第7章 数据挖掘
1.什么是数据挖掘
数据挖掘(Data Mining)就是从大量的数据中,提取隐藏在其中的,事先不知道的、但潜在有用的信息的过程。数据挖掘的目标是建立一个决策模型,根据过去的行动数据来预测未来的行为。
2.阿里数据挖掘平台
阿里巴巴的算法平台选用MPI作为基础计算框架,其核心机器学习算法的开发都是基于阿里云MaxCompute的MPI实现的。
MaxCompute MPI处理流程图如下:
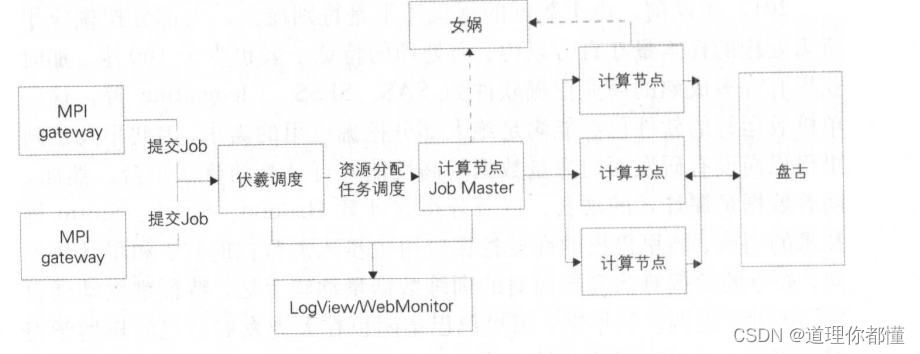
伏羲:阿里云飞天系统的分布式调度系统
女娲:阿里云飞天系统的分布式一致性协同服务系统
盘古:阿里云飞天系统的分布式文件存储系统
基于MaxCompute MPI的机器学习算法如下:
| 分类 | 具体算法 |
|---|---|
| 分类算法 | LogisticRegression、kNN、GBDT、DTC5.0、Randomforest、linearSVM、nonlinearSVM、NavieBayes、Bayes、Fisher 判别、马氏距离判别、标签传播分裂等 |
| 回归算法 | LinearRegression、GBDT、LASSO、RidgeRegression、Factorization Machines、XGBoost等 |
| 聚类算法 | K-Means、Canopy、PSC普聚类、标签传播聚类、EM 聚类等 |
| 推荐算法 | etrec 协同过滤、 SVD协同过滤、 ALS协同过滤等 |
| 深度学习 | Word2Vec、Doc2Vec、CNN、DBN、DeepMatchModel等 |
| 其他 | PageRank、LOA、pLSA、关联规则、NMF、CRF、SVD、RankSVM、PCA、kcore、sssp、Modularity 计算等 |
注:etrec 是阿里巴巴集团搜索算法团队开发的运行于 MaxCompute 上的基于商品的协同过滤算法
3.数据挖掘中台体系
- 挖掘数据中台
数据挖掘的过程中包含两类数据:
特征数据
结果数据
数据中台分为三层:
特征层( Featural Data Mining Layer, FDM )
中间层:
个体中间层( Individual Data Mining Layer, IDM )
关系中间层( Relational Data Mining Layer, RDM )
应用层( Application-oriented Data Mining Layer, ADM )
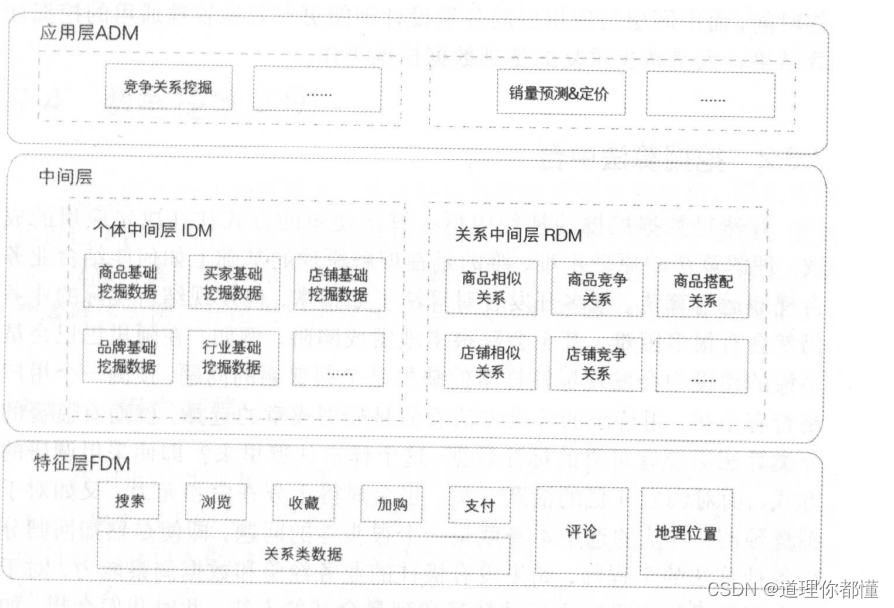
FDM层:用于存储在模型训练前常用的特征指标,并进行统一的清洗和去噪处理,提升机器学习特征工程环节的效率。
IDM层:个体挖掘指标中间层,面向个体挖掘场景,用于存储通用性强的结果数据,主要包含商品、卖家、买家、行业等维度的个体数据挖掘的相关指标
RDM层:关系挖掘指标中间层,面向关系挖掘场景,用于存储通用性强的结果数据,主要包含商品间的相似关系、竞争关系,店铺间的相似关系、竞争关系等。
ADM 层:用来沉淀比较个性偏应用的数据挖掘指标,比如用偏好的类目、品牌等,这些数据已经过深度的加工处理,满足某一特点业务或产品的使用。
- 挖掘算法中台
算法是数据挖掘的神经中枢。
数据挖掘算法中台的建设目的是从各种各样的挖掘场景中抽象出有代表性的几类场景,并形成相应的方法论和实操模板。常见的数据挖掘应用如下:

4.数据挖掘案例
- 用户画像
利用数据分析辅以算法的视角对用户进行特征刻画,为用户打上各种各样的标签。
- 互联网反作弊
从业务上看,反作弊工作主要体现在以下几个方面:
(1)账户/资金安全与网络欺诈防控
(2)非人行为和账户识别
(3)虚假订单与信用炒作识别
(4)广告推广与 APP 安装反作
(5)UGC 恶意信息检测
从所采用的算法技术上说,反作弊方法主要包括如下几类:
(1)基于业务规则的方法
这类方法主要是根据实际的业务场景,不断地发现总结作弊和获利手法,通过反作弊规则的不断拓展或产品设计的完善来识别、缓解甚至消除作弊现象。
优点:精度高、可解释性强,能准确识别老的作弊方式;
缺点:人力成本高,而且对新的作弊手法滞后性较强。
(2)基于有监督学习的方法
按照有监督分类算法的流程来建模,通过正负样本标记、特征提取、模型训练及预测等过程来识别作弊行为。
优点:通用性强,人力成本主要集中在样本的标记和特
缺点:会出现类不平衡现象,有些算法结果的可解释性不强,容易造成错判,需要辅以其他指标和方法进行综合判断。
(3)基于无监督学习的方
在此类方法中较常见的是异常检测算法,该方法假设作弊行为极其见且在某些特征维度下和正常行为能够明显地区分开来。
优点:不需要标记正负样本,而且检测到的异常行为还可以沉淀到规则系统中
缺点:特征设计和提取的工作量大,需要在所有可能的风险维度下刻画行为特征。
应用:
(1)离线反作弊系统
离线反作弊系统主要包含规则判断、分类识别、异常检测等模块,通过历史行为和业务规则的沉淀,来判断未来行为的作弊情况。
优点:准确率较高, 所使用的历史数据越多,判断结果越准确。
缺点:时效性较差,无法及时给出判断结果
(2)实时反作弊系统
随着在某些场景下对时效性要求的不断提高,人们逐渐发现实时反作弊系统的必要性和重要性。所以,将离线中的许多规则和算法进行总结,在基本满足准确率和覆盖率的前提下抽取出其中计算速度较快的准确率为代价,而且由于数据需要进行实时采集和计算,所以对数据存储和计算系统的性能要求也非常高。
挑战:
作弊手段的多样性和多变性
算法的及时性和准确性
数据及作弊手段的沉淀和逆向反馈