文章目录
- 一、Slot Filling
- 二、Recurrent Neural NetWork(RNN)
- 三、Bidirectional RNN(双向RNN)
- 四、Long Short Term Memory(LSTM)
- 五、Learning Target
- 六、RNN 很难 Train
- 七、Helpful Techniques
- 7.1 LSTM
- 7.2 GRU
- 7.3 Others
- 八、Many To One
- 8.1 Sentiment Analysis 情绪分析
- 8.2 Key Term Extraction 关键词提取
- 九、Many To Many(Output is shorter)
- 9.1 Speech Recognition 语音辨识
- 十、Many To Many(No Limitation)
- 十一、Beyond Sequence
- 十二、Sequence To Sequence Auto Encoder
- 12.1 Text
- 12.2 Speech
- 十三、Demo:Chat-bot 聊天机器人
- 十四、Attention-based Model
- 十五、Reading Comprehension 阅读理解
- 十六、Visual Question Answering 可视化答题
- 十七、Speech Question Answering 语音问题解答
- 十八、RNN vs Structured Learning
一、Slot Filling
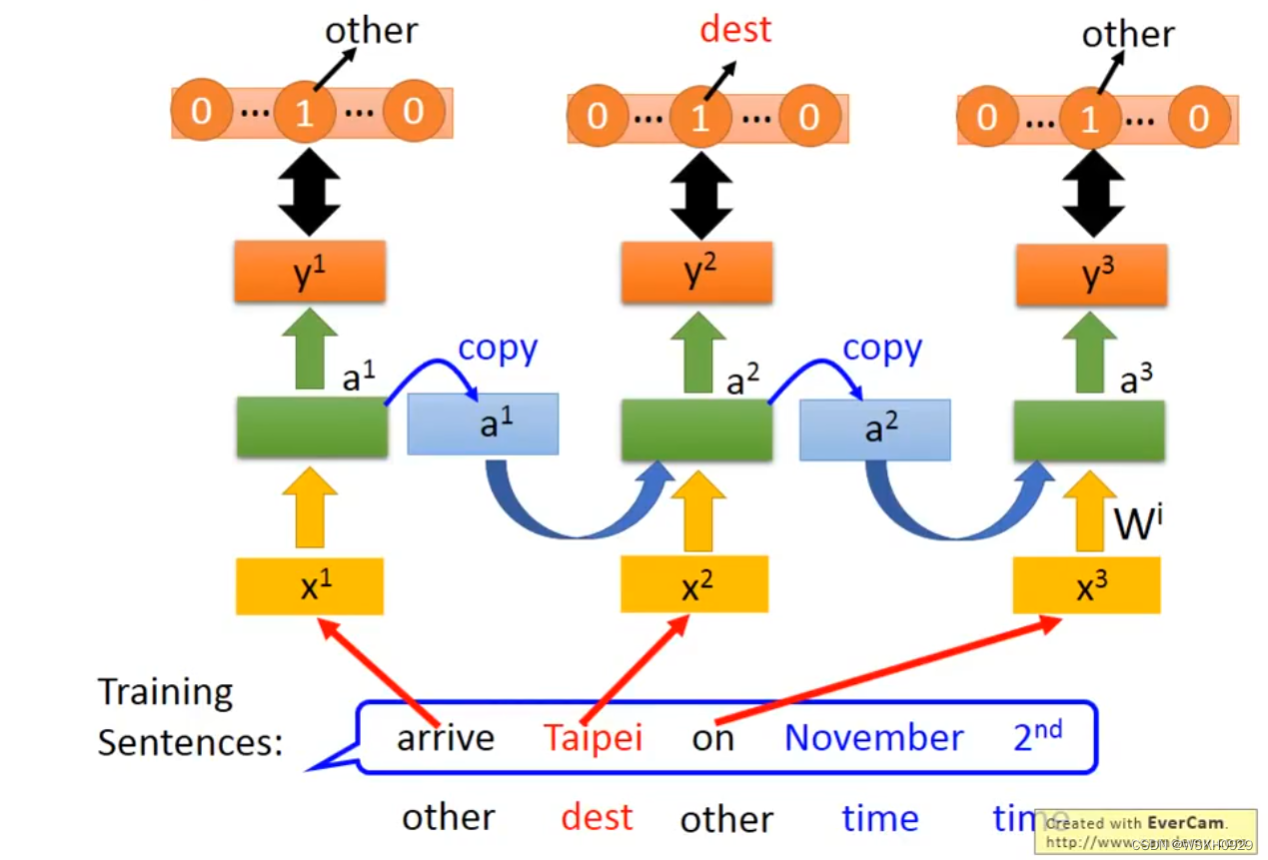
假设一个人说了这样一句话 “I would like to arrive Taipei on November 2nd” ,假设有两个 Slot : 目的地和到达时间。那么 Slot Filling 的任务就是 识别这句话中每个词汇对应属于哪个 Slot,例如 Taipei 属于 目的地,November 2nd 属于 到达时间,其他词汇不属于任何 Slot
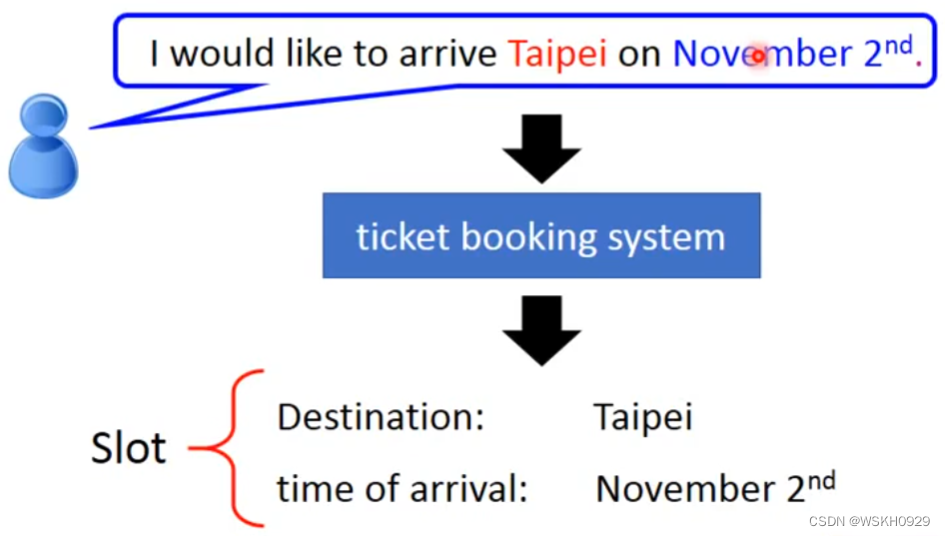
想实现这个效果,最简单的想法就是,直接将词汇转化为向量传给一个 全连接网络,输出是词汇属于每个 Slot 的概率
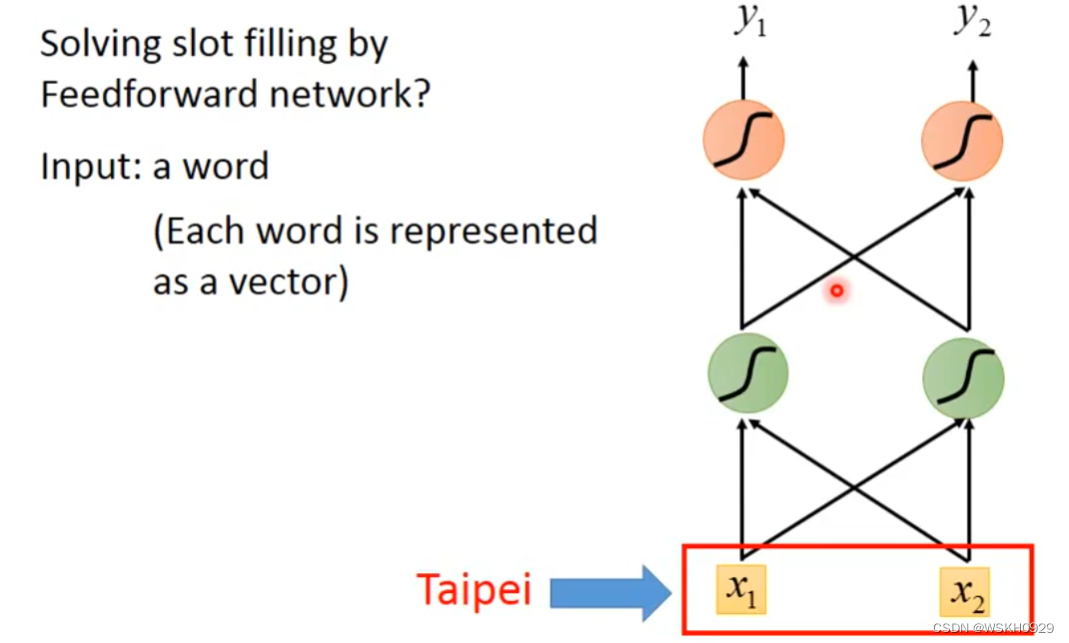
那么怎么将词汇转化为向量呢?可以用1-of-N Encoding,1-of-N Encoding中有一个存有很多词的词典,然后我们可以用类似one-hot编码的方式根据词典将词汇转化为向量

但是世界上的单词太多了,这样会导致词典过于庞大,所以我们可以只放一些出现频率较高的单词到词典里,其余基本不会出现的词统一用“other”代替(如下图所示)

还可以用单词的前后缀来构造向量

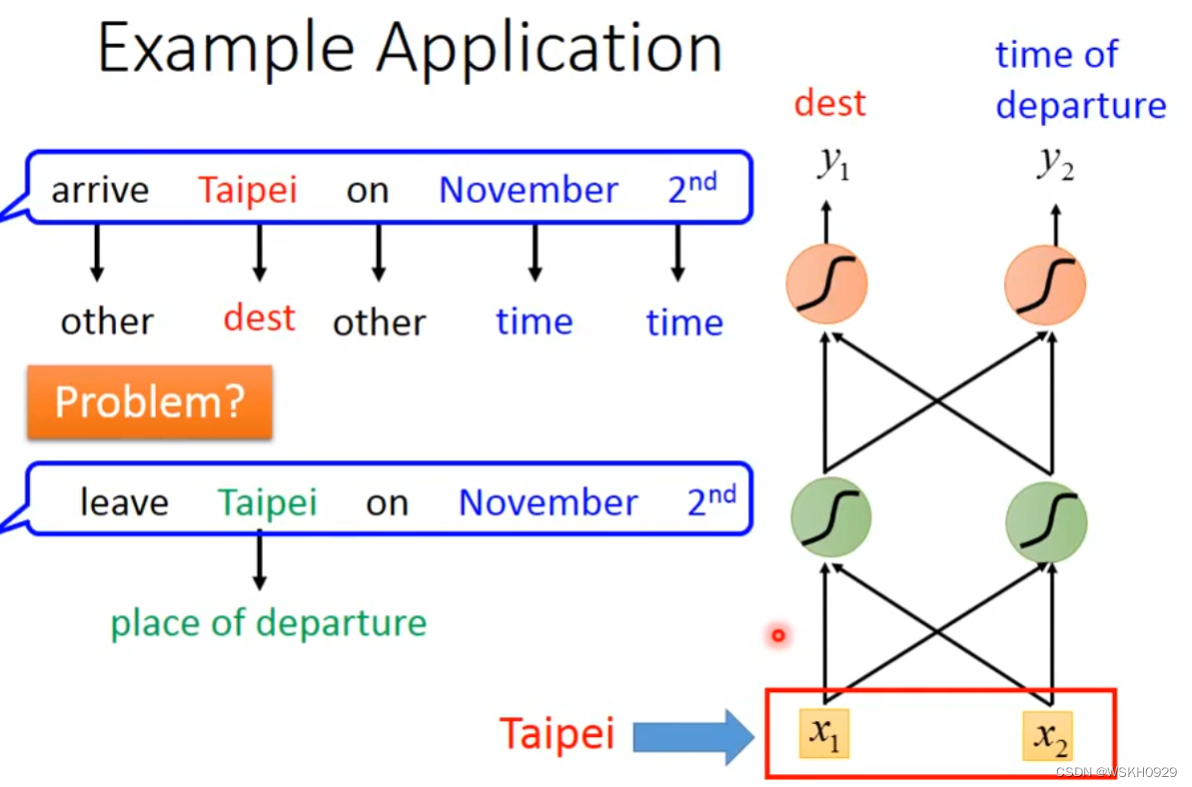
但是,使用单纯使用全连接网络的方法解 Slot Filling 问题会出现下图所示的问题。第一句话中的“Taipei”是目的地,但是第二句话中的“Taipei”却是出发地。两个完全相同的单词在不同的语句中,却应该属于不同的 Slot,这相当于要让模型在输入相同词汇的情况下有时候输出目的地,有时候输出起始地。对此,全连接网络表示:臣妾做不到呀~
于是我们就有了想法,有没有方法可以让神经网络具有“记忆力”,即可以记住一些上下文的咨询,帮助模型更好地理解当前词汇,输出最符合语境的结果呢 ?答案是:有的。它就是本文的主角 - Recurrent Neural NetWork(RNN),循环神经网络
二、Recurrent Neural NetWork(RNN)
那么RNN怎么做到让神经网络具有记忆的呢?其实也不难,其中一个想法就是,将同层中,上一个词汇的 Embedding 作为 当前词汇的 额外输入,这样就具有了上一个词汇的信息,而上一个词汇(如果不是第一个词汇的话)又具有上上个词汇的信息,以此类推,当前词汇就具有了上文所有词汇的信息。
这种以上一阶段,同层的 输出作为当前额外输入的 网络结构 称之为 Elman Network(如下图所示)

还有一种网络结构,它是以上一阶段最后的输出作为当前的额外输入,称之为 Jordan Network。通常 Jordan Network 具有更好的表现,可能是因为最后的输出比中间层的输出具有更具体完备的特征,即信息更有用。

三、Bidirectional RNN(双向RNN)
上面讲的是单向的RNN,即每一阶段只额外获取了上一阶段的咨询,也就是只对上文有记忆。
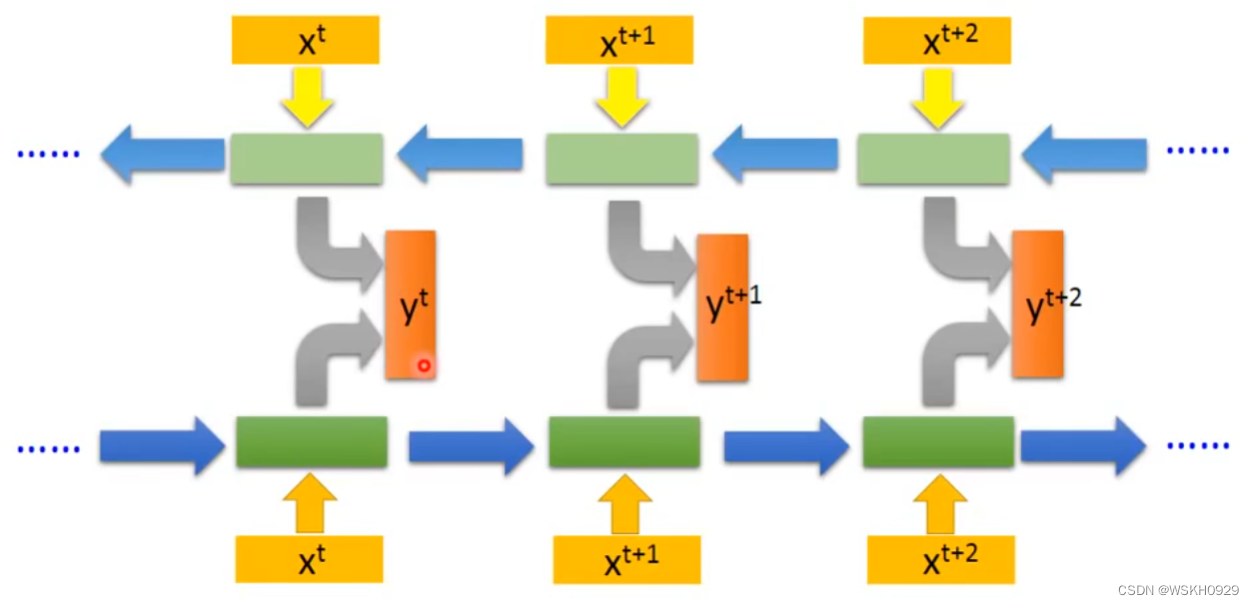
下面我们要讲对上下文都有记忆的双向RNN。其实思路很简单,就是一层正向走,一层反向走,然后对应位置的输出合在一起传给线性层进行分类,输出预测类别即可
如下图所示,上面的链是从语句的最后一个词开始,往前走。下面的链是从语句的第一个词往后走,然后对应位置的输出结合在一起,共同输出 y
四、Long Short Term Memory(LSTM)
Long Short Term Memory(LSTM),中文:长短期记忆网络。注意哈,这里的长短期记忆不是指长期或短期的记忆(我一开始就是这么认为的),其实是长的短期记忆的意思,也就是说LSTM其实还是短期记忆,只是稍微长了那么一些的短期记忆而已!
