本文会按照 聚集集索->唯一索引->普通索引 的顺序
地毯式分析 范围查询中 <、<=、>、>= 的行锁情况,锁表分析在唯一索引 章节,万字长文,力求分析全面,很硬核全网独一份,别忘了收藏! 当然如果落下什么欢迎大家评论指出!
前文回顾
在上文,我们介绍了 MySQL InnoDB行锁的:
- 2个模式:S锁和X锁
- 3种算法:Record Lock、Gap Lock、Next-key Lock
- 如何开启锁监视器 和 如何分辨3种锁
并对等值查询 是 3类索引 时,结合案例 说明了 都加了哪些锁 以及 为什么加这些锁的分析:
- 聚集索引 和 唯一索引: Record Lock
- 普通索引:Next-key Lock + Record Lock + Gap Lock
- 无匹配:全是Gap Lock
详细案例分析和总结,请见上文:行锁 加锁规则 之 等值查询
文章目录
- 前文回顾
- 先说结论
- 聚集索引
- 小于
- 小于等于
- 大于
- 大于等于
- 范围组合
- `聚集索引 小结`
- 唯一索引
- 小于
- 小于等于
- 大于
- 大于等于
- 范围组合
- `唯一索引 小结`
- 普通索引
- 小于
- 小于等于
- 大于
- 大于等于
- 范围组合
- `普通索引 小结`
- 总结
- 最后
先说结论
本文我们主要分析 范围查询,主要包括: <、<=、>、>= 等.
文章很长,我先给出结论 :
聚集索引
对于 聚集索引下的范围查询 <、<=、>、>=,无论是否组合,都会遵循如下规则:
- 所有匹配的索引记录:只有
>=的等值(=)匹配 上Record Lock,其它 上Next-key Lock; - 对于 < 和 <=:向右扫描聚集索引,直到找到 不匹配 的 索引记录 上Next-key Lock.
- 对于 > 和 >=,会对supremum (上界限伪值) 上Next-key Lock:锁的是 聚集索引 最大值 后面的 间隙;
唯一索引 和 普通索引:
对于 唯一索引 和 普通索引 下的范围查询 <、<=、>、>=,无论是否组合,都会遵循如下规则:
- 如果走了索引:
- 在该索引上,所有匹配的 索引记录 上Next-key Lock,对应的聚集索引 上Record Lock;
- 对于 < 和 <=,会在该索引上向右扫描, 直到找到 [不匹配的索引记录] 上Next-key Lock,对应的聚集索引 上Record Lock;
- 对于 > 和 >=,会对supremum (上界限伪值) 上Next-key Lock:锁的是 该索引 最大值 后面的 间隙;
- 如果没走索引,那么就会把所有 聚集索引记录 和 间隙 都锁上,就是所谓的锁表,或叫行锁升表锁.
OK,给完结论,接着就让我们来验证吧 ,先看一看我们表中的数据:
+----+----------+-----+--------+--------+
| id | name | abc | abc_uk | remark |
+----+--------- +-----+--------+--------+
| 10 | 巴西 | 10 | 10 | NULL |
| 15 | 克罗地亚 | 10 | 15 | NULL |
| 20 | 阿根廷 | 20 | 20 | NULL |
| 30 | 葡萄牙 | 30 | 30 | NULL |
| 40 | 法国 | 40 | 40 | NULL |
+----+----------+-----+--------+--------+
5 rows in set (0.02 sec)
id :自增主键
abc :普通索引
abc_uk :唯一索引
新打开一个mysql客户端,我们叫Session1,并开启锁监视器:
SET GLOBAL innodb_status_output=ON;
SET GLOBAL innodb_status_output_locks=ON;
说明,本文基于:
MySQL5.7、InnoDB引擎、可重复读事务隔离级别
聚集索引
小于
新打开一个mysql客户端,我们叫Session2, 执行SQL如下(按id < 20):
begin;
update ct set remark = '巴西 爆冷 克罗地亚'
where id < 20;
注意不要commit或rollback,以便于我们分析行锁
这里匹配id < 20 的 记录有两条:

然后我们在Session1里查看锁的详细信息
show engine innodb status\G;
我们还是主要看TRANSACTIONS这段,如下图:
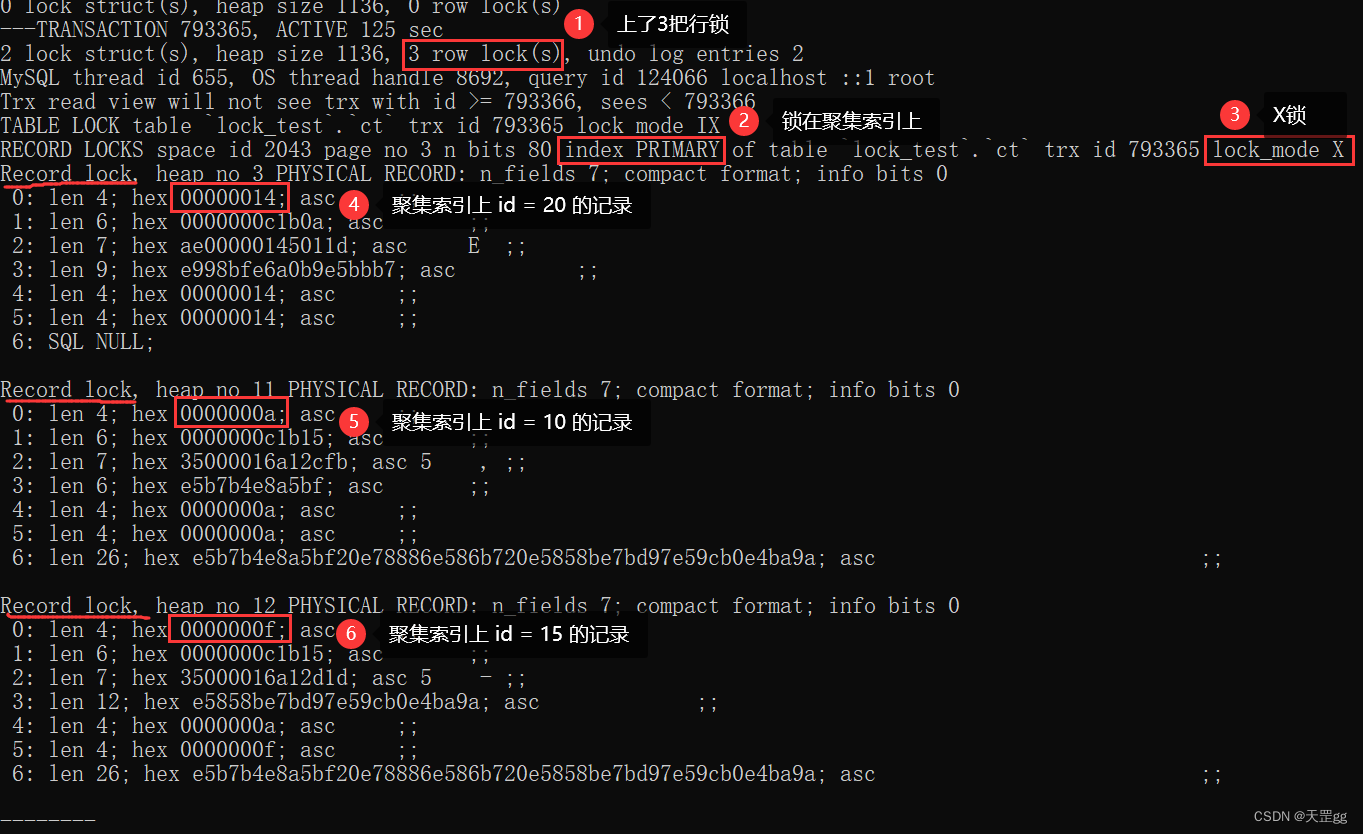
这里上了 3 把锁,因为是 按id,所以全锁在 聚集索引 上:
- id = 20 (向右扫描到的第一个不匹配记录): Next-key Lock;
- id = 10(匹配记录) : Next-key Lock;
- id = 15(匹配记录) : Next-key Lock;
因为 20 刚好是临界值。如果我们换成 id < 19呢?
update ct set remark = '巴西 爆冷 克罗地亚'
where id < 19;
再来看一下:
show engine innodb status\G;
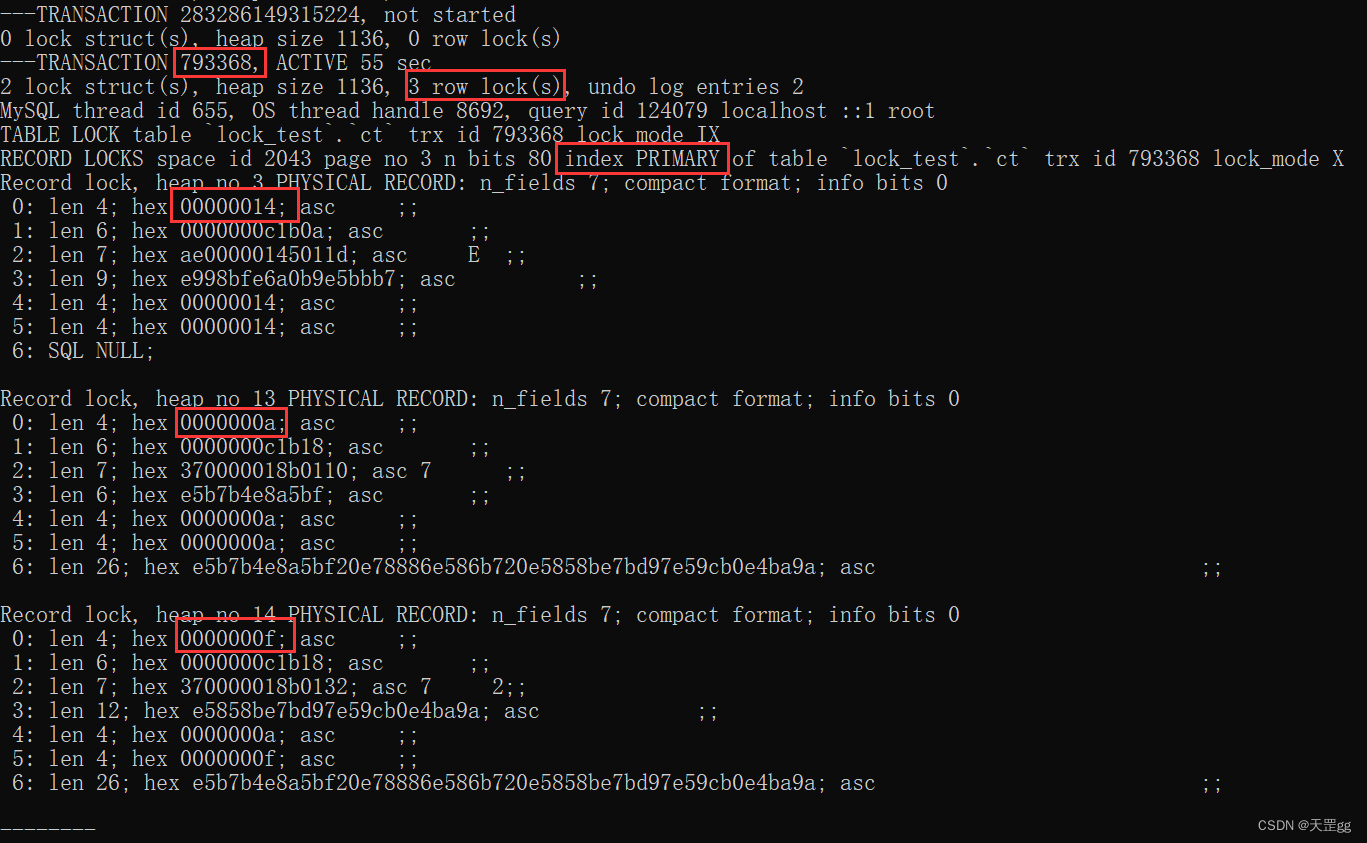
结果依旧!!!(你可以对比一下:上一个事务ID是:793365):
还有一个临界值 id < 16 :
update ct set remark = '巴西 爆冷 克罗地亚'
where id < 16;
结果也是一样的,就不展示了。
所以对于 < 在 聚集索引 上来说,我们得出的结果是:
- 聚集索引上, 所有匹配的 索引记录 上Next-key Lock;
- 向右扫描聚集索引, 直到找到 [不匹配的索引记录] 上Next-key Lock.
小于等于
这里依旧演示两个临界值: id <=19 和 id <= 20
begin;
update ct set remark = '巴西 爆冷 克罗地亚'
where id <= 19;
这里匹配记录有 id =10 和 id =15 两条记录。
我们来看一下:
show engine innodb status\G;
不出所料,因为 和 id < 19 的匹配记录是相同的,所以锁的结果也是相同的!
我们再来看一下临界值 id <=20:
begin;
update ct set remark = '巴西 爆冷 克罗地亚'
where id <= 20;
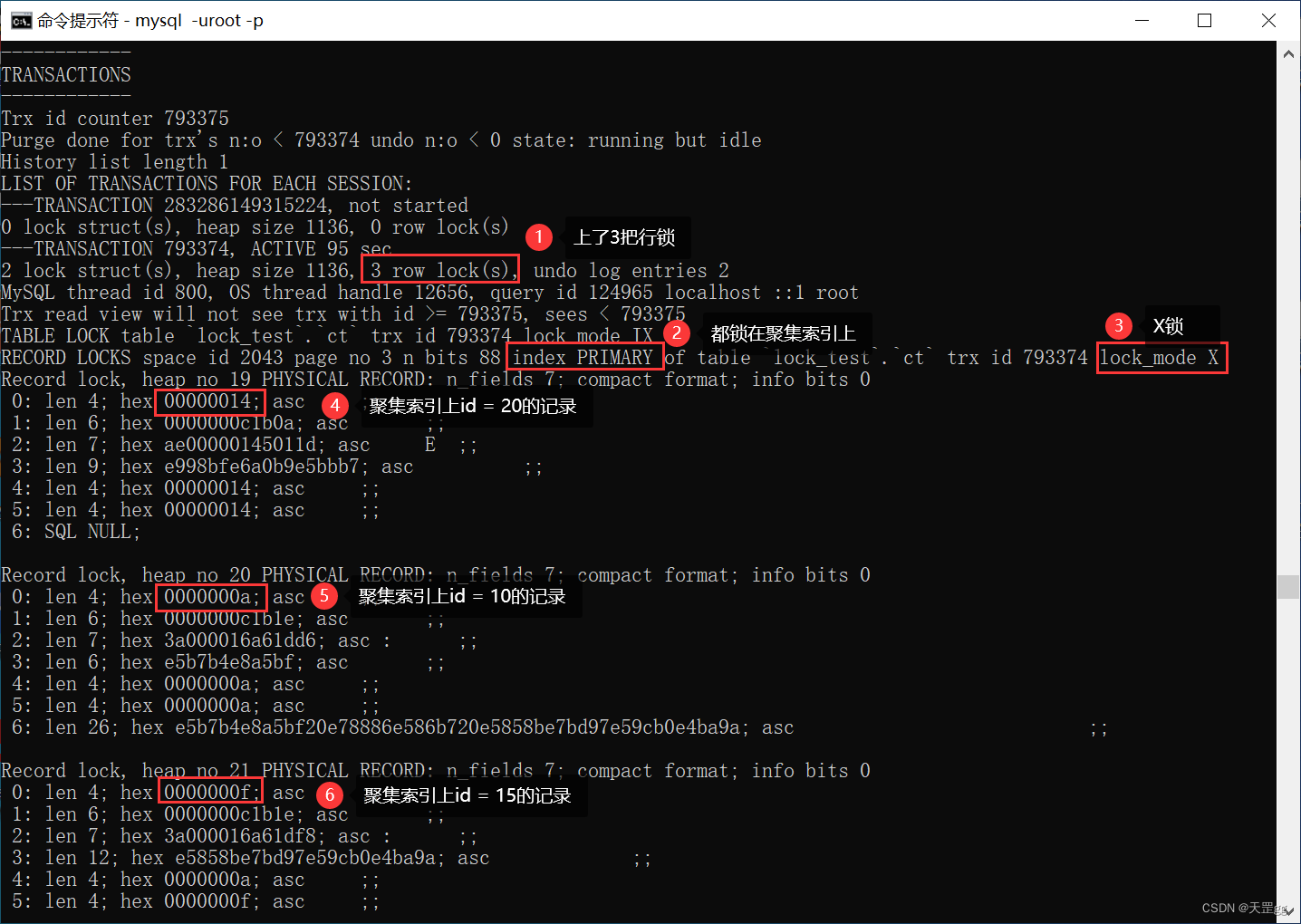
我们看一下修改的记录,共3条:
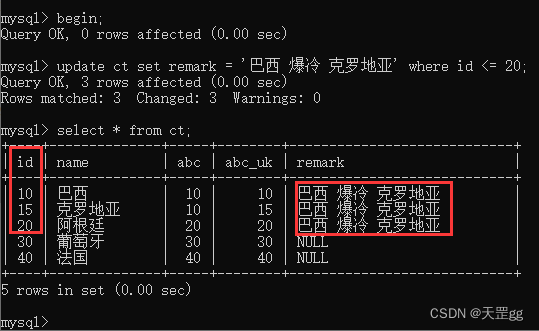
这里对于 3条匹配的 索引记录,上Next-key Lock已尽在我们掌握中,但id = 30 是否会上锁?
