影像组学研究的基本流程知识点
01
准备工作
研究前我们先要做好准备工作:(这个准备工作呢就好像小白做菜)
最开始,我们往往主动提出或者被提出了一个临床问题(临床问题可能是老板直接安排的,也可能是在临床工作中提出经过文献调研归纳的),根据提出的临床问题和手头现有的病例,可以建立一个简化版的科学假设(例如:在xxx疾病中,影像组学模型可以预测/辅助诊断xxx结局;或者是影像组学特征可以反应xxx疾病的病理/生理异质性);
(今晚老婆不在家,要自己做饭了,根据我平时吃饭的经验…)
①进行目标疾病的影像组学研究进行进一步文献调研(先找一本居家小白速成食谱,看看别人都做什么菜)
a.针对所提出临床问题的治疗背景;
b.目前临床上评价该问题的金标准是什么,面临的困境又是什么;
c.现有的针对该临床问题的影像组学研究有哪些,我们是第一个用影像组学方法解决这个临床问题的人嘛?还是前人已经有研究,那么我们的研究相比与前人的研究可以在哪些方面有所提升呢?;
这个过程也是帮助大家写文章的Introduction和Discussion部分的。
②分析收集到的病例(盘点下家里有什么食材和佐料,食材质量如何,食材过没过期)
a.整理患者的基线信息(人口学特征,疾病相关参数,治疗相关参数,病理指标,血液指标,影像学征象等等);
b.整理患者治疗方案和随访方案protocol,以及影像学参数信息;
c.初步建立纳排标准;
d.进行数据集的划分;
e.可以根据PICOS原则进行整理看看有没有缺项;
③据此,整理临床研究的321法则;(决定晚上做什么)
至此,准备工作完毕,下面进入影像组学部分:
简单来说,分为4部分:Imaging(图像收集获取)、Segmentation(分割)、Feature extraction(特征提取)、Analysis(特征选择、预测模型构建)
那么我们下面逐一介绍
02
第一步:Imaging,图像收集获取(+图像预处理)
-
图像格式要求
✓一般来说,收集的格式为DICOM格式(全称Digital Imaging and Communications in Medicine,翻译为“医疗数字影像传输协定”),与PNG,JPG类似,是一种电子文件的储存格式。需要有电脑里专门的软件打开或编辑。
这里我展示的就是CT患者的DICOM影像资料
✓ DICOM格式图片相比Png、Jpg普通图片格式具有以下优势
✓1、DICOM文件的头文件(header)里包含重要信息
- 主要包括四类: Patients病人信息, Study检查信息, Series序列信息 以及Image图像信息
✓2、DICOM文件的 “灰阶” 范围比普通图片大得多
大家先有个印象即可,具体的在以后的实战课程会讲,但是从影像科要的的影像资料先确保DICOM格式,以及如何将DICOM格式的文件转换为nii格式或nrrd格式,今天先不多提。
-
到了这里,大家会不会有这样的疑问:我们医院有5个CT设备,CT图像能一起研究嘛?
✓首先需要明确,我们为什么要对影像进行预处理;
✓拿CT来说,医院/中心不同、CT设备不同、扫描人员不同、以及层厚的具体参数设置不同都会产生差异,而这些差异,对最终提取特征的可重复性和可靠性有时是“毁灭性”的;
-
那么我们应该如何对图像进行处理呢?
