project link: https://styleganfusion.github.io/
文章目录
- Overview
- What problem is addressed in the paper?
- What is the key to the solution?
- What is the main contribution?
- Introduction
- Background
- Latent diffusion model
- Classifier-free guidance
- Method
- Model Structure and Diffusion Guidance Loss
- Directional and Reconstruction Regularizer
- Timestep Range and Layer Selection
- Experiments
- Conclusion
Overview
What problem is addressed in the paper?
In this paper, we show that the classifier-free guidance can be leveraged as a critic and enable generators to distill knowledge from large-scale text-to-image diffusion models. Generators can be efficiently shifted into new domains indicated by text prompts without access to groundtruth samples from target domains
本文表明,可以利用无分类器指导作为批评器,并使生成器从大规模文本到图像扩散模型中提取知识。生成器可以有效地转移到文本提示表示的新域,而无需访问目标域的groundtruth样本
What is the key to the solution?
- We introduce the diffusion model score distillation sampling (SDS) into domain adaptation of style-based image generators and achieve better performance than the prior art. 将扩散模型score distillation sampling (SDS)引入到基于风格的图像生成器的域适应中,并取得了比现有技术更好的性能。
- To regularize the network and prevent model collapse, we propose a diffusion directional regularizer and adapt the reconstruction guidance to SDS. To solve blurry issues, we adapt the layer selection into the SDS finetuning framework. 为了正则化网络并防止模型崩溃,提出了一种扩散定向正则化器,并将重建指导适应于SDS。为了解决模糊问题,我们将图层选择调整到SDS微调框架中。
What is the main contribution?
- our model achieves equally high CLIP scores and significantly lower FID than prior work on short prompts, and outperforms the baseline qualitatively and quantitatively on long and complicated prompts. 所提出模型在短提示上取得了同样高的CLIP分数和显著低于之前工作的FID,并在长而复杂的提示上从质量和数量上超过了基线。
- we extend our work to 3D-aware style-based generators and DreamBooth guidance 将工作扩展到3d感知的基于风格的生成器和DreamBooth指导
Introduction
我们利用预先训练的大规模扩散模型的强大功能,并基于最近提出的评分蒸馏采样技术[38],其中文本到图像的扩散作为一个冻结的、有效的评论家,预测图像空间编辑。
在本文中,我们研究了两种将扩散与基于风格的生成器结合起来的技术,以进一步探索这一想法:
- 我们将扩散模型分数蒸馏采样(SDS)引入到基于风格的图像生成器的领域自适应中,取得了比现有技术更好的性能。
- 为了使网络正则化,防止模型崩溃,我们提出了一种diffusion directional regularizer,并将重构guidance适应于SDS。为了解决模糊问题,我们将layer selection引入SDS调优框架。
Background
Latent diffusion model
本文的guidance model:
latent diffusion model (LDM) StableDiffusion[46]
LDM 用一个编码器
ε
\varepsilon
ε将图像x 编码到潜空间z,
z
0
=
ε
(
x
)
z_0 = \varepsilon(x)