如果上的话,是上 Next-key Lock 还是Gap Lock?
我们来看一下:
show engine innodb status\G;
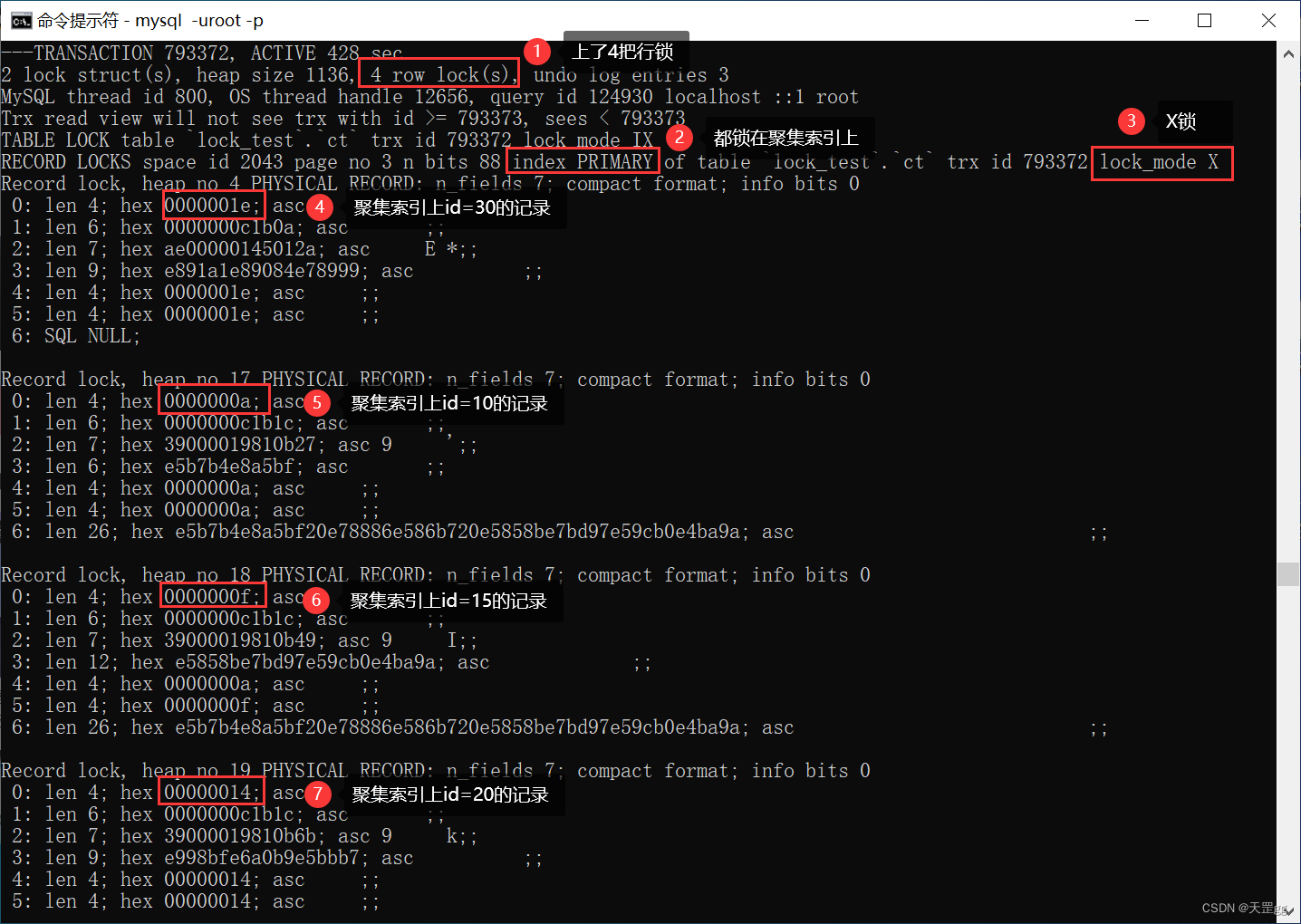
可以看出上了4把锁:3条已匹配记录上了Next-key Lock,向右查找到不匹配的30也上了Next-key Lock。
其实这里不知道你会不会有这个 疑问 :对于聚集索引来说,值是唯一的,既然已经匹配到最大的20了,中止是不是更好?为什么还要继续向右?
如果是<=21,因为21不存在,所以需要继续向右扫描直到查找到30,上一把Next-key Lock倒可以理解!
其实疑问早就存在,前腾讯云数据库负责人林晓斌还曾找社区专家讨论过,官方bug系统上也有提到,但是并未被verified,所以这个也被他称之为bug!
对于 <= 在 聚集索引 上来说,我们得出的结果是(实际和 < 一样):
- 聚集索引上, 所有匹配的 索引记录 上Next-key Lock;
- 向右扫描聚集索引, 直到找到 [不匹配的索引记录] 上Next-key Lock.
大于
我们再来验证 id > 10:
update ct set remark = '巴西 爆冷 克罗地亚'
where id > 10;
这时匹配的记录有 15、20、30、40,所以会上4把Next-key Lock,对于40后的间隙,是对supremum上了Next-key Lock,这个很好理解,没什么特殊的,请看下图:
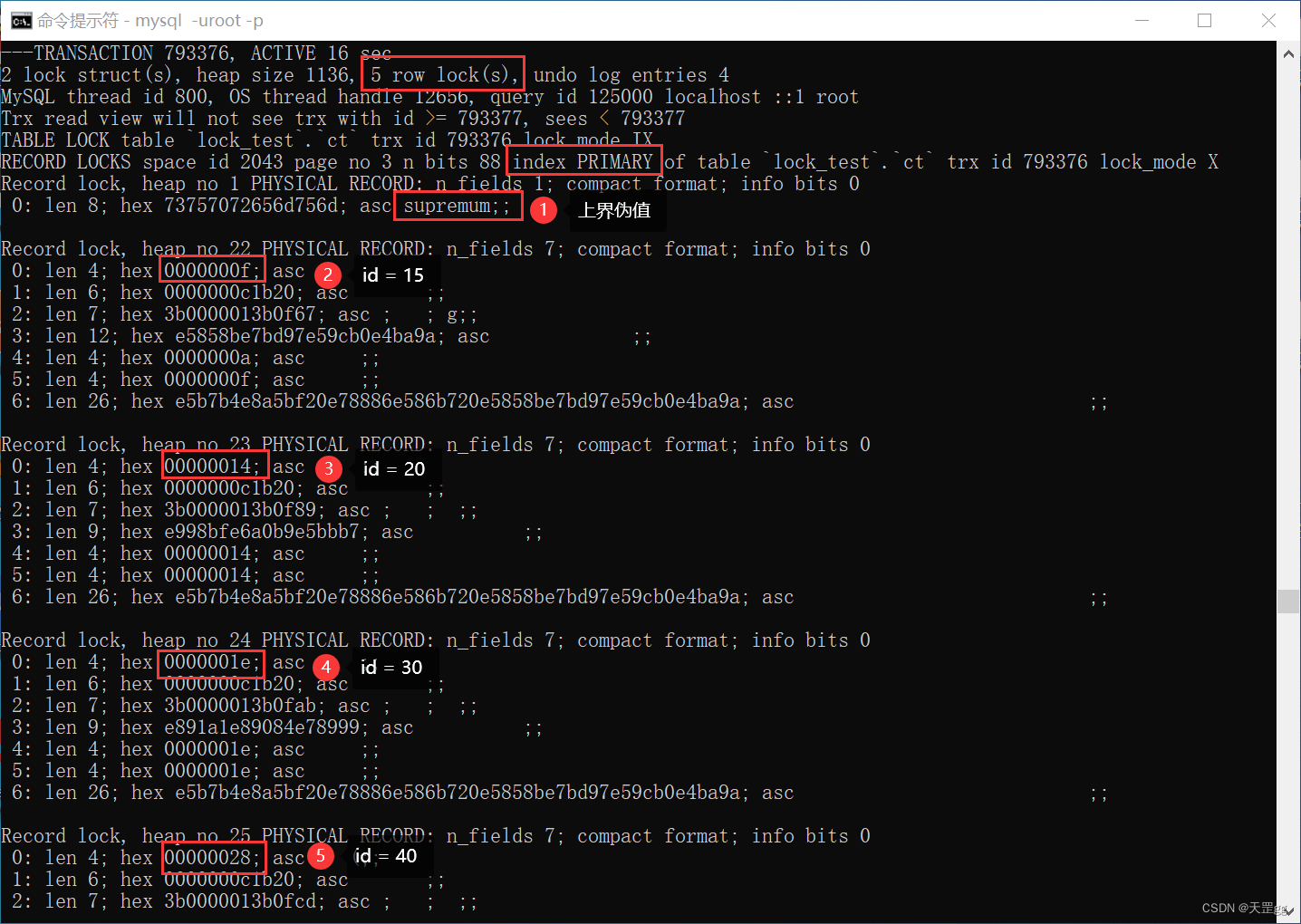
对于 > 在 聚集索引 上来说,我们得出的结果是(实际和 <, <= 类似):
- 聚集索引上, 所有匹配的 索引记录 上Next-key Lock;
- 对supremum (上界限伪值) 上Next-key Lock:锁的是最大值后的间隙;
大于等于
我们最后来看一下 id >= 10,这个有点特殊:
update ct set remark = '巴西 爆冷 克罗地亚'
where id >= 10;
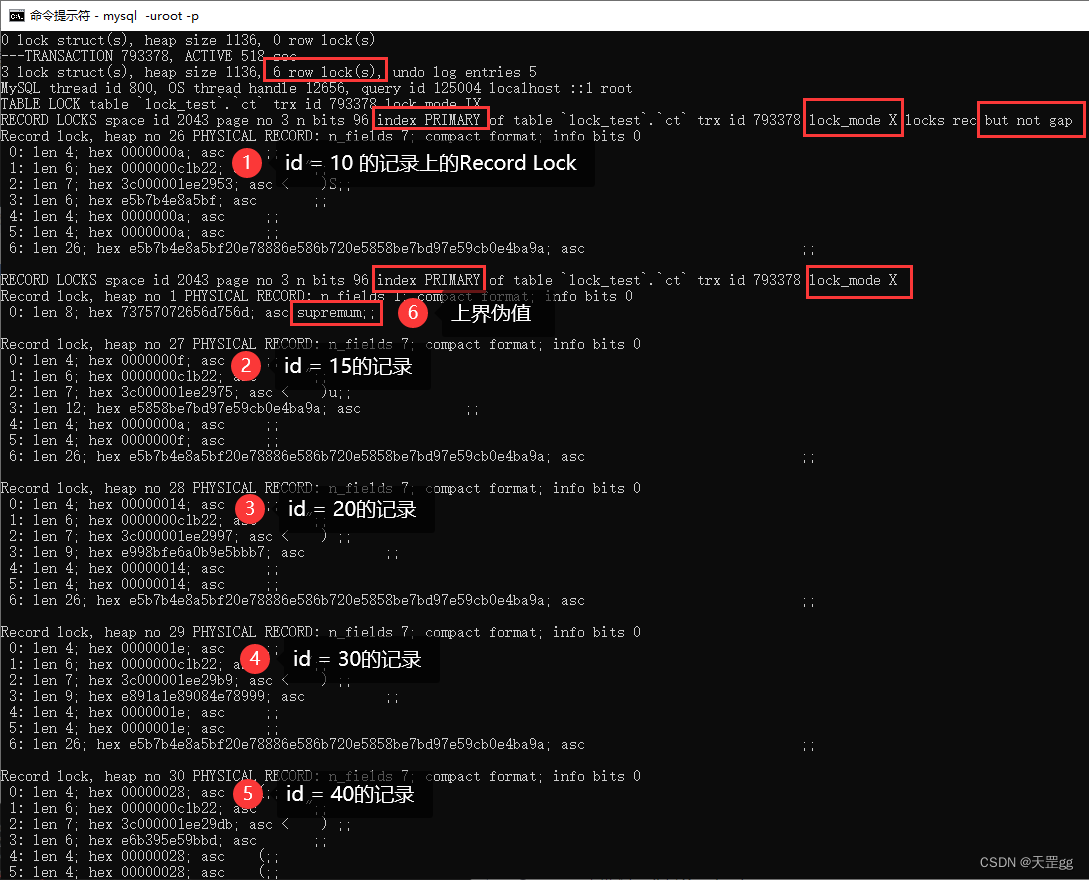
对于 >= 我们得到的结果是:
- 聚集索引上, 所有 > 的 索引记录 上Next-key Lock;
- 聚集索引上,
等值(=) 会上Record Lock,当然:如果没有 等值(=) 就不会上锁,我已验证 id>=11,比较好理解,不做赘述! - 对supremum (上界限伪值) 上Next-key Lock:锁的是最大值后的间隙;
范围组合
范围组合一: > <
update ct set remark = '匹配15'
where id > 10 and id < 20;
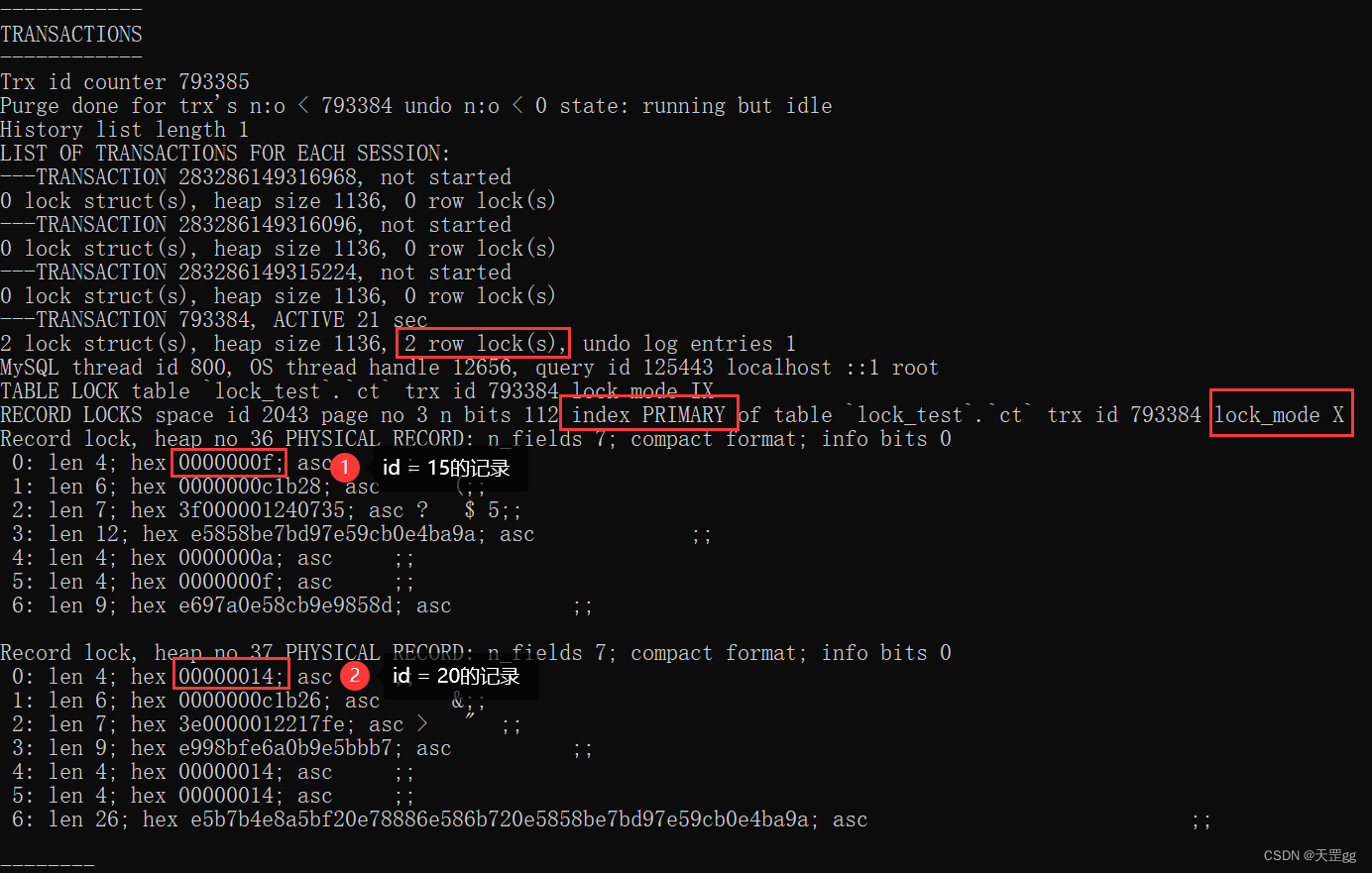
由图可知,对2条索引记录上锁:匹配:15,next-key:20
结果:
- 聚集索引上, 所有匹配的 索引记录 上Next-key Lock;
- 向右扫描聚集索引, 直到找到 [不匹配的索引记录] 上Next-key Lock.
