通过 yolov5修改骨干网络–原网络说明 我们知道:yolov5.yaml中存放的是我们模型构建参数,具体构建过程在yolo.py中的parse_model函数,通过循环遍历yolov5.yaml给的参数,去寻找网络名称,并将args的参数传入网络,下面先用pytorch自带的mobile网络进行修改并替换原有yolov5网络。
网络都是分层次的,比如如果把某个网络模型Net按层次从外到内进行划分的话,features和classifier是Net的子层,而conv2d, ReLU, BatchNorm, Maxpool2d等基础操作可能是features的子层, Linear, Dropout, ReLU等可能是classifier的子层。
- model.modules()不但会遍历模型的子层,还会遍历子层的子层,以及所有子层。
- model.children()只会遍历模型的子层,这里即是features和classifier。
比如先调出pytorch中的Mobilnetv3网络,输出一些相关信息,
from torchvision import models
m = models.mobilenet_v3_small()
print(list(m.children())[0])
print("---"*30)
print(list(m.children())[1])
print("---"*30)
print(list(m.children())[2])
print("len(m.modules()): ",len(list(m.modules())))
print("len(m.children()): ",len(list(m.children())))
print("len(m.children()[0]): ",len(list(m.children())[0]))
--------------------------------------------------------------------
AdaptiveAvgPool2d(output_size=1)
--------------------------------------------------------------------
Sequential(
(0): Linear(in_features=576, out_features=1024, bias=True)
(1): Hardswish()
(2): Dropout(p=0.2, inplace=True)
(3): Linear(in_features=1024, out_features=1000, bias=True)
)
len(m.modules()): 209
len(m.children()): 3
len(m.children()[0]): 13
可以看到网络共三层,分别是0层:特征提取,1层AdaptiveAvgPool2d,2层:分类层,特征提取部分共13层,里面包含卷积、BN、激活等,都加起来共209个这种小结构。
list(m.children())[0]是网络结构,下面来具体分析。
内容比较多,重点关注哪里进行了下采样,卷积步长为2的地方,特征图就缩小一半。
在yolov5中是对尺寸为20、40、80的特征图进行concat,这里也是如此(当然其他尺寸也可以)。
Ctrl F以下可以看到共5个地方使特征图缩小一半,第一次 320 ∗ 320 320*320 320∗320;第二次: 160 ∗ 160 160*160 160∗160;第三次: 80 ∗ 80 80*80 80∗80;第四次: 40 ∗ 40 40*40 40∗40;第五次: 20 ∗ 20 20*20 20∗20。
这样就可以划分了,到特征图为 40 ∗ 40 40*40 40∗40时,卷积在第五个操作中,所以我们要讲前四个作为第一组,其输出与后面的特征图concat。
同样分析后面是[4:9],最后一块是[9:13]
分析出来后就可以开始改代码了。
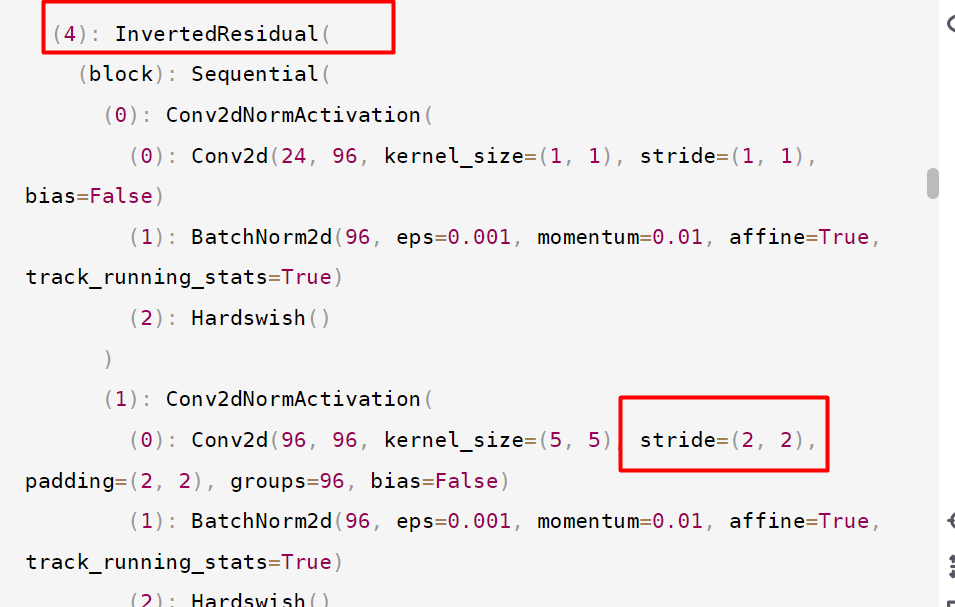
--------------------------------------------------------------------
Sequential(
(0): Conv2dNormActivation(
(0): Conv2d(3, 16, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(16, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): Hardswish()
)
(1): InvertedResidual(
(block): Sequential(
(0): Conv2dNormActivation(
(0): Conv2d(16, 16, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=16, bias=False)
(1): BatchNorm2d(16, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(1): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(16, 8, kernel_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(8, 16, kernel_size=(1, 1), stride=(1, 1))
(activation): ReLU()
(scale_activation): Hardsigmoid()
)
(2): Conv2dNormActivation(
(0): Conv2d(16, 16, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(16, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
)
)
)
(2): InvertedResidual(
(block): Sequential(
(0): Conv2dNormActivation(
(0): Conv2d(16, 72, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(72, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(1): Conv2dNormActivation(
(0): Conv2d(72, 72, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=72, bias=False)
(1): BatchNorm2d(72, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(2): Conv2dNormActivation(
(0): Conv2d(72, 24, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(24, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
)
)
)
(3): InvertedResidual(
(block): Sequential(
(0): Conv2dNormActivation(
(0): Conv2d(24, 88, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(88, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(1): Conv2dNormActivation(
(0): Conv2d(88, 88, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=88, bias=False)
(1): BatchNorm2d(88, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(2): Conv2dNormActivation(
(0): Conv2d(88, 24, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(24, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
)
)
)
(4): InvertedResidual(
(block): Sequential(
(0): Conv2dNormActivation(
(0): Conv2d(24, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(96, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): Hardswish()
)
(1): Conv2dNormActivation(
(0): Conv2d(96, 96, kernel_size=(5, 5), stride=(2, 2), padding=(2, 2), groups=96, bias=False)
