渲染器(四):双端diff算法
在上一章中,我们介绍了简单diff算法的实现原理。它利用vnode的key属性,尽可能多地复用DOM,并通过移动DOM的方式来完成更新,从而减少不断地创建和销毁DOM元素带来的性能开销。但是仍然存在不少缺陷,接下来就介绍双端diff算法来解决。
1.双端比较的原理:
这里主要通过一个例子来说明原理,所以废话会比较多(不是)。如果原理已经了解的朋友,可以直接跳到这节的后面看结论和代码。
先看上一章的例子:
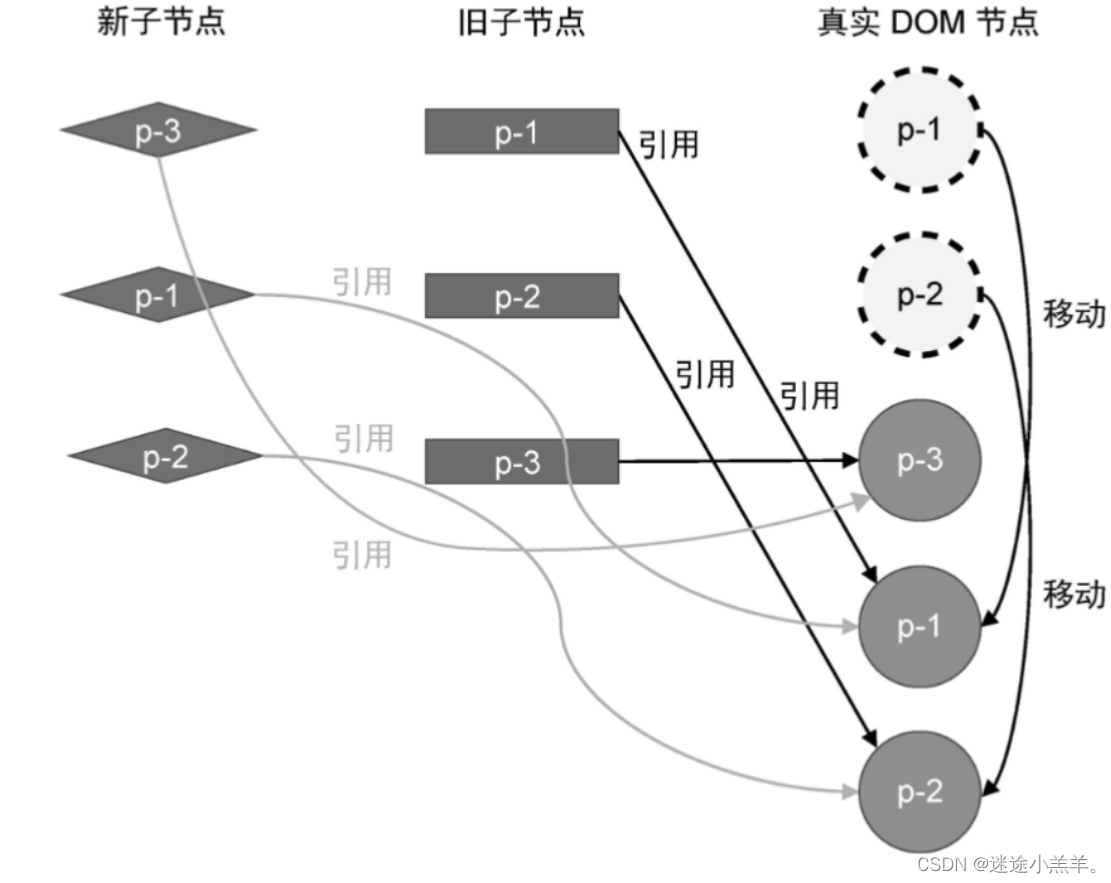
它会发生两次DOM移动操作来完成更新,但是它不是最优解,因为通过观察我们可以最优解应该是:把真实DOM节点 p-3移动到 真实DOM节点 p-1前面,这样就只需要一次DOM移动操作即可完成更新。
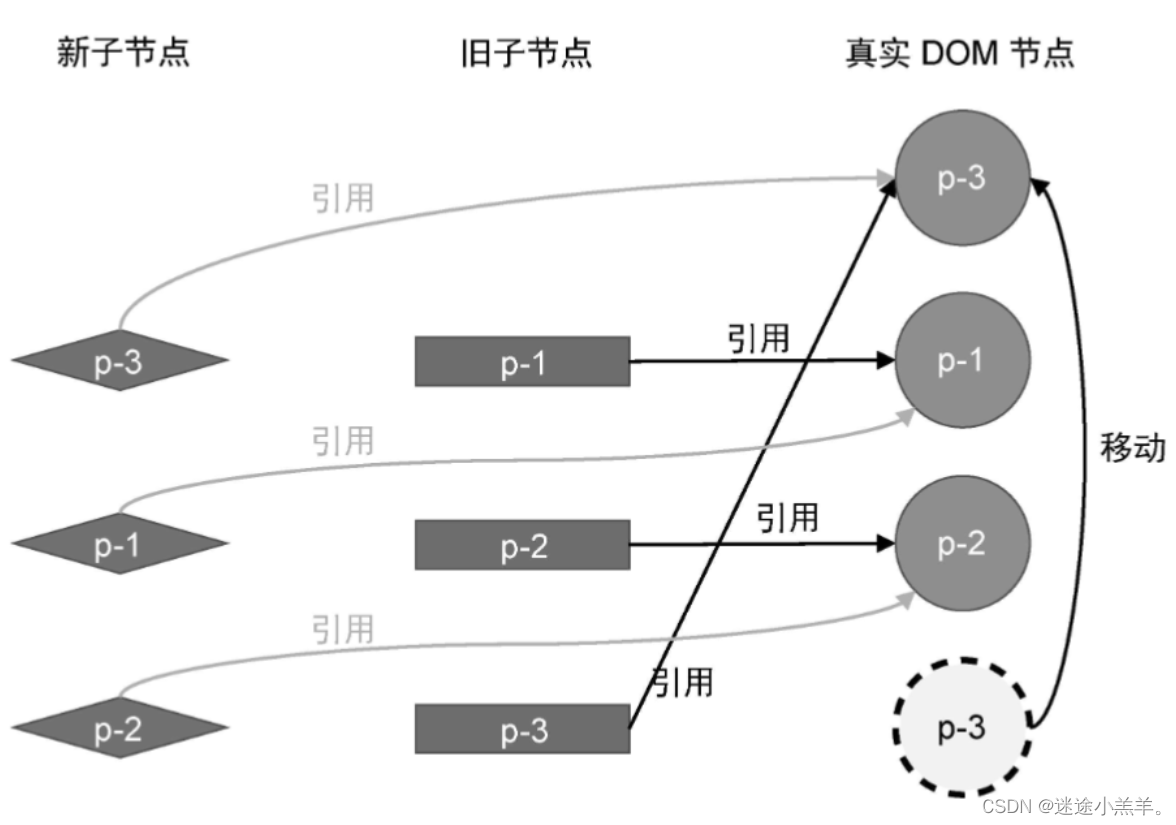
简单diff算法做不到这点,但是双端diff算法可以做到。接下来就让我们来认识下它。
先下定义:双端diff算法是一种同时对新旧vnode的两个端点进行比较的算法。它的优势在于比起简单Diff算法,可以减少DOM移动次数。
我们需要四个索引值,分别指引新旧vnode的端点,如图:
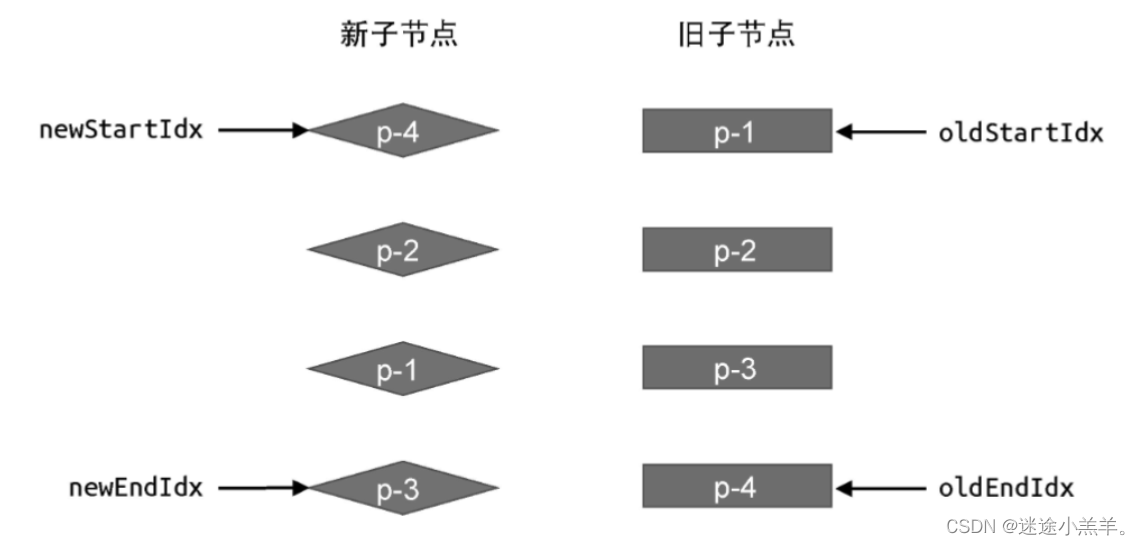
封装 patchKeyChildren函数:
function patchKeyedChildren(n1, n2, container) {
const oldChildren = n1.children
const newChildren = n2.children
// 四个索引值
let oldStartIdx = 0
let oldEndIdx = oldChildren.length - 1
let newStartIdx = 0
let newEndIdx = newChildren.length - 1
// 四个索引指向的 vnode 节点
let oldStartVNode = oldChildren[oldStartIdx]
let oldEndVNode = oldChildren[oldEndIdx]
let newStartVNode = newChildren[newStartIdx]
let newEndVNode = newChildren[newEndIdx]
}
有了这些后,就可以开始进行双端比较了。怎么比较呢?如下图所示:
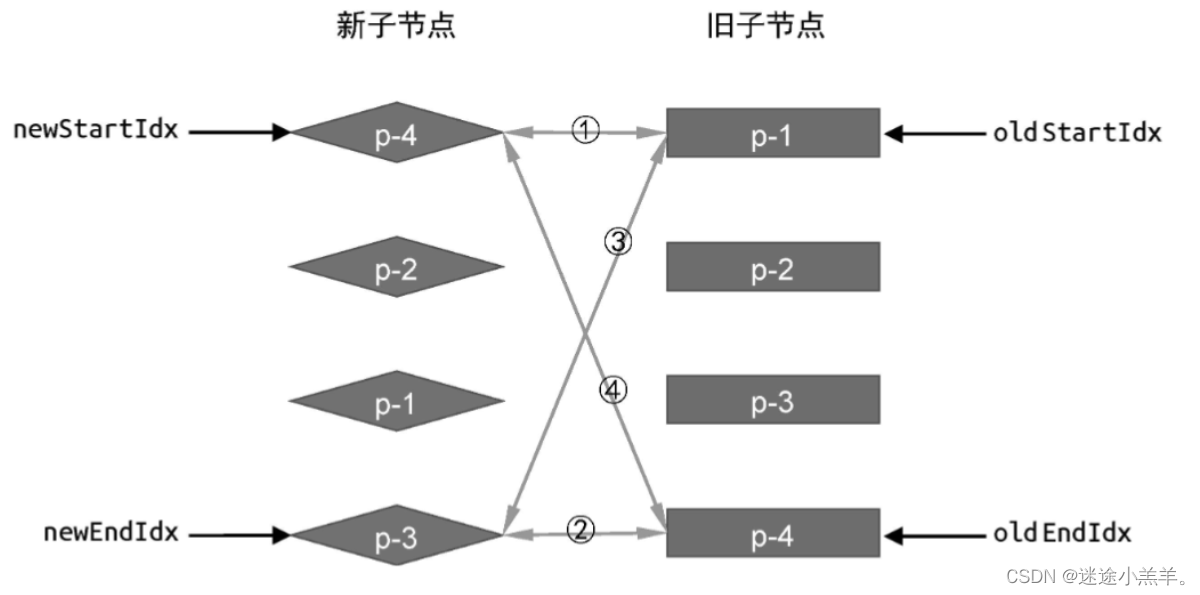
每一轮比较都分为四个步骤,如上图1234所示:
- 第一步:比较旧vnode的第一个子节点p-1 和 新vnode的第一个子节点p-4,key值不同,所以什么也不做;
- 第二步、第三步同上;
- 第四步:比较旧vnode中的最后一个子节点p-4 和新vnode中的第一个子节点p-4,key相同,可以进行DOM复用。
可以看到,在第四步找到了相同节点,通过移动DOM元素来进行真实DOM节点的复用。那么该怎么复用呢?
观察一下,可以发现 旧vnode中p-4原本是最后一个子节点,在新vnode中变成了第一个子节点。对应到程序逻辑:将旧vnode的 oldEndIdx索引指向的vnode所对应的真实DOM,移动到索引 oldStartIdx指向的vnode所对应的真实DOM前面。如下代码:
function patchKeyedChildren(n1, n2, container) {
const oldChildren = n1.children
const newChildren = n2.children
// 四个索引值
let oldStartIdx = 0
let oldEndIdx = oldChildren.length - 1
let newStartIdx = 0
let newEndIdx = newChildren.length - 1
// 四个索引指向的 vnode 节点
let oldStartVNode = oldChildren[oldStartIdx]
let oldEndVNode = oldChildren[oldEndIdx]
let newStartVNode = newChildren[newStartIdx]
let newEndVNode = newChildren[newEndIdx]
if (oldStartVNode.key === newStartVNode.key) {
