正则表达式(Regular Expression, 缩写常用regex, regexp表示)是计算机科学中的一个概念,很多高级语言都支持正则表达式。
目录
何为正则表达式
语法规则
普通字符
字符转义
限定符
定位符
分组构造
模式匹配
regexp包
MatchString函数
实践时刻
FindStringIndex函数
实践时刻
ReplaceAllString函数
实践时刻
补充资料
校验数字的表达式
校验字符的表达式
特殊需求表达式
工具分享
何为正则表达式
正则表达式是根据一定规则构建而出的规则,用于匹配字符串中子串或字符组合的模式。正则表达式可以通过元符号 + 字符的形式来表示,完成对一系列符合某个语法规则的字符串的匹配。正则表达式的应用在许多软件中都有体现,例如Visual Studio中的查找替换功能、谷歌百度搜索引擎中的搜索字段等。
正则表达式在编程中扮演着十分重要的角色。比如我们要接收处理一个文本输入框中的数据,需要判断文本输入框中的内容是否符合邮箱的格式。此时,便可以通过正则表达式来实现判定匹配(当然,繁长的if else这类语句也可实现,但这便偏离了正则表达式的设计初衷)
语法规则
普通字符
普通字符是正则表达式的基本组成之一,是正则表达式的“基石”。普通字符包括有“可打印字符”、“不可打印字符”,其中“可打印字符”中又包含了大写字母、小写字母、数字、标点符号和其他一些符号。
这里设计一个场景,假设我们需要判断一个字符变量是否是数字,若不考虑使用正则表达式,那么要实现这个判断,我们需要使用下列代码
switch num {
case 1 :
case 2 :
case 3 :
.
.
.
case 0 :
}使用用这类编码方式,效率将会大打折扣。
此时,我们便可以尝试用正则表达式了
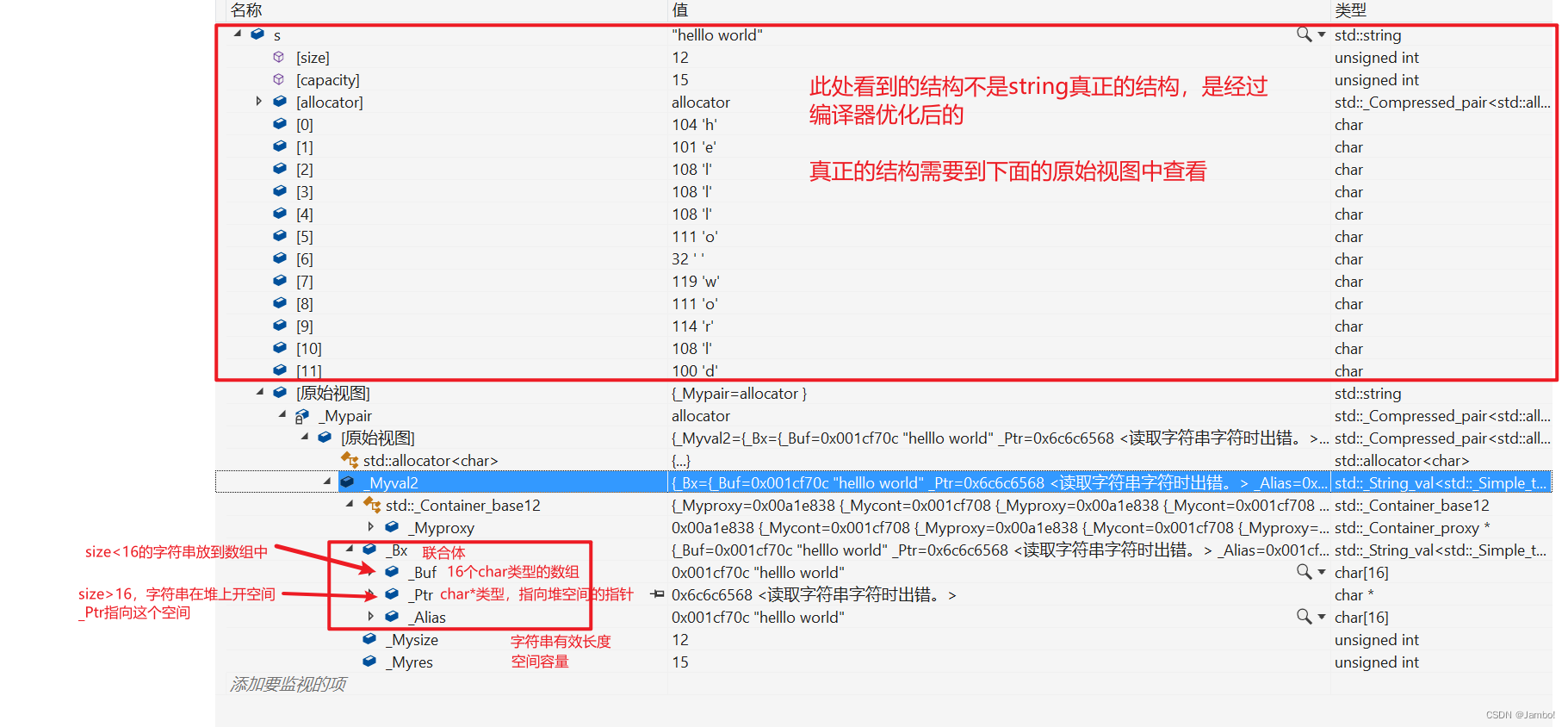
[0123456789]方括号“[]”表示的是一个“字符组”,代表一位字符。方括号中的数字“0123456789”表示只要待匹配的字符串与其中任何一个字符相同,那么程序就会认为匹配成功,反之匹配失败。
如果想表达的数字(ASCII码)是连续的,那么也可以用元字符“-”来对表达式进行简化,见下方:
[0-9]拓展:
ASCII码表

依次类推,当我们想判断一个长度为1的字符串是否是英文小写字母,可以写成:
[a-z]那像表示由大写字母“A”到小写字母"z"呢?这里要注意,我们不能写成 [A-z],观察拓展中的ASCII表,其中在字母“A”和字母"a"之间存在其他字符。
那么正确的表达方式应是
[a-zA-Z]如果要判断长度为2的字符串中是否含有小写字母呢?
[a-z][a-z]当允许的字符范围只有一个时可以省略“[]”。比如,判断输入的是“Hello”还是"hello":
[Hh]ello字符转义
在正则表达式中,有时我们需要使用符号本身的意义,例如之前所用到的字符 ‘-’ ,如果在没进行转义的情况下,它是一个元字符,是一个“功能性”的符号;当我们确实需要表达 ‘-’ 这个符号的本义时,就需要使用反斜杠 ‘\’ 了。例如若要匹配 ‘[’ 符号,则可以表示为:
[\[]如果想匹配“a” “-” “z” 这三个字符,那么便可以用下列表达式:
[0\-9]拓展:
元字符除了 ‘-’ 之外,还有其他的,见下表:
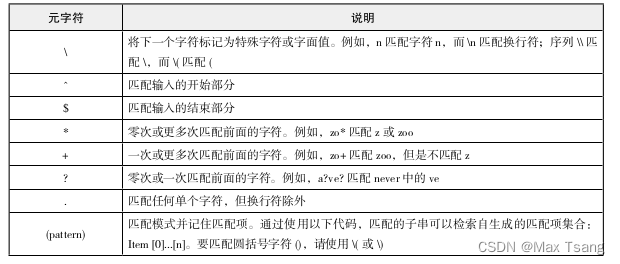
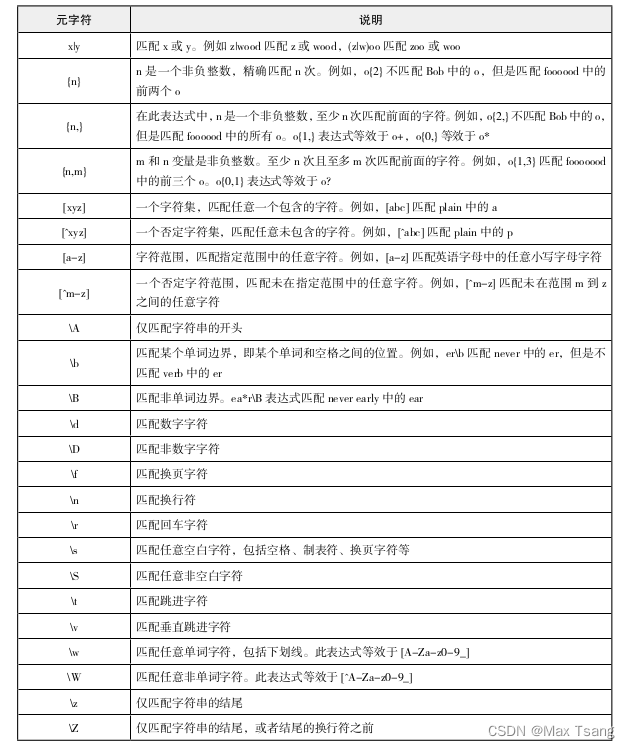
限定符
在上面拓展表格中,有几个重要并且常用的限定符
- {n} : {n}限定符表示匹配上一元素n次,其中n是任意非负整数。例如 a{3} 只能匹配“aaa”;2{4}只能匹配2222;而 \w{5} ,可以匹配任意五位字符,“hello”,"good6",但“helloo”又或“123456”这类未达到字符规定数的皆不可被匹配。
- {n,} : 限定符表示至少匹配上一元素n次,其中n是任意非负整数。例如 “a{3,}” 可以匹配“aaa”也可以匹配“aaaa”。再如 [a-z]{3,} 则可以匹配任意小写字母三位及以上,比如“abc”,"abcde"等。
- {n,m} : 限定符表示至少匹配上一元素n次,但不超过m次,其中n和m为非负整数。比如:a{2,4}可以匹配"a","aa","aaa","aaaa"。同理,“[0-9]{1,10}”表示可以匹配任意一位至十位的数字。
- * : 限定符表示与前面的元素匹配零次或多次,相当于“{0,}”限定符。比如 "ab*c*" 可以匹配 “abaca” "abbcc" "abbcccc" 等。
- + : 限定符表示匹配上一元素一次或多次,相当于 {1,} 限定符。比如 "he\w+" 可以匹配 “hello” 等以“he”开头且字符长度大于等于三的字符串,而“he”本身不能被匹配。
- ? : 限定符表示匹配上一元素零次或一次,相当于{0,1}。比如 "he?"可以匹配"h"和"he",但无法匹配“hello”
定位符
定位符能够对正则表达式进行定位,选取特定位置诸如行首、行尾等进行匹配。
定位符用来描述字符串或单词的边界,“^”和“$”分别指字符串的开始与结束,“\b”描述单词的前、后边界,“\B”表示非单词边界。见如下表格:
- “^” :定位符从字符串的第一个字符位置开始匹配输入。比如 “\d+”可以匹配“abc123”中的"123",“^\d+”则无法匹配“abc123”,但如果用“123abc”,则可完成对“123”的匹配,因为模式匹配是从行首向右开始。
- “$” :匹配输入字符串的结尾位置,与元符号“^”意义相反。举个栗子,依旧是"\d+",可以匹配“123abc”中的123,而“\d+$”则无法匹配“123abc”,只能与“abc123”中“123”匹配,因为模式匹配从行行尾向左开始。
- “\b” :可以匹配单词与空格间的一个边界(注:单词包含 字母、数字、字符、下划线)。比如字符串“ant at hat cat pat ate”,使用正则表达式"\bat\w*\b",可以匹配到“at”和“ate”。
- “\B” :与“\b”定位符意义相反,匹配非单词边界。例如,字符串“hat eating atitude chating”使用正则表达式“\Bat\w+”去匹配,“ating”和“atter”是满足正则表达式的。
分组构造
分组构造用于形成正则表达式的子表达式,能够捕获字符串中的子字符串。采用的结构形式为:
(子表达式)捕获规则按照正则表达式中左括号的顺序从一开始由左向右自动编号。
