一、环境准备
集群环境hadoop11,hadoop12 ,hadoop13
安装 zookeeper 和 HDFS
1、启动zookeeper
-- 启动zookeeper(11,12,13都需要启动)
xcall.sh zkServer.sh start
-- 或者
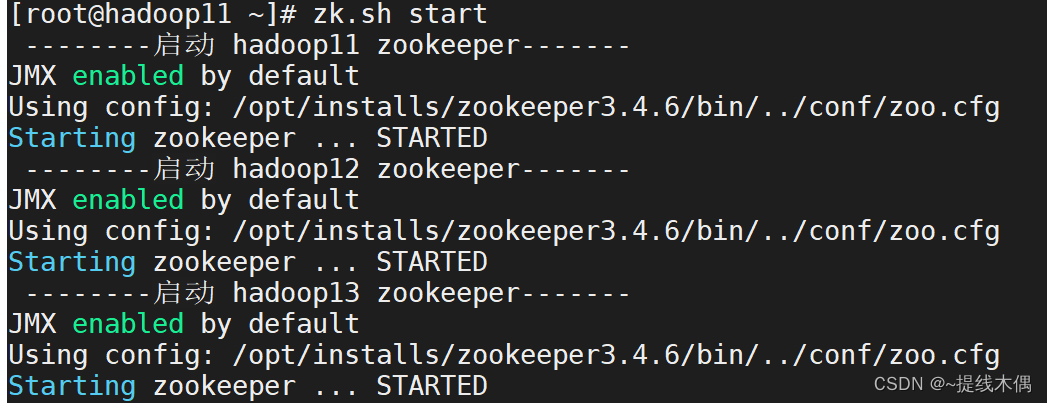
zk.sh start
-- xcall.sh 和zk.sh都是自己写的脚本
-- 查看进程
jps
-- 有QuorumPeerMain进程不能说明zookeeper启动成功
-- 需要查看zookeeper的状态
xcall.sh zkServer.sh status
-- 或者
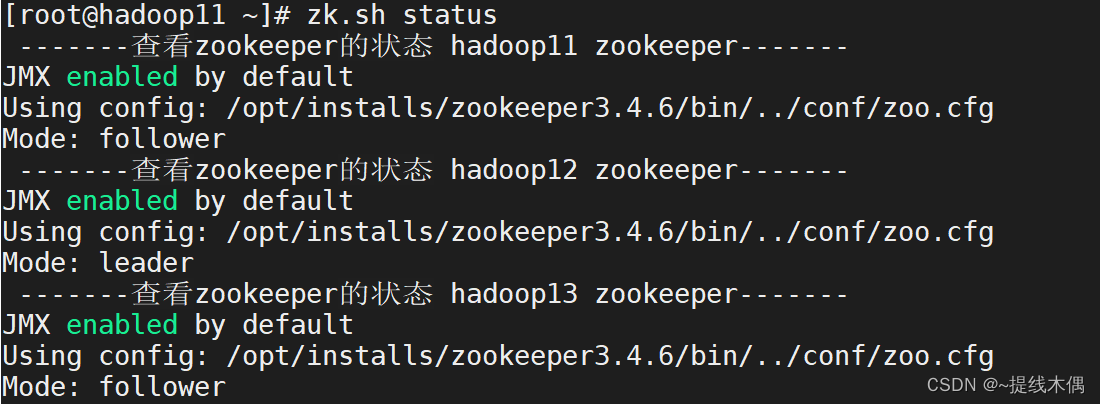
zk.sh status
-------查看zookeeper的状态 hadoop11 zookeeper-------
JMX enabled by default
Using config: /opt/installs/zookeeper3.4.6/bin/../conf/zoo.cfg
Mode: follower
-------查看zookeeper的状态 hadoop12 zookeeper-------
JMX enabled by default
Using config: /opt/installs/zookeeper3.4.6/bin/../conf/zoo.cfg
Mode: leader
-------查看zookeeper的状态 hadoop13 zookeeper-------
JMX enabled by default
Using config: /opt/installs/zookeeper3.4.6/bin/../conf/zoo.cfg
Mode: follower
-- 有leader,有follower才算启动成功
2、启动HDFS
[root@hadoop11 ~]# start-dfs.sh
Starting namenodes on [hadoop11 hadoop12]
上一次登录:三 8月 16 09:13:59 CST 2023从 192.168.182.1pts/0 上
Starting datanodes
上一次登录:三 8月 16 09:36:55 CST 2023pts/0 上
Starting journal nodes [hadoop13 hadoop12 hadoop11]
上一次登录:三 8月 16 09:37:00 CST 2023pts/0 上
Starting ZK Failover Controllers on NN hosts [hadoop11 hadoop12]
上一次登录:三 8月 16 09:37:28 CST 2023pts/0 上
