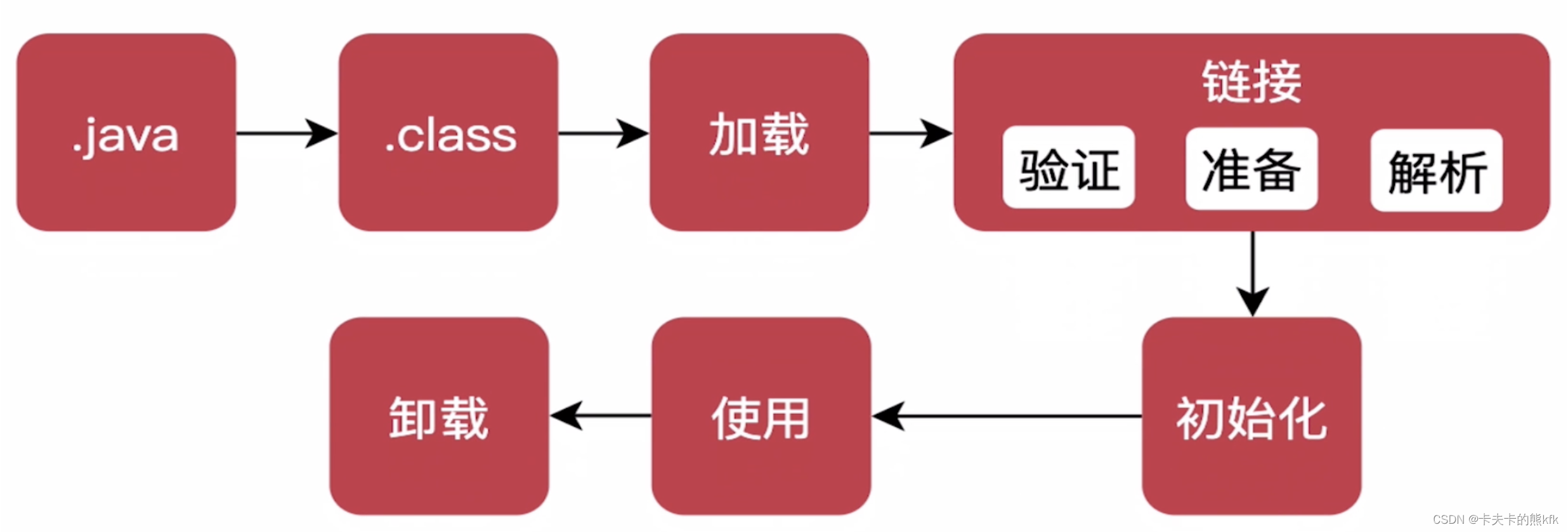
文章目录
- 一:聊天记录传输至电脑
- 二:聊天记录破解
- 三:聊天记录分析
- (1)字段含义
- (2)词频统计和词云制作
- (3)效果展示
一:聊天记录传输至电脑
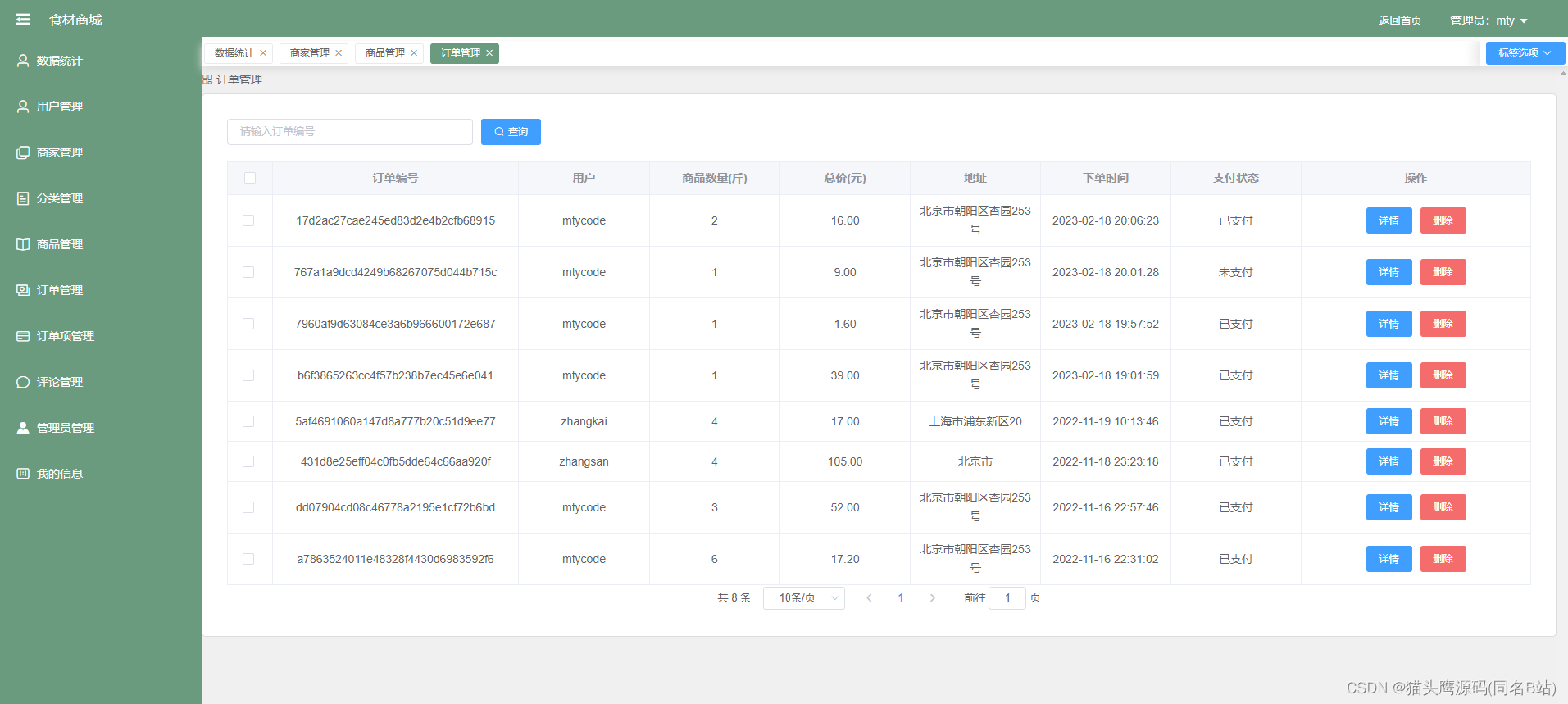
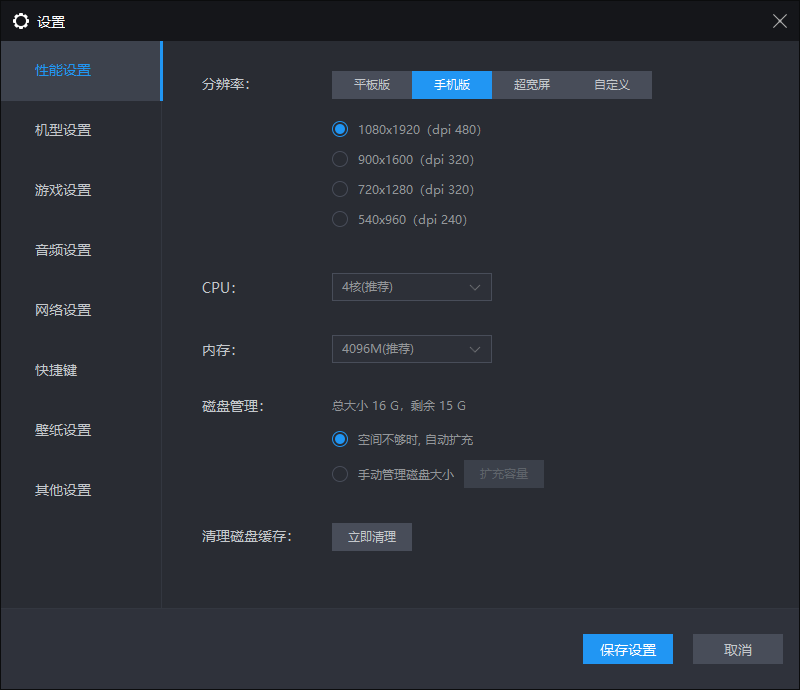
在雷电模拟器中打开root权限,并将分辨率设置为1080×1920
- 其他模拟器也可以
