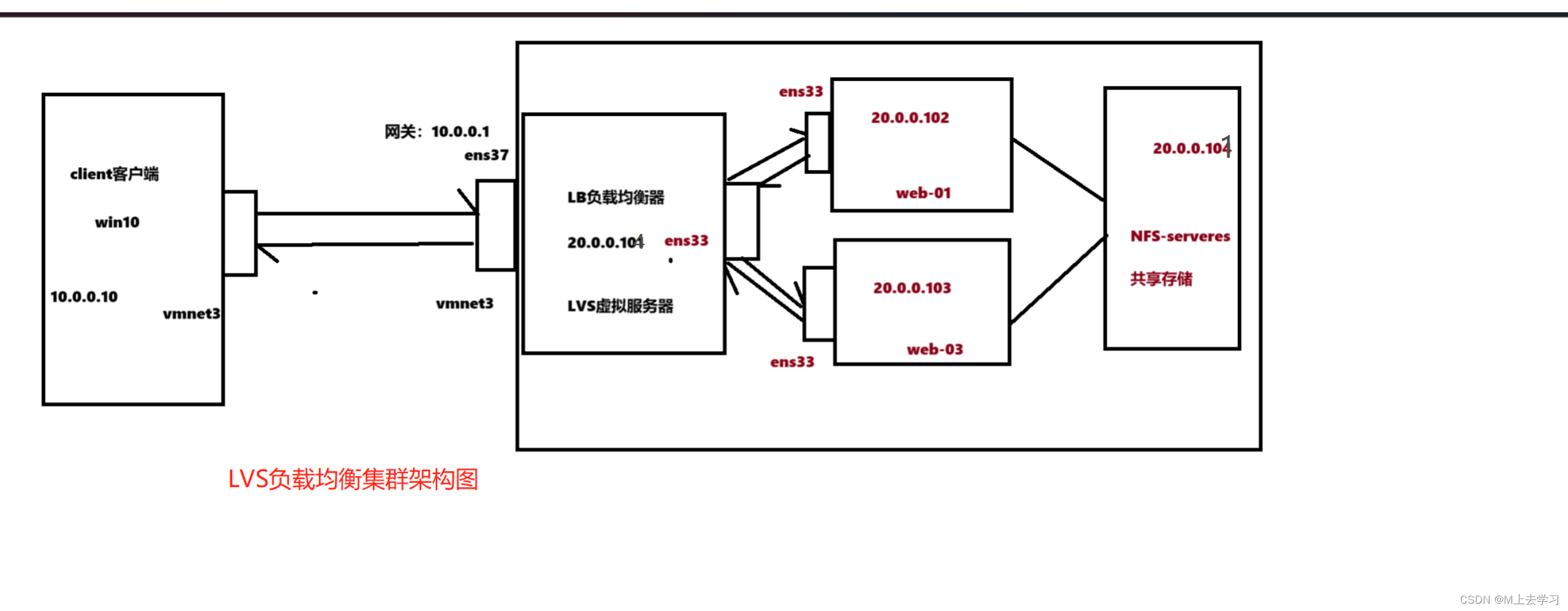
前面我们仅仅取了两个特征维度进行说明。在实际应用中,可能存在着更多特征维度需要计算。
下面以手写数字识别为例进行简单的介绍。
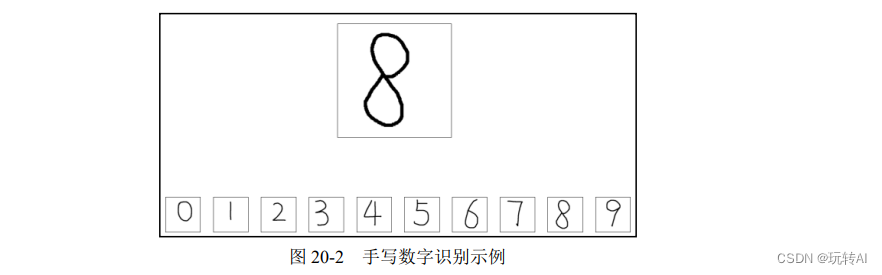
假设我们要让程序识别图 20-2 中上方的数字(当然,你一眼就知道是“8”,但是现在要让计算机识别出来)。识别的方式是,依次计算该数字图像(即写有数字的图像)与下方数字图像的距离,与哪个数字图像的距离最近(此时 k =1),就认为它与哪幅图像最像,从而确定这幅图像中的数字是多少。
下面分别从特征值提取和数字识别两方面展开介绍。
1. 特征值提取
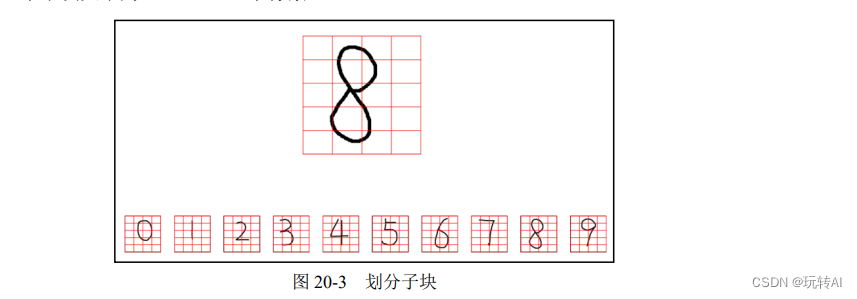
步骤 1:我们把数字图像划分成很多小块,如图 20-3 所示。该图中每个数字被分成 5 行 4列,共计 5×4 = 20 个小块。此时,每个小块是由很多个像素点构成的。当然,也可以将每一个像素点理解为一个更小的子块。
为了叙述上的方便,将这些小块表示为 B(Bigger),将 B 内的像素点,记为 S(Smaller)。
因此,待识别的数字“8”的图像可以理解为:
- 由 5 行 4 列,共计 5×4=20 个小块 B 构成。
- 每个小块 B 内其实是由 M×N 个像素(更小块 S)构成的。为了描述上的方便,假设每个小块大小为 10×10 =100 个像素。
步骤 2:计算每个小块 B 内,有多少个黑色的像素点。或者这样说,计算每个小块 B 内有
多少个更小块 S 是黑色的。
仍以数字“8”的图像为例,其第 1 行中:
- 第 1 个小块 B 共有 0 个像素点(更小块 S)是黑色的,记为 0。
- 第 2 个小块 B 共有 28 个像素点(更小块 S)是黑色的,记为 28。
- 第 3 个小块 B 共有 10 个像素点(更小块 S)是黑色的,记为 10。
- 第 4 个小块 B 共有 0 个像素点(更小块 S)是黑色的,记为 0。
以此类推,计算出数字“8”的图像中每一个小块 B 中有多少个像素点是黑色的,如图 20-4 所示。我们观察后会发现,不同的数字图像中每个小块 B 内黑色像素点的数量是不一样的。正是这种不同,使我们能用该数量(每个小块 B 内黑色像素点的个数)作为特征来表示每一个数字。
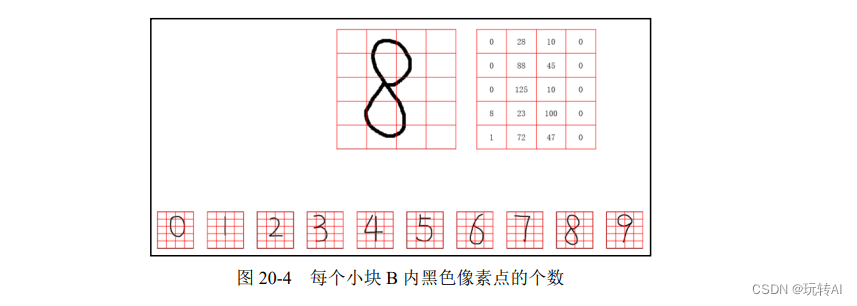
步骤 3:有时,为了处理上的方便,我们会把得到的特征值排成一行(写为数组形式),如图 20-5 所示。
