🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
开始使用 TFDS
将 TFDS 与 Keras 模型结合使用
加载特定版本
使用映射函数进行增强
使用 TensorFlow 插件
使用自定义拆分
了解 TFRecord
在 TensorFlow 中管理数据的 ETL 过程
优化加载阶段
并行化 ETL 以提高训练性能
概括
在在本书的第一章中,您使用各种数据训练了模型,从方便地与 Keras 捆绑在一起的 Fashion MNIST 数据集到基于图像的 Horses or Humans and Dogs vs. Cats 数据集,这些数据集以 ZIP 文件形式提供,您拥有下载和预处理。您可能已经意识到,有许多不同的方法可以获取用于训练模型的数据。
然而,许多公共数据集要求您在开始考虑模型架构之前学习许多不同领域的特定技能。这TensorFlow Datasets (TFDS) 背后的目标是以一种易于使用的方式公开数据集,其中获取数据并将其放入 TensorFlow 友好 API 的所有预处理步骤都为您完成。
您已经在第 1章和第 2章中了解 Keras如何处理 Fashion MNIST 的一些想法。回顾一下,获取数据所需要做的就是:
data = tf.keras.datasets.fashion_mnist
(training_images, training_labels), (test_images, test_labels) =
data.load_data()TFDS建立在这个想法的基础上,但不仅大大扩展了可用数据集的数量,而且极大地扩展了数据集类型的多样性。可用数据集的列表一直在增长,类别如下:
声音的
语音和音乐数据
图片
从简单的学习数据集(如马或人类)到用于糖尿病视网膜病变检测等用途的高级研究数据集
物体检测
COCO、Open Images 等
结构化数据
泰坦尼克号幸存者、亚马逊评论等
总结
来自 CNN 和每日邮报的新闻、科学论文、wikiHow 等
文本
IMDb 评论、自然语言问题等
翻译
各种翻译训练数据集
视频
移动 MNIST、星际争霸等
笔记
TensorFlow Datasets 是独立于 TensorFlow 的安装,因此请务必在尝试任何示例之前安装它!如果您使用的是 Google Colab,它已经预装好了。
本章将向您介绍 TFDS 以及如何使用它来大大简化训练过程。我们将探索底层的 TFRecord 结构,以及它如何提供通用性,而不管底层数据的类型如何。您还将了解使用 TFDS 的提取-转换-加载 (ETL) 模式,该模式可用于高效地训练具有大量数据的模型。
开始使用 TFDS
让我们通过一些简单的示例来说明如何使用 TFDS 来说明它如何为我们的数据提供标准接口,而不管数据类型如何。
pip install tensorflow-datasets一次它已安装,您可以使用它来访问数据集 tfds.load,将所需数据集的名称传递给它。例如,如果你想使用 Fashion MNIST,你可以使用这样的代码:
import tensorflow as tf
import tensorflow_datasets as tfds
mnist_data = tfds.load("fashion_mnist")
for item in mnist_data:
print(item)是确保检查从命令返回的数据类型tfds.load——打印项目的输出将是数据中本机可用的不同拆分。在这种情况下,它是一个包含两个字符串的字典,test和train。这些是可用的拆分。
如果你想将这些拆分加载到包含实际数据的数据集中,你可以简单地在命令中指定你想要的拆分tfds.load,如下所示:
mnist_train = tfds.load(name="fashion_mnist", split="train")
assert isinstance(mnist_train, tf.data.Dataset)
print(type(mnist_train))在在这个实例中,您会看到输出是一个DatasetAdapter,您可以遍历它来检查数据。此适配器的一个不错的功能是您可以简单地调用take(1)以获取第一条记录。让我们这样做来检查数据的样子:
for item in mnist_train.take(1):
print(type(item))
print(item.keys())第一个的输出print将显示每条记录中的项目类型是字典。当我们打印它的键时,我们会看到在这个图像集中,类型是image和label。所以,如果我们想检查数据集中的一个值,我们可以这样做:
for item in mnist_train.take(1):
print(type(item))
print(item.keys())
print(item['image'])
print(item['label'])您会看到图像的输出是一个 28 × 28 的值数组(在 a 中tf.Tensor)从 0–255 表示像素强度。标签将输出为tf.Tensor(2, shape=(), dtype=int64),表示该图像在数据集中属于第 2 类。