模拟器上安装微信(不要着急登录)

在正在使用的手机上选择迁移聊天记录到手机/平板,迁移时不要选择图片和文件,只迁移文字
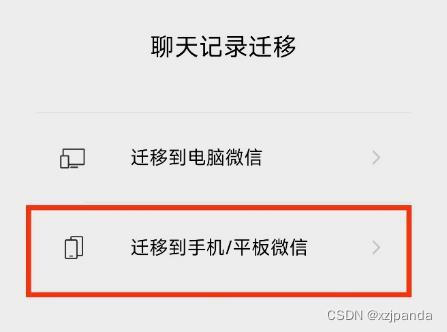
然后在模拟器上登录微信,使用电脑摄像头扫描迁移二维码进行迁移
导入完成
打开模拟器的文件管理器
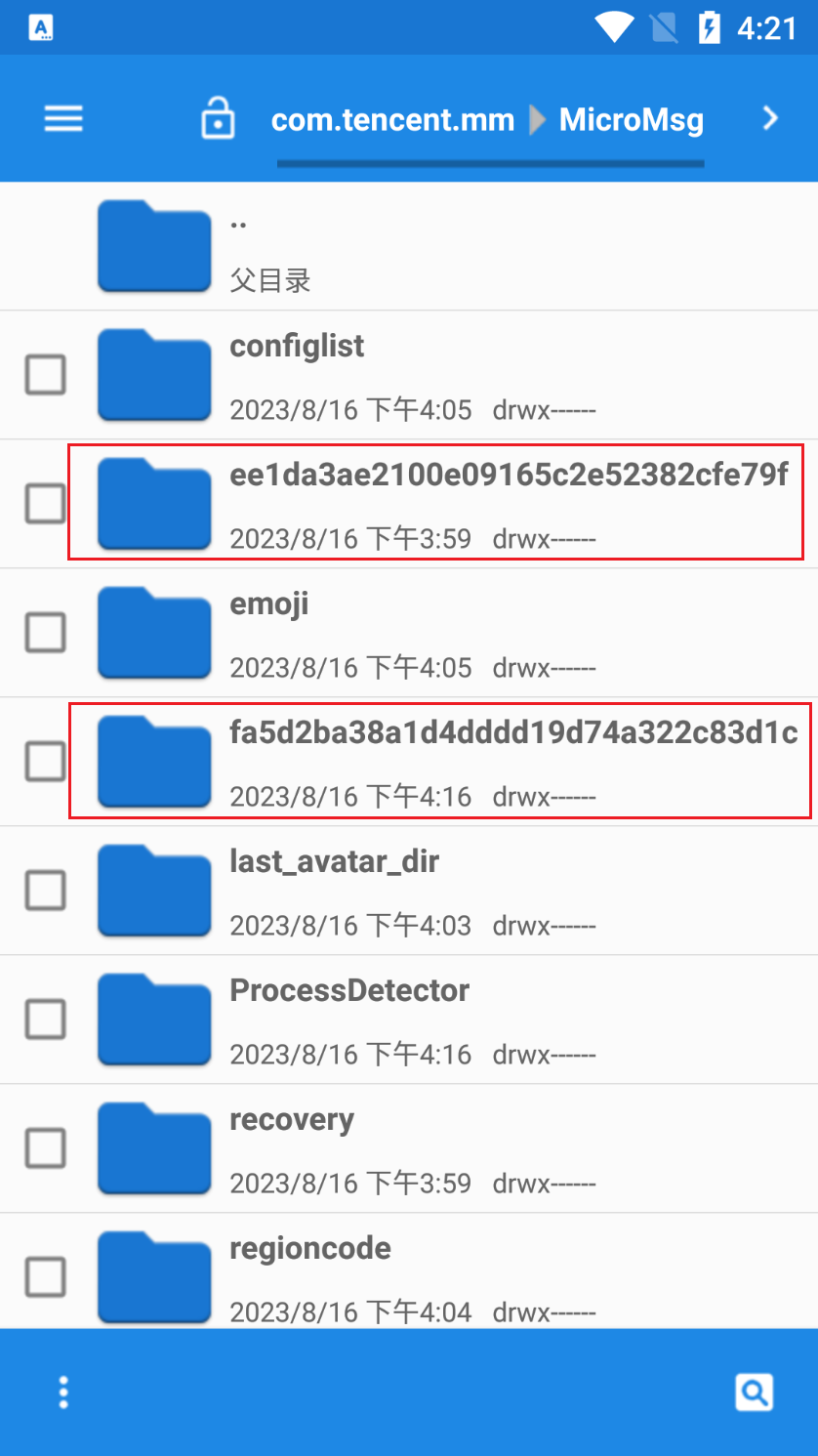
在/data/data/com.tencent.mm/MicroMsg/(一个32位字符串命名的文件夹中)下寻找EnMicroMsg.db文件,如果该文件在此目录下不存在,那么可能有多个微信号在模拟器上登陆过。