1.
这是什么意思? label_viz[:,:,::-1]
这段代码看起来像是Python中处理图像的代码片段。让我来为您解释一下:
1. `label_viz`:这可能是一个二维数组(通常是NumPy数组),代表图像上的标签或类别信息的可视化表示。
2. `[:,:,::-1]`:这是一个数组切片的表达方式。让我逐步解释这个切片的含义:
- 第一个冒号 `:`:表示选择数组的所有行。
- 第二个冒号 `:`:表示选择数组的所有列。
- `::-1`:这是一个步长为-1的切片,它会将选定的行和列倒序排列。在这个上下文中,通常用于颜色通道的倒转。
综合起来,`label_viz[:,:,::-1]` 的意思是,对 `label_viz` 数组进行切片操作,保留所有行和列,并将颜色通道进行颠倒,这通常用于在处理彩色图像时进行通道调整,以便正确地显示图像。
2.
conda 删除环境命令
要使用conda删除环境,您可以使用以下命令:
conda env remove --name <environment_name>在上面的命令中,将 `<environment_name>` 替换为您要删除的环境的名称。请注意,删除环境将永久删除该环境及其包含的所有包和文件,所以请谨慎操作。
另外,如果您希望同时删除环境的所有文件(包括存储的文件、缓存等),可以使用以下命令:
conda env remove --name <environment_name> --all同样,请确保在删除环境之前做好备份和确认,以免丢失重要数据。
3.
mim install mmengine 报错 KeyError: 'pkg_resources'
使用pip安装
pip install mmengine依据:
安装 — mmengine 0.8.4 文档
4.
linux中安装 git
在apt命令前添加sudo,以管理员权限运行该命令。在终端中输入以下命令:
sudo apt install git
5.
jupyter notebook 生成新内核
运行以下命令:
python -m ipykernel install --user --name=myenv --display-name "My Environment"
其中 myenv 是您虚拟环境的名称,"My Environment" 是您想要为内核显示的名称。
6.
mim install mmcv 报错
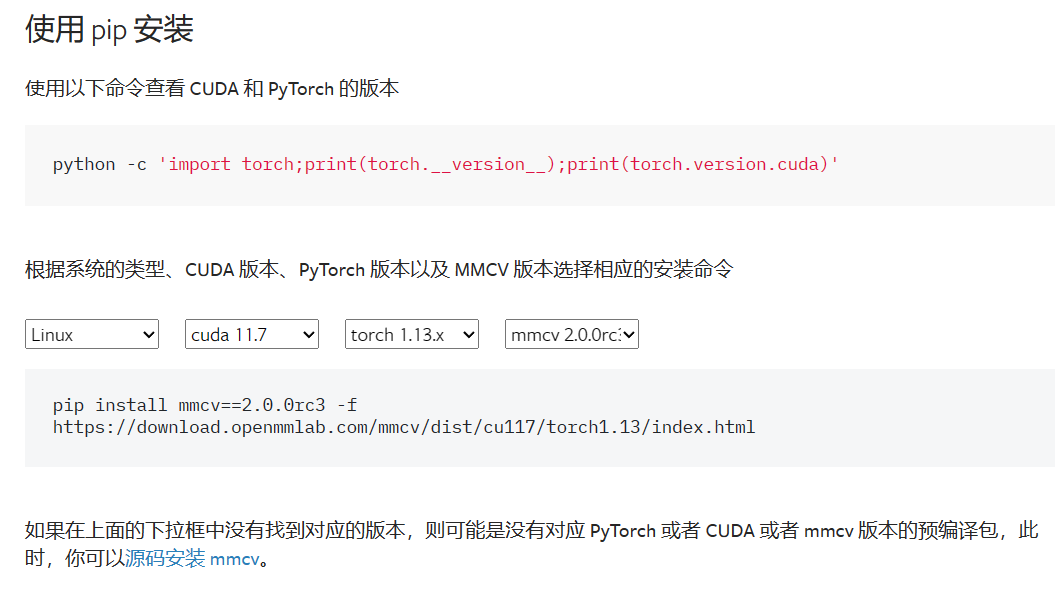
依据:
安装 MMCV — mmcv 2.0.0 文档
根据系统类型、CUDA版本、PyTorch版本及MMCV选择相应安装命令。
python -c 'import torch;print(torch.__version__);print(torch.version.cuda)'7.
