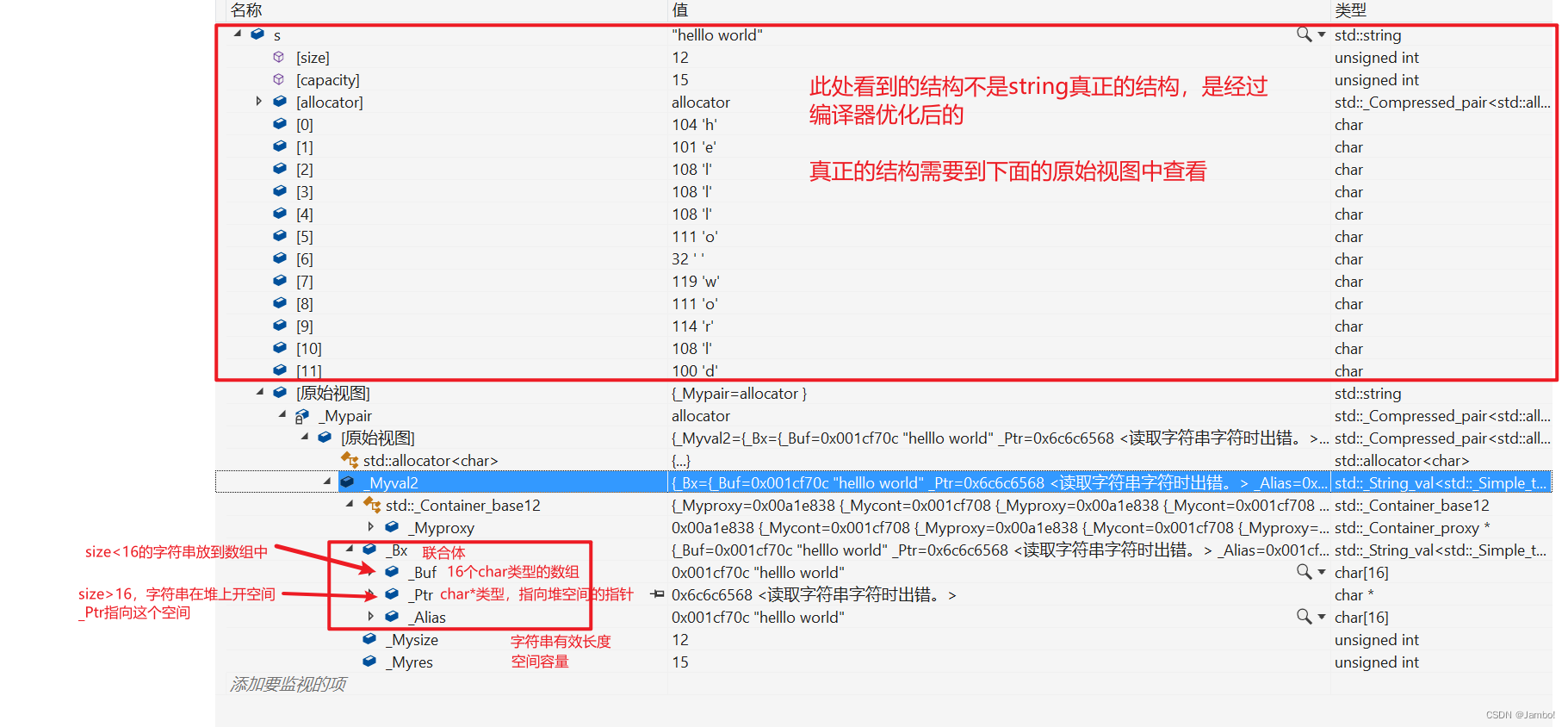
在我们进行深度学习的过程中,不免要用到数据集,那么数据集是如何加载到我们的模型中进行训练的呢?以往我们大多数初学者肯定都是拿网上的代码直接用,但是它底层的原理到底是什么还是不太清楚。所以今天就从内置的Dataset函数和自定义的Dataset函数做一个详细的解析。
文章目录
- 前言
- 1、自定义Dataset类
- 2、torchvision.datasets
- 3、DataLoader
- 4、torchvision.transforms
前言
torch.utils.data 是PyTorch提供的一个模块,用于处理和加载数据。该模块提供了一系列工具类和函数,用于创建、操作和批量加载数据集。
下面是 torch.utils.data 模块中一些常用的类和函数:
Dataset: 定义了抽象的数据集类,用户可以通过继承该类来构建自己的数据集。Dataset类提供了两个必须实现的方法:__getitem__用于访问单个样本,__len__用于返回数据集的大小。TensorDataset: 继承自Dataset类,用于将张量数据打包成数据集。它接受多个张量作为输入,并按照第一个输入张量的大小来确定数据集的大小。DataLoader: 数据加载器类,用于批量加载数据集。它接受一个数据集对象作为输入,并提供多种数据加载和预处理的功能,如设置批量大小、多线程数据加载和数据打乱等。Subset: 数据集的子集类,用于从数据集中选择指定的样本。random_split: 将一个数据集随机划分为多个子集,可以指定划分的比例或指定每个子集的大小。ConcatDataset: 将多个数据集连接在一起形成一个更大的数据集。get_worker_info: 获取当前数据加载器所在的进程信息。
除了上述的类和函数之外,torch.utils.data 还提供了一些常用的数据预处理的工具,如随机裁剪、随机旋转、标准化等。
通过 torch.utils.data 模块提供的类和函数,可以方便地加载、处理和批量加载数据,为模型训练和验证提供了便利。但是,我们最常用的两个类还是Dataset和DataLoader类。
1、自定义Dataset类
torch.utils.data.Dataset是 PyTorch 中用于表示数据集的抽象类,用于定义数据集的访问方式和样本数量。
Dataset 类是一个基类,我们可以通过继承该类并实现下面两个方法来创建自定义的数据集类:
getitem(self, index): 根据给定的索引 index,返回对应的样本数据。索引可以是一个整数,表示按顺序获取样本,也可以是其他方式,如通过文件名获取样本等。
len(self): 返回数据集中样本的数量。
import torch
from torch.utils.data import Dataset
class MyDataset(Dataset):
def __init__(self, data):
self.data = data
def __getitem__(self, index):
# 根据索引获取样本
return self.data[index]
def __len__(self):
# 返回数据集大小
return len(self.data)
# 创建数据集对象
data = [1, 2, 3, 4, 5]
dataset = MyDataset(data)
# 根据索引获取样本
sample = dataset[2]
print(sample)
# 3
上面的代码样例主要实现的是一个自定义Dataset数据集类的方法,这一般都是在我们需要训练自己的数据时候需要定义的。但是一般我们作为深度学习初学者来讲,使用的都是MNIST、CIFAR-10等内置数据集,这时候就不需要再自己定义Dataset类了。至于为什么,我们下面进行详解。
