CAS
CAS(Compare And Swap,比较交换)指的是对于一个变量,比较它的内存的值与期望值是否相同,如果相同则将内存值修改为新的指定的值。即CAS包括两个步骤:1.比较内存值与期望值是否相同;2.相同则赋予新值,使用伪代码实现如下:
if(value == expectedValue) {
value = newValue;
}CAS可以看作是这两个步骤的原子操作,并且原子性是在硬件层面得到保障的。CAS可以看作是一种乐观锁的实现,使用CAS时不会加锁,而是假设没有冲突去完成,发生冲突就不断重试直到成功。
Java中的CAS
Java中的CAS是由Unsafe类提供的,它按照类型提供了三种CAS操作。
//Object
public final native boolean compareAndSwapObject(java.lang.Object o, long l, java.lang.Object o1, java.lang.Object o2);
//Int
public final native boolean compareAndSwapInt(java.lang.Object o, long l, int i, int i1);
//Long
public final native boolean compareAndSwapLong(java.lang.Object o, long l, long l1, long l2);这三个方法都是native的,即具体是在JVM中实现的,不同虚拟机的实现可能会不同,这很容易理解,因为CAS在操作系统中是一个原子指令,不同操作系统的指令也不同。
需要注意的是,Unsafe类的构造函数是私有的,即不能通过new关键字的方式创建对象;它提供了一个getUnsafe()方法,返回值是Unsafe()对象,但该方法是提供给Java API使用的,我们使用此方法获取Unsafe对象,会报SecurityException错误。
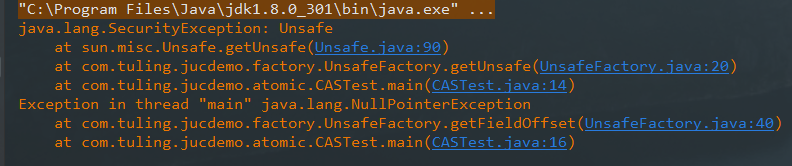
但我们可以通过反射来获取Unsafe类的对象,如下:
public static Unsafe getUnsafe() {
try {
Field field = Unsafe.class.getDeclaredField("theUnsafe");
field.setAccessible(true);
return (Unsafe) field.get(null);
} catch (Exception e) {
e.printStackTrace();
}
return null;
}下面以compareAndSwapInt()方法举例介绍,该方法的参数分别表示要替换的对象实例、要替换的字段在对象中的内存偏移量、字段的期望值、字段的新值。首先使用CAS设置User类的age字段的值为3,随后判断该值如果为3则再将age设置为5,最后判断该值如果为3则设置为8。User类定义如下:
public class User {
private int num;
private int age;
private String name;
}测试代码如下:
public static void main(String[] args) {
User user = new User();
Unsafe unsafe = UnsafeFactory.getUnsafe();
boolean successful;
// 4个参数分别是:对象实例、字段的内存偏移量、字段期望值、字段更新值
successful = unsafe.compareAndSwapInt(user, 16, 0, 3);
System.out.println(successful + "\t" + user.getAge());
successful = unsafe.compareAndSwapInt(user, 16, 3, 5);
System.out.println(successful + "\t" + user.getAge());
successful = unsafe.compareAndSwapInt(user, 16, 3, 8);
System.out.println(successful + "\t" + user.getAge());
}其中字段内存偏移量是16,原因是User对象头中的Markword占8个字节,Klass Pointer占4个字节(指针压缩),User对象的num是int类型的占4个字节,我们要修改的age就是从User对象的第16个字节开始的。
程序执行结果如下:

CAS虽然高效地解决了原子操作,但也存在以下缺陷:
- 自旋CAS长时间不成功,会给CPU带来很大开销;
- 只能保证一个共享变量的原子操作;
- ABA问题。
ABA问题
ABA问题指的是当有多个线程对一个原子类进行操作的时候,某个线程在短时间内将原子类的值A修改为B,随后又将其修改为A,这个过程对于其他线程是感知不到的,其他线程在用A值与修改后的A值比较还是相等的,最终可以修改成功。
一个比较容易想到的解决方案是为这个原子类加一个类似版本号的东西,线程每次对该原子类修改后都要相应的修改其版本号,这样某个线程在使用CAS修改该原子类时判断版本号是否与线程存储的版本号相同即可判断是否出现了ABA问题。
Java为以上方式提供了一个原子类AtomicStampedReference类,其中除了我们实际要计算的变量外,还包括一个类似版本号的变量stamp,AtomicStampedReference类的部分实现如下。
public class AtomicStampedReference<V> {
private static class Pair<T> {
final T reference;
final int stamp;
private Pair(T reference, int stamp) {
this.reference = reference;
this.stamp = stamp;
}
static <T> Pair<T> of(T reference, int stamp) {
return new Pair<T>(reference, stamp);
}
}
}我们使用AtomicStampedReference来实验这样的一个ABA问题:线程1获取AtomicStampedReference变量value的值为1且版本为1随后阻塞1S,线程2将该变量值修改为2且版本加1,然后线程2再次将该变量值修改为1且版本加1,这时线程1尝试修改变量值为3。程序代码如下:
public class AtomicStampedReferenceTest {
public static void main(String[] args) {
// 定义AtomicStampedReference Pair.reference值为1, Pair.stamp为1
AtomicStampedReference atomicStampedReference = new AtomicStampedReference(1,1);
new Thread(()->{
int[] stampHolder = new int[1];
int value = (int) atomicStampedReference.get(stampHolder);
int stamp = stampHolder[0];
log.debug("Thread1 read value: " + value + ", stamp: " + stamp);
// 阻塞1s
LockSupport.parkNanos(1000000000L);
// Thread1通过CAS修改value值为3 stamp是版本,每次修改可以通过+1保证版本唯一性
if (atomicStampedReference.compareAndSet(value, 3,stamp,stamp+1)) {
log.debug("Thread1 update from " + value + " to 3");
} else {
atomicStampedReference.get(stampHolder);
log.debug("Thread1 update fail,oldStamp:" + stamp + ",newStamp:" + stampHolder[0]);
}
},"Thread1").start();
new Thread(()->{
int[] stampHolder = new int[1];
int value = (int)atomicStampedReference.get(stampHolder);
int stamp = stampHolder[0];
log.debug("Thread2 read value: " + value+ ", stamp: " + stamp);
// Thread2通过CAS修改value值为2
if (atomicStampedReference.compareAndSet(value, 2,stamp,stamp+1)) {
log.debug("Thread2 update from " + value + " to 2");
// do something
