🌟【技术大咖愚公搬代码:全栈专家的成长之路,你关注的宝藏博主在这里!】🌟
📣开发者圈持续输出高质量干货的"愚公精神"践行者——全网百万开发者都在追更的顶级技术博主!
👉 江湖人称"愚公搬代码",用七年如一日的精神深耕技术领域,以"挖山不止"的毅力为开发者们搬开知识道路上的重重阻碍!
💎【行业认证·权威头衔】
✔ 华为云天团核心成员:特约编辑/云享专家/开发者专家/产品云测专家
✔ 开发者社区全满贯:CSDN博客&商业化双料专家/阿里云签约作者/腾讯云内容共创官/掘金&亚马逊&51CTO顶级博主
✔ 技术生态共建先锋:横跨鸿蒙、云计算、AI等前沿领域的技术布道者
🏆【荣誉殿堂】
🎖 连续三年蝉联"华为云十佳博主"(2022-2024)
🎖 双冠加冕CSDN"年度博客之星TOP2"(2022&2023)
🎖 十余个技术社区年度杰出贡献奖得主
📚【知识宝库】
覆盖全栈技术矩阵:
◾ 编程语言:.NET/Java/Python/Go/Node…
◾ 移动生态:HarmonyOS/iOS/Android/小程序
◾ 前沿领域:物联网/网络安全/大数据/AI/元宇宙
◾ 游戏开发:Unity3D引擎深度解析
每日更新硬核教程+实战案例,助你打通技术任督二脉!
💌【特别邀请】
正在构建技术人脉圈的你:
👍 如果这篇推文让你收获满满,点击"在看"传递技术火炬
💬 在评论区留下你最想学习的技术方向
⭐ 点击"收藏"建立你的私人知识库
🔔 关注公众号获取独家技术内参
✨与其仰望大神,不如成为大神!关注"愚公搬代码",让坚持的力量带你穿越技术迷雾,见证从量变到质变的奇迹!✨ |
文章目录
- 🚀前言
- 🚀一、编写 Item Pipeline
- 🔎1.项目管道的核心方法
- 🔎2.将信息存储至数据库
🚀前言
在前几篇文章中,我们已经学习了如何搭建 Scrapy 爬虫框架,并掌握了 Scrapy 的基本应用。本篇文章中,我们将深入探讨 Scrapy 中的一个重要组件——Item Pipeline。
Item Pipeline 是 Scrapy 框架中用于处理抓取到的数据的关键部分。通过 Item Pipeline,我们可以对抓取到的数据进行清洗、验证、存储等一系列处理操作,实现数据从网页到最终存储的全流程管理。理解并正确使用 Item Pipeline,将极大提升我们爬虫项目的数据处理效率和质量。
在本篇文章中,我们将会学习到:
- Item Pipeline 的基本概念和作用:了解 Item Pipeline 在 Scrapy 项目中的地位和功能。
- 如何编写和配置 Item Pipeline:从定义和编写 Pipeline 到在项目中进行配置与使用。
- 数据清洗与验证:如何在 Pipeline 中进行数据清洗和验证,以确保数据的准确性和一致性。
- 数据存储:将抓取到的数据存储到各种存储后端,如文件、数据库等。
- 多个 Pipeline 的使用:如何在项目中配置和使用多个 Pipeline,灵活处理不同的数据处理需求。
通过本篇文章的学习,你将全面掌握 Scrapy Item Pipeline 的使用技巧,能够实现对抓取数据的高效处理和存储,使你的爬虫项目更加完整和可靠。
🚀一、编写 Item Pipeline
当爬取的数据被存储在 Item 对象后,Spider(爬虫)解析完 Response(响应结果)后,Item 会传递到 Item Pipeline(项目管道)中。通过自定义的管道类可实现数据清洗、验证、去重及存储到数据库等操作。
🔎1.项目管道的核心方法
Item Pipeline 的主要用途:
- 清理 HTML 数据