所以挨个寻找下图方框内的文件,哪个文件及里有该文件,就选哪个
如下图
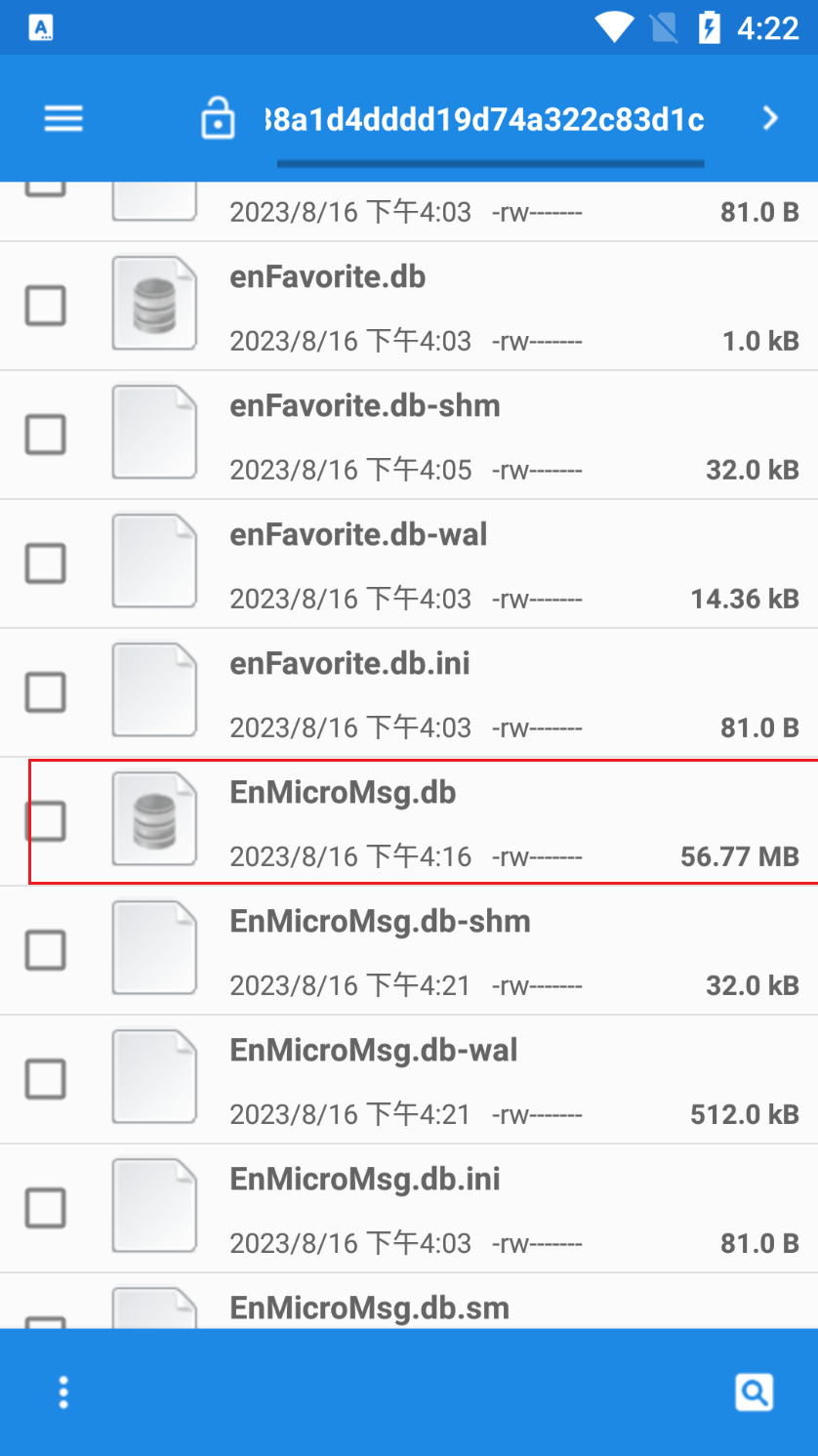
然后把该文件传至电脑,方法是:在雷电模拟器中打开“文件管理器”,再依次点击data、data、com.tencent.mm、MicroMsg,找到EnMicroMsg.db文件;单击选中该文件后,按住Ctrl+5,选择“打开安卓文件夹”;单价左下角三个点,选择“粘贴选择项”。再按住Ctrl+5,选择“打开电脑文件夹”,就可以在电脑的文件夹里看到所需要的文件啦