value = (int) atomicStampedReference.get(stampHolder);
stamp = stampHolder[0];
log.debug("Thread2 read value: " + value+ ", stamp: " + stamp);
// Thread2通过CAS修改value值为1
if (atomicStampedReference.compareAndSet(value, 1,stamp,stamp+1)) {
log.debug("Thread2 update from " + value + " to 1");
}
}
},"Thread2").start();
}
}控制台打印结果如下:

可以看到线程1最后是修改失败的,因为线程1虽然感知不到变量值的变化(一直是1),但版本号不一样了,线程1一开始获取到的版本号是1,经过线程2修改两次之后变成3了,因此线程1修改失败。
Java还提供了另一个类AtomicMarkableReference也可以解决ABA问题,与AtomicStampedReference类不同的是,这个类没有记录版本号(修改次数),只是记录了存储的变量是否被改变。
Atomic原子工具类
在并发编程中为了防止出现并发安全问题,最常用的方法是通过synchronized或Lock加锁来进行控制,但对于一些很简单的i++操作如果也使用这么重量级的锁,就会降低系统的性能。因此JUC(java.util.current)包为我们提供了一个atomic包,其中包含了各种原子工具类,这些原子工具类都是通过Unsafe类提供的CAS方法来完成相应的功能。
atomic包下的原子工具类根据操作数据的类型可以分为以下几类:
- 基本类型:AtomicInteger、AtomicLong、AtomicBoolean;
- 引用类型:AtomicReference、AtomicStampedReference、AtomicMarkableReference;
- 数组类型:AtomicIntegerArray、AtomicLongArray、AtomicReferenceArray;
- 对象属性原则修改器:AtomicIntegerFieldUpdater、AtomicLongFieldUpdater、AtomicReferenceFieldUpdater;
- JDK1.8新增的原子类型累加器:DoubleAccumulator、DoubleAdder、LongAccumulator、LongAdder、Striped64。
下面分别以每个类型中的一个类举例说明这些原子工具类的简单使用。
基本类型
以AtomicInteger为例,其常用的几个方法如下:
//返回旧值并将当前变量值加1
public final int getAndIncrement() {
return unsafe.getAndAddInt(this, valueOffset, 1);
}
//返回旧值并将当前变量的值修改为指定的值
public final int getAndSet(int newValue) {
return unsafe.getAndSetInt(this, valueOffset, newValue);
}
//将当前变量的值加1并返回计算后的新值
public final int incrementAndGet() {
return unsafe.getAndAddInt(this, valueOffset, 1) + 1;
}
//CAS操作
public final boolean compareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}
//将变量值与指定的值相加并返回计算后的新值
public final int addAndGet(int delta) {
return unsafe.getAndAddInt(this, valueOffset, delta) + delta;
}我们使用多个线程并发对一个普通int变量自增100000次,最终得到的结果总是小于100000,因为自增操作不是原子性的,这些线程之间计算的结果会有覆盖的情况,例如下面的程序使用10个线程分别对变量count执行自增操作10000次。
public class AtomicIntegerTest {
private static int count;
public static void main(String[] args) {
for (int i = 0; i < 10; i++) {
