阿拉伯语是互联网上第四大最常用的语言,它在社交媒体上的日益增加为大规模研究阿拉伯语在线社区提供了充足的资源。然而,目前很少有工具可以从这些数据中获得有价值的见解,用于决策、指导政策、协助应对等。这种情况即将改变吗?
自然语言处理(NLP)系统的性能在阅读理解和自然语言推理等任务上得到了显着提高,并且随着这些进步,该技术出现了许多新的应用场景。 不出所料,英语是大多数NLP研发的重点。现在,来自加拿大不列颠哥伦比亚大学自然语言处理实验室的一组研究人员提出了AraNet,这是一个专为阿拉伯语社交媒体处理而设计的深度学习工具包。
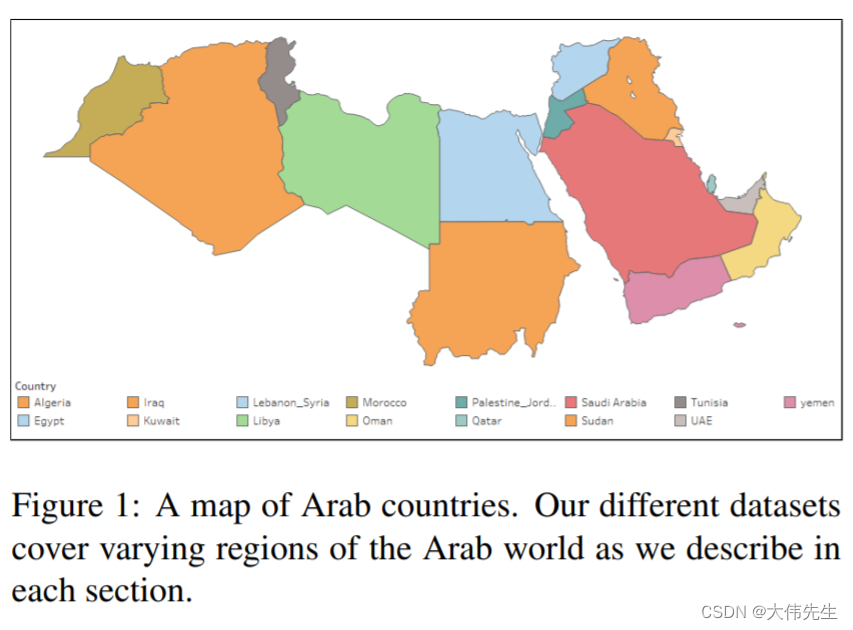
AraNet 包括标识符工具,可以从社交媒体文本中预测年龄、方言、性别、情感、讽刺、情绪等。AraNet建立在Google新的BERT-Base多语言外壳模型的框架之上,该模型经过104种语言(包括阿拉伯语)的训练,并被BERT团队推荐用于这项工作。
