OpenMLDB 提供了一个线上线下一致性的特征平台。其中,为了支持低延迟高并发的在线实时特征计算,OpenMLDB 设计实现了一个高性能的实时 SQL 引擎。本报告覆盖了 OpenMLDB 实时 SQL 引擎的性能测试,包含了在较为复杂的负载、典型配置下的各种性能指标。
了解更多关于 OpenMLDB
**官网:**https://openmldb.ai/
**GitHub:**https://github.com/4paradigm/OpenMLDB/
实时特征计算平台架构方法论和基于 OpenMLDB 的实践
实验环境
本次测试一共使用四台服务器进行,其中 OpenMLDB 服务部署在三台服务器,客户端部署在一台服务器,四台服务器使用的硬件配置一致,实验环境如下表格 Table-1 所示。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rjEIUSGZ-1671010026101)(null)]
Table-1:实验环境配置
测试负载
测试工具和脚本
本测试所使用的测试工具以及使用说明,可以在我们的 GitHub benchmark 页面下载,对本测试进行复现。

https://github.com/4paradigm/OpenMLDB/tree/main/benchmark
测试方法
本次测试主要用于展示 OpenMLDB 在不同工作负载和运行环境下的性能表现,因此使用基于参数变化的方法进行测试,来理解不同的参数对于性能的影响:
首先定义一组我们需要研究展示的参数变量,这部分参数可以分为三类:
系统参数:线程数目,是否打开预聚合优化
查询参数:窗口数目,LAST JOIN 个数
数据参数:窗口内数据条数,被索引列的基数(即 cardinality,列数据去重后的唯一值数目)
对于所有参数,确定一组典型情况下的默认参数值,其默认参数值配置详见 Table-2 。其中,预聚合优化一般针对窗口内数据量巨大(比如几百万条的情况)打开优化才有意义,所以其默认配置为关闭。
确定好默认参数以后,对于每一个实验参数,进行一定合理范围内的取值变化,同时保持其他参数默认不变,观察在不同参数下的性能数字和趋势表现,其参数的变化取值范围如 Table-3 。

Table-2:实验参数以及默认值

Table-3:实验参数取值变化范围
数据集
本次测试基于多个数据表进行,其默认参数下的基准表格建立语句如下。对于某些和表格参数有关的 SQL,部分语句会按照一定的模式进行调整(比如窗口数目,LAST JOIN 数目的变化),在每一个实验下面给出了详细的建表和查询 SQL。
基准表格建立 SQL
CREATE TABLE mt (
