访问外部硬件有两个方式:
- 将某个外设的内存映射到一定范围的地址空间中, CPU 通过地址总线访问该内存区域时会落到外设
的内存中,这种映射让 CPU 访问外设的内存就如同访问主板上的物理内存一样 - 外设是通过 IO 接口与 CPU 通信的, CPU 访问外设,就是访问 IO 接口,由 IO 接口将信息传递
给另一端的外设,也就是说, CPU 从来不知道有这些设备的存在,它只知道自己操作的 IO 接口
如何访问到 IO 接口呢,答案就是 IO 接口上面有一些寄存器,访问 IO 接口本质上就是访问这些寄存器,这些寄存器就是人们常说的端口。
“陷入”内核:从低特权级的用户程序进入高特权级的内核程序,即CPU进入内核态,又称管态
指令大小是由实际指令的操作码决定的,也就是说 CPU 在译码阶段拿到了操作码后,就知道实际指令所占的大小。
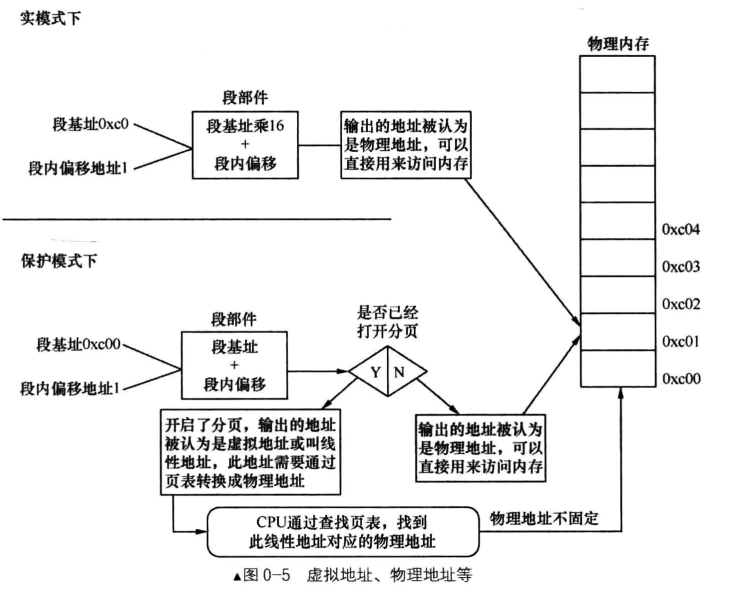
内存分段指的是处理器为访问内存而采用的机制,称之为内存分段机制,程序分段是软件中人为逻辑划分的内存区域,它本身也是内存,所以处理器在访问该区域时,也会采用内存分段机制,用段寄存器指向该区域的起始地址。
在实模式下,“段基址+段内偏移地址”经过段部件的处理,直接输出的就是物理地址, CPU可以直接用此地址访问内存。
而在保护模式下,“段基址+段内偏移地址”称为线性地址,不过,此时的段基址已经不再是真正的地址了,而是选择子 。 。若没有开启地址分页功能, 此线性地址就被当作物理地址来用,可直接访问内存。 若开启了分页功能,此线性地址又多了一个名字,就是虚拟地址 (虚拟地址、线性地址在分页机制下都是一回事) 。虚拟地址要经过页部件转换成具体的物理地址,这样 CPU 才能将其送上地址总线去访问内存。
无论在实模式或是保护模式下,段内偏移地址又称为有效地址,也称为逻辑地址,这是程序员可见的地址 。 这是因为,最终的地址是由段基址和段内偏移地址组合而成的。由于段基址已经有默认的啦,要么是在实模式下的默认段寄存器中,要么是在保护模式下的默认段选择子寄存器指向的段描述符中,所以只要给出段内偏移地址就行了,这个地址虽然只是段内偏移,但加上默认的段基址,依然足够有效 。
段重叠:同一个数据,可以由不同段地址+偏移地址访问到
平坦模型:是相对于多段模型来说的,所以说平坦模型指的就是一个段 。 比如在实模式下,访问超过64KB 的内存,需要重新指定不同的段基址。在保护模式下,由于其是 32 位的,寻址范围便能够达到 4GB ,段内偏移地址也是地址,所以也是 32 位 。 可见,在 32位环境下用一个段就能够访问到硬件所支持的所有内存 。 也就是说,段的大小可以是地址总线能够到达的范围 。相对于那么麻烦的多段模型,平坦模型不需要额外打开 A20 地址线,不需要来回切换段基址就可以在地址空间内任意朝翔。
全局的变量,意味着谁都可以随时随地访问,所以其放在数据段中 。 而局部变量只是自己在用,放在数据段中纯属琅费空间,没有必要,故将其放在自己的战中,随时可以清理,真正体现了局部的意义。
函数参数为什么会放到枝区呢?第一也是其局部性导致的,只有这个函数用这个参数,何必将其放在数据段呢 。 第二 ,这是因为函数是在程序执行过程中调用的,属于动态的调用,编译时无法预测会何时调用及被调用的次数,函数的参数及返回值都需要内存来存储,如果是递归调用的话,参数及返回值需要的内存空间也就不确定了,这取决于递归的次数。
不管什么语言,编译器最终翻译出来的都是机器指令 。 所以在这一点来说,汇编语言编译器编译 出来的机器指令和编译器编译出来的机器指令无异 。应该说汇编语言生成的指令数更少,从而“显得”执行得快。
编译型语言和解释型语言:解释型语言(脚本)本身只是一串字符,后台有一个进程(解释器)来读取它然后做出不同动作。编译型语言运行时本身就是一个进程