- 验证数据(检查字段完整性)
- 去重处理
- 存储数据至数据库
自定义 Pipeline 需实现的方法:
| 方法 | 说明 |
|---|---|
process_item() | 必须实现。处理 Item 对象,参数为 item(Item对象)和 spider(爬虫对象)。 |
open_spider() | 爬虫启动时调用,用于初始化操作(如连接数据库)。 |
close_spider() | 爬虫关闭时调用,用于收尾工作(如关闭数据库连接)。 |
from_crawler() | 类方法(需 @classmethod 装饰),返回实例对象并获取全局配置信息。 |
示例代码框架:
import pymysql
class CustomPipeline:
def __init__(self, host, database, user, password, port):
# 初始化数据库参数
self.host = host
self.database = database
self.user = user
self.password = password
self.port = port
@classmethod
def from_crawler(cls, crawler):
# 从配置中读取数据库参数
return cls(
host=crawler.settings.get('SQL_HOST'),
database=crawler.settings.get('SQL_DATABASE'),
user=crawler.settings.get('SQL_USER'),
password=crawler.settings.get('SQL_PASSWORD'),
port=crawler.settings.get('SQL_PORT')
)
def open_spider(self, spider):
# 连接数据库
self.db = pymysql.connect(
host=self.host,
user=self.user,
password=self.password,
database=self.database,
port=self.port,
charset='utf8'
)
self.cursor = self.db.cursor()
def close_spider(self, spider):
# 关闭数据库连接
self.db.close()
def process_item(self, item, spider):
# 处理数据并插入数据库
data = dict(item)
sql = 'INSERT INTO table_name (col1, col2) VALUES (%s, %s)'
self.cursor.execute(sql, (data['field1'], data['field2']))
self.db.commit()
return item
🔎2.将信息存储至数据库
实现步骤:
-
数据库准备
- 安装 MySQL,创建数据库
jd_data和数据表ranking(包含book_name,author,press字段)。
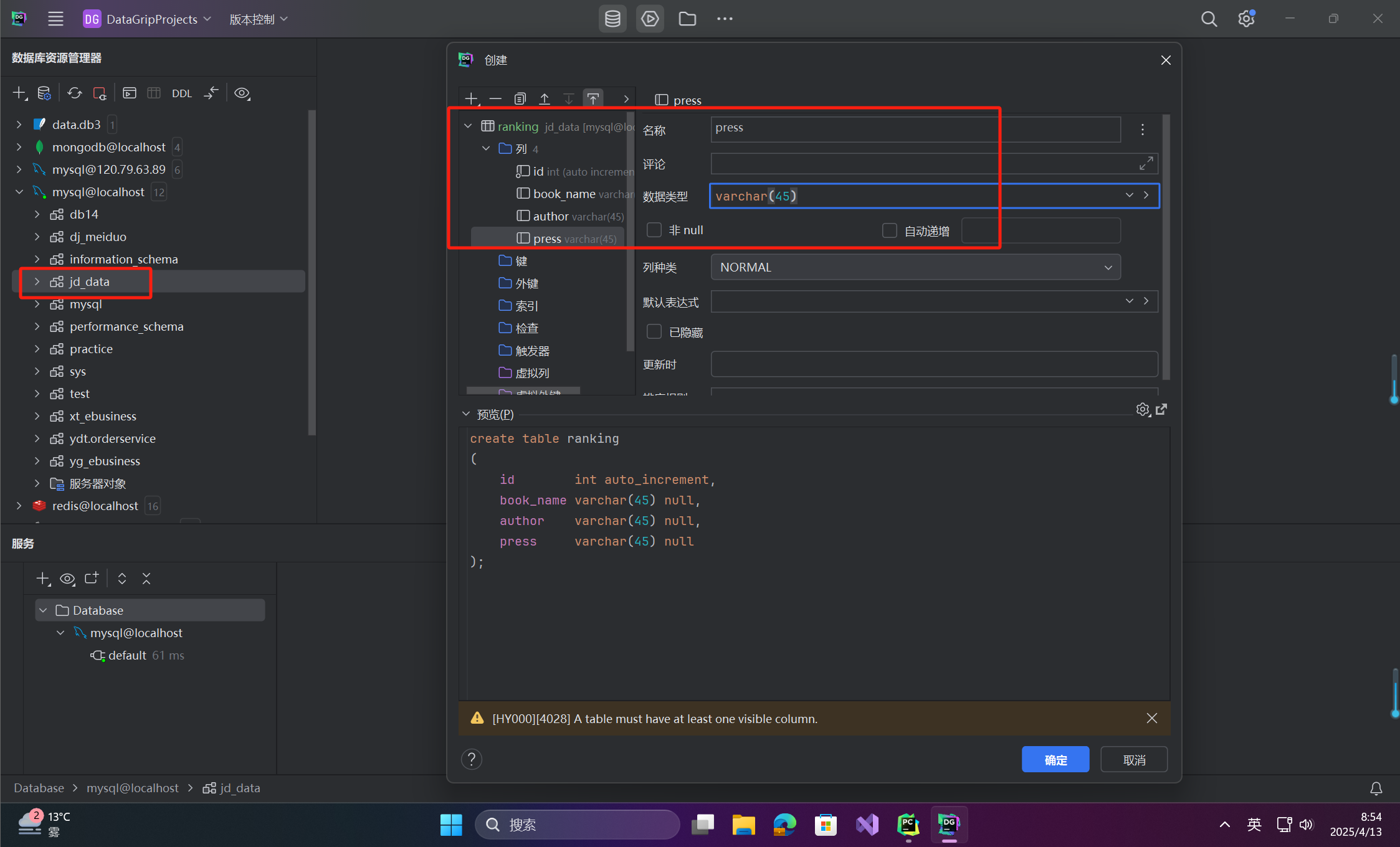
- 安装 MySQL,创建数据库
-
创建 Scrapy 项目
scrapy startproject jd cd jd scrapy genspider jdSpider book.jd.com -
定义 Item(items.py)