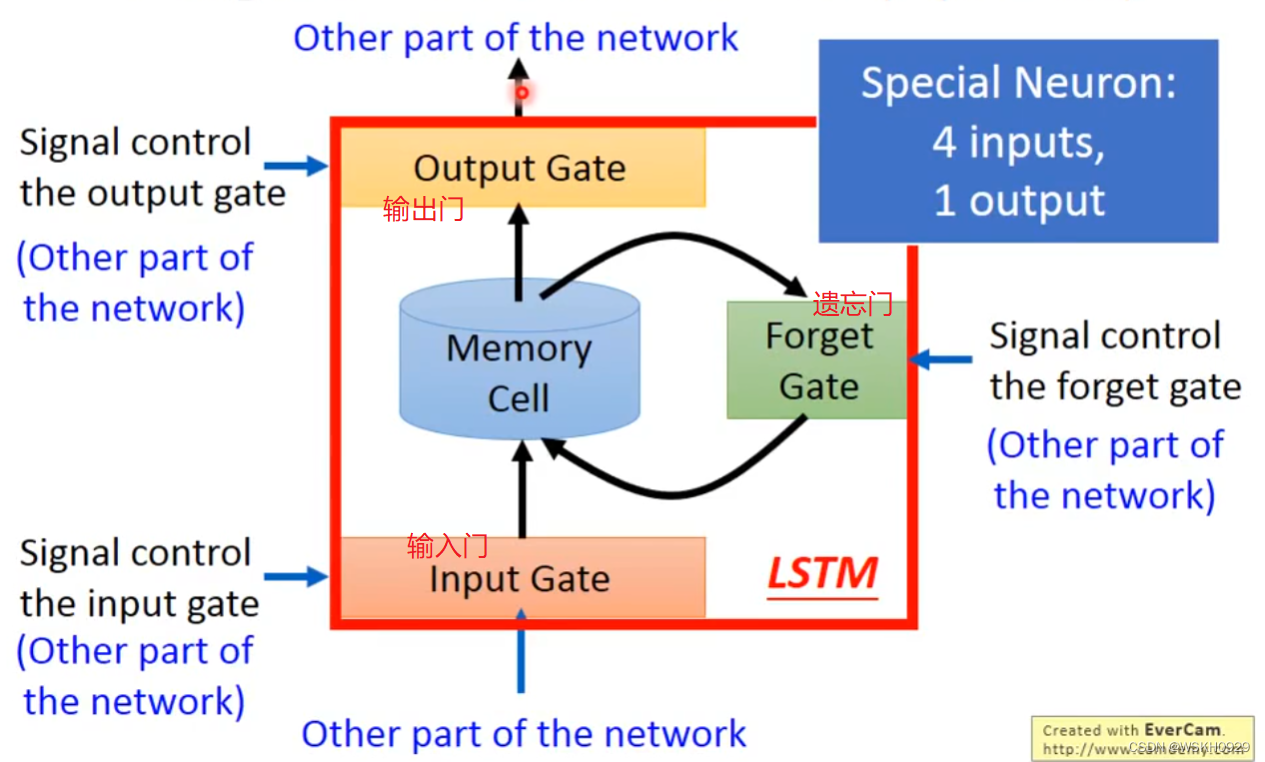
下面用一个形象的例子介绍一下 LSTM。我们前两节介绍的RNN的Memory都是来者不拒,统统记忆的,但是LSTM不一样,LSTM有三个门:
- 第一个门:输入门。用来控制信息传入记忆的程度
- 第二个门:输出门。用来控制记忆输出的程度
- 第三个门:遗忘门。用来控制保留原有记忆的程度
这三个门都是网络自己学出来的,也就是说LSTM会在训练过程中不断学习怎么调节这三个门的参数,让它们合理的开关,这样可能可以过滤或遗忘掉不重要的上下文咨询,从而提升模型效果
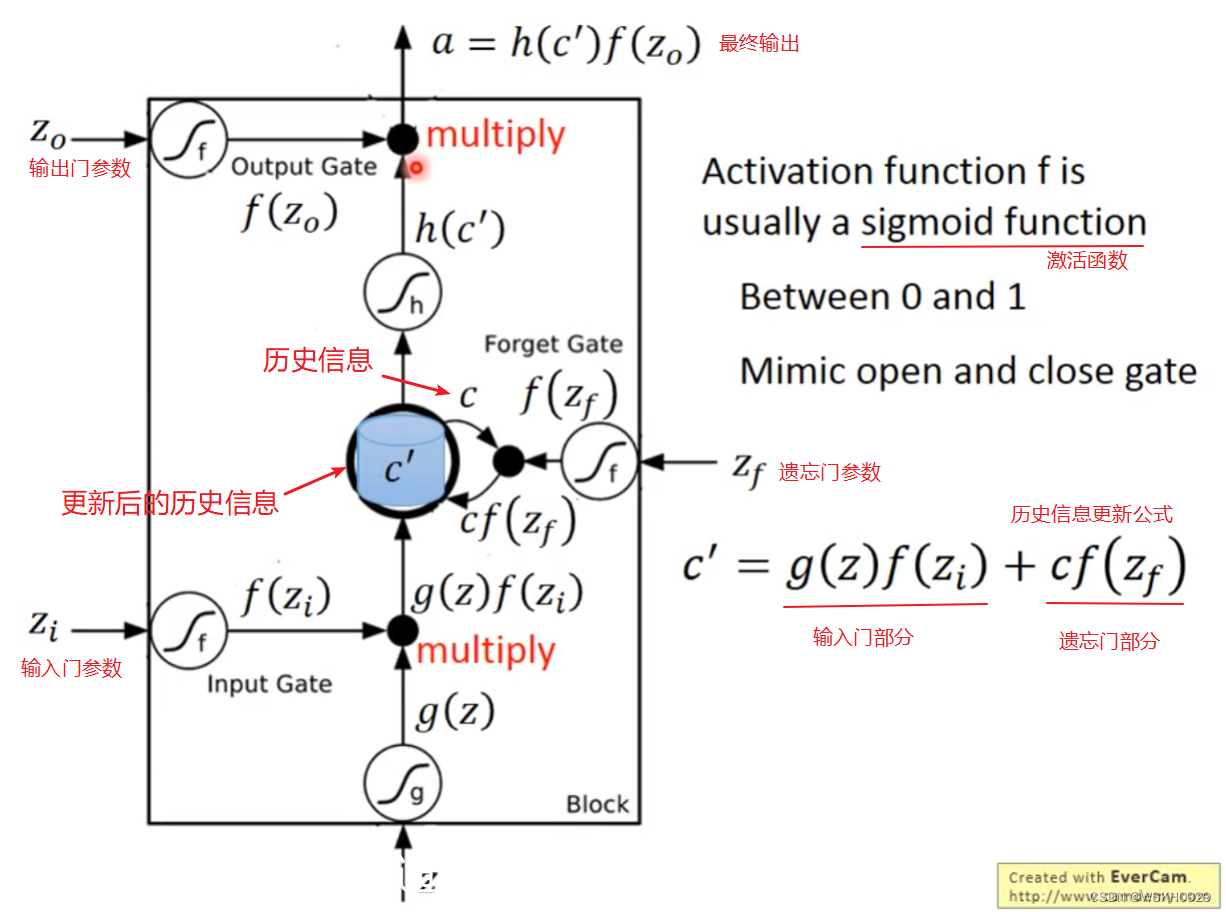
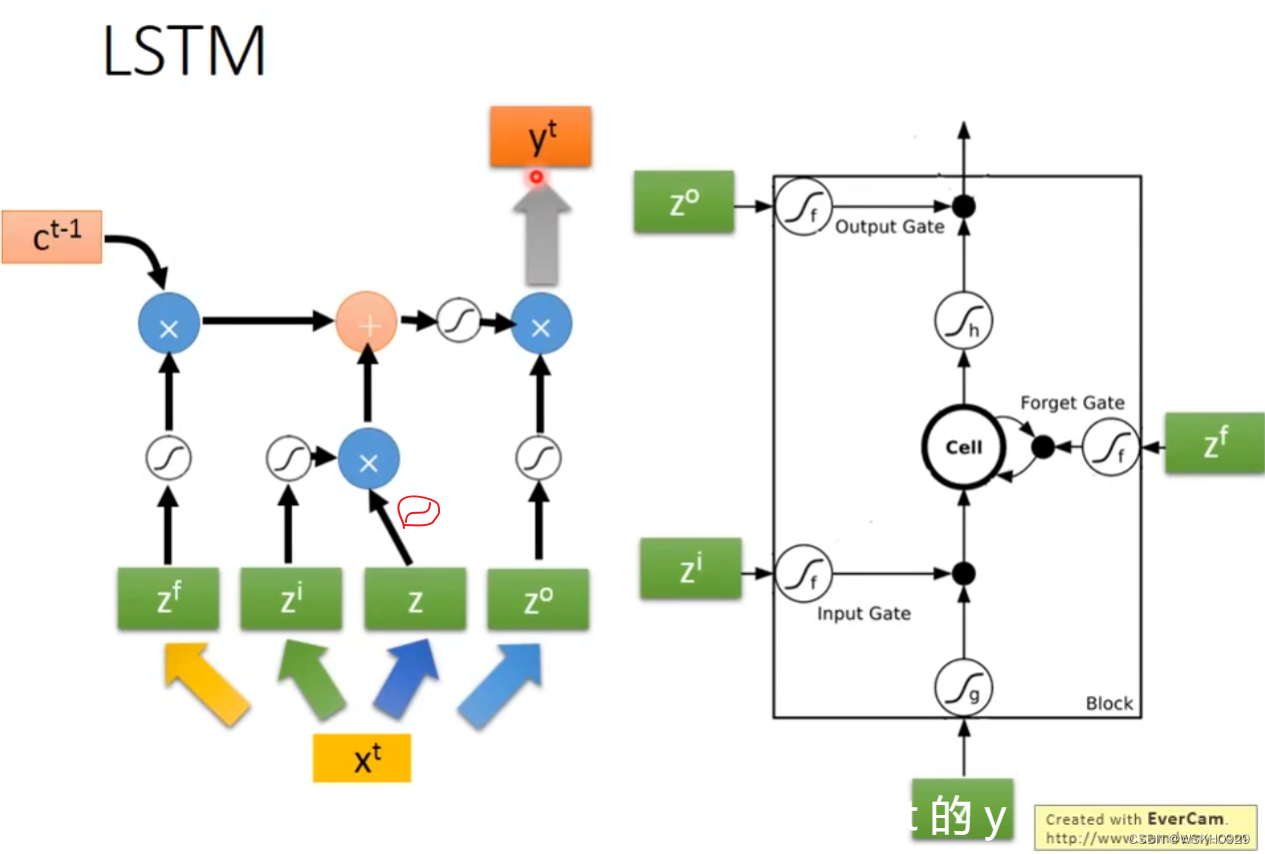
下面是一个LSTM单元的实际结构。来自上一阶段的输出 z z z 作为当前阶段的输入, z z z 经过激活函数后变为 g ( z ) g(z) g(z) , g ( z ) g(z) g(z) 再受到输入门影响,变为 g ( z ) f ( z i ) g(z)f(z_i) g(z)f(zi)。再看中间的蓝色部分,此时它还是原本的历史信息 c c c,经过遗忘门影响得到 c f ( z f ) cf(z_f) cf(zf),然后 g ( z ) f ( z i ) + c f ( z f ) g(z)f(z_i)+cf(z_f) g(z)f(zi)+cf(zf) 得到 c ′ c' c′, c ′ c' c′ 就是新的历史信息,然后讲 c ′ c' c′输出,经过激活函数变为 h ( c ′ ) h(c') h(c′),再受到输出门影响变为 h ( c ′ ) f ( z o ) h(c')f(z_o) h(c′)f(zo),于是就得到了最终的输出: a = h ( c ′ ) f ( z o ) a=h(c')f(z_o) a=h(c′)f(zo)
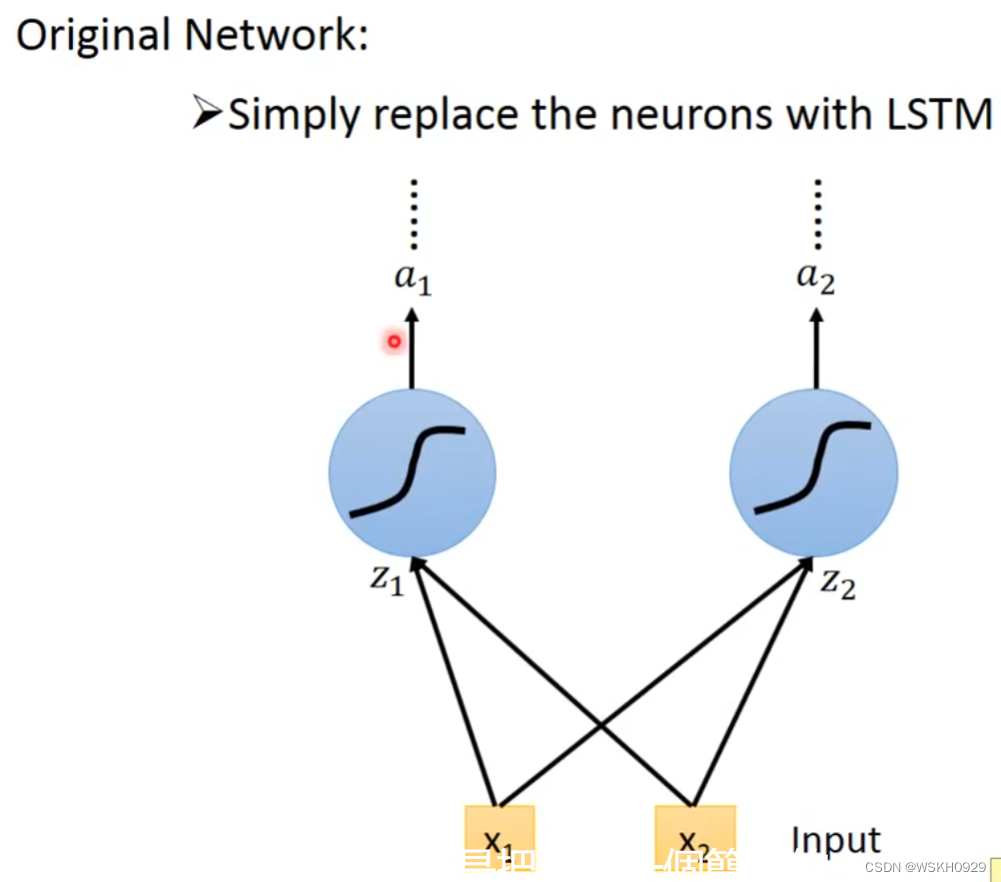
那么LSTM单元在神经网络单元里是怎么连接的呢?下面先看普通的神经网络神经元和输入之间的连接
然后再把LSTM当作一个特殊的神经元,从下图我们可以看出,由于LSTM多出了三个门,所以输入需要额外地与LSTM进行3次连接,即LSTM需要4个Input,这也就意味着LSTM的参数量是普通神经元的4倍
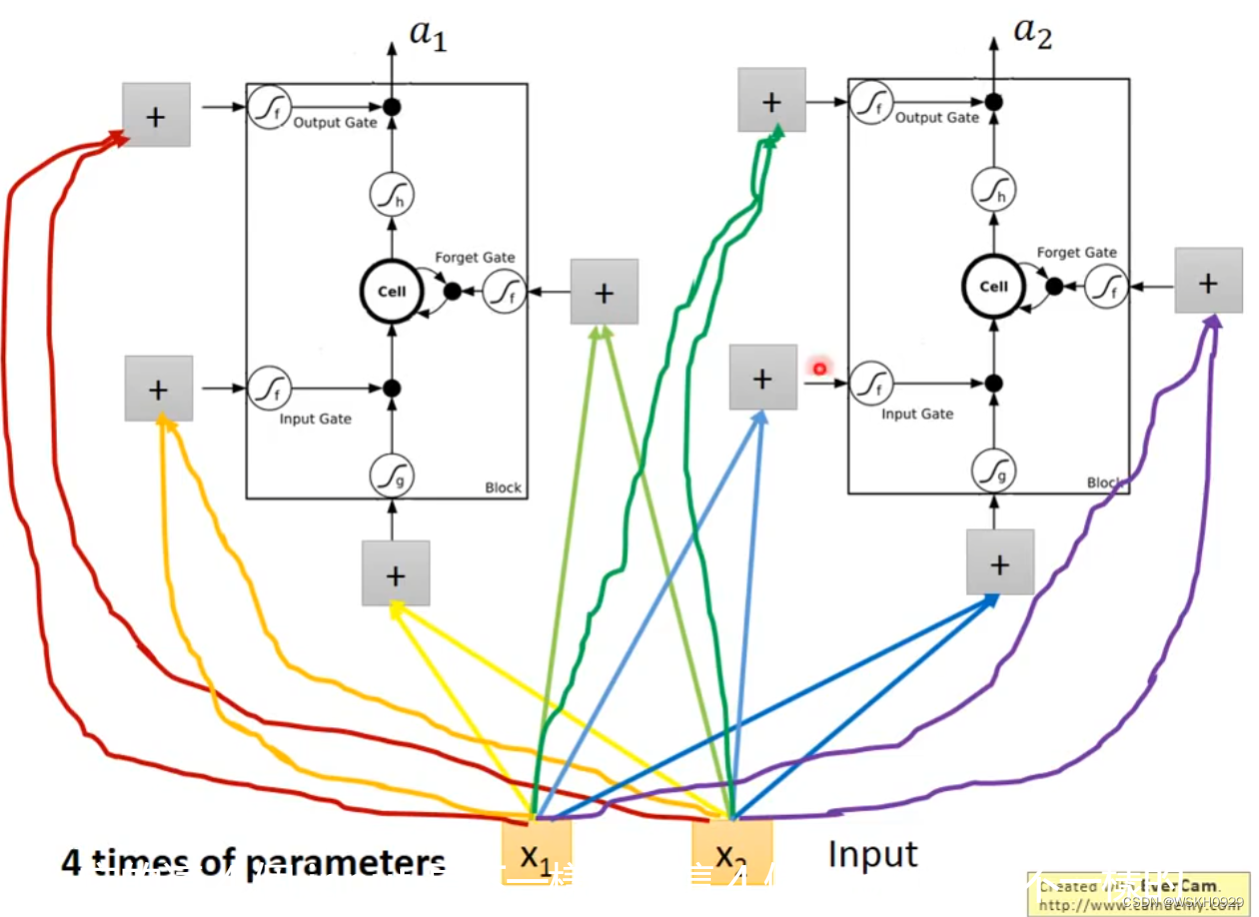
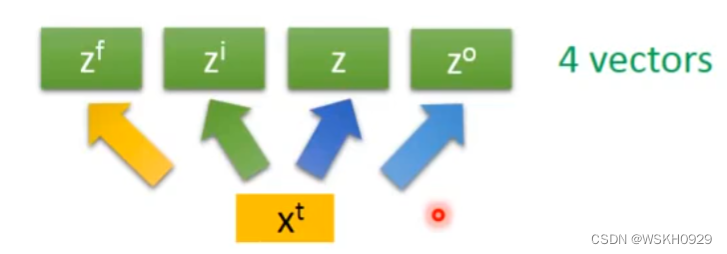
实际中,假设 第 t t t 个词汇的向量输入为 x t x^t xt,首先会将其进行变换为 z z z, z z z 的某一个维度数就等于它对接的那一层的LSTM单元的数量,对应LSTM的输入。
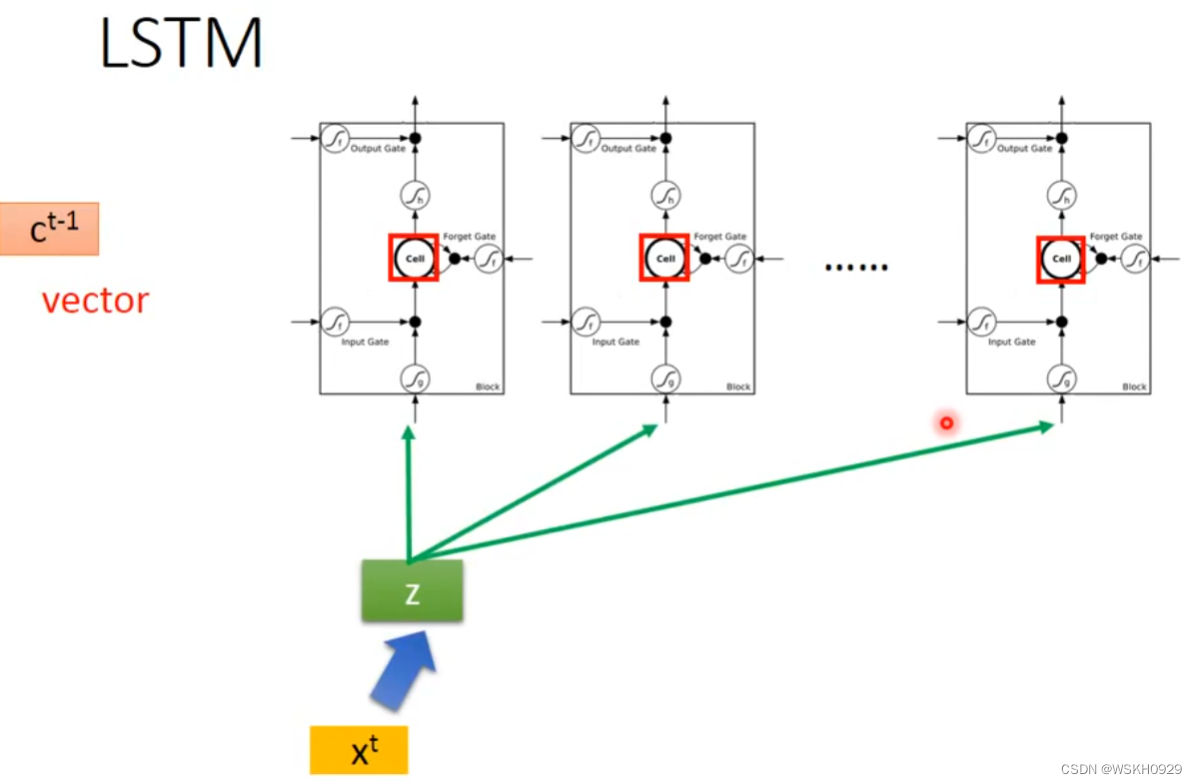
x t x^t xt 还会进行变换为 z i z^i zi,对应LSTM的输入门
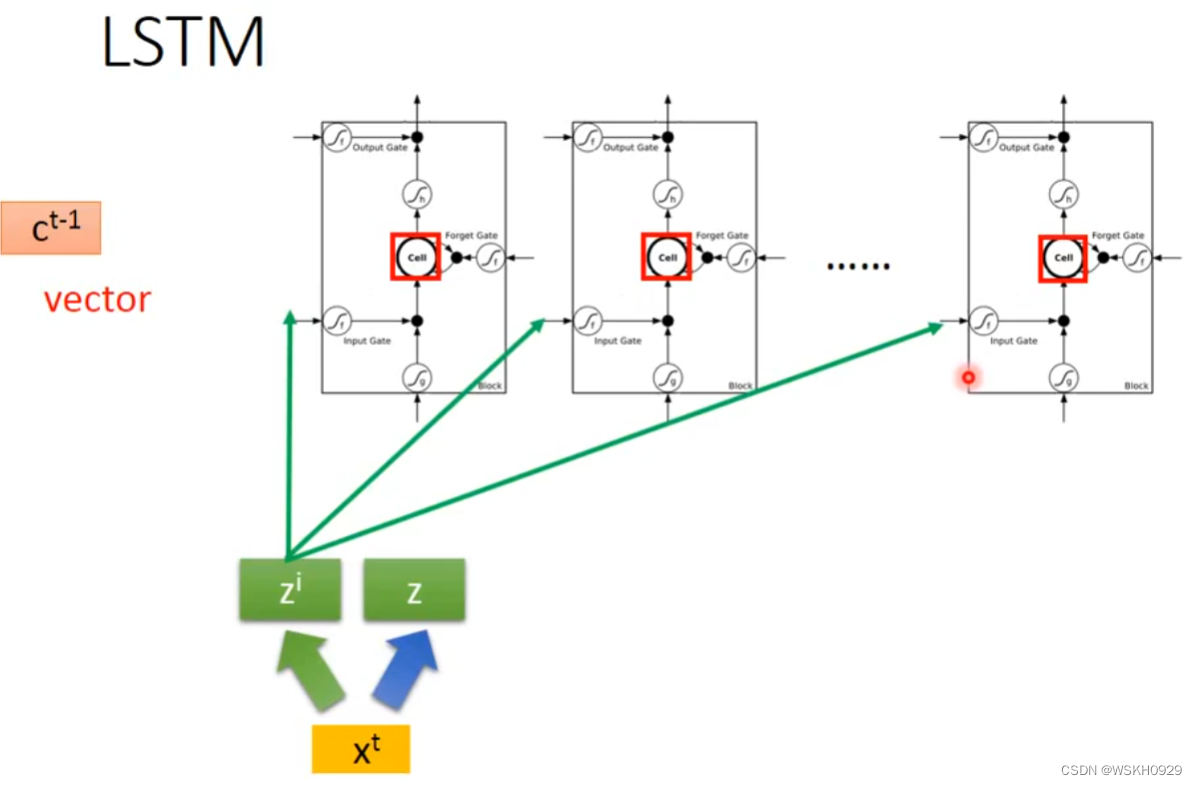