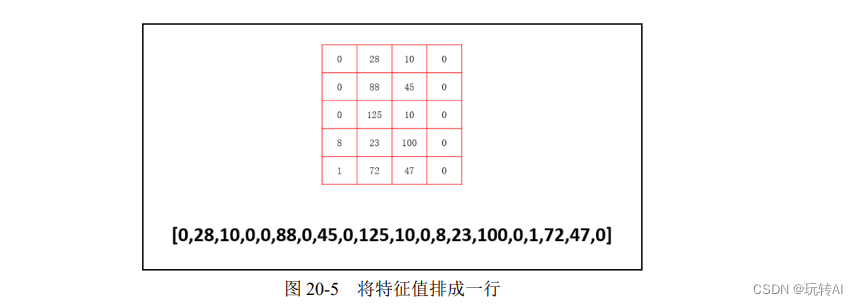
当然,在 Python 里完全没有必要这样做,因为 Python 可以非常方便地直接处理图 20-5 中上方数组(array)形式的数据。这里为了说明上的方便,仍将其特征值处理为一行数字的形式。
经过上述处理,数字“8”图像的特征值变为一行数字,如图 20-6 所示。
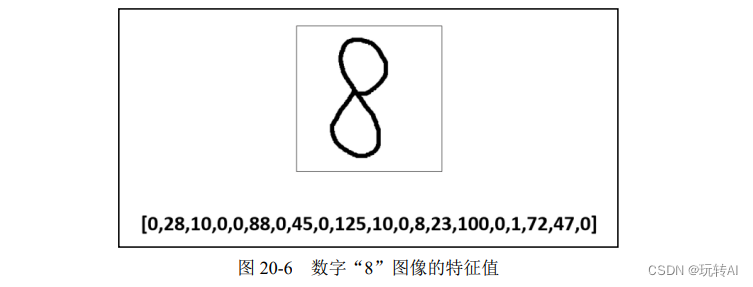
步骤 4:与数字“8”的图像类似,每个数字图像的特征值都可以用一行数字来表示。从某种意义上来说,这一行数字类似于我们的身份证号码,一般来说,具有唯一性。
按照同样的方式,获取每个数字图像的特征值,如图 20-7 所示。

2. 数字识别
数字识别要做的就是比较待识别图像与图像集中的哪个图像最近。这里,最近指的是二者之间的欧氏距离最短。
本例中为了便于说明和理解进行了简化,将原来下方的 10 个数字减少为 2 个(也即将分类从 10 个减少为 2 个)。
假设要识别的图像为图 20-8 中上方的数字“8”图像,需要判断该图像到底属于图 20-8 中下方的数字“8” 图像的分类还是数字“7”图像的分类。
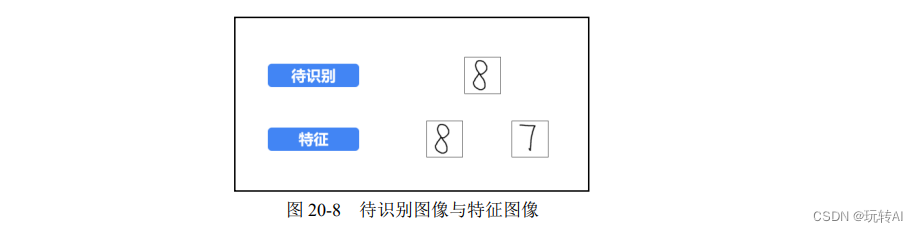
步骤 1:提取特征值,分别提取待识别图像的特征值和特征图像的特征值。
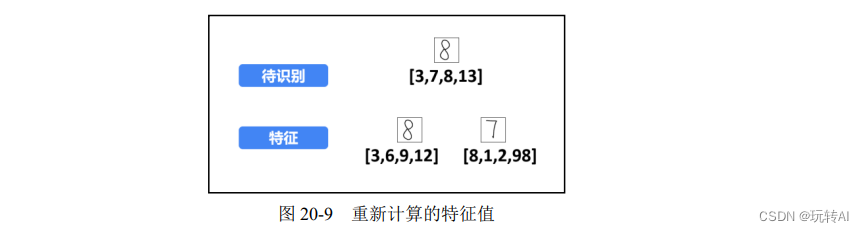
为了说明和理解上的方便,将特征进行简化,每个数字图像只提取 4 个特征值(划分为 2×2 = 4 个子块 B),如图 20-9 所示。此时,提取到的特征值分别为:
- 待识别的数字“8”图像:[3, 7, 8, 13]
- 数字“8”特征图像:[3, 6, 9, 12]
- 数字“7”特征图像:[8, 1, 2, 98]
步骤 2:计算距离。按照 20.1 节介绍的欧氏距离计算方法,计算待识别图像与特征图像之间的距离。
首先,计算待识别的数字“8”图像与下方的数字“8”特征图像之间的距离,如图 20-10所示。计算二者之间的距离:

接下来,计算待识别的数字“8”图像与数字“7”特征图像之间的距离,如图 20-11 所示。二者之间的距离为:

通过计算可知,待识别的数字“8”图像:
- 与数字“8”特征图像的距离为根号3=1.732050807568877。
- 与数字“7”特征图像的距离为根号7322=85.56868586112562。
步骤 3:识别。
根据计算的距离,待识别的数字“8”图像与数字“8”特征图像的距离更近。所以,将待识别的数字“8”图像识别为数字“8”特征图像所代表的数字“8”。