基于神经网络的NLP预训练技术可以很容易地在大量的句子级和令牌级任务上进行微调。这些特征满足了研究人员利用大量可访问的社交媒体数据集(主要来自Twitter)来相应地训练模型的需求。只有用于情绪分析的数据集不同。
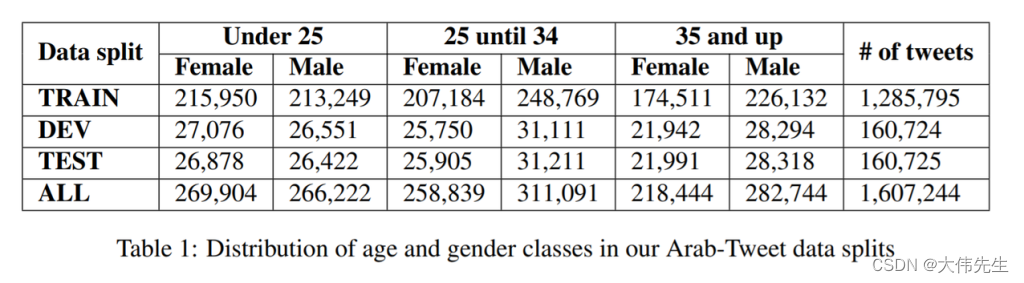
例如,为了训练模型来预测年龄和性别,研究人员采用了两个数据集。大型多方言语料库Arap Tweet收录了来自阿拉伯世界11个地区和16个国家的推文,代表了广泛的阿拉伯语方言。研究人员还创建了自己的推特性别数据集,收集了来自21个阿拉伯语国家的528名男性用户的69509条推文和528名女性用户的67511条推文。
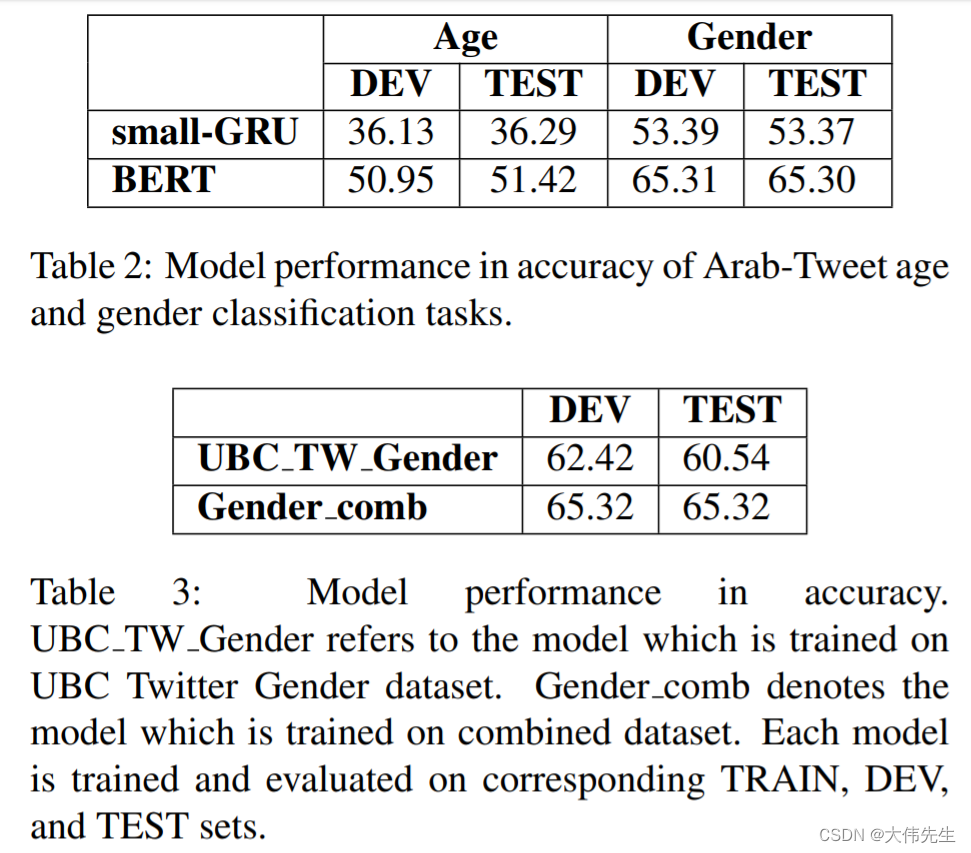
为了进行情感分析,研究人员使用了15个包含MSA(现代标准阿拉伯语)和各种区域方言的数据集。尽管数据集涉及不同类型的情感分析任务,例如二元分类,三向分类或主观语言检测,但研究人员将它们结合起来进行二元情感分类。