jps查看进程
[root@hadoop11 ~]# xcall.sh jps
------------------------ hadoop11 ---------------------------
10017 DataNode
10689 DFSZKFailoverController
9829 NameNode
12440 Jps
9388 QuorumPeerMain
10428 JournalNode
------------------------ hadoop12 ---------------------------
1795 JournalNode
1572 NameNode
1446 QuorumPeerMain
1654 DataNode
1887 DFSZKFailoverController
1999 Jps
------------------------ hadoop13 ---------------------------
1446 QuorumPeerMain
1767 Jps
1567 DataNode
1679 JournalNode
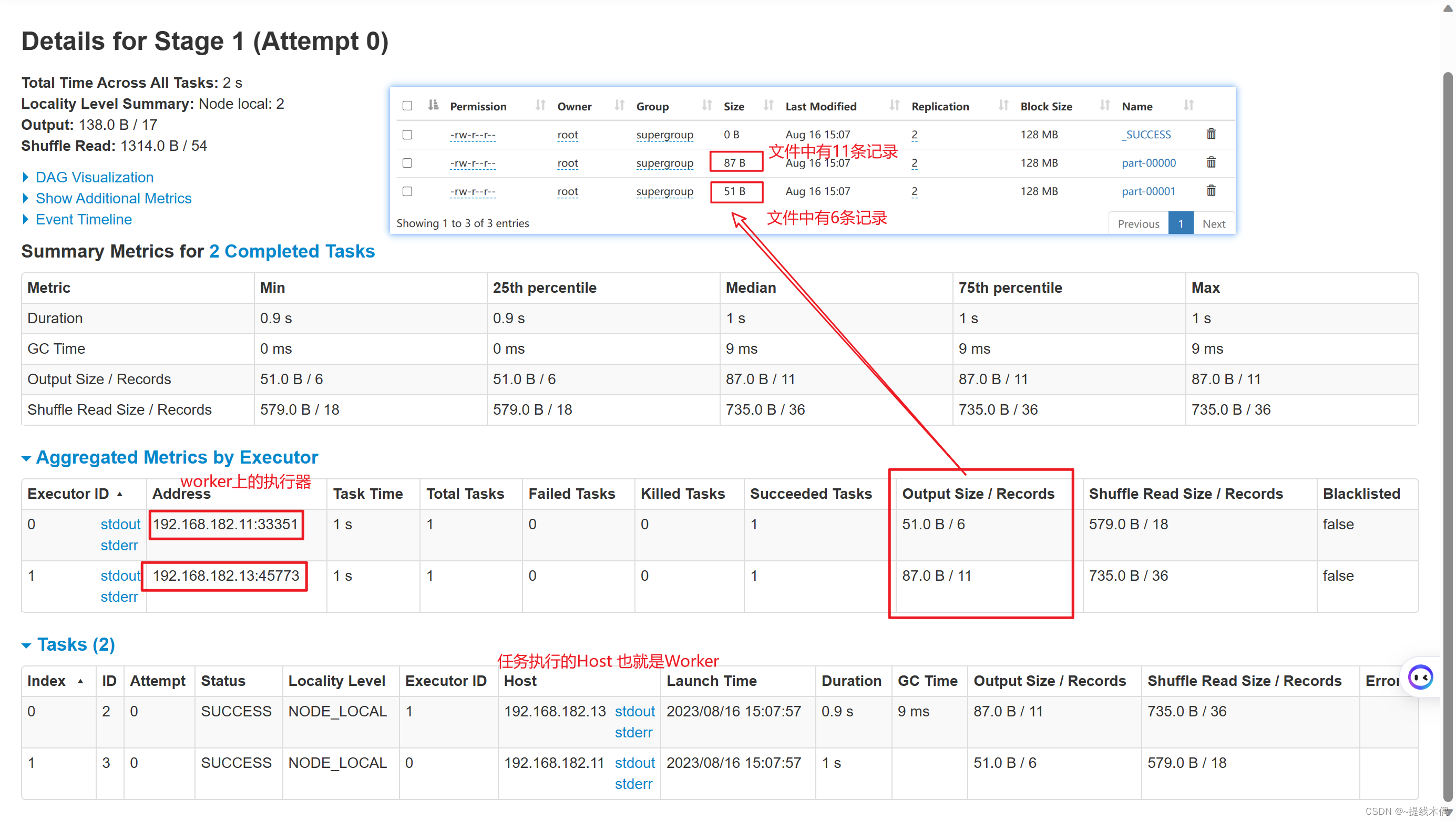
查看HDFS高可用节点状态,出现一个active和一个standby说名HDFS启动成功(或者可以访问web端=>主机名:8020来查看状态)
[root@hadoop11 ~]# hdfs haadmin -getAllServiceState
hadoop11:8020 standby
hadoop12:8020 active
二、安装Spark
1、上传安装包到hadoop11
上传到/opt/modules目录下
我的是2.4.3版本的
2、解压
[root@hadoop11 modules]# tar -zxf spark-2.4.3-bin-hadoop2.7.tgz -C /opt/installs/
[root@hadoop11 modules]# cd /opt/installs/
[root@hadoop11 installs]# ll
总用量 4
drwxr-xr-x. 8 root root 198 6月 21 10:20 flume1.9.0
drwxr-xr-x. 11 1001 1002 173 5月 30 19:59 hadoop3.1.4
drwxr-xr-x. 8 10 143 255 3月 29 2018 jdk1.8
drwxr-xr-x. 3 root root 18 5月 30 20:30 journalnode
drwxr-xr-x. 8 root root 117 8月 3 10:03 kafka3.0
drwxr-xr-x. 13 1000 1000 211 5月 1 2019 spark-2.4.3-bin-hadoop2.7
