🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
从文字中建立意义
一个简单的例子:正面和负面
更深入一点:向量
TensorFlow 中的嵌入
使用嵌入构建讽刺检测器
减少语言模型中的过度拟合
调整学习率
探索词汇量
探索嵌入维度
探索模型架构
使用dropout
使用正则化
其他优化注意事项
使用模型对句子进行分类
可视化嵌入
使用来自 TensorFlow Hub 的预训练嵌入
概括
在第 5 章中,您了解了如何获取单词并将它们编码为标记。然后,您了解了如何将充满单词的句子编码为充满标记的序列,并根据需要填充或截断它们以最终得到一组可用于训练神经网络的形状良好的数据。这些都没有任何类型的词义建模。虽然确实没有可以封装含义的绝对数字编码,但有相对的编码。在本章您将了解它们,尤其是嵌入的概念,其中创建高维空间中的向量来表示单词。随着时间的推移,可以根据语料库中单词的使用来学习这些向量的方向。然后,当给定一个句子时,您可以调查词向量的方向,将它们相加,并从总和的总体方向将句子的情感建立为其词的乘积。
在本章中,我们将探讨它是如何工作的。使用使用第 5 章中的 Sarcasm 数据集,您将构建嵌入以帮助模型检测句子中的讽刺。您还将看到一些很酷的可视化工具,它们可以帮助您了解语料库中的单词如何映射到向量,以便您可以看到哪些单词决定了整体分类。
从文字中建立意义
在我们进入用于嵌入的高维向量之前,让我们尝试通过一些简单的例子来可视化如何从数字中得出意义。考虑一下:使用第 5 章中的 Sarcasm 数据集,如果将构成讽刺标题的所有单词编码为正数,将构成现实标题的单词编码为负数,会发生什么情况?
一个简单的例子:正面和负面
christian bale given neutered male statuette named oscar假设我们词汇表中的所有单词都以 0 值开头,我们可以将这句话中每个单词的值加 1,最终得到:
{ "christian" : 1, "bale" : 1, "given" : 1, "neutered": 1, "male" : 1,
"statuette": 1, "named" : 1, "oscar": 1}笔记
请注意,这与您在上一章中所做的单词标记化不同。您可以考虑用从语料库编码的表示它的标记替换每个单词(例如,“基督教徒”),但我现在将这些单词保留在其中以使其更易于阅读。
然后,在下一步中,考虑一个普通的标题,而不是讽刺的标题,如下所示:
gareth bale scores wonder goal against germany因为这是不同的情绪,我们可以从每个单词的当前值中减去 1,所以我们的值集将如下所示:
{ "christian" : 1, "bale" : 0, "given" : 1, "neutered": 1, "male" : 1,
"statuette": 1, "named" : 1, "oscar": 1, "gareth" : -1, "scores": -1,
"wonder" : -1, "goal" : -1, "against" : -1, "germany" : -1}请注意,讽刺的“bale”(来自“christian bale”)已被非讽刺的“bale”(来自“gareth bale”)抵消,因此它的分数最终为 0。重复此过程数千次,你将结束从你的语料库中根据它们的使用情况评分的大量单词列表。
现在想象一下我们要建立这句话的情感:
neutered male named against germany, wins statuette!使用我们现有的值集,我们可以查看每个单词的分数并将它们相加。我们会得到 2 分,表明(因为它是一个正数)这是一个讽刺的句子。
笔记
就其价值而言,“bale”在 Sarcasm 数据集中使用了五次,在正常标题中使用了两次,在讽刺标题中使用了三次,因此在这样的模型中,“bale”一词在整个数据集中的得分为 –1 .