!wget https://zihao-openmmlab.obs.cn-east-3.myhuaweicloud.com/20220713-mmdetection/images/street_uk.jpeg -P data 是什么意思?
这个命令是使用 `wget` 工具从特定 URL 下载文件,并将其保存到指定目录中。
具体解释如下:
- `wget`: 是一个用于从网络下载文件的命令行工具。
- `https://zihao-openmmlab.obs.cn-east-3.myhuaweicloud.com/20220713-mmdetection/images/street_uk.jpeg`: 这是要下载的文件的 URL,即图片的地址。
- `-P data`: 这是指定下载文件保存路径的参数。`-P` 后面跟着要保存的目录的路径,这里是 `data` 目录。下载后的文件将保存在 `data` 目录中。
所以,这个命令的意思是从给定的 URL 下载一张名为 `street_uk.jpeg` 的图片,并将其保存在当前工作目录下的 `data` 子目录中。如果该目录不存在,`wget` 会自动创建它。
8.
result.pred_sem_seg.data.cpu()这是什么意思?
这段代码看起来像是在处理 PyTorch 中的结果对象。让我来为您解释一下:
1. `result`:这可能是一个包含模型预测结果的对象。通常在深度学习框架中,模型预测的结果会被存储在一个对象中,以便进一步处理和分析。
2. `result.pred_sem_seg`:这是从 `result` 对象中获取名为 `pred_sem_seg` 的属性或字段。这可能是一个包含语义分割预测结果的张量。
3. `.data`:在 PyTorch 中,通过 `.data` 属性可以访问张量的底层数据。这个属性通常用于获取张量的 NumPy 数组表示。
4. `.cpu()`:这是一个方法调用,它将张量从 GPU 转移到 CPU 上。这是因为在处理深度学习模型时,数据通常存储在 GPU 上以加快计算速度。`.cpu()` 方法用于将数据从 GPU 返回到 CPU。
综合起来,`result.pred_sem_seg.data.cpu()` 的意思是,从 `result` 对象中获取 `pred_sem_seg` 属性的底层数据,然后将这些数据从 GPU 移动到 CPU。通常情况下,这是为了将预测结果以 NumPy 数组的形式在 CPU 上进行进一步处理、可视化或保存。
9.
git clone https://github.com/open-mmlab/mmcv.git && cd mmcv
这个命令是用于在命令行中从 GitHub 上克隆一个名为 `mmcv` 的代码库,并进入到该克隆的目录中。
具体来说:
- `git clone https://github.com/open-mmlab/mmcv.git`:这个部分使用 Git 工具来克隆名为 `mmcv` 的代码库。`https://github.com/open-mmlab/mmcv.git` 是该代码库的 URL。在执行这个命令后,Git 会将代码库的内容下载到您当前所在的目录中,并在本地创建一个 `mmcv` 的文件夹来存储代码。
- `&&`:这个符号用于在一个命令成功执行后立即执行下一个命令。
- `cd mmcv`:这个部分用于进入到刚刚克隆的 `mmcv` 代码库的目录中。`cd` 是进入目录的命令,`mmcv` 是目录的名称。
执行这个命令后,您将会在命令行中看到您的当前工作目录变为 `mmcv` 代码库的目录。您可以在这个目录下继续执行其他命令,例如构建、运行代码,或者修改代码库中的文件。
10.
docker build -t mmcv -f docker/release/Dockerfile .
