Ext2的一般特征
类Unix操作系统使用多种文件系统。尽管所有这些文件系统都有少数POSIX API(如state())所需的共同的属性子集,但每种文件系统的实现方式是不同的。
Linux的第一个版本是基于MINIX文件系统的。当Linux成熟时,引入了扩展文件系统(Extended Filesystem,Ext FS),
它包含了几个重要的扩展但提供的性能不令人满意。
在1994年引入了第二扩展文件系统(Ext2);它除了包含几个新的特点外,还相当高效和稳定,Ext2及它的下代文件系统Ext3已成为广泛使用的Linux文件系统。
下列特点有助于Ext2的效率:
1.当创建Ext2文件系统时,系统管理员可以根据预期的文件平均长度来选择最佳块大小(从1024B~4096B)。
例如,当文件的平均长度小于几千字节时,块的大小为1024B是最佳的,因为这会产生较少的内部碎片
——也就是文件长度与存放它的磁盘分区有较少的不匹配(参见第八章中的“内存区管理”一节,在那里讨论了动态内存的内部碎片)。
另一方面,大的块对于大于几千字节的文件通常比较合适,因为这样的磁盘传送较少,因而减轻了系统的开销。
2.当创建Ext2文件系统时,系统管理员可以根据在给定大小的分区上预计存放的文件数来选择给该分区分配多少个索引节点。
这可以有效地利用磁盘的空间。
文件系统把磁盘块分为组。每组包含存放在相邻磁道上的数据块和索引节点。
正是这种结构,使得可以用较少的磁盘平均寻道时间对存放在一个单独块组中的文件进行访问。
在磁盘数据块被实际使用之前,文件系统就把这些块预分配给普通文件。
因此,当文件的大小增加时,因为物理上相邻的几个块已被保留,这就减少了文件的碎片。
3.支持快速符号链接(参见第一章中的“硬链接和软链接”一节)。
如果符号链接表示一个短路径名(小于或等于60个字符),就把它存放在索引节点中而不用通过读一个数据块进行转换。
此外,Ext2还包含了一些使它既健壮又灵活的特点:
1.文件更新策略的谨慎实现将系统崩溃的影响减到最少。
例如,当给文件创建一个新的硬链接时,首先增加磁盘索引节点中的硬链接计数器,然后把这个新的名字加到合适的目录中。
在这种方式下,如果在更新索引节点后而改变这个目录之前出现一个硬件故障,这样即使索引节点的计数器产生错误,但目录是一致的。
因此,尽管删除文件时无法自动收回文件的数据块,但并不导致灾难性的后果。
如果这种操作的顺序相反(更新索引节点前改变目录),同样的硬件故障将会导致危险的不一致:
删除原始的硬链接就会从磁盘删除它的数据块,但新的目录项将指向一个不存在的索引节点。
如果那个索引节点号以后又被另外的文件所使用,那么向这个旧目录项的写操作将毁坏这个新的文件。
2.在启动时支持对文件系统的状态进行自动的一致性检查。这种检查是由外部程序e2fsck完成的,这个外部程序不仅可以在系统崩溃之后被激活,
也可以在一个预定义的文件系统安装数(每次安装操作之后对计数器加1)之后被激活,或者在自从最近检查以来所花的预定义时间之后被激活。
3.支持不可变(immutable)的文件(不能修改、删除和更名)和仅追加(append-only)的文件(只能把数据追加在文件尾)。
4.既与Unix System VRelease4(SVR4)相兼容,也与新文件的用户组ID的BSD 语义相兼容。
在SVR4中,新文件采用创建它的进程的用户组ID;
而在BSD中,新文件继承包含它的目录的用户组ID。Ext2包含一个安装选项,由你指定采用哪种语义。
即使Ext2文件系统是如此成熟、稳定的程序,也还要考虑引入另外几个特性。
一些特性已被实现并以外部补丁的形式来使用。
另外一些还仅仅处于计划阶段,但在一些情况下,已经在Ext2的索引节点中为这些特性引入新的字段。最重要的一些特点如下:
块片(block fragmentation)
系统管理员对磁盘的访问通常选择较大的块,因为计算机应用程序常常处理大文件。
因此,在大块上存放小文件就会浪费很多磁盘空间。这个问题可以通过把几个文件存放在同一块的不同片上来解决。
透明地处理压缩和加密文件
这些新的选项(创建一个文件时必须指定)将允许用户透明地在磁盘上存放压缩和(或)加密的文件版本。
逻辑删除