Thread thread = new Thread(() -> {
for (int j = 0; j < 10000; j++) {
count++;
}
});
thread.start();
}
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(count);
}
}控制台打印结果:

使用AtomicInterger类就可以避免线程对变量值的相互覆盖的问题。
public class AtomicIntegerTest {
static AtomicInteger sum = new AtomicInteger(0);
public static void main(String[] args) {
for (int i = 0; i < 10; i++) {
Thread thread = new Thread(() -> {
for (int j = 0; j < 10000; j++) {
// 原子自增 CAS
sum.incrementAndGet();
}
});
thread.start();
}
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(sum.get());
}
}控制台打印结果如下:

数组类型
以AtomicIntegerArray为例,其常用的几个方法如下:
//为数组指定下标的变量加上指定的值,并返回计算后的新值
public final int addAndGet(int i, int delta) {
return getAndAdd(i, delta) + delta;
}
//为指定下标的变量加1,并返回旧值
public final int getAndIncrement(int i) {
return getAndAdd(i, 1);
}
//CAS设置指定下标的值
public final boolean compareAndSet(int i, int expect, int update) {
return compareAndSetRaw(checkedByteOffset(i), expect, update);
}测试程序:
public class AtomicIntegerArrayTest {
static int[] value = new int[]{ 1, 2, 3, 4, 5 };
static AtomicIntegerArray atomicIntegerArray = new AtomicIntegerArray(value);
public static void main(String[] args) throws InterruptedException {
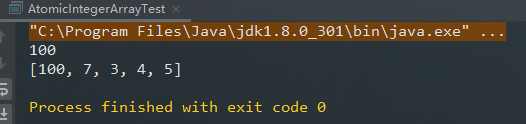
//设置索引0的元素为100
atomicIntegerArray.set(0, 100);
System.out.println(atomicIntegerArray.get(0));
//以原子更新的方式将数组中索引为1的元素与输入值相加
atomicIntegerArray.getAndAdd(1,5);
System.out.println(atomicIntegerArray);
}
}控制台打印结果:
引用类型
AtomicStampedReference和AtomicMarkableReference已经大概介绍过了,此处以AtomicReference为例,AtomicReference是对普通对象的封装,可以保证在修改对象引用时的线程安全。需要注意的是,它只会保证修改对象引用的线程安全。
测试程序:
public class AtomicReferenceTest {
public static void main( String[] args ) {
User user1 = new User("张三", 23);
User user2 = new User("李四", 25);
User user3 = new User("王五", 20);
//初始化为 user1
AtomicReference<User> atomicReference = new AtomicReference<>();
atomicReference.set(user1);
//把 user2 赋给 atomicReference
atomicReference.compareAndSet(user1, user2);
System.out.println(atomicReference.get());