同样的, x t x^t xt 还会进行变换为 z f z^f zf 和 z o z^o zo,分别对应LSTM的遗忘门和输出门
接下来,让我们用结构图表示一下LSTM的传播流程(按照下图右边的LSTM结构,下图左边, z z z 出来那根线应该少了个激活函数,我用红笔画出来了)
然后是同层之间,LSTM单元的连接(如下图所示),即不同词汇间的连接,记忆的传递
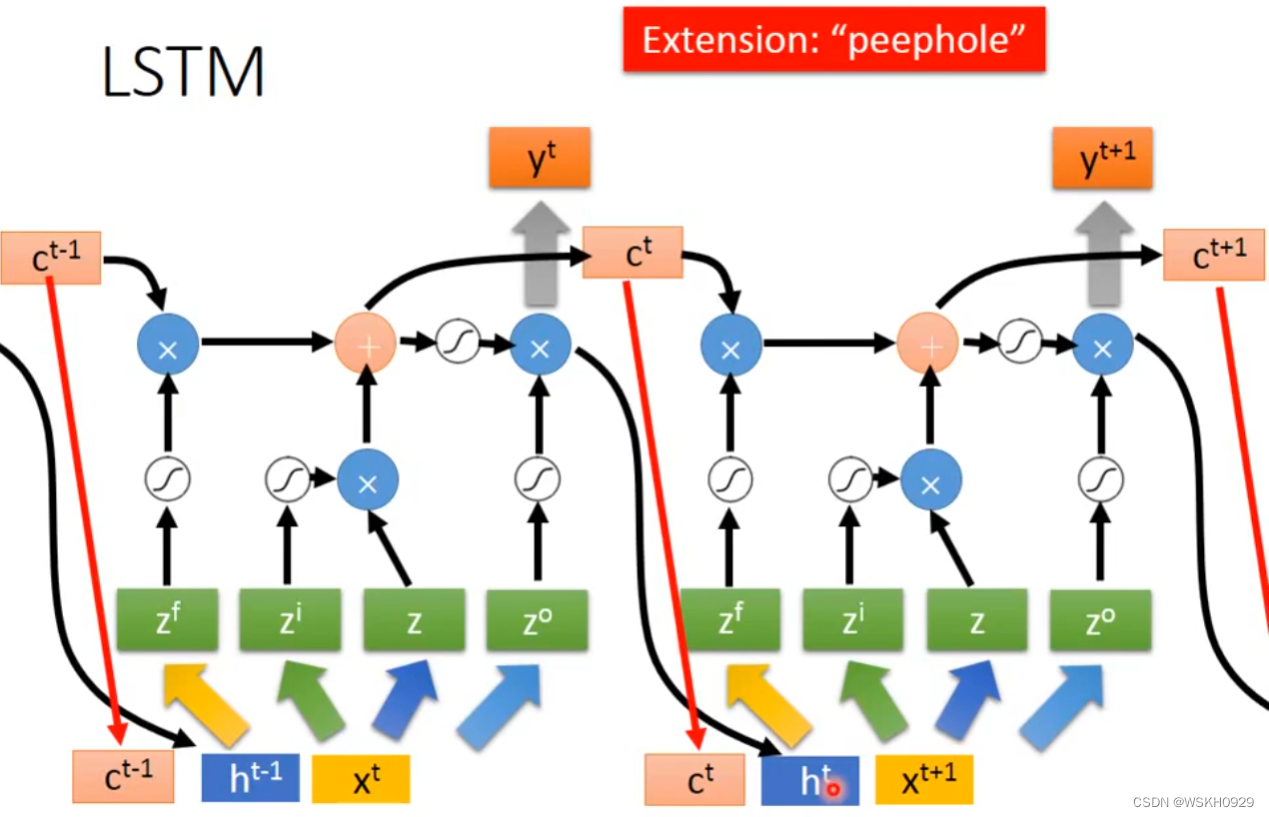
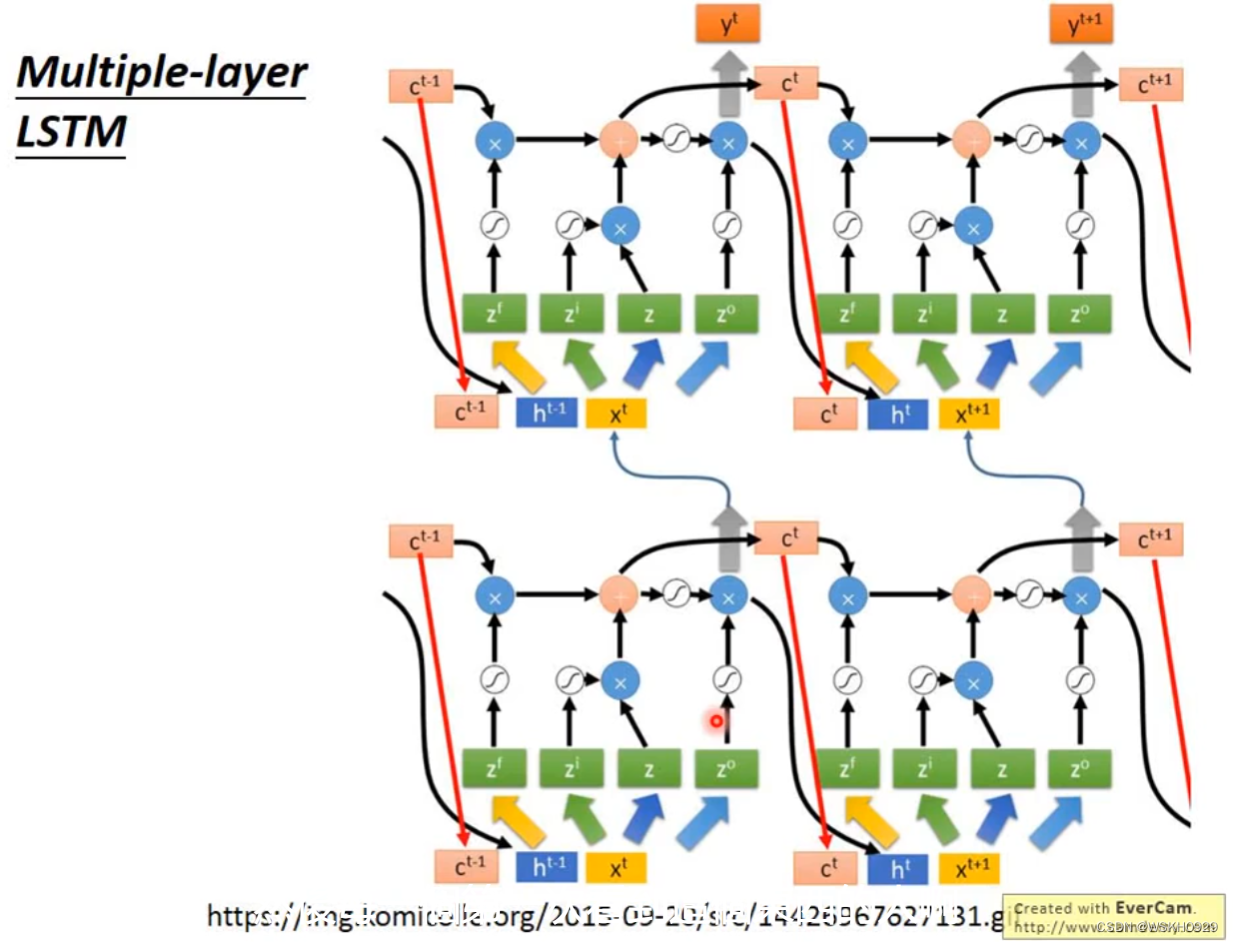
然后是多层的LSTM
五、Learning Target
每个词汇都有一个概率输出,表示其属于每个Slot的概率。损失函数就用交叉熵损失。目标是使得预测整个语句的交叉熵总和最小。
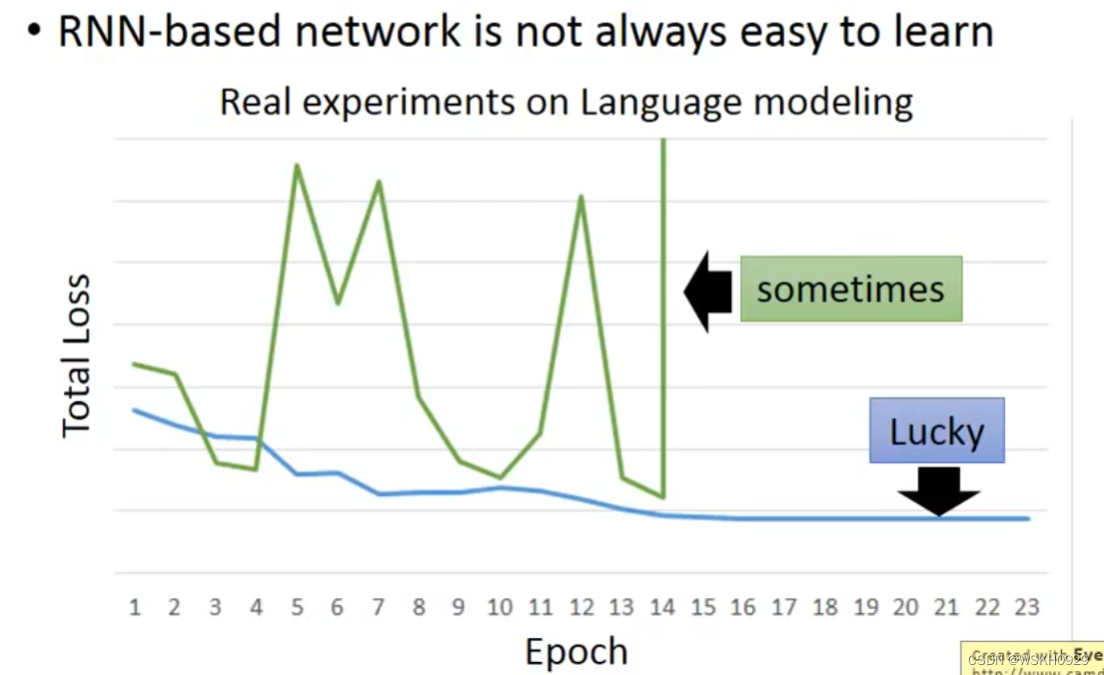
六、RNN 很难 Train
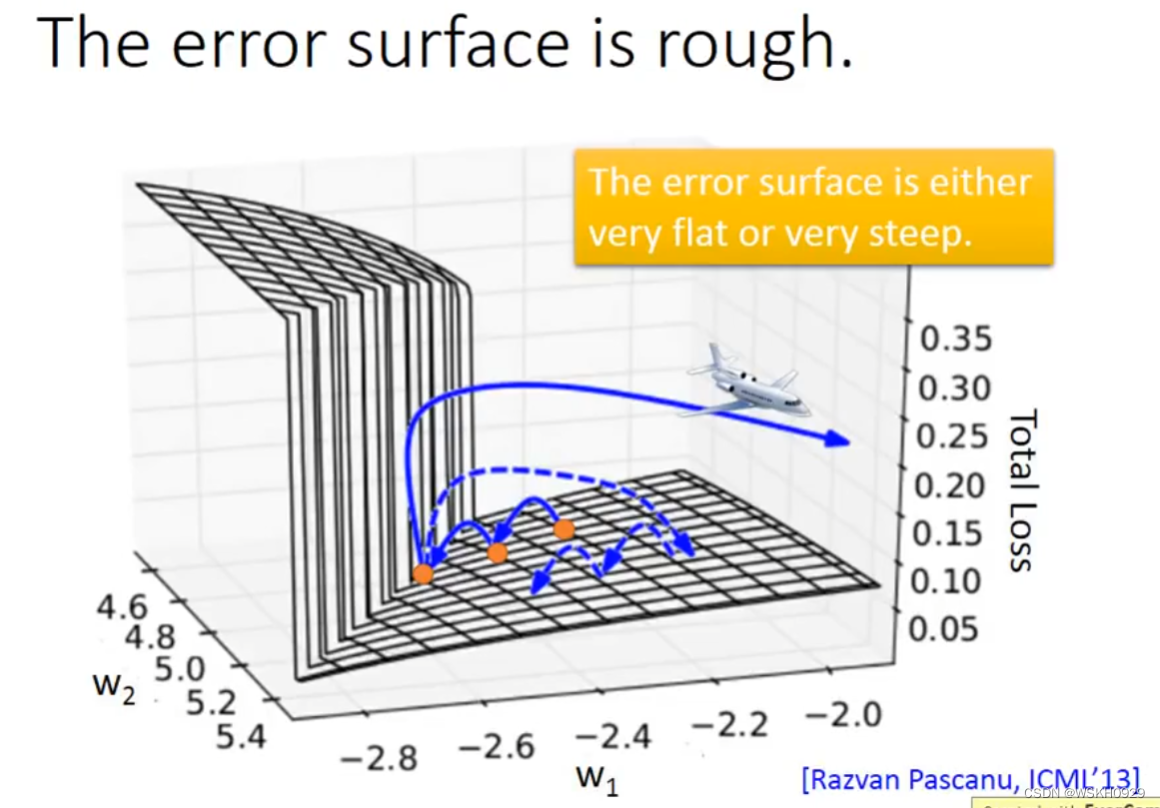
事实上,RNN是很难Train的,在RNN刚被提出时,很少有人能Train起来。其Loss曲线通常如下图绿线所示,蓝线是正常的Loss曲线。
为什么RNN如此难 Train ? 有人做了相关研究,发现是因为RNN的error surface的某些区域非常陡峭,在陡峭的区域,就可能导致参数只改动一点,却使得Loss产生巨大的变化。假设从橙色的点用gradient decent 开始调整参数两次,正好跳过悬崖,loss暴增;有时可能正好踩在悬崖上,悬崖上的gradient 很大,之前的都很小,可能learning rate就很大,很大的gradient 和learning rate就导致参数飞出去了。
Tips:可以采用clipping策略,当gradient 大于某个值的时候,直接令梯度等于该值,防止梯度过大。同样的方法可以用来防止梯度过小。
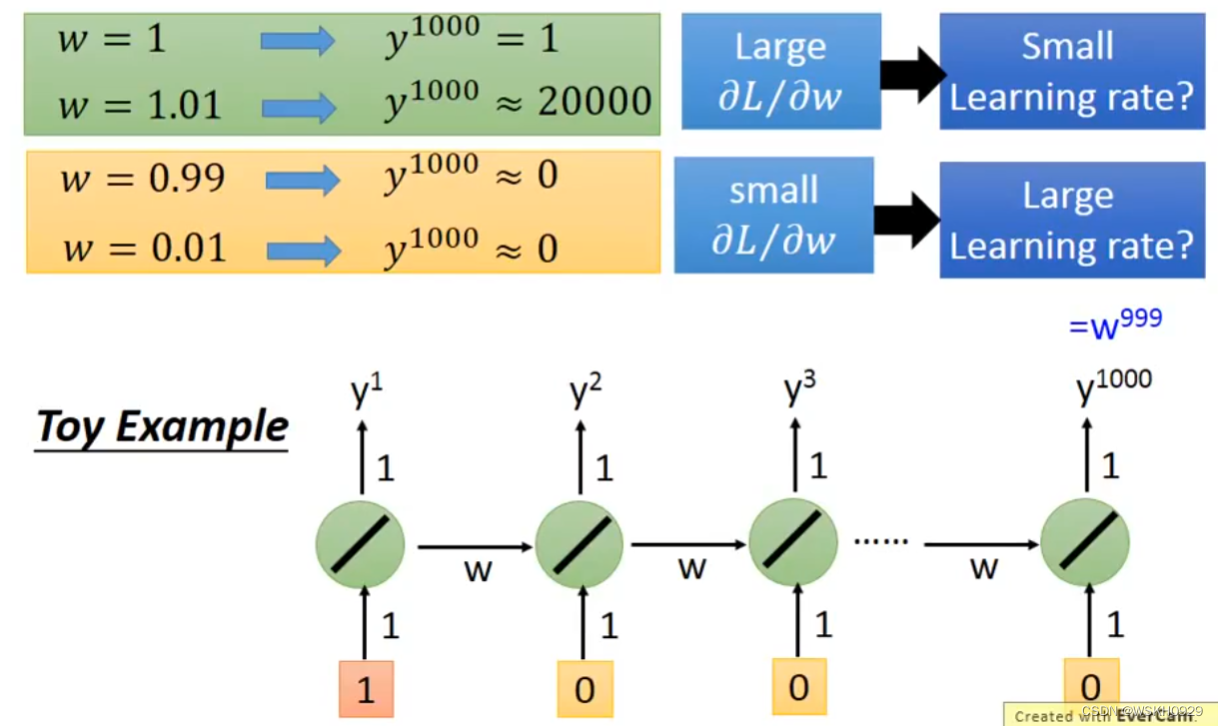
下面用一个详细的例子让大家感受一下。假设有一个包含1000个RNN的单层神经网络,假设除了第一个RNN单元的输入为1,其余均为0,假设所有RNN单元均没有偏置 b 。
- 当所有RNN单元的w为1时, y 1000 = 1 y^{1000}=1 y1000=1
- 当所有RNN单元的w为1.01时, y 1000 ≈ 20000 y^{1000}≈20000 y1000≈20000
可以看出,w仅仅改变了0.01,就导致 y 1000 y{1000} y1000 的输出相差近20000倍。
七、Helpful Techniques
那么针对第六节提出的问题,有什么技巧可以帮我们解决该问题呢?本节就来介绍解决该问题的技术。
7.1 LSTM
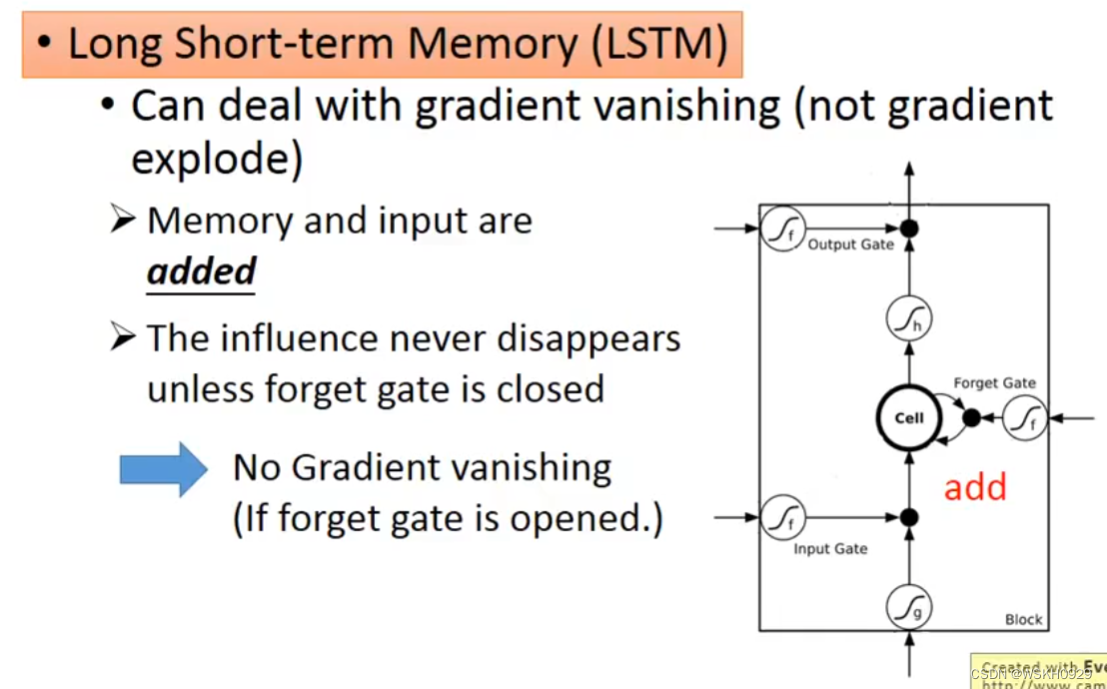
其实,使用LSTM就可以解决这个问题,它可以让 error surface 不要那么陡峭,从而缓解该问题
问:为什么LSTM可以让梯度变小呢?(梯度变小的意思就是不那么陡峭)
答:RNN中,每个时间点,Memory里的咨询会被覆盖。但是在LSTM中,它的Memory是加权叠加性的,所以原来存在Memory里的值基本都会有所残留。(这也是因为,遗忘门很少情况为0)