还是以CT为例
✓1. 首先要对体素大小进行重采样至3×3×3 mm3 ;
-
使各向同性,以减少由于扫描设备与方案存在差异,患者的病灶大小不同等产生的变异
影像扫描得到X,Y,Z三个方向的体素间距,X,Y方向的体素间距较小,Z方向的体素间距略大,我们把这种情况称之为各向异性,而重采样至1*1*1mm3后,各向异性的图像变为各相同性
- 标准化体素间距,最小化影像组学特征对影像体素大小的依赖性
-
确保每个体素所代表的实际物理尺寸一致,减少个体差异影响
✓2. 将体素强度值通过使用 25 HU的固定bin width进行离散化;
-
目的是可以减少图像噪声并标准化强度,从而在所有图像中实现稳定的强度分辨率
✓3. 对图像进行归一化处理,将信号强度归一化至 1~500 HU;
-
目的是可以减少不同机器采集图像信号强度的差异
✓4. 对图像灰度值进行Z-score标准化处理;
-
减少由影像参数不一致产生的对影像组学特征变异的影响
对于MR影像
✓在对病灶进行分割前,对MR图像行N4偏置场校正;
-
MRI 图像数据中存在的
低频强度不均匀性,称为偏置场,
处理MRI图像前我们一般通过
代码对MRI图像进行N4偏执场矫正
✓将图像重新采样到体素大小为1×1×1 mm3,以标准化体素间距;
✓体素强度值通过使用 5 SI的固定bin width进行离散化,以减少图像噪声并标准化强度,从而在所有图像中实现稳定的强度分辨率;
✓对图像进行归一化处理,将信号强度归一化至 1~100 SI,减少不同机器采集图像信号强度的差异。
✓同样MR影像也可以对图像灰度值进行Z-score标准化处理,减少由影像参数不一致产生的对影像组学特征变异的影响。
03
第二步:Segmentation,分割
先给下图像分割的定义:指将图像分成若干特定具备独特属性的区域,并提取感兴趣目标的技术和过程。
分割是影像组学流程中最为重要一个环节。这一步的重要性是因为影像组学特征值直接来源于分割区域。
那么我刚刚提到的感兴趣区又是什么呢?
o感兴趣区分为二维和三维的;
o二维的ROI 全称region of interest;感兴趣区;
-
举个栗子:卵巢癌的ROI
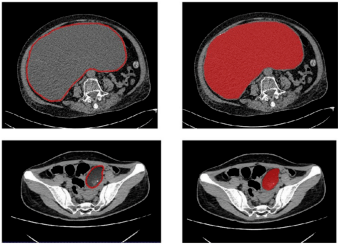
o三维的VOI全称 volume of interst ;感兴趣体积;
- 举个栗子:肾癌的VOI

o目前对于CT和MRI来说,选择VOI还是更多的,提取的特征也会更多;
o而我们常说的掩膜就是实现感兴趣区分割这一过程的手段,简单来讲,就是相当于用一个膜将感兴趣区覆盖,然后从覆盖区域提取矩阵的过程。
感兴趣区的概念介绍到这,我们再来说说分割方法。
-
根据人工参与度的不同,分割方式分为三类
o手动分割:目前一般以此为金标准;费时费力,存在勾画者内/间不一致性
o半自动分割:速度较快,可代替部分人力工作;需要手动校正
o全自动分割:速度快,可重复性高;当前研究仍难以有效应用
o不同的分割标准和算法会导致分割区域有差异,追求真实的病灶边缘(手动分割)还是追求分割的高重复性(自动分割),是分割过程具有争议的点。目前,手动分割还是影像组学分割的金标准。
-
下面就来介绍一下大家比较关心的分割工具
o实现分割的工具也有很多,3DSlicer,ITK-SNAP,LIFEx,Image J,IBEX或者基于Matlab的工具等等;
o
-
3DSlicer(www.slicer.org/)
·由美国国家卫生研究院以及全球开发者社区维护;
·操作简便,有半自动分割工具;
·是影像组学研究的首选,后面小韩老师也会主要对利用3DSlicer进行靶区勾画进行实操教学;
- ITK-SNAP( www.itksnap.org )
·由宾夕法尼亚大学佩恩图像计算与科学实验室开发;
·操作简便,包含大量半自动分割算法;
- 分割过程一般类似这样:由一名影像学医师(10年影像科工作经历)在盲于患者临床资料和诊断结果的情况下独立对病灶进行逐层手动勾画,勾画过程中避开大血管、坏死、囊变等区域(根据具体情况描述)。由另外一名医师(7年影像科工作经历)随机抽取30例进行二次勾画。当然,这里只是举个例子,让大家有一个感性的认知,具体问题具体分析。
- 分割区域:
o全瘤
o瘤周区域
o肿瘤亚区域(生境)
- 最后,再来说说目前分割过程面临的挑战
o首先是没有金标准,手动分割被认为是金标准,但其实还是没有官方明确规定的金标准;
o其次,就是肿瘤形态不规则,临床医生做3D分割需要逐层勾画,而且不同人勾画的结果也不一定相同;
o第三就是肿瘤边界的界定,有一些肿瘤边界是模糊不清的,到底是画还是不画这就很难办;
o一般来说有两种解决方法,第一个就是两名医生画,看到无法界定的,病例就不要了,但是一般这么壕气的人比较少;如果病例本来就少,那么就由第三名更有经验的医生界定完成勾画。