//把 user3 赋给 atomicReference
atomicReference.compareAndSet(user1, user3);
System.out.println(atomicReference.get());
//修改user2对象的值,再将user3赋给atomicReference
user2.setAge(100);
user2.setName("赵六");
atomicReference.compareAndSet(user2,user3);
System.out.println(atomicReference.get());
}
}控制台打印结果:

对象属性原子修改器
以AtomicIntegerFieldUpdater为例,它可以线程安全地更新对象中的整型变量,但它的使用有以下限制:
- 对象的属性必须是volatile修饰的,因为CAS只保证原子性,不保证可见性,事实上AtomicInteger中存储值的属性也是volatile修饰的;
- 字段的描述类型与调用者与操作对象字段的关系一致,即调用者能够直接操作对象字段,就可以通过反射进行原子操作。但对于父类的字段,子类是不能直接操作的;
- 只能是实例变量,不能是类变量;
- 只能是可修改变量,不能是final变量;
- AtomicIntegerFieldUpdater和AtomicLongFieldUpdater只能修改int或long类型的字段,不能修改其包装类型,如果需要修改包装类型需要使用AtomicReferenceFieldUpdater。
测试程序:
public class AtomicIntegerFieldUpdaterTest {
public static class Candidate {
//字段必须是volatile类型
volatile int score = 0;
AtomicInteger score2 = new AtomicInteger();
}
public static final AtomicIntegerFieldUpdater<Candidate> scoreUpdater =
AtomicIntegerFieldUpdater.newUpdater(Candidate.class, "score");
public static AtomicInteger realScore = new AtomicInteger(0);
public static void main(String[] args) throws InterruptedException {
final Candidate candidate = new Candidate();
Thread[] t = new Thread[10000];
for (int i = 0; i < 10000; i++) {
t[i] = new Thread(new Runnable() {
@Override
public void run() {
if (Math.random() > 0.4) {
candidate.score2.incrementAndGet();
scoreUpdater.incrementAndGet(candidate);
realScore.incrementAndGet();
}
}
});
t[i].start();
}
for (int i = 0; i < 10000; i++) {
t[i].join();
}
System.out.println("AtomicIntegerFieldUpdater Score=" + candidate.score);
System.out.println("AtomicInteger Score=" + candidate.score2.get());
System.out.println("realScore=" + realScore.get());
}
}控制台打印结果:

原子类型累加器
AtomicLong是利用了底层的CAS操作来提供并发性的,逻辑是采用自旋的方式不断尝试更新目标值,直到更新成功。在并发量较低的环境下,线程冲突的概率比较小,自旋的次数和时间可能不多。但在高并发场景下,就可能会有很多个线程同时在自旋,也就会出现大量失败并不断自旋的情况,这就让AtomicLong的自旋成为性能瓶颈。
Java为了解决以上问题,引入了LongAdder等累加器类。
设计思路