二:聊天记录破解
使用数据库软件SQLite Database Browser
获取模拟器中的手机IMEI码和微信ui值
- 手机IMEI码:
- 雷电模拟器设置界面可以查看:010306020798103
- 有可能是固定的IMEI码:1234567890ABCDEF
- 微信ui值:安卓模拟器的根目录
/data/data/com.tencent.mm/shared_prefs文件夹下找到auth_info_key_prefs.xml文件拷贝到电脑中并用记事本打开,找到如下auth_uin文字,其中value后面跟着的就是你的uin码了。如果是负数则复制的时候一定要保留负号,每个人uin码的位数可能不一样
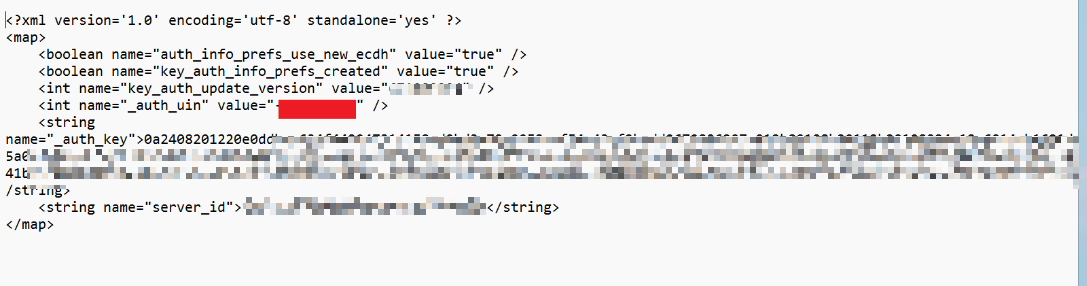
然后将手机IMEI码和微信uin码直接相连后,用换算工具换算成小写32位md5值,其前7位就是破解密码啦!然后用该软件打开哪个数据库文件,并使用密码进入
点击File–>Export–>Table as CSV file,选择message表导出(注意是message表,不要选成其他表了),一定要自己加上后缀.csv!!
