数组交集
- 349. 两个数组的交集
- 排序+双指针
- 数组实现哈希表
- unordered_set
- unordered_map
- 350. 两个数组的交集Ⅱ
- 排序 + 双指针
- 数组实现哈希表
- unordered_map
349. 两个数组的交集
题目链接:349. 两个数组的交集
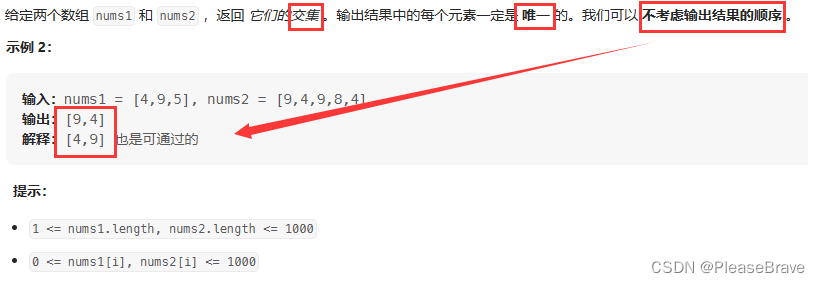
题目内容如下,理解题意:①交集中每个元素是唯一的,只能出现一次,所以本题要找的是同时出现在数组nums1和nums2中的元素,但是并不关心他们出现的次数;②输出结果的顺序不用考虑,也就是只要找到了同时出现在nums1和nums2中的元素就行,可以给数组排序(打乱了原本的顺序)再去查找、可以用map、set(其中key是无序的)……
这个题目暴力求解是可以的,暴力求解两层循环,将nums1和nums2的元素逐个对比,时间复杂度是O(m*n),因为nums1和nums2的长度都<=1000,所以最终也是能够运行的。
考虑更优的解法,直接一遍遍历nums1和nums2就好了。以下详述各解法:
排序+双指针
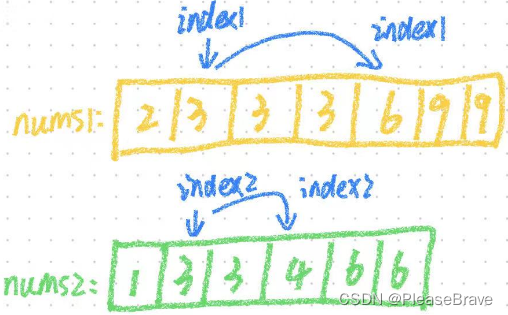
解法Ⅰ,对nums1和nums2排序后,从头开始遍历两个数组(下标用index1和index2),并将nums1[index1] = nums2[index2]的元素加入结果数组中。
存在的问题是:因为nums1和nums2中存在重复元素,如果找到了nums1[index1] = nums2[index2],且在nums1中,nums1[index1] 有重复,即nums1[index1+1] = nums1[index1] ,且在nums2中,nums2[index2]有重复,即nums2[index2+1] = nums2[index2]。那么直接对index++和index2++,会向结果数组中添加重复的元素。
解决:找到nums1[index1] = nums2[index2]后,index1++直到找到与之不同的下一个元素(就是跳过中间的相同的元素);index2++同样。
代码实现(C++):
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
vector<int> ans;
sort(nums1.begin(),nums1.end());//先给nums1和nums2都排序
sort(nums2.begin(),nums2.end());
//排序后双指针(index1和index2遍历nums1和nums2
for(int index1 = 0, index2 = 0; index1 < nums1.size() && index2 < nums2.size();){
if(nums1[index1] == nums2[index2]){
ans.emplace_back(nums1[index1]); //如果找到在两个数组中出现的元素,加入到结果数组中
//之后直接跳过和当前元素相同的一截,避免有可能向ans中重复添加该元素的可能
do{
index1++;
}while(index1 < nums1.size() && nums1[index1] == nums1[index1 - 1]);
do{
index2++;
}while(index2 < nums2.size() && nums2[index2] == nums2[index2 - 1]);
}
//如果不相等,更小的那个数向后移,同样是跳过和当前元素相同的一截,避免重复的比较
else if( nums1[index1] < nums2[index2]){
do{
index1++;
}while(index1 < nums1.size() && nums1[index1] == nums1[index1 - 1]);
}
else{
do{
index2++;
}while(index2 < nums2.size() && nums2[index2] == nums2[index2 -1]);
}
}
return ans;
}
};
数组实现哈希表
哈希表的好处体现在,它能够快速查找一个元素是否存在,时间复杂度是O(1)。我们要找nums1和nums2中同时存在的元素,换句话——查找nums1中某个元素是否出现在了nums2中。那么就可以用哈希表。因为题目中,nums1和num2的长度以及其中的int元素的大小都给了限制(<=1000),那么可以用数组来实现哈希表。
直接定义长度为1001的int数组count_1和count_2,统计nums1中元素的次数和nums2中元素出现的次数,最后对比count_1和count_2的每位元素,如果同时不为0的话,将对应元素加入到ans中。
代码如下(C++):
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
int count_1[1001] = {0}, count_2[1001] = {0};
vector<int> ans;
//分别统计nums1和nums2中元素出现情况
for ( auto& num : nums1){
count_1[num]=1;
}
for ( auto& num : nums2){
count_2[num]++;
}
for ( int i = 0; i <= 1000; i++){
//在两个数组中出现次数均>=1时,加入ans中
if( count_1[i] && count_2[i])
ans.emplace_back(i);
}
return ans;
}
};
优化:上面需要用到两个数组count_1和count_2来分别统计nums1、nums2中元素出现的情况,之后还要遍历这俩数组。是否有可能只使用一个count数组,用两次?——遍历nums1的时候,出现的元素不统计次数,而是count[nums[i]]=1,标记该元素出现过;遍历nums2的时候,如果count[nums2[j]] !=0就表示在两个数组中同时存在;防止重复添加,再将count[nums2[j]]=0;
代码实现(C++):
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
int count[1001] = {0};
vector<int> ans;
//统计nums1中元素的出现情况
for ( auto& num : nums1){
count[num]=1;
}
//遍历nums2
for ( auto& num : nums2){
if(count[num]){ //同时判断nums2中的元素在nums1中是否出现
count[num]=0;
ans.emplace_back(num);
}
}
return ans;
}
};
unordered_set
题意是要找交集,那么直接把数组变成集合,然后求两个集合交集就好。实现上,将vector变成unordered_set,然后对比两个unordered_set的key,找到重叠部分。
代码实现(C++):
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
//把vector转化成unordered_set
unordered_set<int> num_set1(nums1.begin(),nums1.end());
unordered_set<int> num_set2(nums2.begin(),nums2.end());
vector<int> ans;
//遍历两个set,找交集;遍历size小的
if( num_set1.size() < num_set2.size()){
for( auto& key : num_set1)
if(num_set2.count(key))
ans.emplace_back(key);
}
else{
for( auto& key :num_set2)
if(num_set1.count(key))
ans.emplace_back(key);
}
return ans;
}
};
unordered_map
最后也能用map来实现,遍历nums1和nums2的同时,统计其中元素出现的次数,用unordered_map来存,key是数组中出现的元素,value是元素出现的次数; 之后找到两个map中重合的key。
代码(C++):
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
unordered_map<int,int> count_1, count_2;
vector<int> ans;
//用map统计数组中出现的元素及其次数
for ( auto& num : nums1){
count_1[num]++;
}
for ( auto& num : nums2){
count_2[num]++;
}
if(count_1.size() < count_2.size()){
for ( auto key_value : count_1)
if(count_2.count(key_value.first))
ans.emplace_back(key_value.first);
}
else{
for ( auto key_value : count_2)
if(count_1.count(key_value.first))
ans.emplace_back(key_value.first);
}
return ans;
}
};
350. 两个数组的交集Ⅱ
题目链接:350. 两个数组的交集Ⅱ
题目内容: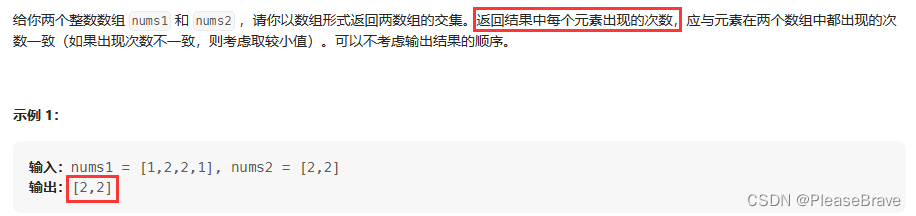
这道题和上一题唯一不同的点在于:在nums1和nums2中同时出现的元素,如果出现次数不止一次,都需要加入到结果中。即不仅要统计同时出现在nums1和nums2中的元素,还要统计他们各自出现的次数(C1和C2),并在结果数组ans中重复min (C1, C2) 次。以下代码均在上一题基础上做一点改动即可。
排序 + 双指针
排序后数组元素逐个对比就好:双指针index1和index2,每次对比nums1[index1]和nums2[index2]的关系后,直接index1++,index2++:
class Solution {
public:
vector<int> intersect(vector<int>& nums1, vector<int>& nums2) {
vector<int> ans;
sort(nums1.begin(),nums1.end());
sort(nums2.begin(),nums2.end());
for(int index1 = 0, index2 = 0; index1 < nums1.size() && index2 < nums2.size();){
if(nums1[index1] == nums2[index2]){
ans.emplace_back(nums1[index1]);
//下标直接向后移动,这样同时重复出现在两个数组中的元素能够重复添加
index1++;
index2++;
}
else if( nums1[index1] < nums2[index2]){
index1++;
}
else{
index2++;
}
}
return ans;
}
};
数组实现哈希表
先用数组count统计nums1中出现的元素,及其次数;再遍历nums2,同时出现在nums1中的元素,count[nums2[i]]- -,向结果数组ans中添加一次该元素。
class Solution {
public:
vector<int> intersect(vector<int>& nums1, vector<int>& nums2) {
int count[1001] = {0};
vector<int> ans;
//统计出现的元素,以及次数
for ( auto& num : nums1){
count[num]++;
}
for ( auto& num : nums2){
if(count[num]){
//对于同时出现的元素,对其次数--,保证后续再出现该元素时,还能重复添加
count[num]--;
ans.emplace_back(num);
}
}
return ans;
}
};
unordered_map
只是将上面的数组换成了unordered_map。用数组实现哈希表适用于nums1和nums2都不大的,并且其中元素也不大的情况,当数组很大并且数组元素为int,大小没有限制的时候,用map更合适(或者set)。
代码如下:
class Solution {
public:
vector<int> intersect(vector<int>& nums1, vector<int>& nums2) {
unordered_map<int,int> count;
vector<int> ans;
for(auto& num : nums1){
count[num]++;
}
for(auto& num : nums2){
if(count.count(num)){
ans.emplace_back(num);
count[num]--;
//如果已经重复添加了min(c1,c2)次了,即便后续再出现也不能再添加了
if(count[num]==0)
count.erase(num);
}
}
return ans;
}
};
![[机缘参悟-100] :今早的感悟:儒释道代表了不同的人生观、思维模式决定了人的行为模式、创业到处是陷阱、梦想与欺骗其实很容易辨认](https://img-blog.csdnimg.cn/img_convert/f3eccd18f44ce05b55e36a08194e4580.jpeg)







![[四次挥手]TCP四次挥手握手由入门到精通(知识精讲)](https://img-blog.csdnimg.cn/24b696d76d374a9992017e1625389592.gif)