两种字节序的优势。
- 低端:因为低位在低字节,强制转换数据型时不需要再调整宇节了。
- 高端:有符号数,其字节最高位不仅表示数值本身,还起到了符号的作用。符号位固定为第一字
节,也就是最高位占据最低地址,符号直接可以取出来,容易判断正负。
section 称为节,是指在汇编源码中经由关键字 section 或 segment 修饰、逻辑划分的指令或数据 区域,汇编器会将这两个关键字修饰的区域在目标文件中编译成节,也就是说“节”最初诞生于目标文件中 。
segment 称为段,是链接器根据目标文件中属性相同的多个 section 合并后的 section 集合,这个集合称为 segment,也就是段,链接器把目标文件链接成可执行文件,因此段最终诞生于可执行文件中 。 我们平时所说的可执行程序内存空间中的代码段和数据段就是指的 segment。
不管定义了多少节名,最终要把属性相同的 section,或者编译认为可以放到一块的,合并到一个大的segment 中。由此可见,某个节( section )属于某个段( segment),段是由节组成的。
MBR:主引导程序,在 MBR 引导扇区中存储引导程序,为的是从 BIOS 手中接过系统的控制权,也就是处理器的使用权。 MBR需要找到内核加载器,即OBR
OBR:操作系统引导记录,即内核
DBR:OBR的前身,DOS Boot Record
EBR:MBR的扩充,整个硬盘只有1个 MBR,其位于整个硬盘最开始的扇区,而 EBR 可有无数个,具体位置取决于扩展分区的分配情况
DBR、 OBR 、 MBR、 EBR 都包含引导程序,因此它们都称为引导扇区,只要该扇区中存在可执行的程序,该扇区就是可引导扇区。若该扇区位于整个硬盘最开始的扇区,并且以 Ox55 和 Ox剧结束, BIOS就认为该扇区中存在 MBR,该扇区就是 MBR 引导扇区。若该扇区位于各分区最开始的扇区,井且以 Ox55和 Ox剧结束, MBR 就认为该扇区中有操作系统引导程序 OBR,该扇区就是 OBR 引导扇区。
vstart 只是告诉编译器以新的数字作为后面数据的地址的起始值,它本身没改变数据本身在文件中的地址(相对于文件开头的偏移〉,若能改的话,比如 vstat=0x7c00,那 0x7c00 之前的间隙肯定得用。来填充,那得多出多少填充物啊,那文件就太大啦。总不该用了 vstart 后,文件就跟着变大 。
因为 8086在寻址方面的硬件电路做得简单有限,为了更简单,某些功能中使用的寄存器甚至要“写死气如该用基址寻址时,电路中就只针对 bx 或 bp 寄存器,从硬件上就没考虑其他寄存器。
为了简化 CPU 访问外部设备的工作,能够轻松地同任何硬件通信,大家就约定好 IO 接口的功能。
-
设置数据缓冲,解决 CPU 与外设的速度不匹配
CPU和外设速度上的差异可以通过设置缓冲区来解决,也就是说,数据先存储在缓冲区里,等需要的时候(无论缓冲区是否满了)就传送出去。
-
设置信号电平转换电路
CPU 和外设的信号电平不同,如 CPU 所用的信号是 πL | 电平,而外设大多数是机电设备,故不能使用 TTL电平驱动,可以在接口电路中设置电平转换电路来解决。
-
设置数据格式转换
外设是多种多样的,输出的信息可能是数字信号、模拟信号等,而 CPU 只能处理数字信号。数字信号需要经过数/模转换( D/A )成模拟量才能被送到外设以驱动硬件,模拟量也同样需要经过模/数( A/D)转换成数字量才能被CPU 处理。所以接口电路中需要包括 AID 转换器和 DIA 转换器。另外,即使双方使用的都是数字信号,这也牵涉到格式和字长的问题,如 CPU 使用的是8位、 16 位或 32 位井行数据,而外设使用并行或串行数据都有可能,所以 IO 接口中必须能够识别格式并且转换成对方需要的形式才行。
-
设置时序控制电路来同步 CPU 和外部设备