col_s0 string,col_s1 string,col_s2 string,col_s3 string,col_s4 string,col_s5 string,col_s6 string,col_s7 string,col_s8 string,col_s9 string,col_s10 string,col_s11 string,col_s12 string,col_s13 string,col_s14 string,col_d0 double,col_d1 double,col_d2 double,col_d3 double,col_d4 double,col_t0 timestamp,col_t1 timestamp,col_t2 timestamp,col_t3 timestamp,col_t4 timestamp,col_i0 bigint,col_i1 bigint,col_i2 bigint,col_i3 bigint,col_i4 bigint,index(key = col_s0, ttl=0m, ttl_type=absolute, ts = col_t0),index(key = col_s1, ttl=0m, ttl_type=absolute, ts = col_t0),) OPTIONS (REPLICANUM = 1);
CREATE TABLE lt0 (
col_s0 string,col_s1 string,col_s2 string,col_s3 string,col_s4 string,col_s5 string,col_s6 string,col_s7 string,col_s8 string,col_s9 string,col_s10 string,col_s11 string,col_s12 string,col_s13 string,col_s14 string,col_d0 double,col_d1 double,col_d2 double,col_d3 double,col_d4 double,col_t0 timestamp,col_t1 timestamp,col_t2 timestamp,col_t3 timestamp,col_t4 timestamp,col_i0 bigint,col_i1 bigint,col_i2 bigint,col_i3 bigint,col_i4 bigint,index(key = col_s0, ttl=0m, ttl_type=absolute, ts = col_t0),) OPTIONS (REPLICANUM = 1);
CREATE TABLE lt1 (
col_s0 string,col_s1 string,col_s2 string,col_s3 string,col_s4 string,col_s5 string,col_s6 string,col_s7 string,col_s8 string,col_s9 string,col_s10 string,col_s11 string,col_s12 string,col_s13 string,col_s14 string,col_d0 double,col_d1 double,col_d2 double,col_d3 