一个undelete选项将允许用户在必要时很容易恢复以前已删除的文件内容。
日志
日志避免文件系统在被突然卸载(例如,作为系统崩溃的后果)时对其自动进行的耗时检查。
实际上,这些特点没有一个正式地包含在Ext2文件系统中。有人可能说Ext2是这种成功的牺牲品;
直到几年前,它仍然是大多数Linux发布公司采用的首选文件系统,每天有成千上万的用户在使用它,
这些用户会对用其他文件系统来代替Ext2的任何企图产生质疑。
Ext2中缺少的最突出的功能就是日志,日志是高可用服务器必需的功能。
为了平顺过渡,日志没有引入到Ext2文件系统;
但是,我们在后面“Ext3文件系统”一节会讨论,完全与Ext2兼容的一种新文件系统已经创建,这种文件系统提供了日志。
不真正需要日志的用户可以继续使用良好而老式的Ext2文件系统,而其他用户可能采用这种新的文件系统。现在发行的大部分系统采用Ext3作为标准的文件系统。
Ext2磁盘数据结构
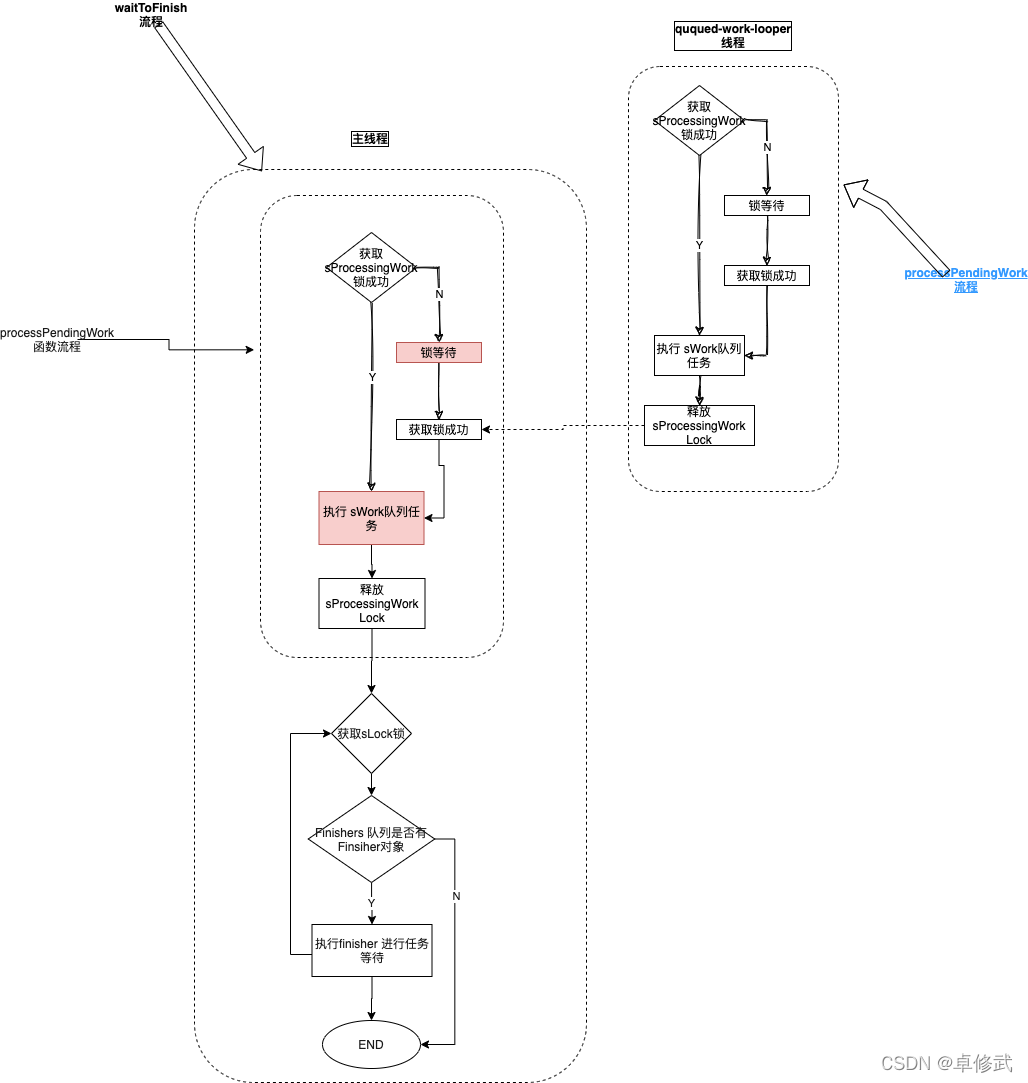
任何Ext2分区中的第一个块从不受Ext2文件系统的管理,因为这一块是为分区的引导扇区所保留的(参见附录一)。
Ext2分区的其余部分分成块组(block group),每个块组的分布图如图18-1所示。
正如你从图中所看到的,一些数据结构正好可以放在一块中,而另一些可能需要更多的块。
在Ext2文件系统中的所有块组大小相同并被顺序存放,因此,内核可以从块组的整数索引很容易地得到磁盘中一个块组的位置。
由于内核尽可能地把属于一个文件的数据块存放在同一块组中,所以块组减少了文件的碎片。块组中的每个块包含下列信息之一:
1.文件系统的超级块的一个拷贝
2.一组块组描述符的拷贝
3.一个数据块位图
4.一个索引节点位图
5.一个索引节表
6.属于文件的一大块数据,即数据块
如果一个块中不包含任何有意义的信息,就说这个块是空闲的。
从图18-1中可以看出,超级块与组描述符被复制到每个块组中。
只有块组0中所包含的超级块和组描述符才由内核使用,而其余的超级块和组描述符保持不变;
事实上,内核甚至不考虑它们。当e2fsck程序对Ext2文件系统的状态执行一致性检查时,
就引用存放在块组0中的超级块和组描述符,然后把它们拷贝到其他所有的块组中。
如果出现数据损坏,并且块组0中的主超级块和主描述符变为无效,
那么,系统管理员就可以命令e2fsck 引用存放在某个块组(除了第一个块组)中的超级块和组描述符的旧拷贝。
通常情况下,这些多余的拷贝所存放的信息足以让e2fsck把Ext2分区带回到一个一致的状态。
有多少块组呢?这取决于分区的大小和块的大小。
其主要限制在于块位图,因为块位图必须存放在一个单独的块中。
块位图用来标识一个组中块的占用和空闲状况。所以,每组中至多可以有8×b个块,b是以字节为单位的块大小。
因此,块组的总数大约是s/(8×b),这里s是分区所包含的总块数。
举例说明,让我们考虑一下32GB的Ext2分区,块的大小为4KB。
在这种情况下,每个4KB的块位图描述32K个数据块,即128MB。因此,最多需要256个块组。显然,块的大小越小,块组数越大。
超级块
Ext2在磁盘上的超级块存放在一个ext2_super_block结构中,它的字段在表18-1中列出(注1)。
__u8、__u16及__u32数据类型分别表示长度为8、16及32位的无符号数,
而__s8、__s16及__s32数据类型表示长度为8、16及32位的有符号数。
为清晰地表示磁盘上字或双字中字节的存放顺序,内核又使用了__le16、__le32、__be16和be32数据类型,
前两种类型分别表示字或双字的“小尾(little-endian)”排序方式(低阶字节在高位地址),
而后两种类型分别表示字或双字的“大尾(big-endian)”排序方式(高阶字节在高位地址)。
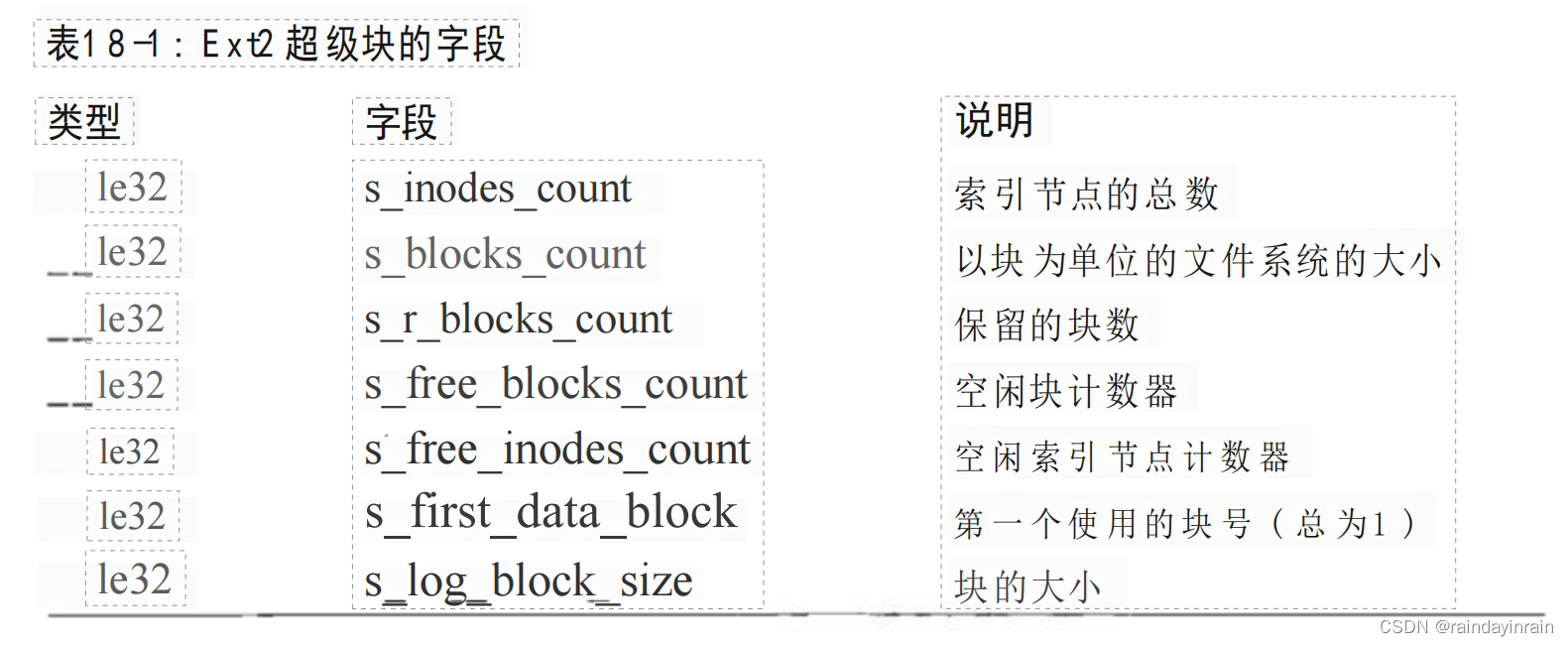



s_inodes_count字段存放索引节点的个数,而s_blocks_count字段存放Ext2文件系统的块的个数。
s_log_block_size字段以2的幂次方表示块的大小,用1024字节作为单位。
因此,0 表示1024字节的块,1表示2048字节的块,如此等等。
目前s_log_frag_size字段与s_log_block_size字段相等,因为块片还没有实现。
s_blocks_per_group、s_frags_per_group与s_inodes_per_group字段分别存放每个块组中的块数、片数及索引节点数。
一些磁盘块保留给超级用户(或由s_def_resuid和s_def_resgid字段挑选给某一其他用户或用户组)。
即使当普通用户没有空闲块可用时,系统管理员也可以用这些块继续使用Ext2文件系统。
s_mnt_count、s_max_mnt_count、s_lastcheck及s_checkinterval字段使系统启动时自动地检查Ext2文件系统。
在预定义的安装操作数完成之后,或自最后一次一致性检查以来预定义的时间已经用完,这些字段就导致e2fsck执行(两种检查可以一起进行)。
如果Ext2文件系统还没有被全部卸载(例如系统崩溃以后),或内核在其中发现一些错误,则一致性检查在启动时要强制进行。
如果Ext2文件系统被安装或未被全部卸载,则s_state字段存放的值为0;如果被正常卸载,则这个字段的值为1;如果包含错误,则值为2。
组描述符和位图
每个块组都有自己的组描述符,它是一个ext2_group_desc结构,它的字段在表18-2中列出。
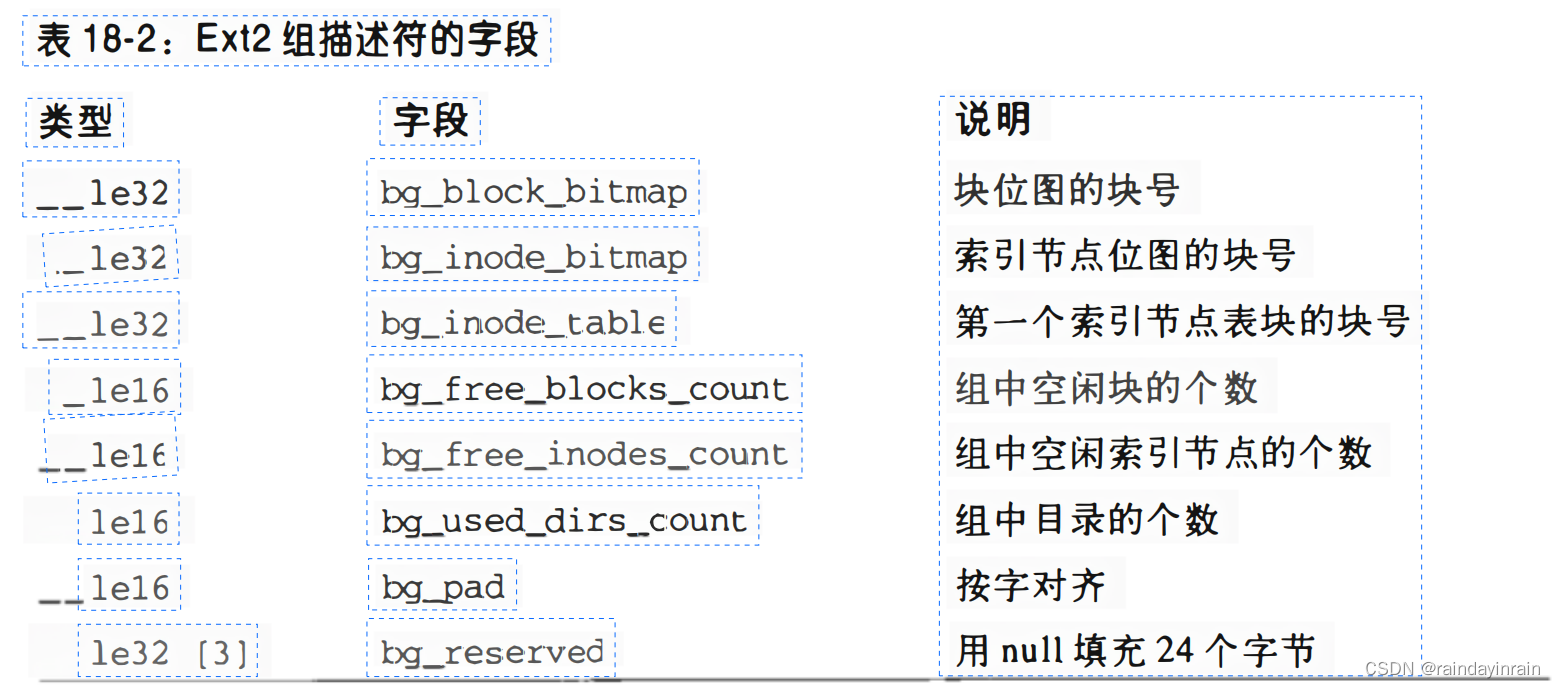
当分配新索引节点和数据块时,会用到bg_free_blocks_count、bg_free_inodes_count 和bg_used_dirs_count字段。
这些字段确定在最合适的块中给每个数据结构进行分配。
位图是位的序列,其中值0表示对应的索引节点块或数据块是空闲的,1表示占用。
因为每个位图必须存放在一个单独的块中,又因为块的大小可以是1024、2048或4096字节,
因此,一个单独的位图描述8192、16384或32768个块的状态。
索引节点表
索引节点表由一连串连续的块组成,其中每一块包含索引节点的一个预定义号。索引节点表第一个块的块号存放在组描述符的bg_inode_table字段中。
所有索引节点的大小相同,即128字节。
一个1024字节的块可以包含8个索引节点,一个4096字节的块可以包含32个索引节点。
为了计算出索引节点表占用了多少块,用一个组中的索引节点总数(存放在超级块的s_inodes_per_group字段中)除以每块中的索引节点数。
每个Ext2索引节点为ext2_innode结构,其字段如表18-3所示。
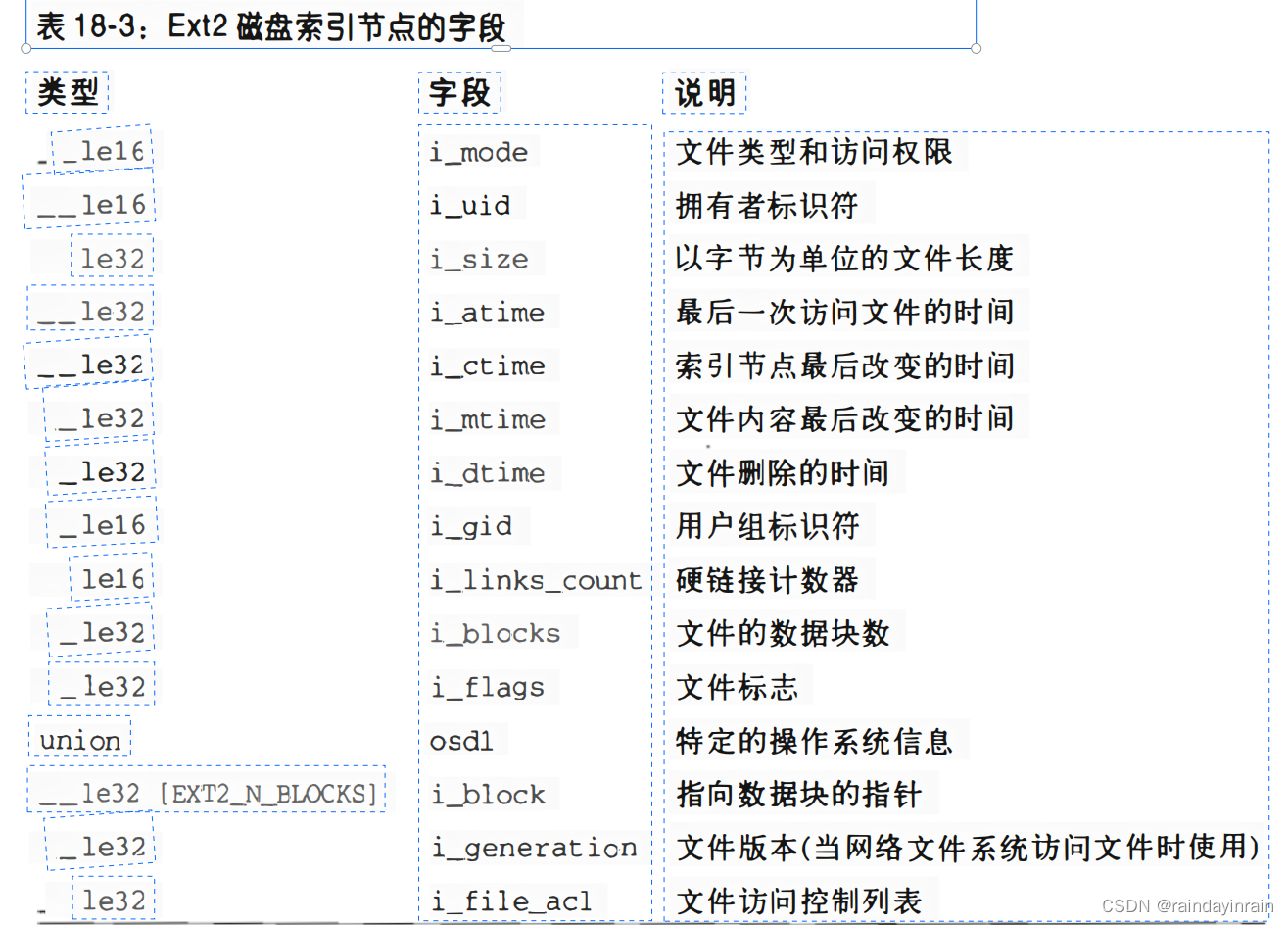

与POSIX规范相关的很多字段类似于VFS索引节点对象的相应字段,这已在第十二章的“索引节点对象”一节中讨论过。
其余的字段与Ext2的特殊实现相关,主要处理块的分配。
特别地,i_size字段存放以字节为单位的文件的有效长度,而i_blocks字段存放已分配给文件的数据块数(以512字节为单位)。
i_size和i_blocks的值没有必然的联系。因为一个文件总是存放在整数块中,一个非空文件至少接受一个数据块(因为还没实现片)且i_size可能小于512× i_blocks。
另一方面,我们将在本章后面的“文件的洞”一节中看到,一个文件可能包含有洞。在那种情况下,i_size可能大于512×i_blocks。
i_blocks字段是具有EXT2_N_BLOCKS(通常是15)个指针元素的一个数组,每个元素指向分配给文件的数据块(参见本章后面的“数据块寻址”一节)。
留给i_size字段的32位把文件的大小限制到4GB。
事实上,i_size字段的最高位没有使用,因此,文件的最大长度限制为2GB。
然而,Ext2文件系统包含一种“脏技巧”,允许像AMD的Opteron和IBM的PowerPC G5这样的64位体系结构使用大型文件。
从本质上说,索引节点的i_dir_acl字段(普通文件没有使用)表示i_size字段的32位扩展。
因此,文件的大小作为64位整数存放在索引节点中。
Ext2文件系统的64位版本与32位版本在某种程度上兼容,因为在64位体系结构上创建的Ext2文件系统可以安装在32位体系结构上,反之亦然。
但是,在32位体系结构上不能访问大型文件,除非以0_LARGEFILE标志打开文件(参见第十二章“open()系统调用”一节)。
回忆一下,VFS模型要求每个文件有不同的索引节点号。
在Ext2中,没有必要在磁盘上存放文件的索引节点号与相应块号之间的转换,因为后者的值可以从块组号和它在索引节点表中的相对位置而得出。
例如,假设每个块组包含4096个索引节点,我们想知道索引节点13021在磁盘上的地址。
在这种情况下,这个索引节点属于第三个块组,它的磁盘地址存放在相应索引节点表的第733个表项中。
正如你看到的,索引节点号是Ext2例程用来快速搜索磁盘上合适的索引节点描述符的一个关键字。
索引节点的增强属性
Ext2索引节点的格式对于文件系统设计者就好像一件紧身衣,索引节点的长度必须是2 的幂,以免造成存放索引节点表的块内碎片。
实际上,一个Ext2索引节点的128个字符空间中充满了信息,只有少许空间可以增加新的字段。
另一方面,将索引节点的长度增加至256不仅相当浪费,而且使用不同索引节点长度的Ext2文件系统之间还会造成兼容问题。
引入增强属性(extended attribute)就是要克服上面的问题。这些属性存放在索引节点之外的磁盘块中。
索引节点的i_file_acl字段指向一个存放增强属性的块。具用同样增强属性的不同索引节点可以共享同一个块。
每个增强属性有一个名称和值。两者都编码为变长字符数组,并由ext2_xattr_entry 描述符来确定。
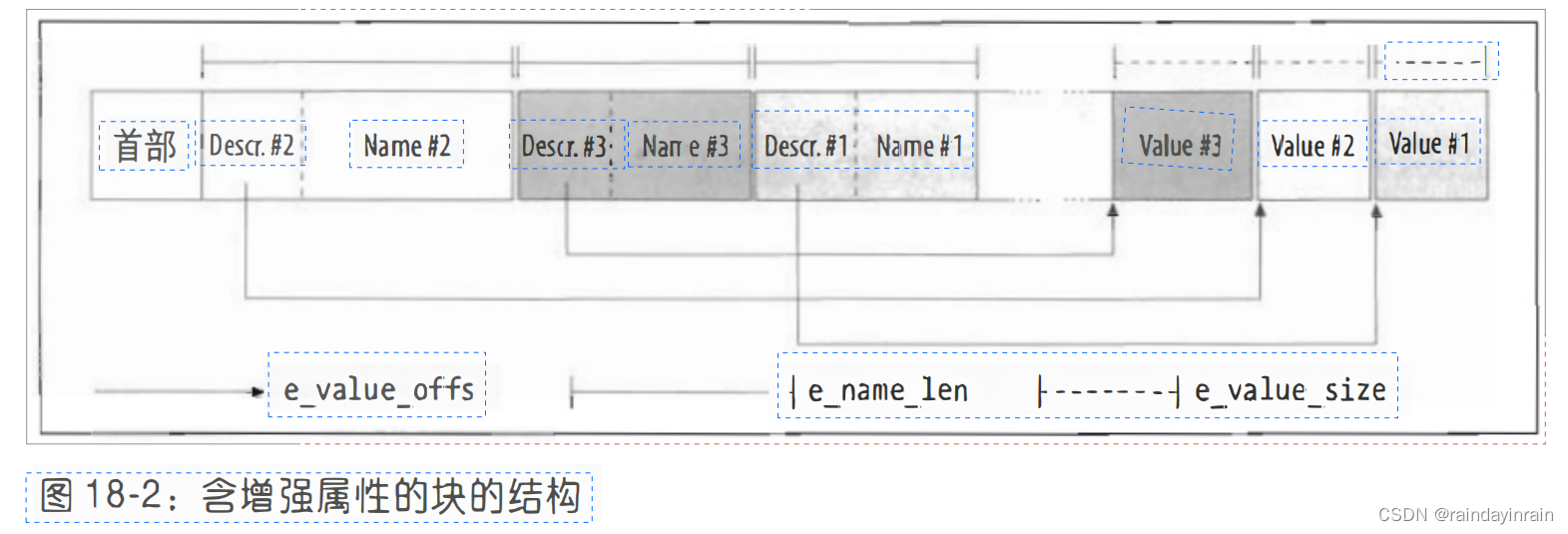
图18-2表示Ext2中增强属性块的结构。
每个属性分成两部分:在块首部的是ext2_xattr_entry描述符与属性名,而属性值则在块尾部。
块前面的表项按照属性名称排序,而值的位置是固定的,因为它们是由属性的分配次序决定的。
有很多系统调用用来设置、取得、列表和删除一个文件的增强属性。
系统调用setxattr()、lsetxattr()和fsetxattr()设置文件的增强属性,它们在符号链接的处理与文件限定的方式(或者传递路径名或者是文件描述符)上根本不同。
类似地,系统调用getxattr()、lgetxattr()和fgetxattr()返回增强属性的值。系统调用listxattr()、llistxattr()和flistxattr()则列出一个文件的所有增强属性。
最后,系统调用removexattr()、lremovexattr()和fremovexattr()从文件删除一个增强属性。
访问控制列表
很早以前访问控制列表就被建议用来改善Unix文件系统的保护机制。
不是将文件的用户分成三类:拥有者、组和其他,
访问控制列表(access controllist,ACL)可以与每个文件关联。有了这种列表,用户可以为他的文件限定可以访问的用户(或用户组)名称以及相应的权限。
Linux 2.6通过索引节点的增强属性完整实现ACL。
实际上,增强属性主要就是为了支持ACL才引入的。
因此,能让你处理文件ACL的库函数chacl()、setfacl()和getfacl()就是通过上一节中介绍的setxattr()和getxattr()系统调用实现的。
不幸的是,在POSIX 1003.1系列标准内,定义安全增强属性的工作组所完成的成果从没有正式成为新的POSIX标准。
因此现在,不同的类Unix文件系统都支持ACL,但不同的实现之间有一些微小的差别。
各种文件类型如何使用磁盘块
Ext2所认可的文件类型(普通文件、管道文件等)以不同的方式使用数据块。有些文件不存放数据,因此根本就不需要数据块。
本节讨论每种文件类型的存储要求,如表18-4所示。

普通文件
普通文件是最常见的情况,本章主要关注它。但普通文件只有在开始有数据时才需要数据块。
普通文件在刚创建时是空的,并不需要数据块;
也可以用truncate()或open()系统调用清空它。这两种情况是相同的,
例如,当你发出一个包含字符串>filename的shell命令时,shell创建一个空文件或截断一个现有文件。
目录