硬件的工作也按照某种时序,它们都有自己的时序系统,就像 CPU 工作在自己的晶振时序上一样。双方时序不同,接口电路就要协调这两种不同的时间计法。例如, CPU 发控制信号、定时信号给 IO 接口电路, IO 接口用它们来控制和管理硬件。随后硬件有了反馈后,其应答信号也需要通过接口返回给 CPU,这样 CPU 先“问飞硬件后“回答气就实现了一次握手,之后便可以实现 IO 的同步操作。
-
提供地址译码
CPU 同多个硬件打交道,每个硬件要反馈的信息很多,所以一个 IO 接口必须包含多个端口,即 IO接口上的寄存器,来存储这些信息内容 。 但同一时刻,只能有一个端口和 CPU 数据交换,这就需要 IO 接口提供地址译码电路,使 CPU 可以选中某个端口,使其可以访问数据总线 。
这里所说的主盘 master、从盘 slave 别和 Primary 通道、 Secondary通道搞混了,通道是channel ,不是 disk,每个通道上分别有主盘和从盘 。
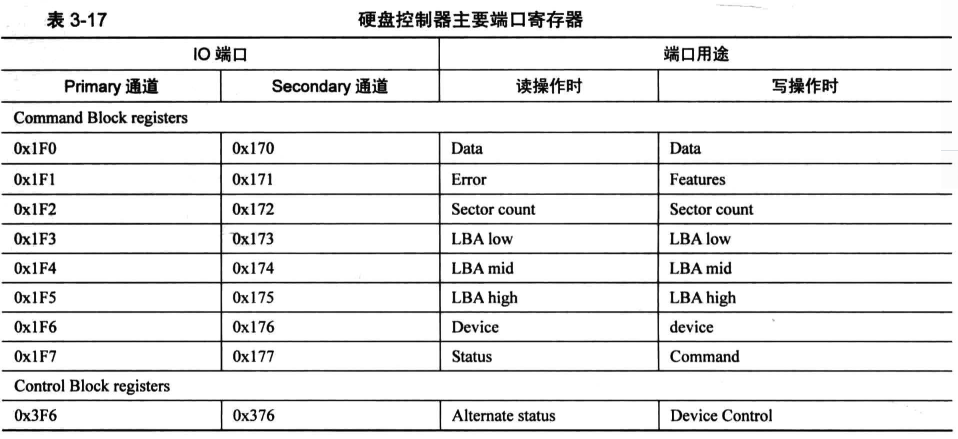
寄存器 error、 feature 和 status、 command,大家可以这样来助记:这4个都是同一寄存器(也就是同一端口)多个用途,对同一端口写操作时,硬盘控制器认为这是个命令,对同一端口读操作时,硬盘控制器认为是想获得状态。
端口是按照通道给出的,也就是说,大家不要像我当初那样误以为端口是直接针对某块硬盘的,不是这样的,一个通道上的主、从两块硬盘都用这些端口号 。 要想操作某通道上的某块硬盘,需要单独指定。
LBA寄存器:这里有 LBA!ow、 LBAmid 、 LBAhigh 三个,它们三个都是8位宽度的。 LBA!ow 寄存器用来存储 28 位地址的第 0 ~7 位,LBAmid 寄存器用来存储第 8 ~ 15 位,LBAhigh 寄存器存储第 16~23 位 。还有一个 device 寄存器。device 寄存器是个杂项,它的宽度是8位。在此寄存器的低4位用来存储 LBA 地址的第 24~27 位。第4位用来指定通道上的主盘或从盘,1代表主盘,0代表从盘。第5位用来设置是否启用 LBA 方式,1代表启用 LBA 模式,0代表启用 CHS 模式。另外的两位:第6位和第7位是固定为1的,称为 MBS 位
定个操作硬盘的步骤:
- 先选择通道,往该通道的 sector count 寄存器中写入待操作的扇区数。
- 往该通道上的三个 LBA 寄存器写入扇区起始地址的低 24 位。
- 往 device 寄存器中写入 LBA 地址的 24~27 位,并置第6位为1,使其为 LBA 模式,设置第4位,选择操作的硬盘( master 硬盘或 slave 硬盘)。
- 往该通道上的 command 寄存器写入操作命令。
- 读取该通道上的 status 寄存器,判断硬盘工作是否完成。
- 如果是为了读硬盘,则将硬盘数据读出。否则,完工。
%include ”boot.inc”:这个%include 是 nasm 编译器中的预处理指令,意思是让编译器在编译之前把 boot.inc 文件包含进来,编译时添加一个参数-I include/表示指定包含文件的路径
GOT 中的第 0 个段描述符是不可用的,原因是定义在 GOT 中的段描述符是要用选择子来访问的,如果使用的选择子忘记初始化,选择子的值便会是 0,这便会访问到第 0 个段描述符。为了避免出现这种因忘记初始化选择子而选择到第 0 个段描述符的情况, GOT中的第 0 个段描述符不可用。也就是说,若选择到了 GOT 中的第 0 个描述符,处理器将发出异常。
LDT 中的段描述符和 GDT 中的一样,与 GDT 不同的是 LDT 中的第0个段描述符是可用的,因为提交的选择子中的 TI 位, TI 位用于指定是 GDT还是 LDT, TI 为1则表示在 LDT 中索引段描述符,即为 1 必然是经过显式初始化的结果,完全排除了忘记初始化的可能。