这个命令是用于在 Docker 中构建一个名为 `mmcv` 的镜像,使用特定的 Dockerfile 进行构建。
具体来说:
- `docker build -t mmcv`:这个部分表示使用 Docker 构建一个镜像,并为该镜像指定一个名称为 `mmcv`。
- `-f docker/release/Dockerfile`:这个部分表示使用位于 `docker/release` 目录中的名为 `Dockerfile` 的文件作为构建镜像的配置文件。Dockerfile 是一种包含构建指令的文本文件,用于定义如何构建镜像。
- `.`:这个点表示构建的上下文路径,即 Docker 在构建过程中会将当前目录下的所有文件和文件夹添加到镜像中。
综合起来,这个命令会使用指定的 Dockerfile 构建一个名为 `mmcv` 的镜像,该镜像将会包含当前目录下的所有文件和文件夹。根据具体情况,这可能是为了构建一个包含 `mmcv` 库或相关项目的 Docker 镜像,以便在容器中运行或部署项目。
11.
docker build -t mmcv https://github.com/open-mmlab/mmcv.git#2.x:docker/release
这个命令是使用 Docker 构建一个名为 `mmcv` 的镜像,通过从 GitHub 上的 `open-mmlab/mmcv` 仓库的特定分支 `2.x` 中的 `docker/release` 目录获取构建配置。
具体来说:
- `docker build -t mmcv`:这个部分表示使用 Docker 构建一个名为 `mmcv` 的镜像。
- `https://github.com/open-mmlab/mmcv.git#2.x:docker/release`:这个部分表示从 GitHub 上的 `open-mmlab/mmcv` 仓库的 `2.x` 分支中的 `docker/release` 目录获取构建所需的配置。这是一个远程路径,Docker 会从这个路径中下载相关的文件来进行构建。
综合起来,这个命令会从指定的 GitHub 仓库分支的特定目录中获取构建配置,然后使用这些配置构建一个名为 `mmcv` 的 Docker 镜像。这通常用于从远程仓库中构建 Docker 镜像,以便在容器中运行或部署项目。
12.
docker image build -t mmcv -f docker/release/Dockerfile --build-arg MMCV=2.0.0rc1 .
这个命令是使用 Docker 构建一个名为 `mmcv` 的镜像,并传递了构建参数(build argument)。
具体来说:
- `docker image build -t mmcv`:这个部分表示使用 Docker 构建一个名为 `mmcv` 的镜像。
- `-f docker/release/Dockerfile`:这个部分表示使用位于 `docker/release` 目录中的名为 `Dockerfile` 的文件作为构建镜像的配置文件。
- `--build-arg MMCV=2.0.0rc1`:这个部分表示传递一个构建参数 `MMCV`,并将其设置为 `2.0.0rc1`。构建参数可以在 Dockerfile 中使用,用于在构建过程中进行条件判断或设置。
- `.`:这个点表示构建的上下文路径,即 Docker 在构建过程中会将当前目录下的所有文件和文件夹添加到镜像中。
综合起来,这个命令会使用指定的 Dockerfile 构建一个名为 `mmcv` 的镜像,同时传递了一个构建参数 `MMCV`,其值为 `2.0.0rc1`。这可以用于在构建过程中根据不同的参数进行定制化操作,例如在 Dockerfile 中根据构建参数来安装不同版本的软件包。
13.
docker build -t mmcv -f docker/release/Dockerfile \
--build-arg PYTORCH=1.11.0 \
--build-arg CUDA=11.3 \
--build-arg CUDNN=8 \
--build-arg MMCV=2.0.0rc1 .