然后使用记事本打开该文件另存为,编码选择utf-8
三:聊天记录分析
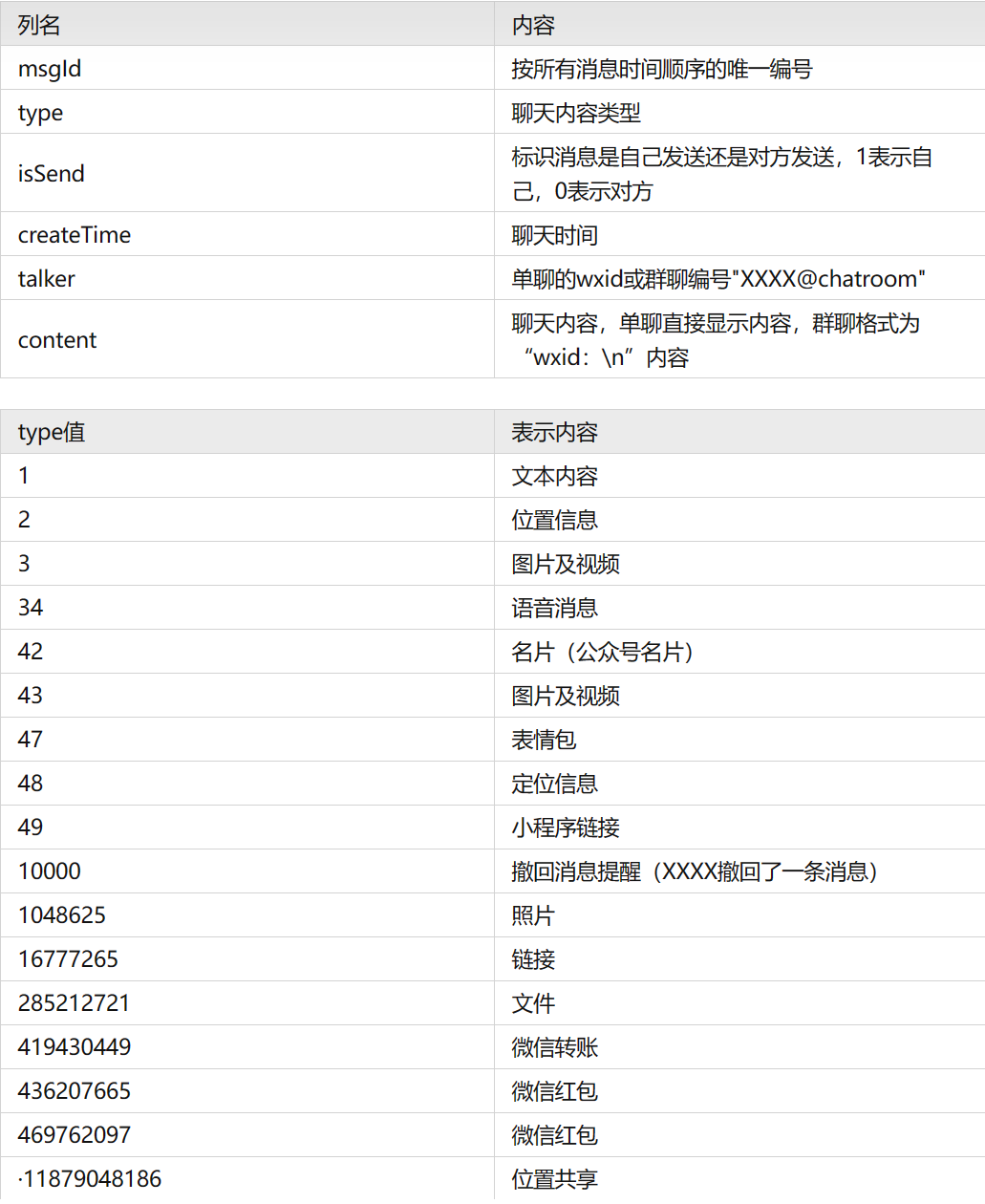
(1)字段含义
上面CSV文件列名部分含义如下
(2)词频统计和词云制作
具体步骤如下
- 将csv文件读取SQL,然后提取message列,将聊天记录写入文件
- 对聊天记录进行处理
- 去除文本表情
- 去除微信系统消息
- 去除空字符串
- 对聊天记录进行分词和停用词处理
- 可以建立自己的分词表,达到更好的分词效果
- 如果不想让某些词在最后的词云图中显示,则加入停用词表
- 词频统计和降序排序
- 利用wordcloud库制作词云图
完整代码如下
from collections import Counter
import pandas
import re
import sqlite3
import numpy as np
import jieba
from wordcloud import WordCloud
from PIL import Image
def read_file(file_name):
fp = open(file_name, "r", encoding="utf-8")
lines = fp.readlines()
fp.close()
for i in range(len(lines)):
lines[i] = lines[i].rstrip("\n")
return lines
# 从message表提取原始聊天记录并保存
def extract():
# 新建聊天记录数据库
conn = sqlite3.connect('chat_log.db')
# 读取csv文件,生成DataFrame
message_df = pandas.read_csv('message.csv', sep=",")
# 将DataFrame写入SQL中,存入message_sql表中
message_df.to_sql('message_sql', conn, if_exists='append', index=False)
# 获得游标
cursor = conn.cursor()
# 选择content
cursor.execute('select content from message_sql where length(content) < 100')
# 返回结果
contents = cursor.fetchall()
# 写入文件
file = open('原始聊天记录.txt', 'w+', encoding='utf-8')
for content in contents:
file.write(content[0] + '\n')
file.close()
cursor.close()
conn.close()
# 对聊天记录进行处理
def process():
emoj_regx = re.compile(r"\[[^\]]+\]")
wxid_regx = re.compile(r"wxid.*")
content_lines = read_file('原始聊天记录.txt')
for i in range(len(content_lines)):
# 去除文本表情
content_lines[i] = emoj_regx.sub(r"", content_lines[i])
# 去除微信消息
content_lines[i] = wxid_regx.sub(r"", content_lines[i])
# 去除空字符串
content_lines = [line for line in content_lines if line != '']