(1): BatchNorm2d(96, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): Hardswish()
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(96, 24, kernel_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(24, 96, kernel_size=(1, 1), stride=(1, 1))
(activation): ReLU()
(scale_activation): Hardsigmoid()
)
(3): Conv2dNormActivation(
(0): Conv2d(96, 40, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(40, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
)
)
)
(5): InvertedResidual(
(block): Sequential(
(0): Conv2dNormActivation(
(0): Conv2d(40, 240, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(240, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): Hardswish()
)
(1): Conv2dNormActivation(
(0): Conv2d(240, 240, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=240, bias=False)
(1): BatchNorm2d(240, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): Hardswish()
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(240, 64, kernel_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(64, 240, kernel_size=(1, 1), stride=(1, 1))
(activation): ReLU()
(scale_activation): Hardsigmoid()
)
(3): Conv2dNormActivation(
(0): Conv2d(240, 40, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(40, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
)
)
)
(6): InvertedResidual(
(block): Sequential(
(0): Conv2dNormActivation(
(0): Conv2d(40, 240, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(240, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): Hardswish()
)
(1): Conv2dNormActivation(
(0): Conv2d(240, 240, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=240, bias=False)
(1): BatchNorm2d(240, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): Hardswish()
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(240, 64, kernel_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(64, 240, kernel_size=(1, 1), stride=(1, 1))
(activation): ReLU()
(scale_activation): Hardsigmoid()
)
(3): Conv2dNormActivation(
(0): Conv2d(240, 40, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(40, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
)
)
)
(7): InvertedResidual(
(block): Sequential(
(0): Conv2dNormActivation(
(0): Conv2d(40, 120, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(120, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): Hardswish()
)
(1): Conv2dNormActivation(
(0): Conv2d(120, 120, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=120, bias=False)
(1): BatchNorm2d(120, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): Hardswish()
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(120, 32, kernel_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(32, 120, kernel_size=(1, 1), stride=(1, 1))
(activation): ReLU()
(scale_activation): Hardsigmoid()
)
(3): Conv2dNormActivation(
(0): Conv2d(120, 48, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(48, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
)
)
)
(8): InvertedResidual(
(block): Sequential(
(0): Conv2dNormActivation(
(0): Conv2d(48, 144, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(144, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): Hardswish()
)
(1): Conv2dNormActivation(
(0): Conv2d(144, 144, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=144, bias=False)
(1): BatchNorm2d(144, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): Hardswish()
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(144, 40, kernel_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(40, 144, kernel_size=(1, 1), stride=(1, 1))
(activation): ReLU()
(scale_activation): Hardsigmoid()
)
(3): Conv2dNormActivation(
(0): Conv2d(144, 48, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(48, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
)
)
)
(9): InvertedResidual(
(block): Sequential(
(0): Conv2dNormActivation(
(0): Conv2d(48, 288, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(288, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): Hardswish()
)
(1): Conv2dNormActivation(
(0): Conv2d(288, 288, kernel_size=(5, 5), stride=(2, 2), padding=(2, 2), groups=288, bias=False)