上面介绍的是 K 近邻算法只考虑最近的一个邻居的情况,相当于 K 近邻中 k =1 的情况。在实际操作中,为了提高可靠性,需要选用大量的特征值。例如,每个数字都选用不同的形态的手写体 100 个,对于 0 ~ 9 这 10
个数字,共需要 100×10 =1000 幅特征图像。在识别数字时, 分别计算待识别的数字图像与这些特征图像之间的距离。这时,可以将 k
调整为稍大的值,例如 k =11,然后看看其最近的 11 个邻居分属于哪些特征图像。
例如,其中:
- 有 8 个属于数字“6”特征图像。
- 有 2 个属于数字“8”特征图像。
- 有 1 个属于数字“9”特征图像。
通过判断,当前待识别的数字为数字“6”特征图像所代表的数字“6”。
自定义函数手写数字识别
在本例中,0~9 的每个数字都有 10 个特征值。例如,数字“0”的特征值如图 20-12 所示。
为了便于描述,将所有这些用于判断分类的图像称为特征图像。

下面分步骤实现手写数字的识别。
1. 数据初始化
对程序中要用到的数据进行初始化。涉及的数据主要有路径信息、图像大小、特征值数量、用来存储所有特征值的数据等。
本例中:
- 特征图像存储在当前路径的“image_number”文件夹下。
- 用于判断分类的特征值有 100 个(对应 100 幅特征图像)。
- 特征图像的行数(高度)、列数(宽度)可以通过程序读取。也可以在图像上单击鼠标右键后通过查找属性值来获取。这里采用设置好的特征图像集,每个特征图像都是高240 行、宽 240 列。
根据上述已知条件,对要用到的数据初始化:
s='image_number\\' # 图像所在的路径
num=100 # 共有特征值的数量
row=240 # 特征图像的行数
col=240 # 特征图像的列数
a=np.zeros((num,row,col)) # a 用来存储所有特征的值
2. 读取特征图像
本步骤将所有的特征图像读入到 a 中。共有 10 个数字,每个数字有 10 个特征图像,采用嵌套循环语句完成读取。具体代码如下:
n=0 # n 用来存储当前图像的编号。
for i in range(0,10):
for j in range(1,11):
a[n,:,:]=cv2.imread(s+str(i)+'\\'+str(i)+'-'+str(j)+'.bmp',0)
n=n+1
3. 提取特征图像的特征值
在提取特征值时,可以计算每个子块内黑色像素点的个数,也可以计算每个子块内白色像素点的个数。这里我们选择计算白色像素点(像素值为 255)的个数。按照上述思路,图像映射到特征值的关系如图 20-13 所示。
