关于作者:CSDN内容合伙人、技术专家, 从零开始做日活千万级APP。
专注于分享各领域原创系列文章 ,擅长java后端、移动开发、商业变现、人工智能等,希望大家多多支持。
目录
- 一、导读
- 二、概览
- 三、使用
- 四、原理
- 五、存在的问题
- 六、优化
- 6.1 DataStore
- 6.2 MMKV
- 6.3 sp优化
- 七、 推荐阅读

一、导读
我们继续总结学习Java基础知识,温故知新。
二、概览
SharedPreferences 是 Android 平台上用于存储轻量级键值对数据的一种机制。它提供了一种简单的方式来保存和获取应用程序的数据。
SharedPreferences 存储的数据是基于键值对的,每个存储项都有一个唯一的键和对应的值。可以通过键来检索特定的值,也可以修改、添加或删除已存储的值。
SharedPreferences 存储的数据是持久化的,即使应用程序被关闭或设备重启,存储的数据仍然可用。
SharedPreferences 首次初始化时把整个xml文件加载到内存中,在使用过程中容易出现ANR,主要是因为加锁及线程等待。
ANR发生在QueuedWork.waitToFinish()方法。
三、使用
SharedPreferences 的使用非常方便,最终数据是以xml文件的形式存在在 /data/data/项目包名/shared_prefs/sp_name.xml文件
// 1、获取实例
SharedPreferences sp = mContext.getSharedPreferences("sp_name", Context.MODE_PRIVATE);
// 2、获取edit
SharedPreferences.Editor edit = sp.edit();
// 3、以key - value 的方式存储
edit.putInt("KEY_SOPHIX", 0);
// 4、异步写入数据
edit.apply();
// 4、同步写入数据
edit.commit();
// 1、获取实例
SharedPreferences sp = getContext().getSharedPreferences("sp_name", Context.MODE_PRIVATE);
// 2、通过key 获取value,后面一个是默认值
String var1 = sp.getString("key", "");
四、原理
SharedPreferences 基于键值对的存储原理。它是通过一个 XML 文件来保存数据,文件位于应用的私有存储空间中。
并且是基于内存缓存的, SharedPreferences在读取xml文件时,会把整个xml文件加载到内存中,并以DOM的形式进行解析。
当应用程序再次访问同一个 SharedPreferences 对象时,系统会直接从内存中读取数据,而不是每次都从 XML 文件中读取。
当新增一个K-V时,写入磁盘是全量更新,即会把之前的文件再次更新一遍。
所以SharedPreferences适用于存储轻量级的数据。
我们在调用getxxx方法时,获取到的数据是内存中的数据,
在保存数据时,也是先保存在内存,再写入文件。
String getString(String key, @Nullable String defValue);
@Override
@Nullable
public String getString(String key, @Nullable String defValue) {
synchronized (mLock) {
awaitLoadedLocked();
String v = (String)mMap.get(key);
return v != null ? v : defValue;
}
}
@Override
public Editor putString(String key, @Nullable String value) {
synchronized (mEditorLock) {
mModified.put(key, value);
return this;
}
}
commit保存数据,先内存,再磁盘,这是一个同步的过程
@Override
public boolean commit() {
long startTime = 0;
// 数据保存到内存
MemoryCommitResult mcr = commitToMemory();
// 数据保存到磁盘文件
SharedPreferencesImpl.this.enqueueDiskWrite(
mcr, null /* sync write on this thread okay */);
try {
mcr.writtenToDiskLatch.await();
} catch (InterruptedException e) {
return false;
} finally {
}
notifyListeners(mcr);
return mcr.writeToDiskResult;
}
apply 保存数据,先内存,再异步保存到磁盘
@Override
public void apply() {
final long startTime = System.currentTimeMillis();
// 数据保存到内存
final MemoryCommitResult mcr = commitToMemory();
final Runnable awaitCommit = new Runnable() {
@Override
public void run() {
try {
看这里
//这里的操作使用CountDownLatch实现等待效果,writtenToDiskLatch类型是CountDownLatch(1)
里面啥也没干,就是进行阻塞
mcr.writtenToDiskLatch.await();
} catch (InterruptedException ignored) {
}
}
};
看这里
//将awaitCommit加入队列中,后续Activity的onStop()中即会执行这个Runnable等待
QueuedWork.addFinisher(awaitCommit);
Runnable postWriteRunnable = new Runnable() {
@Override
public void run() {
awaitCommit.run();
QueuedWork.removeFinisher(awaitCommit);
}
};
// 数据异步保存到磁盘
SharedPreferencesImpl.this.enqueueDiskWrite(mcr, postWriteRunnable);
notifyListeners(mcr);
}
加锁
QueuedWork.java
这个就是后面 Activity的onStop()、Service的onDestroy()执行时,QueuedWork.waitToFinish()里面要执行的线程
public static void addFinisher(Runnable finisher) {
synchronized (sLock) {
sFinishersField.add(finisher);
}
}
写文件后释放锁
SharedPreferencesImpl.java
private void writeToFile(MemoryCommitResult mcr, boolean isFromSyncCommit) {
mcr.setDiskWriteResult(false, true);
}
看这里
void setDiskWriteResult(boolean wasWritten, boolean result) {
这里就是上面awaitCommit 线程
writtenToDiskLatch.countDown();
}
五、存在的问题
- 读取xml文件时,会把整个xml文件直接加载到内存中解析,如果文件过大,容易出内存问题。
- 文件数据的读取都加锁,如果SP 文件未被加载或解析到内存中,读写操作都需要等待,可能会对UI线程流畅度造成一定影响,甚至ANR.
