文章目录
- 1、前言
- 2、简介
- 2.1、STL是什么?
- 2.2、STL能干什么?
- 2.3、STL组成
- 3、容器
- 3.1、顺序容器
- 3.2、排序容器(关联式容器)
- 3.3、哈希容器
- 3.4、容器适配器
- 3、迭代器
- 3.1、迭代器介绍
- 3.2、迭代器定义方式
- 3.3、迭代器类别
- 3.4、辅助函数
- 4、算法
- 5、总结
============================ 【说明】 ===================================================
大家好,本专栏主要是跟学C++内容,自己学习了这位博主【 AI菌】的【C++21天养成计划】,讲的十分清晰,适合小白,希望给这位博主多点关注、收藏、点赞。
主要针对所学内容,通过自己的理解进行整理,希望大家积极交流、探讨,多给意见。后面也会给大家更新,其他一些知识。若有侵权,联系删除!共同维护网络知识权利!
=======================================================================================
1、前言
该专栏也即将接近尾声,👉本专栏涉及最多的还是STL内容。那STL是什么,有什么用,STL又要学习哪些知识呢? 下面就简答介绍一下STL以及相关知识点,更多关于STL内容,后期会专门开一个专栏讲解STL,欢迎大家及时关注。本专栏关于C++以及STL知识适用入门,初步了解即可。
2、简介
2.1、STL是什么?
STL(Standard Template Library),即标准模板库或者泛型库,包含了有量的模板类和模板函数,是 C++ 提供的一个基础模板的集合,用于完成包括输入/输出、数学计算等众多功能。
现在 STL 已完全被内置到支持 C++ 的编译器中,无需额外安装,这可能也是 STL 被广泛使用的原因之一。STL 就位于各个 C++ 的头文件中,并非以二进制代码的形式提供,而是以源代码的形式提供。
从根本上说,STL 是一些容器、算法和其他一些组件的集合,所有容器和算法都是总结了几十年来算法和数据结构的研究成果,可以说,STL 基本上达到了各种存储方法和相关算法的高度优化。
2.2、STL能干什么?
至于STL能干什么这个问题,我们可以用一个简单的案例来形象理解。我们在定义数组的时候,最简单的方式:
int arr[n];
这种定义数组的方法需要事先确定好数组的长度,即 n 必须为常量,在实际应用中无法确定数组长度,一般会将数组长度设为可能的最大值,但这极有可能导致存储空间的浪费。
那另一种定义方式就是堆空间中动态申请内存的方法,不会造成空间浪费,此时长度可以是变量:
int *arr1 = new int[n];
如果程序执行过程中出现空间不足的情况时,则需要加大存储空间,一般会这样操作:
//申请一个较大的内存空间
int * temp = new int[m];
//将原内存空间的数据全部复制到新申请的内存空间中
memecpy(temp, arr1, sizeof(int)*n);
//将原来的堆空间释放
delete [] arr1;
arr1 = temp;
STL的作用就来了,会简单很多。
vector <int> a; //定义 a 数组,当前数组长度为 0,但和普通数组不同的是,此数组 a 可以根据存储数据的数量自动变长。
//向数组 a 中添加 10 个元素
for (int i = 0; i < 10 ; i++)
a.push_back(i)
//还可以手动调整数组 a 的大小
a.resize(100);
a[90] = 100;
//还可以直接删除数组 a 中所有的元素,此时 a 的长度变为 0
a.clear();
//重新调整 a 的大小为 20,并存储 20 个 -1 元素。
a.resize(20, -1)
对比以上两种使用数组的方式不难看出,使用 STL 可以更加方便灵活地处理数据,有需要的可以系统学习STL相关代码。