7.2 GRU
GRU 和LSTM一样,也可以解决该问题
想了解GRU工作原理可以参考这篇文章: 人人都能看懂的GRU

7.3 Others
八、Many To One
之前讲的 Slot Filling 的例子是 Many To Many 的,即输入是向量序列,输出也是向量序列且长度和输入相同
那么 Many To One 指的就是 输入是向量序列,但是输出仅仅只是一个向量 的问题,下面会讲 Many To One 的实际应用
8.1 Sentiment Analysis 情绪分析
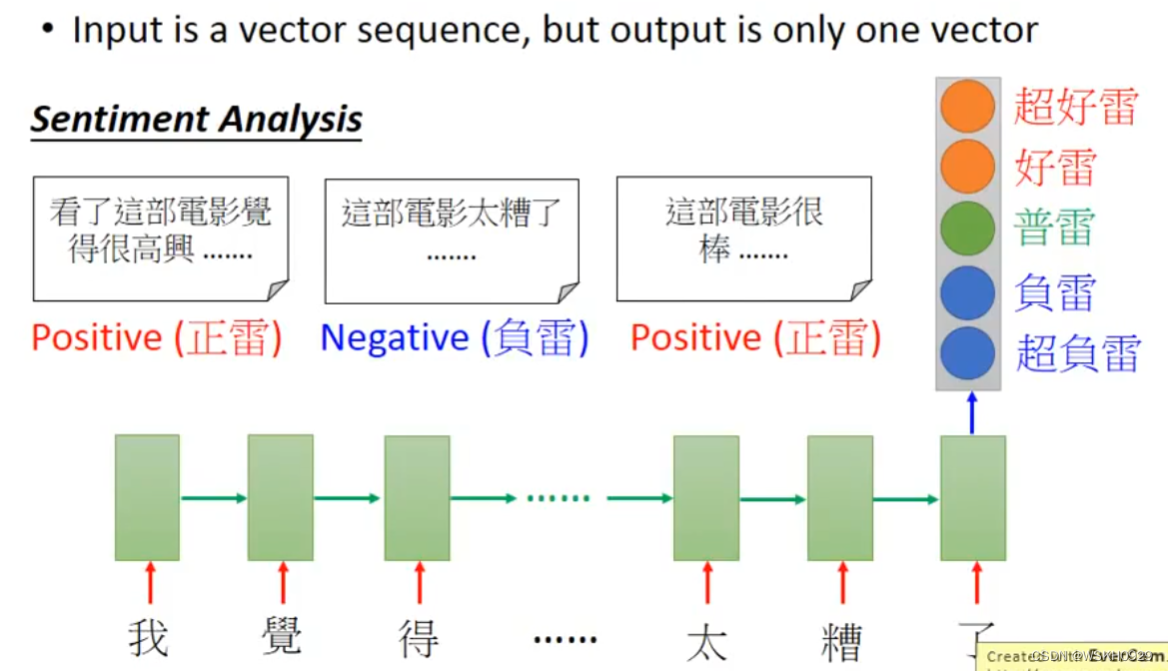
8.2 Key Term Extraction 关键词提取
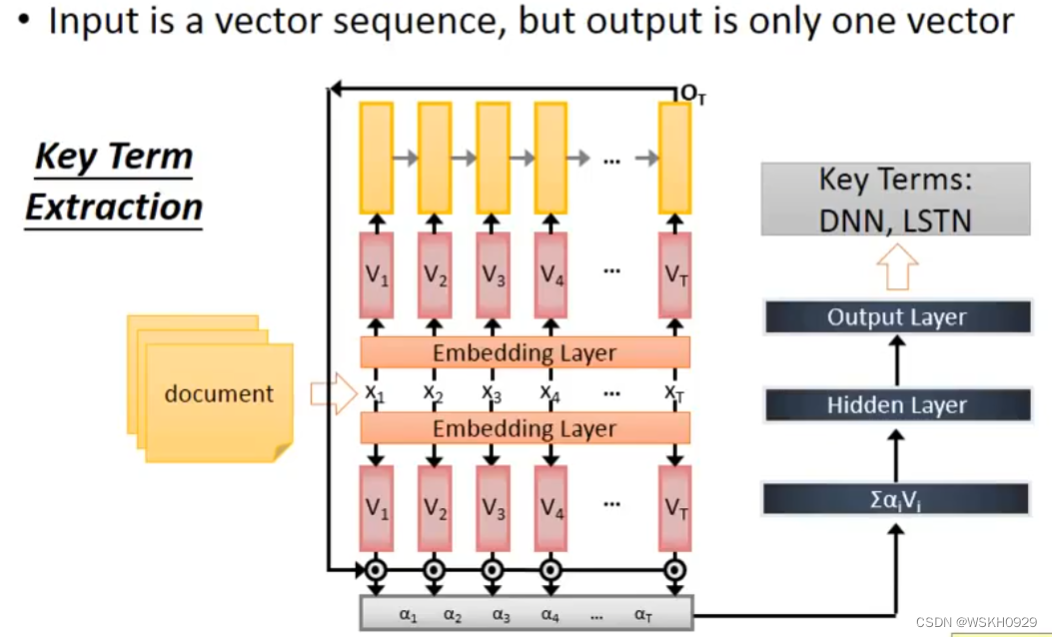
九、Many To Many(Output is shorter)
9.1 Speech Recognition 语音辨识
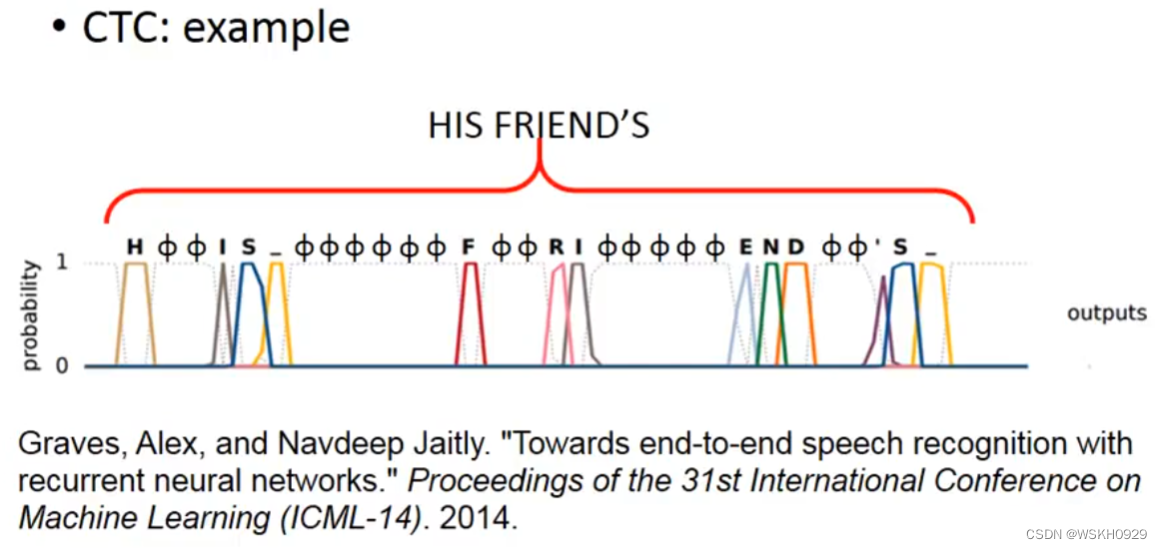
常用的方法叫CTC,即定义一个代表空的符号,然后在得到Output的时候,讲空符号去掉,剩下的就是真正的Output
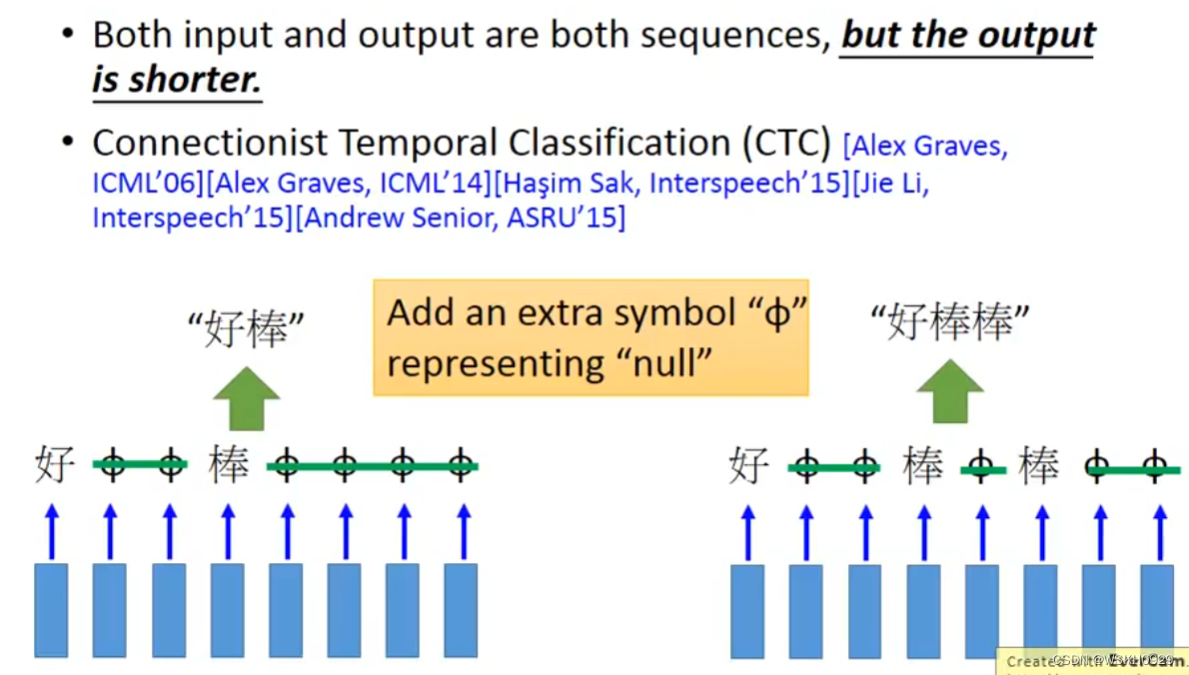
在用CTC法进行Train的时候,我们认为去掉代表空的符号之后是“好棒”的所有排列组合都是正确的
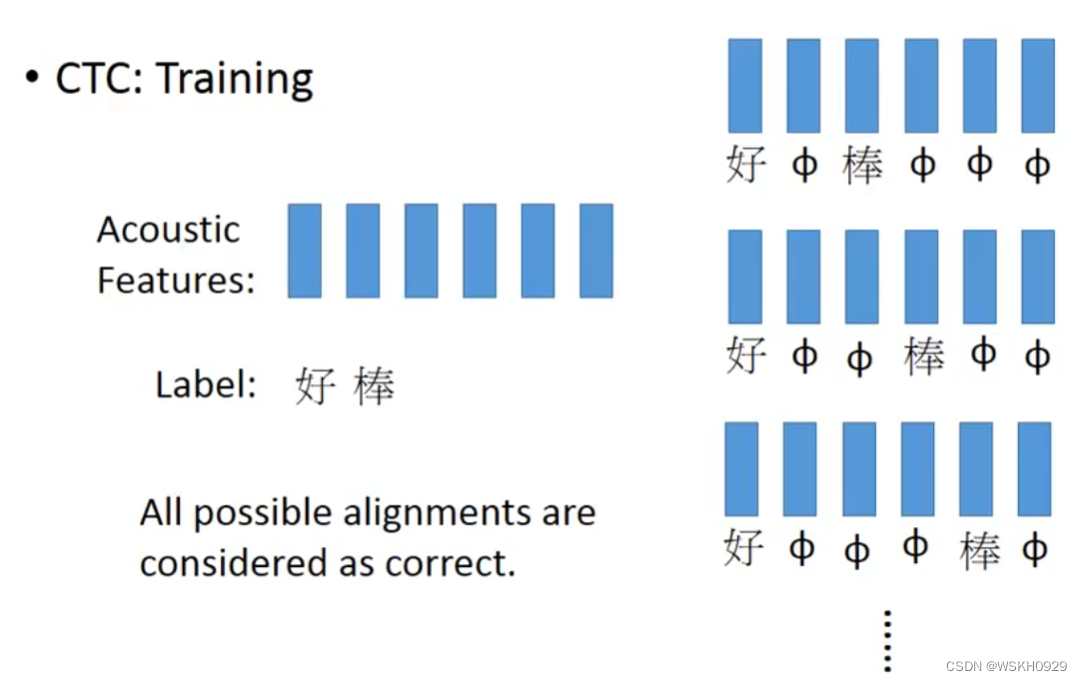