至此,第二步分割讲解完毕。
04
第三步:Feature extraction,特征提取(+数据预处理+特征的一致性评价)
首先,给下定义:从分割后的影像中提取高通量的特征,以供算法和模型使用,是影像组学的核心步骤(“数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已“)。
-
影像组学特征分为两大类:语义特征(semantic features)和非语义特征(non-semantic features/agnostic features不可知特征)。
o语义特征可以指影像学征象:如毛刺征、凹陷征、鳞屑、中央坏死区等,也指放射科医生影像描述中常用的特征:如位置、尺寸、形状、血管等(用影像组学辅助分析我们肉眼可以看到的,早期影像学结合机器学习的研究常用计算机提取识别语义特征);
o非语义特征是指用数学方法(从数据角度)从图像中提取的特征,又可细分为形状特征、一阶、二阶和高阶特征等(机器学习发展);
- 形状特征包括肿瘤的体积、表面积、致密性等;
- 一阶特征用于描述各体素信号强度值的分布情况,多采用信号强度的最大值、最小值、均值、中位数、熵、偏斜度和峰度等方法;
- 二阶特征主要描述各体素之间的关系 ,例如 纹理特征值可以反映病灶内部信号强度的异质性(如GLCM、GLRLM、NGTDM、GLSZM等);
- 高阶特征是指通过添加过滤器提取影像特征变量,包括小波变换( Wavelet) 等(小波变换指的是使用复杂的线性或径向波矩阵乘以图像获得)(其它基于滤波器提取的影像组学特征还包括 LoG、Square、SquareRoot、Exponential、Logarithm、LBP3D 、 Gradient);
- 下面这个框图帮助大家更清晰的了解这些特征在影像组学研究中的位置以及他们的关系

o而我们在影像组学研究更多的关注可以高通量提取的非语义特征。
-
目前,可以进行影像组学特征提取的工具非常之多,随便为大家举个栗子:

o下面是参与影像标志物标准声明IBSI的机构所使用的特征提取方法:
o这些工具包括基于C或C++开发的特征提取工具、在MATLAB中开发的影像组学特征提取工具、影像设备供应的公司提供的特征提取软件,在线网站提取工具等等
o不过呢,目前兼顾功能强大,开源,操作较为简单,并且可以对影像组学特征可以进行批量提取等特质的工具我们首推Pyradiomics(https://pyradiomics.readthedocs.io/en/latest/)
oPyradiomics是一个开源的Python包,不仅可提取三维图像的纹理特征,还可以提取基于 LoG 滤波和小波变换特征。此外,它还可以作为插件与 3DSlicer的分割模块配合使用。
o打开官网,我们看到里面已经有详细的特征类别介绍
o下面简单为大家总结一下这些特征都有什么
- 形状特征(14个):
1 Mesh Volume(网格体积)
2 Voxel Volume(体素体积)
3 Surface Area(表面积)
4 Surface Area to Volume ratio(表面积体积比)
5 Sphericity(球度)
6 Maximum 3D diameter(最大3D直径)
7 Maximum 2D diameter (Slice)(最大2D直径(切片))
8 Maximum 2D diameter (Column)(最大2D直(列))
9 Maximum 2D diameter (Row)(最大2D直径(行))
10 Major Axis Length(最大轴长度)
11 Minor Axis Length(第二大轴长度)
12 Least Axis Length(最短轴长度)
13 Elongation(伸长率)
14 Flatness(平面度)
- 一阶特征(18个)
1 Energy(能量)
2 Total Energy(总能量)
3 Entropy(熵)
4 Minimum(最小值)
5 10th percentile(第十百分位)
6 90th percentile(第九十百分位)
7 Maximum(最大值)
8 Mean(均值)
9 Median(中值)
10 Interquartile Range(四分位范围)
11 Range(极差)
12 Mean Absolute Deviation (MAD)(平均绝对偏差)
13 Robust Mean Absolute Deviation(rMAD,鲁棒平均绝对偏差)
14 Root Mean Squared(RMS,均方根)
15 Skewness(偏度)
16 Kurtosis(峰度)
17 Variance(方差)