指令执行单元 EU 是执行指令的唯一部件,一次只能执行一个指令,单核 CPU 的情况下,只有一个指令处于执行中。 CPU 中的各部分也是同时只能做一件事,但它们就像身体器官一样,也是在并行工作,相当于多个“人手”。 CPU 的指令执行过程分为取指令、译码、执行三个步骤。每个步骤都是独立执行的, CPU可以一边执行指令,一边取指令,一边译码。
虽然在一个时钟周期内 CPU 同时干了三件事,但一定要清楚,这三件事不属于同一个指令,是三个指令重叠在一起了。
CPU 是按照程序中指令顺序来填充流水线的,也就是说按照程序计数器 PC(x86中是 CS: ip)中的值来装载流水线的,当前指令和下一条指令在空间上是挨着的。如果当前执行的指令是jmp,下一条指令已经被送上流水线译码了,第三条指令已经被送上流水线取指啦。仔细想想看,其实这个流水线没用了,因为 CPU 早已经跳到别处去执行了,第二、三条指令用不上了,所以 CPU 在遇到无条件转移指令 jmp 时,会清空流水线。
其实,流水线还是有优化空间的。CPU 指令三个步骤中,只有“执行”这一步才是最重要的,想办法让此步骤的周期更短才是王道。也就是说,执行周期越短, CPU 所执行指令的数量越多,效率也就越高,但流水线级数肯定越多。解决问题的办法是,将每一步操作再继续划分成粒度更细的微操作。
CPU工程师为了提高流水线效率,做出了很多努力:
- 乱序执行,是指在 CPU 中运行的指令并不按照代码中的顺序执行,而是按照一定的策略打乱顺序执行,也许后面的指令先执行,当然,得保证指令之间不具备相关性 。
- 缓存:无论是程序中的数据,还是指令,在 CPU 眼里全是一样形式的二进制 01串,没有任何区别,都是 CPU 待处理的“数据”。所以我们眼中的指令和数据都可以被缓存到 SRAM (使用触发器实现)中。
可以根据程序的局部性原理采取缓存策略。局部性原理是:程序 90%的时间都运行在程序中 10%的代码上 。
局部性分为以下两个方面 。
一方面是时间局部性:最近访问过的指令和数据,在将来一段时间内依然经常被访问。
另一方面是空间局部性:靠近当前访问内存空间的内存地址,在将来一段时间也会被访问 。 - 分支预测:流水线是有效提升 CPU 效率的方式,但流水线最大的问题是程序中的分支结构,如何把握好转移的方向,才是使流水线保持高效的关键,因为如果流水线上的指令放错了的话,必须要清空那些已经在流水线上的指令,一定不能执行错误的指令。随着流水线级数越多,要清空的指令也将越多,清空流水线的代价就越大,这严重影响 CPU 效率。
当遇到一个分岔口时,对于这种分支情况,就需要预测出哪一侧的指令将被执行,然后将预测出的那一分支上的指令放入流水线 。 从统计学的角度来看,某些事情一旦出现,下一次出现的机率还会很大。
段描述符缓冲寄存器在 CPU 的实模式和保护模式中都同时使用,在不重新引用一个段时,段描述符缓冲寄存器中的内容是不会更新的,无论是在实模式,还是保护模式’下, CPU 都以段描述符缓冲寄存器中的内容为主。实模式进入保护模式时,由于段描述符缓冲寄存器中的内容仅仅是实模式下的 20 位的段基址,很多属性位都是错误的值,这对保护模式来说必然会造成错误,所以需要马上更新段描述符缓冲寄存器,也就是要想办法往相应段寄存器中加载选择子。
其次,流水线中指令译码错误。
在默认情况下,如果未使用 bits 伪指令来设置运行环境,编译器就将代码按照 16 位实模式编译。代码 4-3 ,即 loader.S 中唯一的 bits 指令是在 81 行,所以 80 行之前的代码运行在实模式之下,它们是 16 位指令格式 。 第 81 行的[bits 32]是让编译器将此行后面的指令编译成为 32 位。因为此处已经是在保护模式下了,我们知道保护模式下的指令是 32 位,所以要编译成符合保护模式的指令格式。