AtomicLong有个内部变量保存实际的long值,所有的操作都是针对这个变量进行的。在高并发场景下,这个变量可以看作是一个热点,N个线程竞争一个热点,性能自然就下降了。LongAdder的基本思路就是分散热点,将这个变量的值分散到一个数组中,不同线程会命中到数组的不同槽中,各个线程只对自己槽中的那个值进行CAS,这样就达到了分散热点的目的,线程之间的冲突概率变小。如果要获取真正的long值,只需要将所有槽的变量值累加返回即可。

内部结构
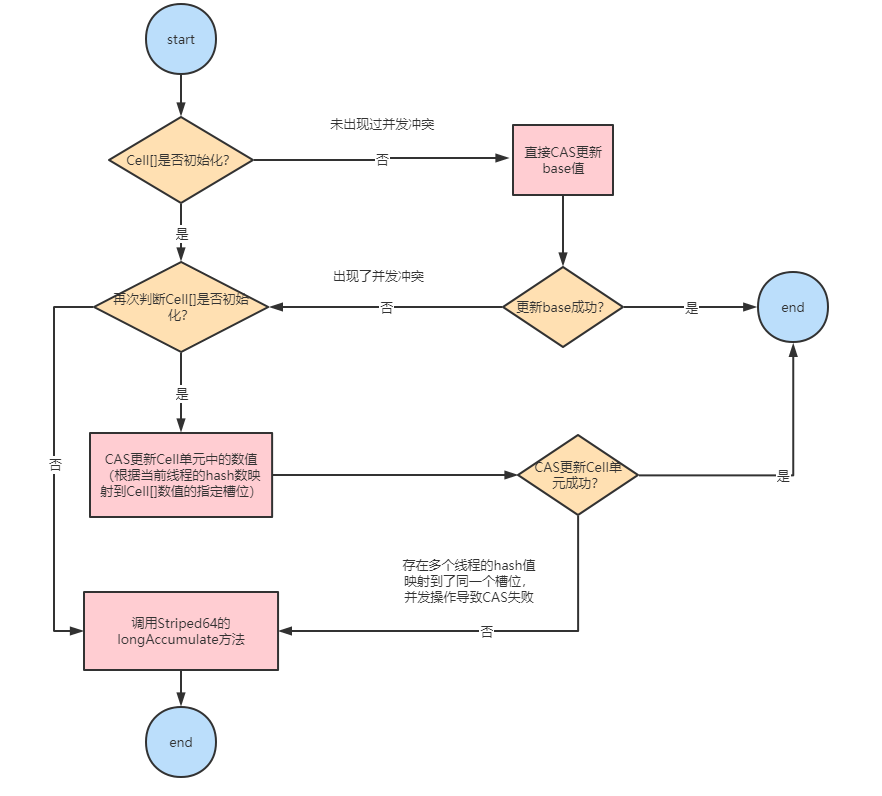
LongAdder内部包含一个base变量和一个Cell[]数组。当没有发生并发竞争时,直接使用base变量累加值,否则将各个线程的值累加到它所在的Cell[]槽中。
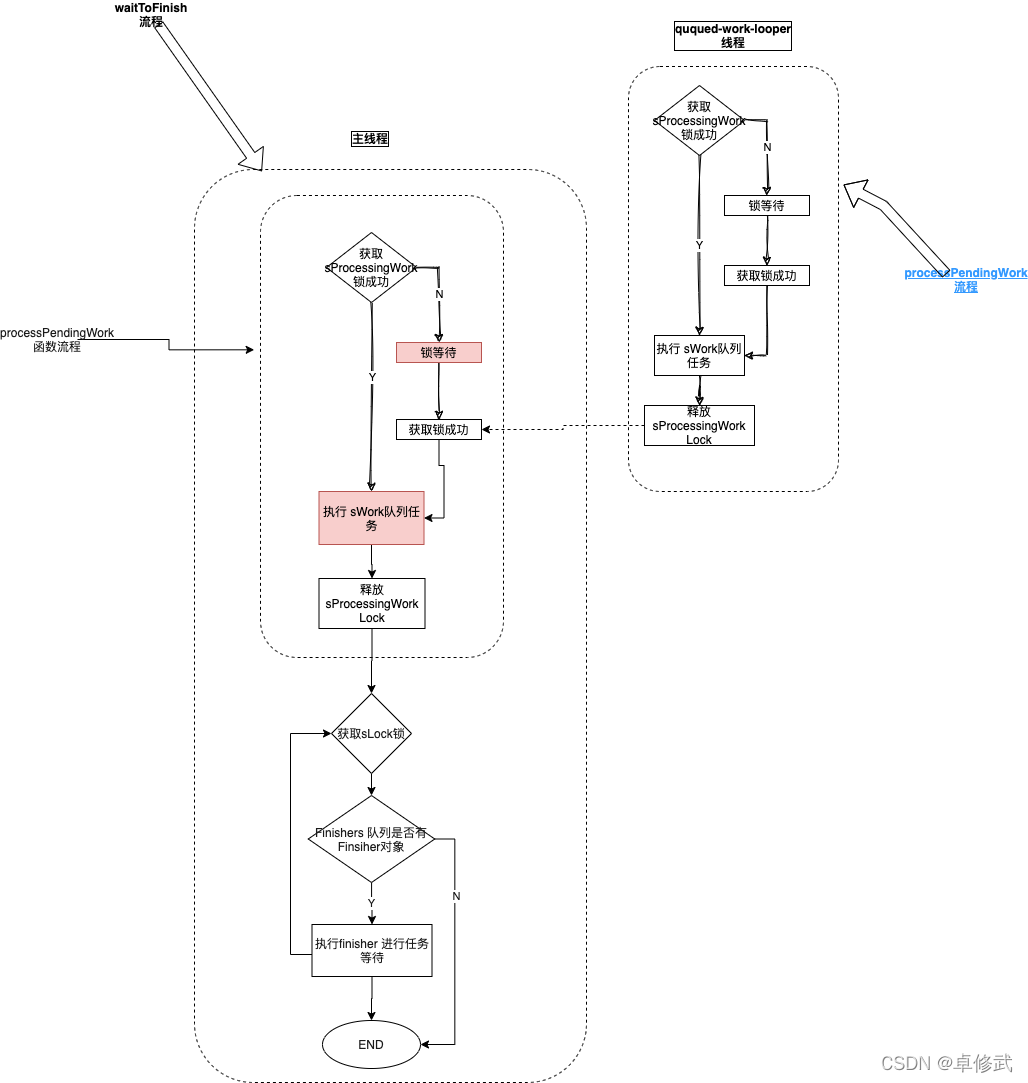
LongAdder的核心方法是add()方法,作用是为当前变量值原子加上一个指定的值,该方法的逻辑可以表示如下图:
LongAdder和AtomicLong
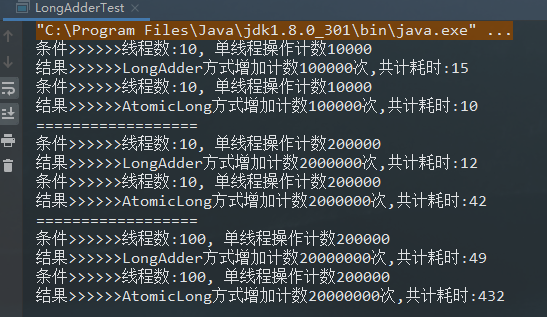
LongAdder和AtomicLong在低并发时差距并不明显,随着并发的增多,它们的效率差距就会越来越大。例如下面的程序,随着线程数和操作数的增加,LongAdder与AtomicLong的耗时差距越来越明显。
public class LongAdderTest {
public static void main(String[] args) {
testAtomicLongVSLongAdder(10, 10000);
System.out.println("==================");
testAtomicLongVSLongAdder(10, 200000);
System.out.println("==================");
testAtomicLongVSLongAdder(100, 200000);
}
static void testAtomicLongVSLongAdder(final int threadCount, final int times) {
try {
long start = System.currentTimeMillis();
testLongAdder(threadCount, times);
long end = System.currentTimeMillis() - start;
System.out.println("条件>>>>>>线程数:" + threadCount + ", 单线程操作计数" + times);
System.out.println("结果>>>>>>LongAdder方式增加计数" + (threadCount * times) + "次,共计耗时:" + end);
long start2 = System.currentTimeMillis();
testAtomicLong(threadCount, times);
long end2 = System.currentTimeMillis() - start2;
System.out.println("条件>>>>>>线程数:" + threadCount + ", 单线程操作计数" + times);
System.out.println("结果>>>>>>AtomicLong方式增加计数" + (threadCount * times) + "次,共计耗时:" + end2);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
static void testAtomicLong(final int threadCount, final int times) throws InterruptedException {
CountDownLatch countDownLatch = new CountDownLatch(threadCount);
AtomicLong atomicLong = new AtomicLong();
for (int i = 0; i < threadCount; i++) {
new Thread(new Runnable() {
@Override
public void run() {
for (int j = 0; j < times; j++) {
atomicLong.incrementAndGet();
}
countDownLatch.countDown();
}
}, "my-thread" + i).start();
}
countDownLatch.await();
}
static void testLongAdder(final int threadCount, final int times) throws InterruptedException {