这个命令是使用 Docker 构建一个名为 `mmcv` 的镜像,并传递了一系列构建参数(build arguments)来定制构建过程中使用的软件版本。
具体来说:
- `docker build -t mmcv`:这个部分表示使用 Docker 构建一个名为 `mmcv` 的镜像。
- `-f docker/release/Dockerfile`:这个部分表示使用位于 `docker/release` 目录中的名为 `Dockerfile` 的文件作为构建镜像的配置文件。
- `--build-arg PYTORCH=1.11.0`:这个部分表示传递构建参数 `PYTORCH`,并将其设置为 `1.11.0`。这个参数可能用于在构建过程中安装特定版本的 PyTorch。
- `--build-arg CUDA=11.3`:这个部分表示传递构建参数 `CUDA`,并将其设置为 `11.3`。这个参数可能用于在构建过程中指定使用的 CUDA 版本。
- `--build-arg CUDNN=8`:这个部分表示传递构建参数 `CUDNN`,并将其设置为 `8`。这个参数可能用于在构建过程中指定使用的 CuDNN 版本。
- `--build-arg MMCV=2.0.0rc1`:这个部分表示传递构建参数 `MMCV`,并将其设置为 `2.0.0rc1`。这个参数可能用于在构建过程中指定使用的 MMCV 版本。
- `.`:这个点表示构建的上下文路径,即 Docker 在构建过程中会将当前目录下的所有文件和文件夹添加到镜像中。
综合起来,这个命令会使用指定的 Dockerfile 构建一个名为 `mmcv` 的镜像,并根据传递的构建参数来定制镜像中使用的软件版本。这使得您可以根据需要定制化不同的构建配置,以满足特定的环境需求。
14.
!pip install -v -e .是什么意思?
这个命令是使用 `pip` 安装一个包,并以“可编辑”(editable)模式进行安装。这通常在开发过程中非常有用,因为它允许您在本地修改包的源代码,并立即看到更改的效果,而无需重新安装。
具体来说:
- `pip install`: 这是用于安装 Python 包的 `pip` 命令。
- `-v`: 这个选项表示启用详细模式(verbose mode),会显示更详细的安装过程和信息。
- `-e .`: 这个选项表示以“可编辑”模式安装当前目录中的包。也就是说,它会将当前目录中的包作为一个包的源代码安装,并将其链接到系统的 Python 包目录中,使您可以在本地修改源代码,而不需要重新安装包。
综合起来,`pip install -v -e .` 命令的意思是以详细模式安装当前目录中的包,并将其安装为“可编辑”模式,以便您可以随时修改源代码并在本地生效,而不需要重新安装包。这在开发过程中非常有用,因为它加快了迭代和测试代码的速度。
15.
import os
os.chdir('mmsegmentation')
使用 os 模块改变当前工作目录(current working directory)为 'mmsegmentation' 目录。
意味着在后续代码中执行文件操作、导入模块等时,会基于 'mmsegmentation' 目录进行。这在需要在特定目录下执行操作的情况下是很有用的。
16.
# 创建 checkpoint 文件夹,用于存放预训练模型权重文件
os.mkdir('checkpoint')
17.
import torch
print(torch.__version__)
print(torch.version.cuda) 查看torch版本和cuda版本

18.
conda list 查看当前环境下的包目录
19.
MMCV 是一个面向计算机视觉的基础库,它提供了以下功能:
-
图像和视频处理
-
图像和标注结果可视化
-
图像变换
-
多种 CNN 网络结构
-
高质量实现的常见 CUDA 算子
20.