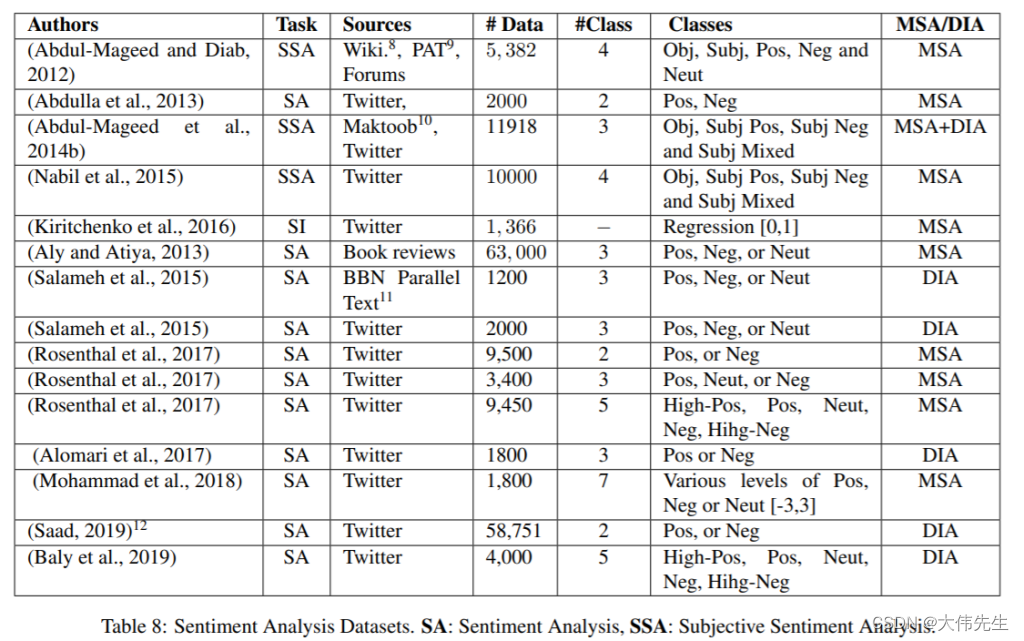
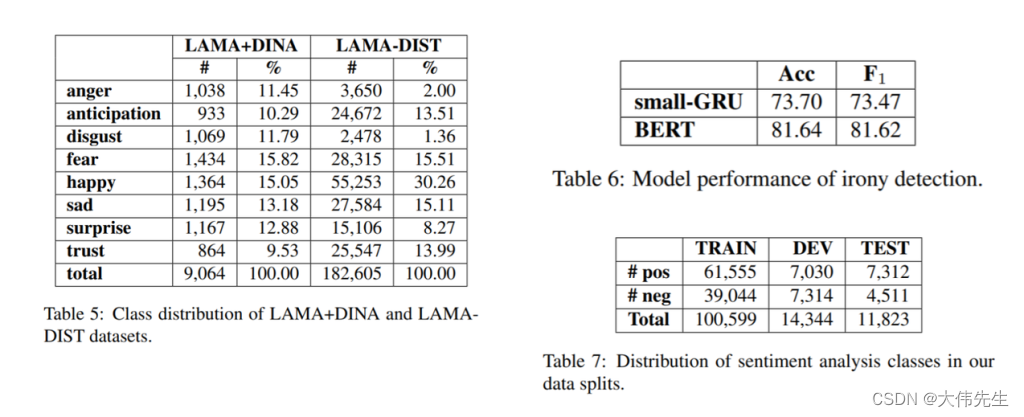
研究人员没有明确地将他们某些任务的基线模型与以前的研究进行比较,并解释说“大多数现有工作要么利用较小的数据(因此这不是一个公平的比较),要么使用早于BERT的方法(因此可能会被我们的模型超越)。
相信AraNet基于BERT模型的统一框架将使未来的研究能够更轻松地实现针对阿拉伯社交媒体的各种NLP任务,并产生有见地的观察结果。更重要的是,研究人员希望该工具包可以为提高对当代阿拉伯语在线社区的理解提供门户。
尽管阿拉伯语NLP语言的复杂性和其他挑战仍然存在,但该项目有望为这一研究领域带来额外的学术关注和进步。
论文AraNet:阿拉伯语社交媒体的深度学习工具包发表在arXiv上。

![[gdc23]《战神:诸神黄昏》中的积雪系统](https://img-blog.csdnimg.cn/cce8f9658b7b418aaced96ad50a66d16.png)