例如,字符串 “Let us learn GO together!” 我们使用 “(\w+)\s(\w+)\W” 来匹配,结
果则是:
- “Let us ”一组,其中 “Let” 和 “us” 各为一个子组;
- “learn GO ”一组,其中 “learn” 和 “GO” 各为一个子组;
模式匹配
匹配模式指的是匹配时使用的规则。使用不同的匹配模式能够改变正则表达式的识别规则,也可能会改变正则表达式中字符的匹配规则。
在这里,介绍三种常见的模式,具体可以查阅相关资料了解
- 不区分大小写模式
- 单行模式
- 多行模式
regexp包
Go提供regexp包来处理正则表达式,能够实现基于正则表达式的查找、替换和模式匹配功能。
MatchString函数
MarchString 函数接收一个欲查找的正则表达式和目标字符串,根据匹配结果返回true或false。
函数定义如下:
func MatchString(pattern string, s string) (matched bool, err error)实践时刻
/*
------------------------------------------------------------------------------
- @FILE regex_match.go
- @AUTHOR MAX TSANG
- @EMAIL ZIHANTSANG@HOTMAIL.COM
- @DATE 2023-08-18 22:37:48
- @BRIEF MATCHSTRING
------------------------------------------------------------------------------
*/
package main
import (
"regexp"
"fmt"
)
func main() {
targetStr := "hello Golang"
matchStr := "Golang"
match , err := regexp.MatchString(matchStr,targetStr)
if err != nil{
fmt.Println(err)
}
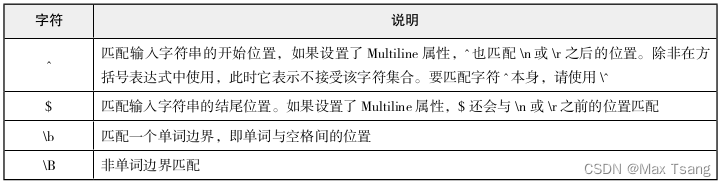
fmt.Println(match)
}输出结果:
但如果我们将目标字符串matchStr中的首字母改为小写(golang),匹配将失败,因为正则表达式默认区分大小写。
如果想以不区分大小写的模式进行匹配,那么需要修改正则表达式,见下方:
matchString := "(?i)golang"在欲进行匹配的子串前加上 (?i) 即可。
FindStringIndex函数
FindStringIndex 函数接收一个目标字符串,并返回第一个匹配的起始位置和结束位置。
函数定义如下:
func (re *Regexp) FindStringIndex(s string) (loc []int)FindStringIndex函数是Regexp结构体的成员函数,需要使用Compile或MustCompile函数进行编译。
- Compile函数:若正则表达式未通过编译,则返回错误。
- MustCompile函数:若正则表达式未通过编译,则引发panic。
实践时刻
/*