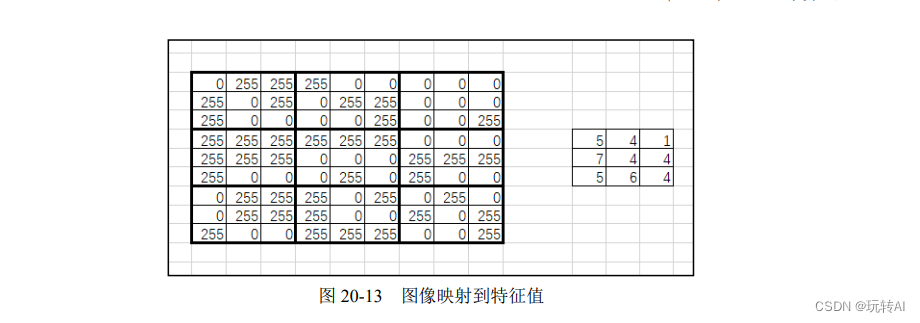
这里需要注意,特征值的行和列的大小都是原图像的 1/5。所以,在设计程序时,如果原始图像内位于(row, col)位置的像素点是白色,则要把对应特征值内位于(row/5, col/5)处的值加 1。
根据上述分析,编写代码如下:
feature=np.zeros((num,round(row/5),round(col/5))) # feature 存储所有样本的特征值
#print(feature.shape) # 在必要时查看 feature 的形状是什么样子
#print(row) # 在必要时查看 row 的值,有多少个特征值(100 个)
for ni in range(0,num):
for nr in range(0,row):
for nc in range(0,col):
if a[ni,nr,nc]==255:
feature[ni,int(nr/5),int(nc/5)]+=1
f=feature #简化变量名称
4. 计算待识别图像的特征值
读取待识别图像,然后计算该图像的特征值。编写代码如下:
o=cv2.imread('image\\test\\9.bmp',0) # 读取待识别图像
# 读取图像的值
of=np.zeros((round(row/5),round(col/5))) # 用来存储待识别图像的特征值
for nr in range(0,row):
for nc in range(0,col):
if o[nr,nc]==255:
of[int(nr/5),int(nc/5)]+=1
5. 计算待识别图像与特征图像之间的距离
依次计算待识别图像与特征图像之间的距离。编写代码如下:
d=np.zeros(100)
for i in range(0,100):
d[i]=np.sum((of-f[i,:,:])*(of-f[i,:,:]))
数组 d 通过依次计算待识别图像特征值 of 与数据集 f 中各个特征值的欧氏距离得到。数据集 f 中依次存储的是数字 0~9 的共计 100 个特征图像的特征值。所以,数组 d 中的索引号对应着各特征图像的编号。例如,d[mn]表示待识别图像与数字“m”的第 n 个特征图像的距离。数组 d 的索引与特征图像之间的对应关系如表 20-2 所示。
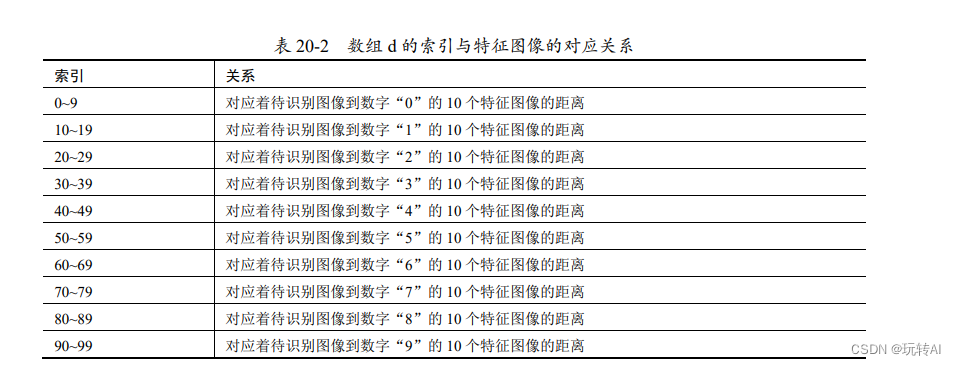