范围组合二: > <=
update ct set remark = '匹配15 + 20'
where id > 10 and id <= 20;
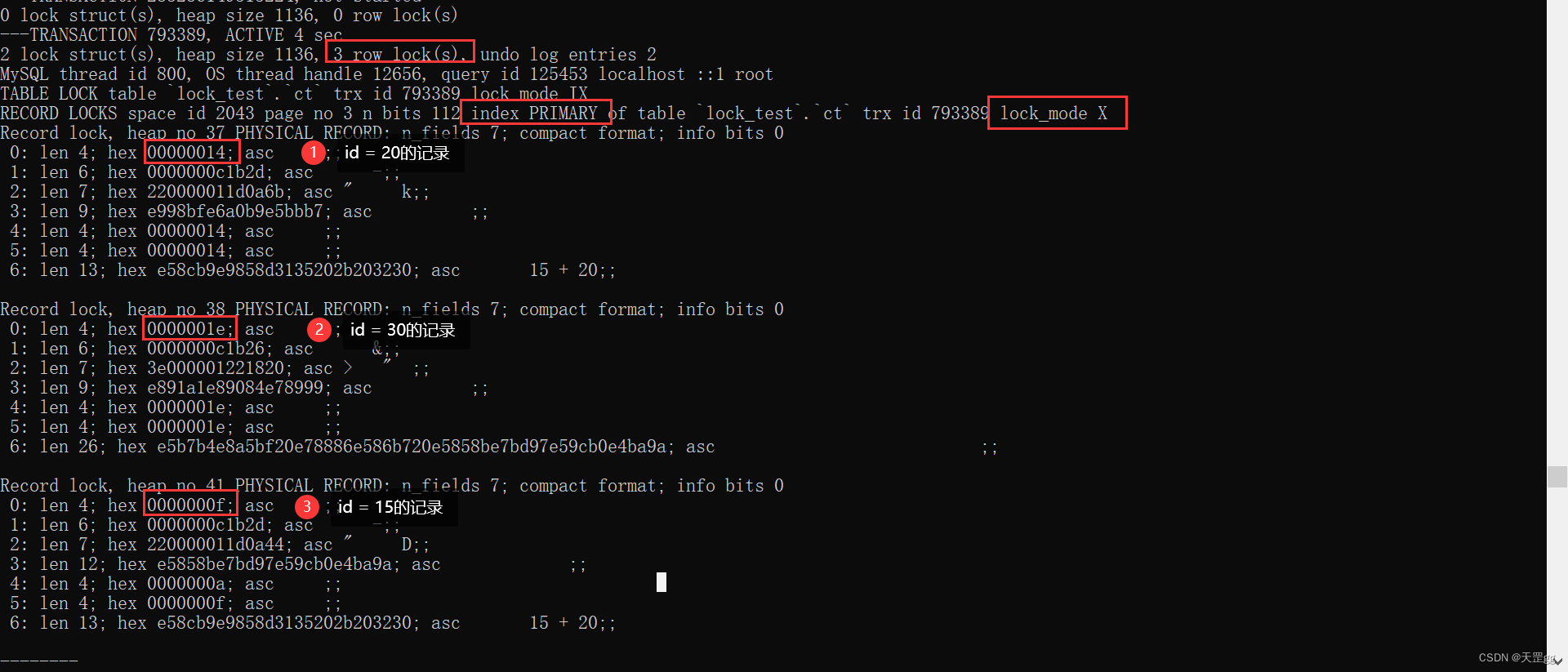
由图可知,对3条索引记录上锁:匹配:15、20,next-key:30
结果 和> <相同,不做赘述!
范围组合三: >= <
update ct set remark = '匹配10 + 15'
where id >= 10 and id < 20;
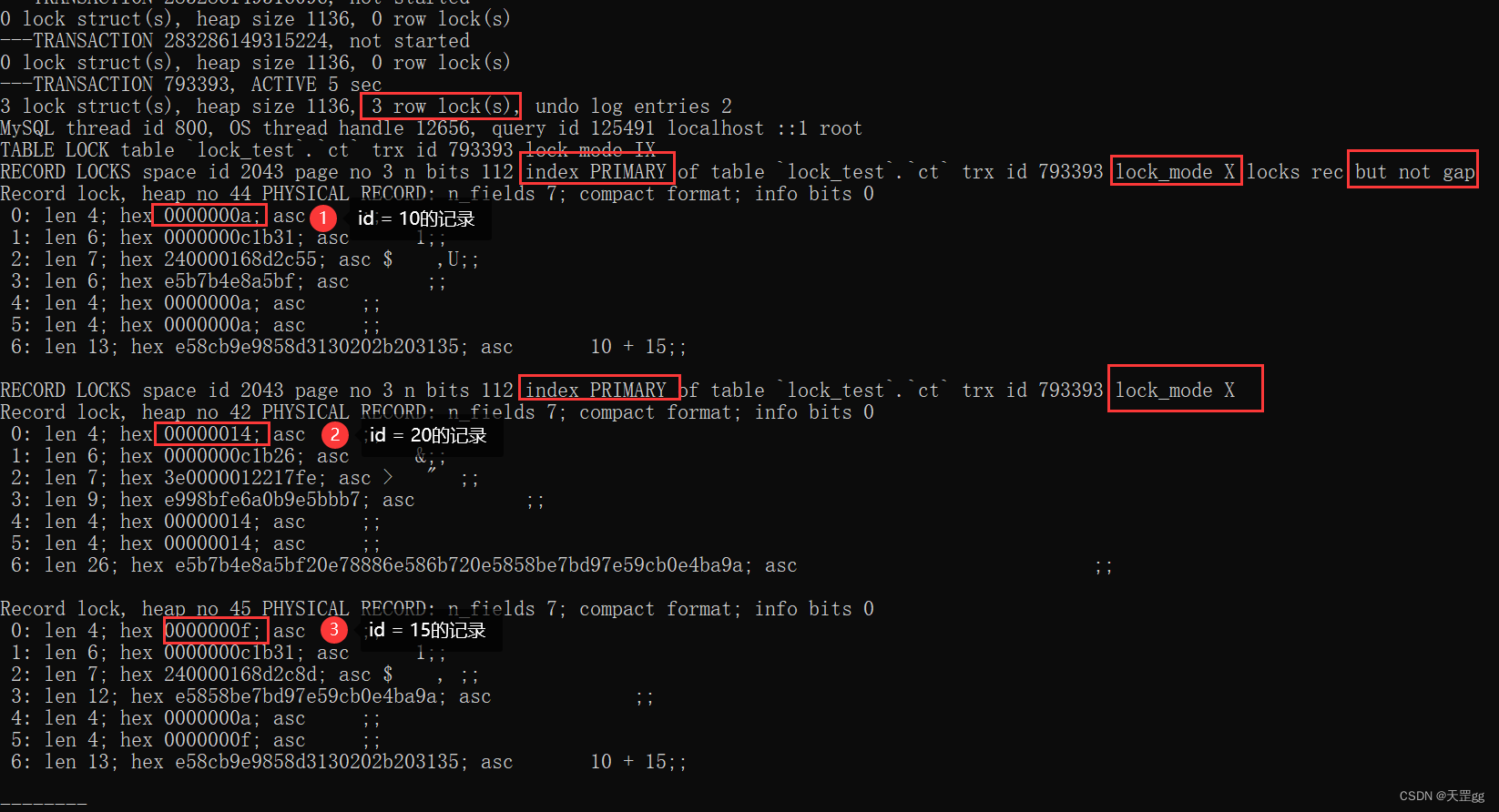
由图可知,对3条索引记录上锁:匹配:10、15,next-key:20
结果:
- 只有 >= 的等值(=)匹配索引记录上Record Lock,其它匹配的 索引记录 上Next-key Lock;
- 向右扫描 直到找到 不匹配 的 索引记录 上Next-key Lock.
范围组合四: >= <=
update ct set remark = '匹配10 + 15 + 20'
where id >= 10 and id <= 20;
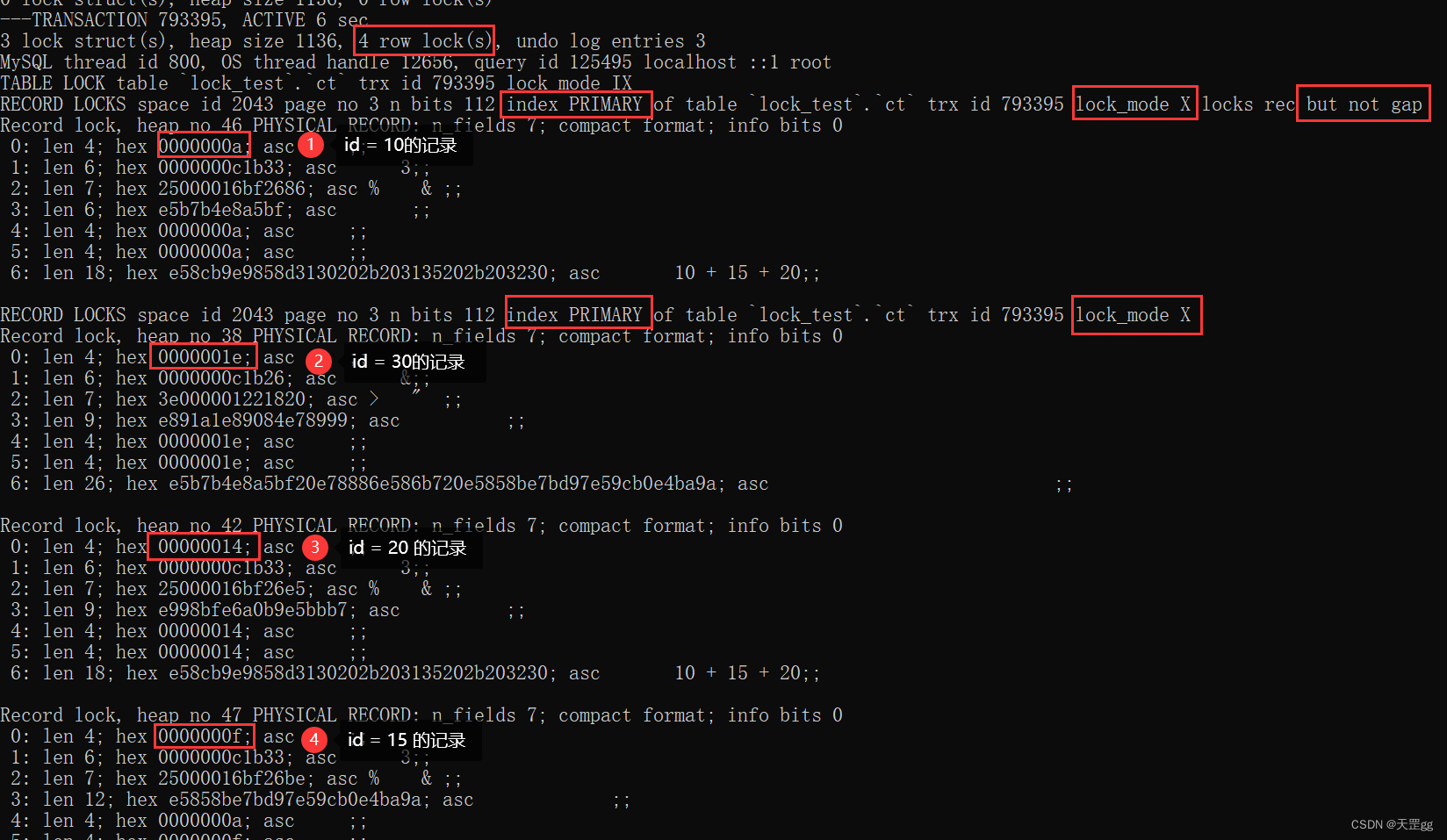
由图可知,对4条索引记录上锁:匹配:10、15、20,next-key:30
结果 和>= <相同,不做赘述!
