文章目录
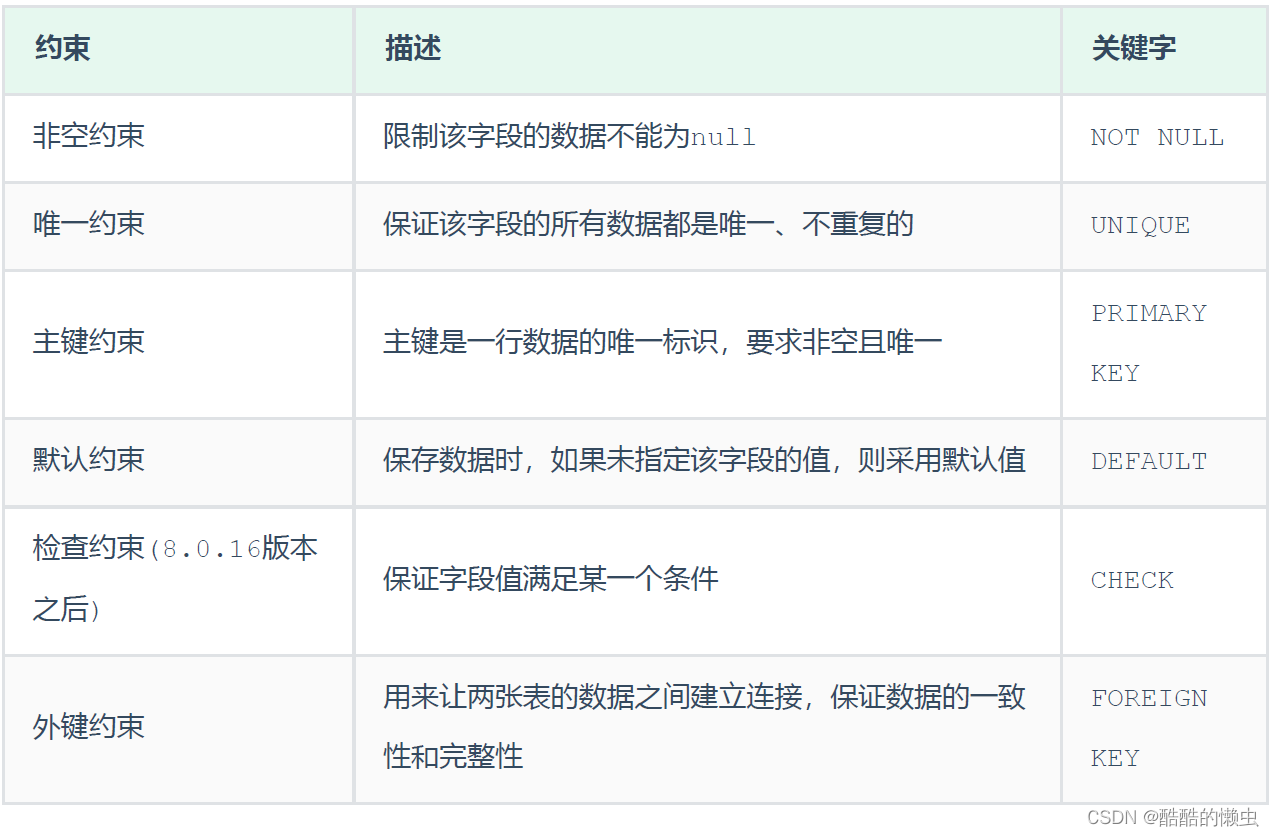
- 主要思路
- 1. 串行归并排序
- 2. 进程的分发
- 3. 对接收到的子数组进行排序
- 4. 合并数组
- 5.输出排序后的数组
- 6.进程分发部分的优化
- 7.完整代码
主要思路
- 我们首先实现串行的归并排序;
- 实现进程的分发;
- 排序其中的每个子部分;
- 进程的合并通信,并实现对有序子数组的归并(注意,这里的合并复杂度应该是O(n)的,不然并行就失去了意义)。
通过以上4步,就可以实现并行的归并排序了。
1. 串行归并排序
// 归并排序,输入一个vector的引用
void mergeSort(vector<int>& vec) {
if (vec.size() <= 1) return;
int mid = vec.size() / 2;
vector<int> left(vec.begin(), vec.begin() + mid);
vector<int> right(vec.begin() + mid, vec.end());
mergeSort(left);
mergeSort(right);
int i = 0, j = 0, k = 0;
while (i < left.size() && j < right.size()) {
if (left[i] < right[j]) {
vec[k++] = left[i++];
}
else {
vec[k++] = right[j++];
}
}
while (i < left.size()) {
vec[k++] = left[i++];
}
while (j < right.size()) {
vec[k++] = right[j++];
}
}
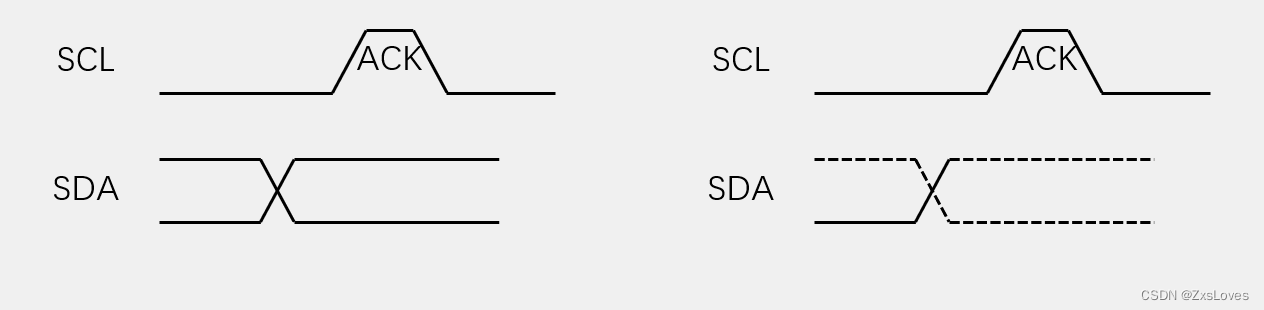
2. 进程的分发
进程如何分发?看下面这张图:

这里就需要计算数组的划分次数,到底划分多少份?每个进程一份。
我起初实现了一个很简单的做法,就是由 0进程 来划分,然后分发给其它进程。
if (myrank == 0) {
// 计算每个进程分配完,多余出来的数量
int remain = numberNums % processNum;
// 主进程 排序 自己的 + 多余出来的
subVec = vector<int>(vec.begin(), vec.begin() + n + remain);
for (int i = 1; i < processNum; i++) {
MPI_Send(vec.data() + i * n + remain, n,
MPI_INT, i, 0, MPI_COMM_WORLD);
}
}
else {
// 接收数组
MPI_Recv(subVec.data(), n, MPI_INT,
0, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
}
其中的 numberNums 表示数组大小,processNum 表示进程数量。
值得注意的是,如果数组没有被进程刚好划分,也就是有余数(remain),我是这样处理的,让 0进程 来多排序一下,最终划分结果即:
0进程:排序n+remain个;其它进程:排序n个。
3. 对接收到的子数组进行排序
这一步比较简单,对于每一个进程都是相同的,即:排序(干活)。
// 对接收到的子数组进行排序
mergeSort(subVec);
4. 合并数组
数组的合并的主要思路如下:

就是两两进行合并,注意,这里不是一个进程合并所有其它的,那样的时间复杂度是 O ( n 2 ) O(n^2) O(n2),即合并操作是在一个进程中完成的。
我们需要让合并的操作再多个进程中完成,这样时间复杂度为 O ( n l o g n ) O(nlogn) O(nlogn)(注:这里没有考虑进程通信的成本,也没有考虑的必要)
我们首先需要计算出合并的次数,合并的次数是由进程的数量决定的。
如果有 8 个进程,那么我们两两合并,需要合并 3 = l o g 2 ( 8 ) 3=log_2(8) 3=log2(8) 次。
那么如果有 7 个进程呢?合并过程如下图所示:

树的层数(合并的)是没有发生变化的。
如果有 6 个进程,合并过程如下图:

树的层数(合并次数)同样没有发生变化。
因此我们的合并次数应该为进程数对2的对数,然后向上取整就不难理解了。
m e r g e T i m e s = c e i l ( l o g 2 ( p r o c e s s N u m ) ) mergeTimes=ceil(log_2(processNum)) mergeTimes=ceil(log2(processNum))
具体代码如下:
// 合并数组
// 计算合并的次数
int mergeTimes = ceil(log2(processNum));