(1): BatchNorm2d(288, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): Hardswish()
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(288, 72, kernel_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(72, 288, kernel_size=(1, 1), stride=(1, 1))
(activation): ReLU()
(scale_activation): Hardsigmoid()
)
(3): Conv2dNormActivation(
(0): Conv2d(288, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(96, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
)
)
)
(10): InvertedResidual(
(block): Sequential(
(0): Conv2dNormActivation(
(0): Conv2d(96, 576, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(576, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): Hardswish()
)
(1): Conv2dNormActivation(
(0): Conv2d(576, 576, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=576, bias=False)
(1): BatchNorm2d(576, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): Hardswish()
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(576, 144, kernel_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(144, 576, kernel_size=(1, 1), stride=(1, 1))
(activation): ReLU()
(scale_activation): Hardsigmoid()
)
(3): Conv2dNormActivation(
(0): Conv2d(576, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(96, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
)
)
)
(11): InvertedResidual(
(block): Sequential(
(0): Conv2dNormActivation(
(0): Conv2d(96, 576, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(576, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): Hardswish()
)
(1): Conv2dNormActivation(
(0): Conv2d(576, 576, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=576, bias=False)
(1): BatchNorm2d(576, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): Hardswish()
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(576, 144, kernel_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(144, 576, kernel_size=(1, 1), stride=(1, 1))
(activation): ReLU()
(scale_activation): Hardsigmoid()
)
(3): Conv2dNormActivation(
(0): Conv2d(576, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(96, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
)
)
)
(12): Conv2dNormActivation(
(0): Conv2d(96, 576, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(576, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): Hardswish()
)
)
修改代码
先写一下common.py中的MobileNet函数
class MobileNet(nn.Module):
def __init__(self, *args) -> None:
super().__init__()
model = models.mobilenet_v3_small(pretrained=True)
modules = list(model.children())
modules = modules[0][args[1]:args[2]]
self.model = nn.Sequential(*modules)
def forward(self, x):
return self.model(x)
*args传入的是前面我们数的模型块
然后修改yolov5.yaml中的backbone,注意第一个的output channel是第4个模型块的输出channel;第二个的output channel是第9个模型块的输出channel;第三个的output channel是第13个也就是最后一个模型块的输出channel,
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, MobileNet, [24, 0, 4]], # 0
[-1, 1, MobileNet, [48, 4, 9]], # 1
[-1, 1, MobileNet, [576, 9, 13]], # 2
[-1, 1, SPPF, [1024, 5]], # 3
]
然后是改yolo.py中的parse_model 函数,很简单,在后面加一个
elif m is MobileNet:
c2 = args[0]
同理修改efficientnet_b0
class effb0(nn.Module):
def __init__(self, *args) -> None:
super().__init__()
model = models.efficientnet_b0(pretrained=True)
modules = list(model.children())
modules = modules[0][args[1]:args[2]]
self.model = nn.Sequential(*modules)
def forward(self, x):
return self.model(x)
然后修改yaml
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, effb0, [40,0,4]], # 0
[-1, 1, effb0, [112,4,6]], # 1
[-1, 1, effb0, [1280,6,9]], # 2
[-1, 1, SPPF, [1024, 5]], # 3
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 1], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 7
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 0], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 11 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 7], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 14 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 3], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 17 (P5/32-large)
[[11, 14, 17], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
添加parse_model
elif m is effb0:
c2 = args[0]
其他的可以看看resnet、shufflenet,与上面两个有些许差别,我没弄出来。