double,col_d4 double,col_t0 timestamp,col_t1 timestamp,col_t2 timestamp,col_t3 timestamp,col_t4 timestamp,col_i0 bigint,col_i1 bigint,col_i2 bigint,col_i3 bigint,col_i4 bigint,index(key = col_s0, ttl=0m, ttl_type=absolute, ts = col_t0),) OPTIONS (REPLICANUM = 1);`
其中,数据表内的 String 类型长度为 10 bytes,其余字段为随机生成的数据。
测试 SQL
我们使用一个较为复杂的实际场景中可能使用到的 SQL 进行测试。由于我们的部分实验参数会针对不同的 SQL 负载进行调整(窗口数目,LAST JOIN 表的个数),所以具体 SQL 会有一定的变化。下面的 SQL 表示了在默认参数下的基准查询语句(除了预聚合实验)。对于不同的窗口数目以及 LAST JOIN 数目,相应的 WINDOW 相关,以及 LAST JOIN 相关的语句会相应变化。具体每个实验的 SQL 脚本,可以参照每个实验结果下附上的脚本文件。
默认参数下的基准负载 SQL:
SELECT * FROM
(SELECT
col_s0,
concat(col_s1, col_d0) as concat_col_s1,
upper(col_s2) as upper_col_s2,
substr(col_s3, 3) as substr_col_s3,
year(col_t0) as year_col_t0,
string(col_i2) as str_col_i2,
add(col_i1, col_i3) as add_i1_i3,
distinct_count(col_s1) OVER w0 AS distinct_count_w0_col_s1,
sum(col_i1) OVER w0 AS sum_w0_col_i1,
count(col_s11) OVER w0 AS count_w0_col_s11,
avg(col_i4) OVER w0 AS avg_w0_col_i4,
case when !isnull(at(col_s5, 0)) OVER w0 then count(col_s5) OVER w0 else null end AS case_when_count_w0_col_s5,
case when !isnull(at(col_i3, 0)) OVER w0 then count(col_i3) OVER w0 else null end AS case_when_count_w0_col_i3,
distinct_count(col_s1) OVER w1 AS distinct_count_w1_col_s1,
sum(col_i1) OVER w1 AS sum_w1_col_i1,