2.3、STL组成
STL 是由容器、算法、迭代器、函数对象、适配器、内存分配器这 6 部分构成,其中后面 4 部分是为前 2 部分服务的,比较核心的还是本章的主题:容器/迭代器/算法。
通过下表,我们快速了解下每个组成的主要含义:
| 构成 | 注释 |
|---|---|
| 容器 | 封装好的数据结构模板类;如 vector 向量容器、list 列表容器等。 |
| 算法 | STL 提供了约 100 个的数据结构算法,都是一个个模板函数。这些算法在 std 命名空间中定义,其中大部分算法都包含在头文件 <algorithm> 中,少部分位于头文件 <numeric> 中。 |
| 迭代器 | 迭代器是容器和算法的桥梁,能无缝地将容器与STL算法连接起来;容器中数据的读和写,是通过迭代器完成的。 |
| 函数对象 | 如果一个类将 () 运算符重载为成员函数,这个类就称为函数对象类,这个类的对象就是函数对象(又称仿函数)。 |
| 适配器 | 可以将一个类的接口(模板的参数)适配成用户指定的形式,让原本不能在一起工作的两个类工作在一起。容器、迭代器和函数都有适配器。 |
| 内存分配器 | 为容器类模板提供自定义的内存申请和释放功能,内存分配器一般来说,不常用。 |
STL原本被组成 48 个头文件;在 C++ 标准中,被重新组织为 13 个头文件:
| 头文件 | 注释 |
|---|---|
<iterator> | 迭代器头文件 |
<functional> | 用于表示函数对象的类模板 |
<vector> | 向量容器 |
<deque> | 双端队列容器,序列式容器,或理解为动态数组类 |
<list> | 列表容器 |
<queue> | 队列容器 |
<stack> | 栈容器 |
<map> | 键—值对容器 |
<algorithm> | 标准算法库,主要应用在容器上 |
<numeric> | 包含了一系列可用于操作数值序列的函数,可以方便地对例如vector,list等容器进行数值计算 |
<memory> | 用于管理动态内存 |
<utility> | 通用工具库,其他函数归它所有 |
下面主要介绍三大件:容器、迭代器、算法。其他内容,后续会专门写一个关于STL的专栏,欢迎大家及时关注。
3、容器
简单的理解容器,它就是一些模板类的集合,但和普通模板类不同的是,容器中封装的是组织数据的方法(也就是数据结构)。通俗来讲,容器就是用于存储数据的STL类。好比用来乘放菜品的锅碗一样,它是用来制作美味佳肴的必需品。
STL 提供有 3 类标准容器,分别是:(顺序)序列容器、排序容器和哈希容器,其中后两类容器有时也统称为关联容器。可以把它分为2类,即(顺序)序列容器和关联容器:
| 容器 | 注释 |
|---|---|
| (顺序)序列容器 | 按顺序存储数据,以线性排列(类似普通数组的存储方式)来存储某一指定类型(例如 int、double 等)的数据,需要特殊说明的是,该类容器并不会自动对存储的元素按照值的大小进行排序 |
| 排序容器(关联式容器) | 属于关联容器,关联容器按指定的顺序存储数据,就像词典一样,关联容器在查找时具有非常好的性能。排序容器中的元素默认是由小到大排序好的,即便是插入元素,元素也会插入到适当位置这将降低插入数据的速度,但在查询方面有很大的优势。 |
| 哈希容器 | 属于关联容器,和排序容器不同,哈希容器中的元素是未排序的,元素的位置由哈希函数确定。 |
3.1、顺序容器
常见的 (顺序)序列容器如下:
| 容器 | 注释 |
|---|---|
array<T,N>(数组容器) | 表示可以存储 N 个 T 类型的元素;该容器一旦建立,其长度就是固定不变的,这意味着不能增加或删除元素,只能改变某个元素的值 |
vector<T>(向量容器) | 用来存放 T 类型的元素,是一个长度可变的序列容器,即在存储空间不足时,会自动申请更多的内存;在尾部增加或删除元素的效率最高,在其它位置插入或删除元素效率较差,类似数据结构中顺序表特点 |