for (int i = 0; i < mergeTimes; i++) {
// 判断当前进程 在 第 i 个轮次 是否需要接收数据
if (myrank % int(pow(2, i + 1)) == 0) {
// 计算当前进程的下一个进程
int nextProcess = myrank + pow(2, i);
// 如果下一个进程存在,那么就接收下一个进程的数据
if (nextProcess < processNum) {
// 接收数组的大小
int vecNum;
MPI_Recv(&vecNum, 1, MPI_INT, nextProcess, 0,
MPI_COMM_WORLD, MPI_STATUS_IGNORE);
// 接收数组
vector<int> recvVec(vecNum, 0);
MPI_Recv(recvVec.data(), vecNum, MPI_INT,
nextProcess, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
// 合并数组
subVec = merge(subVec, recvVec);
}
}
// 判断当前进程 在 第 i 个轮次 是否需要发送数据给前边的进程
if ((myrank + int(pow(2,i))) % int(pow(2, i + 1)) == 0) {
// 计算上一个进程
int preProcess = myrank - pow(2, i);
// 发送数组的大小
int vecNum = subVec.size();
MPI_Send(&vecNum, 1, MPI_INT, preProcess,
0, MPI_COMM_WORLD);
// 发送数组
MPI_Send(subVec.data(), subVec.size(),
MPI_INT, preProcess, 0, MPI_COMM_WORLD);
}
}
关于两个 if 条件判断的理解,主要是两两合并的思想。
1 2合并,3 4合并,5 6合并 7 8合并;
1 3 合并,5 7合并;
1 5合并。
这样合并 3 次就可以了,至于判断到底为什么这样写?主要利用了进程号、合并轮次两个参数控制的。
读者需要自己想一下,然后再根据代码看一下,进行理解。
其中,merge函数部分的代码主要功能是,将两个有序数组合并成一个,代码如下:
// vec1 和 vec2 是两个有序数组,将其合并为一个有序数组
vector<int> merge(vector<int> vec1, vector<int> vec2) {
int i = 0, j = 0;
vector<int> res;
while(i < vec1.size() && j < vec2.size()) {
if (vec1[i] < vec2[j]) {
res.push_back(vec1[i++]);
}
else {
res.push_back(vec2[j++]);
}
}
while (i < vec1.size()) {
res.push_back(vec1[i++]);
}
while (j < vec2.size()) {
res.push_back(vec2[j++]);
}
return res;
}
5.输出排序后的数组
最后输出排序后的数组,具体代码如下:
// 输出排序后的数组
if (myrank == 0) {
// 计算排序时间
cout << "time=" << (MPI_Wtime() - startTime) * 1000 << " ms" << endl;
// 输出排序后的数组
for (int i = 0; i < subVec.size(); i++) {
cout << subVec[i] << " ";
}
cout << endl;
}
6.进程分发部分的优化
我们是采用主进程进行数组分发的,一个进程进行数组的分发,时间复杂度为 O ( n ) O(n) O(n),相对较低。
另一种方法是,多个进程同时进行分发,时间复杂度为 O ( l o g n ) O(logn) O(logn)。
主要思想如下:

编程的思路就是,首先接收数据。
然后计算需要划分的轮次。
根据轮次和进程号,得到每个进程需要发送消息的进程的进程号。
具体代码如下:
// 计算划分次数
int splitTimes = ceil(log2(processNum));
if (myrank != 0) {
// 计算当前进程的上一个进程
int preProcess = getPreProcess(myrank);
// 接收数组的大小
int vecNum;
MPI_Recv(&vecNum, 1, MPI_INT, preProcess,
0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
cout << "process=" << myrank << " receive " <<