更深入一点:向量
希望前面的例子帮助你理解了通过与同一“方向”上的其他词的关联,为一个词建立某种形式的相对意义的心智模型。在我们的例子中,虽然计算机不理解单个词的含义,但它可以将已知讽刺标题中的标记词朝一个方向移动(通过加 1),并将来自已知正常标题的标记词朝另一个方向移动(通过减去 1 ). 这使我们对单词的含义有了基本的理解,但确实失去了一些细微差别。
如果我们增加方向的维度以尝试捕获更多信息会怎样?例如,假设我们要看简·奥斯丁小说《傲慢与偏见》中的人物,考虑性别和贵族的维度。我们可以将前者绘制在 x 轴上,将后者绘制在 y 轴上,向量的长度表示每个角色的财富(图 6-1)。

图 6-1。傲慢与偏见中的人物作为矢量
通过检查图形,您可以得出有关每个字符的大量信息。其中三个是男性。达西先生非常富有,但他的贵族身份并不明确(他被称为“先生”,这与不太富有但显然更高贵的威廉·卢卡斯爵士不同)。另一位“先生”,班纳特先生,显然不是贵族,在经济上举步维艰。他的女儿伊丽莎白·班纳特 (Elizabeth Bennet) 与他相似,但为女性。凯瑟琳夫人,我们例子中的另一个女性角色,高贵且非常富有。达西先生和伊丽莎白之间的罗曼史引起了紧张——从矢量的高尚的一面到不那么高贵的一面的偏见。
正如这个例子所示,通过考虑多个维度,我们可以开始看到单词(这里是字符名称)的真正含义。同样,我们不是在谈论具体的定义,而是基于轴的相对含义以及一个词的向量与其他向量之间的关系。
这使我们想到了嵌入的概念,它只是在训练神经网络时学习的单词的向量表示。接下来我们将探讨这一点。
TensorFlow 中的嵌入
作为你已经看到了 和Dense,Conv2D使用tf.keras层实现嵌入。这将创建一个从整数映射到嵌入表的查找表,其内容是表示由该整数标识的单词的向量的系数。因此,在上一节的傲慢与偏见示例中, x和y坐标将为我们提供书中特定角色的嵌入。当然,在真正的 NLP 问题中,我们使用的维度远不止两个维度。因此,向量空间中向量的方向可以看作是对单词“含义”的编码,具有相似向量的单词——即指向大致相同的方向——可以被认为与该单词相关。
嵌入层将被随机初始化——也就是说,向量的坐标将完全随机开始并被学习在使用反向传播的训练期间。训练完成后,嵌入将粗略地编码单词之间的相似性,使我们能够根据这些单词的向量方向来识别有些相似的单词。
这一切都非常抽象,所以我认为了解如何使用嵌入的最好方法是卷起袖子尝试一下。让我们从使用第 5 章中的 Sarcasm 数据集的讽刺检测器开始。
使用嵌入构建讽刺检测器
import numpy as np
training_padded = np.array(training_padded)
training_labels = np.array(training_labels)
testing_padded = np.array(testing_padded)
testing_labels = np.array(testing_labels)这些是使用具有指定最大词汇量和词汇表外标记的分词器创建的:
tokenizer = Tokenizer(num_words=vocab_size, oov_token=oov_tok)要初始化嵌入层,您需要词汇表大小和指定数量的嵌入维度:
tf.keras.layers.Embedding(vocab_size, embedding_dim),embedding_dim这将为每个单词初始化一个包含点的数组。因此,例如,如果embedding_dim是16,词汇表中的每个单词都将被分配一个 16 维向量。
随着时间的推移,当网络通过将训练数据与其标签匹配来学习时,将通过反向传播学习维度。
下一步重要的是将嵌入层的输出馈送到致密层。执行此操作的最简单方法(类似于使用卷积神经网络时的方法)是使用池化。在这种情况下,嵌入的维度被平均以产生固定长度的输出向量。
例如,考虑这个模型架构:
model = tf.keras.Sequential([
tf.keras.layers.Embedding(10000, 16),