deque<T>(双端队列容器) | 和 vector 非常相似,区别在于使用该容器不仅尾部插入和删除元素高效,在头部插入或删除元素也同样高效,但是在容器中某一位置处插入或删除元素,时间复杂度为 O(n) |
list<T>(链表容器) | 是一个长度可变的、由 T 类型元素组成的序列,它以双向链表的形式组织元素,在这个序列的任何地方都可以高效地增加或删除元素,但访问容器中任意元素的速度要比前三种容器慢,这是因为 list 必须从第一个元素或最后一个元素开始访问,需要沿着链表移动,直到到达想要的元素 |
forward_list<T>(正向链表容器) | 和 list 容器非常类似,只不过它以单链表的形式组织元素,它内部的元素只能从第一个元素开始访问,是一类比链表容器快、更节省内存的容器 |
顺序容器一般都具有插入速度快,但查找操作相对较慢的特点。不同的容器,各自优缺点如下:
| 容器 | 优点 | 缺点 |
|---|---|---|
array<T,N>(数组容器) | 简单方便 | 长度固定不变的,不能增加或删除元素,只能改变某个元素的值 |
vector<T>(向量容器) | 在末尾插入和删除数据时速度快,时间固定 | 在中间插入或删除数据时,后面元素的位置都需要往前挪,查找操作时间复杂度为O(n),只能在末尾插入数据 |
deque<T>(双端队列容器) | 与std::vector类似,区别是允许在数组开头插入或删除元素 | 与vector缺点相同 |
list<T>(链表容器) | 任意位置插入或删除元素,所需时间是固定的; | 不能像数组一样根据索引随机访问元素;搜索速度比vector慢,因为元素没有存储在连续的内存中;查找操作时间复杂度O(n) |
关于顺序容器的相关详细介绍,可以转至本专栏以下博客:
【跟学C++】C++链表——List类(Study11)
【跟学C++】C++动态数组——vector/deque类(Study14)
3.2、排序容器(关联式容器)
关联容器按指定的顺序存储数据,就像词典一样。降低了插入数据的速度,但在查询方面有很大的优势。C++ STL 标准库提供了 4 种关联式容器,分别为 map、set、multimap、multiset:
| 容器 | 注释 |
|---|---|
map | 定义在 <map> 头文件中,使用该容器存储的数据,其各个元素的键必须是唯一的(即不能重复),该容器会根据各元素键的大小,默认进行升序排序(调用 std::less<T>)。 |
set | 定义在 <set> 头文件中,使用该容器存储的数据,各个元素键和值完全相同,且各个元素的值不能重复(保证了各元素键的唯一性)。该容器会自动根据各个元素的键(其实也就是元素值)的大小进行升序排序(调用 std::less<T>)。 |
multimap | 定义在 <map> 头文件中,和 map 容器唯一的不同在于,multimap 容器中存储元素的键可以重复。 |
multiset | 定义在 <set> 头文件中,和 set 容器唯一的不同在于,multiset 容器中存储元素的值可以重复(一旦值重复,则意味着键也是重复的)。 |
关联容器按指定的顺序存储数据,就像词典一样。这将降低插入数据的速度,但在查询方面有很大的优势。不同的容器,各自优缺点如下:
| 容器 | 优点 | 缺点 |
|---|---|---|
map | 存储键-值对,查找速度快 | 在插入元素(键-值对)时进行排序,所以插入速度比顺序容器慢 |
set | 查找操作速度快 | 元素的插入速度比顺序容器慢,因为在插入时要对元素进行排序 |
multimap | 与map类似,键可不唯一 | 在插入元素(键-值对)时进行排序,插入速度比顺序容器慢 |
multiset | 与set类似,元素可不唯一 | 元素的插入速度比顺序容器慢,插入时要对元素进行排序 |
关于排序容器(关联式容器)的相关详细介绍,可以转至本专栏以下博客:
【跟学C++】C++集合——set/multiset类(Study16)
【跟学C++】C++映射类——map/multimap类(Study17)
3.3、哈希容器
有“特殊”的关联式容器,称为“无序容器”,也叫“哈希容器”或者“无序关联容器”。
注意,无序容器是 C++ 11 标准才正式引入到 STL 标准库中的,如果要使用该类容器,则必须选择支持 C++ 11 标准的编译器。
和关联式容器一样,无序容器也使用键值对的方式存储数据。不过,本文将二者分开进行讲解,因为它们有本质上的不同:
(1) 关联式容器的底层实现采用的树存储结构,更确切的说是红黑树结构。 👉红黑树与平衡二叉树区别;
(2) 无序容器的底层实现采用的是哈希表的存储结构。 关注此专栏👉数据结构了解更多数据结构知识。
C++ STL 底层采用哈希表实现无序容器时,会将所有数据存储到一整块连续的内存空间中,并且当数据存储位置发生冲突时,解决方法选用的是“链地址法”(又称“开链法”)。
有关哈希表存储结构,可阅读我正在更新的专栏【数据结构】详细了解。
基于底层实现采用了不同的数据结构,因此和关联式容器相比,无序容器具有以下 2 个特点:
(1) 无序容器内部存储的键值对是无序的,各键值对的存储位置取决于该键值对中的键,
(2) 和关联式容器相比,无序容器擅长通过指定键查找对应的值;但对于使用迭代器遍历容器中存储的元素,无序容器的执行效率则不如关联式容器。
C++ STL 标准库提供了 4 种无序关联式容器,分别为 unordered_map、unordered_multimap、unordered_set 以及 unordered_multiset:
| 容器 | 注释 |
|---|---|
unordered_map | 存储键值对 <key, value> 类型的元素,其中各个键值对键的值不允许重复,且该容器中存储的键值对是无序的。 |
unordered_multimap | 和 unordered_map 唯一的区别在于,该容器允许存储多个键相同的键值对。 |
unordered_set | 直接存储数据元素本身(可以理解为:该容器存储的全部都是键 key 和值 value 相等的键值对,正因为它们相等,因此只存储 value 即可)。另外,该容器存储的元素不能重复,且容器内部存储的元素也是无序的。 |
unordered_multiset | 和 unordered_set 唯一的区别在于,该容器允许存储值相同的元素。 |
不同的容器,各自优缺点如下:
| 容器 | 优点 | 缺点 |
|---|---|---|
unordered_map | 查找、插入和删除操作的速度几乎不受容器包含元素个数的影响 | 元素未被严格排序,不适合用于顺序很重要的情形 |
unordered_multimap | 查找、插入和删除操作的速度几乎不受容器包含元素个数的影响;同时不要求键是唯一的 | 元素未被严格排序,不适合用于顺序很重要的情形 |
unordered_set | 查找、插入和删除操作的速度几乎不受容器包含元素个数的影响 | 由于元素未被严格排序,不能依赖元素在容器中的相对位置 |
unordered_multiset | 与unordered_set类似,元素可不唯一 | 由于元素未被严格排序,不能依赖元素在容器中的相对位置 |
关于哈希容器(无序关联式容器)的相关详细介绍,可以转至本专栏以下博客:
【跟学C++】C++集合——set/multiset类(Study16)
【跟学C++】C++映射类——map/multimap类(Study17)
3.4、容器适配器
容器适配器给人感觉是适配器,其实容器适配器是顺序容器和关联容器的变种。它的功能有限,用于满足特定的需求,容器适配器本质上还是容器,只不过此容器模板类的实现,利用了大量其它基础容器模板类中已经写好的成员函数。当然,如果必要的话,容器适配器中也可以自创新的成员函数。通过一个通俗案例,了解什么是容器适配器?
