multi_scale_output)
)
num_inchannels = modules[-1].get_num_inchannels() # 当前模型的输入通道数
return nn.Sequential(*modules), num_inchannels
def forward(self, x): # x: [b,3,h,w]
x = self.conv1(x) # x: [b,64,h/2,w/2]
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(x) # x: [b,64,h/4,w/4]
x = self.bn2(x)
x = self.relu(x)
'''stage 1'''
x = self.layer1(x)
'''stage 2'''
x_list = []
for i in range(self.stage2_cfg['NUM_BRANCHES']): # 2个分支
if self.transition1[i] is not None:
x_list.append(self.transition1[i](x)) # 首先创建transition 层
else:
x_list.append(x)
y_list = self.stage2(x_list) # 输入transitino 层,生成一个stage
'''stage 3'''
x_list = []
for i in range(self.stage3_cfg['NUM_BRANCHES']): # 3个分支
if self.transition2[i] is not None:
if i < self.stage2_cfg['NUM_BRANCHES']: # 如果当前阶段分支index < 上一阶段的分支数
x_list.append(self.transition2[i](y_list[i])) # 输入transition的是上一个stage的对应分支的输出
else:
x_list.append(self.transition2[i](y_list[-1])) # 输入transition的是上一个stage的最后一个分支的输出
else:
x_list.append(y_list[i])
y_list = self.stage3(x_list)
'''stage 4'''
x_list = []
for i in range(self.stage4_cfg['NUM_BRANCHES']): # 4个分支
if self.transition3[i] is not None:
if i < self.stage3_cfg['NUM_BRANCHES']: # 如果当前阶段分支index < 上一阶段的分支数
x_list.append(self.transition3[i](y_list[i]))# 输入transition的是上一个stage的对应分支的输出
else:
x_list.append(self.transition3[i](y_list[-1]))# 输入transition的是上一个stage的最后一个分支的输出
else:
x_list.append(y_list[i])
x = self.stage4(x_list)
# Upsampling
x0_h, x0_w = x[0].size(2), x[0].size(3) # stage 4 输出的第1个branch的宽高
# 然后将stage 4 输出的第2,3,4个branch的宽高都上采样到相同的大小
x1 = F.interpolate(x[1], size=(x0_h, x0_w), mode='bilinear', align_corners=ALIGN_CORNERS)
x2 = F.interpolate(x[2], size=(x0_h, x0_w), mode='bilinear', align_corners=ALIGN_CORNERS)
x3 = F.interpolate(x[3], size=(x0_h, x0_w), mode='bilinear', align_corners=ALIGN_CORNERS)
# 在通道维度上进行连接
x = torch.cat([x[0], x1, x2, x3], 1)
x = self.last_layer(x)
return x
# 初始化权重
def init_weights(self, pretrained='',):
logger.info('=> init weights from normal distribution')
# 用随机生成的数初始化
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.normal_(m.weight, std=0.001)
elif isinstance(m, BatchNorm2d_class):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# 采用预训练权重初始化
if os.path.isfile(pretrained):
pretrained_dict = torch.load(pretrained)
logger.info('=> loading pretrained model {}'.format(pretrained))
model_dict = self.state_dict()
pretrained_dict = {k: v for k, v in pretrained_dict.items()
if k in model_dict.keys()}
for k, _ in pretrained_dict.items():
logger.info(
'=> loading {} pretrained model {}'.format(k, pretrained))
model_dict.update(pretrained_dict)
self.load_state_dict(model_dict)
get_seg_model
# 获取分割的模型
def get_seg_model(cfg, **kwargs):
model = HighResolutionNet(cfg, **kwargs) # 定义模型
model.init_weights(cfg.MODEL.PRETRAINED) # 初始化权重
return model