MMEngine 是一个基于 PyTorch 实现的,用于训练深度学习模型的基础库,支持在 Linux、Windows、macOS 上运行。它具有如下三个特性:
-
通用且强大的执行器:
-
支持用少量代码训练不同的任务,例如仅使用 80 行代码就可以训练 ImageNet(原始 PyTorch 示例需要 400 行)。
-
轻松兼容流行的算法库(如 TIMM、TorchVision 和 Detectron2)中的模型。
-
-
接口统一的开放架构:
-
使用统一的接口处理不同的算法任务,例如,实现一个方法并应用于所有的兼容性模型。
-
上下游的对接更加统一便捷,在为上层算法库提供统一抽象的同时,支持多种后端设备。目前 MMEngine 支持 Nvidia CUDA、Mac MPS、AMD、MLU 等设备进行模型训练。
-
-
可定制的训练流程:
-
定义了“乐高”式的训练流程。
-
提供了丰富的组件和策略。
-
使用不同等级的 API 控制训练过程。
-
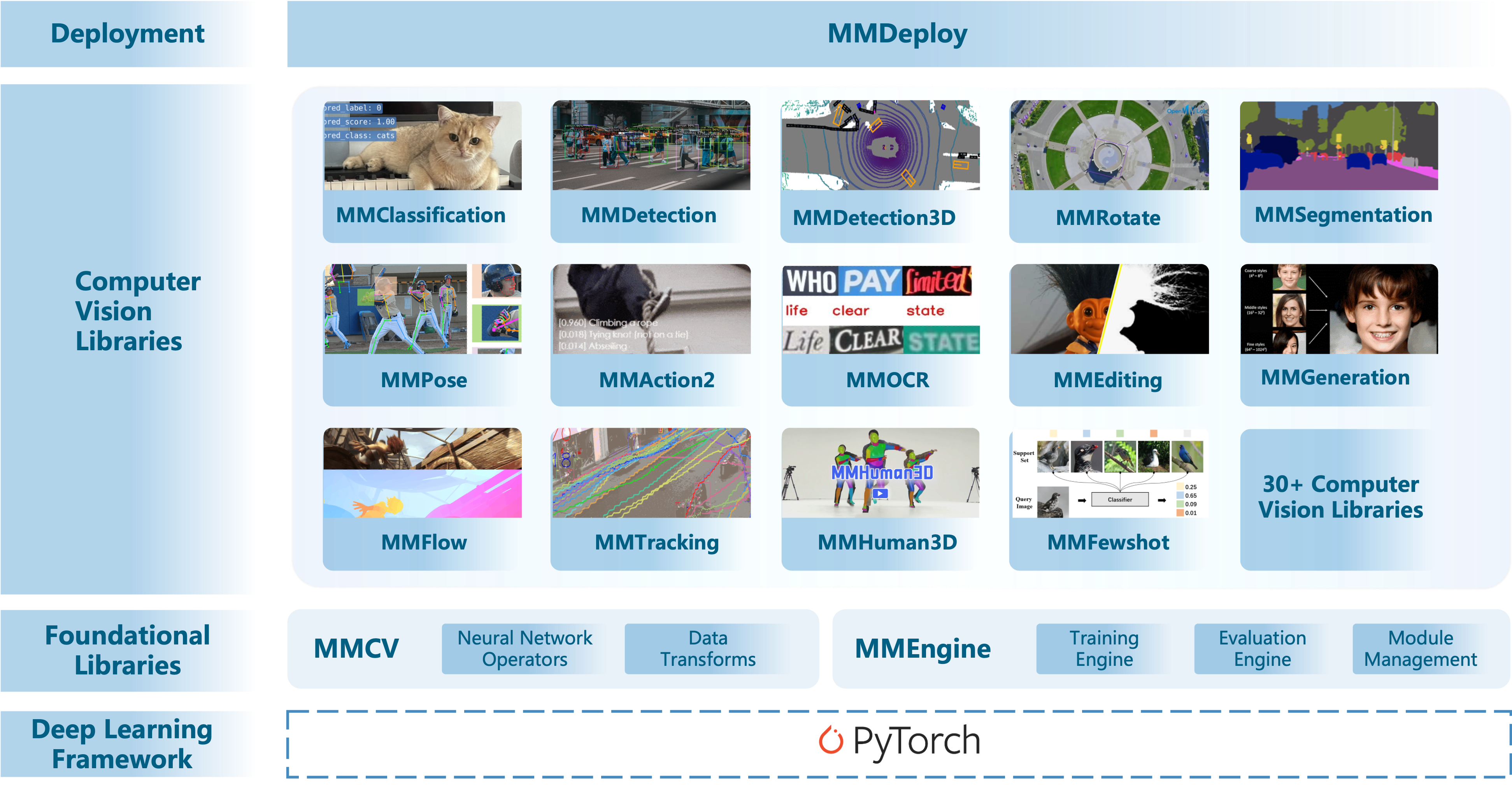
详细官网:介绍 — mmengine 0.8.4 文档
21.