下面是一个CTC的例子,最终得到识别结果为 “HIS FRIEND’S”
十、Many To Many(No Limitation)
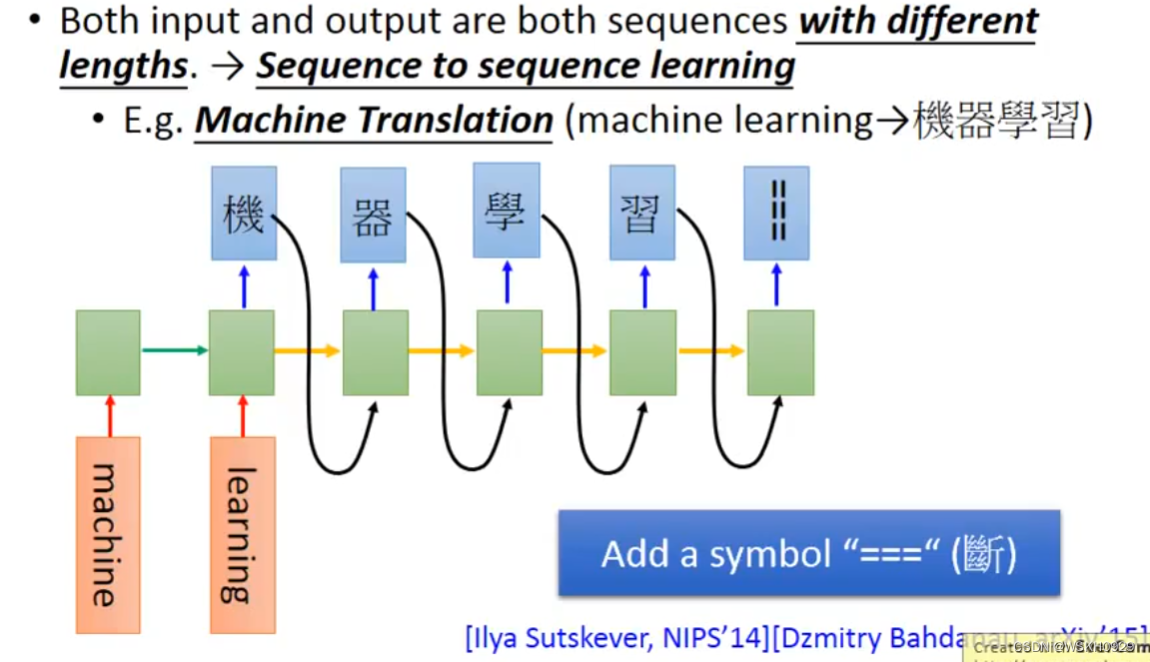
十一、Beyond Sequence
输出树结构的数据。方法:把树结构描述成一个序列进行训练。
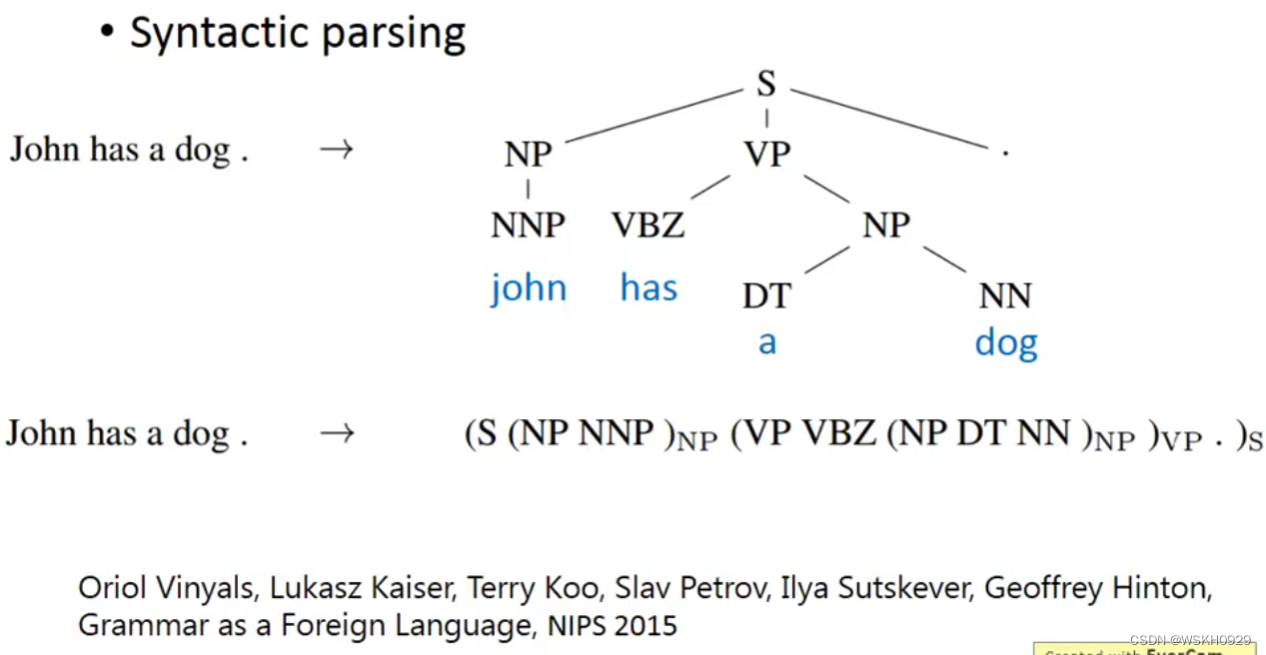
十二、Sequence To Sequence Auto Encoder
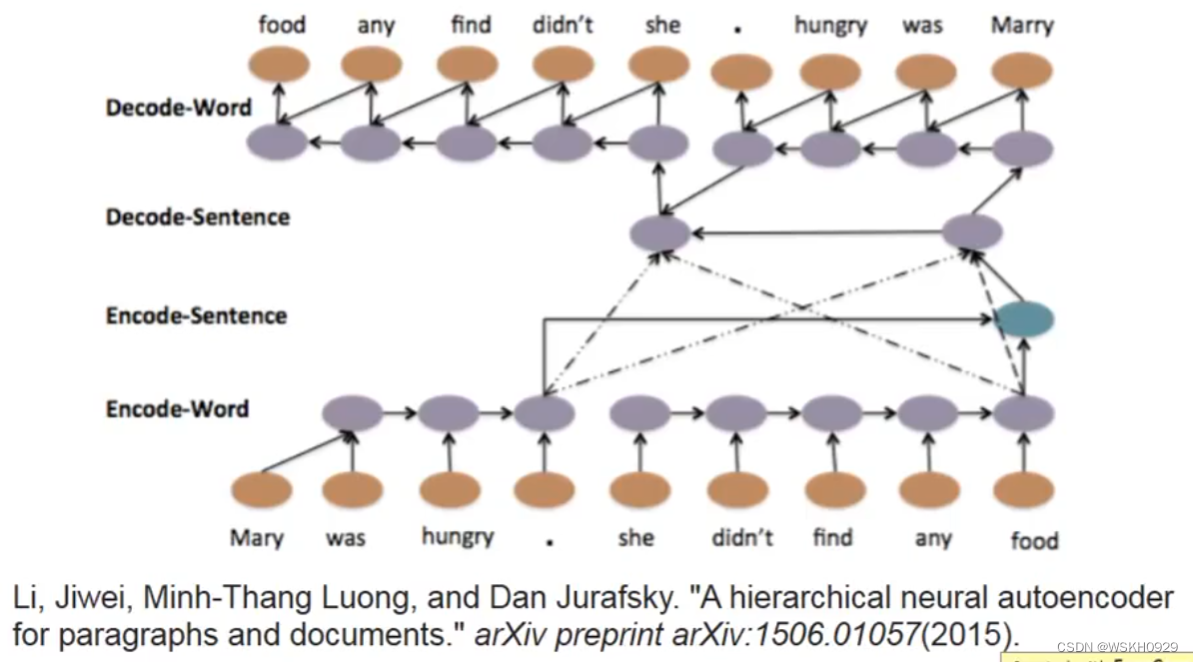
12.1 Text
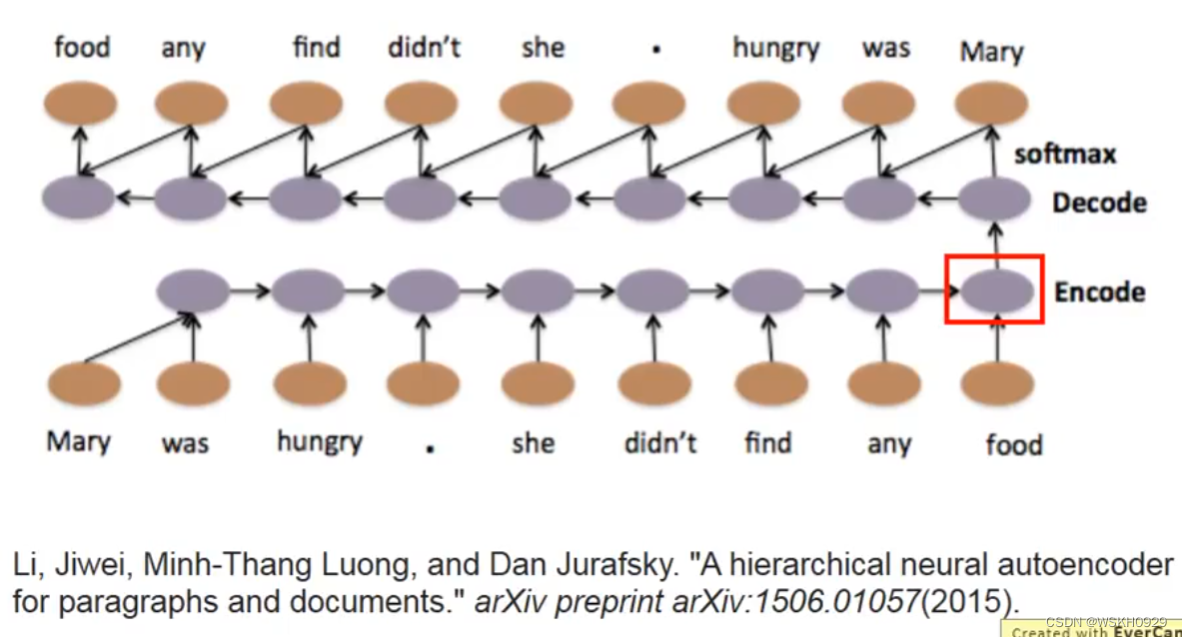
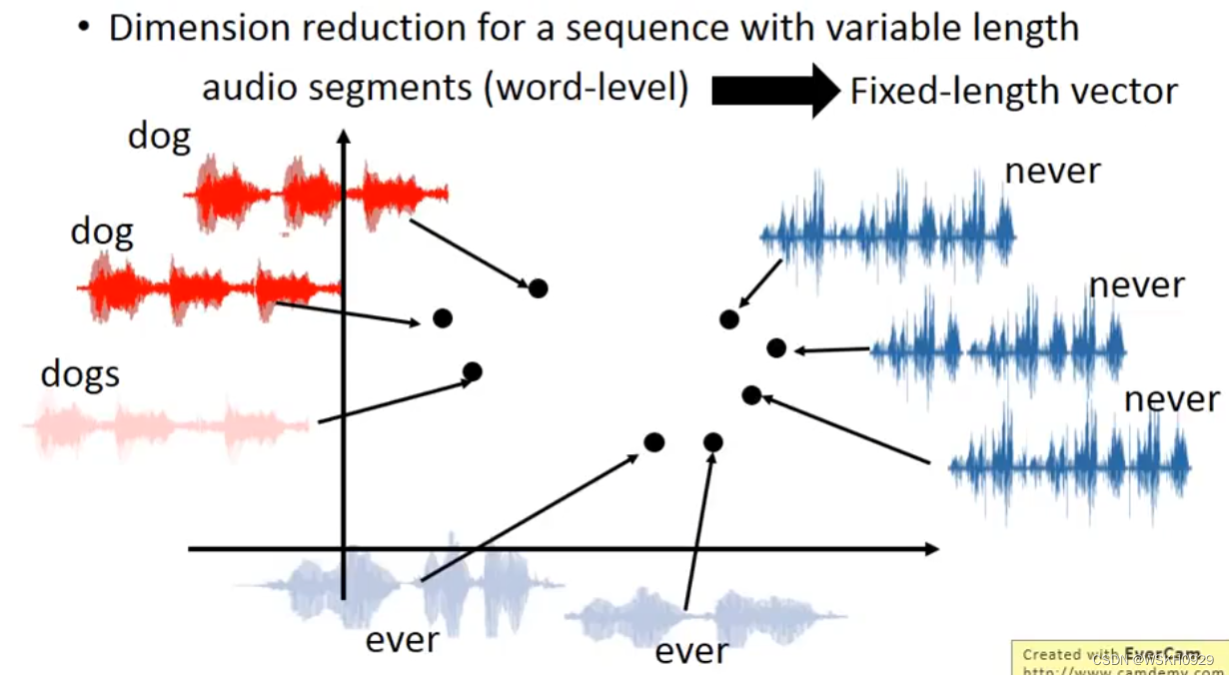
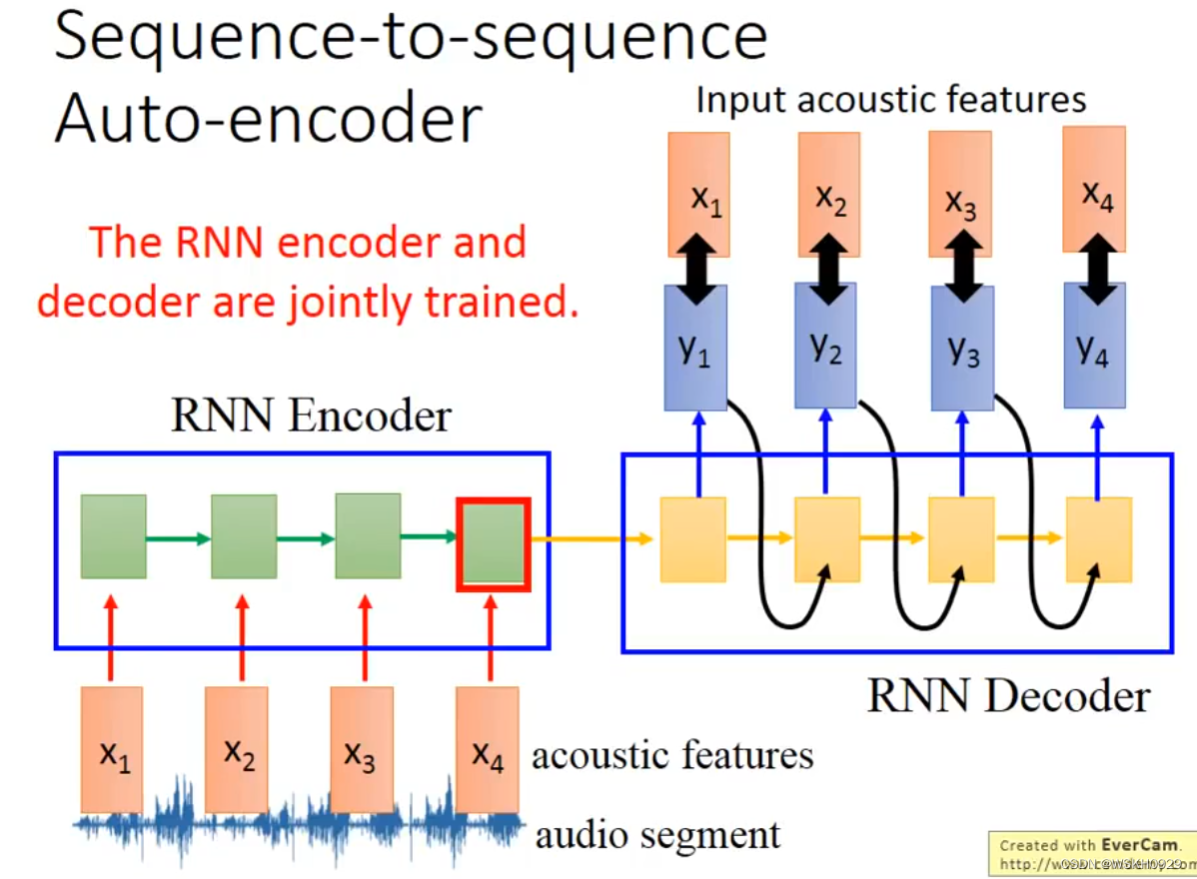
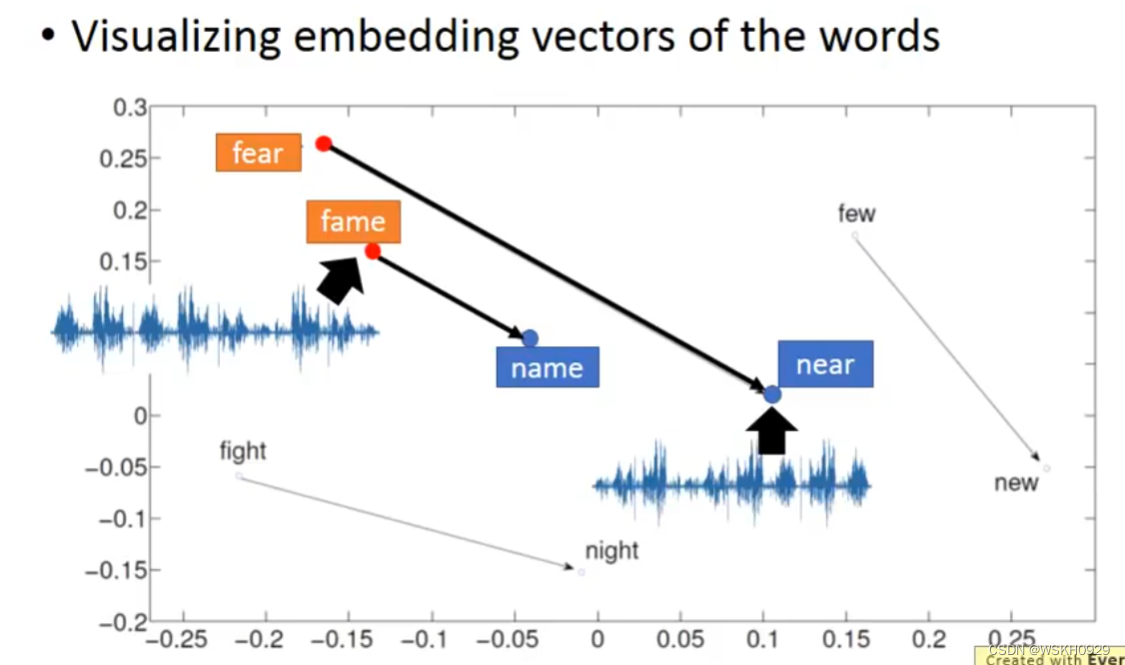
12.2 Speech
讲语音编码为向量,可以用于比较语音的相似程度
十三、Demo:Chat-bot 聊天机器人
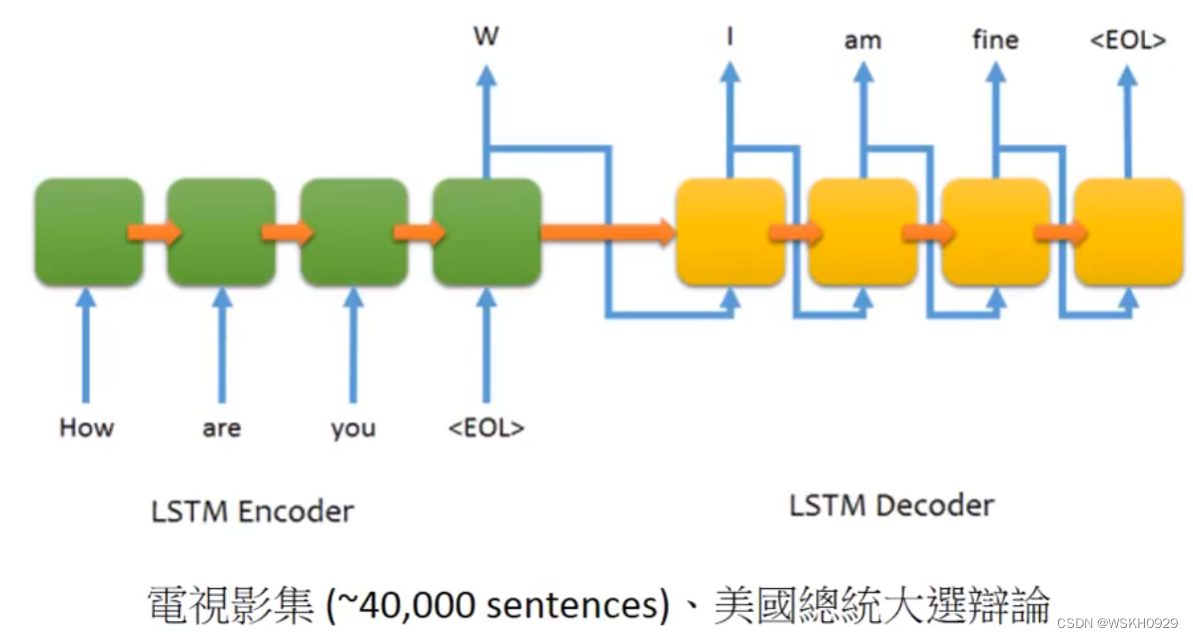
十四、Attention-based Model
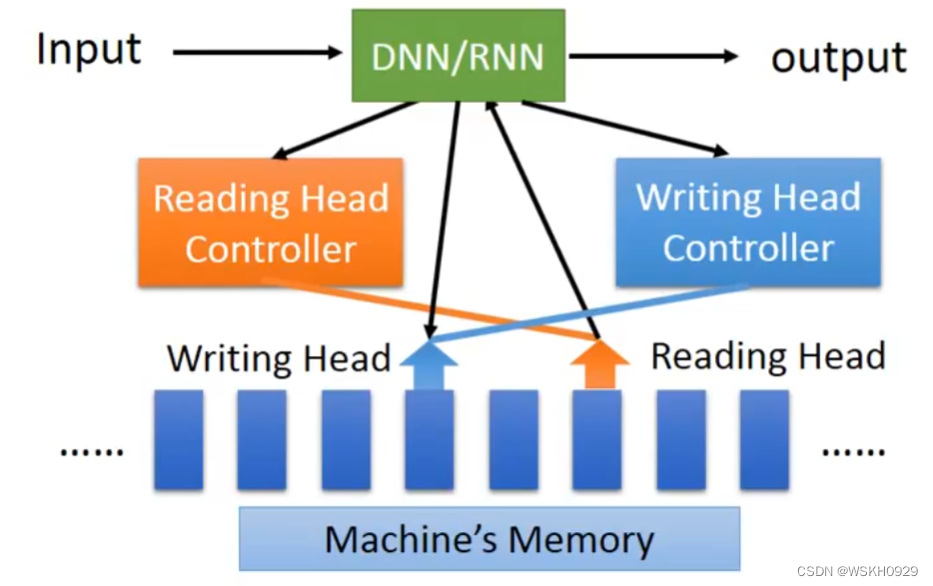
十五、Reading Comprehension 阅读理解
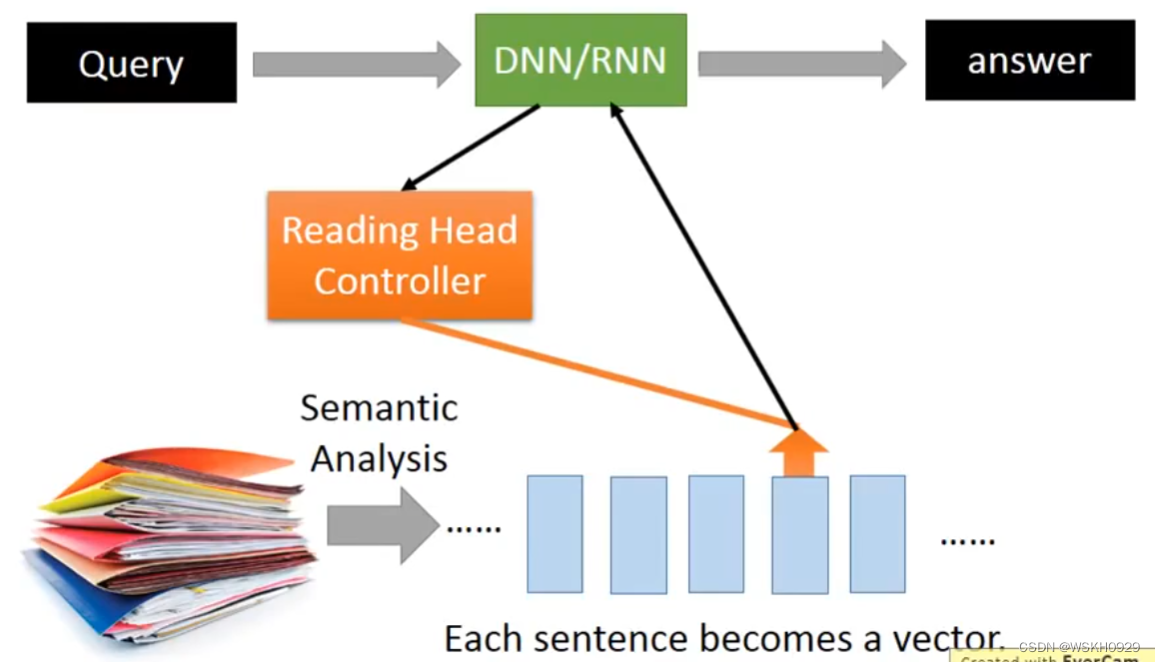