- 在保存数据,apply 及 commit 都会出现ANR问题。
具体可以看上面的源码, apply 其实利用了CountDownLatch机制,阻塞了当前线程,后续 Activity 的onStop()
中会将这里的awaitCommit取出来执行,即UI线程会阻塞等待sp文件写入磁盘。
所以我们有的时候可以看到退出一个页面的时候,感觉也会卡,因为阻塞了主线程。
Activity的onStop()、Service的onDestroy()执行时,都会调用到QueuedWork.waitToFinish()方法。
具体代码在ActivithThread.java
public static void waitToFinish() {
long startTime = System.currentTimeMillis();
try {
while (true) {
Runnable finisher;
synchronized (sLock) {
finisher = sFinishersField.poll();
}
if (finisher == null) {
break;
}
finisher.run();
}
} finally {
sCanDelay = true;
}
}
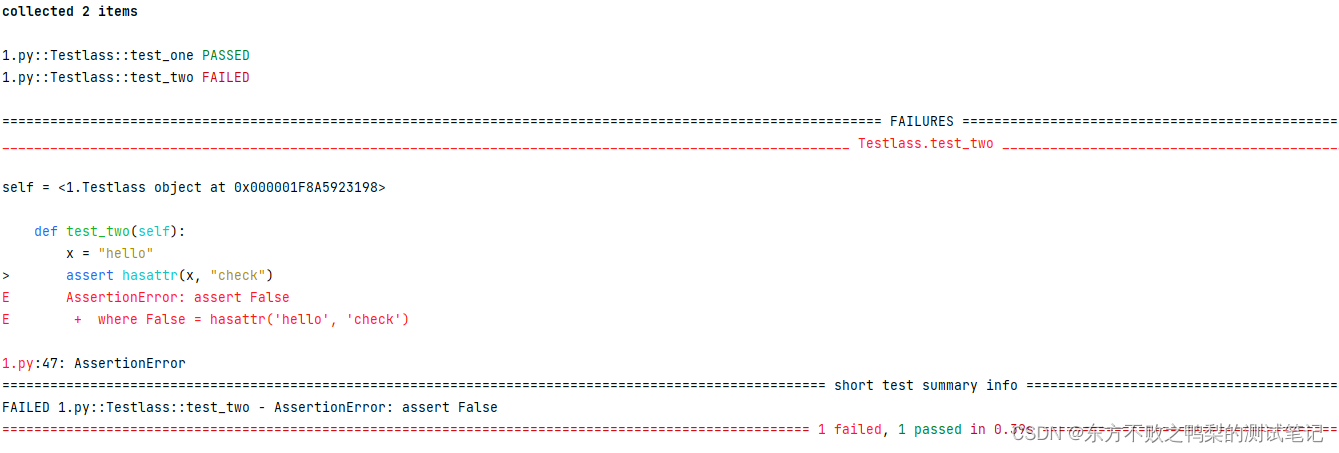
借用一张图总结下:
图片来自:今日头条 ANR 优化实践系列 - 告别 SharedPreference 等待
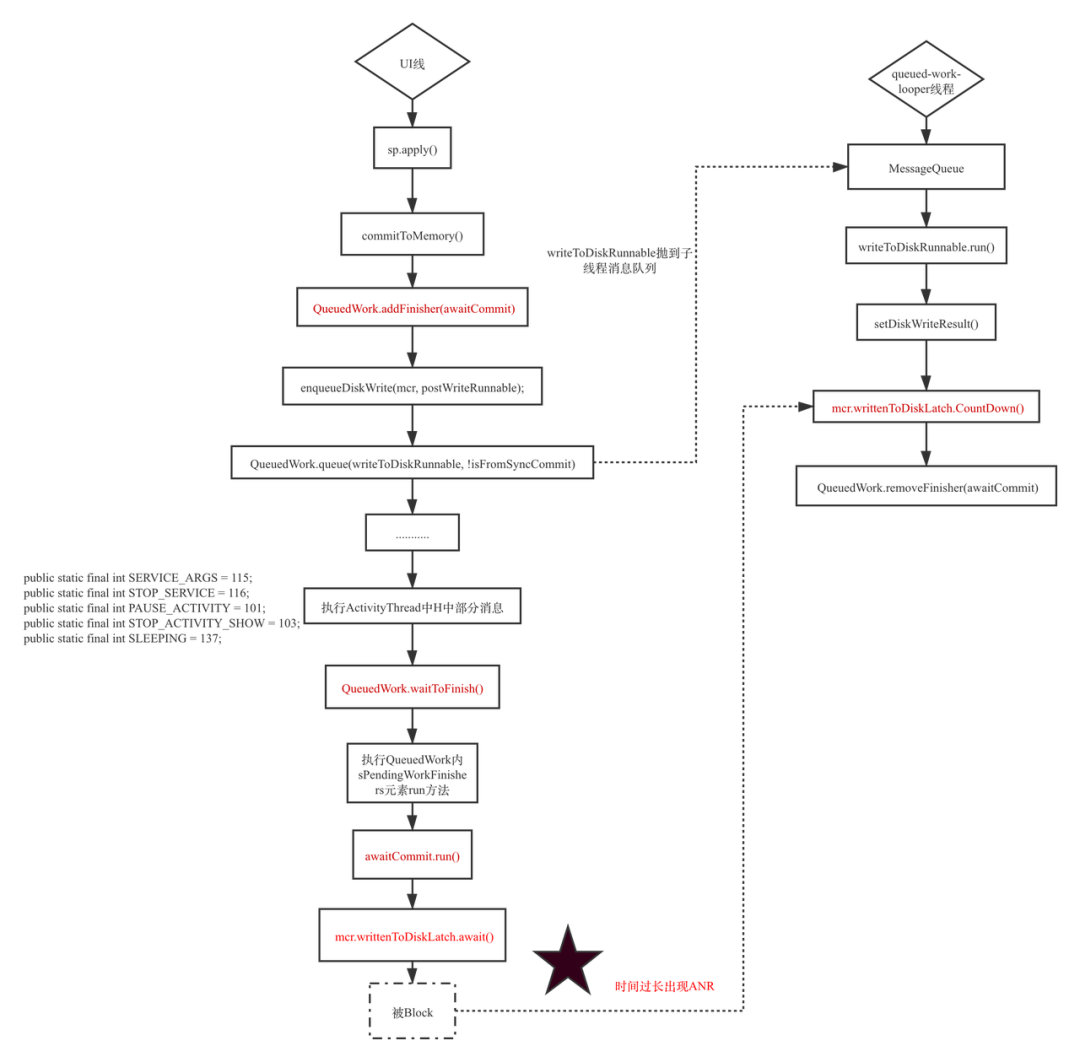
六、优化
6.1 DataStore
DataStore
6.2 MMKV
MMKV 是基于 mmap 内存映射的 key-value 组件,底层序列化/反序列化使用 protobuf 实现,性能高,稳定性强,且支持多进程访问。
使用起来也非常简单,先引入依赖
dependencies {
implementation 'com.tencent:mmkv:1.3.0'
// replace "1.3.0" with any available version
}
public void onCreate() {
super.onCreate();
String rootDir = MMKV.initialize(this);
System.out.println("mmkv root: " + rootDir);
//……
}
MMKV kv = MMKV.defaultMMKV();
kv.encode("bool", true);
boolean bValue = kv.decodeBool("bool");
kv.encode("int", Integer.MIN_VALUE);
int iValue = kv.decodeInt("int");
kv.encode("string", "Hello from mmkv");
String str = kv.decodeString("string");
MMKV地址:https://github.com/tencent/mmkv
6.3 sp优化
- SP文件按分类去加载存储,K-V数据不要太多。
- 利用反射,使waitToFinish 失效
参考头条的文章,如果需要主线程在 waitToFinish 的时候直接跳过去,让 sPendingWorkFinishers.poll()返回为 null,
则这里的等待行为直接就跳过去了,sPendingWorkFinishers 是个 ConcurrentLinkedQueue 集合,
可以直接动态代理这个集合,复写 poll 方法,让其永远返回 null,这个时候 UI 永远不会等待子线程写入文件完毕。
ActivithThread.java
public static void waitToFinish() {
try {
看这里,这里也可能发生ANR 哦,
processPendingWork();
} finally {
StrictMode.setThreadPolicy(oldPolicy);
}
try {
while (true) {
synchronized (sLock) {
finisher = sFinishersField.poll();
}
看这里,不让它执行即可,
if (finisher == null) {
break;
}
finisher.run();
}
} finally {
}
}
为什么可以这么做呢,我们回头看看源码,这里面加入进来的线程,其实就一个线程阻塞的方法,
我们不让它运行,就不会阻塞主线程了。
mcr.writtenToDiskLatch.await();
Class<?> aClass = Class.forName("android.app.QueuedWork");
if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.O && Build.VERSION.SDK_INT <= Build.VERSION_CODES.S) {
获取指定name名称的(包含private修饰的)字段,不包括继承的字段
Field sFinishersField = aClass.getDeclaredField("sFinishersField");
将此对象的 accessible 标志设置为指示的布尔值,即设置其可访问性
sFinishersField.setAccessible(true);
返回指定对象上此 Field 表示的字段的值,这里返回的是 LinkedList<Runnable> sFinishersField = new LinkedList<>()
LinkedList<?> sPendingWorkFinishers = (LinkedList<?>) sFinishersField.get(null);
HookLinkedList<?> proxyFinishers = new HookLinkedList<>(sPendingWorkFinishers);
将指定对象变量上此 Field 对象表示的字段设置为指定的新值。
sFinishersField.set(null, proxyFinishers);
}
private static class HookLinkedList<T> extends LinkedList<T> {
private final LinkedList<T> linkedList;
public HookLinkedList(LinkedList<T> linkedList) {
this.linkedList = linkedList;
}
/**
* always return null
*/
@Nullable
@Override
public T poll() {
return null;
}
@Override
public boolean add(T t) {
return linkedList.add(t);
}
@Override
public boolean isEmpty() {
return true;
}
@Override
public boolean remove(@Nullable Object o) {
return linkedList.remove(o);
}
}
由于源码不一样,8.0以下用以下方法,方式跟上面一样
Field sPendingWorkFinishers = aClass.getDeclaredField("sPendingWorkFinishers");
sPendingWorkFinishers.setAccessible(true);
ConcurrentLinkedQueue<?> sPendingWorkFinishers = (ConcurrentLinkedQueue<?>) sPendingWorkFinishers.get(null);
SpConcurrentLinkedQueue<?> proxyFinishers = new SpConcurrentLinkedQueue<>(sPendingWorkFinishers);
sPendingWorkFinishers.set(null, proxyFinishers);
private static class SpConcurrentLinkedQueue<T> extends ConcurrentLinkedQueue<T> {