// 第一步比较
} else if (oldEndVNode.key === newEndVNode.key) {
// 第二步比较
} else if (oldStartVNode.key === newEndVNode.key) {
// 第三步比较
} else if (oldEndVNode.key === newStartVNode.key) {
// 第四步比较
// 仍然调用patch函数进行打补丁
patch(oldEndVNode, newStartVNode, container);
// 移动DOM操作
insert(oldEndVNode.el, container, oldStartVNode.el);
// 移动DOM完成后,更新索引值,并指向下一个位置
oldEndVNode = oldChildren[--oldEndIdx];
newStartVNode = newChildren[++newStartIdx];
}
}
在这段代码中,增加了一系列的 if...else if语句,用来实现四个索引指向的vnode之间的比较。但是我们只实现了第四步的,后面再慢慢完善。在第四步DOM移动操作完成后,新旧vnode以及真实DOM节点的状态如下图: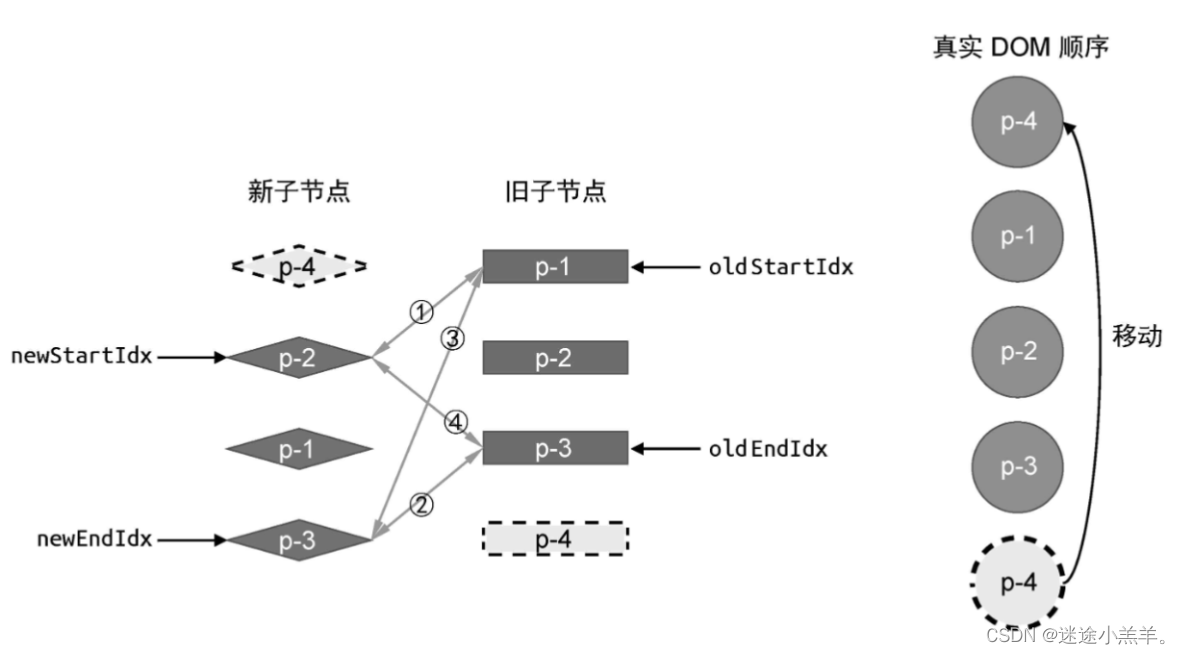
此时,真实DOM节点顺序为 p-4 、p-1、p-2、p-3,这与新vnode子节点顺序不同。因为diff算法还没有结束,还需要进行下一轮更新。因此将更新逻辑封装到一个while循环中,如下代码:
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
if (oldStartVNode.key === newStartVNode.key) {
// 第一步比较
} else if (oldEndVNode.key === newEndVNode.key) {
// 第二步比较
} else if (oldStartVNode.key === newEndVNode.key) {
// 第三步比较
} else if (oldEndVNode.key === newStartVNode.key) {
// 第四步比较
// 仍然调用patch函数进行打补丁
patch(oldEndVNode, newStartVNode, container);
// 移动DOM操作
insert(oldEndVNode.el, container, oldStartVNode.el);
// 移动DOM完成后,更新索引值,并指向下一个位置
oldEndVNode = oldChildren[--oldEndIdx];
newStartVNode = newChildren[++newStartIdx];
}
}
在第一轮更新结束后循环条件仍然成立,因此需要进行下一轮比较,如上图所示,第二轮更新:
- 第一步:比较旧vnode中的头部节点 p-1与新vnode中的头部节点p-2,key不同不可复用。
- 第二步:比较旧vnode中的尾部节点 p-3与新vnode中的尾部节点p-3,key相同可以复用。
此时的代码:
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
if (oldStartVNode.key === newStartVNode.key) {
// 第一步比较
} else if (oldEndVNode.key === newEndVNode.key) {
patch(oldEndVNode, newEndVNode, container);
// 节点在新的顺序中仍然处于尾部,不需要insert来移动
oldEndVNode = oldChildren[--oldEndIdx];
newEndVNode = newChildren[--newEndIdx];
} else if (oldStartVNode.key === newEndVNode.key) {
// 第三步比较
} else if (oldEndVNode.key === newStartVNode.key) {
patch(oldEndVNode, newStartVNode, container);
insert(oldEndVNode.el, container, oldStartVNode.el);
oldEndVNode = oldChildren[--oldEndIdx];