------------------------------------------------------------------------------
- @FILE regexp_findindex.go
- @AUTHOR MAX TSANG
- @EMAIL ZIHANTSANG@HOTMAIL.COM
- @DATE 2023-08-18 22:39:14
- @BRIEF FINDINEXBYREGEX
------------------------------------------------------------------------------
*/
package main
import (
"fmt"
"regexp"
)
func main() {
targetStr := "hello golang"
re := regexp.MustCompile(`(\w)+`)
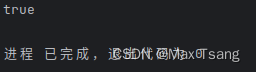
res := re.FindStringIndex(targetStr)
fmt.Println(res)
}
输出结果:
ReplaceAllString函数
ReplaceAllString 函数返回第一个参数的拷贝,将第一个参数中所有re的匹配结果都替换为
repl。
函数定义如下:
func (re *Regexp) ReplaceAllString(src, repl string) string实践时刻
/*
------------------------------------------------------------------------------
- @FILE regexp_replace.go
- @AUTHOR MAX TSANG
- @EMAIL ZIHANTSANG@HOTMAIL.COM
- @DATE 2023-08-18 22:49:42
- @BRIEF REPLACESTRINGBYREGEX
------------------------------------------------------------------------------
*/
package main
import (
"fmt"
"regexp"
)
func regexp_replace() {
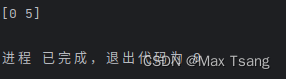
targetStr := "hello golang"
re := regexp.MustCompile(`o`)
res := re.ReplaceAllString(targetStr,"O")
fmt.Println(res)
}
输出结果:
补充资料
常用正则表达式
校验数字的表达式
- 数字:^[0-9]*$
- n位的数字:^\d{n}$
- 至少n位的数字:^\d{n,}$
- m-n位的数字:^\d{m,n}$
- 零和非零开头的数字:^(0|[1-9][0-9]*)$
- 非零开头的最多带两位小数的数字:^([1-9][0-9]*)+(\.[0-9]{1,2})?$
- 带1-2位小数的正数或负数:^(\-)?\d+(\.\d{1,2})$