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(24, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(loss='binary_crossentropy',
optimizer='adam',metrics=['accuracy'])这里定义了一个嵌入层,并为其指定了词汇大小 ( 10000) 和嵌入维数16。让我们看一下网络中可训练参数的数量,使用model.summary:
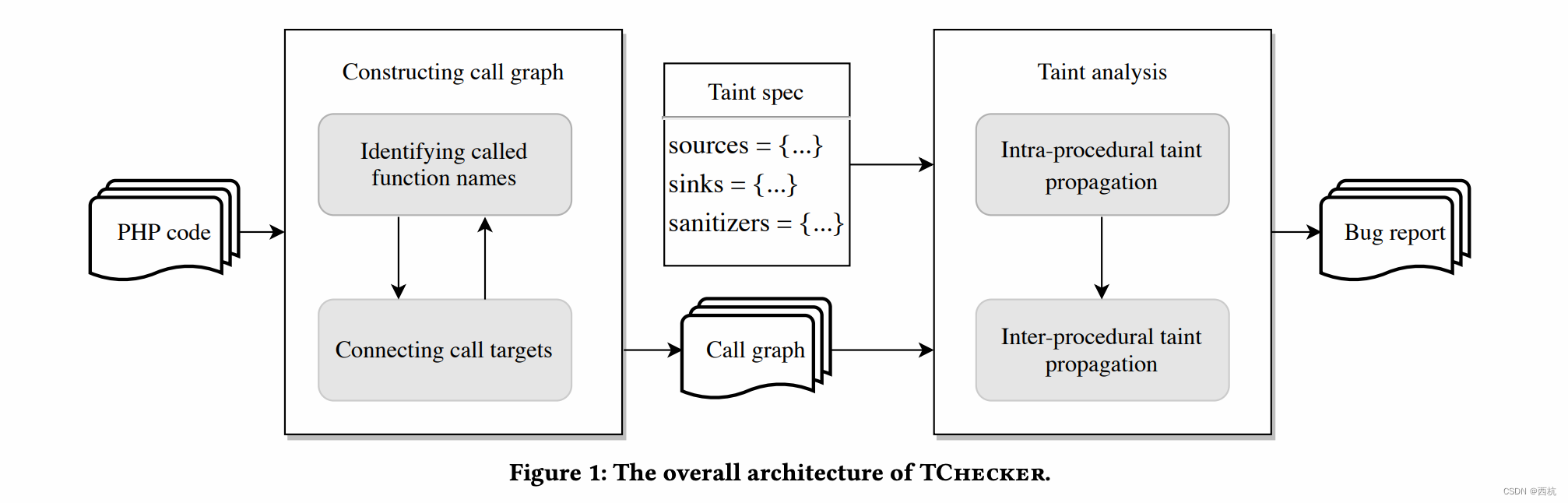
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_2 (Embedding) (None, None, 16) 160000
_________________________________________________________________
global_average_pooling1d_2 ( (None, 16) 0
_________________________________________________________________
dense_4 (Dense) (None, 24) 408
_________________________________________________________________
dense_5 (Dense) (None, 1) 25
=================================================================
Total params: 160,433
Trainable params: 160,433
Non-trainable params: 0
_________________________________________________________________由于嵌入有 10,000 个单词的词汇表,每个单词都是 16 维的向量,因此可训练参数的总数为 160,000。
平均池化层有 0 个可训练参数,因为它只是对之前嵌入层中的参数进行平均,以获得单个 16 值向量。
然后将其送入 24 个神经元的致密层。请记住,密集神经元使用权重和偏差进行有效计算,因此需要学习 (24 × 16) + 16 = 408 个参数。
然后将该层的输出传递到最后的单神经元层,其中将有 (1 × 24) + 1 = 25 个参数需要学习。
如果我们训练这个模型,在 30 个时期后我们将获得 99+% 的相当不错的准确率——但我们的验证准确率将只有大约 81%(图 6-2)。
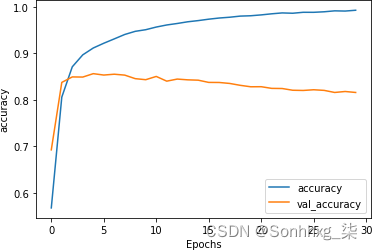
图 6-2。训练准确性与验证准确性
考虑到验证数据可能包含许多训练数据中不存在的词,这似乎是一条合理的曲线。但是,如果您检查30 个时期内训练与验证的损失曲线,你会发现一个问题。尽管您希望看到训练准确度高于验证准确度,但一个明确的指标过度拟合是,虽然验证准确率随着时间的推移略有下降(在图 6-2中),但它的损失却在急剧增加,如图 6-3所示。
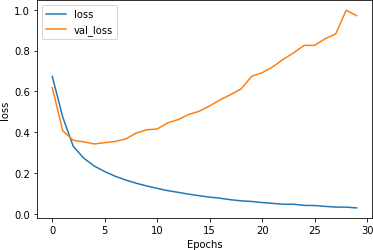
图 6-3。训练损失与验证损失
由于语言的某种不可预测性,像这样的过度拟合在 NLP 模型中很常见。在接下来的部分中,我们将研究如何使用多种技术来减少这种影响。
减少语言模型中的过度拟合
过拟合当网络对训练数据过度专业化时,就会发生这种情况,其中一部分是它已经非常擅长匹配训练集中“嘈杂”数据中的模式,而这些模式在其他任何地方都不存在。因为验证集中不存在这种特殊的噪声,所以网络匹配得越好,验证集的损失就越严重。这会导致您在图 6-3中看到的不断增加的损失。在本节中,我们将探讨几种泛化模型和减少过度拟合的方法。
调整学习率
也许可能导致过度拟合的最大因素是优化器的学习率是否过高。这意味着网络学习太快了。对于这个例子,编译模型的代码如下:
model.compile(loss='binary_crossentropy',
optimizer='adam', metrics=['accuracy'])优化器简单地声明为adam,它使用默认参数调用 Adam 优化器。但是,此优化器支持多个参数,包括学习率。您可以将代码更改为:
adam = tf.keras.optimizers.Adam(learning_rate=0.0001,
beta_1=0.9, beta_2=0.999, amsgrad=False)
model.compile(loss='binary_crossentropy',
optimizer=adam, metrics=['accuracy'])其中学习率的默认值(通常为 0.001)已减少 90% 至 0.0001。和beta_1值beta_2保持默认值, 也是如此amsgrad。beta_1并且beta_2必须介于 0 和 1 之间,通常两者都接近 1。Amsgrad 是 Adam 优化器的替代实现,在Sashank Reddi、Satyen Kale 和 Sanjiv Kumar 的论文“On the Convergence of Adam and Beyond”中介绍。
这个低得多的学习率对网络有深远的影响。图 6-4显示了网络超过 100 个时期的准确率。在前 10 个时期左右可以看到较低的学习率,在网络“爆发”并开始快速学习之前,网络似乎没有在学习。
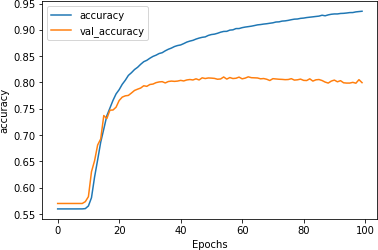
图 6-4。较低学习率的准确性
探索损失(如图 6-5所示)我们可以看到,即使在前几个时期的准确性没有上升,损失也在下降,所以你可以相信网络最终会开始学习,如果你一个时代一个时代地看着它。
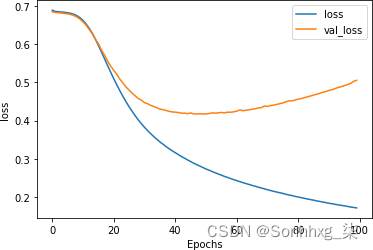
图 6-5。学习率较低的损失
虽然损失确实开始显示与您在图 6-3中看到的相同的过度拟合曲线,但请注意,它发生的时间要晚得多,而且发生率要低得多。到第 30 轮时,损失约为 0.45,而图 6-3中学习率较高时,损失是该数量的两倍多。虽然网络需要更长的时间才能达到良好的准确率,但它的损失更少,因此您可以对结果更有信心。使用这些超参数,验证集的损失在大约第 60 个时期开始增加,此时训练集的准确度为 90%,验证集的准确度约为 81%,表明我们拥有一个非常有效的网络。
当然,调整优化器然后宣布胜利很容易,但是您可以使用许多其他方法来改进您的模型,您将在接下来的几节中看到这些方法。对于这些,我恢复使用默认的 Adam 优化器,因此调整学习率的效果不会隐藏这些其他技术提供的好处。
探索词汇量
这Sarcasm 数据集处理单词,因此如果您探索数据集中的单词,尤其是它们的频率,您可能会得到有助于解决过度拟合问题的线索。
这tokenizer 为您提供了一种方法 word_counts财产。如果你要打印它,你会看到这样的东西,一个OrderedDict包含字和字数的元组:
wc=tokenizer.word_counts
print(wc)
OrderedDict([('former', 75), ('versace', 1), ('store', 35), ('clerk', 8),
('sues', 12), ('secret', 68), ('black', 203), ('code', 16),...单词的顺序由它们在数据集中出现的顺序决定。如果您查看训练集中的第一个标题,就会发现这是一个关于前 Versace 店员的讽刺标题。停用词已被删除;否则你会看到大量的单词,如“a”和“the”。
鉴于它是一个OrderedDict,您可以将其排序为单词量的降序:
from collections import OrderedDict
newlist = (OrderedDict(sorted(wc.items(), key=lambda t: t[1], reverse=True)))
print(newlist)
OrderedDict([('new', 1143), ('trump', 966), ('man', 940), ('not', 555), ('just',
430), ('will', 427), ('one', 406), ('year', 386),如果你想绘制它,你可以遍历列表中的每个项目并使x值成为你所在位置的序数(第一个项目为 1,第二个项目为 2,等等)。y值将是newlist[item]. 然后可以用 绘制matplotlib。这是代码:
xs=[]
ys=[]
curr_x = 1
for item in newlist:
xs.append(curr_x)
curr_x=curr_x+1
ys.append(newlist[item])
plt.plot(xs,ys)
plt.show()结果如图6-6所示。
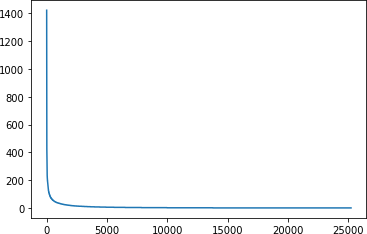
图 6-6。探索单词的频率
这条“曲棍球棒”曲线向我们展示了很少的单词被多次使用,而大多数单词被使用的次数很少。但是每个词实际上都具有相同的权重,因为每个词在嵌入中都有一个“条目”。鉴于与验证集相比我们有一个相对较大的训练集,我们最终会遇到训练集中存在许多验证集中不存在的单词的情况。
您可以通过在调用 之前更改绘图的轴来放大数据plt.show。例如,要查看 x 轴上 300 到 10,000 的单词数量,以及 y 轴上从 0 到 100 的刻度,您可以使用以下代码:
plt.plot(xs,ys)
plt.axis([300,10000,0,100])
plt.show()结果如图 6-7所示。
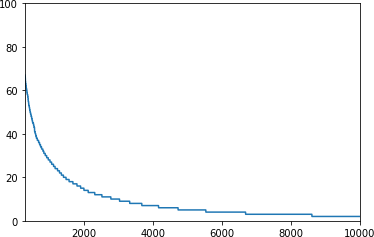
图 6-7。词频 300–10,000
虽然语料库中有超过 20,000 个单词,但代码设置为仅训练 10,000 个单词。但是,如果我们查看 2,000-10,000 位置的词,也就是我们词汇量的 80% 以上,我们会发现它们在整个语料库中的使用次数都不到 20 次。
这可以解释过度拟合。现在考虑如果将词汇量更改为 2000 并重新训练会发生什么。图 6-8显示了准确度指标。现在训练集准确率约为 82%,验证准确率约为 76%。它们彼此更接近并且没有发散,这是一个很好的迹象,表明我们已经摆脱了大部分过度拟合。
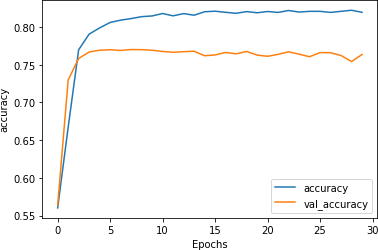
图 6-8。两千字词汇量的准确性
图 6-9中的损耗图在某种程度上加强了这一点。验证集的损失正在上升,但比以前慢得多,因此减少词汇量以防止训练集过度拟合可能只出现在训练集中的低频词似乎奏效了。
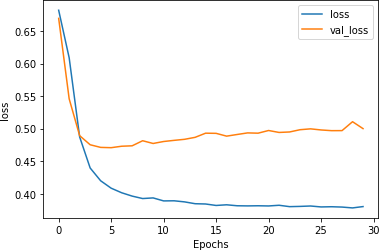
图 6-9。损失了两千个单词的词汇
尝试不同的词汇大小是值得的,但请记住,您也可以使用太小的词汇大小并对其过度拟合。你需要找到一个平衡点。在这种情况下,我选择出现 20 次或更多次的词纯粹是武断的。
探索嵌入维度
为了在这个例子中,任意选择了 16 的嵌入维度。在这个例子中,单词被编码为 16 维空间中的向量,它们的方向表示它们的整体含义。但是 16 是一个好数字吗?我们的词汇量只有两千个单词,它可能偏高,导致方向高度稀疏。
嵌入大小的最佳实践是让它成为词汇大小的四次方根。2,000 的四次方根是 6.687,所以让我们探讨一下如果将嵌入维度更改为 7 并重新训练模型 100 个时期会发生什么。
您可以在图 6-9中看到关于准确性的结果。训练集的准确率稳定在 83% 左右,验证集的准确率稳定在 77% 左右。尽管有些紧张,但线条非常平坦,表明模型已经收敛。这与图 6-6中的结果没有太大区别,但降低嵌入维数可使模型的训练速度提高 30% 以上。
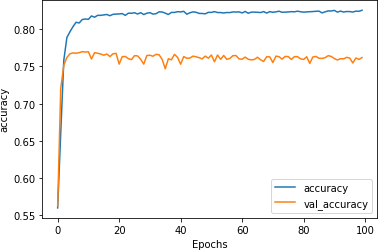
图 6-10。七个维度的训练与验证准确性
图 6-11显示了训练和验证中的损失。虽然最初看起来损失在大约第 20 轮开始攀升,但很快就趋于平缓。又是一个好兆头!