综上所述,解决问题的关键就是既要改变代码段描述符缓冲寄存器的值,又要清空流水线 。 CPU 遇到 jmp指令时,之前已经送上流水线上的指令只有清空,所以 jmp 指令有清空流水线的神奇功效 。
既然有了一级页表,为什么还要搞个二级页表呢?理由如下。
- 一级页表中最多可容纳 1M ( 1048576 )个页表项,每个页表项是 4 字节,如果页表项全满的话,便是 4画面大小。
- 一级页表中所有页表项必须要提前建好,原因是操作系统要占用 4GB 虚拟地址空间的高 1GB,用户进程要占用低 3GB
- 每个进程都有自己的页表,进程一多,光是页表占用的空间就很可观了。
归根结底,我们要解决的是:不要一次性地将全部页表项建好,需要时动态创建页表项 。
总结一下用虚拟地址获取页表中各数据类型的方法
-
获取页目录表物理地址:让虚拟地址的高 20 位为 0xffilf,低 12 位为 0x000 ,即 0xfffif000,这也是页目录表中第 0 个页目录项自身的物理地址。
-
访问页目录中的页目录项,即获取页表物理地址:要使虚拟地址为 0xffiffxxx,其中 xxx 是页目录项的索引乘以4的积
-
访问页表中的页表项: 要使虚拟地址高 10 位为 0x3ff,目的是获取页目录表物理地址。中间 10 位为页表的索引,因为是 10 位的索引值,所以这里不用乘以 4。低 12 位为页表内的偏移地址,用来定位页表项,它必须是己经乘以 4 后的值。公式为 0x3ff << 22+中间 10 位 << 12+低 12 位。
处理器准备了一个高速缓存,可以匹配高速的处理器速率和低速的内存访问速度,它专门用来存放虚拟地址页框与物理地址页框的映射关系,这个调整缓存就是 TLB ,即Translation Lookaside Buffer,俗称快表
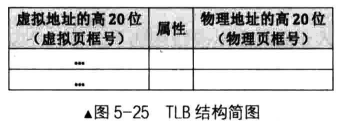
有了 TLB,处理器在寻址之前会用虚拟地址的高 20 位作为索引来查找 TLB 中的相关条目,如果命中(匹配到相关条目)则返回虚拟地址所映射的物理页框地址,否则会查询内存中的页表,获得页框物理地址后再更新 TLB 。
TLB 必须实时更新。TLB 的维护工作交给操作系统开发人员,由开发人员于动控制。这的确是非常合理的,毕竟维护页表的代码是开发人员自己写的,他们肯定知道何时修改了页表,或是修改了哪些条目。
有两种方法可以间接更新 TLB ,一个是针对 TLB 中所有条目的方法一一重新加载 CR3 ,比如将 CR3 寄存器的数据读出来后再写入 CR3 ,这会使整个 TLB 失效。另一个方法是针对 TLB 中某个条目的更新。处理器提供了指令 invlpg (invalidate page ),它用于在 TLB 中刷新, 某个虚拟地址对应的条目
生成 C 语言程序的过程是这样的。先将源程序编译成目标文件(由 c 代码变成汇编代码后,再由汇编代码生成二进制的目标文件),再将目标文件链接成二进制可执行文件。
经过gcc -c -o main.o main.c 的编译后,我们得到了 main.o 文件,目前为止,它还是个“半成品”,为什么这么说呢?因为它只是个目标文件,也称为待重定位文件,重定位指的是文件里面所用的符号还没有安排地址,这些符号的地址需要将来与其他目标文件“组成”一个可执行文件时再重新定位(编排地址〉,这里的符号就是指该目标文件中所调用的函数或使用的变量,而这里的“组成”就是指链接。这些符号一般是位于其他文件中,所以在编译时不能确定其地址,需要在所有目标文件都到齐了,将它们链接到一起时再重新定位(编排地址)。由于不知道可执行文件由几个目标文件组成,所以一律在链接阶段对符号重新定位(编排地址)。所以说,哪怕是可执行文件只是由一个文件组成的,其目标文件中的符号也是未编址的,编址工作,即重定位,一律统一在链接阶段完成。
