大数据产业创新服务媒体
——聚焦数据 · 改变商业
近期,云从科技发布了2023年半年报。应该说,云从科技交出的成绩单很不好。事实上,商汤、旷视等CV厂商的情况也好不到哪去。云从科技的处境有一定的代表性,因此,我们将通过深入分析这个公司的财报,来看看云从科技遇到的问题,并探讨中国CV可能的突破方向。
财务表现堪忧
首先,我们来看看云从科技今年上半年整体的业绩表现。
以下是数据猿根据云从科技半年报,制作的其核心业务数据表格:

从2022年到2023年半年度,营业总收入出现了显著下降,降幅高达58.2%。营业总成本在2023年也有所下降,但其下降幅度(-39.6%)与营业总收入的下降幅度不同步。净利润方面,依然在大幅亏损,只是亏损幅度略微收窄。
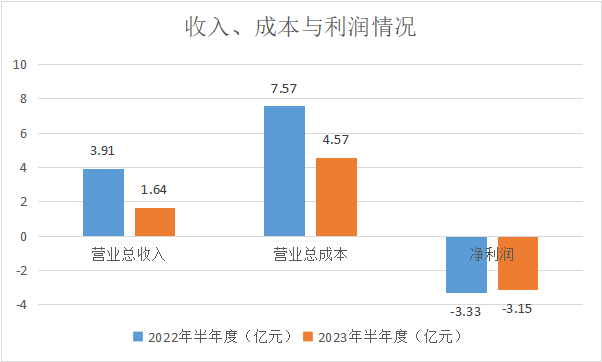
各项成本方面,与2022年相比,2023年的营业成本大幅下降了72.4%。营业成本之所以大降,主要是因为购买商品、接受劳务支付的现金从2022年上半年的3.26亿大幅下降到2023年上半年0.7亿。更少的销售,意味着更少的零部件采购。另外,可以预估,云从科技可能通过大规模裁员,来减少劳务支出。
让我们来看看云从科技的人员规模,其2023年上半年研发人员规模从2022年的609人下降到522人。我们再根据研发人员占比反推公司整体人员规模,可得2022年总人数月1141人,2023年上半年864人,人员规模下降24.3%。
需要指出的是,云从科技虽然经历了较大规模裁员,但留下来的研发人员却普遍涨工资了,平均薪酬从18.28万上涨到23.17万元。看来,云从科技还是很重视研发的。
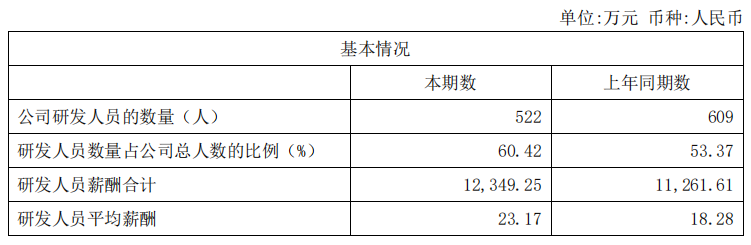
销售费用和管理费用在2023年均有所下降,分别减少了18.6%和24.9%。尽管总体费用有所下降,但研发费用只下降了22.6%。

接下来,计算净利润与各项成本占总收入的比例情况。
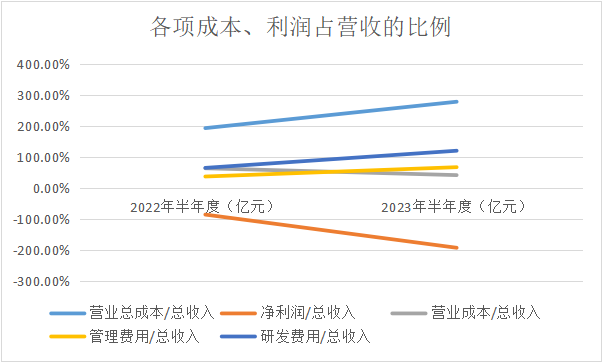
虽然云从科技的营业成本、销售费用、管理费用、研发费用都在降低,但除了营业成本外,其他几项成本的降幅都小于收入降幅,因而其占营收的比例都在上升。
经营情况的变化,会带来其现金流的变化。
从2022年上半年到2023年上半年,云从科技的经营活动产生的现金流量净额从-4.86亿元增长到2.36亿元;投资活动产生的现金流量从2022年的-9.95亿元下降到2023年的-2.96亿元;筹资活动产生的现金流量2022年为19.58亿元,而2023年减少到1.44亿元。最终,期末现金及现金等价物余额从2022年的10.80亿元减少到2023年的7.31亿元。可以看见,虽然云从科技在通过缩减业务规模来控制现金流出,但由于筹资活动大幅减少,其账户上的现金也在快速流失。