容器适配器中的“适配器”,和生活中常见的电源适配器中“适配器”的含义非常接近。我们知道,无论是电脑、手机还是其它电器,充电时都无法直接使用 220V 的交流电,为了方便用户使用,各个电器厂商都会提供一个适用于自己产品的电源线,它可以将 220V 的交流电转换成适合电器使用的低压直流电。从我们用户的角度看,电源线扮演的角色就是将原本不适用的交流电变得适用,因此其又被称为电源适配器。
再如下面这个案例:
定义一个A类:
class A{
public:
void f1(){}
void f2(){}
void f3(){}
void f4(){}
};
需求是:设计一个模板 B,其实只需要组合一下模块 A 中的 f1()、f2()、f3(),就可以实现模板 B 需要的功能。其中 f1() 单独使用即可,而 f2() 和 f3() 需要组合起来使用。我们可以:
class B{
private:
A * a;
public:
void g1(){
a->f1();
}
void g2(){
a->f2();
a->f3();
}
};
可以看到,就如同是电源适配器将不适用的交流电变得适用一样,模板 B 将不适合直接拿来用的模板 A 变得适用了,因此我们可以将模板 B 称为 B 适配器。
容器适配器也是同样的道理,简单的理解容器适配器,其就是将不适用的序列式容器(包括 vector、deque 和 list)变得适用。容器适配器的底层实现和模板 A、B 的关系是完全相同的,即通过封装某个序列式容器,并重新组合该容器中包含的成员函数,使其满足某些特定场景的需要。
主要的容器适配器有3种,分别是 stack、queue、priority_queue:
| 容器 | 注释 |
|---|---|
stack<T> | 是一个封装了 deque<T> 容器的适配器类模板,默认实现的是一个先进后先出的栈。stack<T> 模板定义在头文件 stack 中。 |
queue<T> | 是一个封装了 deque<T> 容器的适配器类模板,默认实现的是一个先入先出的队列。可以为它指定一个符合确定条件的基础容器。queue<T> 模板定义在头文件 queue 中。 |
priority_queue<T> | 是一个封装了 vector<T> 容器的适配器类模板,默认实现的是一个会对元素排序,从而保证最大元素总在队列最前面的队列。priority_queue<T> 模板定义在头文件 queue 中。 |
其实,从功能上讲,线性表可以替代栈或队列。但是线性表的操作过于灵活,这意味着,它们过多暴露了可操作的接口。这些没有意义的接口过多,当数据量很大的时候就会出现一些隐藏的风险。
适配器类在基础序列容器的基础上实现了一些自己的操作,显然也可以添加一些自己的操作。它们提供的优势是简化了公共接口,而且提高了代码的可读性。所以虽然栈和队列限定降低了操作的灵活性,但也使得增删数据时,安全性和时效性更高。
关于容器适配器的相关详细介绍,可以转至本专栏以下博客:
【跟学C++】C++栈——Stack类(Study12)
【跟学C++】C++队列——queue类(Study13)
关于栈和队列的相关详细介绍,可以转至此专栏👉数据结构以下博客:
【数据结构与算法】——第三章:栈
【数据结构与算法】——第四章:队列
3、迭代器
3.1、迭代器介绍
无论是序列容器还是关联容器,常用操作就是遍历容器中存储的元素,但实现此操作,多数情况会选用迭代器(iterator)来实现。那么,迭代器是什么呢?