设置Matplotlib中文字体
# # windows操作系统
plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号# Mac操作系统,参考 https://www.ngui.cc/51cto/show-727683.html
# 下载 simhei.ttf 字体文件
# !wget https://zihao-openmmlab.obs.cn-east-3.myhuaweicloud.com/20220716-mmclassification/dataset/SimHei.ttf# Linux操作系统,例如 云GPU平台:https://featurize.cn/?s=d7ce99f842414bfcaea5662a97581bd1
# 如果遇到 SSL 相关报错,重新运行本代码块即可
!wget https://zihao-openmmlab.obs.cn-east-3.myhuaweicloud.com/20220716-mmclassification/dataset/SimHei.ttf -O /environment/miniconda3/lib/python3.7/site-packages/matplotlib/mpl-data/fonts/ttf/SimHei.ttf
!rm -rf /home/featurize/.cache/matplotlib
import matplotlib
import matplotlib.pyplot as plt
matplotlib.rc("font",family='SimHei') # 中文字体将上面的 -O 中的目录改为自己对应的虚拟环境下一般在anaconda3中
plt.plot([1,2,3], [100,500,300])
plt.title('matplotlib中文字体测试', fontsize=25)
plt.xlabel('X轴', fontsize=15)
plt.ylabel('Y轴', fontsize=15)
plt.show()
22.
docker run --gpus all --shm-size=8g -it mmengine是什么意思?
这个命令是在 Docker 容器中运行一个名为 `mmengine` 的镜像,并设置了一些容器运行时的选项。
具体来说:
- `docker run`: 这是用于在 Docker 中运行容器的命令。
- `--gpus all`: 这个选项表示将所有可用的 GPU 分配给容器。这适用于使用 GPU 加速的任务,让容器可以利用 GPU 资源进行计算。
- `--shm-size=8g`: 这个选项表示设置容器的共享内存大小为 8GB。共享内存是容器中用于进程间通信的一种机制,该选项允许您为容器中的进程分配一定的共享内存空间。
- `-it`: 这些选项用于分配一个交互式的终端(terminal)并将标准输入(stdin)连接到容器中,使您可以在容器内部与其进行交互。
- `mmengine`: 这是要运行的容器的名称,可能是一个事先构建好的 Docker 镜像。
综合起来,`docker run --gpus all --shm-size=8g -it mmengine` 命令的意思是在一个新的 Docker 容器中运行名为 `mmengine` 的镜像,分配所有可用的 GPU 资源,并设置共享内存大小为 8GB。同时,它会为容器分配一个交互式的终端,使您可以与容器进行交互。这通常用于在容器中执行需要 GPU 加速的任务,并在容器内部进行交互操作。
22.
源码安装
# 如果克隆代码仓库的速度过慢,可以从 https://gitee.com/open-mmlab/mmengine.git 克隆 git clone https://github.com/open-mmlab/mmengine.git cd mmengine pip install -e . -v
23.
从Model Zoo中选择预训练语义分割模型的config文件和checkpoint权重文件
Model Zoo:GitHub - open-mmlab/mmsegmentation: OpenMMLab Semantic Segmentation Toolbox and Benchmark.