vecNum << " numbers from " << preProcess << endl;
// 接收数组
subVec = vector<int>(vecNum, 0);
MPI_Recv(subVec.data(), vecNum, MPI_INT, preProcess,
0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
}
for (int i = splitTimes; i > 0; i--) {
// 初始化 0 号进程的子数组
if (myrank == 0 && i == splitTimes)
subVec = vector<int>(vec.begin(), vec.end());
// 如果当前进程是 2 的 i 次方的倍数,那么就发送数据
if (myrank % int(pow(2, i)) == 0) {
// 计算当前进程的下一个进程
int nextProcess = myrank + pow(2, i - 1);
// 如果下一个进程存在,那么就发送数据给下一个进程
if (nextProcess < processNum) {
// 发送数组的大小
int vecNum = subVec.size() - subVec.size() / 2;
cout<<"process="<<myrank<<" send "<<vecNum<<" numbers to "<<nextProcess<<endl;
MPI_Send(&vecNum, 1, MPI_INT, nextProcess,
0, MPI_COMM_WORLD);
// 发送数组
// subVec = vector<int>(subVec.begin() + subVec.size() / 2, subVec.end());
MPI_Send(subVec.data() + subVec.size() / 2, vecNum,
MPI_INT, nextProcess, 0, MPI_COMM_WORLD);
subVec = vector<int>(subVec.begin(), subVec.begin() + subVec.size() / 2);
}
}
}
代码思路也有些绕,其中还涉及到一个 int getPreProcess(int curProcessNum) 函数,该函数主要用来求解给当前进程发送信息的进程的进程号,我们得到了之后好去接收它。
主要就是找比当前进程数小的,2的幂次方的累加和,但注意是要贪心去找,比如:
7->4+2
6->4
5->4
4->0
3->2
2->0
1->0
具体代码如下:
int getPreProcess(int curProcessNum) {
int tmp;
int sum = 0;
while (sum < curProcessNum) {
tmp = 2;
bool flag = false;
while (sum + tmp < curProcessNum) {
tmp *= 2;
}
if (tmp == 2 || sum + tmp == curProcessNum) {
return sum;
}
else {
sum += tmp / 2;
}
}
}
说的还是很绕。
还是下面这张图,每个进程只接收一次消息,但是可能会发送多次消息。

因此,我们上面可以得到这个进程接收消息的进程号。
然后再去求它发送消息的进程号就可以了,具体还是看代码。
因为划分并不是该并行算法的性能瓶颈,最大的运算量还是在各个子进程的 mergeSort函数 以及 merge函数 上面。
所以划分这块性能看上去并没有过于明显的差别。下面是我按照两种划分方法,排序100万数据量的数组,所耗费的时间(单位:ms)对比:

可以看到单个进程划分效率看起来更高一些。具体的原因,我推测可能是 getPreProcess函数 的时间复杂度较大导致的。
7.完整代码
#include<vector>
#include<iostream>
#include<mpi.h>
using namespace std;
// 归并排序,输入一个vector的引用
void mergeSort(vector<int>& vec) {
if (vec.size() <= 1) return;
int mid = vec.size() / 2;
vector<int> left(vec.begin(), vec.begin() + mid);
vector<int> right(vec.begin() + mid, vec.end());
mergeSort(left);
mergeSort(right);
int i = 0, j = 0, k = 0;
while (i < left.size() && j < right.size()) {
if (left[i] < right[j]) {
vec[k++] = left[i++];
}
else {
vec[k++] = right[j++];
}
}
while (i < left.size()) {
vec[k++] = left[i++];
}
while (j < right.size()) {
vec[k++] = right[j++];
}
}
// vec1 和 vec2 是两个有序数组,将其合并为一个有序数组
vector<int> merge(vector<int> vec1, vector<int> vec2) {
int i = 0, j = 0;
vector<int> res;
while(i < vec1.size() && j < vec2.size()) {
if (vec1[i] < vec2[j]) {
res.push_back(vec1[i++]);
}
else {
res.push_back(vec2[j++]);
}
}
while (i < vec1.size()) {
res.push_back(vec1[i++]);
}
while (j < vec2.size()) {
res.push_back(vec2[j++]);
}
return res;
}
int getPreProcess(int curProcessNum) {
int tmp;
int sum = 0;
while (sum < curProcessNum) {
tmp = 2;
bool flag = false;
while (sum + tmp < curProcessNum) {
tmp *= 2;
}
if (tmp == 2 || sum + tmp == curProcessNum) {
return sum;
}
else {
sum += tmp / 2;
}
}
}
double startTime;
int main(int argc, char* argv[]) {
int myrank, processNum;
char processor_name[MPI_MAX_PROCESSOR_NAME];
int namelen;
MPI_Init(&argc, &argv);
// 当前进程的编号
MPI_Comm_rank(MPI_COMM_WORLD, &myrank);
// 进程总数
MPI_Comm_size(MPI_COMM_WORLD, &processNum);
// 数据的数量
int numberNums = 10;
vector<int> vec;
// 初始化数据
if (myrank == 0) {
srand(time(NULL));
// 随机生成10个数
for (int i = 0; i < numberNums; i++) {
vec.push_back(rand() % 100);
}
// 记录开始时间
startTime = MPI_Wtime();
}
// 每个进程排序的数量
int n = numberNums / processNum;
// 分出来的子数字
vector<int> subVec(n, 0);
// 如果是主进程,那么就进行子数组的分发
//if (myrank == 0) {
// // 计算每个进程分配完,多余出来的数量
// int remain = numberNums % processNum;
// // 主进程 排序 自己的 + 多余出来的
// subVec = vector<int>(vec.begin(), vec.begin() + n + remain);
// for (int i = 1; i < processNum; i++) {
// MPI_Send(vec.data() + i * n + remain, n,
// MPI_INT, i, 0, MPI_COMM_WORLD);
// }
//}
//else {
// // 接收数组
// MPI_Recv(subVec.data(), n, MPI_INT,
// 0, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
//}
// 计算划分次数
int splitTimes = ceil(log2(processNum));
if (myrank != 0) {
// 计算当前进程的上一个进程
int preProcess = getPreProcess(myrank);
// 接收数组的大小
int vecNum;
MPI_Recv(&vecNum, 1, MPI_INT, preProcess,
0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
cout << "process=" << myrank << " receive " <<
vecNum << " numbers from " << preProcess << endl;