18 Uniformity(均匀性)
-
灰度共生矩阵特征GLCM(24个)
GLCM描述图像在变化幅度、相邻间隔、方向等方面的信息
1 Autocorrelation(自相关)
2 Joint Average(联合平均)
3 Cluster Prominence(集群突出)
4 Cluster Shade(集群阴影)
5 Cluster Tendency(集群趋势)
6 Contrast(对比度)
7 Correlation(相关性)
8 Difference Average(差平均)
9 Difference Entropy(差熵)
10 Difference Variance(差方差)
11 Joint Energy(联合能量)
12 Joint Entropy(联合熵)
13 Informational Measure of Correlation 1(IMC 1,相关信息测度1)
14 Informational Measure of Correlation 2(IMC 2,相关信息测度2)
15 Inverse Difference Moment(IDM,逆差矩)
16 Maximal Correlation Coefficient(MCC,最大相关系数)
17 Inverse Difference Moment Normalized(IDMN,归一化逆差矩)
18 Inverse Difference(ID,逆差)
19 Inverse Difference Normalized(IDN,归一化逆差)
20 Inverse Variance(逆方差)
21 Maximum Probability(最大概率)
22 Sum Average(和平均)
23 Sum Entropy(和熵)
24 Sum of Squares(和方差)
-
灰度区域大小矩阵特征GLSZM(16个)
GLSZM描述同质性区域的特征
1 Small Area Emphasis(SAE,小面积强调)
2 Large Area Emphasis(LAE,大面积强调)
3 Gray Level Non-Uniformity(GLN,灰度不均匀性)
4 Gray Level Non-Uniformity Normalized(GLNN,归一化灰度不均匀性)
5 Size-Zone Non-Uniformity(SZN,区域大小不均匀性)
6 Size-Zone Non-Uniformity Normalized(SZNN,归一化区域大小不均匀性)
7 Zone Percentage(ZP,区域百分比)
8 Gray Level Variance(GLV,灰度方差)
9 Zone Variance(ZV,区域方差)
10 Zone Entropy(ZE,区域熵)
11 Low Gray Level Zone Emphasis(LGLZE,低灰度区域强调)
12 High Gray Level Zone Emphasis(HGLZE,高灰度区域强调)
13 Small Area Low Gray Level Emphasis(SALGLE,小区域低灰度强调)
14 Small Area High Gray Level Emphasis(SAHGLE,小区域高灰度强调)
15 Large Area Low Gray Level Emphasis(LALGLE,大区域低灰度强调)
16 Large Area High Gray Level Emphasis(LAHGLE,大区域高灰度强调)
-
灰度行程矩阵特征GLRLM(16个)
GLRLM可量化图像中的灰度级的分布
1 Short Run Emphasis(SRE,短行程强调)
2 Long Run Emphasis(LRE,长行程强调)
3 Gray Level Non-Uniformity(GLN,灰度不均匀性)
4 Gray Level Non-Uniformity Normalized(GLNN,归一化灰度不均匀性)
5 Run Length Non-Uniformity(RLN,行程不均匀性)
6 Run Length Non-Uniformity Normalized(RLNN,归一化行程不均匀性)
7 Run Percentage(RP,行程百分比)
8 Gray Level Variance(GLV,灰度方差)
9 Run Variance(RV,行程方差)
10 Run Entropy(RE,行程熵)
11 Low Gray Level Run Emphasis(LGLRE,低灰度行程强调)
12 High Gray Level Run Emphasis(HGLRE,高灰度行程强调)