十六、Visual Question Answering 可视化答题
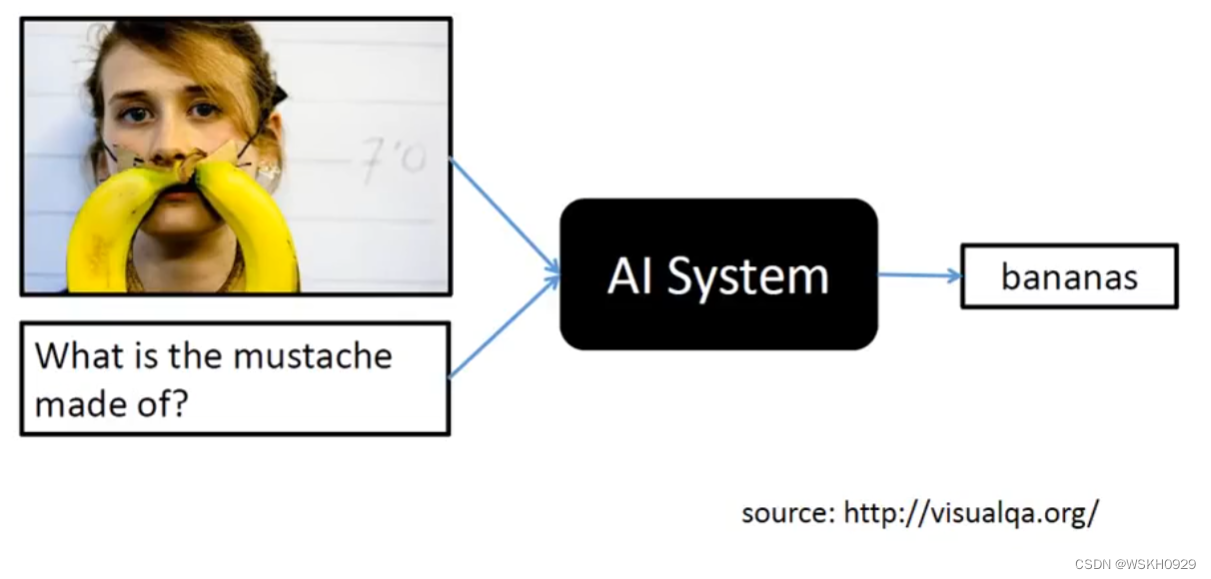
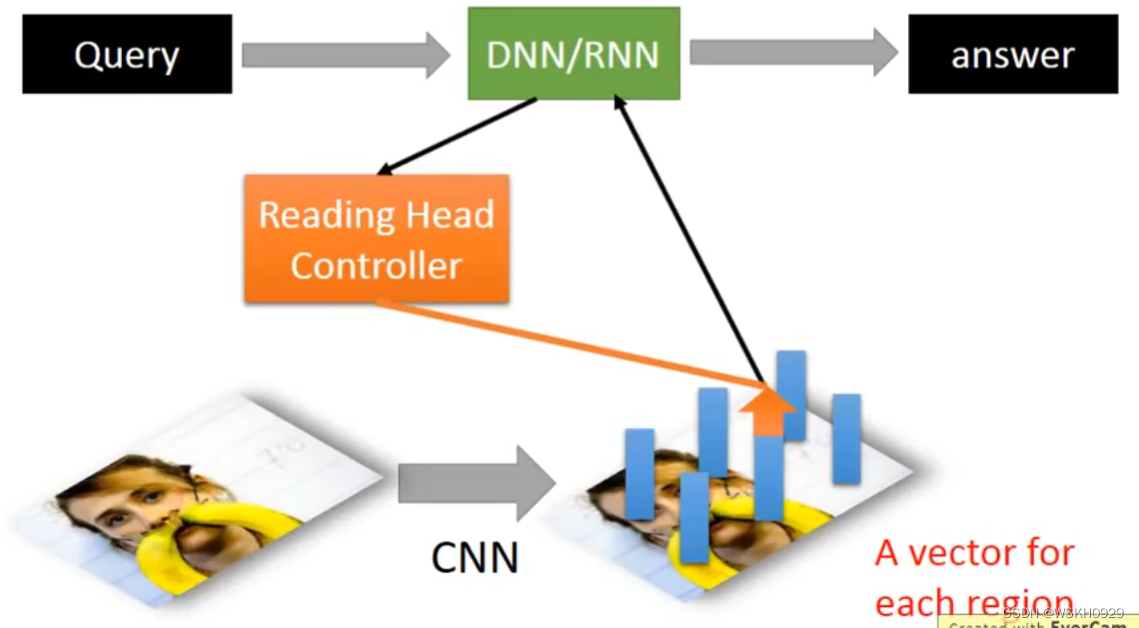
十七、Speech Question Answering 语音问题解答

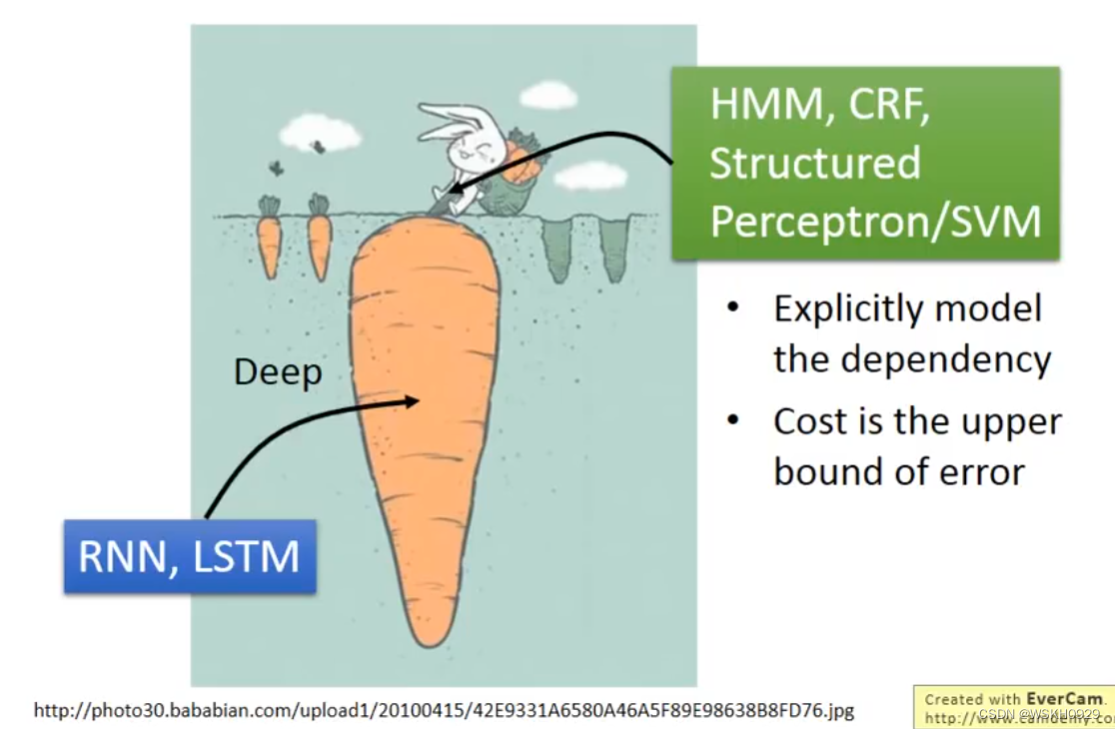
十八、RNN vs Structured Learning
可以Deep Learning,是非常强的

但是他们两个可以结合。即将先用RNN提取到较好的讯息,然后再传给 Structured Learning 的模型进行接下来的步骤。这样可以结合两个模型的优势。


![[附源码]Python计算机毕业设计非处方药的查询与推荐系统Django(程序+LW)](https://img-blog.csdnimg.cn/71fdb38623bb481f821877e52ddbb4b0.png)
![[ vulhub漏洞复现篇 ] struts2远程代码执行漏洞s2-059(CVE-2019-0230)](https://img-blog.csdnimg.cn/b6672e2d9bd34a539d4364b2db053d15.png)


![[附源码]Nodejs计算机毕业设计基于Web的在线音乐网站Express(程序+LW)](https://img-blog.csdnimg.cn/5b0960558e204976acdfd9359a8e564b.png)