大家好,小机又来分享AI了。
今天分享一些新奇的东西,
你有没有试过和ChatGPT聊天时,心里偷偷犯嘀咕:"这AI怎么跟真人一样对答如流?它真的会思考吗?" 或者刷到技术文章里满屏的"Token""微调""LoRA"时,瞬间感觉在看火星文?
别慌!这感觉就像第一次看到智能手机——明明知道它厉害,但那些专业术语让人望而却步。
其实大模型的秘密,用大白话就能讲明白!
准备好了吗?咱们这就开始剥开大模型的"洋葱皮"!
一、大模型基础概念拆解
1. 什么是Token?
Token可以看作是语言的“积木块”,每个Token都是语言的最小单元,类似于我们在玩乐高积木时的一块小积木。
想象你在玩乐高,每一块小积木都代表了一个元素,拼接起来才构成完整的模型。语言也是如此,当你输入一个句子时,计算机将其拆分成一个个Token,便于进行分析和处理。
比如在中文中,"深度学习"这个词会被拆分成【深】【度】【学】【习】四个Token;而在英文中,"This is a input text."则通常拆成【This】和【is】,【a】,【input】,【.】多个Token。
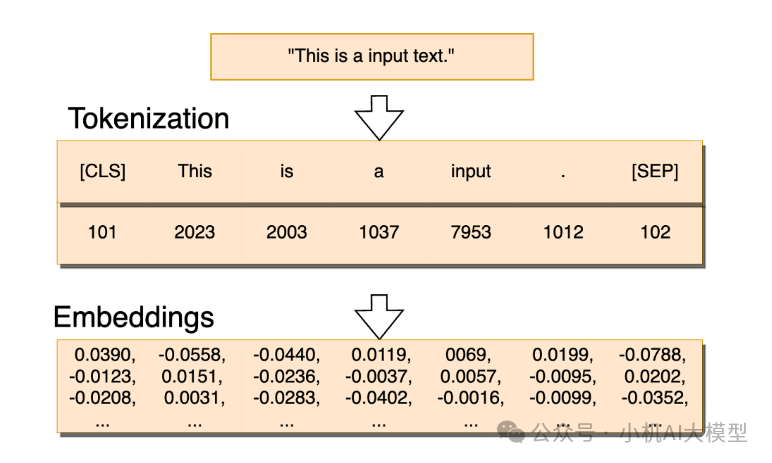
这个拆分过程可以帮助计算机更好地理解每个词的意思和它们之间的关系。
一个实用的小技巧是,当你在ChatGPT里输入长句时,注意它可能会根据不同的规则来拆分句子中的词语,这种拆分方式可能和你自己理解的有些不同。
所以,了解Token的概念能够帮助你更好地理解计算机是如何处理语言的,也能帮助你更精准地与AI进行互动。
2. 模型通信三兄弟
大模型的训练就像在经营一个物流公司,它需要合理的运输方案来处理海量的数据。
为了让训练过程更高效,大模型使用了三种不同的“运输方案”,分别是DP(数据并行)、PP(流水线并行)和TP(张量并行)。
这些方案帮助将训练任务分配给多个计算节点(类似于卡车、工人或快递员),提高效率并减少时间和资源消耗。
DP(数据并行)
就像是将100箱货物分给10辆卡车同时送。每辆卡车负责运送相同数量的货物,但每辆卡车装载的内容是不同的。
对于大模型来说,数据并行意味着把训练数据分成多个小批次,并将这些批次同时送到多个计算设备上处理。
这样可以加速处理过程,尤其是在数据量非常大的时候,能够有效提高训练效率。
PP(流水线并行)
类似于工厂流水线的工作方式,不同的车间处理不同的工序。每个计算设备负责模型训练的一个特定阶段,类似于流水线的各个环节。
通过流水线并行,可以最大化设备的利用率,减少等待时间,让每个阶段的计算任务都能高效地完成。
TP(张量并行)
则像是把一个超大的箱子拆成多个小件,分别交给多个快递员来搬运。对于一些超大模型,单个设备无法处理那么庞大的数据量。
张量并行通过将模型拆分成多个小部分,分别交给不同的计算单元来处理,最终再将结果组合起来。
这个方法特别适用于“巨无霸”模型,可以有效解决计算资源不足的问题。
DP适合于大规模的数据处理,PP优化了计算流程中的时效性,而TP则专门解决了超大模型的训练问题。
这三种方法在不同的场景下各有优势,共同帮助大模型在训练过程中更加高效和精确。
3. 关键术语闪电战
微调可以理解为给AI上补习班,目的是让它掌握特定的技能或领域知识。
就像一个学生在上完通识课程后,如果他想成为法律专家,就需要进行针对性的学习和训练。通过微调,AI在预先训练好的基础上,使用新的专业数据进一步训练,使得它能够专门应对某些领域的任务,比如法律咨询、医学诊断等。
例如,我们可以把一个通用的ChatGPT模型,通过微调,让它变成一个“法律咨询专家”,使得它在法律领域能够回答更为准确和专业的问题。
LoRA(Low-Rank Adaptation)则是另一种优化方法,它就像是给AI戴上了一副“知识增强眼镜”。
与传统的微调方法不同,LoRA通过只调整模型的一部分参数,而不是对整个模型进行训练,来实现对新知识的学习。
这样一来,AI能够在保持原有知识的同时,迅速吸收新领域的知识。LoRA的优势非常明显:训练速度可以提升3倍,显存占用减少了70%。
这一点对于大规模模型尤其重要,因为它能够大大降低硬件资源的需求,同时提升训练的效率。
微调是通过系统的再训练让AI更专业,LoRA则是通过更高效的方式来让AI快速掌握新知识,而两者都能帮助提升AI在特定任务中的表现。
1. 四大核心能力
-
文本生成:输入“写首关于春天的诗”,AI秒变文艺青年
示例输出:
樱花纷落键盘轻,代码如泉涌不停
春风不解程序员,偏把Bug藏绿荫
-
多模态处理:CLIP模型看一眼猫咪图片,就能匹配“毛茸茸的捕鼠高手”文字
-
代码生成:对Code Llama说“用Python画个爱心”,直接生成可运行代码
-
涌现能力:当模型参数超过1000亿,突然会解微积分题——就像小孩突然会骑自行车
2. 商业应用雷达图
-
智能客服:
→ 黄金话术:“请用不超过20字解释5G套餐”
→ 避坑指南:一定要设置“转人工”触发词 -
内容创作:
→ 爆款标题公式:“3个{领域}技巧,让你{收获}翻倍”
→ 案例:输入“生成小红书风格的美妆文案”,获得带emoji的种草文 -
数据分析:
→ 神奇指令:“帮我把这份销售数据总结成3点结论”
→ 防翻车口诀:数据描述越具体,输出结果越靠谱
三、小白实践指南
1. 零代码体验路径
-
3个免费用大模型的平台:
-
ChatGPT(网页直接聊)
-
文心一言(中文场景特化)
-
新手提示词模板:
"假设你是{角色},请用{风格}帮我{任务},要求{具体条件}" 示例: "假设你是旅行达人,请用幽默语气帮我规划杭州三日游,要求包含小众景点"
结语
看完这篇,你已经完成了大模型学习的关键三步:
1️⃣ 看懂了专业术语的“人话版”
2️⃣ 见识了AI的十八般武艺
3️⃣ 掌握了立刻能用的实战技巧
小机的愿景是成为 AI 提示词与AI大模型的布道者,带领 更多 小白入门 AI,让更多的人在已经到来的 AI 时代不掉队,不被 AI 淘汰。
我也期望能遇到更多优秀的自媒体创作者,期待与大家一起进步!
如果您对AI大模型充满好奇,想要了解更多关于它的信息,不妨联系我进行交流,我将为你带来更多的大模型相关知识。我是小机学AI大模型,一个专注于输出 AI+ 提示词和AI + 大模型,AI编程内容的学者,关注我一起进步。
@小机
对了,如果您有AI方面的问题,或者有对AI其他方面感兴趣的地方,也欢迎通过下面的链接加我好友一起交流,我会送您一份领价值499元的AI资料,帮助您入门AI。
原文链接:
AI大模型科普:从零开始理解AI的"超级大脑",以及如何用好提示词?(附赠书活动)大模型到底是如何工作的?![]() https://mp.weixin.qq.com/s/QmNUFb6rJXzsJzswhF8sTQ
https://mp.weixin.qq.com/s/QmNUFb6rJXzsJzswhF8sTQ
![STM32单片机入门学习——第40节: [11-5] 硬件SPI读写W25Q64](https://i-blog.csdnimg.cn/direct/a8d908602f5a417ba564991076396886.png)