散列表
- 哈希函数
- 散列表读写
- 写
- 读
- 扩容
- 总结
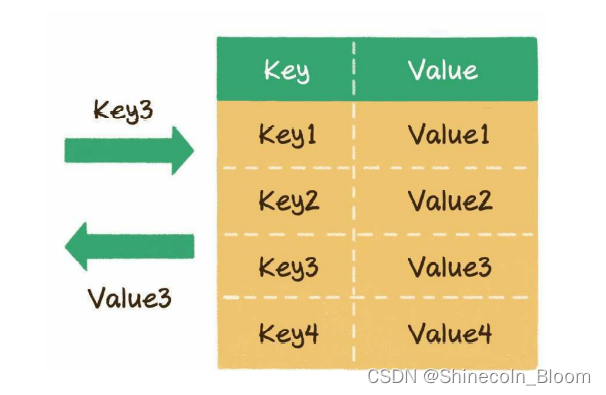
散列表也叫作 哈希表(hash table),这种数据结构提供了键(Key)和值
(Value)的映射关系。只要给出一个Key,就可以高效查找到它所匹配的Value,时间复杂度接近于O(1)。
哈希函数
散列表在本质上也是一个数组。
存在的问题是:数组只能根据下标,像a[0]、a[1]、a[2]、a[3]、a[4]这样来访问,而散列表的Key则是以字符串类型为主的。
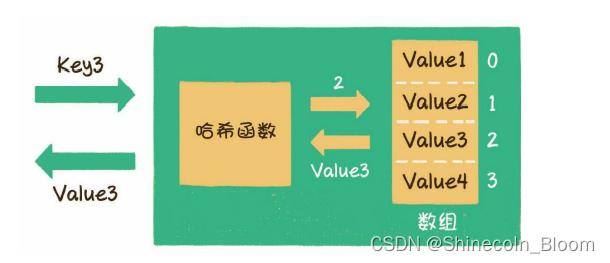
解决方法:我们需要一个“中转站”,通过某种方式,把Key和数组下标进行转换。这个中转站就叫作哈希函数。
在JAVA中,每一个对象都有属于自己的hashcode,这个hashcode是区分不同对象的重要标识。无论对象自身的类型是什么,它们的hashcode都是一个整型变量。
将hashcode转换为数组下标index公式:
index = HashCode (Key) % Array.length
通过哈希函数,我们可以把字符串或其他类型的Key,转化成数组的下标index。
散列表读写
写
写操作就是在散列表中插入新的键值对(在JDK中叫作Entry)。
调用hashMap.put(“002931”, “王五”),意思是插入一组Key为002931、Value为王五的键值对。
第1步,通过哈希函数,把Key转化成数组下标5。
第2步,如果数组下标5对应的位置没有元素,就把这个Entry填充到数组下标5
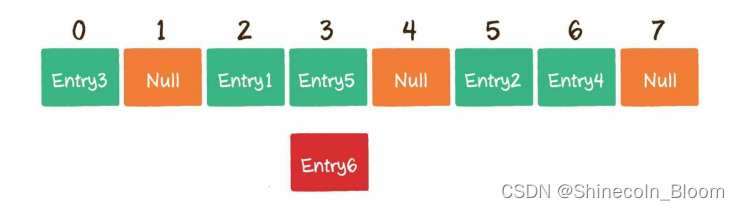
哈希冲突

由于数组的长度是有限的,当插入的Entry越来越多时,不同的Key通过
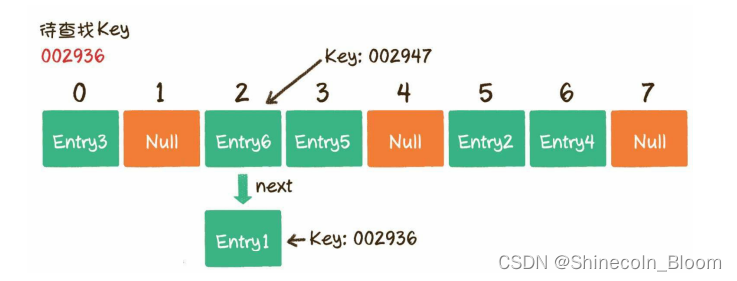
哈希函数获得的下标有可能是相同的。例如002936这个Key对应的数组下标是2;
002947这个Key对应的数组下标也是2。
解决办法:开放寻址法、链表法
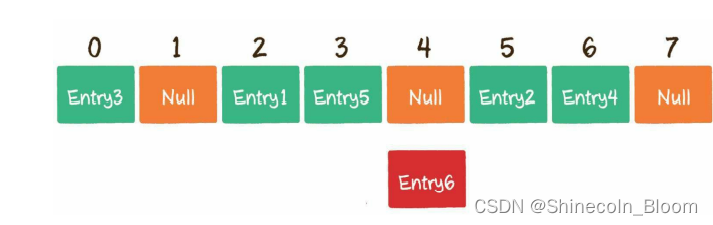
开放寻址法:Entry6通过哈希函数得到下标2,该下标在数组中已经有了其他元素,那么就向后移动1位,看看数组下标3的位置是否有空。