Ext2以一种特殊的文件实现了目录,这种文件的数据块把文件名和相应的索引节点号存放在一起。
特别说明的是,这样的数据块包含了类型为ext2_dir_entry_2的结构。
表18-5列出了这个结构的字段。因为该结构最后一个name字段是最大为EXT2_NAME_LEN (通常是255)个字符的变长数组,因此这个结构的长度是可变的。
此外,因为效率的原因,目录项的长度总是4的倍数,并在必要时用null字符(10)填充文件名的末尾。
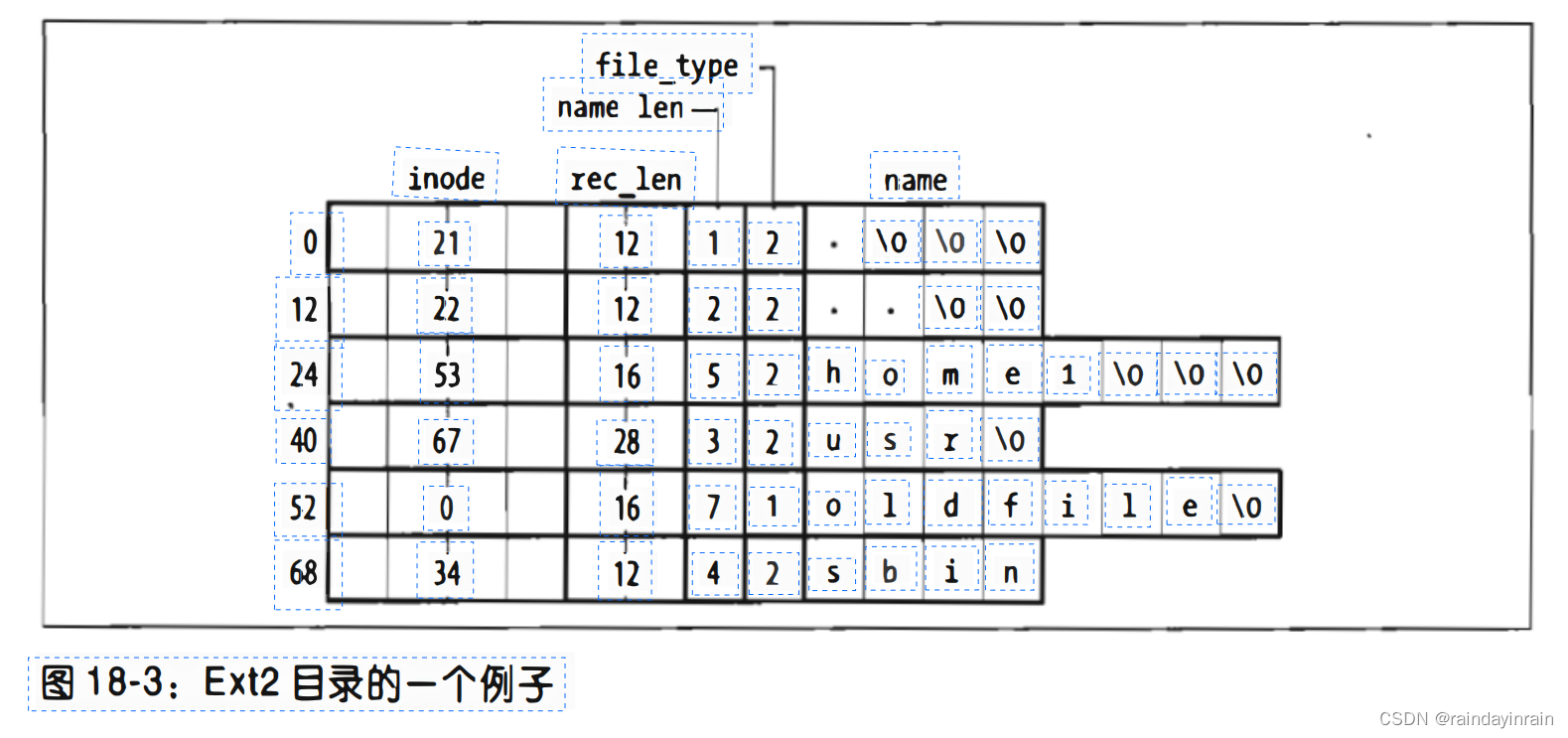
name_len字段存放实际的文件名长度(参见图18-3)。
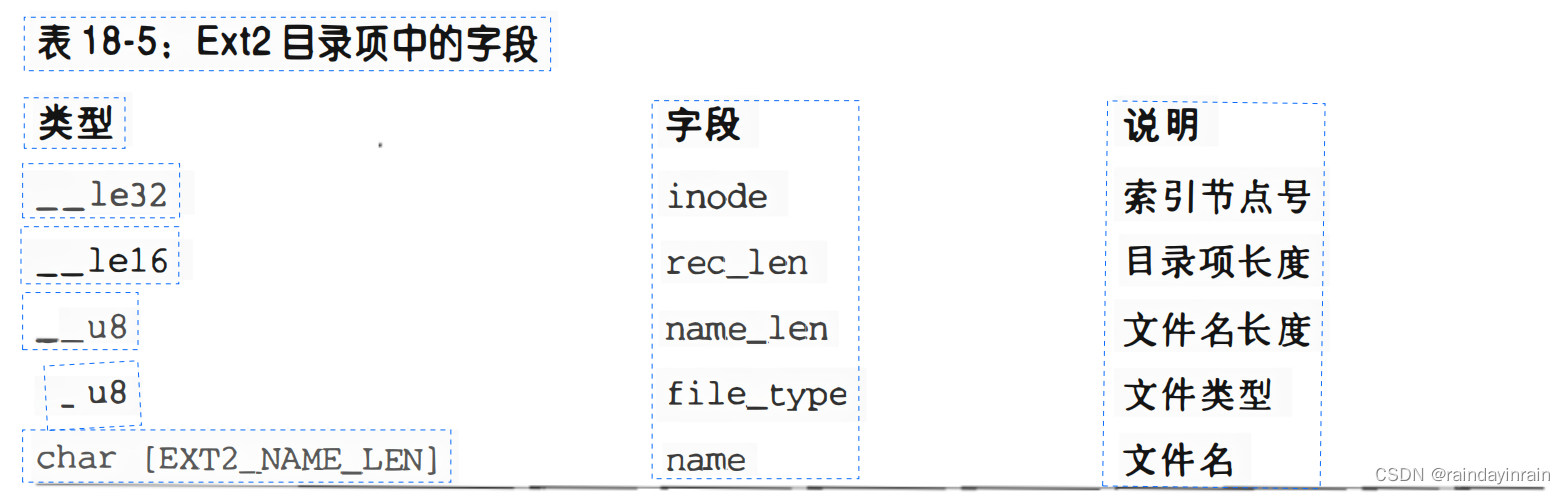
file_type字段存放指定文件类型的值(见表18-4)。
rec_len字段可以被解释为指向下一个有效目录项的指针:它是偏移量,与目录项的起始地址相加就得到下一个有效目录项的起始地址。
为了删除一个目录项,把它的inode字段置为0并适当地增加前一个有效目录项rec_len字段的值就足够了。
仔细看一下图18-3的rec_len字段,你会发现oldfile 项已被删除,因为usr的rec_len字段被置为12+16(usr和oldfile目录项的长度)。
符号链接
如前所述,如果符号链接的路径名小于等于60个字符,就把它存放在索引节点的i_blocks字段,该字段是由15个4字节整数组成的数组,因此无需数据块。
但是,如果路径名大于60个字符,就需要一个单独的数据块。
设备文件、管道和套接字
这些类型的文件不需要数据块。所有必要的信息都存放在索引节点中。
Ext2的内存数据结构
为了提高效率,当安装Ext2文件系统时,存放在Ext2分区的磁盘数据结构中的大部分信息被拷贝到RAM中,从而使内核避免了后来的很多读操作。
那么一些数据结构如何经常更新呢?让我们考虑一些基本的操作:
1.当一个新文件被创建时,必须减少Ext2超级块中s_free_inodes_count字段的值和相应的组描述符中bg_free_inodes_count字段的值。
2.如果内核给一个现有的文件追加一些数据,以使分配给它的数据块数因此也增加,
那么就必须修改Ext2超级块中s_free_blocks_count字段的值和组描述符中bg_free_blocks_count字段的值。
3.即使仅仅重写一个现有文件的部分内容,也要对Ext2超级块的s_wtime字段进行更新。
因为所有的Ext2磁盘数据结构都存放在Ext2分区的块中,因此,内核利用页高速缓存来保持它们最新(参见第十五章中的“把脏页写入磁盘”一节)。
对于与Ext2文件系统以及文件相关的每种数据类型,
表18-6详细说明了在磁盘上用来表示数据的数据结构、在内存中内核所使用的数据结构以及决定使用多大容量高速缓存的经验方法。
频繁更新的数据总是存放在高速缓存,也就是说,这些数据一直存放在内存并包含在页高速缓存中,直到相应的Ext2分区被卸载。
内核通过让缓冲区的引用计数器一直大于0来达到此目的。


在任何高速缓存中不保存“从不缓存”的数据,因为这种数据表示无意义的信息。
相反,“总是缓存”的数据也总在RAM中,这样就不必从磁盘读数据了(但是,数据必须周期性地写回磁盘)。
除了这两种极端模式外,还有一种动态模式。
在动态模式下,只要相应的对象(索引节点、数据块或位图)还在使用,它就保存在高速缓存中;
而当文件关闭或数据块被删除后,页框回收算法会从高速缓存中删除有关数据。
有意思的是,索引节点与块位图并不永久保存在内存里,而是需要时从磁盘读。
有了页高速缓存,最近使用的磁盘块保存在内存里,这样可以避免很多磁盘读(参见第十五章“把块存放在页高速缓存中”一节)(注2)。
Ext2的超级块对象
在第十二章“超级块对象”一节我们介绍过,VFS超级块的s_fs_info字段指向一个包含文件系统信息的数据结构。
对于Ext2,该字段指向ext2_sb_info类型的结构,它包含如下信息:
1.磁盘超级块中的大部分字段
2.s_sbh指针,指向包含磁盘超级块的缓冲区的缓冲区首部
3.s_es指针,指向磁盘超级块所在的缓冲区
4.组描述符的个数s_desc_per_block,可以放在一个块中