聚集索引 小结
对于 聚集索引下的范围查询 <、<=、>、>=,无论是否组合,都会遵循如下规则:
- 所有匹配的索引记录:只有
>=的等值(=)匹配 上Record Lock,其它 上Next-key Lock; - 对于 < 和 <=:向右扫描聚集索引,直到找到 不匹配 的 索引记录 上Next-key Lock.
- 对于 > 和 >=,会对supremum (上界限伪值) 上Next-key Lock:锁的是 聚集索引 最大值 后面的 间隙;
唯一索引
小于
我们在Session2 执行SQL如下(按abc_uk < 20):
update ct set remark = '巴西 爆冷 克罗地亚'
where abc_uk < 20;
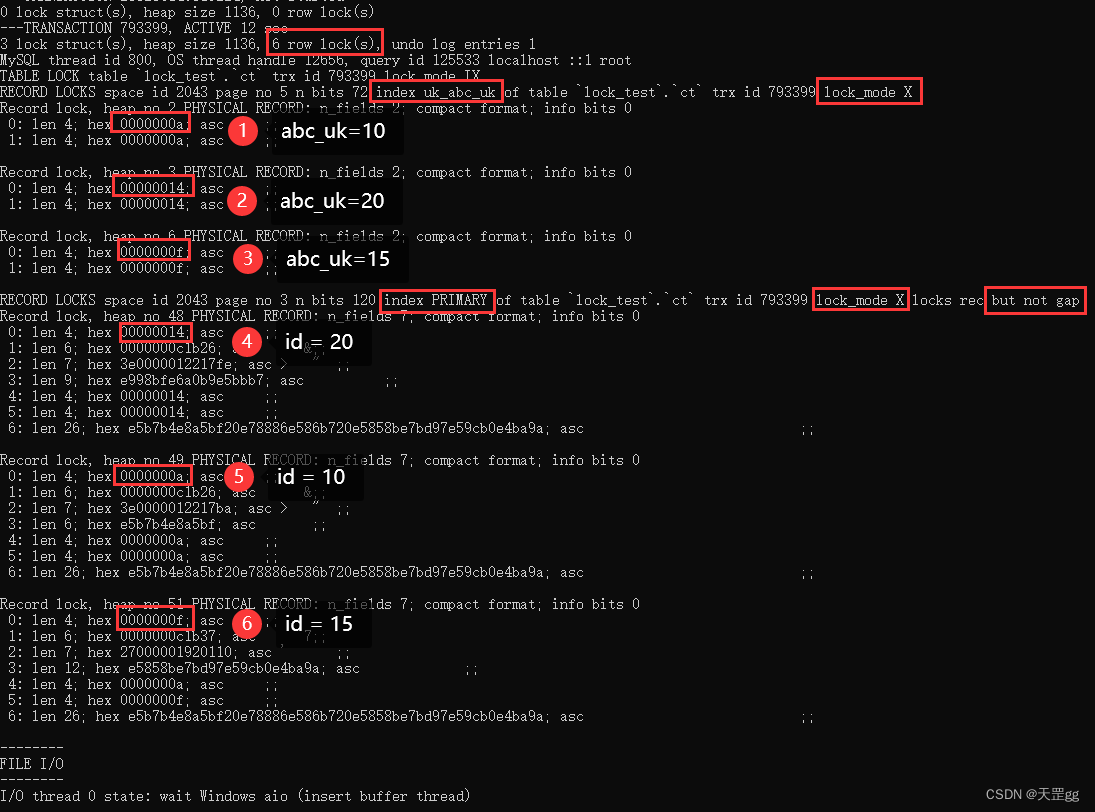
这里共匹配2条记录:abc_uk = 10 和 abc_uk = 15。
共上了 6 把锁,3把锁在唯一索引上:
- abc_uk = 20 (向右扫描到的第一个不匹配记录): Next-key Lock;
- abc_uk = 10(匹配记录) : Next-key Lock;
- abc_uk = 15(匹配记录) : Next-key Lock;
3把锁在聚集索引上:
- id = 20 (向右扫描到的第一个不匹配记录): Record Lock;
- id = 10(匹配记录) : Record Lock;
- id = 15(匹配记录) : Record Lock;
到这,我猜你肯定认为 和 聚集索引 一样有结果了,请看好了,好戏即将上演~
我改下sql,sql语句本身没变,只是 20换成30:
update ct set remark = '巴西 爆冷 克罗地亚'
where abc_uk < 30;
这里共匹配3条记录,分别是abc_uk = 10 、15、20。
我们看一下锁监视器:
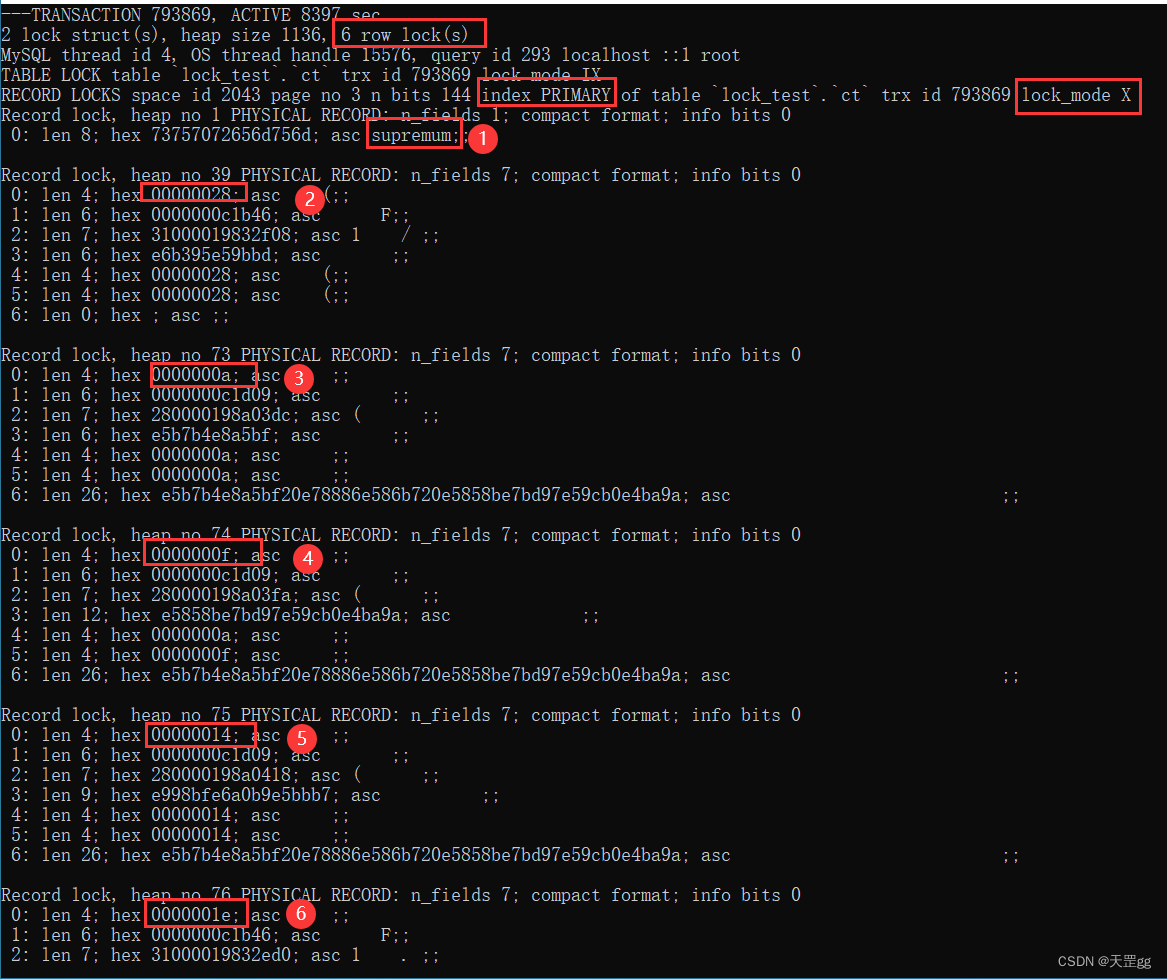
这里对聚集索引上了6把锁!!!
表里所有的5条聚集索引记录都上了Next-key Lock,还把supremum上了Next-key Lock。
你是不是会怀疑我搞错了?
那咱们走着瞧~,咱们先看一下explain的结果:
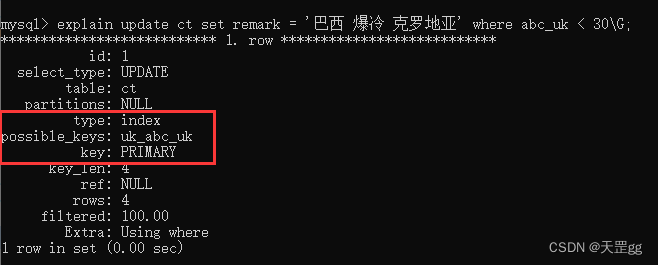
possible_keys: uk_abc_uk,意思说可能走的索引是uk_abc_uk
key:PRIMARY,意思说实际走的索引是聚集索引
type:index,意思说扫描了整个索引树
所以:这条SQL并没有使用唯一索引,而使用的是全表扫描。
这里其实是索引相关的知识,也就是索引失效了,实际是通过索引成本计算,得出全表扫描的cost(3.9) 小于 走唯一索引再回表的cost(4.61):
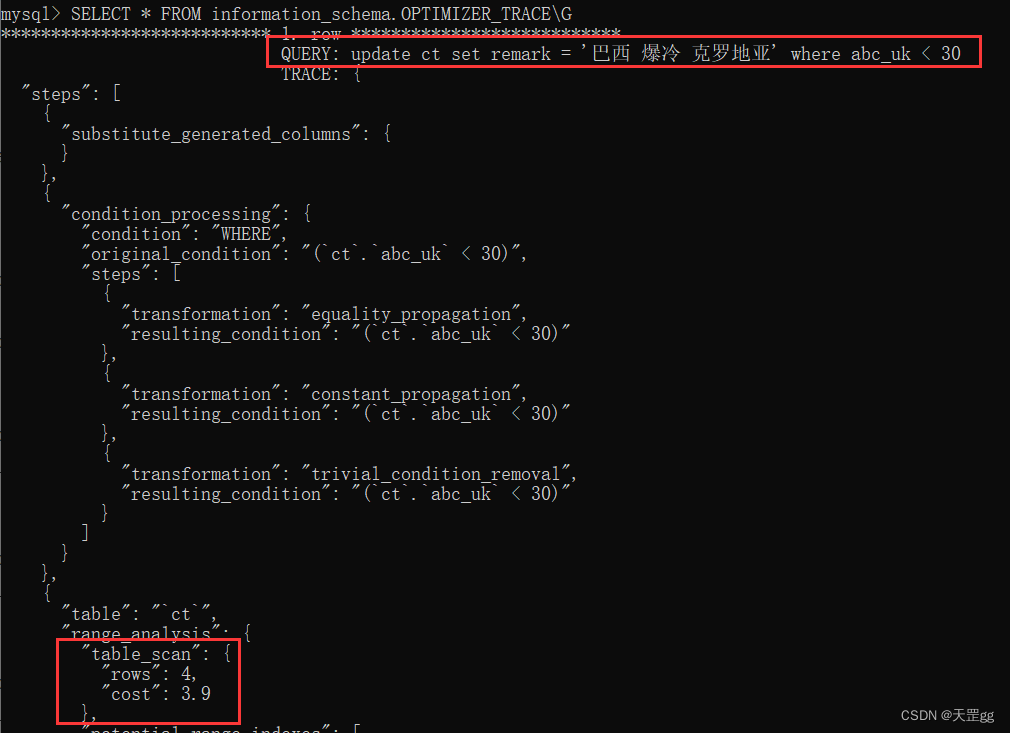
全表扫描的成本计算(上图):
- I/0成本:1*1.0+1.1 = 2.1
- CPU成本:4*0.2+1.0 = 1.8
- 总成本:I/0成本(2.1)+CPU成本(1.8) = 3.9
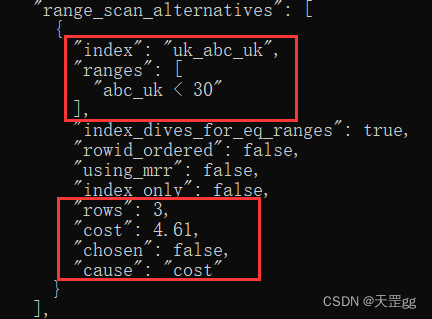
使用唯一索引的成本计算(上图):
- I/0成本1 - 范围区间的数量: 1 * 1.0 = 1.0
- I/0成本2 - 回表成本:3 * 1.0 = 3.0
- CPU成本:3 * 0.2 + 0.01 = 0.61
- 总成本:I/0成本(4.0)+CPU成本(0.61) = 4.61
说白了,就是表里一共才5条记录,这个范围就匹配了3条记录,我用唯一索引先查id,再用id回表去修改,还不如直接遍历全表来的快!!!
实际项目里,表里的数据一般不会这么少,所以这个示例的修改占比(60%)还是很高的,所以才造成了全表扫描(全表成本低于使用索引)。
对于索引要细说的话内容很多,远没有这么简单,这里只是简单说明,不懂不要紧,先作为了解,后面再安排细聊索引的成本计算!
安排结果!对于 < 在 唯一索引 上来说,我们得出的结果是:
- 如果走了唯一索引:
- 在该索引上,所有匹配的索引记录 上Next-key Lock,对应的聚集索引 上Record Lock;
- 向右扫描该索引,直到找到 [不匹配的索引记录] 上Next-key Lock,对应的聚集索引 上Record Lock;
- 如果没走唯一索引,那么就会把所有 聚集索引记录 和 间隙 都锁上,就是所谓的锁表,或叫行锁升表锁.