drwxr-xr-x. 11 1000 1000 4096 5月 30 06:32 zookeeper3.4.6
3、更名
[root@hadoop11 installs]# mv spark-2.4.3-bin-hadoop2.7/ spark
[root@hadoop11 installs]# ls
flume1.9.0 hadoop3.1.4 jdk1.8 journalnode kafka3.0 spark zookeeper3.4.6
4、配置环境变量
vim /etc/profile
-- 添加
export SPARK_HOME=/opt/installs/spark
export PATH=$PATH:$SPARK_HOME/bin
-- 重新加载环境变量
source /etc/profile
5、修改配置文件
(1)conf目录下的 slaves 和 spark-env.sh
cd /opt/installs/spark/conf/
-- 给文件更名
mv slaves.template slaves
mv spark-env.sh.template spark-env.sh
#配置Spark集群节点主机名,在该主机上启动worker进程
[root@hadoop11 conf]# vim slaves
[root@hadoop11 conf]# tail -3 slaves
hadoop11
hadoop12
hadoop13
#声明Spark集群中Master的主机名和端口号
[root@hadoop11 conf]# vim spark-env.sh
[root@hadoop11 conf]# tail -3 spark-env.sh
SPARK_MASTER_HOST=hadoop11
SPARK_MASTER_PORT=7077

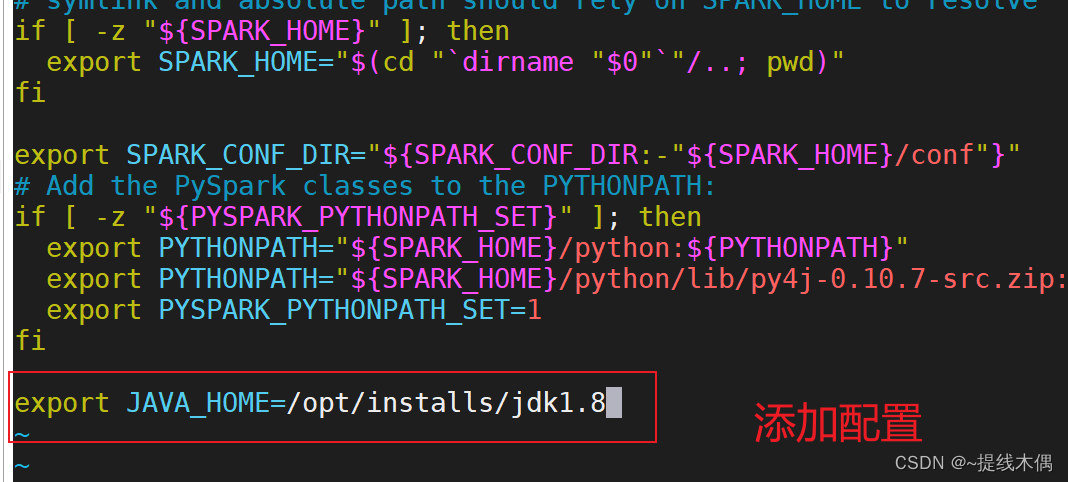
(2)sbin 目录下的 spark-config.sh
vim spark-config.sh
#在最后增加 JAVA_HOME 配置
export JAVA_HOME=/opt/installs/jdk1.8
6、配置JobHistoryServer
(1)修改配置文件
[root@hadoop11 sbin]# hdfs dfs -mkdir /spark-logs
[root@hadoop11 sbin]# cd ../conf/
[root@hadoop11 conf]# mv spark-defaults.conf.template spark-defaults.conf
[root@hadoop11 conf]# vim spark-defaults.conf