import scrapy class JdItem(scrapy.Item): book_name = scrapy.Field() # 图书名称 author = scrapy.Field() # 作者 press = scrapy.Field() # 出版社 -
编写爬虫(jdSpider.py)
# -*- coding: utf-8 -*- import scrapy from jd.items import JdItem # 导入JdItem类 class JdspiderSpider(scrapy.Spider): name = 'jdSpider' # 默认生成的爬虫名称 allowed_domains = ['book.jd.com'] start_urls = ['http://book.jd.com/'] def start_requests(self): # 需要访问的地址 url = 'https://book.jd.com/booktop/0-0-0.html?category=3287-0-0-0-10001-1' yield scrapy.Request(url=url, callback=self.parse) # 发送网络请求 def parse(self, response): all=response.xpath(".//*[@class='p-detail']") # 获取所有信息 book_name = all.xpath("./a[@class='p-name']/text()").extract() # 获取所有图书名称 author = all.xpath("./dl[1]/dd/a[1]/text()").extract() # 获取所有作者名称 press = all.xpath("./dl[2]/dd/a/text()").extract() # 获取所有出版社名称 item = JdItem() # 创建Item对象 # 将数据添加至Item对象 item['book_name'] = book_name item['author'] = author item['press'] = press yield item # 打印item信息 pass # 导入CrawlerProcess类 from scrapy.crawler import CrawlerProcess # 导入获取项目设置信息 from scrapy.utils.project import get_project_settings # 程序入口 if __name__=='__main__': # 创建CrawlerProcess类对象并传入项目设置信息参数 process = CrawlerProcess(get_project_settings()) # 设置需要启动的爬虫名称 process.crawl('jdSpider') # 启动爬虫 process.start() -
配置管道(pipelines.py)
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html import pymysql # 导入数据库连接pymysql模块 class JdPipeline(object): # 初始化数据库参数 def __init__(self,host,database,user,password,port): self.host = host self.database = database self.user = user self.password = password self.port = port @classmethod def from_crawler(cls,crawler): # 返回cls()实例对象,其中包含通过crawler获取配置文件中的数据库参数 return cls( host=crawler.settings.get('SQL_HOST'), user=crawler.settings.get('SQL_USER'), password=crawler.settings.get('SQL_PASSWORD'), database = crawler.settings.get('SQL_DATABASE'), port = crawler.settings.get('SQL_PORT') ) # 打开爬虫时调用 def open_spider(self, spider): # 数据库连接 self.db = pymysql.connect(self.host,self.user,self.password,self.database,self.port,charset='utf8') self.cursor = self.db.cursor() #床架游标 # 关闭爬虫时调用 def close_spider(self, spider): self.db.close() def process_item(self, item, spider): data = dict(item) # 将item转换成字典类型 # sql语句 sql = 'insert into ranking (book_name,press,author) values(%s,%s,%s)' # 执行插入多条数据 self.cursor.executemany(sql, list(zip(data['book_name'], data['press'], data['author']))) self.db.commit() # 提交 return item # 返回item -
激活管道(settings.py)
ITEM_PIPELINES = { 'jd.pipelines.JdPipeline': 300, } SQL_HOST = 'localhost' SQL_USER = 'root' SQL_PASSWORD = 'root' SQL_DATABASE = 'jd_data' SQL_PORT = 3306 -
运行爬虫
from scrapy.crawler import CrawlerProcess from scrapy.utils.project import get_project_settings if __name__ == '__main__': process = CrawlerProcess(get_project_settings()) process.crawl('jdSpider') process.start()
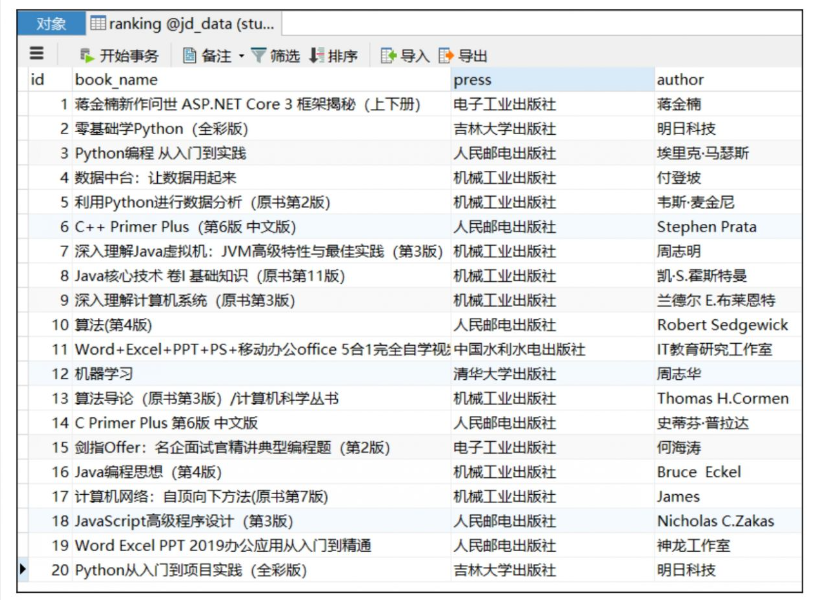
注意事项
- 确保已安装
pymysql:pip install pymysql - 若出现编码问题,可在 MySQL 连接参数中添加
charset='utf8mb4'。 - 数据库表字段需与
Item中定义的字段一致。





![[react]Next.js之自适应布局和高清屏幕适配解决方案](https://i-blog.csdnimg.cn/direct/4494b56f3c2b419681cb1cdf6d04361d.png)