newStartVNode = newChildren[++newStartIdx];
}
}
第二轮更新完成后,此时新旧vnode与真实DOM的状态:
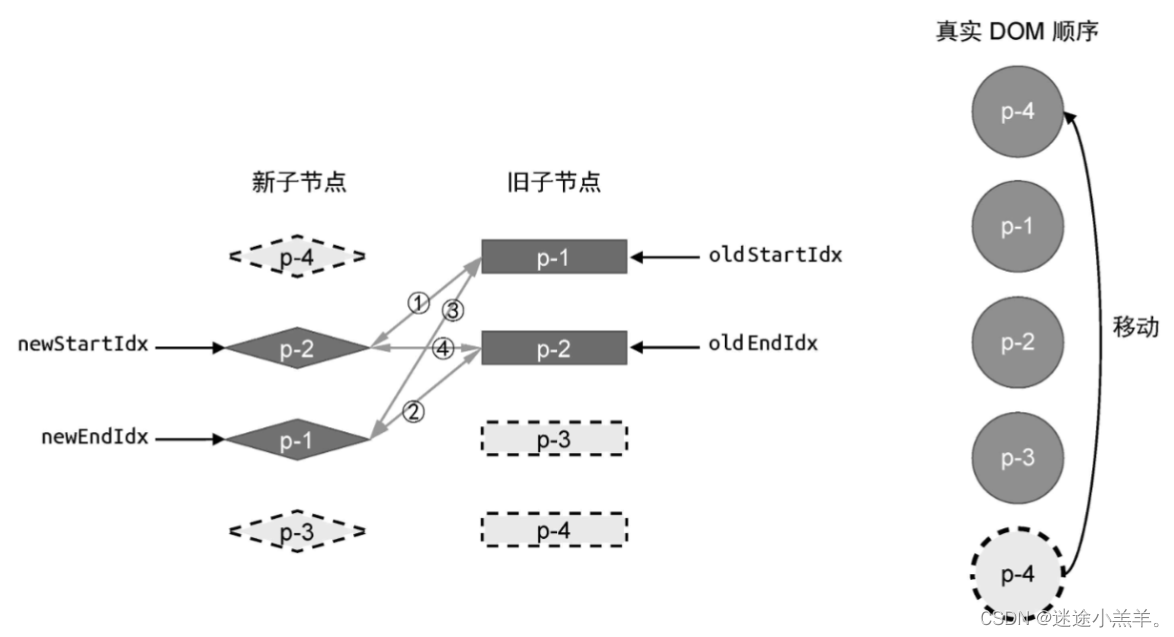
真实DOM的顺序相比上一轮没有变化,因为在这一轮的比较中没有对DOM节点进行移动,只是对p-3节点打补丁。
接下来继续进行下一轮的比较,具体步骤与前面类似,省略了,直接看图吧:
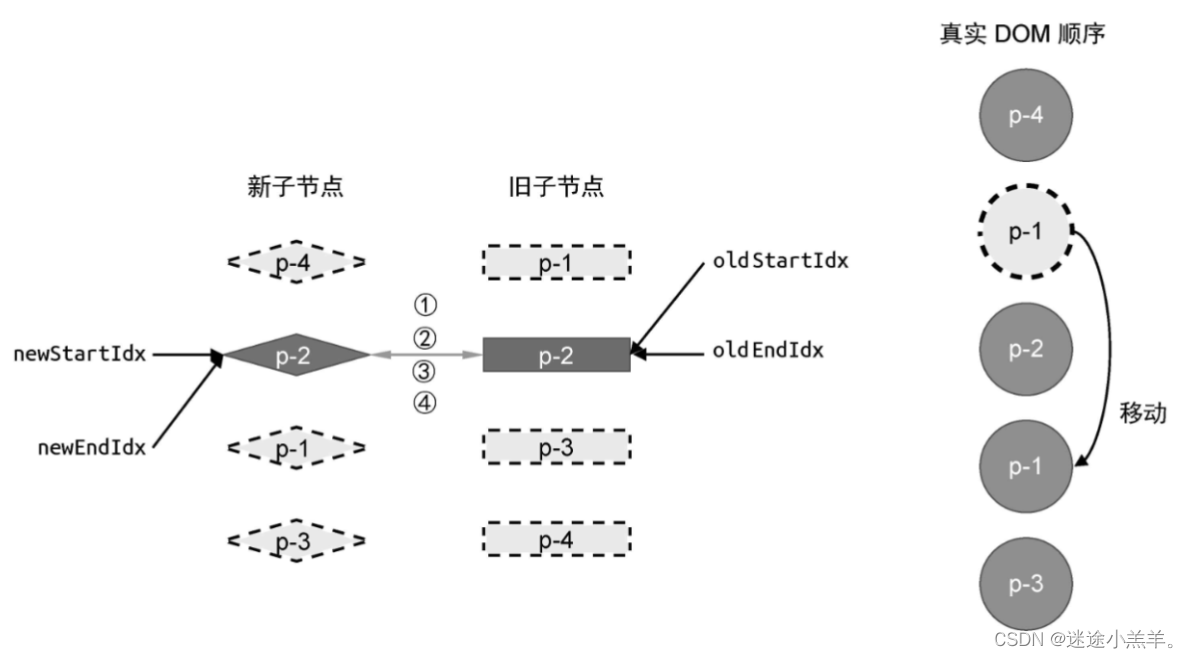
这是在第三步的比较中找到了相同的节点,即比较旧vnode的头部节点与新vnode的尾部节点p-1(在第二轮比较中,尾部节点自减发生了变化),两者的key相同,可以复用。
因此需要将节点p-1 对应的真实DOM移动到旧vnode的尾部节点p-2 所对应的真实DOM后面,并且更新索引,如图:
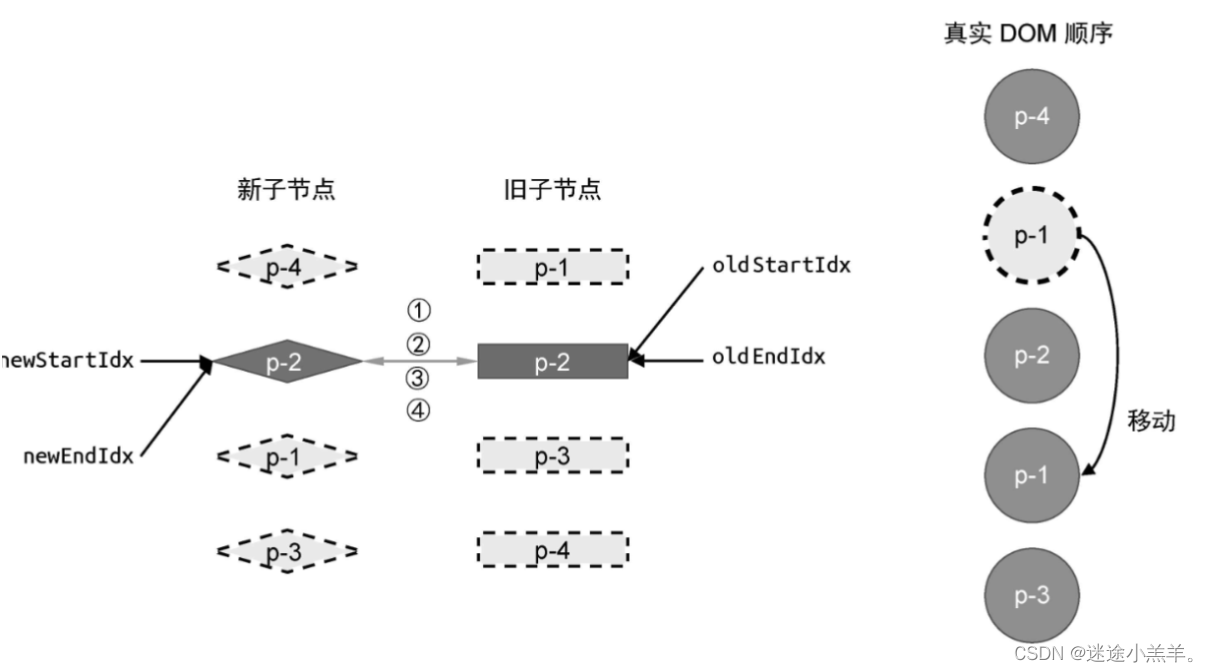
如下代码:
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
if (oldStartVNode.key === newStartVNode.key) {
// 第一步比较
} else if (oldEndVNode.key === newEndVNode.key) {
patch(oldEndVNode, newEndVNode, container);
// 节点在新的顺序中仍然处于尾部,不需要insert来移动
oldEndVNode = oldChildren[--oldEndIdx];
newEndVNode = newChildren[--newEndIdx];
} else if (oldStartVNode.key === newEndVNode.key) {
patch(oldStartVNode, newEndVNode, container);
// 移动DOM到旧vnode的尾部节点对应的真实DOM节点后面
insert(oldStartVNode.el, container, oldEndVNode.el.nextSibling);
oldStartVNode = oldChildren[++oldStartIdx];
newEndVNode = newChildren[--newEndIdx];
} else if (oldEndVNode.key === newStartVNode.key) {
patch(oldEndVNode, newStartVNode, container);
insert(oldEndVNode.el, container, oldStartVNode.el);
oldEndVNode = oldChildren[--oldEndIdx];
newStartVNode = newChildren[++newStartIdx];
}
}
如上面代码所示,如果旧vnode的头部节点与新vnode的尾部节点匹配,则说明要将旧vnode所对应的真实DOM移动到尾部。因此需要获取当前尾部节点的下一个兄弟节点作为锚点,即 oldEndVNode.el.nextSibling。最后更新相关索引到下一个位置。
最后一步,看上图可知,新旧vnode的头/尾索引发生重合,但仍然满足循环条件,所以还会进行下一轮更新。
直接上代码了,详细解释就不说了,挺简单的,把握一点即可:主要通过新旧vnode的前后指针来判断,有四种命中情况,命中一种则不再进行判断。
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
if (oldStartVNode.key === newStartVNode.key) {
patch(oldStartVNode, newStartVNode, container);
oldStartVNode = oldChildren[++oldStartIdx];
newStartVNode = newChildren[++newStartIdx];
} else if (oldEndVNode.key === newEndVNode.key) {
patch(oldEndVNode, newEndVNode, container);
oldEndVNode = oldChildren[--oldEndIdx];
newEndVNode = newChildren[--newEndIdx];
} else if (oldStartVNode.key === newEndVNode.key) {
patch(oldStartVNode, newEndVNode, container);
insert(oldStartVNode.el, container, oldEndVNode.el.nextSibling);
oldStartVNode = oldChildren[++oldStartIdx];
newEndVNode = newChildren[--newEndIdx];
} else if (oldEndVNode.key === newStartVNode.key) {
patch(oldEndVNode, newStartVNode, container);
insert(oldEndVNode.el, container, oldStartVNode.el);
oldEndVNode = oldChildren[--oldEndIdx];
newStartVNode = newChildren[++newStartIdx];
}
}
此时新旧vnode与真实DOM节点如图所示:
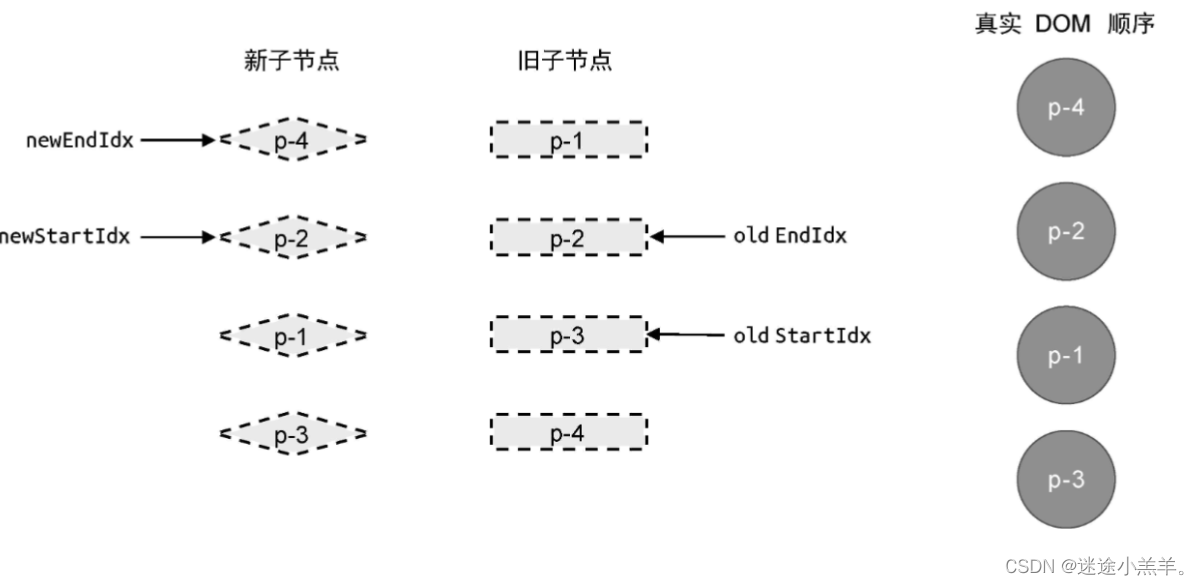
2.非理想状况的处理方式:
根据前面的讲解,每一轮比较都会命中四个步骤中的一个,这是比较理想的情况。那么如果没有命中呢?如下图所示:
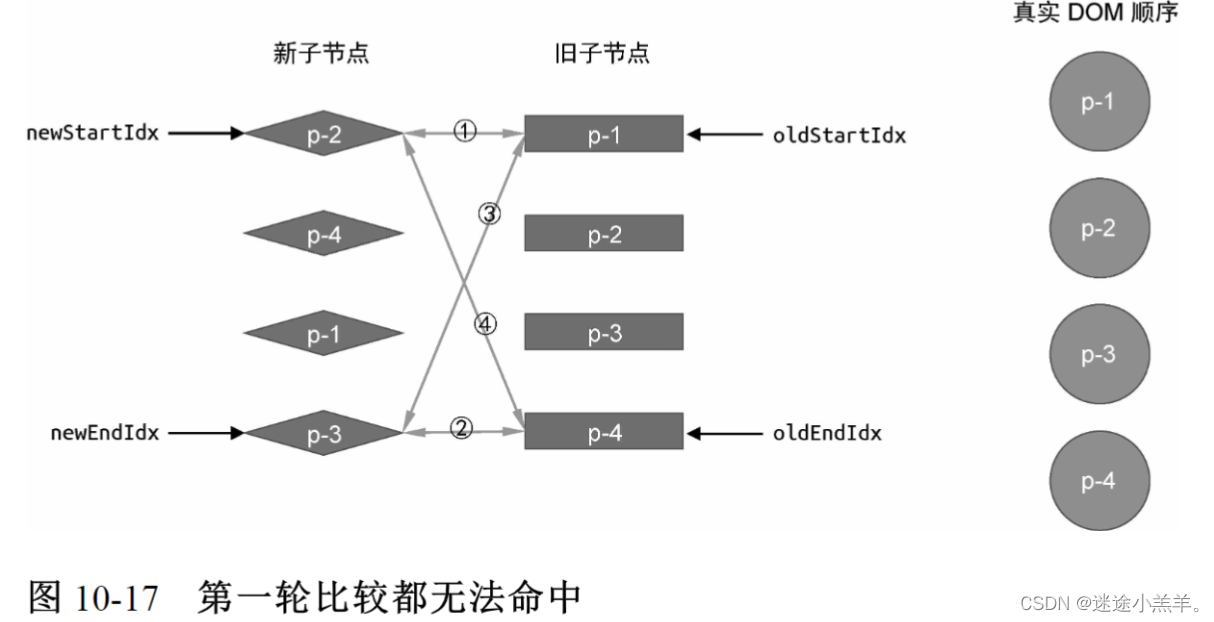
当尝试按照双端diff算法思路进行第一轮比较时,会发现无法命中四个步骤中的任何一步。我们只能通过额外增加的处理步骤来处理这种非理想情况。即,拿新vnode的头部节点去旧vnode的一组子节点中寻找,如下代码:
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
if (oldStartVNode.key === newStartVNode.key) {
patch(oldStartVNode, newStartVNode, container);
oldStartVNode = oldChildren[++oldStartIdx];
newStartVNode = newChildren[++newStartIdx];
} else if (oldEndVNode.key === newEndVNode.key) {
patch(oldEndVNode, newEndVNode, container);
oldEndVNode = oldChildren[--oldEndIdx];
newEndVNode = newChildren[--newEndIdx];
} else if (oldStartVNode.key === newEndVNode.key) {
patch(oldStartVNode, newEndVNode, container);
insert(oldStartVNode.el, container, oldEndVNode.el.nextSibling);
oldStartVNode = oldChildren[++oldStartIdx];
newEndVNode = newChildren[--newEndIdx];
} else if (oldEndVNode.key === newStartVNode.key) {
patch(oldEndVNode, newStartVNode, container);
insert(oldEndVNode.el, container, oldStartVNode.el);
oldEndVNode = oldChildren[--oldEndIdx];
newStartVNode = newChildren[++newStartIdx];
} else {
// 遍历旧vnode,寻找与 newStartVnode有相同key的节点
// idxInOld就是新vnode的头部节点在旧vnode中的索引
const idxInOld = oldChildren.findIndex(
node => node.key === newStartVNode.key
)
}
}
上面增加的代码在注释里面写了,先遍历旧vnode,然后寻找与 newStartVnode 有相同key的节点,idxInOld 就是新vnode的头部节点在旧vnode中的索引。这么做的目的是啥?
先来搞清楚:在旧vnode中,找到与新vnode的头部节点具有相同key的节点意味着啥?如下图所示: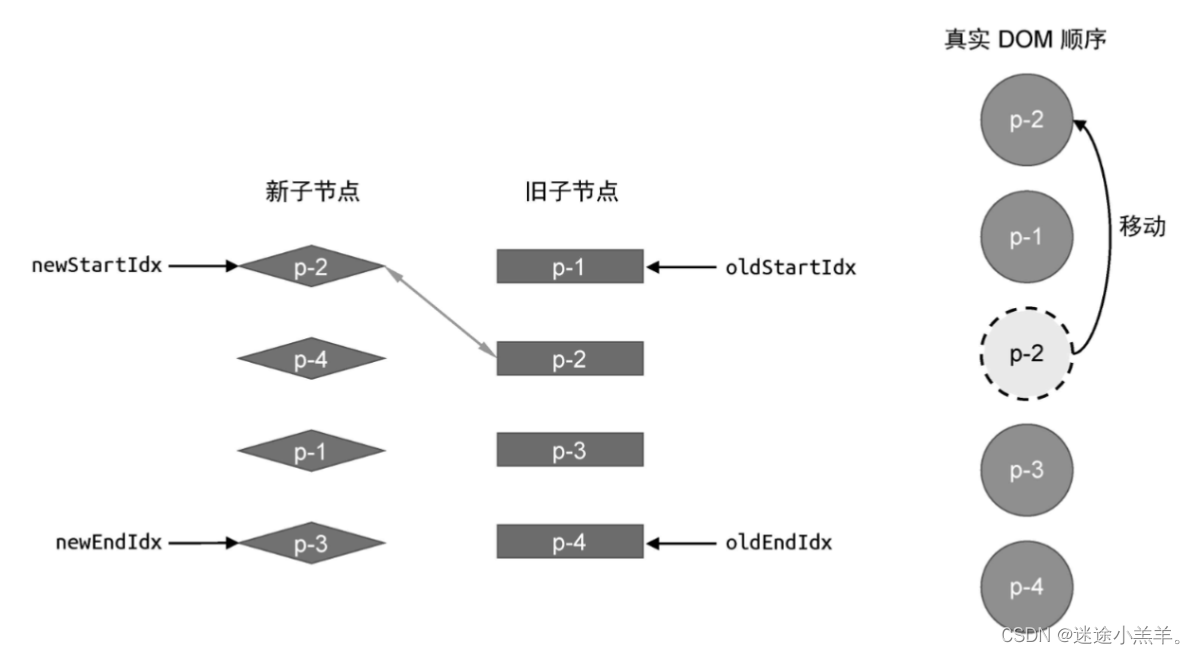
当我们拿新vnode的头部节点在旧vnode中寻找适,会在索引为1的位置找到可复用节点。
这意味着更新后 p-2应该变成头部节点,所以要将 p-2对应的真实DOM移动到当前旧vnode的头部节点p-1所对应的真实DOM之前。具体实现如下:
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
if (oldStartVNode.key === newStartVNode.key) {
patch(oldStartVNode, newStartVNode, container);
oldStartVNode = oldChildren[++oldStartIdx];
newStartVNode = newChildren[++newStartIdx];
} else if (oldEndVNode.key === newEndVNode.key) {
patch(oldEndVNode, newEndVNode, container);
oldEndVNode = oldChildren[--oldEndIdx];
newEndVNode = newChildren[--newEndIdx];
} else if (oldStartVNode.key === newEndVNode.key) {
patch(oldStartVNode, newEndVNode, container);
insert(oldStartVNode.el, container, oldEndVNode.el.nextSibling);
oldStartVNode = oldChildren[++oldStartIdx];
newEndVNode = newChildren[--newEndIdx];
} else if (oldEndVNode.key === newStartVNode.key) {
patch(oldEndVNode, newStartVNode, container);
insert(oldEndVNode.el, container, oldStartVNode.el);
oldEndVNode = oldChildren[--oldEndIdx];
newStartVNode = newChildren[++newStartIdx];
} else {
// 遍历旧vnode,寻找与 newStartVnode有相同key的节点
// idxInOld就是新vnode的头部节点在旧vnode中的索引
const idxInOld = oldChildren.findIndex(
node => node.key === newStartVNode.key
)
// idxInOld>0,说明找到了可复用节点,并且需要将其对应的真实DOM移动到头部
if (idxInOld > 0) {
// idxInOld 对应的 vnode就是需要移动的节点
const vnodeToMove = oldChildren[idxInOld];
// 移除操作外还应该打补丁
patch(vnodeToMove, newStartVNode, container);
// 将 vnodeToMove.el移动到头部节点 oldStartVnode.el之前,因此使用后者作为锚点
insert(vnodeToMove.el, container, oldStartVNode.el);
// 由于idxInOld处所对应的真实DOM已经移动到了别处,因此将其设置为 undefined
oldChildren[idxInOld] = undefine;
// 最后更新 newStartIdx到下一个位置
newStartVNode = newChildren[++newStartIdx];
}
}
}
上面代码的解释卸载了注释里了。经过上面步骤操作后,新旧vnode以及真实DOM的状态如图所示: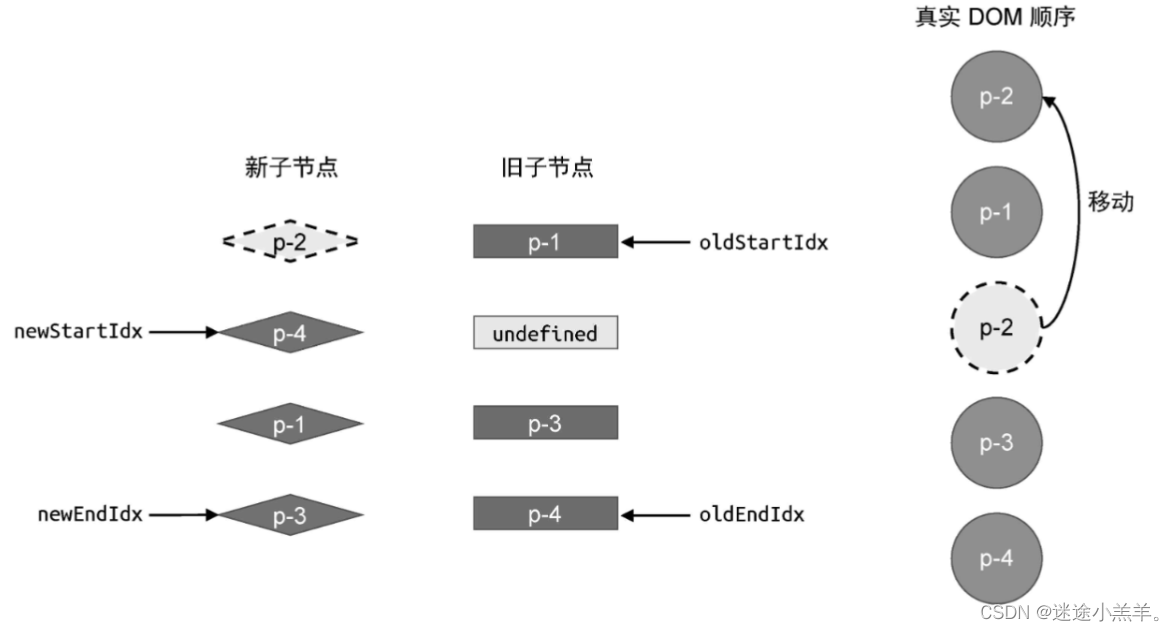
此时真实DOM顺序为:p-2、p-1、p-3、p-4。然后双端diff算法将继续执行(步骤跟前面一样),逻辑将变成这样:
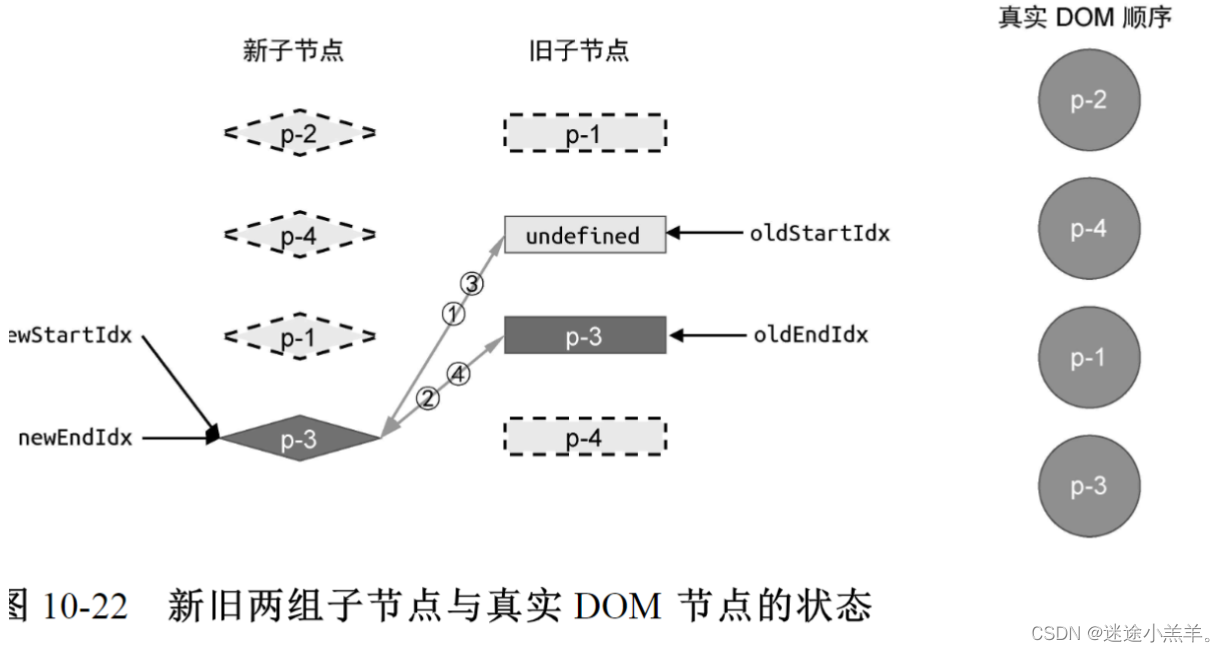
需要注意的是,当旧vnode的头部节点为 undefined适,说明该节点被处理过了,因此直接跳过即可。补充这部分的逻辑代码:
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
// 增加两个判断分支,如果头尾节点为undefined,则说明该节点已经被处理了,跳过
if (!oldStartVNode) {
oldStartVNode = oldChildren[++oldStartIdx];
} else if (!oldEndVNode) {
oldEndVNode = oldChildren[--oldEndIdx];
} else if (oldStartVNode.key === newStartVNode.key) {
patch(oldStartVNode, newStartVNode, container);
oldStartVNode = oldChildren[++oldStartIdx];
newStartVNode = newChildren[++newStartIdx];
} else if (oldEndVNode.key === newEndVNode.key) {
patch(oldEndVNode, newEndVNode, container);
oldEndVNode = oldChildren[--oldEndIdx];
newEndVNode = newChildren[--newEndIdx];
} else if (oldStartVNode.key === newEndVNode.key) {
patch(oldStartVNode, newEndVNode, container);
insert(oldStartVNode.el, container, oldEndVNode.el.nextSibling);
oldStartVNode = oldChildren[++oldStartIdx];
newEndVNode = newChildren[--newEndIdx];
} else if (oldEndVNode.key === newStartVNode.key) {
patch(oldEndVNode, newStartVNode, container);
insert(oldEndVNode.el, container, oldStartVNode.el);
oldEndVNode = oldChildren[--oldEndIdx];
newStartVNode = newChildren[++newStartIdx];
} else {
const idxInOld = oldChildren.findIndex(
node => node.key === newStartVNode.key
)
if (idxInOld > 0) {
const vnodeToMove = oldChildren[idxInOld];
patch(vnodeToMove, newStartVNode, container);
insert(vnodeToMove.el, container, oldStartVNode.el);
oldChildren[idxInOld] = undefine;
newStartVNode = newChildren[++newStartIdx];
}
}
}
只是增加了两个判断分支,在这一轮比较过后,新旧vnode与真实DOM节点的状态如图:
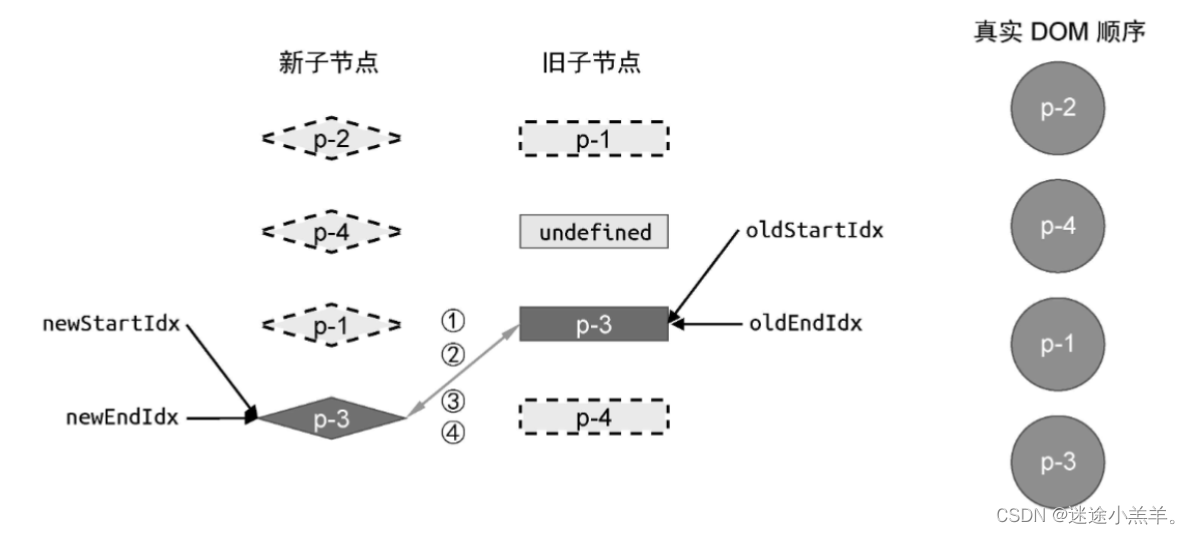
至此四个步骤又重合了,接着进行最后一轮的比较。
- 第一步:比较旧vnode中的头部节点 p-3 与新vnode中的头部节点p-3,两者key值相同,进行复用。