- 正数、负数、和小数:^(\-|\+)?\d+(\.\d+)?$
- 有两位小数的正实数:^[0-9]+(\.[0-9]{2})?$
- 有1~3位小数的正实数:^[0-9]+(\.[0-9]{1,3})?$
- 非零的正整数:^[1-9]\d*$ 或 ^([1-9][0-9]*){1,3}$ 或 ^\+?[1-9][0-9]*$
- 非零的负整数:^\-[1-9][]0-9"*$ 或 ^-[1-9]\d*$
- 非负整数:^\d+$ 或 ^[1-9]\d*|0$
- 非正整数:^-[1-9]\d*|0$ 或 ^((-\d+)|(0+))$
- 非负浮点数:^\d+(\.\d+)?$ 或 ^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$
- 非正浮点数:^((-\d+(\.\d+)?)|(0+(\.0+)?))$ 或 ^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$
- 正浮点数:^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$ 或 ^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$
- 负浮点数:^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ 或 ^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$
- 浮点数:^(-?\d+)(\.\d+)?$ 或 ^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$
校验字符的表达式
- 汉字:^[\u4e00-\u9fa5]{0,}$
- 英文和数字:^[A-Za-z0-9]+$ 或 ^[A-Za-z0-9]{4,40}$
- 长度为3-20的所有字符:^.{3,20}$
- 由26个英文字母组成的字符串:^[A-Za-z]+$
- 由26个大写英文字母组成的字符串:^[A-Z]+$
- 由26个小写英文字母组成的字符串:^[a-z]+$
- 由数字和26个英文字母组成的字符串:^[A-Za-z0-9]+$
- 由数字、26个英文字母或者下划线组成的字符串:^\w+$ 或 ^\w{3,20}$
- 中文、英文、数字包括下划线:^[\u4E00-\u9FA5A-Za-z0-9_]+$
- 中文、英文、数字但不包括下划线等符号:^[\u4E00-\u9FA5A-Za-z0-9]+$ 或 ^[\u4E00-\u9FA5A-Za-z0-9]{2,20}$
- 可以输入含有^%&',;=?$\"等字符:[^%&',;=?$\x22]+
- 禁止输入含有~的字符:[^~]+
特殊需求表达式
- Email地址:^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$
- 域名:[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(\.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+\.?