5.s_group_desc指针,指向一个缓冲区(包含组描述符的缓冲区)首部数组(通常一项就够)
6.其他与安装状态、安装选项等有关的数据
图18-4表示的是与Ext2超级块和组描述符有关的缓冲区与缓冲区首部和ext2_sb_info 数据结构之间的关系。
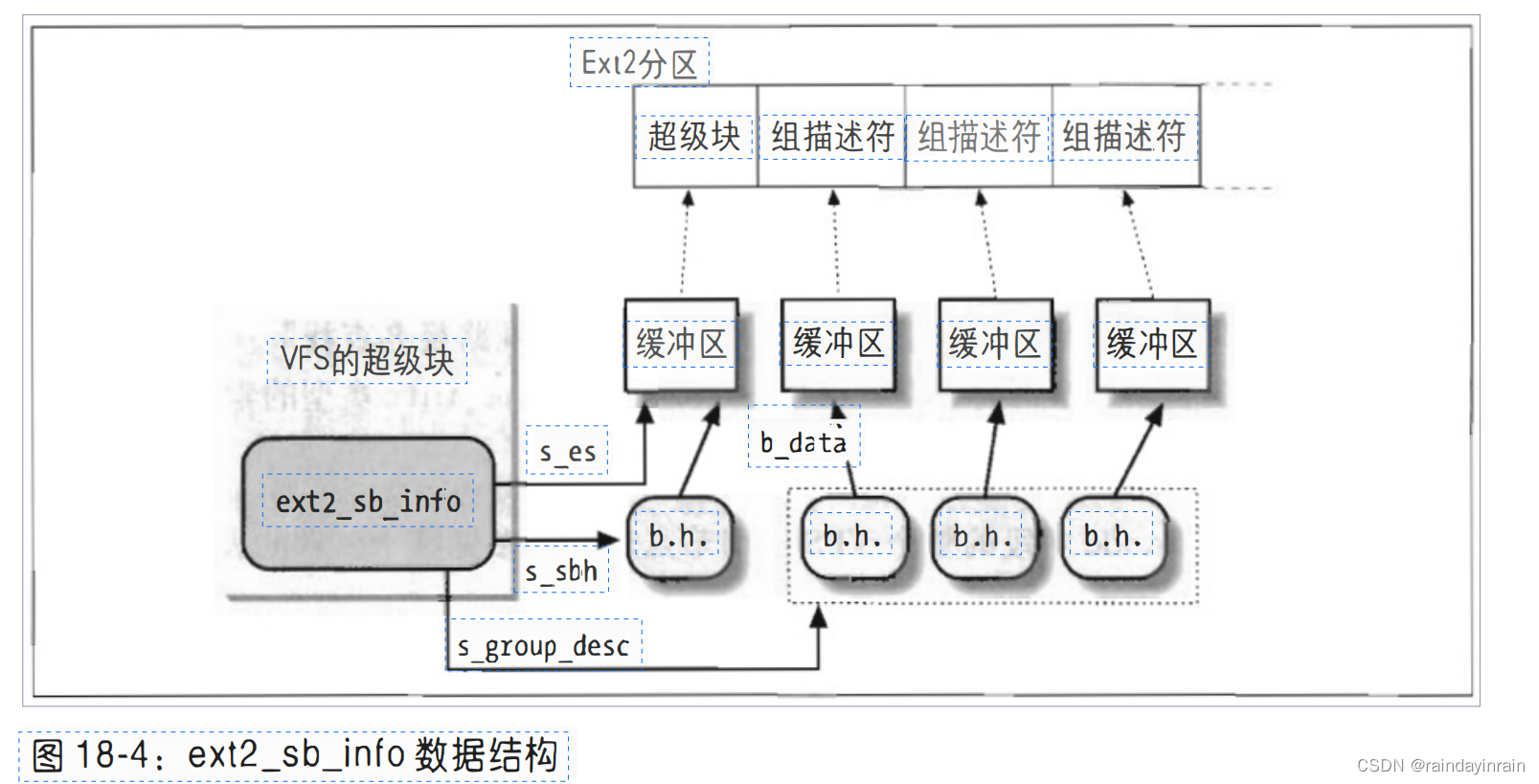
当内核安装Ext2文件系统时,它调用ext2_fill_super()函数来为数据结构分配空间,并写入从磁盘读取的数据(参见第十二章“安装普通文件系统”一节)。
这里是对该函数的一个简要说明,只强调缓冲区与描述符的内存分配。
1. 分配一个ext2_sb_info描述符,将其地址当作参数传递并存放在超级块的s_fs_info字段。
2. 调用__bread()在缓冲区页中分配一个缓冲区和缓冲区首部。然后从磁盘读入超级块存放在缓冲区中。
在第十五章的“在页高速缓存中搜索块”一节我们讨论过,如果一个块已在页高速缓存的缓冲区页而且是最新的,那么无需再分配。
将缓冲区首部地址存放在Ext2超级块对象的s_sbh字段。
3. 分配一个字节数组,每组一个字节,把它的地址存放在ext2_sb_info描述符的s_debts字段(参见本章后面的“创建索引节点”一节)。
4. 分配一个数组用于存放缓冲区首部指针,每个组描述符一个,把该数组地址存放在ext2_sb_info的s_group_desc字段。
5. 重复调用__bread()分配缓冲区,从磁盘读入包含Ext2组描述符的块。把缓冲区首部地址存放在上一步得到的s_group_desc数组中。
6. 为根目录分配一个索引节点和目录项对象,为超级块建立相应的字段,从而能够从磁盘读入根索引节点对象。
很显然,ext2_fill_super()函数返回后,分配的所有数据结构都保存在内存里,只有当Ext2文件系统卸载时才会被释放。
当内核必须修改Ext2超级块的字段时,它只要把新值写入相应缓冲区内的相应位置然后将该缓冲区标记为脏即可。
Ext2的索引节点对象
在打开文件时,要执行路径名查找。对于不在目录项高速缓存内的路径名元素,
会创建一个新的目录项对象和索引节点对象(参见第十二章“标准路经名查找”一节)。
当VFS 访问一个Ext2磁盘索引节点时,它会创建一个ext2_inode_info类型的索引节点描述符。该描述符包含下列信息:
1.存放在vfs_inode字段的整个VFS索引节点对象(参见第十二章的表12-3)
2.磁盘索引节点对象结构中的大部分字段(不保存在VFS索引节点中)
3.索引节点对应的i_block_group块组索引(参见本章前面“Ext2磁盘数据结构”一节)
4.i_next_alloc_block和i_next_alloc_goal字段,分别存放着最近为文件分配的磁盘块的逻辑块号与物理块号
5.i_prealloc_block和i_prealloc_count字段,用于数据块预分配(参见本章后面“分配数据块”一节)
6.xattr_sem字段,一个读写信号量,允许增强属性与文件数据同时读入
7.i_acl和i_default_acl字段,指向文件的ACL
当处理Ext2文件时,alloc_inode超级块方法是由ext2_alloc_inode()函数实现的。
它首先从ext2_inode_cachep slab分配器高速缓存得到一个ext2_inode_info描述符,然后返回在这个ext2_inode_info描述符中的索引节点对象的地址。
创建Ext2文件系统
在磁盘上创建一个文件系统通常有两个阶段。
第二步格式化磁盘,以使磁盘驱动程序可以读和写磁盘上的块。
现在的硬磁盘已经由厂家预先格式化,因此不需要重新格式化;
在Linux上可以使用superformat或fdformat等实用程序对软盘进行格式化。第二步才涉及创建文件系统,这意味着建立本章前面详细描述的结构。
Ext2文件系统是由实用程序mke2fs创建的。mke2fs采用下列缺省选项,用户可以用命令行的标志修改这些选项:
1.块大小:1024字节(小文件系统的缺省值)
2.片大小:块的大小(块的分片还没有实现)
3.所分配的索引节点个数:每8192字节的组分配一个索引节点·
4.保留块的百分比:5%
mke2fs程序执行下列操作:
1. 初始化超级块和组描述符。
2. 作为选择,检查分区是否包含有缺陷的块;
如果有,就创建一个有缺陷块的链表。
3. 对于每个块组,保留存放超级块、组描述符、索引节点表及两个位图所需要的所有磁盘块。
4. 把索引节点位图和每个块组的数据映射位图都初始化为0。
5. 初始化每个块组的索引节点表。
6. 创建/root目录。
7. 创建lost+found目录,由e2fsck使用这个目录把丢失和找到的缺陷块连接起来。
8. 在前两个已经创建的目录所在的块组中,更新块组中的索引节点位图和数据块位图。
9. 把有缺陷的块(如果存在)组织起来放在lost+found目录中。
让我们看一下mke2fs是如何以缺省选项初始化Ext2的1.44 MB软盘的。
软盘一旦被安装,VFS就把它看作由1412个块组成的一个卷,每块大小为1024字节。为了查看磁盘的内容,我们可以执行如下Unix命令:
s dd if=/dev/fd0 bs=1k count=1440lod-tx1-Ax>/tmp/dump_hex
从而获得了/mp目录下的一个文件,这个文件包含十六进制的软盘内容的转储(注3)。
通过查看dump_hex文件我们可以看到,由于软盘有限的容量,一个单独的块组描述符就足够了。
我们还注意到保留的块数为72(1440块的5%),并且根据缺省选项,索引节点表必须为每8192个字节设置一个索引节点,也就是有184个索引节点存放在23个块中。
表18-7总结了按缺省选项如何在软盘上建立Ext2文件系统。

Ext2的方法
在第十二章所描述的关于VFS的很多方法在Ext2都有相应的实现。
因为对所有的方法都进行描述将需要整整一本书,因此我们仅仅简单地回顾一下在Ext2中所实现的方法。
一旦你真正搞明白了磁盘和内存数据结构,你就应当能理解实现这些方法的Ext2函数的代码。
Ext2超级块的操作
很多VFS超级块操作在Ext2中都有具体的实现,
这些方法为alloc_inode、destroy_inode、readinode、write_inode、delete_inode、put_super、write_super、statfs、remount_fs和clear_inode。
超级块方法的地址存放在ext2_sops指针数组中
Ext2索引节点的操作
一些VFS索引节点的操作在Ext2中都有具体的实现,这取决于索引节点所指的文件类型。
Ext2的普通文件和目录文件的索引节点操作见表18-8。每个方法的目的在第十二章的“索引节点对象”一节有介绍。
表中没有列出普通文件和目录中未定义的方法(NULL指针)。
回忆一下,如果方法未定义,VFS要么调用通用函数,要么什么也不做。
普通文件与目录的Ext2方法地址分别存放在ext2_file_inode_operations和ext2_dir_inode_operations 表中。


Ext2的符号链接的索引节点操作见表18-9(省略未定义的方法)。
实际上有两种符号链接:快速符号链接(路径名全部存放在索引节点内)与普通符号链接(较长的路径名)。
因此,有两套索引节点操作,分别存放在ext2_fast_symlink_inode_operations和ext2_symlink_inode_operations表中


如果索引节点指的是一个字符设备文件、块设备文件或命名管道(参见第十九章中的“FIFO”一节),
那么这种索引节点的操作不依赖于文件系统,其操作分别位于chrdev_inode_operations、blkdev_inode_operations和fifo_inode_operations 表中。
Ext2的文件操作
表18-10列出了Ext2文件系统特定的文件操作。
正如你看到的,一些VFS方法是由很多文件系统共用的通用函数实现的。这些方法的地址存放在ext2_file_operations表中。

注意,Ext2的read和write方法是分别通过generic_file_read()和generic_file_write()函数实现的。
这两个函数在第十五章的“从文件中读取数据”和“写入文件”两节进行了描述。