要访问顺序容器和关联容器中的元素,需要通过迭代器(iterator) 进行。 迭代器是容器和操纵容器的算法之间的中介。它可以指向容器中的某个元素,通过迭代器也可以读写它指向的元素。简单来说:迭代器和指针类似,可以是需要的任意类型,通过迭代器可以指向容器中的某个元素,如果需要,还可以对该元素进行读/写操作。
3.2、迭代器定义方式
不同容器对应不同的迭代器,但是迭代器有着较为统一的定义方式:
| 迭代器定义方式 | 格式 |
|---|---|
| 正向迭代器 | 容器名::interaor 迭代器名; |
| 常量正向迭代器 | 容器名::const_interaor 迭代器名; |
| 反向迭代器 | 容器名::reverse_interaor 迭代器名; |
| 常量反向迭代器 | 容器名::const_reverse_interaor 迭代器名; |
通过定义以上几种迭代器,就可以读取它指向的元素,*迭代器名就表示迭代器指向的元素。
其中,常量迭代器和非常量迭代器的区别在于:通过非常量迭代器还能修改其指向的元素;
另外,反向迭代器和正向迭代器的区别在于:
对正向迭代器进行 ++ 操作时,迭代器会指向容器中的后一个元素;
对反向迭代器进行 ++ 操作时,迭代器会指向容器中的前一个元素。
注意:以上 4 种定义迭代器的方式,并不是每个容器都适用。有一部分容器同时支持以上 4 种方式,比如 array、deque、vector;而有些容器只支持其中部分的定义方式,例如 forward_list 容器只支持定义正向迭代器,不支持定义反向迭代器。
下面利用迭代器简单演示:
#include <iostream>
#include <map>
#include<list>
#include<functional>
#include<string>
#include<vector>
#include<algorithm>
using namespace std;
int main() {
vector<int> vec;//定义一个容量可变数组
//从数组末尾插入元素
for (int i = 0; i < 10; i++)
{
vec.push_back(i);
}
vector<int>::iterator n;//正向迭代器
//迭代器遍历访问容器
cout << "vec:";
for ( n = vec.begin(); n != vec.end(); n++)
{
cout << *n << ","; // *n 为迭代器n指向的元素
}
return 0;
}

3.3、迭代器类别
STL 标准库为每一种标准容器定义了一种迭代器类型,这意味着,不同容器的迭代器也不同,其功能强弱也有所不同。容器的迭代器的功能强弱,决定了该容器是否支持STL中的某种算法。例如,排序算法需要通过随机访问迭代器来访问容器中的元素,因此有的容器就不支持排序算法。
常用的迭代器按功能强弱分为输入、输出、前向、双向、随机访问 5 种:
输入迭代器:通过对输入迭代器解除引用,它将引用对象,而对象可能位于集合中。最严格的输入迭代器确保只能以只读的方式访问对象。
输出迭代器:输出迭代器让程序员对集合执行写入操作。最严格的输出迭代器确保只能执行写入操作’
注意:输入迭代器和输出迭代器比较特殊,它们不是把数组或容器当做操作对象,而是把输入流/输出流作为操作对象。
前向迭代器:假设p是一个正向迭代器,则p支持以下操作: ++p, p++, *p。还可以用==和!=运算符进行比较。此外,两个正向迭代器可以互相赋值。
双向迭代器:双向迭代器具有正向迭代器的全部功能。除此之外,若p是一个双向迭代器,则--p和p–都是有定义,即一次向后移动一个位置。--p使得p朝和++p相反的方向移动。
随机访问迭代器:具有双向迭代器的全部功能。假设 p 是一个随机访问迭代器,i 是一个整型变量或常量,则 p 还支持以下操作:
p+=i:使得 p 往后移动 i 个元素。
p-=i:使得 p 往前移动 i 个元素。
p+i:返回 p 后面第 i 个元素的迭代器。
p-i:返回 p 前面第 i 个元素的迭代器。
p[i]:返回 p 后面第 i 个元素的引用。
此外,两个随机访问迭代器 p1、p2 还可以用 <、>、<=、>= 运算符进行比较。另外,表达式 p2-p1 也是有定义的,其返回值表示 p2 所指向元素和 p1 所指向元素的序号之差(即 p2 和 p1 之间的元素个数减一)。
下表是 C++ 11 标准中不同容器指定使用的迭代器类型:
| 容器 | 迭代器类型 |
|---|---|
array | 随机访问迭代器 |
vector | 随机访问迭代器 |
deque | 随机访问迭代器 |
list | 双向迭代器 |
set/multiset | 双向迭代器 |
map/multimap | 双向迭代器 |
forward_list | 前向迭代器 |
unordered_map / unordered_multimap | 前向迭代器 |
unordered_set / unordered_multiset | 前向迭代器 |
stack | 不支持迭代器 |
queue/priority_queue | 不支持迭代器 |
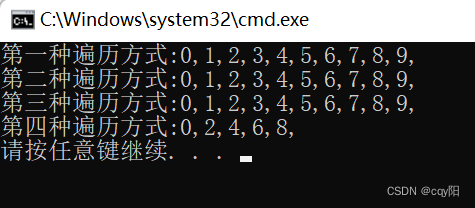
以上对迭代器做了很详细的介绍,下面就以 vector 容器为例,实际感受迭代器的用法和功能。通过前面的学习,vector 支持随机访问迭代器,因此遍历 vector 容器有以下几种做法。下面的程序中,每个循环演示了一种做法:
int main() {
vector<int> vec;//定义一个容量可变数组
//从数组末尾插入元素
for (int i = 0; i < 10; i++)
{
vec.push_back(i);
}
//第一种遍历方式
cout << "第一种遍历方式:";
for (int i = 0; i < vec.size(); i++)
{
cout << vec[i] << ","; // *n 为迭代器n指向的元素
}
cout << endl;
vector<int>::iterator i;//正向迭代器
//迭代器遍历访问容器
//第二种遍历方式
//用 != 比较两个迭代器
cout << "第二种遍历方式:";
for (i = vec.begin(); i != vec.end(); i++)
{
cout << *i << ","; // *i 为迭代器n指向的元素
}
cout << endl;
//第三种遍历方式
//用 < 比较两个迭代器
cout << "第三种遍历方式:";
for (i = vec.begin(); i < vec.end(); i++)
{
cout << *i << ","; // *i 为迭代器n指向的元素
}
cout << endl;
//第四种遍历方式
cout << "第四种遍历方式:";
i = vec.begin();
while (i<vec.end())
{
cout << *i << ","; // *i 为迭代器n指向的元素
i += 2; // 随机访问迭代器支持 "+= 整数" 的操作
}
cout << endl;
return 0;
}
案例对比
我们知道,list 容器的迭代器是双向迭代器。假设 v 和 i 的定义如下:
//创建一个 v list容器
list<int> v;
//创建一个常量正向迭代器,同样,list也支持其他三种定义迭代器的方式。
list<int>::const_iterator i;
合法代码:
for(i = v.begin(); i != v.end(); ++i)
cout << *i;
不合法代码('<'不支持双向迭代器):
for(i = v.begin(); i < v.end(); ++i)
cout << *i;
不合法代码(双向迭代器不支持数组下标访问方式):
for(int i=0; i<v.size(); ++i)
cout << v[i];
其实在 C++ 中,数组也是容器。数组的迭代器就是指针,而且是随机访问迭代器。
例如,对于数组 int a[10],int * 类型的指针就是其迭代器。则 a、a+1、a+2 都是 a 的迭代器。
3.4、辅助函数
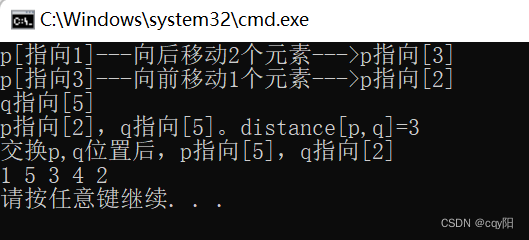
STL中有用于操作迭代器的三个函数模板:
advance(p, n): 使迭代器p向前或向后移动n个元素;
distance(p, q): 计算两个迭代器之间的距离,即迭代器p经过多少次+ +操作后和迭代器q相等。如果调用时p已经指向q的后面,则这个函数会陷入死循环;
iter_ swap(p, q): 用于交换两个迭代器p、 q指向的值;
#include <list>
#include <iostream>
#include <algorithm> //要使用操作迭代器的函数模板,需要包含此文件