小于等于
update ct set remark = '巴西 爆冷 克罗地亚'
where abc_uk <= 19;
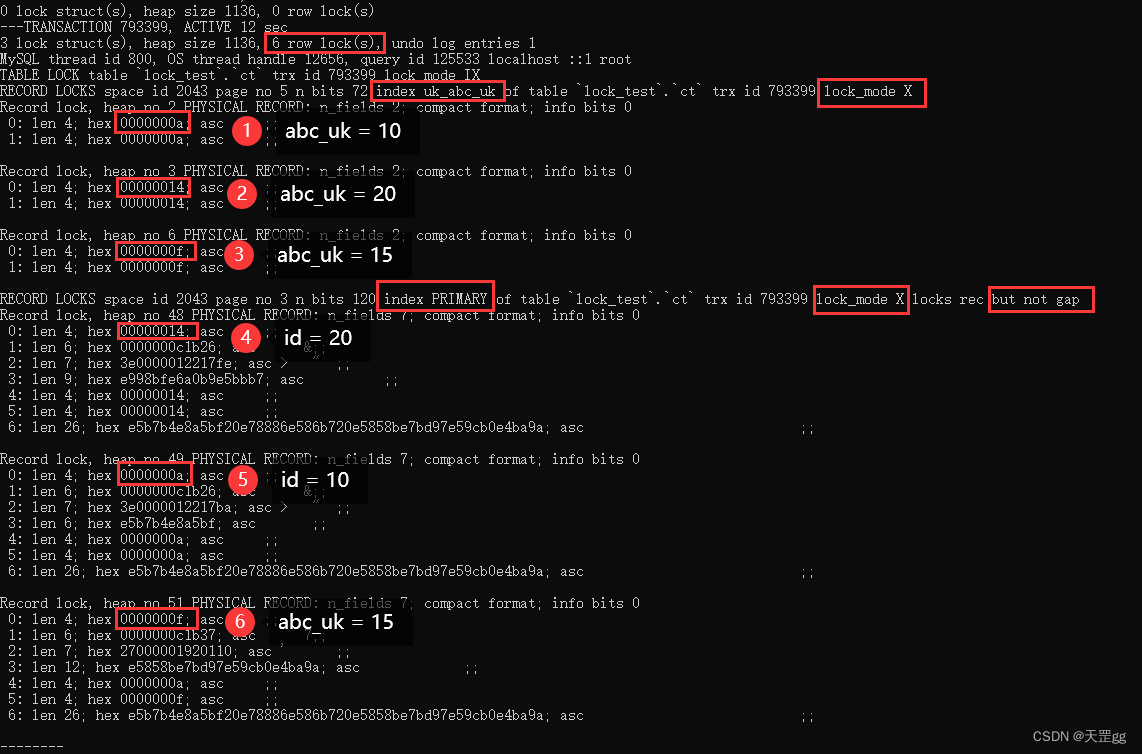
不出所料,因为 和 abc_uk < 20 的匹配记录是相同的,所以锁的结果也是相同的!
我们再来看一下临界值 abc_uk <=20:
begin;
update ct set remark = '巴西 爆冷 克罗地亚'
where abc_uk <= 20;
这里依然是会影响到3条记录 abc_uk = 10、15、20,所以你懂的,又锁表了!!! 具体就不截图了。
所以我们改成范围小一点的临界值 abc_uk <=15:
begin;
update ct set remark = '巴西 爆冷 克罗地亚'
where abc_uk <= 15;
这里只会影响到2条记录 abc_uk = 10、15
我们来看一下:
show engine innodb status\G;
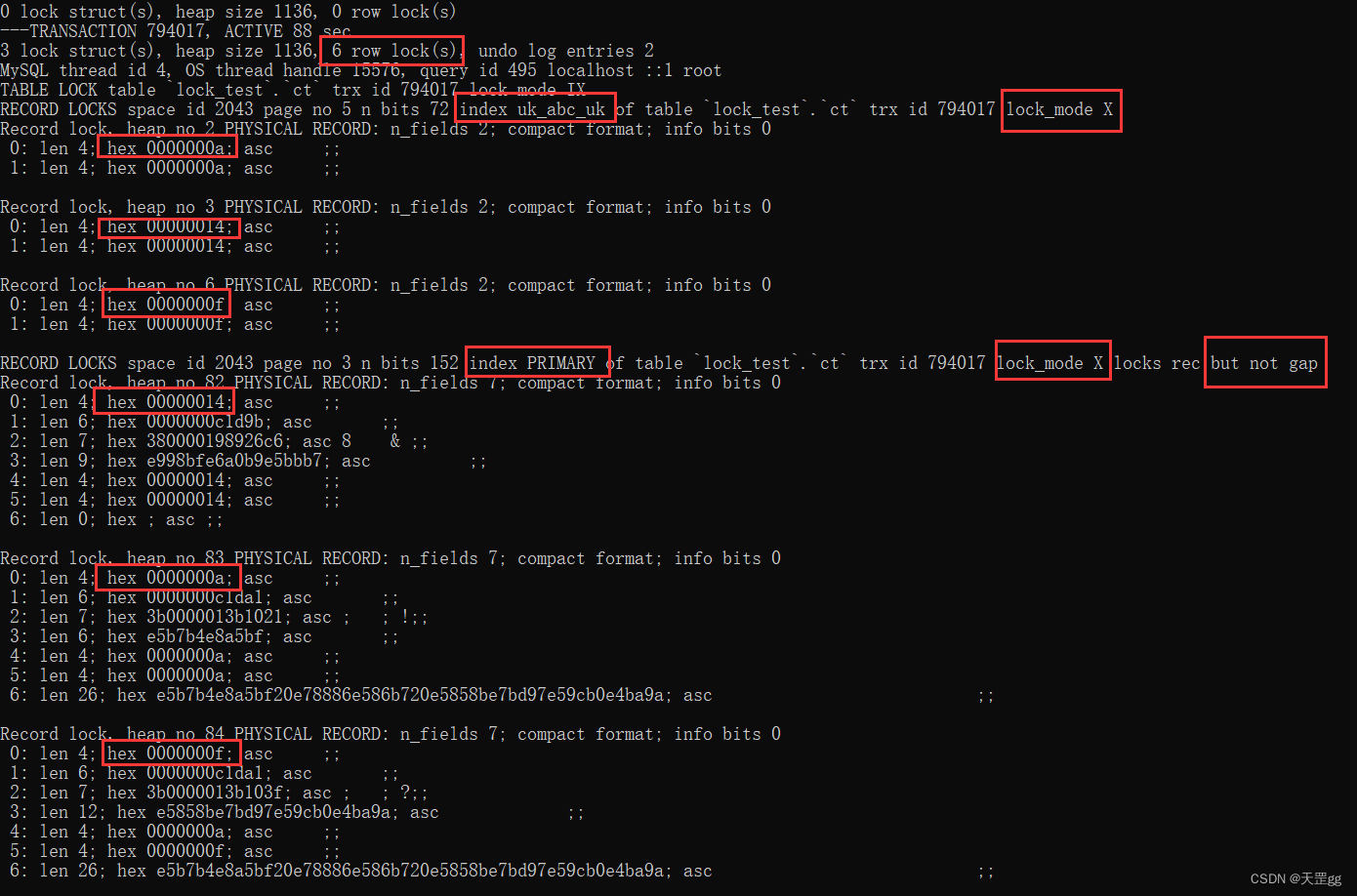
这里共匹配2条记录:abc_uk = 10 和 abc_uk = 15。
共上了 6 把锁,3把锁在唯一索引上:
- abc_uk = 20 (向右扫描到的第一个不匹配记录): Next-key Lock;
- abc_uk = 10(匹配记录) : Next-key Lock;
- abc_uk = 15(匹配记录) : Next-key Lock;
3把锁在聚集索引上:
- id = 20 (向右扫描到的第一个不匹配记录): Record Lock;
- id = 10(匹配记录) : Record Lock;
- id = 15(匹配记录) : Record Lock;
综上,对于 <= 在 聚集索引 上来说,我们得出的结果 实际和 < 一样,不做赘述!
大于
我们先来验证 abc_uk > 10:
update ct set remark = '阿根廷 3:0 克罗地亚'
where abc_uk > 10;
这里共匹配4条记录:abc_uk = 15、20、30、40,所以你懂的,又锁表了!!! 具体就不截图了。
所以我们改成范围小一点的 abc_uk > 20:
update ct set remark = '阿根廷 3:0 克罗地亚'
where abc_uk > 20;
这里只会影响到2条记录 abc_uk = 30、40
我们来看一下:
show engine innodb status\G;
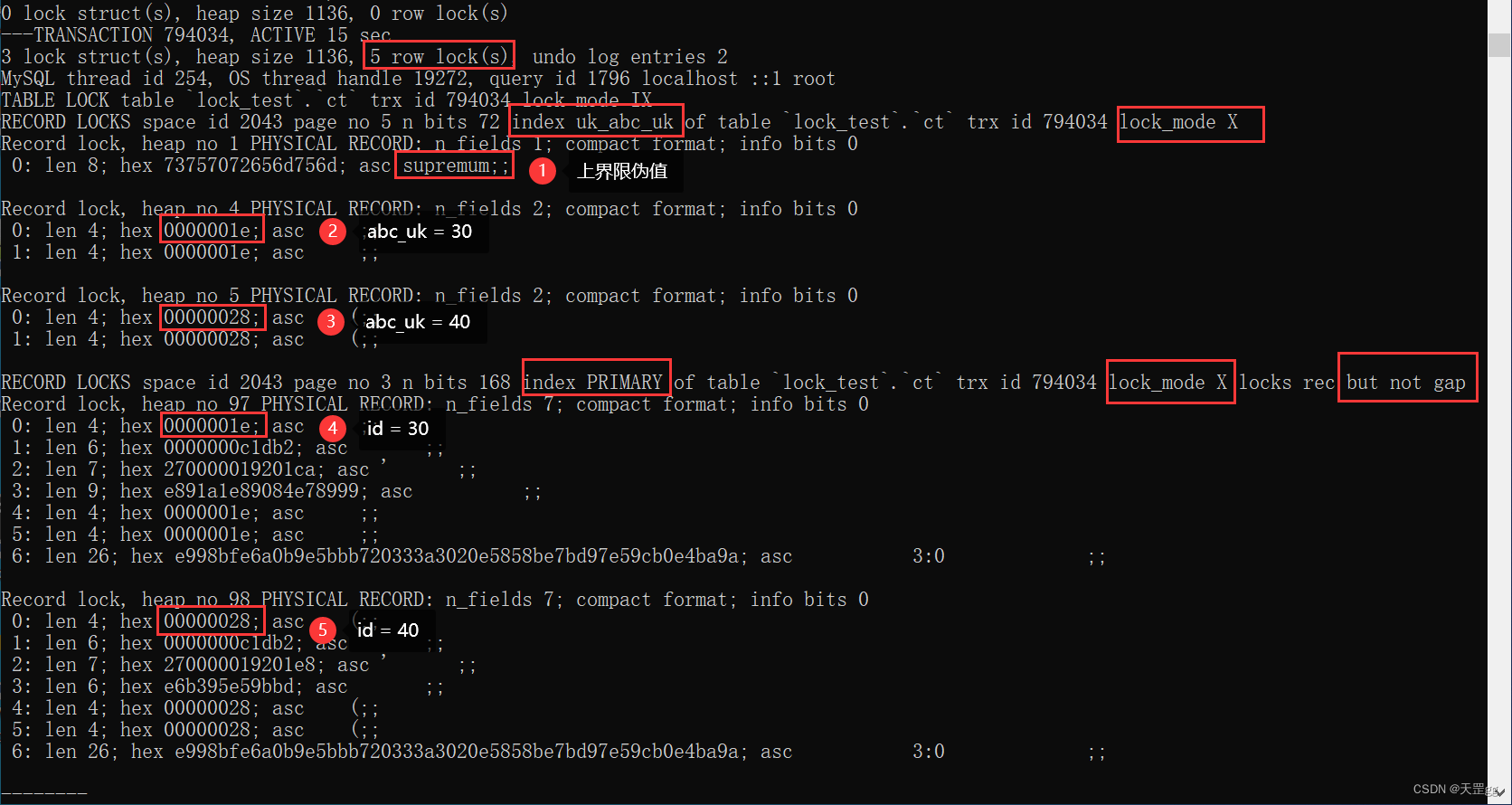
这里共匹配2条记录:abc_uk = 30 和 abc_uk = 40。
共上了 5把锁,3把锁在唯一索引上:
- abc_uk = supremum (上界限伪值,锁的是最大值后的间隙): Next-key Lock;
- abc_uk = 30(匹配记录) : Next-key Lock;
- abc_uk = 40(匹配记录) : Next-key Lock;
2把锁在聚集索引上:
- id = 30(匹配记录) : Record Lock;
- id = 40(匹配记录) : Record Lock;
对于 > 在 唯一索引 上来说,我们得出的结果是(实际和 <, <= 类似):
- 如果走了唯一索引:
- 在该索引上,所有匹配的索引记录 上Next-key Lock,对应的聚集索引 上Record Lock;
- 在该索引上,对supremum (上界限伪值) 上Next-key Lock:锁的是最大值后的间隙;
- 如果没走唯一索引,那么就会把所有 聚集索引记录 和 间隙 都锁上,就是所谓的锁表,或叫行锁升表锁.
大于等于
因为 abc_uk >= 10匹配了所有记录,所以你懂的,又锁表了!!! 具体就不截图了。
我们直接来看不锁表的 abc_uk >= 30
update ct set remark = '阿根廷 3:0 克罗地亚'
where abc_uk >= 30;
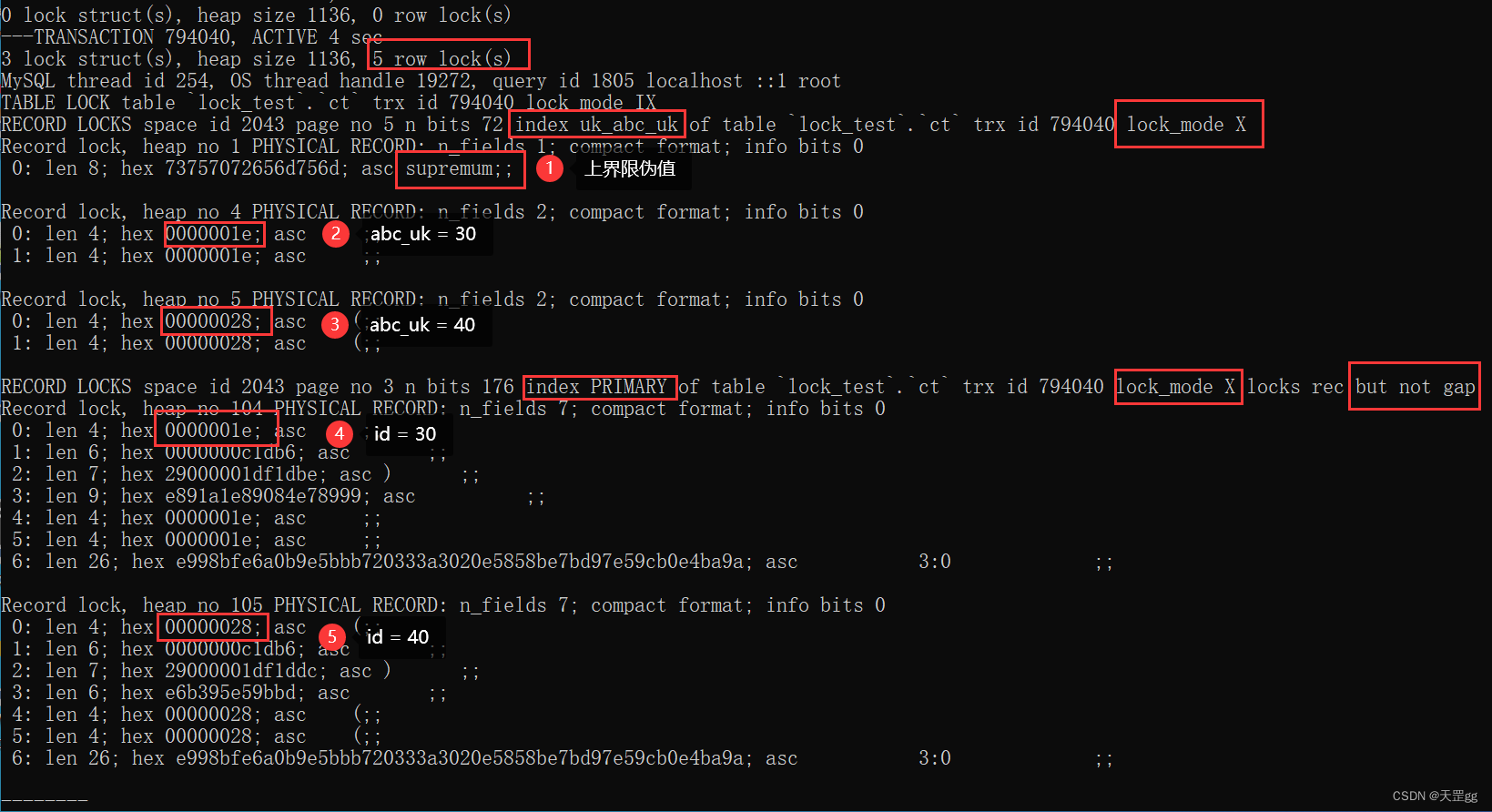
从上图可知,abc_uk >= 30 和 abc_uk > 20 上的锁是一样的,并不像 id >= 时那样将匹配值优化为Record Lock。
所以,对于 >= 我们得到的结果 实际和 > 一样,不做赘述!