注意,config文件和checkpoint文件是一一对应的
- Segformer算法,Cityscpaes数据集预训练模型
configs/segformer/segformer_mit-b5_8xb1-160k_cityscapes-1024x1024.py
https://download.openmmlab.com/mmsegmentation/v0.5/segformer/segformer_mit-b5_8x1_1024x1024_160k_cityscapes/segformer_mit-b5_8x1_1024x1024_160k_cityscapes_20211206_072934-87a052ec.pth

https://github.com/open-mmlab/mmsegmentation/blob/main/configs/segformer/segformer_mit-b5_8xb1-160k_cityscapes-1024x1024.py
https://download.openmmlab.com/mmsegmentation/v0.5/segformer/segformer_mit-b5_8x1_1024x1024_160k_cityscapes/segformer_mit-b5_8x1_1024x1024_160k_cityscapes_20211206_072934-87a052ec.pth
预训练模型是pth文件
24.
!python demo/image_demo.py \
data/street_uk.jpeg \
configs/segformer/segformer_mit-b5_8xb1-160k_cityscapes-1024x1024.py \
https://download.openmmlab.com/mmsegmentation/v0.5/segformer/segformer_mit-b5_8x1_1024x1024_160k_cityscapes/segformer_mit-b5_8x1_1024x1024_160k_cityscapes_20211206_072934-87a052ec.pth \
--out-file outputs/B1_uk_segformer.jpg \
--device cuda:0 \
--opacity 0.5这是什么意思?
这个命令是运行一个 Python 脚本来进行图像分割的演示,使用了 MMsegmentation 库来执行操作。具体来说,这个命令是运行 `image_demo.py` 脚本,传递了一系列参数来指定输入图像、配置文件、预训练模型、设备等信息。
让我逐一解释每个参数的含义:
- `demo/image_demo.py`: 这是要运行的 Python 脚本的路径,相对于当前工作目录。
- `data/street_uk.jpeg`: 这是要进行图像分割的输入图像的路径。
- `configs/segformer/segformer_mit-b5_8xb1-160k_cityscapes-1024x1024.py`: 这是 MMsegmentation 的配置文件,指定了图像分割模型的设置和参数。
- `https://download.openmmlab.com/mmsegmentation/v0.5/segformer/segformer_mit-b5_8x1_1024x1024_160k_cityscapes/segformer_mit-b5_8x1_1024x1024_160k_cityscapes_20211206_072934-87a052ec.pth`: 这是预训练模型的下载链接。
- `--out-file outputs/B1_uk_segformer.jpg`: 这个参数指定了输出图像的保存路径和文件名。
- `--device cuda:0`: 这个参数指定了使用的计算设备,这里是使用 GPU(CUDA)设备编号为 0。
- `--opacity 0.5`: 这个参数指定了绘制分割结果时使用的透明度。
综合起来,这个命令的意思是运行一个 Python 脚本来对输入图像进行分割,使用指定的配置文件和预训练模型,将结果保存在输出图像中。该过程会在 GPU 设备上执行,并且分割结果会绘制在原始图像上,透明度为 0.5。这通常用于演示图像分割模型在特定图像上的效果。
25.
segformer_mit-b5_8xb2-160k_ade20k-640x640.py 这个命名是什么意思?
`segformer_mit-b5_8xb2-160k_ade20k-640x640.py` 是一个文件名,通常用于指代一个深度学习模型的配置文件。这个文件名中包含了一些关键信息,让人可以了解这个配置文件是用于哪种模型、数据集、训练设置等。
让我来解释这个文件名的各部分含义:
- `segformer_mit-b5`: 这部分表示使用的分割模型的名称,可能是某个模型的名称或标识符。
- `8xb2`: 这部分可能表示训练的 batch size 和 GPU 数量。在这里,`8xb2` 可能表示每个训练批次(batch)包含 2 个样本,同时使用 8 个 GPU 进行训练。
- `160k`: 这部分可能表示训练的迭代次数。在这里,`160k` 可能表示训练进行了 160,000 次迭代。
- `ade20k`: 这部分可能表示使用的数据集。在这里,`ade20k` 可能表示使用 ADE20K 数据集进行训练。
- `640x640`: 这部分可能表示输入图像的大小。在这里,`640x640` 可能表示输入图像的尺寸为 640x640 像素。
综合起来,这个文件名中包含了模型名称、训练设置、数据集和输入图像大小等信息,让人可以在一定程度上了解这个配置文件的作用和用途。这种命名方式通常用于深度学习框架中的配置文件,以便更好地管理和区分不同的模型和训练设置。
26.
seg_map = pred_mask.astype('uint8')
seg_img = Image.fromarray(seg_map).convert('P')
seg_img.putpalette(np.array(palette, dtype=np.uint8))什么意思?