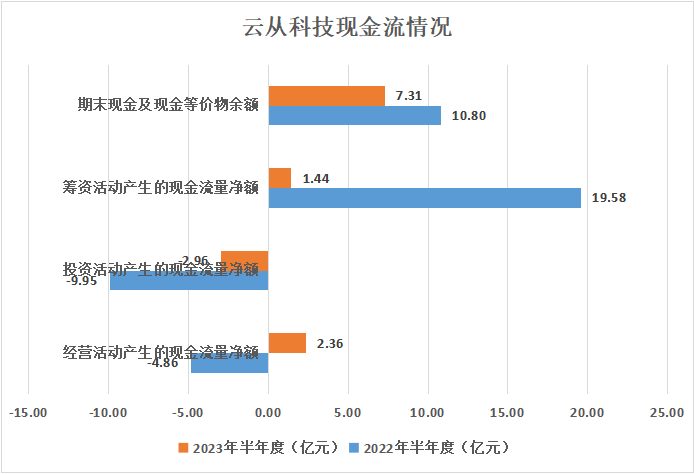
综合上面的财务数据,可以发现,2023年云从科技经历了严重的业务收缩,首先是收入端的大幅度降低,成本端也在控制各项费用。然而,由于收入下降过快,各项成本占营收的比例还是在上升。并且,云从科技的现金流状况在恶化。
这不禁让笔者产生疑问,现在不正是AI的快速发展期么?作为“AI四小龙”之一的云从科技,不应该交出这样的成绩单啊。问题出在了哪里?这需要我们进一步深入其业务当中来寻找原因。
押注大模型
云从科技的核心业务就两项,即人机协同操作系统和人工智能解决方案。所谓人机协同操作系统,包括各类AI算法、AI应用框架以及相关的管理系统。在此基础上,面向不同行业构建解决方案。
其中,人工智能解决方案业务,在2023年是上半年都出现了大幅度的下滑,这也是导致云从科技整体收入下滑的关键原因。
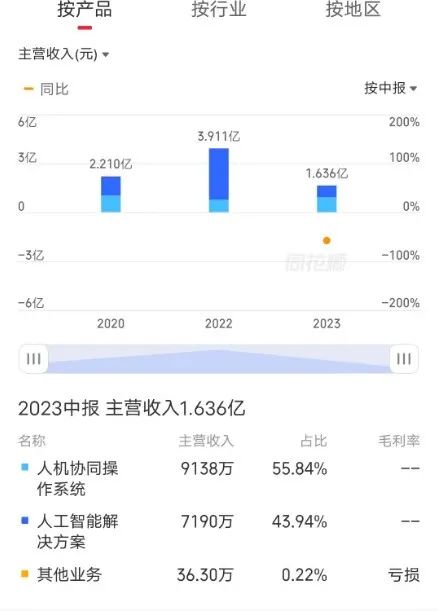
以下是云从科技的技术产品体系图,从图中可以看到,其核心算法库里增加了不少跟大模型相关的内容,包括LLM、CV大模型、跨模态大模型、ASR大模型。某种程度上,云从科技业务在收缩(行业应用),但技术产品端却在扩张,在大力开发新的技术产品,尤其是跟大模型相关的产品。

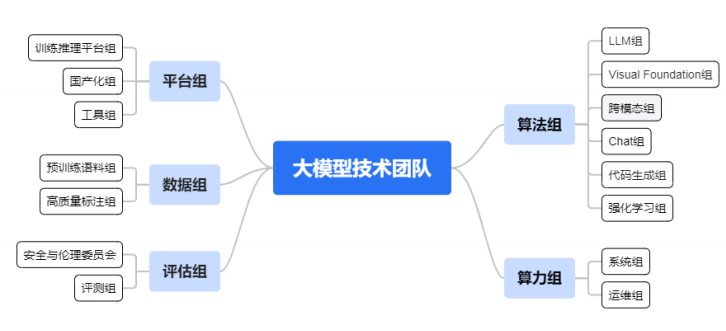
在大模型领域,云从科技下了重注。根据其2023年半年报,云从科技从 2022 年 12 月开始组织筹备人工智能大数据模型队伍建设,目前已建成近百人规模的大型团队,占其整体522人研发团队的近20%。再结合其研发团队薪酬的大幅度增长,可见云从科技应该是裁撤了不少其他研发团队,然后招聘成本更高的研发人员,并结合原来的一些骨干研发力量,来组建一个较大规模的大模型团队,可见其对于大模型的决心。
云从科技的大模型团队下设算法组、平台组、算力组和数据组。其中,算法组分为语言、视觉、语音等若干小组,主要成员为原 CV 团队在预训练技术具有较深经验的算法专家和原语音/NLP 团队的算法专家;平台组则由训练平台团队和信创团队的成员组成,该团队长期与华为昇腾、寒武纪等团队进行技术合作;算力组由云平台运维团队和供应链团队的成员组成;数据组由数据服务部成员、大数据团队成员和部分算法工程师组成。
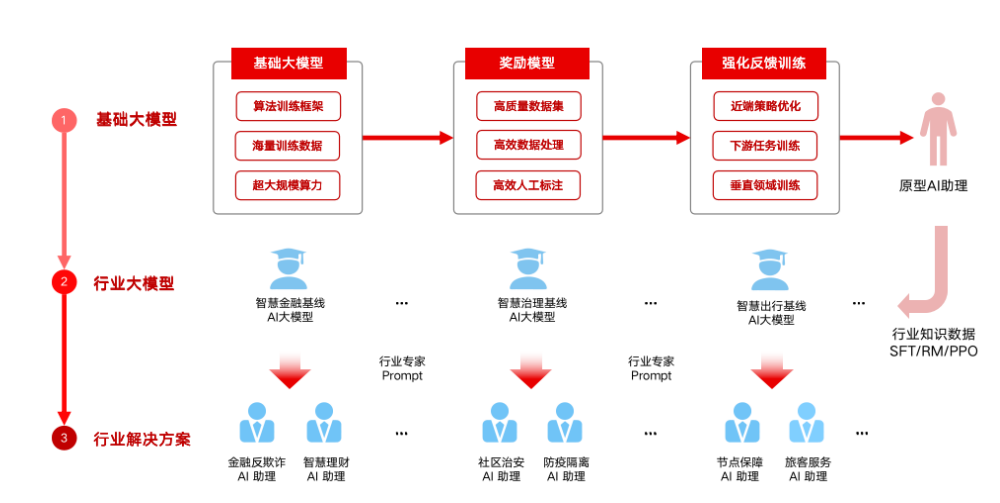