private final ConcurrentLinkedQueue<T> concurrentLinkedQueue;
public MyConcurrentLinkedQueue(ConcurrentLinkedQueue<T> concurrentLinkedQueue) {
this.concurrentLinkedQueue = concurrentLinkedQueue;
}
/**
* always return null
*/
@Nullable
@Override
public T poll() {
return null;
}
@Override
public boolean remove(@Nullable Object o) {
return concurrentLinkedQueue.remove(o);
}
@Override
public boolean isEmpty() {
return true;
}
@Override
public boolean add(T t) {
return concurrentLinkedQueue.add(t);
}
}
processPendingWork的ANR 也要处理下,这里有两个block点
- 异步线程正在执行 processPendingWork函数,异步工作线程持有 sProcessingWork锁,因此主线程执行 processPendingWork时 ,因为获取不到 sProcessingWork锁 ,出现锁等待
- 当主线程成功获取到 sProcessingWork锁,调用clone函数时,sWork队列中 确实存在未执行的任务,这部分任务将在主线程直接执行,如果此时IO操作较慢,则主线程因为慢IO出现阻塞甚至ANR
思路原理:
无论实在哪个线程执行,代理的clone函数都返回空队列,这样保证了processPendingWork的调用不会出现互相阻塞,相当于processPendingWork实际上没有执行任何操作, 并且通过反射获取QueuedWork的mHandler的Looper对象,创建一个新的Hander,并将sWork中的任务提交到这个Handler去执行,从而实现了无阻塞运行
推荐一个大佬的开源,里面有完整的处理代码,
再借一张大佬图:
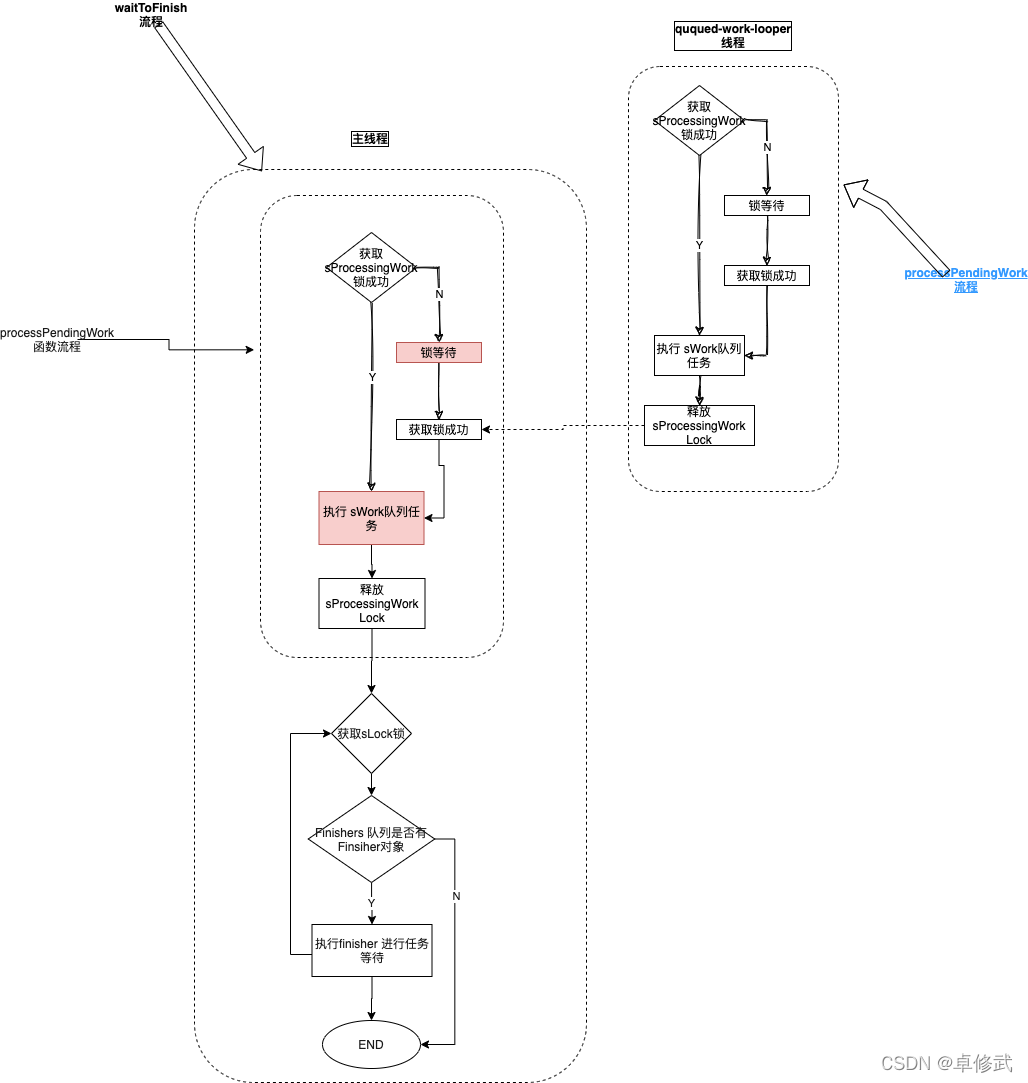
github: https://github.com/Knight-ZXW/SpWaitKiller
七、 推荐阅读
Java 专栏
SQL 专栏
数据结构与算法
Android学习专栏

![【LeetCode-经典面试150题-day9]](https://img-blog.csdnimg.cn/img_convert/782086183cb0869cded4e389e8150bd7.jpeg)