管理Ext2磁盘空间
文件在磁盘的存储不同于程序员所看到的文件,这表现在两个方面:
块可以分散在磁盘上(尽管文件系统尽力保持块连续存放以提高访问速度),以及程序员看到的文件似乎比实际的文件大,
这是因为程序可以把洞引入文件(通过lseek()系统调用)。
在本节,我们将介绍Ext2文件系统如何管理磁盘空间,也就是说,如何分配和释放索引节点和数据块。有两个主要的问题必须考虑:
1.空间管理必须尽力避免文件碎片,也就是说,避免文件在物理上存放于几个小的、不相邻的盘块上。
2.文件碎片增加了对文件的连续读操作的平均时间,因为在读操作期间,磁头必须频繁地重新定位(注4)。
这个问题类似于在第八章的“伙伴系统算法”一节中所讨论的RAM的外部碎片问题。
3.空间管理必须考虑效率,也就是说,内核应该能从文件的偏移量快速地导出Ext2 分区上相应的逻辑块号。
为了达到此目的,内核应该尽可能地限制对磁盘上寻址表的访问次数,因为对该表的访问会极大地增加文件的平均访问时间。
创建索引节点
ext2_new_inode()函数创建Ext2磁盘的索引节点,返回相应的索引节点对象的地址(或失败时为NULL)。
该函数谨慎地选择存放该新索引节点的块组;
它将无联系的目录散放在不同的组,而且同时把文件存放在父目录的同一组。
为了平衡普通文件数与块组中的目录数,Ext2为每一个块组引入“债(debt)”参数。
该函数作用于两个参数:
dir,一个目录对应的索引节点对象的地址,新创建的索引节点必须插入到这个目录中;
mode,要创建的索引节点的类型。
后一个参数还包含一个MS_SYNCHRONOUS标志,该标志请求当前进程一直挂起,直到索引节点被分配。该函数执行如下操作:
1.调用new_inode()分配一个新的VFS索引节点对象,并把它的i_sb字段初始化为存放在dir->i_sb中的超级块地址。
然后把它追加到正在用的索引节点链表与超级块链表中(参见第十二章“索引节点对象”一节)。
2. 如果新的索引节点是一个目录,函数就调用find_group_orlov()为目录找到一个合适的块组(注5)。该函数执行如下试探法:
a.以文件系统根root为父目录的目录应该分散在各个组。这样,函数在这些块组去查找一个组,它的空闲索引节点数和空闲块数比平均值高。
如果没有这样的组则跳到第2c步。
b.如果满足下列条件,嵌套目录(父目录不是文件系统根root)就应被存放到父目录组:
b.1.该组没有包含太多的目录
b.2.该组有足够多的空闲索引节点
b.3.该组有一点小“债”。(块组的债存放在一个ext2_sb_info描述符的s_debts字段所指向的计数器数组中。
每当一个新目录加入,债加一;每当其他类型的文件加入,债减一)
如果父目录组不满足这些条件,那么选择第一个满足条件的组。如果没有满足条件的组,则跳到第2c步。
c.这是一个“退一步”原则,当找不到合适的组时使用。函数从包含父目录的块组开始选择第一个满足条件的块组,
这个条件是:它的空闲索引节点数比每块组空闲索引节点数的平均值大。
3. 如果新索引节点不是个目录,则调用find_group_other(),在有空闲索引节点的块组中给它分配一个。该函数从包含父目录的组开始往下找。具体如下:
a. 从包含父目录dir的块组开始,执行快速的对数查找。这种算法要查找log(n)个块组,这里n是块组总数。
该算法一直向前查找直到找到一个可用的块组,
具体如下:如果我们把开始的块组称为i,那么,该算法要查找的块组为imod(n),i+1 mod(n),i+1+2 mod(n),i+l+2+4 mod(n),等等。
b.如果该算法没有找到含有空闲索引节点的块组,就从包含父目录dir的块组开始执行彻底的线性查找。
4.调用read_inode_bitmap()得到所选块组的索引节点位图,并从中寻找第一个空位,这样就得到了第一个空闲磁盘索引节点号。
5.分配磁盘索引节点:把索引节点位图中的相应位置位,并把含有这个位图的缓冲区标记为脏。
此外,如果文件系统安装时指定了MS_SYNCHRONOUS标志(参见第十二章中的“安装普通文件系统”一节),
则调用sync_dirty_buffer()开始I/O写操作并等待,直到写操作终止。