ld main.o -Ttext 0xc0001500 -e main -o kernel.bin-Ttext 指定起始虚拟地址为 0xc0001500,-e用来指定程序的起始地址/标号
物理内存中0x900处是loader.bin加载的地址,在loader.bin的开始部分是GDT,它可是必须要保留下来的,可不能覆盖,我们不打算在内核中重新定义它,以后都要指望它了。正如伟大领袖虽然仙逝了,但威望犹在,虽然loader的工作结束啦,但loader所完成的工作成果咱们还得继续发扬继续用。预计loader.bin的大小不会超过2000字节。所以咱们可选的起始物理地址是0x900+2000=0x10d0(不要把注意力放在这个奇怪的数上,偶然得出的)。内存很大,但也尽量往低了选,于是凑了个整数,选了0x1500做为内核映像的入口地址。
根据咱们的页表,低端1MB的虚拟内存与物理内存是一一对应的,所以物理地址是0x1500对应的虚拟地址是0xc0001500
Window 下的可执行文件格式是 PE(如果您想说的是 EXE,不要搞混了, EXE是扩展名,属于文件名的一部分,只是名字的后缀,它并不是真正的格式), PE 即 Portable Exeeutable,Linux 下可执行文件格式是 ELF。
程序中最重要的部分就是段(segment)和节( section),它们是真正的程序体,是真真切切的程序资源,所以下面的说明咱们以它们为例。程序中有很多段,如代码段和数据段等,同样也有很多节,段是由节来组成的,多个节经过链接之后就被合并成一个段了。
段和节的信息也是用 header 来描述的,程序头是 program header,节头是 section header。程序中段的大小和数量是不固定的,节的大小和数量也不固定,因此需要为它们专门找个数据结构来描述它们,这个描述结构就是程序头表( program header table)和节头表( section header table )。既然程序头表和节头表都称为表,这说明里面存储的是多个程序头 program header和多个节头 section header 的信息,故这两个表相当于数组,数组元素分别是程序头 program header 和节头 section header 。
在表中,每个成员(数组元素)都统称为条目,即entry,一个条目代表一个段或一个节的头描述信息。对于程序头表,它本质上就是用来描述段(segment)的,所以您也可以称它为段头表。从名字上就能够看出,段等同于程序,所以将描述段信息的表说成 program header table,可见“段”才是程序本身的组成部分。
由于程序中段和节的数量不固定,程序头表和节头表的大小自然也就不固定了,而且各表在程序文件中的存储顺序自然也要有个先后,故这两个表在文件中的位直也不会固定。因此,必须要在一个固定的位置,用 一个固定大小的数据结构来描述程序头表和节头表的大小及位置信息,这个数据结构便是 ELF header,它位于文件最开始的部分,并具有固定大小。
ELF header 是个用来描述各种“头”的“头”,程序头表和节头表中的元素也是程序头和节头,可见,elf 文件格式的核心思想就是头中嵌头,是种层次化结构的格式。
我们的内核是由 loader 加载的,所以我们还要去修改下 loader. S,loader.S 需要修改两个地方。
- 加载内核:需要把内核文件加载到内存缓冲区。
- 初始化内核:需要在分页后,将加载进来的 elf 内核文件安置到相应的虚拟内存地址,然后跳过去执行,从此 loader 的工作结束。
在任意时刻,当前特权级 CPL 保存在 cs 选择子中的请求特权级 RPL 部分。