count(col_s11) OVER w1 AS count_w1_col_s11,
avg(col_i4) OVER w1 AS avg_w1_col_i4,
case when !isnull(at(col_s5, 0)) OVER w1 then count(col_s5) OVER w1 else null end AS case_when_count_w1_col_s5,
case when !isnull(at(col_i3, 0)) OVER w1 then count(col_i3) OVER w1 else null end AS case_when_count_w1_col_i3,
from mt
WINDOW w0 as ( partition by col_s0 order by col_t0 rows_range between 30d PRECEDING AND CURRENT ROW MAXSIZE 1000),
w1 as ( partition by col_s1 order by col_t0 rows_range between 30d PRECEDING AND CURRENT ROW MAXSIZE 1000)
) as out0 LAST JOIN
(SELECT
lt0.col_s0 as out1_col_s0,
concat(lt0.col_s1, mt.col_d0) as out1_concat_col_s1,
upper(mt.col_s2) as out1_upper_col_s2,
substr(lt0.col_s3, 3) as out1_substr_col_s3,
year(mt.col_t0) as out1_year_col_t0,
string(lt0.col_i2) as out1_str_col_i2,
add(lt0.col_i1, mt.col_i3) as out1_add_i1_i3
from mt LAST JOIN lt0 order by lt0.col_t0 ON mt.col_s0 = lt0.col_s0
) as out1 ON out0.col_s0 = out1.out1_col_s0 LAST JOIN
(SELECT
lt1.col_s0 as out2_col_s0,
concat(lt1.col_s1, mt.col_d0) as out2_concat_col_s1,
upper(mt.col_s2) as out2_upper_col_s2,
substr(lt1.col_s3, 3) as out2_substr_col_s3,
year(mt.col_t0) as out2_year_col_t0,
string(lt1.col_i2) as out2_str_col_i2,
add(lt1.col_i1, mt.col_i3) as out2_add_i1_i3
from mt LAST JOIN lt1 order by lt1.col_t0 ON mt.col_s0 = lt1.col_s0
) as out2 ON out0.col_s0 = out2.out2_col_s0;
注意,由于目前部分聚合函数(如 distinct_count)在 OpenMLDB v0.5.0 还不支持预聚合优化,因此预聚合优化技术的实验的 SQL 是单独生成的,详见相关实验章节。我们在预聚合完善以后将会更新本份报告。
测试指标
在本次测试中,我们主要使用两种性能指标
延迟(latency):使用业界常用的 top percentile 定义(详见解释 Latency metrics | Cloud Spanner | Google Cloud),图上标记为 TPXX,即 XXth percentile latency
吞吐(throughput):使用 QPS ,即 queries per second,代表了每秒处理的请求数量
测试结果
「系统参数」
线程数变化
Figure-1 显示了在固定其他默认参数,线程数目变化的情况下,延迟和吞吐的性能表现。可以看到,随着线程的增加,请求延迟都呈现上升的趋势。而明显的上升拐点是当线程数为 20 时,增加线程数目会显著增加请求的延迟。总体来说,延迟均保持在个位数毫秒级别。对于吞吐,增加线程数目可以显著提升吞吐表现,在该较为复杂的场景下可以达到万级别的吞吐。
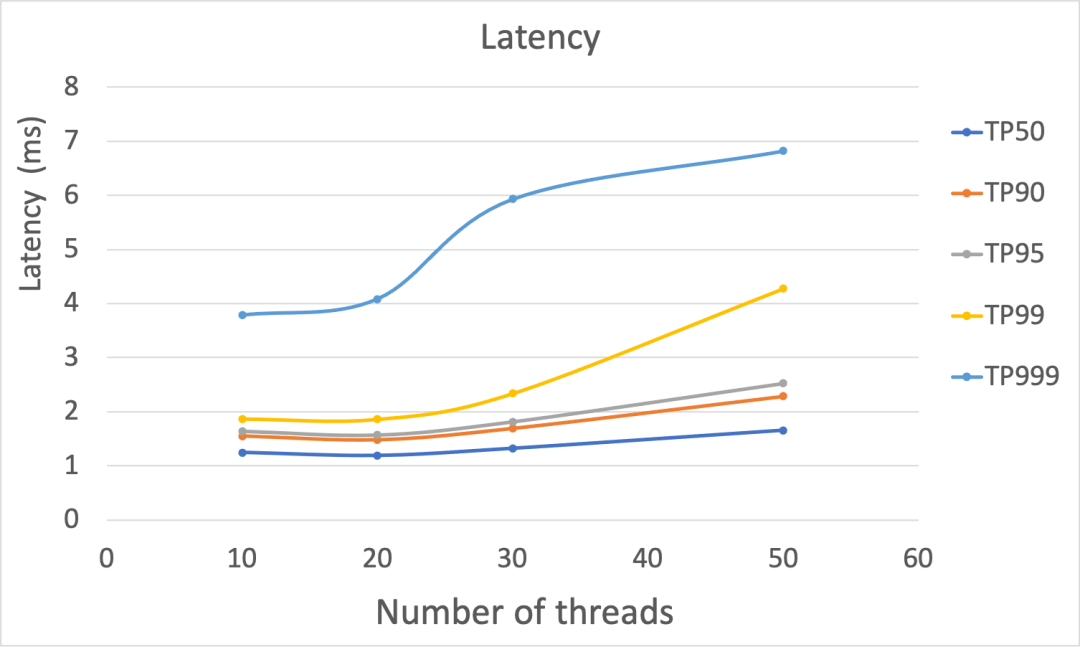
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AuPPJx9P-1671010028922)(null)]
Figure-1: 在线程数目变化的情况下,延迟(上图)和吞吐(下图)的性能表现
数据和查询脚本
该实验使用了基准的表格数据和查询 SQL 脚本(参见章节 “2.2. 数据集” 和 “2.3. 测试 SQL”)。
预聚合优化
预聚合实验配置
如之前所提到,由于预聚合还不能支持所有的聚合函数,因此针对预聚合的测试,我们单独设计了一套查询 SQL 进行测试,相关脚本附上。
/* Create table */
CREATE TABLE mt (
col_s0 string,col_s1 string,col_s2 string,col_s3 string,col_s4 string,col_s5 string,col_s6 string,col_s7 string,col_s8 string,col_s9 string,col_s10 string,col_s11 string,col_s12 string,col_s13 string,col_s14 string,col_d0 double,col_d1 double,col_d2 double,col_d3 double,col_d4 double,col_t0 timestamp,col_t1 timestamp,col_t2 timestamp,col_t3 timestamp,col_t4 timestamp,col_i0 bigint,col_i1 bigint,col_i2 bigint,col_i3 bigint,col_i4 bigint,index(key = col_s0, ttl=0m, ttl_type=absolute, ts = col_t0),) OPTIONS (REPLICANUM = 1);
/* Deploy SQL */
DEPLOY demo_long OPTIONS(long_windows="w0:1000")
/* Query */
SELECT
col_s0,count(col_s11) OVER w0 AS count_w0_col_s11,
FROM mt
WINDOW w0 as (partition by col_s0 order by col_t0 rows_range between 30d PRECEDING AND CURRENT ROW);
其相关的参数设置和变化参数显示在 Table-4 中:

Table-4:预聚合优化实验的参数设置
预聚合实验结果
结果如下图 Figure-2 所示,开启预聚合优化时,其延迟显著低于不开启预聚合的情况,随着窗口内数据条数增多,这样的差距随之变大,整体来说,预聚合技术在长窗口的情形下,对于延迟达到了两个数量级左右的性能提升。注意,由于两者性能差距巨大,以下图片纵坐标均使用了对数坐标。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wT6aw0mW-1671010027348)(null)]
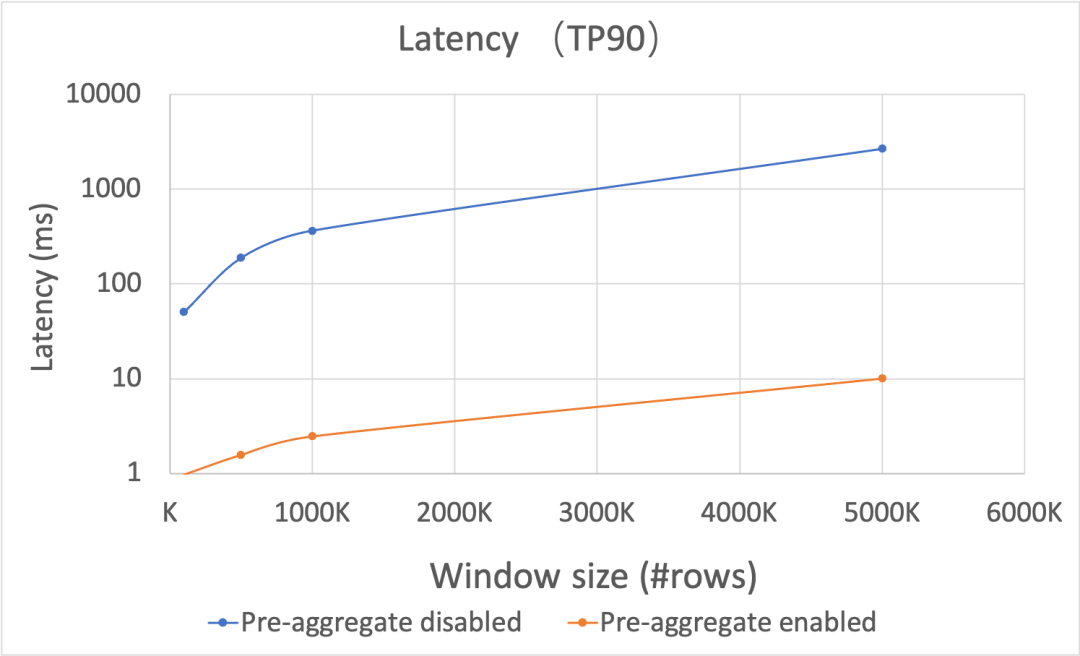
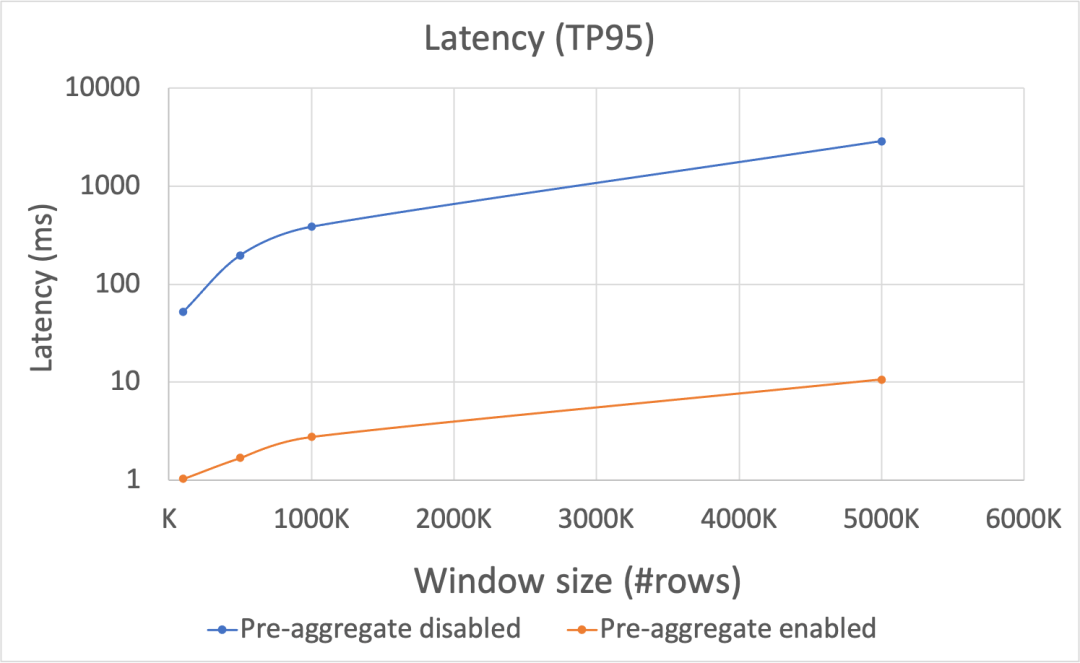
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lri8mJSB-1671010029711)(null)]

Figure-2: 在窗口内数据条数变化的情况下,延迟性能表现
下图 Figure-3 显示了当在不同的窗口大小下,是否使用预聚合的吞吐性能表现:当窗口内数据行数变多,两种情况的吞吐性能都呈现下降趋势,但是开启预集合技术的吞吐量远远高于不使用的情况,而且当窗口变大时,这样的差距更加明显,超过 200 倍。注意,由于两者性能差距巨大,以下图片纵坐标使用了对数坐标。
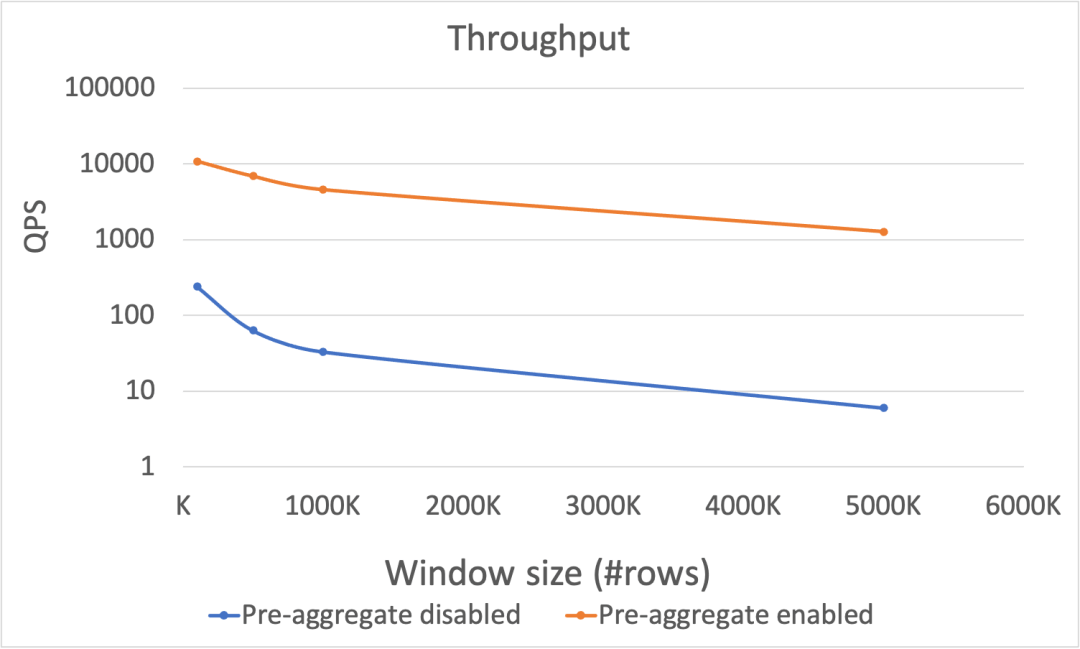
Figure-3: 在窗口内数据条数变化的情况下,吞吐性能表现
「查询参数」
窗口数变化
Figure-4 显示了不同窗口数量的情况下,延迟和吞吐的性能表现。随着窗口的数目的上升,请求延迟呈现明显的上升趋势,其中,当 top percentile 值为 TP999 时,与其他情形差距更大,但是也都保持在个位数的毫秒级别。对于吞吐,窗口数量增多,吞吐缓慢减少,并呈现不断下降的趋势。
