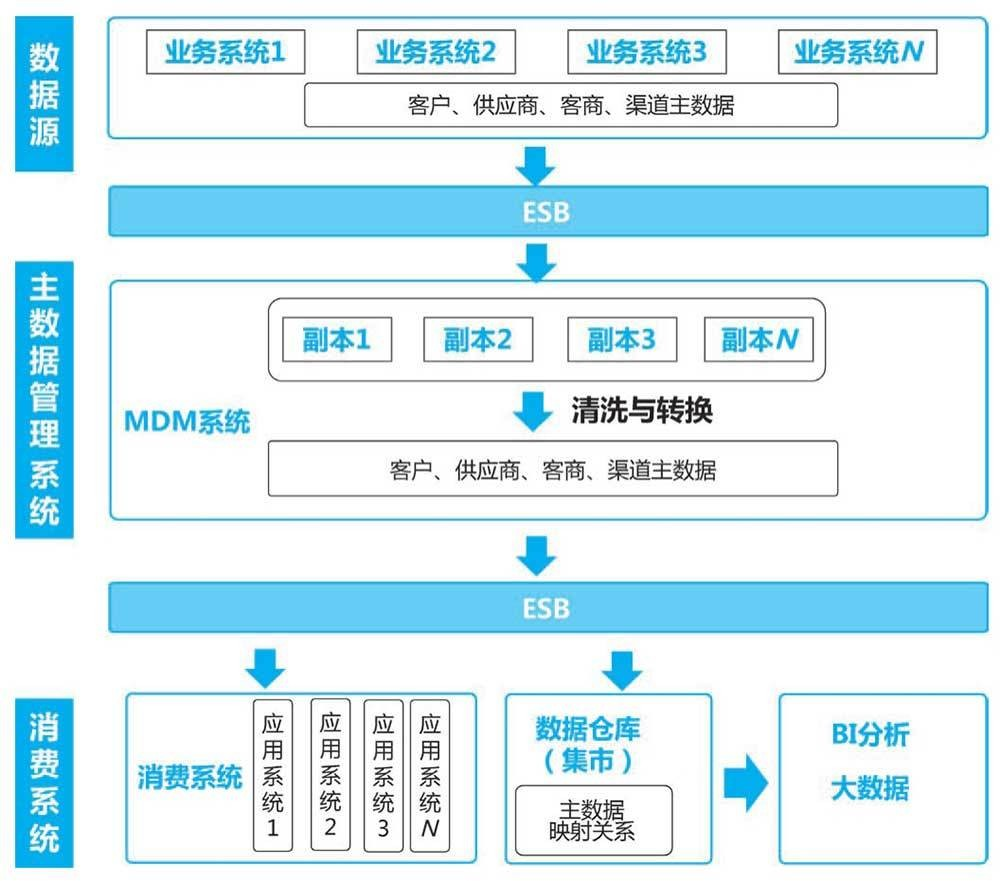
| 函数 | 描述 |
|---|---|
| len() | 计算序列的长度 |
| max() | 找出序列中的最大元素 |
| min() | 找出序列中的最小元素 |
| list() | 将序列转换为列表 |
| str() | 将序列转换为字符串 |
| sum() | 计算元素的和 |
| sorted() | 对元素进行排序 |
| enumerate() | 将序列组合为一个索引序列,多用在 for 循环中 |
关键字
| and | exec | not | assert | finally | or |
|---|---|---|---|---|---|
| break | for | pass | class | from | |
| continue | global | raise | def | if | return |
| del | import | try | elif | in | while |
| else | is | with | except | lambda | yield |
常用运算符
| 运算符 | 描述 | 示例 |
|---|---|---|
| + | 相加 | a + b |
| - | 相减 | a - b |
| * | 相乘 | a * b |
| / | 相除 | a / b |
| % | 取模 | a % b |
| ** | 幂 | a**b 表示 a 的 b 次幂 |
| // | 取整除 | 9 // 4 结果为 2 |
| == | 是否相等 | a == b |
| != | 是否不等于 | a != b |
| > | 是否大于 | a > b |
| >= | 是否大于等于 | a >= b |
| <= | 是否小于等于 | a <= b |
| = | 简单的赋值运算符 | a = b + c |
| += | 加法赋值运算符 | a += b 等效于 a = a + b |
| -= | 减法赋值运算符 | a -= b 等效于 a = a - b |
| *= | 乘法赋值运算符 | a *= b 等效于 a = a * b |
| /= | 除法赋值运算符 | a /= b 等效于 a = a / b |
| %= | 取模赋值运算符 | a %= b 等效于 a = a % b |
| **= | 幂赋值运算符 | a **= b 等效于 a = a ** b |
| //= | 取整除赋值运算符 | a //= b 等效于 a = a // b |
| & | 与 | a & b |
| | 或 | a | b |
| ^ | 异或 | a ^ b |
| ~ | 取反 | ~a |
| << | 左移动 | a << 3 |
| >> | 右移动 | a >> 3 |
| and | 布尔类型与 | a and b |
| or | 布尔类型或 | a or b |
| not | 布尔类型非 | not a |
| is | 判断两个标识符是否引用同一个对象 | a is b |
| is not | 判断两个标识符是否引用不同对象 | a is not b |
运算符优先级
| 运算符 | 描述(由上至下对应优先级由高到低) |
|---|---|
| ** | 幂运算 |
| ~ + - | 取反、正号、负号 |
| * / % // | 乘、除、取模、取整除 |
| + - | 加法、减法 |
| >> << | 右移、左移 |
| & | 与 |
^ | | 异或、或 |
| <= < > >= | 比较运算符 |
| == != | 是否等于、是否不等于 |
| = %= /= //= -= += *= **= | 赋值运算符 |
| is is not | 身份运算符 |
| in not in | 成员运算符 |
| not and or | 逻辑运算符 |
| 索引 | 属性 | 值 |
|---|---|---|
| 0 | tm_year(年) | 如:1945 |
| 1 | tm_mon(月) | 1 ~ 12 |
| 2 | tm_mday(日) | 1 ~ 31 |
| 3 | tm_hour(时) | 0 ~ 23 |
| 4 | tm_min(分) | 0 ~ 59 |
| 5 | tm_sec(秒) | 0 ~ 61 |
| 6 | tm_wday(周) | 0 ~ 6 |
| 7 | tm_yday(一年内第几天) | 1 ~ 366 |
| 8 | tm_isdst(夏时令) | -1、0、1 |
常用函数
| 函数(常量) | 说明 |
|---|---|
| time() | 返回当前时间的时间戳 |
| gmtime([secs]) | 将时间戳转换为格林威治天文时间下的 struct_time,可选参数 secs 表示从 epoch 到现在的秒数,默认为当前时间 |
| localtime([secs]) | 与 gmtime() 相似,返回当地时间下的 struct_time |
| mktime(t) | localtime() 的反函数 |
| asctime([t]) | 接收一个 struct_time 表示的时间,返回形式为:Mon Dec 2 08:53:47 2019 的字符串 |
| ctime([secs]) | ctime(secs) 相当于 asctime(localtime(secs)) |
| strftime(format[, t]) | 格式化日期,接收一个 struct_time 表示的时间,并返回以可读字符串表示的当地时间 |
| sleep(secs) | 暂停执行调用线程指定的秒数 |
| altzone | 本地 DST 时区的偏移量,以 UTC 为单位的秒数 |
| timezone | 本地(非 DST)时区的偏移量,UTC 以西的秒数(西欧大部分地区为负,美国为正,英国为零) |
| tzname | 两个字符串的元组:第一个是本地非 DST 时区的名称,第二个是本地 DST 时区的名称 |
strftime 函数日期格式化符号说明如下所示
| 符号 | 说明 |
|---|---|
| %a | 本地化的缩写星期中每日的名称 |
| %A | 本地化的星期中每日的完整名称 |
| %b | 本地化的月缩写名称 |
| %B | 本地化的月完整名称 |
| %c | 本地化的适当日期和时间表示 |
| %d | 十进制数 [01,31] 表示的月中日 |
| %H | 十进制数 [00,23] 表示的小时(24小时制) |
| %I | 十进制数 [01,12] 表示的小时(12小时制) |
| %j | 十进制数 [001,366] 表示的年中日 |
| %m | 十进制数 [01,12] 表示的月 |
| %M | 十进制数 [00,59] 表示的分钟 |
| %p | 本地化的 AM 或 PM |
| %S | 十进制数 [00,61] 表示的秒 |
| %U | 十进制数 [00,53] 表示的一年中的周数(星期日作为一周的第一天) |
| %w | 十进制数 [0(星期日),6] 表示的周中日 |
| %W | 十进制数 [00,53] 表示的一年中的周数(星期一作为一周的第一天) |
| %x | 本地化的适当日期表示 |
| %X | 本地化的适当时间表示 |
| %y | 十进制数 [00,99] 表示的没有世纪的年份 |
| %Y | 十进制数表示的带世纪的年份 |
| %z | 时区偏移以格式 +HHMM 或 -HHMM 形式的 UTC/GMT 的正或负时差指示,其中 H 表示十进制小时数字,M 表示小数分钟数字 [-23:59, +23:59] |
| %Z | 时区名称 |
| %% | 字面的 '%' 字符 |
基本语法
| 字符 | 说明 |
|---|---|
. | 默认情况,匹配除了换行的任意字符;如果指定了标签 DOTALL,则匹配包括换行符的任意字符 |
^ | 匹配字符串的开头,在 MULTILINE 模式也匹配换行后的首个符号 |
$ | 匹配字符串尾或者换行符的前一个字符,在 MULTILINE 模式匹配换行符的前一个字符 |
* | 匹配前一个字符 0 到无限次 |
+ | 匹配前一个字符 1 到无限次 |
? | 匹配前一个字符 0 次或 1 次 |
{m} | 匹配前一个字符 m 次 |
{m, n} | 匹配前一个字符 m 到 n 次 |
*? +? ?? {m,n}? | 使 *、+、?、{m,n} 变成非贪婪模式,也就是使这些匹配次数不定的表达式尽可能少的匹配 |
\ | 转义特殊字符 |
[...] | 用于表示一个字符集合 |
| | 匹配 | 两边任意表达式 |
(...) | 将括起来的表达式分组, |
(?aiLmsux) | aiLmsux 每一个字符代表一个匹配模式,可选多个 |
(?:…) | (...) 的不分组版本 |
(?P<name>…) | 分组,除了原有的编号外再指定一个额外的别名 |
(?P=name) | 引用别名为 name 的分组匹配到的字符串 |
(?#…) | # 后面的将作为注释被忽略 |
(?=…) | 匹配 … 的内容,但是并不消费样式的内容 |
(?!…) | 匹配 … 不符合的情况 |
(?<=…) | 匹配字符串的当前位置,它的前面匹配 … 的内容到当前位置 |
(?<!…) | 匹配当前位置之前不是 ... 的样式 |
(?(id/name)yes-pattern|no-pattern) | 如果给定的 id 或 name 存在,将会尝试匹配 yes-pattern ,否则就尝试匹配 no-pattern,no-pattern 可选,也可以被忽略 |
\number | 匹配数字代表的组合 |
\A | 只匹配字符串开始 |
\b | 匹配空字符串,但只在单词开始或结尾的位置 |
\B | 匹配空字符串,但不能在词的开头或者结尾 |
\d | 主要匹配数字 [0-9] |
\D | 匹配任何非十进制数字的字符 |
\s | 匹配空白字符,主要包括:空格 \t \n \r \f \v |
\S | 匹配任何非空白字符 |
\w | 匹配 [a-zA-Z0-9_] |
\W | 匹配非单词字符 |
\Z | 只匹配字符串尾 |
![]()
| 参数 | 说明 |
|---|---|
re.A | 让 \w, \W, \b, \B, \d, \D, \s, \S 只匹配 ASCII |
re.I | 忽略大小写 |
re.M | 多行模式 |
re.L | 由当前语言区域决定 \w, \W, \b, \B 和大小写敏感匹配 |
re.S | . 匹配包括换行符在内的任意字符 |
re.U | 在 Python3 中是冗余的,因为 Python3 中字符串已经默认为 Unicode |
re.X | 忽略空格和 # 后面的注释 |



![[R语言]手把手教你如何绘图(万字)](https://img-blog.csdnimg.cn/img_convert/c76c1058d2825fedeb2301666ca431e0.png)


![[附源码]Python计算机毕业设计二手交易平台Django(程序+LW)](https://img-blog.csdnimg.cn/889c75ced0a740c49a630474fd4b2c00.png)