如果将索引号整除 10,得到的值正好是其对应的特征图像上的数字。例如 d[34]对应着待识别图像到数字“3”的第 4 个特征图像的欧式距离。而将 34 整除 10,得到 int(34/10) = 3,正好是其对应的特征图像上的数字。
确定了索引与特征图像的关系,下一步可以通过计算索引达到数字识别的目的。
6. 获取k个最短距离及其索引
从计算得到的所有距离中,选取 k 个最短距离,并计算出这 k 个最短距离对应的索引。具体实现方式是:
- 每次找出最短的距离(最小值)及其索引(下标),然后将该最小值替换为最大值。
- 重复上述过程 k 次,得到 k 个最短距离对应的索引。
每次将最小值替换为最大值,是为了确保该最小值在下一次查找最小值的过程中不会再次被找到。
例如,要在数字序列“11, 6, 3, 9”内依次找到从小到大的值。
- 第 1 次找到了最小值“3”,同时将“3”替换为“11”。此时,要查找的序列变为“11, 6,11, 9”。
- 第 2 次查找最小值时,在序列“11, 6, 11, 9”内找到的最小值是数字“6”,同时将“6”替换为最大值“11”,得到序列“11,11,11,9”。
不断地重复上述过程,依次在第 3 次找到最小值“9”,在第 4 次找到最小值“11”。当然,
在本例中查找的是数值,具体实现时查找的是索引值。
根据上述思路,编写代码如下:
d=d.tolist()
temp=[]
Inf = max(d)
#print(Inf)
k=7
for i in range(k):
temp.append(d.index(min(d)))
d[d.index(min(d))]=Inf
7. 识别
根据计算出来的 k 个最小值的索引,结合表 20-2 就可以确定索引所对应的数字。
具体实现方法是将索引值整除 10,得到对应的数字。
例如,在 k =11 时,得到最小的 11 个值所对应的索引依次为:66、60、65、63、68、69、67、78、89、96、32。它们所对应的特征图像如表 20-3 所示。
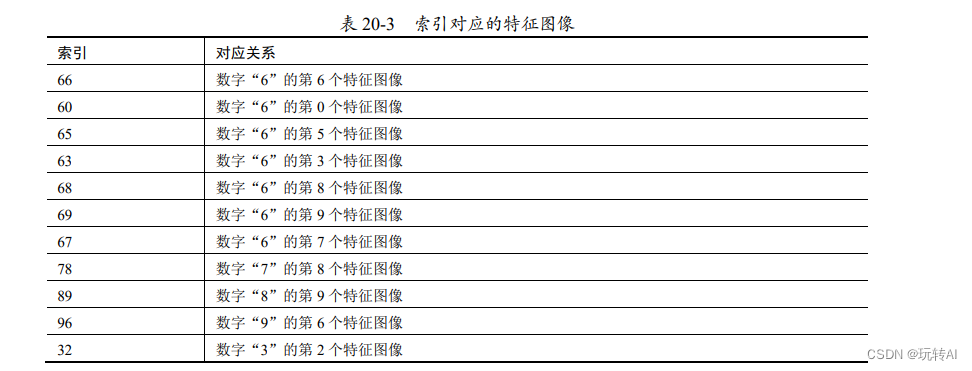
这说明,当前待识别图像与数字“6”的第 6 个特征图像距离最近;接下来,距离最近的第 2 个特征图像是数字“6”的第 0 个特征图像(序号从 0 开始);
以此类推,距离最近的第 11个特征图像是数字“3”的第 2 个特征图像。
上述结果说明,与待识别图像距离最近的特征图像中,有 7 个是数字“6”的特征图像。所以,待识别图像是数字“6”。
下面讨论如何通过程序识别数字。已知将索引整除 10,就能得到对应特征图像上的数字,因此对于上述索引整除 10:
(66, 60, 65, 63, 68, 69, 67, 78, 89, 96, 32)整除 10 = (6, 6, 6, 6, 6, 6,
6, 7, 8, 9, 3)
为了叙述上的方便,将上述整除结果标记为 dr,在 dr 中出现次数最多的数字,就是识别结果。对于上例,dr 中“6”的个数最多,所以识别结果就是数字“6”。
这里我们借助索引判断一组数字中哪个数字出现的次数最多:
- 建立一个数组 r,让其元素的初始值都是 0。
- 依次从 dr 中取数字 n,将数组 r 索引位置为 n 的值加 1。
例如,从 dr 中取到的第 1 个数字为“6”,将 r[6]加上 1;从 dr 中取到第 2 个数字也为“6”,将 r[6]加上 1;以此类推,对于 dr=[6, 6, 6, 6, 6, 6, 6, 7, 8, 9, 3],得到数组 r 的值为[0, 0, 0, 1, 0, 0, 7, 1, 1, 1]。
在数组 r 中:
- r[0]=0,表示在 dr 中不存在值为 0 的元素。
- r[3]=1,表示在 dr 中有 1 个“3”。
- r[6]=7,表示在 dr 中有 7 个“6”。
- r[7]=1,表示在 dr 中有 1 个“7”。
根据上述思路,编写代码如下:
temp=[i/10 for i in temp]
# 数组 r 用来存储结果,r[0]表示 K 近邻中“0”的个数,r[n]表示 K 近邻中“n”的个数
r=np.zeros(10)
for i in temp:
r[int(i)]+=1
print('当前的数字可能为:'+str(np.argmax(r)))
上述过程是分步骤的分析结果,以下是全部源代码:
import time
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 读取样本(特征)图像的值
start_time = time.time();
s='image_number\\' # 图像所在路径
num=100 # 样本总数
row=240 # 特征图像的行数
col=240 # 特征图像的列数
a=np.zeros((num,row,col)) # 存储所有样本的数值
#print(a.shape)
n=0 # 存储当前图像的编号
for i in range(0,10):
for j in range(1,11):
a[n,:,:]=cv2.imread(s+str(i)+'\\'+str(i)+'-'+str(j)+'.bmp',0)
n=n+1
#提采样本图像的特征