# print(content_lines)
return content_lines
# 分词和去除停用词
def cut():
jieba.load_userdict('./mywords.txt')
stopwords = read_file('stopwords.dat')
all_words = []
for line in content_lines:
all_words += [word for word in jieba.cut(line) if word not in stopwords]
dict_words = dict(Counter(all_words))
return dict_words
def get_cloud():
mask_image = np.array(Image.open('muban3.png').convert('L'))
wordcloud = WordCloud(background_color='white', mask=mask_image, font_path='simhei.ttf')
# top_100_words = dict(list(sorted_words.items())[:100])
wordcloud.generate_from_frequencies(sorted_words)
wordcloud.to_file('cloud.png')
if __name__ == '__main__':
# 提取聊天记录
# extract()
# 聊天记录处理
content_lines = process()
# 分词和停用词去除
dict_words = cut()
# 降序排序
sorted_words = sorted(dict_words.items(), key=lambda d: d[1], reverse=True)
sorted_words = {word: freq for word, freq in sorted_words}
print(sorted_words)
# 词云生成
get_cloud()
这里附加一段有关文本表情信息统计的代码
import re
def count_emoticons(file_path, target_emoticon):
with open(file_path, 'r', encoding='utf-8') as f:
chat_records = f.read()
all_emoticons = []
for line in chat_records.split('\n'):
if line.strip():
emoticons = re.findall(r'\[(.*?)\]', line)
all_emoticons.extend(emoticons)
total_emoticons = len(all_emoticons)
target_count = all_emoticons.count(target_emoticon)
return total_emoticons, target_count
file_path = '原始聊天记录.txt' # 聊天记录文件路径
target_emoticon = '捂脸' # 目标表情
total_emoticons, target_count = count_emoticons(file_path, target_emoticon)
print("总共有{}个表情".format(total_emoticons))
print("表情'{}'出现了{}次".format(target_emoticon, target_count))
(3)效果展示
使用如下模板图,使背景为白色,词云图将会显示在非白色位置处

效果如下(已对敏感信息打码处理)