范围组合
说明:
索引失效 会 锁表的规则是通用的,所以这里就 统一只演示 不锁表的情况。
范围组合一: > <
update ct set remark = '格子军团'
where abc_uk > 10 and abc_uk < 20;
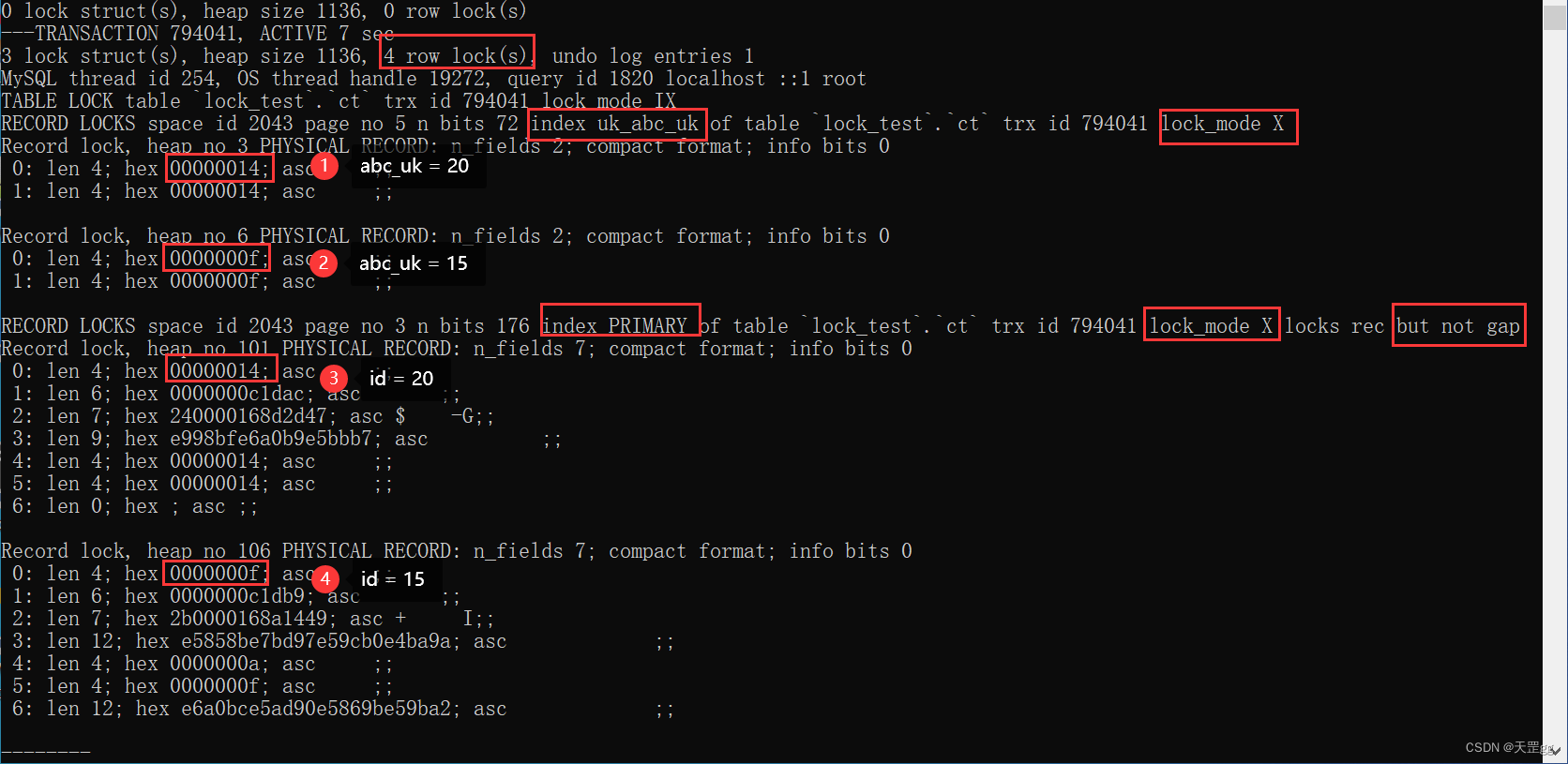
不出所料,由图可知,对 2条唯一索引 和对应的 2条聚集索引 上锁:匹配:15,next-key:20
结果:(和单个规则相同)
- 如果走了唯一索引:
- 在该索引上,所有匹配的索引记录 上Next-key Lock,对应的聚集索引 上Record Lock;
- 向右扫描该索引, 直到找到 [不匹配的索引记录] 上Next-key Lock,对应的聚集索引 上Record Lock.
- 如果没走唯一索引,那么就会把所有 聚集索引记录 和 间隙 都锁上,就是所谓的锁表,或叫行锁升表锁.
范围组合二: > <=
update ct set remark = '格子军团'
where abc_uk > 10 and abc_uk <= 20;
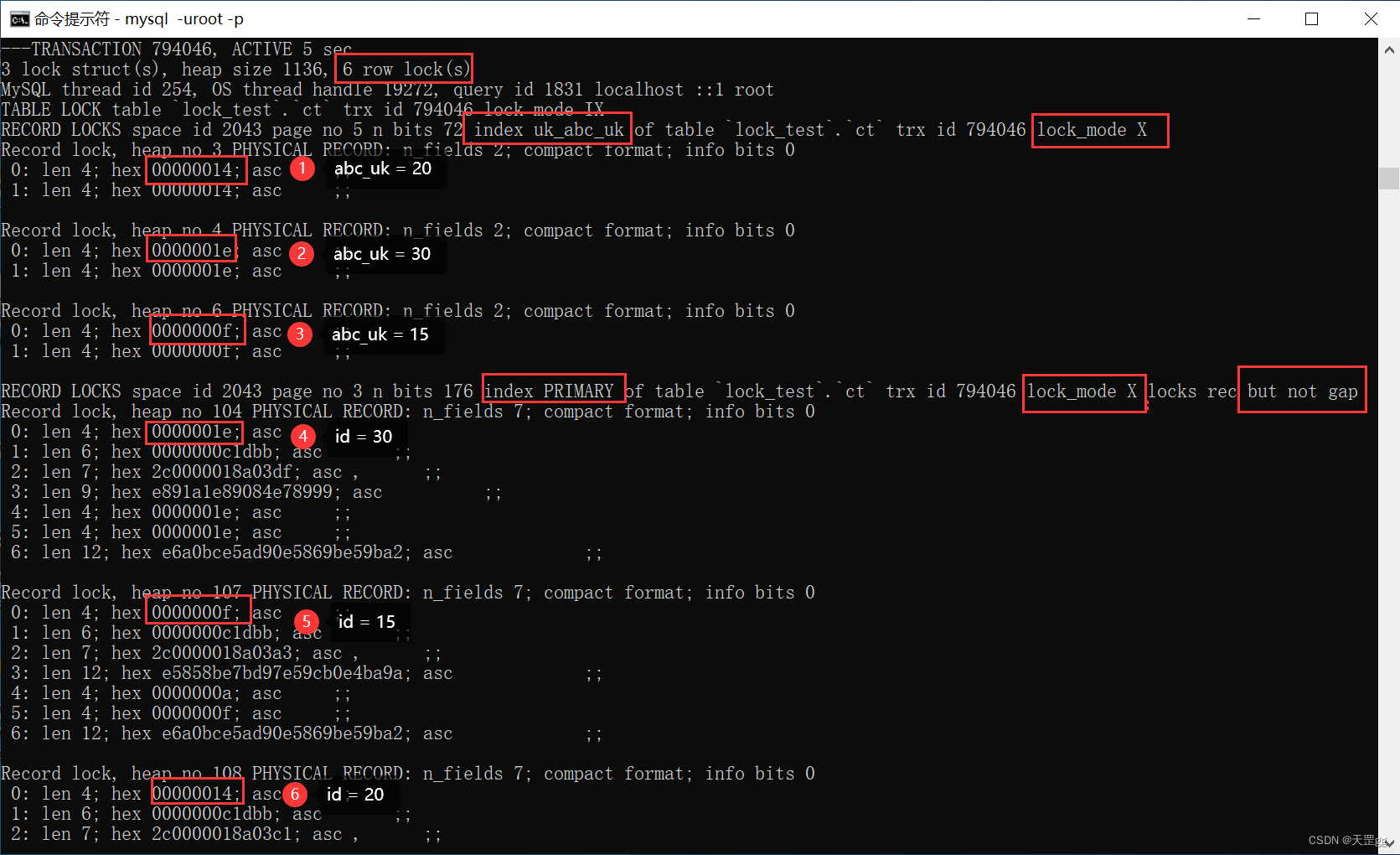
不出所料,由图可知,对 3条唯一索引 和对应的 3条聚集索引 上锁:匹配:15、20,next-key:30
结果:(和单个规则相同)
- 如果走了唯一索引:
- 在该索引上,所有匹配的索引记录 上Next-key Lock,对应的聚集索引 上Record Lock;
- 向右扫描该索引, 直到找到 [不匹配的索引记录] 上Next-key Lock,对应的聚集索引 上Record Lock.
- 如果没走唯一索引,那么就会把所有 聚集索引记录 和 间隙 都锁上,就是所谓的锁表,或叫行锁升表锁.
范围组合三: >= <
update ct set remark = '梅西加油'
where abc_uk >= 10 and abc_uk < 20;
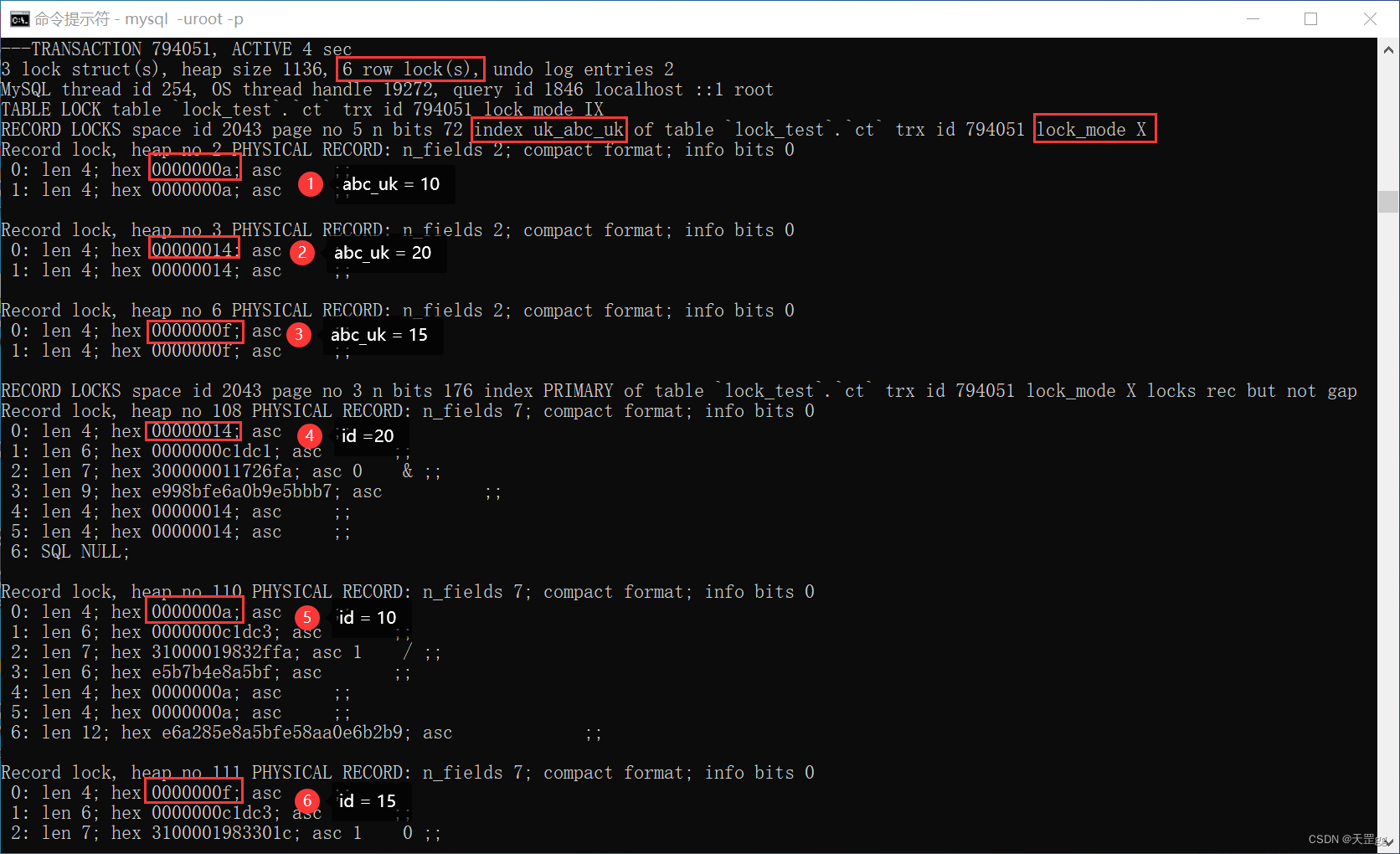
不出所料,由图可知,对 3条唯一索引 和对应的 3条聚集索引 上锁:匹配:10、15,next-key:20
结果:(和单个规则相同)
- 如果走了唯一索引:
- 在该索引上,所有匹配的索引记录 上Next-key Lock,对应的聚集索引 上Record Lock;
- 向右扫描该索引, 直到找到 [不匹配的索引记录] 上Next-key Lock,对应的聚集索引 上Record Lock.