此时不需要进行DOM移动操作,直接打补丁即可。在这一轮比较过后,最后状态如图所示:

这样,更新就完成了。
3.添加新元素:
在前面我们讲解了非理想情况的处理,即在一轮比较过程中,不会命中四个步骤的任何一步,这时会拿新vnode的头节点去旧vnode中寻找可复用的节点。
但是有可能存在找不到的情况,看个图就明白了:
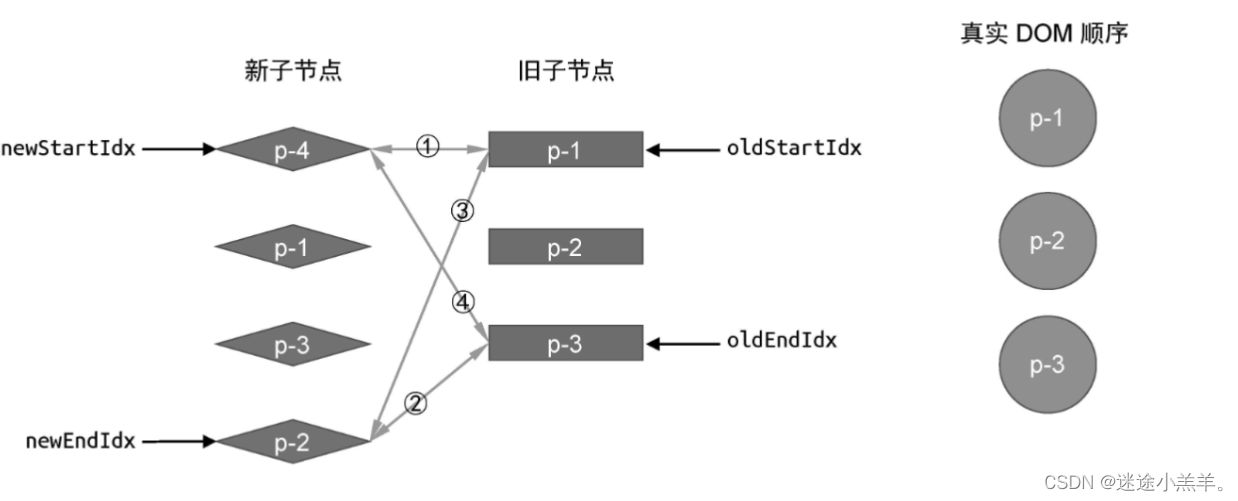
上图中新vnode p-4 在旧vnode中找不到可复用的节点,这说明它是一个新增节点,需要将它挂载。那么应该挂载到哪里?很简单,因为p-4是新的一组子节点中的头部节点,所以将它挂载到当前头部节点之前即可。当前头部节点:旧vnode头部节点p-1所对应的真实DOM节点。
老规矩,注释部分代表新增代码:
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
if (!oldStartVNode) {
oldStartVNode = oldChildren[++oldStartIdx];
} else if (!oldEndVNode) {
oldEndVNode = oldChildren[--oldEndIdx];
} else if (oldStartVNode.key === newStartVNode.key) {
patch(oldStartVNode, newStartVNode, container);
oldStartVNode = oldChildren[++oldStartIdx];
newStartVNode = newChildren[++newStartIdx];
} else if (oldEndVNode.key === newEndVNode.key) {
patch(oldEndVNode, newEndVNode, container);
oldEndVNode = oldChildren[--oldEndIdx];
newEndVNode = newChildren[--newEndIdx];
} else if (oldStartVNode.key === newEndVNode.key) {
patch(oldStartVNode, newEndVNode, container);
insert(oldStartVNode.el, container, oldEndVNode.el.nextSibling);
oldStartVNode = oldChildren[++oldStartIdx];
newEndVNode = newChildren[--newEndIdx];
} else if (oldEndVNode.key === newStartVNode.key) {
patch(oldEndVNode, newStartVNode, container);
insert(oldEndVNode.el, container, oldStartVNode.el);
oldEndVNode = oldChildren[--oldEndIdx];
newStartVNode = newChildren[++newStartIdx];
} else {
const idxInOld = oldChildren.findIndex(
node => node.key === newStartVNode.key
)
if (idxInOld > 0) {
const vnodeToMove = oldChildren[idxInOld];
patch(vnodeToMove, newStartVNode, container);
insert(vnodeToMove.el, container, oldStartVNode.el);
oldChildren[idxInOld] = undefine;
newStartVNode = newChildren[++newStartIdx];
} else {
// 将 newStartVNode作为新节点挂载到头部,
// 使用当前头部节点 oldStartVNode.el作为锚点