// 接收数组
subVec = vector<int>(vecNum, 0);
MPI_Recv(subVec.data(), vecNum, MPI_INT, preProcess,
0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
}
for (int i = splitTimes; i > 0; i--) {
// 初始化 0 号进程的子数组
if (myrank == 0 && i == splitTimes)
subVec = vector<int>(vec.begin(), vec.end());
// 如果当前进程是 2 的 i 次方的倍数,那么就发送数据
if (myrank % int(pow(2, i)) == 0) {
// 计算当前进程的下一个进程
int nextProcess = myrank + pow(2, i - 1);
// 如果下一个进程存在,那么就发送数据给下一个进程
if (nextProcess < processNum) {
// 发送数组的大小
int vecNum = subVec.size() - subVec.size() / 2;
cout<<"process="<<myrank<<" send "<<vecNum<<" numbers to "<<nextProcess<<endl;
MPI_Send(&vecNum, 1, MPI_INT, nextProcess,
0, MPI_COMM_WORLD);
// 发送数组
// subVec = vector<int>(subVec.begin() + subVec.size() / 2, subVec.end());
MPI_Send(subVec.data() + subVec.size() / 2, vecNum,
MPI_INT, nextProcess, 0, MPI_COMM_WORLD);
subVec = vector<int>(subVec.begin(), subVec.begin() + subVec.size() / 2);
}
}
}
// 对接收到的子数组进行排序
mergeSort(subVec);
// 合并数组
// 计算合并的次数
int mergeTimes = ceil(log2(processNum));
for (int i = 0; i < mergeTimes; i++) {
// 判断当前进程 在 第 i 个轮次 是否需要接收数据
if (myrank % int(pow(2, i + 1)) == 0) {
// 计算当前进程的下一个进程
int nextProcess = myrank + pow(2, i);
// 如果下一个进程存在,那么就接收下一个进程的数据
if (nextProcess < processNum) {
// 接收数组的大小
int vecNum;
MPI_Recv(&vecNum, 1, MPI_INT, nextProcess, 0,
MPI_COMM_WORLD, MPI_STATUS_IGNORE);
// 接收数组
vector<int> recvVec(vecNum, 0);
MPI_Recv(recvVec.data(), vecNum, MPI_INT,
nextProcess, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
// 合并数组
subVec = merge(subVec, recvVec);
}
}
// 判断当前进程 在 第 i 个轮次 是否需要发送数据给前边的进程
if ((myrank + int(pow(2,i))) % int(pow(2, i + 1)) == 0) {
// 计算上一个进程
int preProcess = myrank - pow(2, i);
// 发送数组的大小
int vecNum = subVec.size();
MPI_Send(&vecNum, 1, MPI_INT, preProcess,
0, MPI_COMM_WORLD);
// 发送数组
MPI_Send(subVec.data(), subVec.size(),
MPI_INT, preProcess, 0, MPI_COMM_WORLD);
}
}
// 输出排序后的数组
if (myrank == 0) {
// 计算排序时间
cout << "time=" << (MPI_Wtime() - startTime) * 1000 << " ms" << endl;
// 输出排序后的数组
for (int i = 0; i < subVec.size(); i++) {
cout << subVec[i] << " ";
}
cout << endl;
}
MPI_Finalize();
return 0;
}