代码指令代表 CPU 的行为,低特权级的代码能做的事,高特权级代码也能做,换句话说高特权的代码不需要低特权代码的帮助,正常情况下 CPU 没有理由先自降等级后再去做某事。代码段是 CPU 执行的指令,不是数据,这里所说的“受访者为代码段”其实就是指 CPU 从访问者所在的段转移到该代码段上去执行。
这是唯一一种处理器会从高特权降到低特权运行的情况:处理器从中断处理程序中返回到用户态的时候。
一致性代码段的一大特点是转移后的特权级不与自己的特权级 (DPL)为主,而是与转移前的低特权级一致,昕从、依从转移前的低特权级,这就是它称为“依从、一致”的原因 。 也就是说,处理器遇到目标段为一致性代码段时,并不会将 CPL 用该目标段的 DPL 替换 。
既然是转移到特权级更高的一致性代码段后 CPL 不变,这说明这种转移本身井没有提升特权级,只是可以跑到特权级更高的代码段中去执行指令,对计算机而言并未因特权级升高而产生潜在危险,所以在特权级检查过程中,请求者的 RPL 并不参与。
代码段可以有一致性和非一致性之分,但所有的数据段总是非一致的,即数据段不允许被比本数据段特权级更低的代码段访问 。
大家不要把 CPL 和 RPL 搞混了,不要误以为都是对同一个程序而言的,它们也许不都属于同一个程序。RPL 是位于选择子中的,所以,要看当前运行的程序在访问数据或代码时用的是谁提供的选择子,如果用的是自己提供的选择子,那肯定 CPL 和 RPL 都出自同一个程序,如果选择子是别人提供的,那就有可能 RPL和 CPL 出自两段程序。 CPL 是对当前正在运行的程序而言的,而 RPL 有可能是正在运行的程序,也可能不是。在一般情况下,如果低特权级不向高特权级程序提供自己特权级下的选择子,也就是不涉及向高特权级程序“委托、代理”办事的话, CPL 和 RPL 都来自同一程序。但凡涉及“委托、代理”,进入 0 特权级后, CPL 是指代理人,即内核, RPL 则有可能是委托者,即用户程序,也有可能是内核自己。
在保护模式下,处理器中的“阶级”不仅体现在数据和代码的访问,还体现在指令中。
一方面将指令分级的原因是有些指令的执行对计算机有着严重的影响,它们只有在0特权级下被执行,因此被称为特权指令( Privilege Instruction)。比如 hlt 指令,它可以让计算机停机,处理器只信任操作系统,所以它不得不放在 0 特权级下。同类的指令还有 lgdt、 lidt、ltr、 popf等,这些对计算机的正常运行起着非同小可的影响,操作系统只有亲自执行它们才放心。
另一方面体现在 1/0 读写控制上。 IO 读写特权是由标志寄存器 eflags 中的 IOPL 位和 TSS 中的 IO 位图决定的,它们用来指定执行 IO 操作的最小特权级。 IO 相关的指令只有在当前特权级大于等于 IOPL 时才能执行,所以它们称为 IO 敏感指令( 1/0 Sensitive Instruction),如果当前特权级小于 IOPL 时执行这些指令会引发处理器异常。这类指令有 in、 out、 cli 、 sti。所以你懂的,不只是操作系统可以进行 IO 端口访问,用户进程也是可以的,只是操作系统不允许用户进程这么做。
处理器要求位图的最后一字节必须是 0xFF,此字节有两个作用。
第一 ,处理器允许I/O位图中不映射所有的端口,即I/O位图长度可以不足 8阻,但位固的最后一字节必须为 0xFF 。 如果在位图范围外的端口,处理器一律默认禁止访问。这样一来,如果位图最后一字节的 0xFF 属于全部 65536 个端口范围之内,字节各位全为 1 表示禁止访问此字节代表的全部端口,这并没什么过错。
第二 ,如果该字节已经超过了全部端口的范围,它并不用来映射端口,只是用来作为位图的边界标记,用于跨位图最后一个字节时的“余量字节”。避免越界访问 TSS 外的内存。