[root@hadoop11 conf]# vim spark-env.sh
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://hdfs-cluster/spark-logs"
这里使用hdfs-cluster的原因:
在scala中写hdfs-cluster而不写具体的主机名,需要将hadoop中的两个配置文件拷贝到resources目录下,原因和这里的一样(需要动态寻找可用的hadoop节点,以便读写数据)
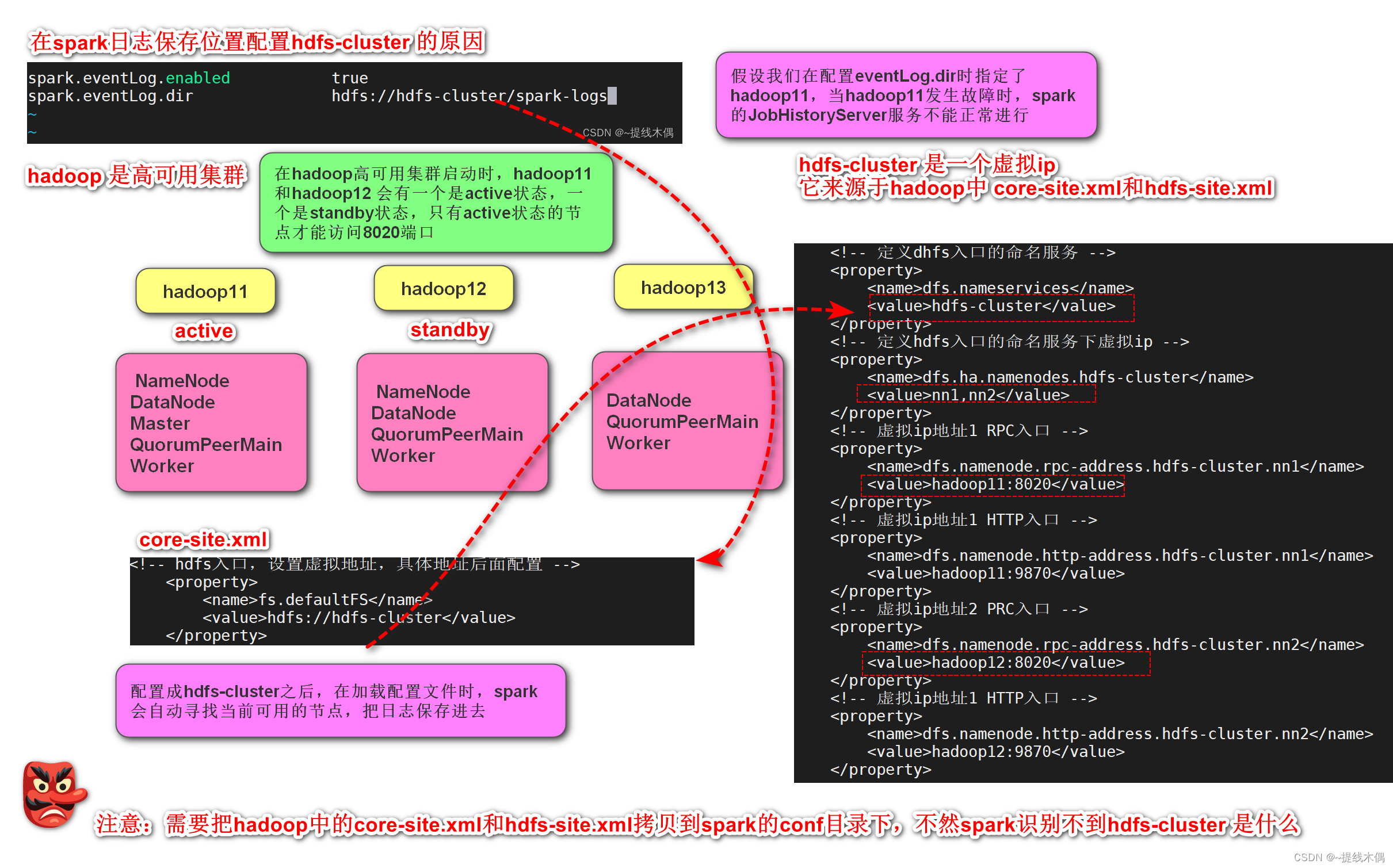
(2)复制hadoop的配置文件到spark的conf目录下
[root@hadoop11 conf]# cp /opt/installs/hadoop3.1.4/etc/hadoop/core-site.xml ./
[root@hadoop11 conf]# cp /opt/installs/hadoop3.1.4/etc/hadoop/hdfs-site.xml ./
[root@hadoop11 conf]# ll
总用量 44
-rw-r--r--. 1 root root 1289 8月 16 11:10 core-site.xml
-rw-r--r--. 1 1000 1000 996 5月 1 2019 docker.properties.template
-rw-r--r--. 1 1000 1000 1105 5月 1 2019 fairscheduler.xml.template
-rw-r--r--. 1 root root 3136 8月 16 11:10 hdfs-site.xml
-rw-r--r--. 1 1000 1000 2025 5月 1 2019 log4j.properties.template
-rw-r--r--. 1 1000 1000 7801 5月 1 2019 metrics.properties.template
-rw-r--r--. 1 1000 1000 883 8月 16 10:47 slaves
-rw-r--r--. 1 1000 1000 1396 8月 16 11:03 spark-defaults.conf
-rwxr-xr-x. 1 1000 1000 4357 8月 16 11:05 spark-env.sh
7、集群分发
分发到hadoop12 hadoop13 上
myscp.sh ./spark/ /opt/installs/
-- myscp.sh是脚本
[root@hadoop11 installs]# cat /usr/local/sbin/myscp.sh
#!/bin/bash
# 使用pcount记录传入脚本参数个数
pcount=$#
if ((pcount == 0))