13 Short Run Low Gray Level Emphasis(SRLGLE,短行程低灰度强调)
14 Short Run High Gray Level Emphasis(SRHGLE,短行程高灰度强调)
15 Long Run Low Gray Level Emphasis(LRLGLE,长行程低灰度强调)
16 Long Run High Gray Level Emphasis(LRHGLE,长行程高灰度强调)
-
邻域灰度差矩阵特征NGTDM(5个)
NGTDM描述每个体素与相邻体素的不同
1 Coarseness(粗糙度)
2 Contrast(对比度)
3 Busyness(繁忙度)
4 Complexity(复杂度)
5 Strength(强度)
-
灰度依赖矩阵GLDM(14个)
GLDM描述图像中的灰度级相关性
1 Small Dependence Emphasis(SDE,小依赖强调)
2 Large Dependence Emphasis(LDE,大依赖强调)
3 Gray Level Non-Uniformity(GLN,灰度不均匀性)
4 Dependence Non-Uniformity(DN,依赖不均匀性)
5 Dependence Non-Uniformity Normalized(DNN,归一化依赖不均匀性)
6 Gray Level Variance(GLV,灰度方差)
7 Dependence Variance(DV,依赖方差)
8 Dependence Entropy(DE,依赖熵)
9 Low Gray Level Emphasis(LGLE,低灰度强调)
10 High Gray Level Emphasis(HGLE,高灰度强调)
11 Small Dependence Low Gray Level Emphasis(SDLGLE,小依赖低灰度强调)
12 Small Dependence High Gray Level Emphasis(SDHGLE,小依赖高灰度强调)
13 Large Dependence Low Gray Level Emphasis(LDLGLE,大依赖低灰度强调)
14 Large Dependence High Gray Level Emphasis(LDHGLE,大依赖高灰度强调)
- 小波特征(744个)
至于提取的具体过程,我们后面的老师会为大家进行细致的讲解。
至此,特征提取介绍完毕。
数据预处理
在特征提取之后,需要进行数据预处理(特征标准化):采用R的caret包的preProcess功能对训练集上提取的特征值进行z-score标准化处理;然后使用训练集上求得的平均值和标准差值对测试集的特征值进行标准化处理。这一步大家也不用担心,同样是几行代码就可以搞定的问题。
特征的一致性评价
数据预处理后,可以进行特征的一致性评价,目的是为了评价分割结果的好坏,分割得到的影像组学特征有没有比较好的一致性。
可以通过组内/组间相关系数ICC实现。一般而言,由于分割工作由两名或多名医师完成,大多数影像组学文章的特征一致性评价部分是不同医师同一时间进行勾画评价Inter-observer-ICC(观察者间一致性)进行比较和同一个医生不同时间点多次勾画的Intra-observer-ICC(观察者内一致性)。同时,也可以取cutoff值先筛选掉一部分特征。
小注:
这里一般认为 ICC≥0.8 为一致性很好,0.51~0.79 为中等,低于 0.50 为差
05
第四步:Analysis,特征选择、预后模型构建
我们先来说特征选择:
对于机器学习模型来说,我们可以将刚刚提取得到的影像组学特征分为三类。
第一类是相关特征,这类特征是对机器学习有用的特征,可以提升学习算法的效果。
第二类是无关特征,这类特征对算法没有任何帮助,不会对学习算法带来任何提升。
第三类是冗余特征,这类特征可以通过其他的信息推断出来,不会对学习算法来带新的信息。
相信大家已经看出来这一步的目的了:我们在做特征筛选或降维过程中所希望的是降低和去除的是无关特征和冗余特征携带的信息,而尽可能保留相关的特征的信息。即,特征降维的目的是提高机器学习模型的学习效率,同时降低过拟合的概率。
-
简单来说就是从相关性高的一组特征中选择变异性最大的特征;
o举个例子,实际生活中,把主要矛盾解决了(缺钱),大部分次要矛盾就随之消失了(可以买衣服了,可以吃火锅了),生活开始变得美好。特征选择是一样的道理,成千上百个特征,对因变量(Y,自己要研究的东西)有重要影响的,可能就几个几十个。
做了特征选择,消除冗余信息,避免多重共线性,简化模型,使得模型更具有泛化能力(模型的通用性,说明模型不止是在训练数据上表现得好,随便拿一批数据来,该模型一样能正常发挥作用),这就是特征选择存在的意义!