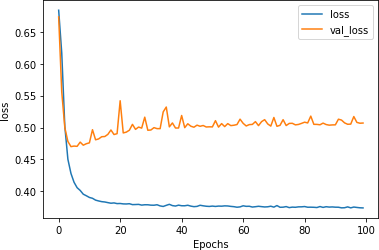
图 6-11。七个维度的训练与验证损失
现在维度已经减少,我们可以对模型架构做更多的调整。
探索模型架构
model = tf.keras.Sequential([
tf.keras.layers.Embedding(2000, 7),
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(24, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(loss='binary_crossentropy',
optimizer='adam',metrics=['accuracy'])突然想到的一件事是维度——该GlobalAveragePooling1D层现在只发射七个维度,但它们被馈送到一个由 24 个神经元组成的密集层中,这太过分了。让我们探索一下当它减少到只有八个神经元并训练一百个时期时会发生什么。
你可以在图 6-12中看到训练与验证的准确性。与使用 24 个神经元的图 6-7相比,整体结果非常相似,但波动已被平滑(在线条中可见锯齿较少)。训练速度也稍快一些。
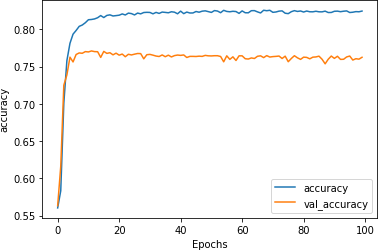
图 6-12。降低密集架构精度结果
同样,图 6-13中的损失曲线显示了类似的结果,但锯齿状减少了。

图 6-13。减少密集架构损失结果
使用dropout
现在我们的架构已被简化为在中间密集层中只有八个神经元,dropout 的影响可能会最小化,但无论如何让我们探索一下。这是模型架构的更新代码,添加了 0.25 的 dropout(相当于我们八个神经元中的两个):
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim),
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(8, activation='relu'),
tf.keras.layers.Dropout(.25),
tf.keras.layers.Dense(1, activation='sigmoid')
])图 6-14显示了训练一百个 epoch 后的准确率结果。
这次我们看到训练准确率攀升至之前的阈值之上,而验证准确率却在缓慢下降。这表明我们再次进入过拟合领域。研究图 6-15中的损耗曲线证实了这一点。
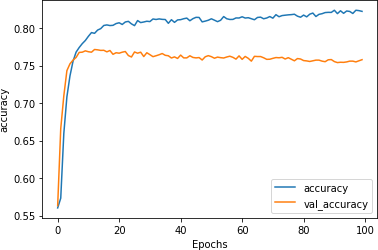
图 6-14。增加 dropout 的准确性
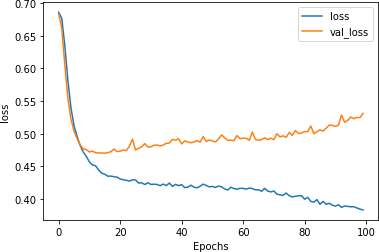
图 6-15。添加丢失的损失
在这里,您可以看到该模型正在回到其先前的验证损失随时间增加的模式。它不像以前那么糟糕,但它正朝着错误的方向前进。
在这种情况下,当神经元很少时,引入 dropout 可能不是正确的主意。不过,在您的武器库中拥有此工具仍然是一件好事,因此请务必牢记这一点,以了解比此工具更复杂的架构。
使用正则化
正则化是一种通过减少权重的极化来帮助防止过度拟合的技术。如果一些神经元的权重太重,正则化会有效地惩罚它们。从广义上讲,有两种类型的正则化:L1和L2。
L1 正则化通常称为套索(最小绝对收缩和选择算子)正则化。它有效地帮助我们在计算层中的结果时忽略零或接近零的权重。
L2 正则化通常称为岭回归,因为它通过取正方形将值分开。这往往会放大非零值与零值或接近零值之间的差异,从而产生岭效应。
对于像我们正在考虑的 NLP 问题,L2 是最常用的。它可以作为一个属性添加到Dense层使用 kernel_regularizers属性,并采用浮点值作为正则化因子。这是您可以用来改进模型的另一个超参数!
这是一个例子:
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim),
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(8, activation='relu',
kernel_regularizer = tf.keras.regularizers.l2(0.01)),
tf.keras.layers.Dense(1, activation='sigmoid')
])在像这样的简单模型中添加正则化的影响并不是特别大,但它确实在一定程度上消除了我们的训练损失和验证损失。对于这种情况可能有点矫枉过正,但就像 dropout 一样,了解如何使用正则化来防止模型过度专业化是个好主意。
其他优化注意事项
尽管我们所做的修改为我们提供了一个大大改进的模型,减少了过度拟合,您还可以试验其他超参数。例如,我们选择将最大句子长度设置为 100,但这纯粹是任意的,可能不是最优的。探索语料库并查看更好的句子长度是个好主意。这是一个查看句子并绘制每个句子的长度的代码片段,从低到高排序:
xs=[]
ys=[]
current_item=1
for item in sentences:
xs.append(current_item)
current_item=current_item+1
ys.append(len(item))
newys = sorted(ys)
import matplotlib.pyplot as plt
plt.plot(xs,newys)
plt.show()结果如图6-16所示。
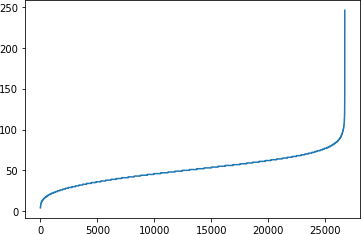
图 6-16。探索句子长度
在 26,000 多个语料库中,只有不到 200 个句子的长度为 100 个或更长,因此通过选择这个作为最大长度,我们引入了很多不必要的填充,并影响了模型的性能。将其减少到 85 仍然会保留 26,000 个句子 (99%+),根本没有任何填充。
使用模型对句子进行分类
现在您已经创建了模型,对其进行了训练并对其进行了优化以消除导致过度拟合的许多问题,下一步是运行模型并检查其结果。为此,创建一个新句子数组。例如:
sentences = ["granny starting to fear spiders in the garden might be real",
"game of thrones season finale showing this sunday night",
"TensorFlow book will be a best seller"]然后可以使用创建训练词汇表时使用的相同分词器对这些进行编码。使用它很重要,因为它具有用于训练网络的单词的标记!