using namespace std;
int main()
{
int a[5] = { 1, 2, 3, 4, 5};
list <int> lst(a, a + 5);
list <int>::iterator p = lst.begin();
advance(p, 2); //p向后移动两个元素,指向3
cout << "p[指向1]---向后移动2个元素--->p指向[" << *p <<"]"<< endl;
advance(p, -1); //p向前移动一个元素,指向2
cout << "p[指向3]---向前移动1个元素--->p指向[" << *p << "]" << endl;
list<int>::iterator q = lst.end();
q--; //q 指向 5
cout << "q指向[" << *q << "]"<< endl;
cout << "p指向["<<*p<<"],"<< "q指向[" << *q << "]。"<<"distance[p,q]="<< distance(p, q) << endl;
iter_swap(p, q); //交换 2 和 5
cout << "交换p,q位置后,p指向[" << *p << "]," << "q指向[" << *q << "]" << endl;
for (p = lst.begin(); p != lst.end(); ++p)
cout << *p << " ";
cout << endl;
return 0;
}
4、算法
查找、排序和反转等都是编程常用操作。为了避免重复实现,STL 算法的方式提供这些函数,通过结合使用这些函数和迭代器,可对容器执行最常见的操作,下面总结一些常见操作:
| 算法 | 注释 |
|---|---|
| sort | 使用指定的排序标准,对范围内的元素进行排序 |
| find | 在集合中查找值 |
| search | 在范围内,查找第一个满足条件的元素 |
| count | 在指定范围内,查找值与指定值匹配的所有元素 |
| reverse | 对集合中元素的排列顺序反转操作 |
| remove_if | 根据用户定义的谓词将元素从集合中删除 |
| transform | 使用用户定义的变换函数对容器中的元素进行变换 |
| equal | 比较两个元素是否相等,或使用二元谓词判断两者否相等 |
| fill | 将指定值分配给指定范围中的每个元素 |
| generate | 将指定函数对象的返回值分配给指定范围中的每个元素 |
| for_each | 对指定范围内的每一个元素执行指定的操作 |
| copy | 将一个范围复制到另一个范围 |
| remove | 将指定范围中包含指定值的元素删除 |
| unique | 比较指定范围内的相邻元素,并删除重复的元素 |
| replace | 用一个值来替换指定范围中与指定值匹配的所有元素 |
关于更多STL算法介绍,可以转至本专栏以下博客:
【跟学C++】C++STL标准模板库——算法详细整理(上)(Study18)
【跟学C++】C++STL标准模板库——算法详细整理(中)(Study18)
【跟学C++】C++STL标准模板库——算法详细整理(下)(Study18)
5、总结
最后,长话短说,大家看完就好好动手实践一下,切记不能三分钟热度、三天打鱼,两天晒网。大家也可以自己尝试写写博客,来记录大家平时学习的进度,可以和网上众多学者一起交流、探讨,我也会及时更新,来督促自己学习进度。一开始提及的博主【AI菌】,个人已关注,并订阅了相关专栏(对我有帮助的),希望大家觉得不错的可以点赞、关注、收藏。

![[论文解析] Diffusion Guided Domain Adaptation of Image Generators](https://img-blog.csdnimg.cn/5940fad334b04157837dbfd32870970a.png)


![[附源码]Node.js计算机毕业设计高校创新学分申报管理系统Express](https://img-blog.csdnimg.cn/b1e9540c62794d8fb5f689560c82ad81.png)


![SpringSecurity[3]-自定义登录逻辑,自定义登录页面,以及认证过程的其他配置](https://img-blog.csdnimg.cn/c525c1e81f9f44d6ae2a073d0af3763a.png)