o特征选择的主要方法有以下几类:
- 过滤法:例如方差过滤,相关性过滤等
- 嵌入法: 例如加入L1范数作为惩罚项(也就是我们常见的LASSO回归)
- 包装法: 例如递归特征消除法等
- 降维法: 例如PCA(主成分分析)等
而模型构建是对选定的高度显著的特征输入分类器来进行进一步的分析和评估。
-
虽然说,很多时候特征选择和模型构建过程是一起完成的。不过在特征选择后,我们也可以运用运用机器学习算法构建模型。根据数据是否有标签,机器学习算法模型可分为有监督学习、无监督学习及半监督学习
o有监督学习模型:需要明确的输出以作为算法学习的依据。常用的有监督分类器包括决策树、 支持向量机、贝叶斯分类器等;
o无监督学习模型:通过距离判定规则将新样本划分到相应的类别中。常见的无监督分类器包括 K 均值、高斯混合聚类、密度聚类等;
o半监督学习模型:将有监督学习及无监督学习结合起来,同时使用 标记数据和未标记数据,在减少人力的情况下保证较高的准确性。常用的半监督模型包括图论推理和拉普拉斯支持向量机等;

medical3d体素前处理重采样处理
1;医学图像处理入门知识 | 格式DICOM,MHD+RAW | 坐标系 | ITK-SNAP | 重采样_zlzhucsdn的博客-CSDN博客_mhd raw
2:
医学图像预处理(二)——重采样(resampling)_normol的博客-CSDN博客_new_spacing[::-1]
3:
MICCAI 2019肾&肿瘤分割挑战赛第一名方案学习笔记
该比赛第一名作者在预处理方法也下了很多功夫,
- 将所有图像重采样到spacing= 3.22×1.62×1.62mm
- 将灰度值cut off 到[-79, 304],然后Z-Score
- 去掉一些对label不确定的病例以及修正部分病例 (主办方允许这样做)
更进一步可能要问:这些参数如何得到的?
- 重采样:目的是为了让图像的spacing一致;CNN中Conv操作被提出来的其中一个重要motivation就是图像中有相似的块能用共享的卷积来提取特征,因此对所有图像重采样能减少不同图像之间的不一致性,便于卷积操作提取共同的特征。至于作者采用的参数,文中提到:Optimizing the trade-off between the amount of contextual information in the networks patch size vs the details retained in the image data is crucial in obtaining ideal performance. 最后一段 we attempted to vary the target spacing for resampling as well as the patch size of our network architecture. 为了文章的简介,作者没展开说,但是能从侧面感受到,找到这个参数作者是花了不少功夫试验的。
- 灰度值的cut off是考虑了适合肾脏的窗宽窗位,这个需要一点医学背景;Z-Score是最常用的灰度值标准化方法,直觉上要比归一化到[0,1]好,因为前者能避免网络权重初始化的时候产生明显的bias (即所有样本都归到分类面的同一侧)。此外,评论区陈昊还补充了一点,采用Z score 还可以防止数据规范化时被压缩;比如CT图像中如有金属伪影,如采用min-max规范化,会造成规范后数据区分度不高的现象。
4:
医学图像预处理之重采样详细说明
5:完整预处理教程(DICOM医学图像分割)
- 加载DICOM文件,并补充缺失的元数据
- 将像素值转换为Hounsfield单位(HU),以及这些单位值对应的组织
- 重采样到同构分辨率,以消除扫描仪分辨率的差异。
- 三维绘图、可视化对查看我们的进程非常有帮助。
- 肺部分割
- 归一化
- Zero-centering










![[附源码]Nodejs计算机毕业设计基于的仓库管理系统Express(程序+LW)](https://img-blog.csdnimg.cn/feeef451e0254f3d80283edf7f586dbc.png)