feature=np.zeros((num,round(row/5),round(col/5))) # 用来存储所有样本的特征值
#print(feature.shape) # 看看特征值的形状是什么样子
#print(row) # 看看 row 的值,有多少个特征值(100)
for ni in range(0,num):
for nr in range(0,row):
for nc in range(0,col):
if a[ni,nr,nc]==255:
feature[ni,int(nr/5),int(nc/5)]+=1
f=feature # 简化变量名称
#####计算当前待识别图像的特征值
o=cv2.imread('image_number\\test\\5.bmp',0) # 读取待识别图像
##读取图像值
of=np.zeros((round(row/5),round(col/5))) # 存储待识别图像的特征值
for nr in range(0,row):
for nc in range(0,col):
if o[nr,nc]==255:
of[int(nr/5),int(nc/5)]+=1
##计算待识别图像与样本图像的距离
d=np.zeros((num,1)) # 存储待识别图像与样本图像的距离
for i in range(0,100):
d[i]=np.sum((of-f[i,:,:])*(of-f[i,:,:]))
#print(d)
d=d.tolist()
temp=[]
Inf = max(d)
#print(Inf)
k=7
for i in range(k):
temp.append(d.index(min(d)))
d[d.index(min(d))]=Inf
#print(temp) #看看都被识别为哪些特征值
temp=[i/10 for i in temp]
# 也可以返回去处理为 array,使用函数处理
#temp=np.array(temp)
#temp=np.trunc(temp/10)
#print(temp)
# 数组 r 用来存储结果,r[0]表示 K 近邻中“0”的个数,r[n]表示 K 近邻中“n”的个数
r=np.zeros(10)
for i in temp:
r[int(i)]+=1
#print(r)
print('当前的数字可能为:'+str(np.argmax(r)))
print('识别所用时间为:'+str(time.time()-start_time)+'秒')
运行结果:
当前的数字可能为:5
识别所用时间为:4.173201560974121秒
测试图片下载地址 点击下载