patch(null, newStartVNode, container, oldStartVNode.el);
}
newStartVNode = newChildren[++newStartIdx];
}
}
如上代码所示,当条件 idxInOld > 0不成立时,说明newStartVNode节点是全新的节点,又由于这个索引表示的是新头部节点,所以需要将其进行挂载。这一步操作完成后,新旧vnode以及真实DOM节点状态如图:
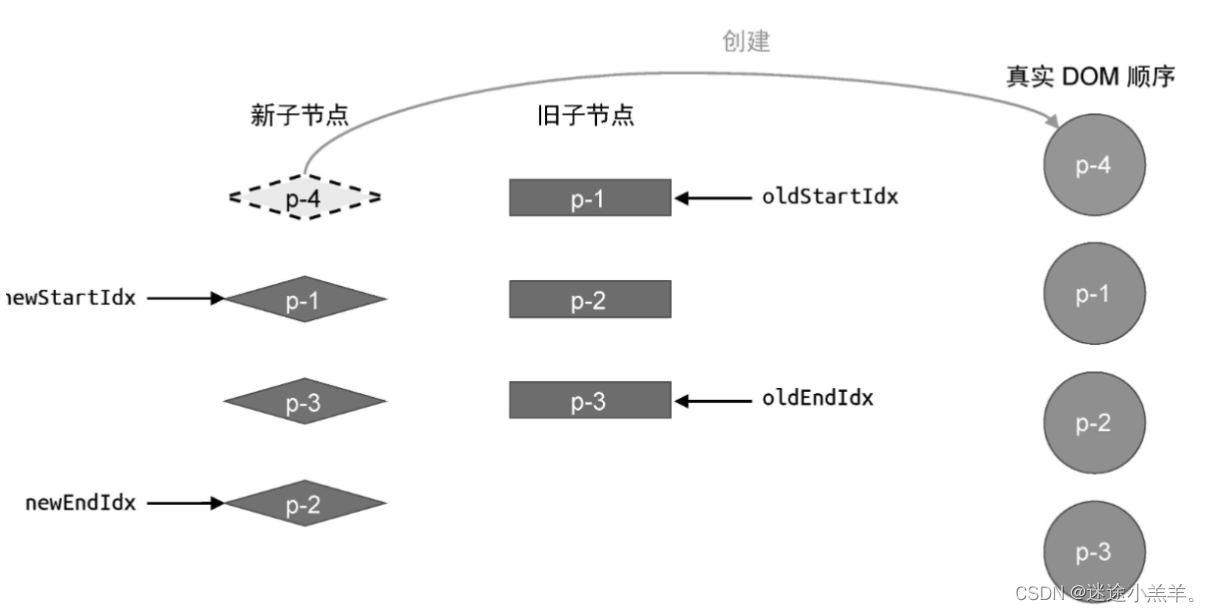
但是其实还是不够完美,有一个缺陷,来看一个例子:
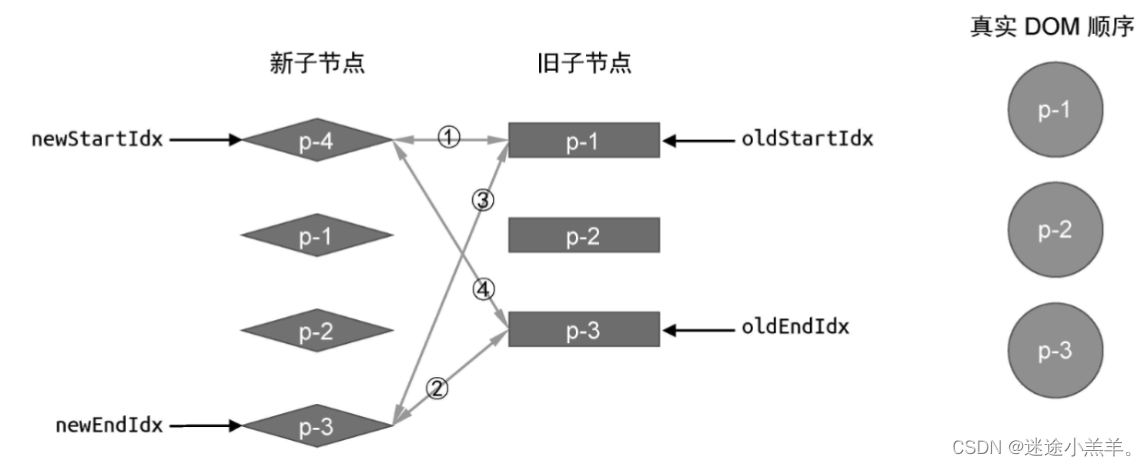
这个例子和前面的不同,此时新vnode的顺序是: p-4 、p-1、p-2、p-3。下面按照双端diff算法的思路来执行更新,看看会发生什么。
- 第一轮更新:在第二步比较旧vnode的p-3 与新vnode的 p-3 中发现了可复用节点。
- 第二轮更新:在第二步比较旧vnode的p-2 与新vnode的 p-2 中发现了可复用节点。
- 第三轮更新…(也是在第二步)
最后更新完后的状态:(具体移动步骤啥的就省略啦,跟前面一样)
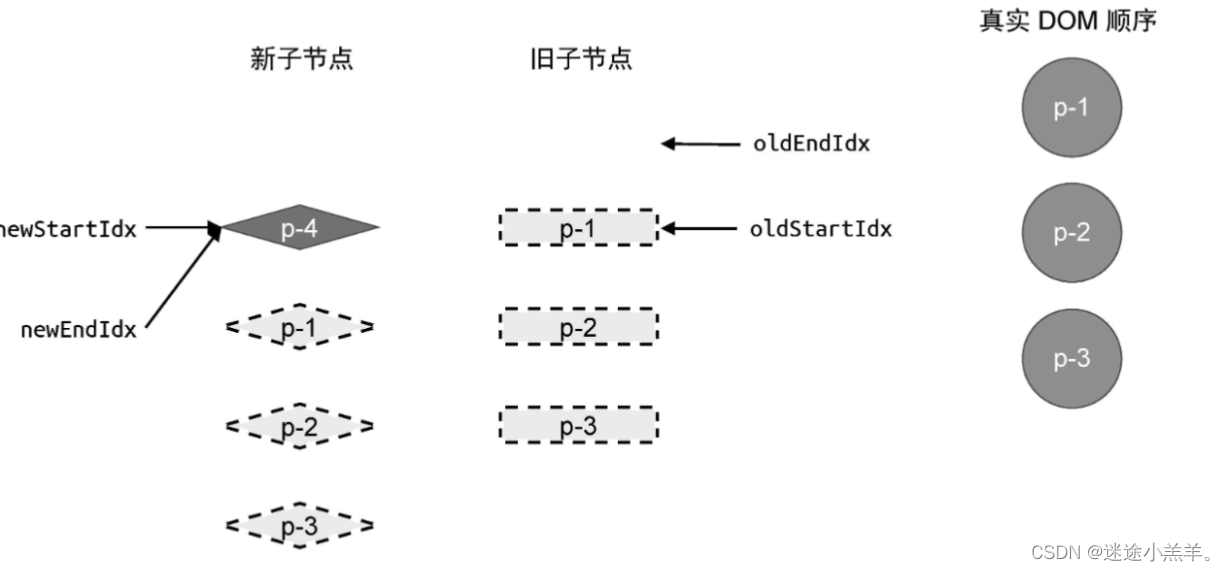
注意旧vnode的两个前后指针,这时满足了更新停止的 条件,但是节点p-4在整个更新过程中被遗漏了,这时就需要弥补这个缺陷,添加额外处理代码:
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
// ...省略
}
// 循环结束后检查索引值的情况:
if (oldEndIdx < oldStartIdx && newStartIdx <= newEndIdx) {
// 满足条件则说明有新节点遗留,需要进行挂载
for (let i = newStartIdx; i <= newEndIdx; i++) {
patch(null, newChildren[i], container, oldStartVNode.el);
}
}
代码解释都写在注释里了,注意一点:如何说明新vnode中有遗留的节点需要作为新vnode挂载?位于 索引值 newStartIdx 和 newEndIdx这个区间内的节点都是新节点。
4.移除不存在的元素:
解决了新增节点的问题,来思考如何移除旧vnode中多余的元素,如图:
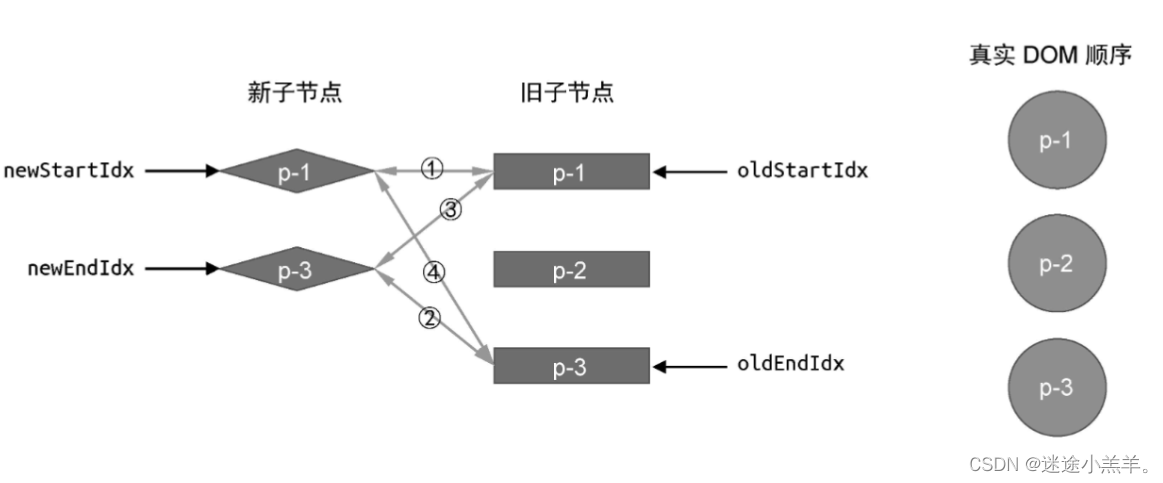
按照我们前面实现的diff算法来完成更新后,最后的状态应该是这样:
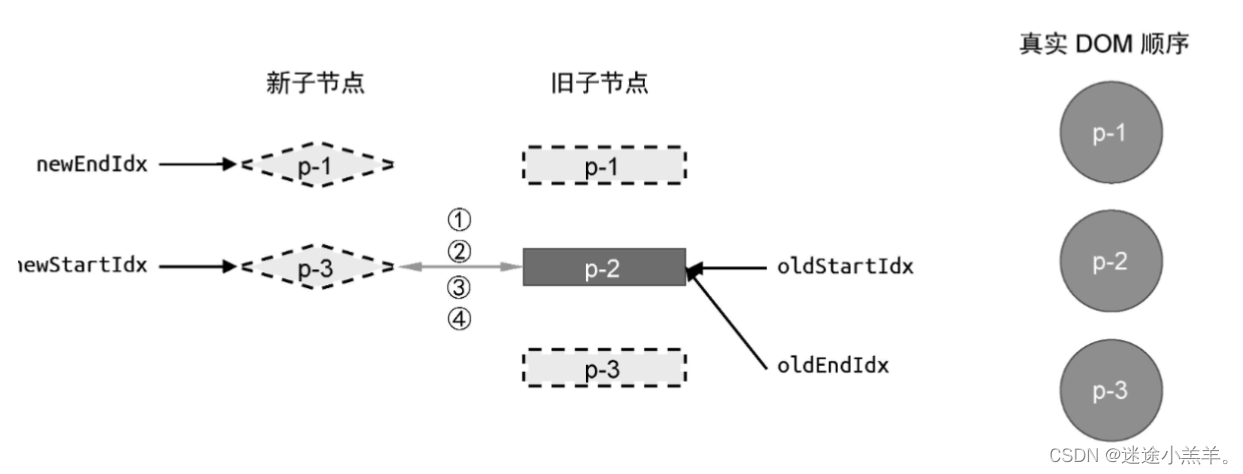
此时变量 newStartIdx > newEndIdx的值,满足更新停止的条件。但是看上图,旧vnode中还存在未被处理的节点,应该将其移除。所以我们需要增加额外的代码来处理它,如下图:
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
// ...省略
}
// 循环结束后检查索引值的情况:
if (oldEndIdx < oldStartIdx && newStartIdx <= newEndIdx) {
// ...省略(添加新节点)
} else if (newEndIdx < newStartIdx && oldStartIdx <= oldEndIdx) {
// 移除操作
for (let i = oldStartIdx; i <= oldEndIdx; i++) {
unmount(oldChildren[i]);
}
}
5.总结:
这章介绍了双端Diff算法的原理和优势,简单来说主要通过新旧vnode的前后指针来判断,有四种命中情况,命中一种则不再进行判断。








![[附源码]Nodejs计算机毕业设计基于WEB的心理测评系统Express(程序+LW)](https://img-blog.csdnimg.cn/fa55f326335c437785a39861e83f6d71.png)