2、torchvision.datasets
如果要使用PyTorch中的内置数据集,通常是通过torchvision.datasets模块来实现。torchvision.datasets模块提供了许多常用的计算机视觉数据集,如MNIST、CIFAR10、ImageNet等。
下面是使用内置数据集的示例代码:
import torch
from torchvision import datasets, transforms
# 定义数据转换
transform = transforms.Compose([
transforms.ToTensor(), # 将图像转换为张量
transforms.Normalize((0.5,), (0.5,)) # 标准化图像
])
# 加载MNIST数据集
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
在上述代码中,我们实现的便是一个内置MNIST(手写数字)数据集的加载和使用。可以看到,我们在这里面并未用到上面所提到的torch.utils.data.Dataset类,这是为什么呢?
这是因为在 torchvision.datasets 模块中,内置的数据集类已经实现了torch.utils.data.Dataset 接口,并直接返回一个可用的数据集对象。因此,在使用内置数据集时,我们可以直接实例化内置数据集类,而不需要显式地继承 torch.utils.data.Dataset 类。
内置数据集类(如 torchvision.datasets.MNIST)的实现已经包含了对 __getitem__ 和 __len__ 方法的定义,这使得我们可以直接从内置数据集对象中获取样本和确定数据集的大小。这样,我们在使用内置数据集时可以直接将内置数据集对象传递给 torch.utils.data.DataLoader 进行数据加载和批量处理。
在内置数据集的背后,它们仍然是基于 torch.utils.data.Dataset 类进行实现,只是为了方便使用和提供更多功能,PyTorch 将这些常用数据集封装成了内置的数据集类。
为此,我专门到pytorch官网去查看了该内置数据集的加载代码,如下图所示:
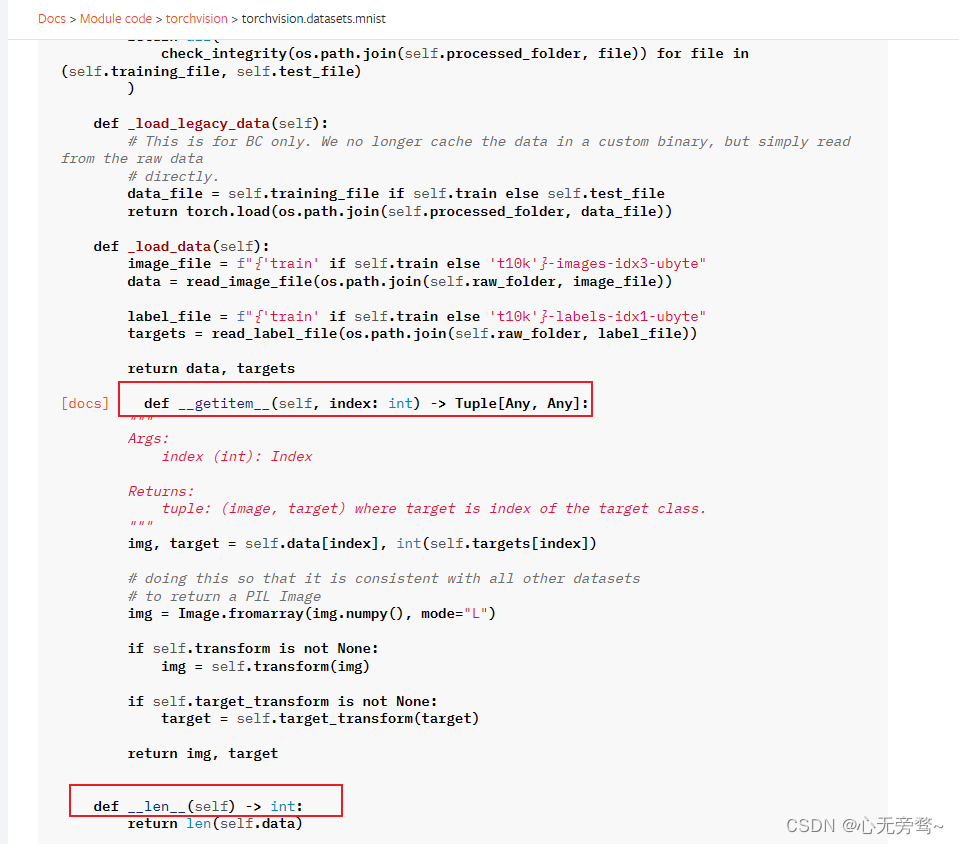
可以看出,确实以及内置了Dataset数据集类。
3、DataLoader
torch.utils.data.DataLoader 是 PyTorch 中用于批量加载数据的工具类。它接受一个数据集对象(如 torch.utils.data.Dataset 的子类)并提供多种功能,如数据加载、批量处理、数据打乱等。
以下是 torch.utils.data.DataLoader 的常用参数和功能:
dataset: 数据集对象,可以是torch.utils.data.Dataset的子类对象。batch_size: 每个批次的样本数量,默认为 1。shuffle: 是否对数据进行打乱,默认为False。在每个 epoch 时会重新打乱数据。num_workers: 使用多少个子进程加载数据,默认为 0,表示在主进程中加载数据。其实在Windows系统里面都设置为0,但是在Linux中可以设置成大于0的数。collate_fn: 在返回批次数据之前,对每个样本进行处理的函数。如果为None,默认使用torch.utils.data._utils.collate.default_collate函数进行处理。drop_last: 是否丢弃最后一个样本数量不足一个批次的数据,默认为False。pin_memory: 是否将加载的数据存放在 CUDA 对应的固定内存中,默认为False。prefetch_factor: 预取因子,用于预取数据到设备,默认为 2。persistent_workers: 如果为True,则在每个 epoch 中使用持久的子进程进行数据加载,默认为False。
示例代码如下:
import torch
from torchvision import datasets, transforms
# 定义数据转换
transform = transforms.Compose([
transforms.ToTensor(), # 将图像转换为张量
transforms.Normalize((0.5,), (0.5,)) # 标准化图像
])
# 加载MNIST数据集
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
# 创建数据加载器
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True, num_workers=4)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=64, shuffle=False, num_workers=4)
# 使用数据加载器迭代样本
for images, labels in train_loader:
# 训练模型的代码
...
4、torchvision.transforms
torchvision.transforms模块是PyTorch中用于图像数据预处理的功能模块。它提供了一系列的转换函数,用于在加载、训练或推断图像数据时进行各种常见的数据变换和增强操作。下面是一些常用的转换函数的详细解释:
-
Resize:调整图像大小
Resize(size):将图像调整为给定的尺寸。可以接受一个整数作为较短边的大小,也可以接受一个元组或列表作为图像的目标大小。
-
ToTensor:将图像转换为张量
ToTensor():将图像转换为张量,像素值范围从0-255映射到0-1。适用于将图像数据传递给深度学习模型。
-
Normalize:标准化图像数据
Normalize(mean, std):对图像数据进行标准化处理。传入的mean和std是用于像素值归一化的均值和标准差。需要注意的是,mean和std需要与之前使用的数据集相对应。
-
RandomHorizontalFlip:随机水平翻转图像
RandomHorizontalFlip(p=0.5):以给定的概率对图像进行随机水平翻转。概率p控制翻转的概率,默认为0.5。
-
RandomCrop:随机裁剪图像
RandomCrop(size, padding=None):随机裁剪图像为给定的尺寸。可以提供一个元组或整数作为目标尺寸,并可选地提供填充值。
-
ColorJitter:颜色调整
ColorJitter(brightness=0, contrast=0, saturation=0, hue=0):随机调整图像的亮度、对比度、饱和度和色调。可以通过设置不同的参数来调整图像的样貌。
在使用的时候,我们常常通过transforms.Compose来对这些数据处理操作进行一个组合,使用的时候,直接调用该组合即可。
示例代码如下:
from torchvision import transforms
# 定义图像预处理操作
transform = transforms.Compose([
transforms.Resize((256, 256)), # 缩放图像大小为 (256, 256)
transforms.RandomCrop((224, 224)), # 随机裁剪图像为 (224, 224)
transforms.RandomHorizontalFlip(), # 随机水平翻转图像
transforms.ToTensor(), # 将图像转换为张量
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 标准化图像
])
# 对图像进行预处理
image = transform(image)