- 如果没走唯一索引,那么就会把所有 聚集索引记录 和 间隙 都锁上,就是所谓的锁表,或叫行锁升表锁.
范围组合四: >= <=
update ct set remark = '梅西加油'
where abc_uk >= 10 and abc_uk <= 15;
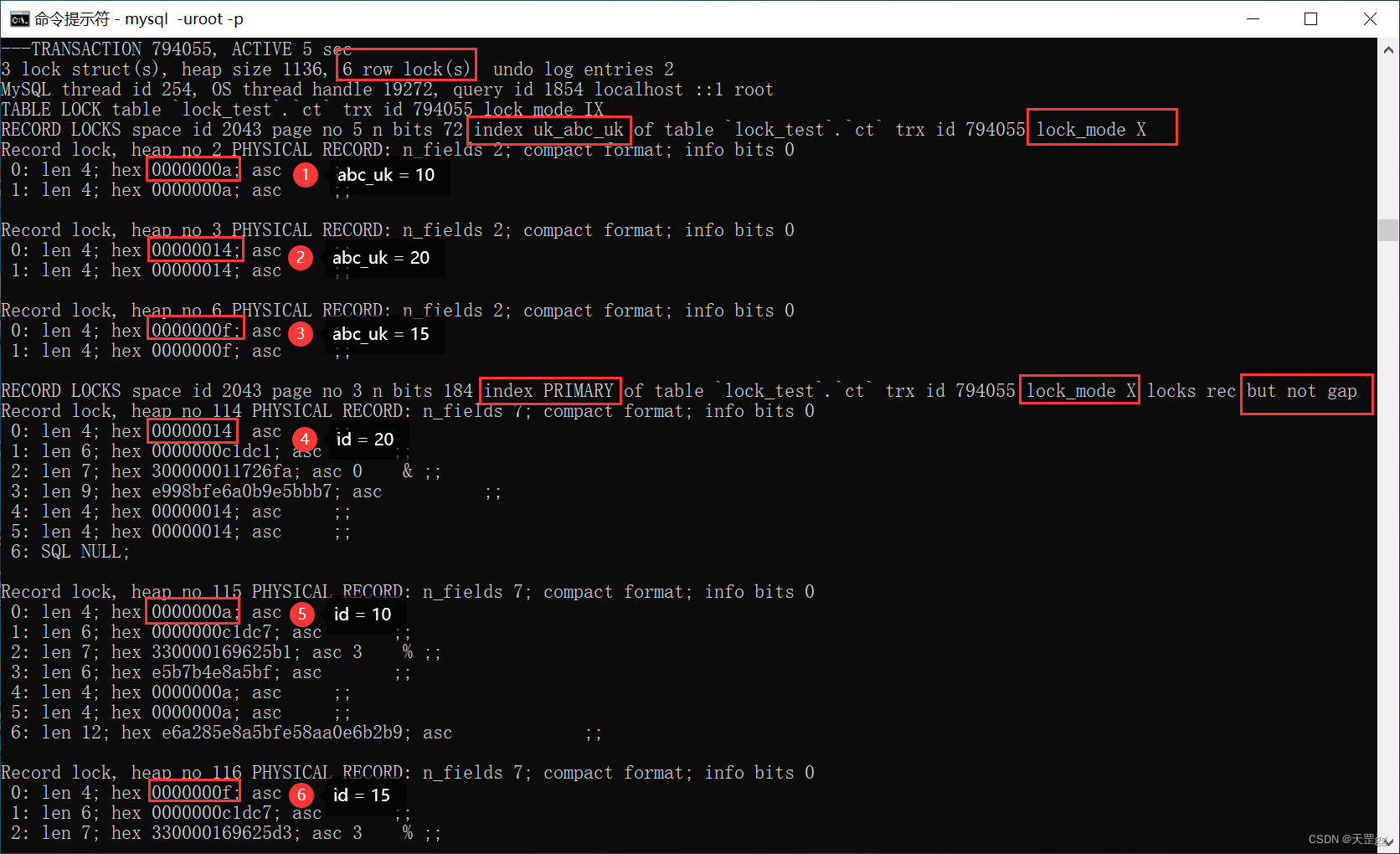
不出所料,由图可知,对 3条唯一索引 和对应的 3条聚集索引 上锁:匹配:10、15,next-key:20
结果:(和单个规则相同)
- 如果走了唯一索引:
- 在该索引上,所有匹配的索引记录 上Next-key Lock,对应的聚集索引 上Record Lock;
- 向右扫描该索引, 直到找到 [不匹配的索引记录] 上Next-key Lock,对应的聚集索引 上Record Lock.
- 如果没走唯一索引,那么就会把所有 聚集索引记录 和 间隙 都锁上,就是所谓的锁表,或叫行锁升表锁.
唯一索引 小结
对于 唯一索引下的范围查询 <、<=、>、>=,无论是否组合,都会遵循如下规则:
- 如果走了唯一索引:
- 在该索引上,所有匹配的 索引记录 上Next-key Lock,对应的聚集索引 上Record Lock;
- 对于 < 和 <=,会在该索引上向右扫描, 直到找到 [不匹配的索引记录] 上Next-key Lock,对应的聚集索引 上Record Lock;
- 对于 > 和 >=,会对supremum (上界限伪值) 上Next-key Lock:锁的是 该索引 最大值 后面的 间隙;
- 如果没走唯一索引,那么就会把所有 聚集索引记录 和 间隙 都锁上,就是所谓的锁表,或叫行锁升表锁.
普通索引
说明:
索引失效 会 锁表的规则是通用的,所以这里就 统一只演示 不锁表的情况。
小于
我们在Session2 执行SQL如下(按abc < 20):
update ct set remark = '梅西加油'
where abc < 20;
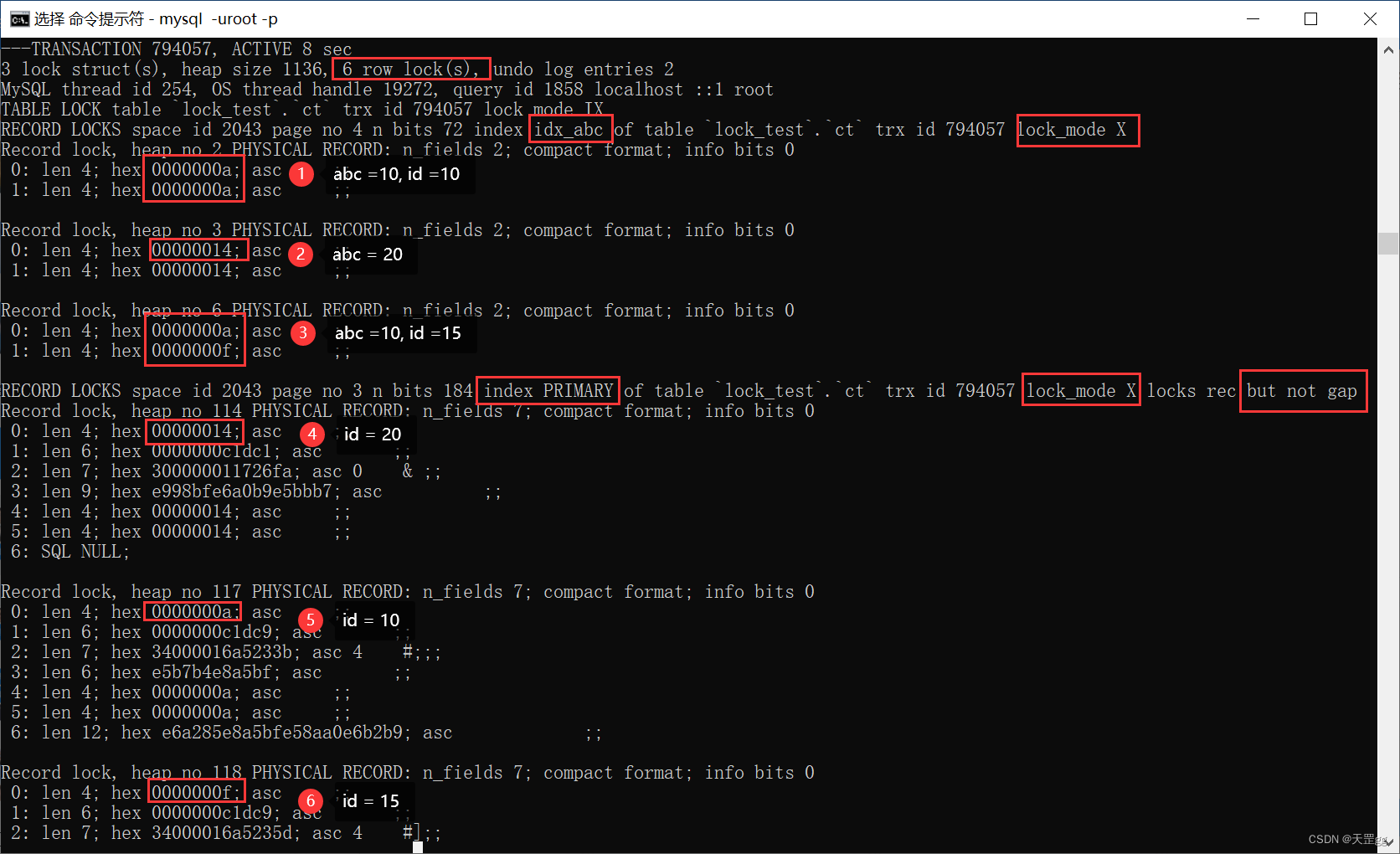
这里共匹配2条abc=10的记录。
所以共上了 6 把锁,3把锁在普通索引上:
- abc = 20 (向右扫描到的第一个不匹配记录): Next-key Lock;
- abc = 10,id = 10(匹配记录) : Next-key Lock;
- abc = 10,id = 15(匹配记录) : Next-key Lock;
3把锁在聚集索引上:
- id = 20 (向右扫描到的第一个不匹配记录): Record Lock;
- id = 10(匹配记录) : Record Lock;
- id = 15(匹配记录) : Record Lock;
可以看出:和唯一索引上锁规则没什么两样!,
锁表只需要把范围扩大就可以复现,比如:
update ct set remark = '梅西加油'
where abc < 30;
所以,对于 < 在 普通索引 上来说,我们得出的结果是(和唯一索引的 < 相同):
- 如果走了普通索引:
- 在该索引上,所有匹配的 索引记录 上Next-key Lock,对应的聚集索引 上Record Lock;
- 向右扫描该索引,直到找到 [不匹配的索引记录] 上Next-key Lock,对应的聚集索引 上Record Lock.
- 如果没走普通索引,那么就会把所有 聚集索引记录 和 间隙 都锁上,就是所谓的锁表,或叫行锁升表锁.
小于等于
update ct set remark = '梅西加油'
where abc <= 19;
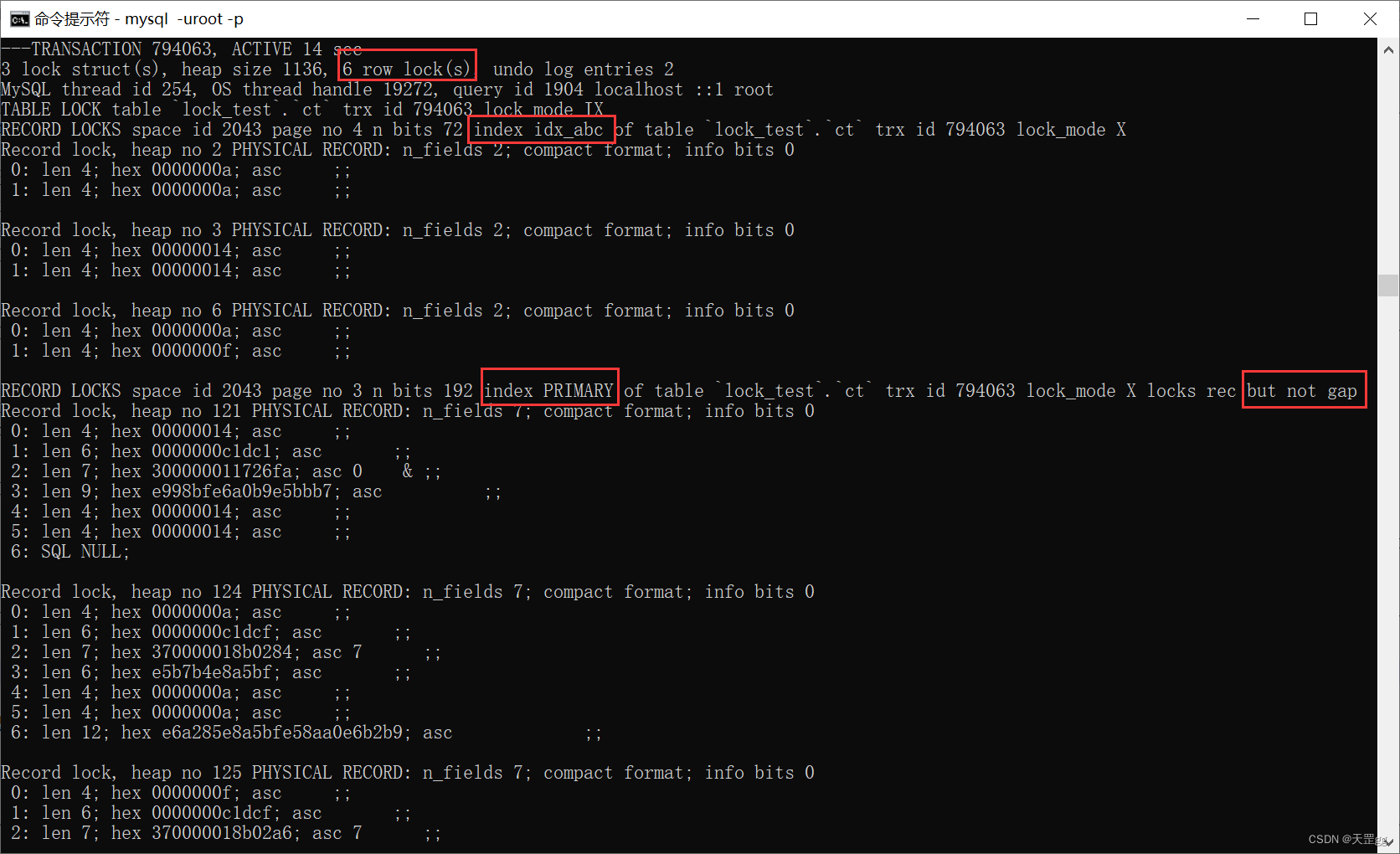
不出所料,因为 和 abc < 20 的匹配记录是相同的,所以锁的结果也是相同的!
所以,对于 <= 在 普通索引 上来说,我们得出的结果:实际和 < 一样,不做赘述.