在大模型领域,云从科技的“野心”也不小,从技术端,涵盖了大语言模型(LLM)、CV大模型、多模态大模型;从业务规划来看,涵盖基础大模型、行业大模型以及行业解决方案全链条。
要走一条不同的路
作为AI四小龙之一,云从科技的处境和业务布局,具有一定的代表性。云从遇到的问题,商汤、旷视、依图、格林深瞳等都或多或少遇到过。某种程度上,云从科技的困局与探索,代表了上一波AI浪潮中崛起的CV新贵们的彷徨。从目前的情况来看,商汤和云从在大模型领域的发展思路类似。
接下来,我们以云从科技为例,来探讨一下CV企业在这一波大模型浪潮中的挑战和探索。
CV转型到LLM跨度不小。
ChatGPT火了之后,几乎所有人工智能企业全部转向了大模型。2023年年初至今,中国市场上已经发布了近百个大模型产品了。但任何技术的迅速崛起都应当带来冷静的分析,特别是对于那些核心业务不直接与此相关的公司。
首先,让我们更清晰地理解技术的“血缘”关系:自然语言处理(NLP)本质上是对人类语言的模拟和理解,而大语言模型(LLM)则是其最新的进展。NLP和LLM共同的核心在于对语言结构、语境和语义的深入分析。与此相反,计算机视觉(CV)主要关注的是图像和视频的处理、分析和理解。
尽管Transformer已经在一些视觉任务中展现出潜力,但要构建一个与ChatGPT规模相当的CV模型,面临的技术挑战和策略考量会有很大区别。首先,数据的本质不同。图像通常包含更多的信息和更高的维度,这使得处理和训练变得更加复杂。一个大型的CV模型需要能够有效地处理这种复杂性,并从中捕捉到有意义的模式。其次,任务的多样性也存在显著差异。CV的任务涵盖了从图像分类到目标检测、语义分割和姿态估计等多个子领域。而NLP的任务,尽管也有其多样性,但其输入(文本)的结构通常更为统一。因此,CV大模型可能需要更为通用和灵活的架构来处理不同的任务。
对于像百度和科大讯飞这样的公司,它们长期投资于语音和文字技术,因此LLM为它们带来了天然的竞争优势。然而,对于以计算机视觉为核心业务的公司如云从科技和商汤科技来说,直接转型到LLM领域是一个具有挑战性的决策。这不仅仅是因为技术复用的问题,而是更多的是围绕研发资源、人才结构和市场定位等多方面的综合考量。
研发资源上,原本针对CV领域的优化和研发不易直接迁移到LLM上;人才结构上,需要大量熟悉语言模型的研发人员,这可能导致招聘和培训的额外成本;从市场定位角度来看,纵使成功转型,这些CV公司在LLM领域可能还需要与已经建立起品牌认知的大企业竞争。
当然,并不是说CV企业就不能在大模型领域取得成功,只是其困难和挑战会更大一些。
相对于大语言模型LLM,CV大模型似乎更适合计算机视觉厂商。