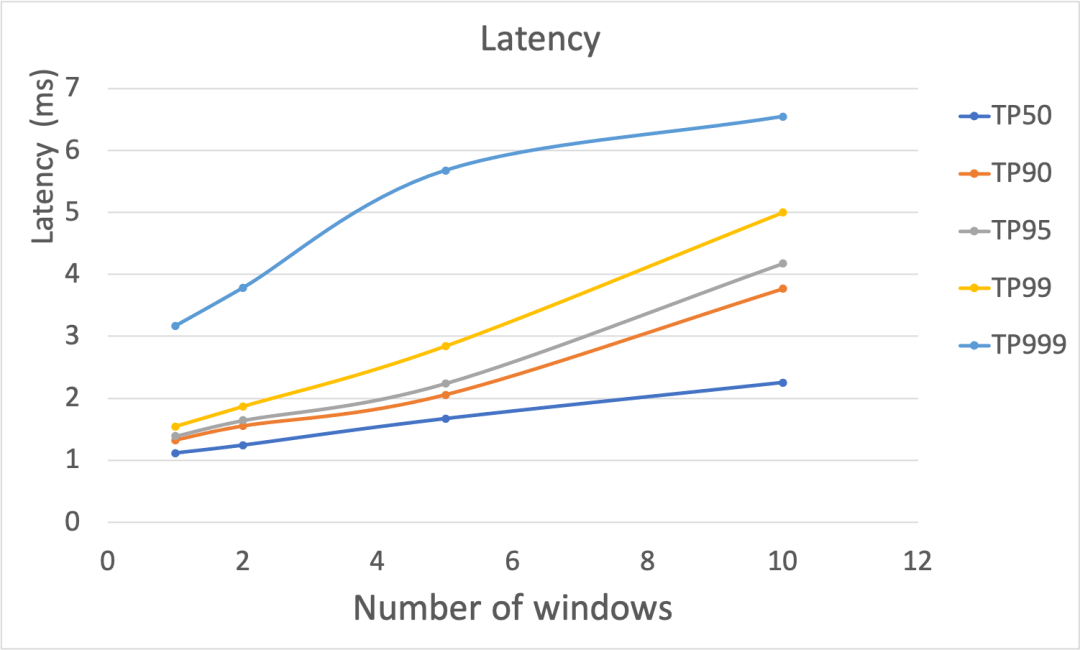
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UhzilKYH-1671010031803)(null)]
Figure-4: 在窗口数目变化的情况下,延迟(上图)和吞吐(下图)的性能表现
数据和查询脚本
窗口数不同时,脚本有相应变化,具体代码请参照:
http://openmldb.ai/download/benchmark/num_win_1.sql
http://openmldb.ai/download/benchmark/num_win_2.sql
http://openmldb.ai/download/benchmark/num_win_5.sql
http://openmldb.ai/download/benchmark/num_win_10.sql
LAST JOIN 个数变化
Figure-5 显示了在 LAST JOIN 数目变化时,延迟和吞吐的表现。随着 LAST JOIN 表数量的增加,不同 TP 指标下,延迟都呈现平缓的上升趋势,其中 TP999 与其他指标下的数字有非常明显的差距,但是都在5毫秒以内。而随着 LAST JOIN 表数量的增加,吞吐性能稍有下降,但是整体维持在6千以上。
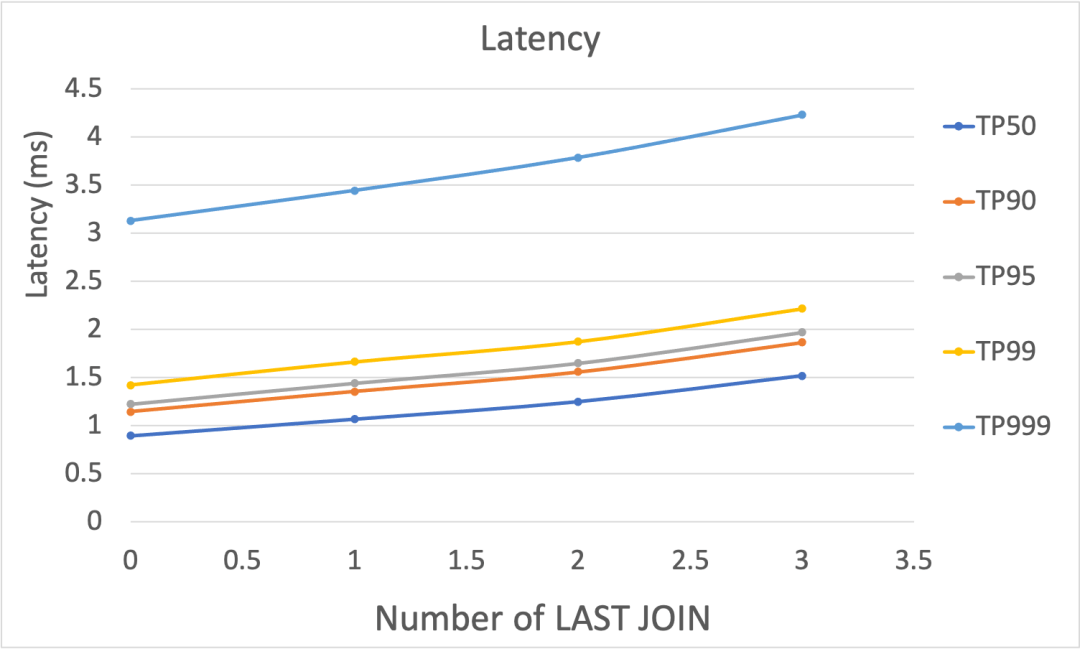
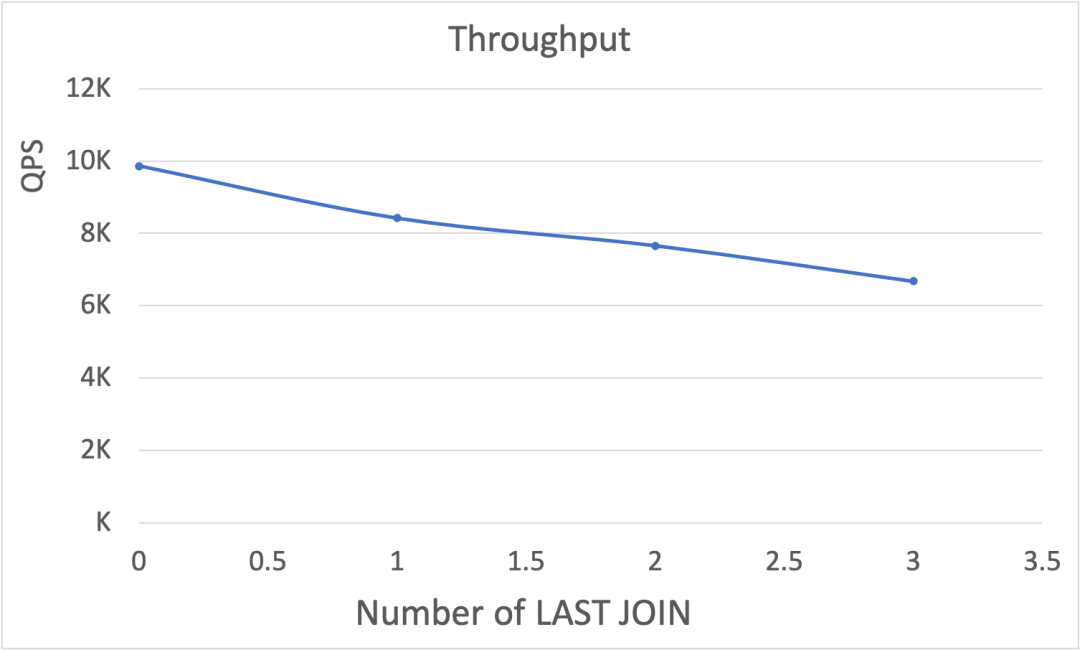
Figure-5: 在LAST JOIN表数目变化的情况下,延迟(上图)和吞吐(下图)的性能表现
数据和查询脚本
LAST JOIN 个数不同时,脚本有相应变化,具体代码请参照:
http://openmldb.ai/download/benchmark/num_lastjoin_0.sql
http://openmldb.ai/download/benchmark/num_lastjoin_1.sql
http://openmldb.ai/download/benchmark/num_lastjoin_2.sql
http://openmldb.ai/download/benchmark/num_lastjoin_3.sql
「数据参数」
窗口内数据条数变化
Figure-6 显示了在窗口内数据条数变化时,延迟和吞吐的表现。随着窗口内数据条数的增多,延迟都呈现非常明显的上升趋势,但是基本都在 10 毫秒以内。增加窗口内数据条数时,吞吐性能会有较为显著的下降。
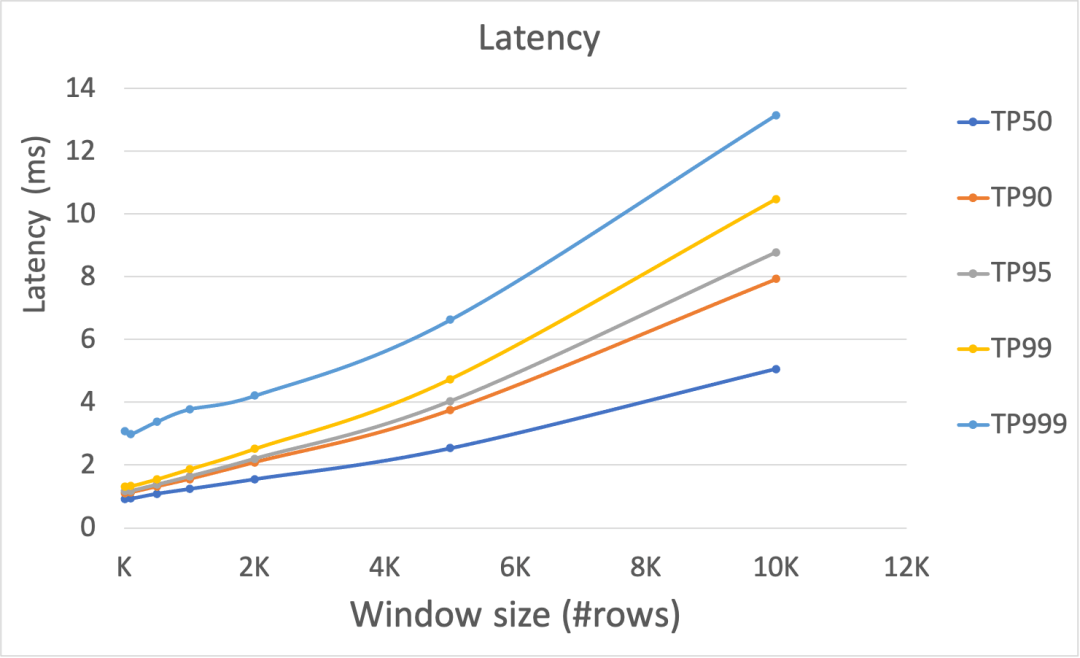
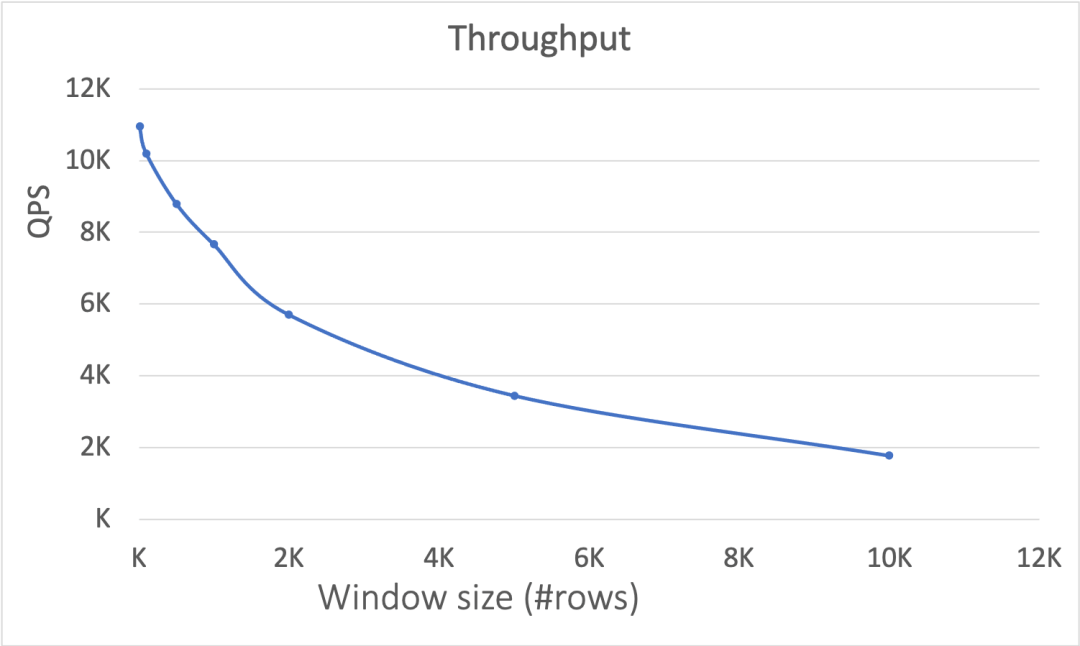
Figure-6: 在窗口内数据条数变化的情况下,延迟(上图)和吞吐(下图)的性能表现
数据和查询脚本
该实验使用了基准的表格数据和查询 SQL 脚本(参见章节 “2.2. 数据集” 和 “2.3. 测试 SQL”)。
索引列基数变化
Figure-7 显示了在索引列的基数变化时,延迟和吞吐的表现。随着基数增加,每一种 top percentile 参数下,耗时无明显变化,但是 TP999 的延迟明显较高。同时,吞吐没有明显的变化,QPS 值基本维持在7000以上。
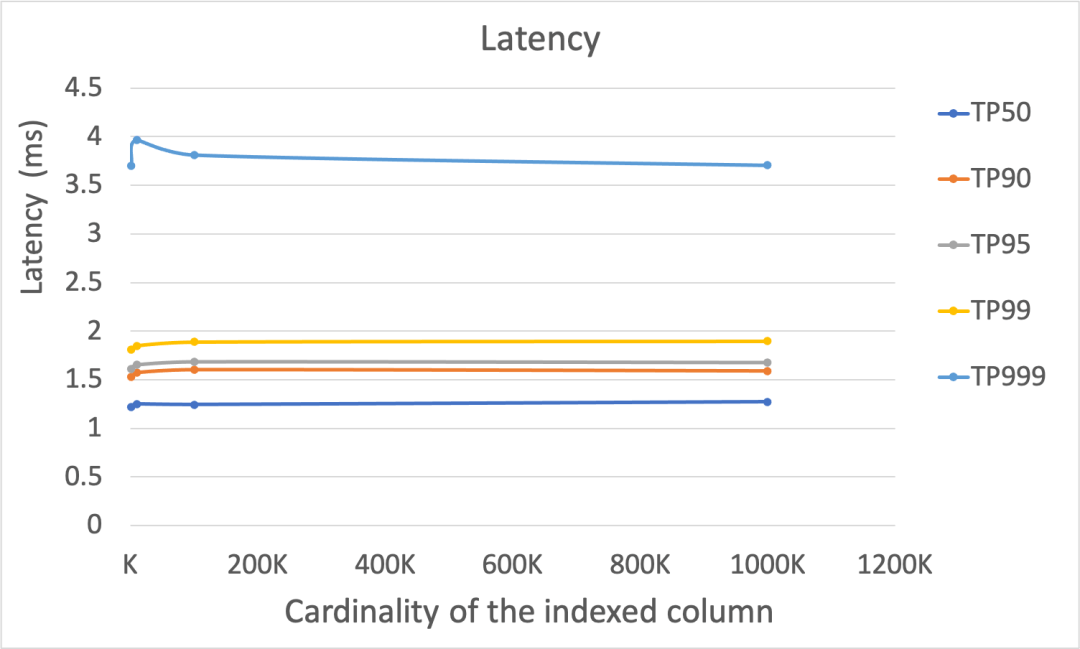
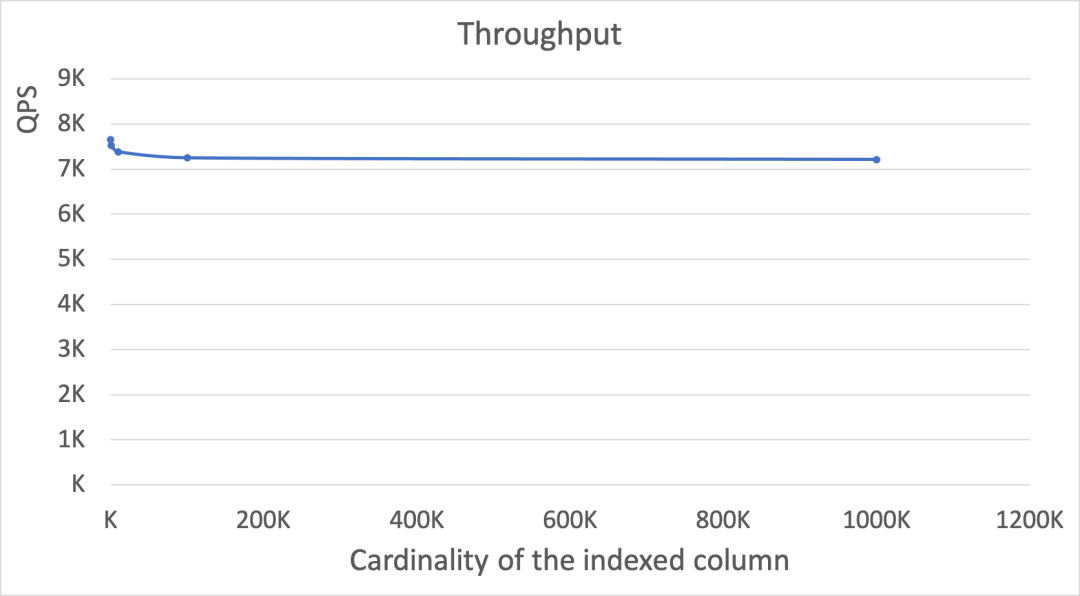
Figure-7: 在索引列基数变化的情况下,延迟(上图)和吞吐(下图)的性能表现
数据和查询脚本
该实验使用了基准的表格数据和查询 SQL 脚本(参见章节 “2.2. 数据集” 和 “2.3. 测试 SQL”)。
联系我们
如果你对上述实验报告内容有任何问题,欢迎在社区渠道和我们取得联系。
GitHub Issues
https://github.com/4paradigm/OpenMLDB/issues
对于严肃的使用者和开发者,关于程序使用过程中遇到的任何问题或者特性诉求,欢迎来我们的项目需求搜基地给我们提出反馈和意见。我们会对每一个反馈的 issue 给出 feedback,并且在项目规划的时候会有效考虑社区需求。
微信使用交流群
关于 OpenMLDB 的任何使用问题,扫码进群

Roadmap
https://github.com/4paradigm/OpenMLDB/projects/10
我们在此汇集了开发历程,对于规划中的 Roadmap,你可以在相关 issues 下参与讨论:
如果你有意愿参与其中已经规划的开发计划,请留言和我们互动,确认以后请认领相关 issue,成为 owner
如果你有特别希望在下一个版本中加入的产品特性,也可以留言和我们进行讨论,确认以后我们将正式加入到 roadmap
Slack
https://openmldb.slack.com/join/shared_invite/zt-ozu3llie-Khn9Ss1GZcFW2K_L5sMg#/shared-invite/email
你也可以在 Slack 上我和我们进行实时交流,有关任何的使用或者开发问题。
有关任何问题,也可以通过 Email 和我们联系:contact@openmldb.ai
开发者邮件列表
https://groups.google.com/u/3/g/openmldb-developers
我们维护了一个针对开发者的邮件列表,有关开发的重要事项将会在群里通知讨论。如果你有意愿参与 OpenMLDB 的开发,你可以加入我们的 OpenMLDB-Developers Google Group ,通过验证以后即可以通过邮件列表方式和我们的社区开发者互动。






![[附源码]Nodejs计算机毕业设计基于Web学术会议投稿管理系统Express(程序+LW)](https://img-blog.csdnimg.cn/2638f337dcd848198bc7ce303ce612d8.png)