sequences = tokenizer.texts_to_sequences(sentences)
print(sequences)打印语句的输出将是前面句子的序列:
[[1, 816, 1, 691, 1, 1, 1, 1, 300, 1, 90],
[111, 1, 1044, 173, 1, 1, 1, 1463, 181],
[1, 234, 7, 1, 1, 46, 1]]这里有很多1标记(“<OOV>”),因为像“in”和“the”这样的停用词已从字典中删除,而像“granny”和“spiders”这样的词在字典中没有出现。
在将序列传递给模型之前,它们需要具有模型期望的形状,即所需的长度。您可以使用与pad_sequences训练模型时相同的方式执行此操作:
padded = pad_sequences(sequences, maxlen=max_length,
padding=padding_type, truncating=trunc_type)
print(padded)这会将句子输出为 length 的序列100,因此第一个序列的输出将是:
[ 1 816 1 691 1 1 1 1 300 1 90 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0]很短的一句话!
现在句子已经被标记化和填充以符合模型对输入维度的期望,是时候将它们传递给模型并取回预测了。这就像这样做一样简单:
print(model.predict(padded))结果将作为列表传回并打印,高值表示可能是讽刺。以下是我们的示例句子的结果:
[[0.7194135 ]
[0.02041999]
[0.13156283]]第一句话的高分(“奶奶开始害怕花园里的蜘蛛可能是真的”),尽管它有很多停用词并用很多零填充,表明这里有很高的讽刺意味。另外两个句子得分低得多,表明其中讽刺的可能性较低。
可视化嵌入
至可视化嵌入,您可以使用称为Embedding Projector 的工具。它预加载了许多现有数据集,但在本节中,您将了解如何从刚刚训练的模型中获取数据并使用此工具将其可视化。
首先,您需要一个函数来反转单词索引。它目前将词作为标记,将键作为值,但这需要倒置,以便我们在投影仪上绘制词值。这是执行此操作的代码:
reverse_word_index = dict([(value, key)
for (key, value) in word_index.items()])您还需要提取嵌入中向量的权重:
e = model.layers[0]
weights = e.get_weights()[0]
print(weights.shape)(2000,7)如果您按照本章中的优化进行操作,其输出将是这样的——我们使用了 2,000 个单词的词汇表和 7 个维度的嵌入。如果你想探索一个词和它的向量细节,你可以用这样的代码来实现:
print(reverse_word_index[2])
print(weights[2])这将产生以下输出:
new
[ 0.8091359 0.54640186 -0.9058702 -0.94764805 -0.8809764 -0.70225513
0.86525863]因此,“新”一词由一个轴上带有这七个系数的向量表示。
Embedding Projector 使用两个制表符分隔值 (TSV) 文件,一个用于矢量维度,一个用于元数据。此代码将为您生成它们:
import io
out_v = io.open('vecs.tsv', 'w', encoding='utf-8')
out_m = io.open('meta.tsv', 'w', encoding='utf-8')
for word_num in range(1, vocab_size):
word = reverse_word_index[word_num]
embeddings = weights[word_num]
out_m.write(word + "\n")
out_v.write('\t'.join([str(x) for x in embeddings]) + "\n")
out_v.close()
out_m.close()如果您使用的是 Google Colab,则可以使用以下代码或从“文件”窗格下载 TSV 文件:
try:
from google.colab import files
except ImportError:
pass
else:
files.download('vecs.tsv')
files.download('meta.tsv')拥有它们后,您可以按投影仪上的加载按钮来可视化嵌入,如图6-17所示。