数据关于数据集也可以使用 with_info加载数据集时的参数,如下所示:
mnist_test, info = tfds.load(name="fashion_mnist", with_info="true")
print(info)打印信息将为您提供有关数据集内容的详细信息。例如,对于 Fashion MNIST,您将看到如下输出:
tfds.core.DatasetInfo(
name='fashion_mnist',
version=3.0.0,
description='Fashion-MNIST is a dataset of Zalando's article images
consisting of a training set of 60,000 examples and a test set of 10,000
examples. Each example is a 28x28 grayscale image, associated with a
label from 10 classes.',
homepage='https://github.com/zalandoresearch/fashion-mnist',
features=FeaturesDict({
'image': Image(shape=(28, 28, 1), dtype=tf.uint8),
'label': ClassLabel(shape=(), dtype=tf.int64, num_classes=10),
}),
total_num_examples=70000,
splits={
'test': 10000,
'train': 60000,
},
supervised_keys=('image', 'label'),
citation="""@article{DBLP:journals/corr/abs-1708-07747,
author = {Han Xiao and
Kashif Rasul and
Roland Vollgraf},
title = {Fashion-MNIST: a Novel Image Dataset for Benchmarking
Machine Learning
Algorithms},
journal = {CoRR},
volume = {abs/1708.07747},
year = {2017},
url = {http://arxiv.org/abs/1708.07747},
archivePrefix = {arXiv},
eprint = {1708.07747},
timestamp = {Mon, 13 Aug 2018 16:47:27 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/abs-1708-07747},
bibsource = {dblp computer science bibliography, https://dblp.org}
}""",
redistribution_info=,
)在其中,您可以看到详细信息,例如拆分(如前所述)和数据集中的特征,以及引文、描述和数据集版本等额外信息。
将 TFDS 与 Keras 模型结合使用
在 第 2 章介绍了如何使用 TensorFlow 和 Keras 创建一个简单的计算机视觉模型,使用来自 Keras 的内置数据集(包括 Fashion MNIST),使用如下简单代码:
mnist = tf.keras.datasets.fashion_mnist
(training_images, training_labels),
(test_images, test_labels) = mnist.load_data()什么时候使用 TFDS 的代码非常相似,但有一些小的变化。Keras 数据集为我们提供了ndarray在 中原生工作的类型model.fit,但对于 TFDS,我们需要做一些转换工作:
(training_images, training_labels),
(test_images, test_labels) =
tfds.as_numpy(tfds.load('fashion_mnist',
split = ['train', 'test'],
batch_size=-1,
as_supervised=True))在这种情况下,我们使用 tfds.load,将其fashion_mnist作为所需的数据集传递。我们知道它有训练和测试拆分,因此将它们传递到一个数组中将返回一个数据集适配器数组,其中包含图像和标签。tfds.as_numpy在对的调用中使用tfds.load会使它们作为 Numpy 数组返回。指定batch_size=-1为我们提供了所有数据,并as_supervised=True确保我们得到返回的 (input, label) 元组。
一旦我们这样做了,我们就拥有了与 Keras 数据集中可用的数据格式几乎相同的数据,只是做了一点修改——TFDS 中的形状是 (28, 28, 1),而在 Keras 数据集中是 (28 , 28).
这意味着代码需要稍微更改以指定输入数据形状为 (28, 28, 1) 而不是 (28, 28):
import tensorflow as tf
import tensorflow_datasets as tfds
(training_images, training_labels), (test_images, test_labels) =
tfds.as_numpy(tfds.load('fashion_mnist', split = ['train', 'test'],
batch_size=-1, as_supervised=True))
training_images = training_images / 255.0
test_images = test_images / 255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28,28,1)),
tf.keras.layers.Dense(128, activation=tf.nn.relu),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(training_images, training_labels, epochs=5)为了更复杂的示例,您可以查看第 3 章中使用的 Horses 或 Humans 数据集。这在 TFDS 中也可用。这是用它训练模型的完整代码:
import tensorflow as tf
import tensorflow_datasets as tfds
data = tfds.load('horses_or_humans', split='train', as_supervised=True)
train_batches = data.shuffle(100).batch(10)
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(16, (3,3), activation='relu',
input_shape=(300, 300, 3)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(32, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(optimizer='Adam', loss='binary_crossentropy',
metrics=['accuracy'])
history = model.fit(train_batches, epochs=10)如您所见,它非常简单:只需调用tfds.load,将所需的拆分传递给它(在本例中为train),然后在模型中使用它。数据被分批和混洗以使训练更有效。
Horses 或 Humans 数据集分为训练集和测试集,因此如果您想在训练时对模型进行验证,可以通过从 TFDS 加载单独的验证集来实现,如下所示:
val_data = tfds.load('horses_or_humans', split='test', as_supervised=True)您需要对其进行批处理,就像对训练集所做的一样。例如:
validation_batches = val_data.batch(32)然后,在训练时,您将验证数据指定为这些批次。您还必须显式设置每个时期要使用的验证步骤数,否则 TensorFlow 会抛出错误。如果您不确定,只需将其设置为1:
history = model.fit(train_batches, epochs=10,
validation_data=validation_batches, validation_steps=1)加载特定版本
当您检查数据集时,您会看到何时有不同的版本可用——例如,cnn_dailymail数据集就是这种情况。如果您不想要默认版本(在撰写本文时为 3.0.0),而是想要更早的版本(例如 1.0.0),您可以像这样简单地加载它:
data, info = tfds.load("cnn_dailymail:1.0.0", with_info=True)笔记如果您使用的是 Colab,最好检查一下它使用的 TFDS 版本。在撰写本文时,Colab 已针对 TFDS 2.0 进行了预配置,但在加载数据集(包括那个)时存在一些错误,这些错误cnn_dailymail已在 TFDS 2.1 及更高版本中修复,因此请务必使用其中一个版本,或者至少安装它们进入 Colab,而不是依赖内置的默认设置。
使用映射函数进行增强
在 第 3 章ImageDataGenerator介绍了使用为模型提供训练数据时可用的有用增强工具。您可能想知道在使用 TFDS 时如何实现相同的效果,因为您不像以前那样从子目录中传输图像。实现此目的的最佳方法(或任何其他形式的转换)是在数据适配器上使用映射函数。让我们来看看如何做到这一点。
早些时候,对于我们的马或人类数据,我们只是从 TFDS 加载数据并为其创建批处理,如下所示:
data = tfds.load('horses_or_humans', split='train', as_supervised=True)
train_batches = data.shuffle(100).batch(10)去做转换并将它们映射到数据集,您可以创建一个映射函数。这只是标准的 Python 代码。例如,假设您创建了一个名为的函数augmentimages并让它进行一些图像增强,如下所示:
def augmentimages(image, label):
image = tf.cast(image, tf.float32)
image = (image/255)
image = tf.image.random_flip_left_right(image)
return image, label然后,您可以将其映射到数据以创建一个名为的新数据集train:
train = data.map(augmentimages)然后,当您创建批次时,从而train不是从中执行此操作data,如下所示:
train_batches = train.shuffle(100).batch(32)你可以在 augmentimages使用 完成图像向左或向右随机翻转的功能tf.image.random_flip_left_right(image)。里面有很多功能 tf.image可用于扩充的库;有关详细信息,请参阅文档。
使用 TensorFlow 插件
这 TensorFlow Addons库包含更多您可以使用的函数。扩充中的一些功能ImageDataGenerator(如rotate)只能在那里找到,所以最好检查一下。
使用 TensorFlow Addons 非常简单——您只需安装库:
pip install tensorflow-addons完成后,您可以将插件混合到映射函数中。这是一个示例,其中rotate插件用于之前的映射函数:
import tensorflow_addons as tfa
def augmentimages(image, label):
image = tf.cast(image, tf.float32)
image = (image/255)
image = tf.image.random_flip_left_right(image)
image = tfa.image.rotate(image, 40, interpolation='NEAREST')
return image, label使用自定义拆分
向上到目前为止,您用来构建模型的所有数据都已预先拆分为训练集和测试集。例如,对于 Fashion MNIST,您分别拥有 60,000 条和 10,000 条记录。但是,如果您不想使用这些拆分怎么办?如果你想根据自己的需要自己拆分数据怎么办?这是 TFDS 真正强大的方面之一——它配备了一个 API,可以让您精细、精细地控制数据的拆分方式。
在加载这样的数据时,您实际上已经看到了它:
data = tfds.load('cats_vs_dogs', split='train', as_supervised=True)笔记该split参数是一个字符串,在这种情况下,您要求进行拆分train,这恰好是整个数据集。如果您熟悉Python 切片表示法,也可以使用它。这种表示法可以概括为在方括号内定义所需的切片,如下所示:[<start>: <stop>: <step>]。这是一种相当复杂的语法,为您提供了极大的灵活性。
例如,如果您希望的前 10,000 条记录作为train您的训练数据,您可以省略<start>并仅调用 for train[:10000](一个有用的助记符是将前导冒号读作“第一个”,因此这将读作“train the first 10,000 records ”):
data = tfds.load('cats_vs_dogs', split='train[:10000]', as_supervised=True)您还可以使用%来指定拆分。例如,如果你想要前 20% 的记录用于训练,你可以:20%这样使用:
data = tfds.load('cats_vs_dogs', split='train[:20%]', as_supervised=True)你甚至可以变得有点疯狂并组合拆分。也就是说,如果您希望训练数据是第一千条记录和最后一千条记录的组合,您可以执行以下操作(其中-1000:表示“最后 1,000 条记录”,:1000表示“前 1,000 条记录”):
data = tfds.load('cats_vs_dogs', split='train[-1000:]+train[:1000]',
as_supervised=True)Dogs vs. Cats 数据集没有固定的训练、测试和验证拆分,但是使用 TFDS,创建您自己的拆分很简单。假设您希望拆分为 80%、10%、10%。您可以像这样创建三个集合:
train_data = tfds.load('cats_vs_dogs', split='train[:80%]',
as_supervised=True)
validation_data = tfds.load('cats_vs_dogs', split='train[80%:90%]',
as_supervised=True)
test_data = tfds.load('cats_vs_dogs', split='train[-10%:]',
as_supervised=True)一旦拥有它们,就可以像使用任何命名拆分一样使用它们。
需要注意的是,由于无法查询返回的数据集的长度,因此通常很难检查您是否正确拆分了原始数据集。要查看拆分中有多少条记录,您必须遍历整个集合并一条一条地计算它们。以下是为您刚刚创建的训练集执行此操作的代码:
train_length = [i for i,_ in enumerate(train_data)][-1] + 1
print(train_length)这可能是一个缓慢的过程,因此请务必仅在调试时使用它!
了解 TFRecord

图 4-1。将 cnn_dailymail 数据集下载为 TFRecord 文件
这是 TensorFlow 中用于存储和检索大量数据的首选格式。这是一个非常简单的文件结构,顺序读取以获得更好的性能。磁盘上的文件非常简单,每条记录都包含一个表示记录长度的整数、一个循环冗余校验 (CRC)、一个数据字节数组和一个字节数组的 CRC。记录连接到文件中,然后在大型数据集的情况下进行分片。
例如,图 4-2显示了训练集 fromcnn_dailymail在下载后如何分片为 16 个文件。
要看一个更简单的示例,请下载 MNIST 数据集并打印其信息:
data, info = tfds.load("mnist", with_info=True)
print(info)在信息中,您会看到它的功能是这样存储的:
features=FeaturesDict({
'image': Image(shape=(28, 28, 1), dtype=tf.uint8),
'label': ClassLabel(shape=(), dtype=tf.int64, num_classes=10),
}),与 CNN/DailyMail 示例类似,文件下载到/root/tensorflow_datasets/mnist/<version>/files。
您可以像这样加载原始记录TFRecordDataset:
filename="/root/tensorflow_datasets/mnist/3.0.0/
mnist-test.tfrecord-00000-of-00001"
raw_dataset = tf.data.TFRecordDataset(filename)
for raw_record in raw_dataset.take(1):
print(repr(raw_record))请注意,您的文件名位置可能因操作系统而异。
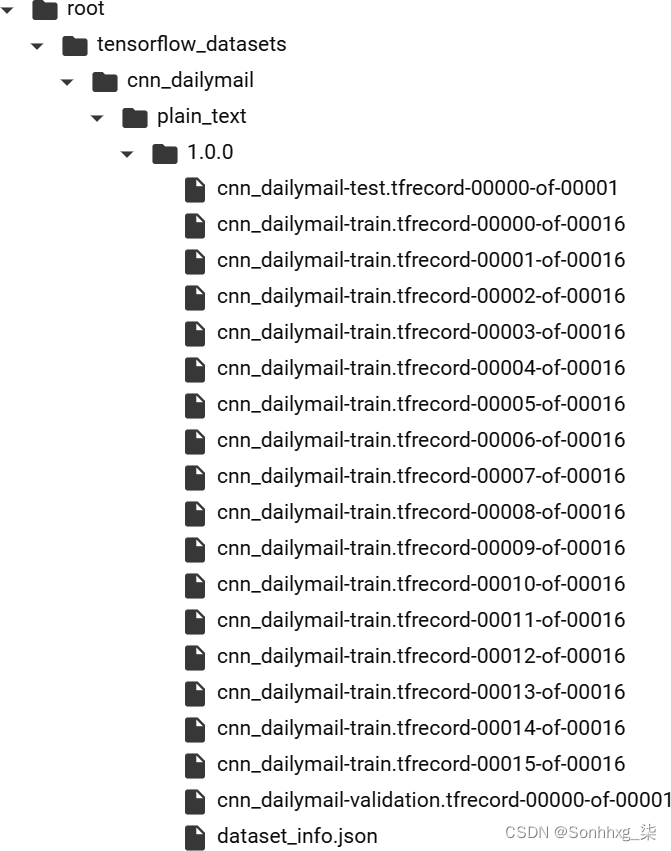
图 4-2。检查 cnn_dailymail 的 TFRecords
这将打印出记录的原始内容,如下所示:
<tf.Tensor: shape=(), dtype=string,
numpy=b"\n\x85\x03\n\xf2\x02\n\x05image\x12\xe8\x02\n\xe5\x02\n\xe2\x02\x89PNG\r
\n\x1a\n\x00\x00\x00\rIHDR\x00\x00\x00\x1c\x00\x00\x00\x1c\x08\x00\x00\x00\x00Wf
\x80H\x00\x00\x01)IDAT(\x91\xc5\xd2\xbdK\xc3P\x14\x05\xf0S(v\x13)\x04,.\x82\xc5A
q\xac\xedb\x1d\xdc\n.\x12\x87n\x0e\x82\x93\x7f@Q\xb2\x08\xba\tbQ0.\xe2\xe2\xd4\x
b1\xa2h\x9c\x82\xba\x8a(\nq\xf0\x83Fh\x95\n6\x88\xe7R\x87\x88\xf9\xa8Y\xf5\x0e\x
8f\xc7\xfd\xdd\x0b\x87\xc7\x03\xfe\xbeb\x9d\xadT\x927Q\xe3\xe9\x07:\xab\xbf\xf4\
xf3\xcf\xf6\x8a\xd9\x14\xd29\xea\xb0\x1eKH\xde\xab\xea%\xaba\x1b=\xa4P/\xf5\x02\
xd7\\\x07\x00\xc4=,L\xc0,>\x01@2\xf6\x12\xde\x9c\xde[t/\xb3\x0e\x87\xa2\xe2\
xc2\xe0A<\xca\xb26\xd5(\x1b\xa9\xd3\xe8\x0e\xf5\x86\x17\xceE\xdarV\xae\xb7_\xf3
I\xf7(\x06m\xaaE\xbb\xb6\xac\r*\x9b$e<\xb8\xd7\xa2\x0e\x00\xd0l\x92\xb2\xd5\x15\
xcc\xae'\x00\xf4m\x08O'+\xc2y\x9f\x8d\xc9\x15\x80\xfe\x99[q\x962@CN|i\xf7\xa9!=\
\xab\x19\x00\xc8\xd6\xb8\xeb\xa1\xf0\xd8l\xca\xfb]\xee\xfb]*\x9fV\xe1\x07\xb7\xc
9\x8b55\xe7M\xef\xb0\x04\xc0\xfd&\x89\x01<\xbe\xf9\x03*\x8a\xf5\x81\x7f\xaa/2y\x
87ks\xec\x1e\xc1\x00\x00\x00\x00IEND\xaeB`\x82\n\x0e\n\x05label\x12\x05\x1a\x03\
n\x01\x02">它是一个长字符串,包含记录的详细信息以及校验和等。但是如果我们已经知道这些特征,我们可以创建一个特征描述并使用它来解析数据。这是代码:
# Create a description of the features
feature_description = {
'image': tf.io.FixedLenFeature([], dtype=tf.string),
'label': tf.io.FixedLenFeature([], dtype=tf.int64),
}
def _parse_function(example_proto):
# Parse the input `tf.Example` proto using the dictionary above
return tf.io.parse_single_example(example_proto, feature_description)
parsed_dataset = raw_dataset.map(_parse_function)
for parsed_record in parsed_dataset.take(1):
print((parsed_record))这个输出有点友好!首先,您可以看到图像是一个Tensor,并且它包含一个 PNG。PNG 是一种压缩图像格式,其标头由 和 定义,IHDR图像数据介于IDAT和之间IEND。如果你仔细观察,你可以在字节流中看到它们。还有标签,存储为int并包含值2:
{'image': <tf.Tensor: shape=(), dtype=string,
numpy=b"\x89PNG\r\n\x1a\n\x00\x00\x00\rIHDR\x00\x00\x00\x1c\x00\x00\x00\x1c\x08\
x00\x00\x00\x00Wf\x80H\x00\x00\x01)IDAT(\x91\xc5\xd2\xbdK\xc3P\x14\x05\xf0S(v\x1
3)\x04,.\x82\xc5Aq\xac\xedb\x1d\xdc\n.\x12\x87n\x0e\x82\x93\x7f@Q\xb2\x08\xba\tb
Q0.\xe2\xe2\xd4\xb1\xa2h\x9c\x82\xba\x8a(\nq\xf0\x83Fh\x95\n6\x88\xe7R\x87\x88\x
f9\xa8Y\xf5\x0e\x8f\xc7\xfd\xdd\x0b\x87\xc7\x03\xfe\xbeb\x9d\xadT\x927Q\xe3\xe9\
x07:\xab\xbf\xf4\xf3\xcf\xf6\x8a\xd9\x14\xd29\xea\xb0\x1eKH\xde\xab\xea%\xaba\x1
b=\xa4P/\xf5\x02\xd7\\\x07\x00\xc4=,L\xc0,>\x01@2\xf6\x12\xde\x9c\xde[t/\xb3\x0e
\x87\xa2\xe2\xc2\xe0A<\xca\xb26\xd5(\x1b\xa9\xd3\xe8\x0e\xf5\x86\x17\xceE\xdarV\
xae\xb7_\xf3AR\r!I\xf7(\x06m\xaaE\xbb\xb6\xac\r*\x9b$e<\xb8\xd7\xa2\x0e\x00\xd0l
\x92\xb2\xd5\x15\xcc\xae'\x00\xf4m\x08O'+\xc2y\x9f\x8d\xc9\x15\x80\xfe\x99[q\x96
2@CN|i\xf7\xa9!=\xd7
\xab\x19\x00\xc8\xd6\xb8\xeb\xa1\xf0\xd8l\xca\xfb]\xee\xfb]*\x9fV\xe1\x07\xb7\xc
9\x8b55\xe7M\xef\xb0\x04\xc0\xfd&\x89\x01<\xbe\xf9\x03*\x8a\xf5\x81\x7f\xaa/2y\x
87ks\xec\x1e\xc1\x00\x00\x00\x00IEND\xaeB`\x82">, 'label': <tf.Tensor: shape=(),
dtype=int64, numpy=2>}在 TensorFlow 中管理数据的 ETL 过程
ETL是TensorFlow 用于训练的核心模式,无论规模如何。在本书中,我们一直在探索小型单机模型构建,但同样的技术可用于跨多台机器和海量数据集的大规模训练。
这 ETL 过程的提取阶段是从存储原始数据的任何地方加载原始数据,并以可以转换的方式进行准备。转换阶段是指以适合或改进训练的方式处理数据。例如,批处理、图像增强、映射到特征列以及应用于数据的其他此类逻辑都可以视为此阶段的一部分。加载阶段是将数据加载到神经网络进行训练的阶段。
考虑训练马或人分类器的完整代码,如下所示。我添加了注释以显示提取、转换和加载阶段发生的位置:
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_addons as tfa
# MODEL DEFINITION START #
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(16, (3,3), activation='relu',
input_shape=(300, 300, 3)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(32, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(optimizer='Adam', loss='binary_crossentropy',
metrics=['accuracy'])
# MODEL DEFINITION END #
# EXTRACT PHASE START #
data = tfds.load('horses_or_humans', split='train', as_supervised=True)
val_data = tfds.load('horses_or_humans', split='test', as_supervised=True)
# EXTRACT PHASE END
# TRANSFORM PHASE START #
def augmentimages(image, label):
image = tf.cast(image, tf.float32)
image = (image/255)
image = tf.image.random_flip_left_right(image)
image = tfa.image.rotate(image, 40, interpolation='NEAREST')
return image, label
train = data.map(augmentimages)
train_batches = train.shuffle(100).batch(32)
validation_batches = val_data.batch(32)
# TRANSFORM PHASE END
# LOAD PHASE START #
history = model.fit(train_batches, epochs=10,
validation_data=validation_batches, validation_steps=1)
# LOAD PHASE END #使用此过程可以使您的数据管道不易受数据和底层模式变化的影响。当您使用 TFDS 提取数据时,无论数据小到足以放入内存,还是大到即使在简单的机器上也无法容纳,都会使用相同的底层结构。转换的APItf.data也是一致的,无论底层数据源如何,都可以使用类似的。而且,当然,一旦它被转换,加载数据的过程也是一致的,无论你是在单个 CPU、GPU、GPU 集群,还是 TPU pod 上训练。
但是,加载数据的方式会对训练速度产生巨大影响。接下来让我们看一下。
优化加载阶段
让我们仔细研究训练模型时的提取-转换-加载过程。我们可以考虑在任何处理器(包括 CPU)上提取和转换数据都是可能的。事实上,这些阶段中用于执行下载数据、解压缩数据、逐条记录和处理数据等任务的代码并不是 GPU 或 TPU 的构建目的,因此这些代码很可能会在 CPU 上执行。然而,在训练方面,您可以从 GPU 或 TPU 中获益良多,因此如果可能的话,在此阶段使用一个是有意义的。因此,在您可以使用 GPU 或 TPU 的情况下,您应该理想地在 CPU 和 GPU/TPU 之间分配工作负载,Extract 和 Transform 发生在 CPU 上,而 Load 发生在 GPU/TPU 上。
假设您正在处理一个大型数据集。假设它太大以至于您必须批量准备数据(即进行提取和转换),您最终会遇到如图 4-3 所示的情况。在准备第一批时,GPU/TPU 处于空闲状态。当该批准备就绪时,可以将其发送到 GPU/TPU 进行训练,但现在 CPU 处于空闲状态,直到训练完成,此时它可以开始准备第二批。这里有很多空闲时间,所以我们可以看到还有优化的空间。

图 4-3。在 CPU/GPU 上训练
合乎逻辑的解决方案是并行进行工作,同时进行准备和培训。这个过程称为流水线,如图 4-4所示。

图 4-4。流水线
在这种情况下,当 CPU 准备第一批时,GPU/TPU 再次无事可做,因此处于空闲状态。第一批完成后,GPU/TPU 可以开始训练——但与此同时,CPU 将准备第二批。当然,训练第n -1 批次和准备第 n批次所花费的时间并不总是相同的。如果训练时间更快,您将在 GPU/TPU 上有一段时间的空闲时间。如果速度较慢,您将在 CPU 上有一段时间的空闲时间。选择正确的批量大小可以帮助您在此处进行优化 — 由于 GPU/TPU 时间可能更昂贵,您可能希望尽可能减少其空闲时间。
您可能已经注意到,当我们从 Keras 中的 Fashion MNIST 等简单数据集转移到使用 TFDS 版本时,您必须先对它们进行批处理,然后才能进行训练。这就是原因:流水线模型已到位,因此无论您的数据集有多大,您都将继续对其使用一致的 ETL 模式。
并行化 ETL 以提高训练性能
张量流为您提供并行化提取和转换过程所需的所有 API。让我们使用 Dogs vs. Cats 和底层的 TFRecord 结构来探索它们的样子。
首先,您使用tfds.load获取数据集:
train_data = tfds.load('cats_vs_dogs', split='train', with_info=True)如果您想使用底层 TFRecords,您需要访问已下载的原始文件。由于数据集很大,它被分成许多文件(8 个,在 4.0.0 版中)。
您可以创建这些文件的列表并使用 tf.Data.Dataset.list_files加载它们:
file_pattern =
f'/root/tensorflow_datasets/cats_vs_dogs/4.0.0/cats_vs_dogs-train.tfrecord*'
files = tf.data.Dataset.list_files(file_pattern)一旦你有了文件,就可以使用files.interleave这样的方式将它们加载到数据集中:
train_dataset = files.interleave(
tf.data.TFRecordDataset,
cycle_length=4,
num_parallel_calls=tf.data.experimental.AUTOTUNE
)这里有一些新概念,让我们花点时间来探讨一下。
该cycle_length参数指定并发处理的输入元素的数量。因此,稍后您将看到映射函数,该函数在记录从磁盘加载时对其进行解码。因为cycle_length设置为4,此过程将一次处理四个记录。如果您不指定此值,则它将从可用 CPU 内核数中派生。
该num_parallel_calls参数在设置时将指定要执行的并行调用的数量。使用tf.data.experimental.AUTOTUNE,就像这里所做的那样,将使您的代码更具可移植性,因为该值是根据可用的 CPU 动态设置的。与 结合使用时cycle_length,您将设置最大并行度。因此,例如,如果num_parallel_calls设置为6after autotuning 并且cycle_lengthis 4,您将有六个单独的线程,每个线程一次加载四个记录。
现在提取过程已并行化,让我们探索并行化数据转换。首先,创建加载原始 TFRecord 并将其转换为可用内容的映射函数——例如,将 JPEG 图像解码到图像缓冲区中:
def read_tfrecord(serialized_example):
feature_description={
"image": tf.io.FixedLenFeature((), tf.string, ""),
"label": tf.io.FixedLenFeature((), tf.int64, -1),
}
example = tf.io.parse_single_example(
serialized_example, feature_description
)
image = tf.io.decode_jpeg(example['image'], channels=3)
image = tf.cast(image, tf.float32)
image = image / 255
image = tf.image.resize(image, (300,300))
return image, example['label']如您所见,这是一个典型的映射函数,没有做任何特定的工作来使其并行工作。这将在我们调用映射函数时完成。以下是如何做到这一点:
cores = multiprocessing.cpu_count()
print(cores)
train_dataset = train_dataset.map(read_tfrecord, num_parallel_calls=cores)
train_dataset = train_dataset.cache()首先,如果你不想自动调整,你可以使用multiprocessing库来计算你的 CPU。然后,当您调用映射函数时,只需将其作为要进行的并行调用的数量传递即可。就这么简单。
该cache方法会将数据集缓存在内存中。如果您有大量 RAM 可用,这将是一个非常有用的加速。在 Colab with Dogs vs. Cats 中尝试此操作可能会由于数据集不适合 RAM 而导致 VM 崩溃。之后,如果可用,Colab 基础设施将为您提供一台新的、更高 RAM 的机器。
加载和训练也可以并行化。除了对数据进行混洗和批处理外,您还可以根据可用的 CPU 内核数量进行预取。这是代码:
train_dataset = train_dataset.shuffle(1024).batch(32)
train_dataset = train_dataset.prefetch(tf.data.experimental.AUTOTUNE)一旦你的训练集全部并行化,你就可以像以前一样训练模型:
model.fit(train_dataset, epochs=10, verbose=1)当我在 Google Colab 中尝试这个时,我发现这个用于并行化 ETL 过程的额外代码将训练时间减少到每个时期大约 40 秒,而没有它时则为 75 秒。这些简单的改变将我的训练时间缩短了将近一半!
概括
本章介绍了 TensorFlow 数据集,这是一个让您可以访问范围广泛的数据集的库,从小型学习数据集到研究中使用的全面数据集。您看到了他们如何使用通用 API 和通用格式来帮助减少您为访问数据而必须编写的代码量。您还看到了如何使用 ETL 过程,这是 TFDS 设计的核心,特别是我们探索了数据提取、转换和加载的并行化以提高训练性能。在下一章中,您将把所学知识应用到自然语言处理问题中。


![[附源码]Nodejs计算机毕业设计基于web的学生社团管理系统Express(程序+LW)](https://img-blog.csdnimg.cn/96bcc320595d4d6e80d9c54e73f02a2e.png)







![[R语言]手把手教你如何绘图(万字)](https://img-blog.csdnimg.cn/img_convert/c76c1058d2825fedeb2301666ca431e0.png)