CountDownLatch countDownLatch = new CountDownLatch(threadCount);
LongAdder longAdder = new LongAdder();
for (int i = 0; i < threadCount; i++) {
new Thread(new Runnable() {
@Override
public void run() {
for (int j = 0; j < times; j++) {
longAdder.add(1);
}
countDownLatch.countDown();
}
}, "my-thread" + i).start();
}
countDownLatch.await();
}
}控制台打印结果:
Java休眠线程
在Java中,让一个线程休眠有三种方法,分别为:Thread.sleep()、Object.wait()和LockSupport.park()方法。
Thread.sleep()
sleep()方法必须指定线程休眠时间,调用此方法后线程在Java层面的状态是TIMED_WAITING,且需要捕获InterruptedException异常。sleep()方法不会释放线程持有的锁。
Object.wait()
wait()方法是和notify()或notifyAll()方法配合使用的,它们都是Object提供的方法,可用来实现等待唤醒机制,但拥有以下缺点:
- 在使用这几个方法前必须要获取锁对象,即这几个方法只能在synchronized方法或synchronized块中运行;
- 当对象的等待队列有多个线程时,notify()方法只能随机选择其中一个线程唤醒,不能指定唤醒某个线程。
LockSupport.park()
LockSupport是JDK中用来实现线程阻塞和唤醒的工具。使用它可以在任何场合使线程阻塞,且可以指定任何线程进行唤醒,不用担心阻塞和唤醒操作的顺序,但连续多次唤醒和一次唤醒效果是一样的。JUC包下的锁和其他同步工具的底层实现大量地使用了LockSupport进行线程的阻塞和唤醒。需要注意的是,park()方法不会释放锁。
LockSupport的park()和unpark()方法作用分别是使线程阻塞和唤醒线程,简单使用方法如下面的程序:
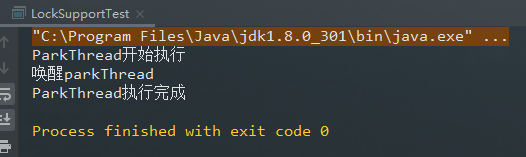
public class LockSupportTest {
public static void main(String[] args) throws InterruptedException {
Thread parkThread = new Thread(new ParkThread());
parkThread.start();
Thread.sleep(1000);
System.out.println("唤醒parkThread");
//为指定线程parkThread提供“许可”
LockSupport.unpark(parkThread);
}
static class ParkThread implements Runnable{
@Override
public void run() {
System.out.println("ParkThread开始执行");
// 等待“许可”
LockSupport.park();
System.out.println("ParkThread执行完成");
}
}
}控制台打印结果:
实现原理
LockSupport的park()和unpark()方法也是通过Unsafe类来实现的,这两个方法在Unsafe中都是native方法,即都是在JVM中实现的。这两个方法原理是:使某个线程阻塞需要消耗线程的一个凭证,这个凭证至多有一个。当调用park()方法时,线程如果有凭证则直接消耗掉这个凭证并正常退出;如果线程没有凭证,则阻塞该线程直到凭证可用。当调用unpark()方法时,它会为线程增加一个凭证,但至多有一个,即调用多次unpark()方法与调用一次效果是一样的。
这个凭证在JVM的C++实现中就对应着Parker实例中的_counter变量,每个线程都有Parker实例。
class Parker : public os::PlatformParker {
private:
volatile int _counter ;
...
public:
void park(bool isAbsolute, jlong time);
void unpark();
...