使用结果对话框中推荐的矢量和元 TSV 文件,然后单击投影仪上的 Sphereize Data。这将使单词聚集在一个球体上,并使您清楚地看到该分类器的二元性质。它只接受过讽刺和非讽刺句子的训练,因此单词倾向于聚集到一个或另一个标签(图 6-18)。
图 6-17。使用嵌入投影仪

图 6-18。可视化讽刺嵌入
屏幕截图并不公正;你应该亲自尝试一下!您可以旋转中心球体并探索每个“极点”上的单词,以查看它们对整体分类的影响。您还可以选择单词并在右侧窗格中显示相关单词。玩一玩,做个实验。
使用来自 TensorFlow Hub 的预训练嵌入
一个训练自己的嵌入的替代方法是使用已经为您预训练并打包到 Keras 层中的嵌入。您可以在TensorFlow Hub上探索其中的许多内容。需要注意的一件事是它们还可以包含为您提供标记化逻辑,因此您不必像目前为止自己处理标记化、排序和填充。
TensorFlow Hub 预装在 Google Colab 中,因此本章中的代码将按原样运行。如果您想将其作为依赖项安装在您的机器上,则需要按照说明安装最新版本。
例如,对于 Sarcasm 数据,而不是所有用于标记化、词汇管理、排序、填充等的逻辑,一旦你有了完整的句子和标签集,你就可以做这样的事情。首先,将它们分成训练集和测试集:
training_size = 24000
training_sentences = sentences[0:training_size]
testing_sentences = sentences[training_size:]
training_labels = labels[0:training_size]
testing_labels = labels[training_size:]一旦你有了这些,你就可以像这样从 TensorFlow Hub 下载一个预训练层:
import tensorflow_hub as hub
hub_layer = hub.KerasLayer(
"https://tfhub.dev/google/tf2-preview/gnews-swivel-20dim/1",
output_shape=[20], input_shape=[],
dtype=tf.string, trainable=False
)然后,您可以使用该层而不是嵌入层来创建模型架构。这是一个使用它的简单模型:
model = tf.keras.Sequential([
hub_layer,
tf.keras.layers.Dense(16, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
adam = tf.keras.optimizers.Adam(learning_rate=0.0001, beta_1=0.9,
beta_2=0.999, amsgrad=False)
model.compile(loss='binary_crossentropy',optimizer=adam,
metrics=['accuracy'])该模型将在训练中迅速达到最高准确度,并且不会像我们之前看到的那样过度拟合。超过 50 个时期的准确性表明训练和验证彼此非常同步(图 6-19)。
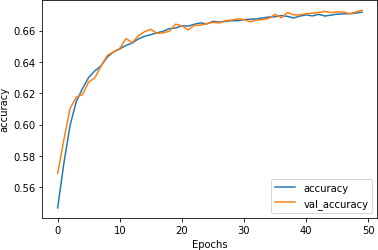
图 6-19。使用旋转嵌入的准确性指标
损失值也是同步的,表明我们拟合得非常好(图 6-20)。
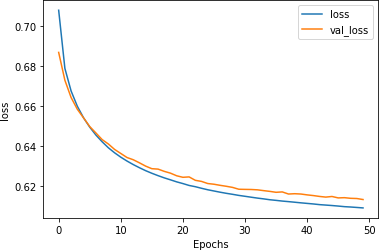
图 6-20。使用旋转嵌入的损失指标
然而,值得注意的是,整体准确率(大约 67%)相当低,考虑到抛硬币有 50% 的机会正确!这是由于将所有基于单词的嵌入编码为基于句子的嵌入——在讽刺标题的情况下,似乎单个单词会对分类产生巨大影响(见图 6-18 )。因此,虽然使用预训练嵌入可以加快训练速度并减少过度拟合,但您还应该了解它们的用途是什么,并且它们可能并不总是最适合您的场景。
概括
在本章中,您构建了第一个模型来理解文本中的情绪。它通过获取第 5 章中的标记化文本并将其映射到向量来实现。然后,使用反向传播,它根据包含它的句子的标签为每个向量学习适当的“方向”。最后,它能够将所有向量用于一组单词,以构建句子中的情感概念。您还探索了优化模型以避免过度拟合的方法,并看到了简洁的可视化效果代表你的话的最终向量。虽然这是一种很好的句子分类方法,但它只是将每个句子视为一堆单词。不涉及固有顺序,并且由于单词出现的顺序对于确定句子的真正含义非常重要,因此最好看看我们是否可以通过考虑顺序来改进我们的模型。我们将在下一章中通过引入一种新的层类型来探索这一点——循环层,它是循环神经网络的基础。您还会看到另一个预训练嵌入,称为 GloVe,它允许您在迁移学习场景中使用基于词的嵌入。