- InternetURL:[a-zA-z]+://[^\s]* 或 ^http://([\w-]+\.)+[\w-]+(/[\w-./?%&=]*)?$
- 手机号码:^(13[0-9]|14[01456879]|15[0-35-9]|16[2567]|17[0-8]|18[0-9]|19[0-35-9])\d{8}$
- 电话号码("XXX-XXXXXXX"、"XXXX-XXXXXXXX"、"XXX-XXXXXXX"、"XXX-XXXXXXXX"、"XXXXXXX"和"XXXXXXXX):^(\(\d{3,4}-)|\d{3.4}-)?\d{7,8}$
- 国内电话号码(0511-4405222、021-87888822):\d{3}-\d{8}|\d{4}-\d{7}
- 电话号码正则表达式(支持手机号码,3-4位区号,7-8位直播号码,1-4位分机号): ((\d{11})|^((\d{7,8})|(\d{4}|\d{3})-(\d{7,8})|(\d{4}|\d{3})-(\d{7,8})-(\d{4}|\d{3}|\d{2}|\d{1})|(\d{7,8})-(\d{4}|\d{3}|\d{2}|\d{1}))$)
- 身份证号(15位、18位数字),最后一位是校验位,可能为数字或字符X:(^\d{15}$)|(^\d{18}$)|(^\d{17}(\d|X|x)$)
- 帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
- 密码(以字母开头,长度在6~18之间,只能包含字母、数字和下划线):^[a-zA-Z]\w{5,17}$
- 强密码(必须包含大小写字母和数字的组合,不能使用特殊字符,长度在 8-10 之间):^(?=.*\d)(?=.*[a-z])(?=.*[A-Z])[a-zA-Z0-9]{8,10}$
- 强密码(必须包含大小写字母和数字的组合,可以使用特殊字符,长度在8-10之间):^(?=.*\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$
- 日期格式:^\d{4}-\d{1,2}-\d{1,2}
- 一年的12个月(01~09和1~12):^(0?[1-9]|1[0-2])$
- 一个月的31天(01~09和1~31):^((0?[1-9])|((1|2)[0-9])|30|31)$
- 钱的输入格式:
- 有四种钱的表示形式我们可以接受:"10000.00" 和 "10,000.00", 和没有 "分" 的 "10000" 和 "10,000":^[1-9][0-9]*$
- 这表示任意一个不以0开头的数字,但是,这也意味着一个字符"0"不通过,所以我们采用下面的形式:^(0|[1-9][0-9]*)$
- 一个0或者一个不以0开头的数字.我们还可以允许开头有一个负号:^(0|-?[1-9][0-9]*)$
- 这表示一个0或者一个可能为负的开头不为0的数字.让用户以0开头好了.把负号的也去掉,因为钱总不能是负的吧。下面我们要加的是说明可能的小数部分:^[0-9]+(.[0-9]+)?$
- 必须说明的是,小数点后面至少应该有1位数,所以"10."是不通过的,但是 "10" 和 "10.2" 是通过的:^[0-9]+(.[0-9]{2})?$
- 这样我们规定小数点后面必须有两位,如果你认为太苛刻了,可以这样:^[0-9]+(.[0-9]{1,2})?$
- 这样就允许用户只写一位小数.下面我们该考虑数字中的逗号了,我们可以这样:^[0-9]{1,3}(,[0-9]{3})*(.[0-9]{1,2})?$
- 1到3个数字,后面跟着任意个 逗号+3个数字,逗号成为可选,而不是必须:^([0-9]+|[0-9]{1,3}(,[0-9]{3})*)(.[0-9]{1,2})?$
- 备注:这就是最终结果了,别忘了"+"可以用"*"替代如果你觉得空字符串也可以接受的话(奇怪,为什么?)最后,别忘了在用函数时去掉去掉那个反斜杠,一般的错误都在这里
- xml文件:^([a-zA-Z]+-?)+[a-zA-Z0-9]+\\.[x|X][m|M][l|L]$
- 中文字符的正则表达式:[\u4e00-\u9fa5]
- 双字节字符:[^\x00-\xff] (包括汉字在内,可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1))
- 空白行的正则表达式:\n\s*\r (可以用来删除空白行)
- HTML标记的正则表达式:<(\S*?)[^>]*>.*?|<.*? /> ( 首尾空白字符的正则表达式:^\s*|\s*$或(^\s*)|(\s*$) (可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式)
- 腾讯QQ号:[1-9][0-9]{4,} (腾讯QQ号从10000开始)
- 中国邮政编码:[1-9]\d{5}(?!\d) (中国邮政编码为6位数字)
- IPv4地址:((2(5[0-5]|[0-4]\d))|[0-1]?\d{1,2})(\.((2(5[0-5]|[0-4]\d))|[0-1]?\d{1,2})){3}
工具分享
在线正则表达式可视化工具正则表达式可视化工具![]() https://c.runoob.com/front-end/7625/#!flags=&re=%5E(a%7Cb)*%3F%24
https://c.runoob.com/front-end/7625/#!flags=&re=%5E(a%7Cb)*%3F%24