大于
update ct set remark = '梅西加油'
where abc > 20;
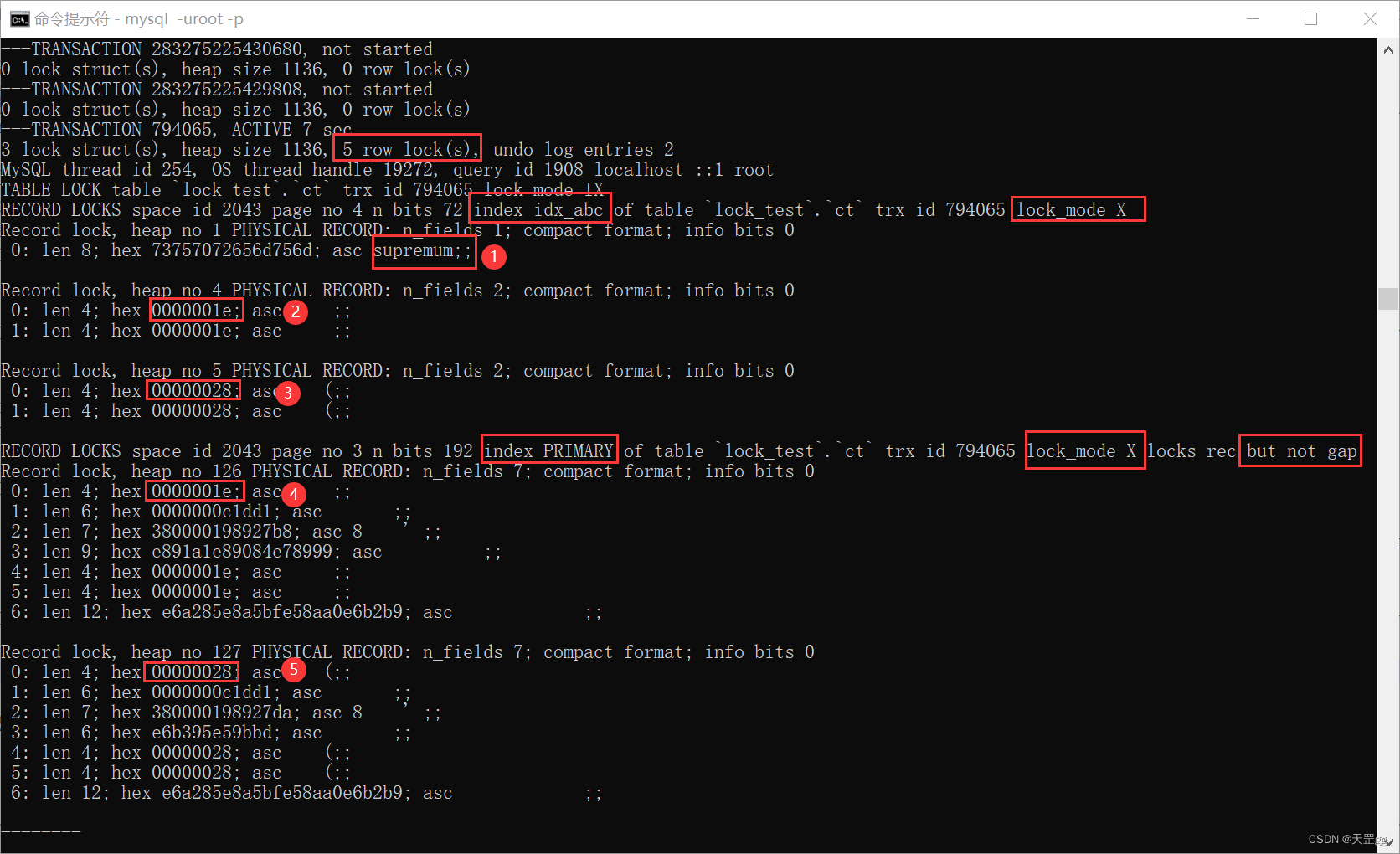
这里共匹配2条记录:abc = 30、40
共上了 5把锁,3把锁在普通索引上:
- abc = supremum (上界限伪值,锁的是最大值后的间隙): Next-key Lock;
- abc = 30(匹配记录) : Next-key Lock;
- abc = 40(匹配记录) : Next-key Lock;
2把锁在聚集索引上:
- id = 30(匹配记录) : Record Lock;
- id = 40(匹配记录) : Record Lock;
对于 > 在 普通索引 上来说,我们得出的结果是(实际和唯一索引的相同):
- 如果走了普通索引:
- 在该索引上,所有匹配的 索引记录 上Next-key Lock,对应的聚集索引 上Record Lock;
- 在该索引上,对supremum (上界限伪值) 上Next-key Lock:锁的是最大值后的间隙;
- 如果没走唯一索引,那么就会把所有 聚集索引记录 和 间隙 都锁上,就是所谓的锁表,或叫行锁升表锁.
大于等于
update ct set remark = '梅西加油'
where abc >= 30;
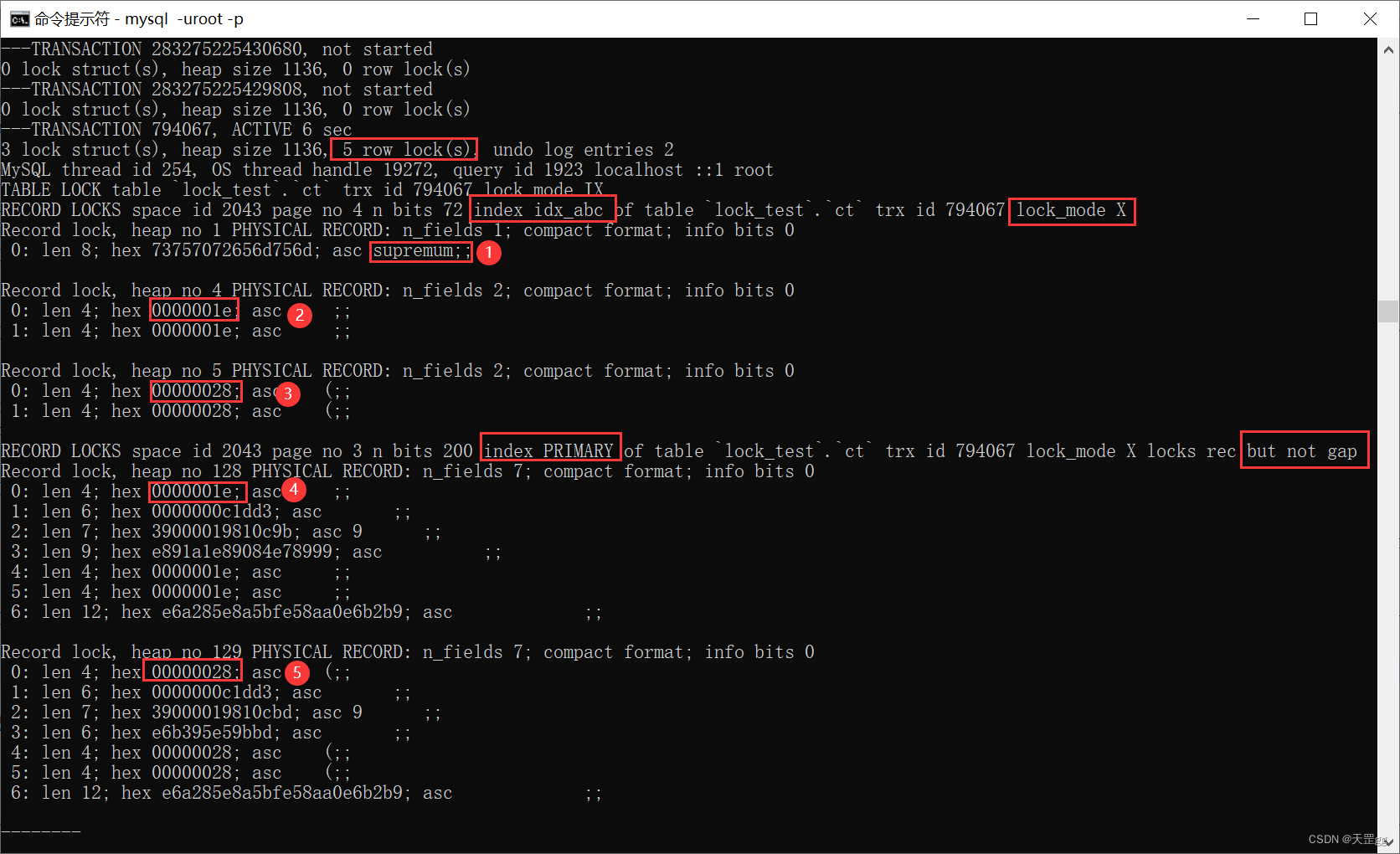
从上图可知,abc >= 30 和 abc > 20 的上锁是一样的,和唯一索引规则相同,并不像id>=时那样将匹配值优化为Record Lock。
所以,对于 >= 在 普通索引 上来说,我们得出的结果:实际和 > 一样,不做赘述.
范围组合
范围组合一: > <
update ct set remark = '格子军团'
where abc > 10 and abc < 20;
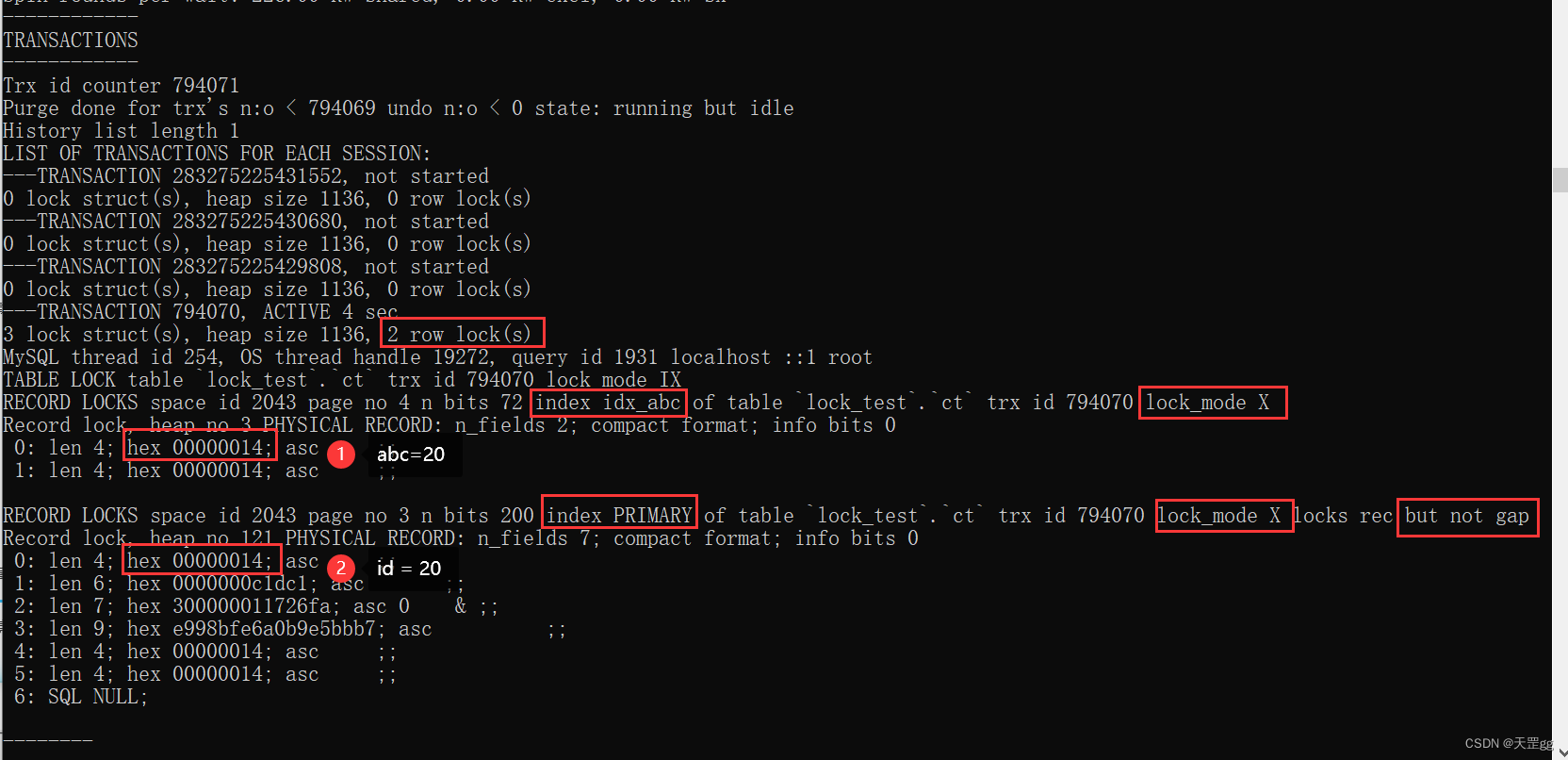
不出所料,由图可知,无匹配记录,所以只对next-key:abc=20以及对应的id = 20上了锁
结果:(和单个规则相同)
- 如果走了普通索引:
- 在该索引上,所有匹配的 索引记录 上Next-key Lock,对应的聚集索引 上Record Lock;
- 在该索引上,向右扫描 直到找到 [不匹配的索引记录] 上Next-key Lock,对应的聚集索引 上Record Lock.
- 如果没走唯一索引,那么就会把所有 聚集索引记录 和 间隙 都锁上,就是所谓的锁表,或叫行锁升表锁.
因为其它范围组合实际都和单个规则相同,所以不做赘述!
普通索引 小结
对于 普通索引下的范围查询 <、<=、>、>=,无论是否组合,都会遵循如下规则:
- 如果走了普通索引:
- 在该索引上,所有匹配的 索引记录 上Next-key Lock,对应的聚集索引 上Record Lock;
- 对于 < 和 <=,会在该索引上向右扫描, 直到找到 [不匹配的索引记录] 上Next-key Lock,对应的聚集索引 上Record Lock;
- 对于 > 和 >=,会对supremum (上界限伪值) 上Next-key Lock:锁的是 该索引 最大值 后面的 间隙;
- 如果没走普通索引,那么就会把所有 聚集索引记录 和 间隙 都锁上,就是所谓的锁表,或叫行锁升表锁.
总结
这里需要补充说明的是:因为对于范围查询,都会有个边界,所以如果没有任何匹配,就会只对边界加锁,规则不变!
结论开篇就给出了,结论传送门.
最后
如果感觉不错,请收藏本专栏,后面还有更详细的锁机制陆续放出。
关注我 天罡gg 分享更多干货: https://blog.csdn.net/scm_2008
大家的「关注 + 点赞 + 收藏」就是我创作的最大动力!谢谢大家的支持,我们下文见!




![[附源码]Python计算机毕业设计SSM基于Java的运动健身平台(程序+LW)](https://img-blog.csdnimg.cn/380bd1fe78784cf5b6d50e82edbe675d.png)


![[附源码]Python计算机毕业设计高校社团管理平台Django(程序+LW)](https://img-blog.csdnimg.cn/b5a00ac25a554d5e8ec9e6a850bf4387.png)