这段代码是用于将预测的分割掩码转换成彩色分割图像,然后将分割图像添加调色板(palette),以便在显示或保存时可以正确地显示分割类别的颜色。
让我逐步解释每一步:
1. `seg_map = pred_mask.astype('uint8')`:这一步将预测的分割掩码 `pred_mask` 转换为无符号8位整数(uint8)类型。这可能是为了确保像素值在0到255之间。
2. `seg_img = Image.fromarray(seg_map).convert('P')`:这一步使用 `Image.fromarray()` 函数将转换后的分割掩码数组转换为一个 `P` 模式的图像,其中 `P` 表示调色板(palette)模式。在调色板模式下,每个像素值对应一个调色板索引,而不是直接的颜色值。
3. `seg_img.putpalette(np.array(palette, dtype=np.uint8))`:这一步使用 `putpalette()` 方法为图像添加调色板。`palette` 是一个颜色映射表,它将分割类别与颜色之间建立了联系。`np.array(palette, dtype=np.uint8)` 将颜色映射表转换为无符号8位整数数组,以便用于图像的调色板。
综合起来,这段代码的目的是将预测的分割掩码转换为彩色的分割图像,并将每个分割类别映射到特定的颜色,以便于可视化分割结果。这在分割任务中常用于将掩码可视化为彩色的分割效果图。
27.
patches = [mpatches.Patch(color=np.array(palette[i])/255., label=classes[i]) for i in range(len(classes))]
plt.legend(handles=patches, bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0., fontsize='large') 是什么意思?
这段代码是用于在 Matplotlib 图中添加图例(legend),以便将颜色与类别名称进行对应,从而解释图中的颜色所代表的含义。
让我逐步解释每一步:
1. `patches = [mpatches.Patch(color=np.array(palette[i])/255., label=classes[i]) for i in range(len(classes))]`:这一步创建了一个列表 `patches`,其中每个元素都是一个 `mpatches.Patch` 对象。这些对象表示图例中的每个条目,每个条目的颜色和标签都与特定的类别相关。`np.array(palette[i])/255.` 将调色板中的颜色值除以 255,以确保颜色值在0到1之间。
2. `plt.legend(handles=patches, bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0., fontsize='large')`:这一步使用 `plt.legend()` 函数在图中添加图例。`handles` 参数传递了要在图例中显示的条目列表,即上面创建的 `patches` 列表。`bbox_to_anchor` 参数设置图例的位置,`(1.05, 1)` 表示将图例放置在右上角。`loc` 参数设置图例的位置相对于 `bbox_to_anchor`,`borderaxespad` 参数设置图例与图的边框之间的间隔。`fontsize` 参数设置图例文本的字体大小。
综合起来,这段代码的目的是在 Matplotlib 图中添加一个图例,以解释图中的颜色与类别的对应关系。图例中的每个条目都由一个颜色块和相应的类别名称组成,使得图中的颜色可以与特定类别进行对应和解释。这在可视化分类或分割结果时非常有用,可以让观众明确地了解不同颜色所代表的类别信息。

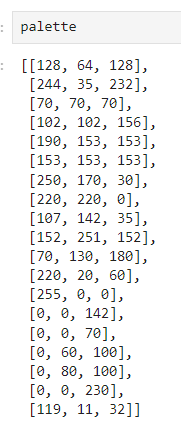








![【LeetCode-经典面试150题-day9]](https://img-blog.csdnimg.cn/img_convert/782086183cb0869cded4e389e8150bd7.jpeg)