z0=ε(x)denoising process 实在latent space Z中进行的。
我们用
ϵ
θ
\epsilon_{\theta}
ϵθ 表示一个latent diffusion model,其训练的目标函可以表示如下:
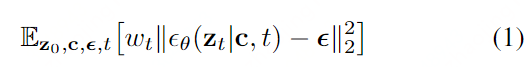
其中
(
x
,
c
)
(x,c)
(x,c) 是data-conditioning pairs.
ϵ
∼
N
(
0
,
1
)
,
t
∼
U
n
i
f
o
r
m
(
1
,
T
)
\epsilon \sim N(0,1), t \sim Uniform(1,T)
ϵ∼N(0,1),t∼Uniform(1,T)(t服从1到T之间的均匀分布)。
Classifier-free guidance
classifier guidance是一种有效的方法,可以更好地引导合成朝着期望的方向进行, classifier 可以是 a class or a text prompt…
这个方法使用从预训练模型
p
(
c
∣
z
t
)
p(c|z_t)
p(c∣zt)在采样过程中的梯度。
Classifier-free guidance (CFG) 是一个可替换的技术,它避免了使用预训练的分类器。 具体地,在训练conditional diffusion model的过程中, 随机dropping 条件c,从而让模型学习在没有condition的情况的去生成图像。因此,在扩散过程中,通过将条件C下的合成结果推向远离非条件结果,可以生成条件良好的图像。
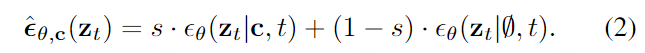
这里前后两项
ϵ
θ
\epsilon_{\theta}
ϵθ分别表示 conditional 和unconditional的 误差预测。S为guidance权重,s越大(>1),引导效果越强。
Method
Model Structure and Diffusion Guidance Loss
一张使用生成器G,根据style code w 生成的图像x,其中w 服从
P
w
P_w
Pw分布。生成图像表示为:
x
=
G
(
w
)
x = G(w)
x=G(w).
将x嵌入到 StableDiffusion model中:
z
0
=
ε
(
x
)
∈
R
c
×
h
×
w
z_0 = \varepsilon(x) \in R^{c \times h \times w}
z0=ε(x)∈Rc×h×w.
根据标准的diffusion model 的前向过程,我们采样时间步t,来获得噪音潜码: 我们遵循DreamFusion[38]提出的梯度技巧,直接使用预测分数和ground-truth分数之间的差值作为梯度并反向传播
我们遵循DreamFusion[38]提出的梯度技巧,直接使用预测分数和ground-truth分数之间的差值作为梯度并反向传播
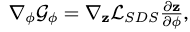
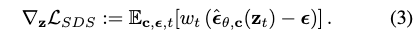
Directional and Reconstruction Regularizer
diffusion directional regularizer:
我们用
G
t
r
a
i
n
G_{train}
Gtrain 和
G
f
r
o
z
e
n
G_{frozen}
Gfrozen 分别表示当前训练的和初始冻结的生成器。
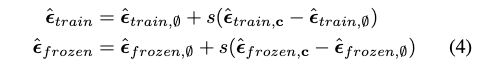
提供的正则化是上述二者之间的cosine相似性。
我们根据其预期半径对每个分数张量进行归一化,添加如下定义的正则化梯度项:
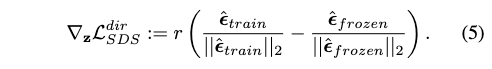
我们使用这个梯度项来优化生成器。
实验表明,方向正则化算法能有效地防止模型崩溃。它是一个与其他正则化方法兼容的插件模块。
我们将分数蒸馏框架扩展到重建指导[13],并引入了重建正则化:
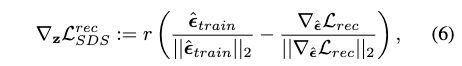
其中
▽
ϵ
^
L
r
e
c
\bigtriangledown_{\hat{\epsilon}}L_{rec}
▽ϵ^Lrec 是重构损失
L
r
e
c
=
∣
∣
z
^
0
−
z
0
∣
∣
2
L_{rec}=||\hat{z}_0-z_0||^2
Lrec=∣∣z^0−z0∣∣2的梯度,并且:
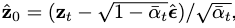
整体损失表示为:
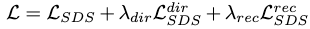
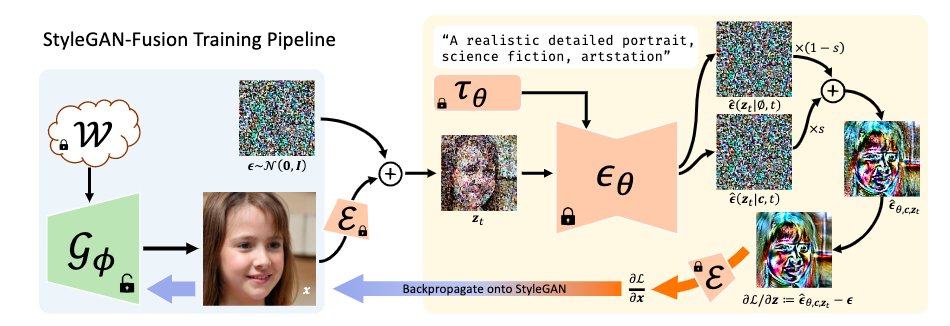
Overview of our StyleGAN-Fusion framework.
Timestep Range and Layer Selection
较小的 T S D S T_{SDS} TSDS留给指导的空间较小,并且更多地与局部结构和细节有关。去噪时间步长范围配置允许我们控制变化的规模。
如果我们一起优化生成器层,可能会出现不满意的情况,即使用高层次的整体结构引导损失来更新浅层和详细的生成器层,导致生成的图像模糊。
我们基于SDS目标对W+风格代码空间进行N次优化,并选择对应于变化最显著的风格代码的k层,消融研究(见第4.3节)显示了多个k设置的质量提升,特别是在减少模糊模糊性方面。
Experiments