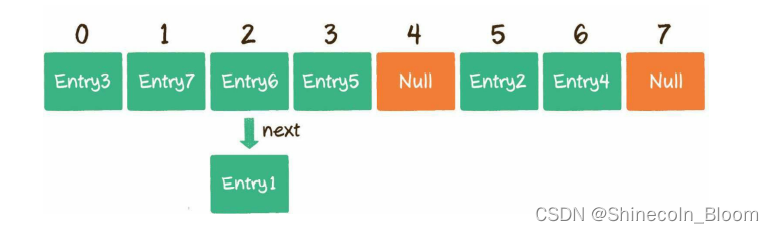
链表法:HashMap数组的每一个元素不仅是一个Entry对象,还是一个链表的头节点。每
一个Entry对象通过next指针指向它的下一个Entry节点。当新来的Entry映射到与
之冲突的数组位置时,只需要插入到对应的链表中即可。 (数组+链表)
JAVA用这种方法解决哈希冲突

读
读操作就是通过给定的Key,在散列表中查找对应的Value。
步骤:
第1步,通过哈希函数,把Key转化成数组下标2。
第2步,找到数组下标2所对应的元素,如果这个元素的Key是002936,那么就找到了;如果这个Key不是002936也没关系,由于数组的每个元素都与一个链表对应,我们可以顺着链表慢慢往下找,看看能否找到与Key相匹配的节点。
扩容
什么情况需要扩容
当经过多次元素插入,散列表达到一定饱和度时,Key映射位置发生冲突的概率会逐渐提高。这样一来,大量元素拥挤在相同的数组下标位置,形成很长的链表,对后续插入操作和查询操作的性能都有很大影响。(散列表是基于数组实现的,那么散列表也要涉及扩容的问题。)

扩容条件:
HashMap.Size >= Capacity×LoadFactor
其中
Capacity,即HashMap的当前长度
LoadFactor,即HashMap的负载因子,默认值为0.75f
扩容步骤:
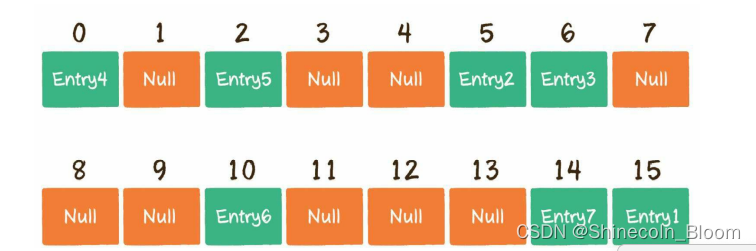
- 扩容,创建一个新的Entry空数组,长度是原数组的2倍。
- 重新Hash,遍历原Entry数组,把所有的Entry重新Hash到新数组中。为什么要重新Hash呢?因为长度扩大以后,Hash的规则也随之改变。
扩容后
注意:当多个Entry被Hash到同一个数组下标位置时,为了提升插入和查找的效率,HashMap会把Entry的链表转化为红黑树这种数据结构。
总结
散列表也叫哈希表,是存储Key-Value映射的集合。对于某一个Key,散列表可以在接近O(1)的时间内进行读写操作。散列表通过哈希函数实现Key和数组下标的转换,通过开放寻址法和链表法来解决哈希冲突。





![[附源码]Python计算机毕业设计SSM基于Java的运动健身平台(程序+LW)](https://img-blog.csdnimg.cn/380bd1fe78784cf5b6d50e82edbe675d.png)

![[附源码]Python计算机毕业设计高校社团管理平台Django(程序+LW)](https://img-blog.csdnimg.cn/b5a00ac25a554d5e8ec9e6a850bf4387.png)