}
class PlatformParker : public CHeapObj<mtInternal> {
protected:
pthread_mutex_t _mutex [1] ;
pthread_cond_t _cond [1] ;
...
}LockSupport就是通过控制_counter变量来对控制线程的阻塞和唤醒,具体如下:
- 当调用park()方法时,将_counter置为0,同时判断修改前的值如果大于0则说明前面调用过unpark()方法,直接退出;否则使线程阻塞。
- 当调用unpark()方法时,将_counter置为1,同时判断修改前的值如果小于1则说明前面调用过unpark()方法,进行线程唤醒;否则直接退出。
需要注意的是,如果先调用两次unpark()方法再调用两次park()方法,线程仍会阻塞,因此两次unpark()方法与一次unpark()方法效果一致,只是将_counter的值设为1,但park()方法调用一次都需要消耗掉一个凭证。下面的例子可以证明。
测试程序:
public class LockSupportTest {
public static void main(String[] args) throws InterruptedException {
Thread parkThread = new Thread(new ParkThread());
//为指定线程parkThread提供“许可”
System.out.println("唤醒parkThread");
LockSupport.unpark(parkThread);
LockSupport.unpark(parkThread);
parkThread.start();
}
static class ParkThread implements Runnable{
@Override
public void run() {
System.out.println("ParkThread开始执行");
// 等待“许可”
LockSupport.park();
LockSupport.park();
System.out.println("ParkThread执行完成");
}
}
}控制台执行结果:

但先调用两次park()方法再间隔调用两次unpark()方法,线程就会被唤醒。此处我们可以理解为,线程等待两个凭证,当调用一次unpark()方法提供一个凭证时就会被消耗掉,如果第二次unpark()方法的执行在第一个unpark()方法提供的凭证消耗掉之前,第二次unpark()方法不起作用;如果第二次unpark()方法的执行在第一个unpark()方法提供的凭证被消耗掉之后,第二次unpark()方法也会提供一个凭证。
我们来做一次测试,首先调用两次park()方法,随后连续调用两次unpark()方法,测试程序代码如下:
public class LockSupportTest {
public static void main(String[] args) throws InterruptedException {
Thread parkThread = new Thread(new ParkThread());
parkThread.start();
Thread.sleep(1000);
//为指定线程parkThread提供“许可”
System.out.println("唤醒parkThread");
LockSupport.unpark(parkThread);
LockSupport.unpark(parkThread);
}
static class ParkThread implements Runnable{
@Override
public void run() {
System.out.println("ParkThread开始执行");
// 等待“许可”
LockSupport.park();
LockSupport.park();
System.out.println("ParkThread执行完成");
}
}
}控制台打印结果如下:

可以看到线程是被阻塞了的。下面修改下代码,让两次unpark()方法调用有一定的时间间隔,这个时间间隔是用来让第一次unpark()方法提供的凭证消耗掉,这样使第二次unpark()方法提供的凭证起作用。测试程序代码如下:
public class LockSupportTest {
public static void main(String[] args) throws InterruptedException {
Thread parkThread = new Thread(new ParkThread());
parkThread.start();
Thread.sleep(1000);
//为指定线程parkThread提供“许可”
System.out.println("唤醒parkThread");
LockSupport.unpark(parkThread);
Thread.sleep(1);
LockSupport.unpark(parkThread);
}
static class ParkThread implements Runnable{
@Override
public void run() {
System.out.println("ParkThread开始执行");
// 等待“许可”
LockSupport.park();
LockSupport.park();
System.out.println("ParkThread执行完成");
}
}
}控制台打印结果如下: