读入给定的文本文件“hamlet.txt”,编写两个函数分别实现:
1) 统计所有字母的出现频度,依据频度从高到低,显示前5个字母及其频度,同时把结果写入文件“hamlet_字母频度.txt”。
2) 统计所有单词的出现频度,依据频度从高到低,显示前10个单词及其频度,同时把结果写入文件“hamlet_单词频度.txt”。
import re
from collections import Counter
f=open("hamlet.txt", "r", encoding="utf-8")
line = f.readlines()
f.close()
txt = ""
for i in line:
txt += i
txt=txt.lower()
def Read01():
letters = ""
for i in txt:
if i.islower():
letters+=i
letterf = Counter(letters)
letterf = sorted(letterf.items(), key=lambda x:x[1], reverse=True)
of = open("./hamlet_字母频度.txt", 'w')
print(letterf, file=of)
of.close()
print("字母频度:")
counts = 0
for i in letterf:
counts += 1
if counts > 5:
break
print(i)
def Read02():
words = re.split("[,, |\n]",txt)
words_ = []
for w in words:
if re.match(r'[A-Za-z0-9_]', w):
words_.append(w)
wordf = Counter(words_)
wordf = sorted(wordf.items(), key=lambda x: x[1], reverse=True)
of = open("./hamlet_单词频度.txt", 'w')
print(wordf, file=of)
of.close()
print("单词频度:")
counts=0
for i in wordf:
counts+=1
if counts > 10:
break
print(i)
Read01()
print("*"*50)
Read02()
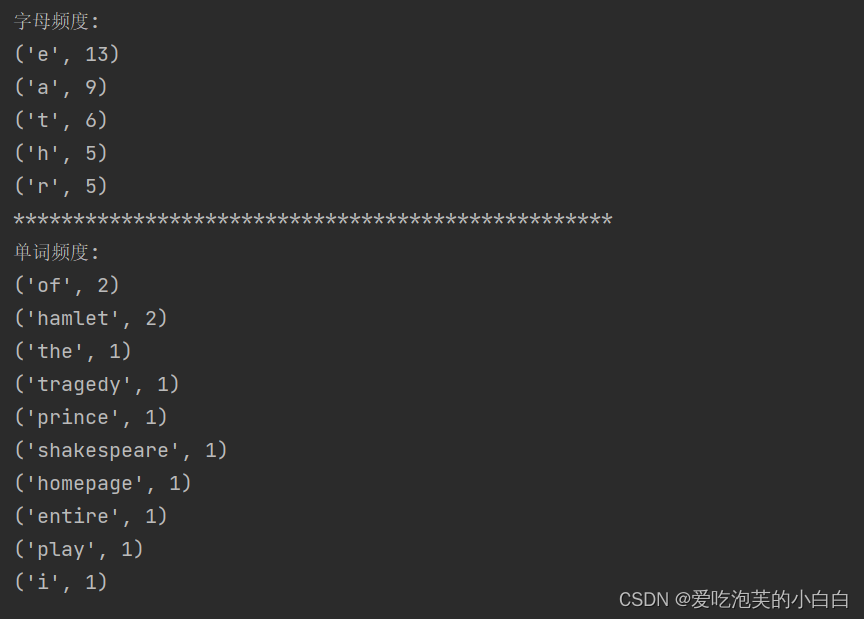
字母频度统计数据:

单词频度统计数据:

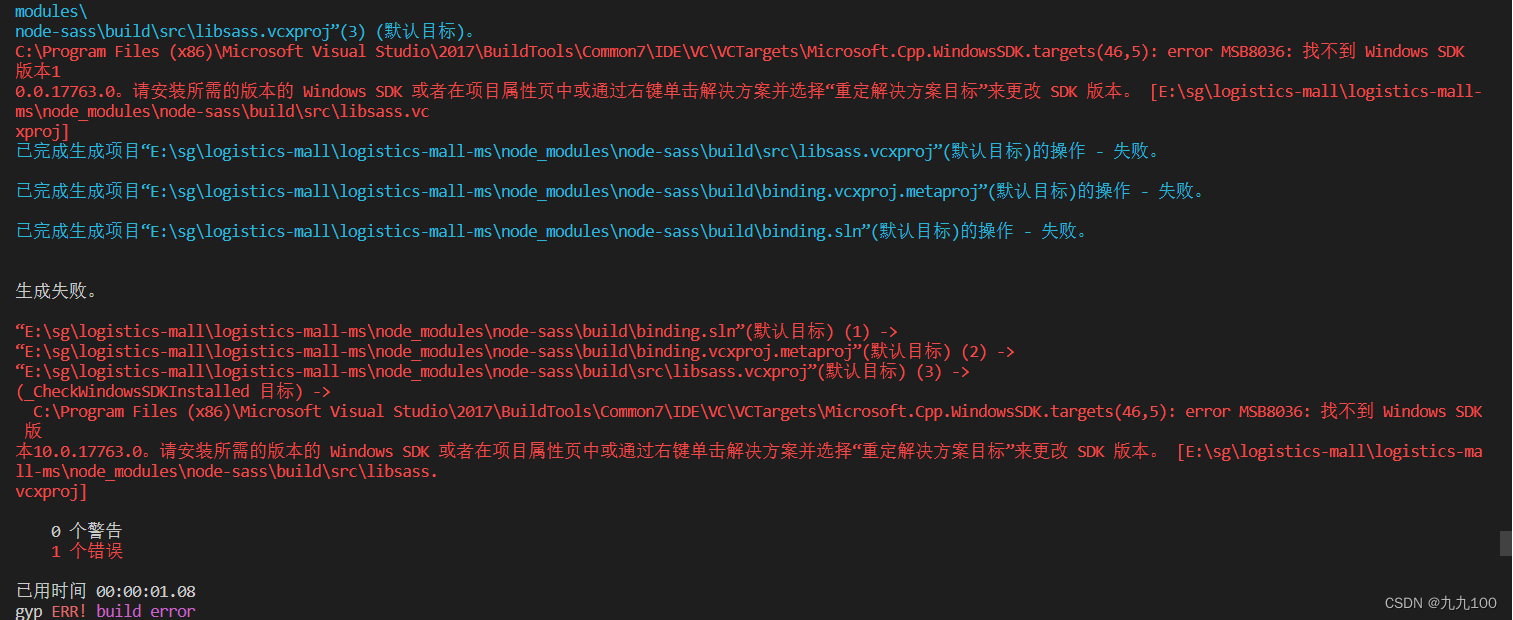
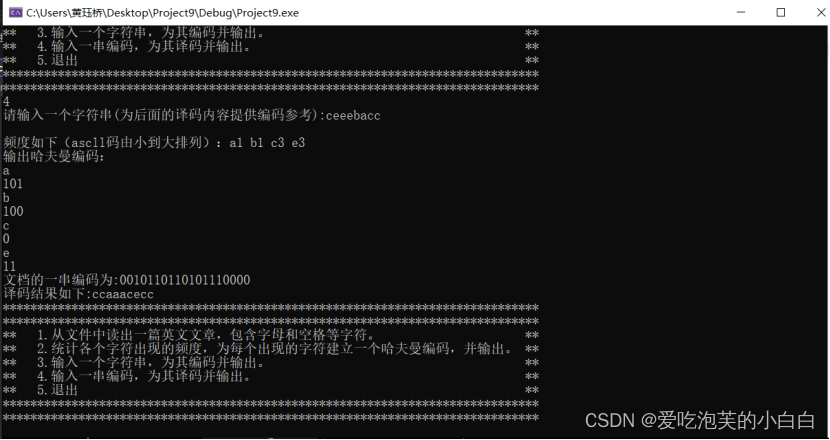
运行结果:


![数字乡镇综合解决方案[59页PPT]](https://img-blog.csdnimg.cn/img_convert/56a4aef29e3c02f32a68dbb847e004af.jpeg)