云从科技这样的CV公司,也许将方向定位于CV大模型,比做一个ChatGPT这样的大语言模型更合适。
更大的模型规模,会带来两个显著的好处:更强的表现力,更多的参数意味着模型有更强的表现能力,可以捕获更复杂的特征和关系;任务泛化能力,大模型经常可以在多个任务上进行微调,实现一种形式的迁移学习,从而在不同的任务上都表现良好,这两个能力对于提升如今CV的应用效果非常重要。
目前,大部分CV产品局限性都很强,一个CV模型往往只能识别某类物体,比如人脸识别模型认不出来猫。在自动驾驶领域,一个关键的挑战就是AI系统无法识别出没见过的物体,而要实现全自动驾驶,就要求AI系统必须在任何情况下都知道如何处理,即使是以前没见过的情况。
如果通过大幅提升模型规模,比如千亿级参数的CV模型,来显著提升模型的泛化能力,让一个模型可以识别万事万物,那其应用价值将不可限量。比如,一个CV大模型,既可以识别人脸,也能认出家里的猫和狗,还能认出家里的家具、办公用品,而且具备很强的空间理解能力,能理解不同物体之间的关系,这样的CV大模型才是人们想要的。
在技术路线上,虽然可以考虑基于Transformer构建CV大模型,但也有可能需要探索全新的架构。例如,针对视觉数据的特点,可能会考虑引入更多的卷积结构,或者采用新的注意力机制。此外,为了支持大型CV模型,可能还需要对硬件和优化策略进行调整。由于视觉数据的复杂性,简单地扩展模型规模可能会导致内存不足或计算效率低下的问题。
总的来说,尽管在构建CV大模型的道路上还有很多技术挑战和未知问题,但这个方向的探索和突破无疑将为计算机视觉领域带来革命性的变革。与NLP的大模型类似,一旦成功,CV大模型有可能为我们提供前所未有的视觉理解能力,并开启全新的应用领域。
正因为困难,也正因为别人还没做到,才是后来者的机会。中国有一批像云从、商汤、旷视、格林深瞳这样不错的CV企业,如果他们能够把CV大模型这条路走通,那我们将引领人工智能的下一个浪潮,而不是像现在这样,跟在OpenAI、谷歌后面亦步亦趋。
文:一蓑烟雨 / 数据猿




![Electron 报gpu_process_host.cc(951)] GPU process launch faile错误](https://img-blog.csdnimg.cn/1c4d52d7c7ff41c88f2c8d3e56c75a05.png)


![数字乡镇综合解决方案[59页PPT]](https://img-blog.csdnimg.cn/img_convert/56a4aef29e3c02f32a68dbb847e004af.jpeg)