We compare our method and the baseline, StyleGANNADA
实验表明,StyleGANNADA很难捕获长文本提示中提到的所有关键约束。相比之下,当文本提示很长很复杂时,我们的模型生成的图像具有更高的质量和保真度。

图5 :我们的结果更符合提示,特别是在自然和不扭曲的脸部布局和大而美丽的反射眼睛方面。此外,我们的模型的结果有更真实的三维照明和更好地匹配文本提示。
我们尝试采用StyleGAN2-Cat[18],使用包含多个约束的长提示符,包括渲染引擎、3D样式、纹理和照明。

图6显示了我们的方法和基线生成的图像。基线模型没有正确地遵循文本描述,在许多方面都失败了。阴影不像我们的那么真实,有很多不需要的纹理。正如提示符所描述的,我们的模型有更多电影般的照明。
结果中的纹理比基线更平滑。与看起来平坦的基线图像不同,我们的结果实现了具有高质量细节的更强烈的3D风格。我们从两个角度来解决这些问题:
- 生成器和扩散引导由图像编码器分开,使得生成器更有可能在语义有意义的水平上进行优化,而不是在像素水平上进行对抗。
- 由于StableDiffusion使用了一系列文本嵌入和跨域注意,所提出的扩散引导具有更丰富的信息,使其具有更高的能力来捕获长文本提示中提到的多个关键约束。

图8:我们的方法生成了视觉上更真实和自然的结果,包括未扭曲的面部组件、更干净的背景、多样的姿势和更高的姿势逼真度。
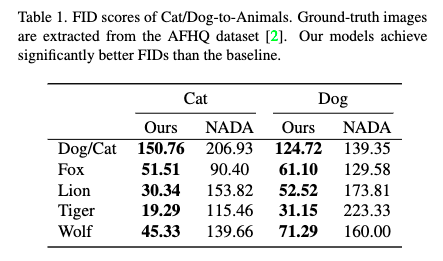

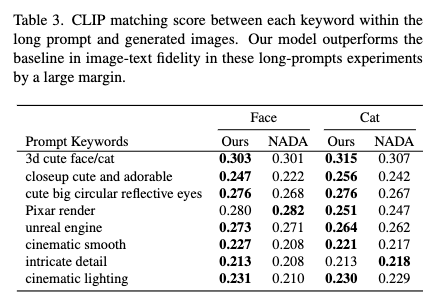

图7:较大的范围可以实现结构变化,并增加图像对目标域的保真度,而较小的范围关注局部变化,并倾向于对源域的保真度。

图9: 选择更少的层需要更多的训练迭代,我们为每个层配置显示最佳视觉质量的结果。选择的图层越少,模糊的感觉就会消失,头发的细节也会得到更好的保存。

图10:
L
S
D
S
d
i
r
L_{SDS}^{dir}
LSDSdir 更好地保留了包括面部表情、耳环和背景颜色在内的细节,而非reg方法最终忽略了它们。

图11:
L
S
D
S
r
e
c
L_{SDS}^{rec}
LSDSrec 是一个更强的约束,并保留更好的细节,而
L
S
D
S
d
i
r
L_{SDS}^{dir}
LSDSdir 允许添加新的颜色,如蓝色眼睛。



Conclusion
我们提出了一种新的图像生成域自适应方法,该方法使用稳定扩散引导和分数蒸馏采样。我们的方法允许通过选择TSDS的值来灵活地控制修改的幅度。通过引入扩散引导方向正则化器和层选择技术,我们的模型能够将生成器从文本提示指示的目标域生成新的图像,与现有方法相比,质量有所提高。


![[附源码]Node.js计算机毕业设计高校创新学分申报管理系统Express](https://img-blog.csdnimg.cn/b1e9540c62794d8fb5f689560c82ad81.png)


![SpringSecurity[3]-自定义登录逻辑,自定义登录页面,以及认证过程的其他配置](https://img-blog.csdnimg.cn/c525c1e81f9f44d6ae2a073d0af3763a.png)