then
echo no args;
exit;
fi
pname=$1
#根据给定的路径pname获取真实的文件名fname
fname=`basename $pname`
echo "$fname"
#根据给定的路径pname,获取路径中的绝对路径,如果是软链接,则通过cd -P 获取到真实路径
pdir=`cd -P $(dirname $pname);pwd`
#获取当前登录用户名
user=`whoami`
for((host=12;host<=13;host++))
do
echo"scp -r $pdir/$fname $user@hadoop$host:$pdir"
scp -r $pdir/$fname $user@hadoop$host:$pdir
done
查看hadoop12 和hadoop13 上是否有spark
hadoop12
[root@hadoop12 ~]# cd /opt/installs/
[root@hadoop12 installs]# ll
总用量 4
drwxr-xr-x. 11 root root 173 5月 30 19:59 hadoop3.1.4
drwxr-xr-x. 8 10 143 255 3月 29 2018 jdk1.8
drwxr-xr-x. 3 root root 18 5月 30 20:30 journalnode
drwxr-xr-x. 8 root root 117 8月 3 10:06 kafka3.0
drwxr-xr-x. 13 root root 211 8月 16 11:13 spark
drwxr-xr-x. 11 root root 4096 5月 30 06:39 zookeeper3.4.6
hadoop13
[root@hadoop13 ~]# cd /opt/installs/
[root@hadoop13 installs]# ll
总用量 4
drwxr-xr-x. 11 root root 173 5月 30 19:59 hadoop3.1.4
drwxr-xr-x. 8 10 143 255 3月 29 2018 jdk1.8
drwxr-xr-x. 3 root root 18 5月 30 20:30 journalnode
drwxr-xr-x. 8 root root 117 8月 3 10:06 kafka3.0
drwxr-xr-x. 13 root root 211 8月 16 11:13 spark
drwxr-xr-x. 11 root root 4096 5月 30 06:39 zookeeper3.4.6
三、启动spark
在Master所在的机器上启动
[root@hadoop11 installs]# cd spark/sbin/
# 开启standalone分布式集群
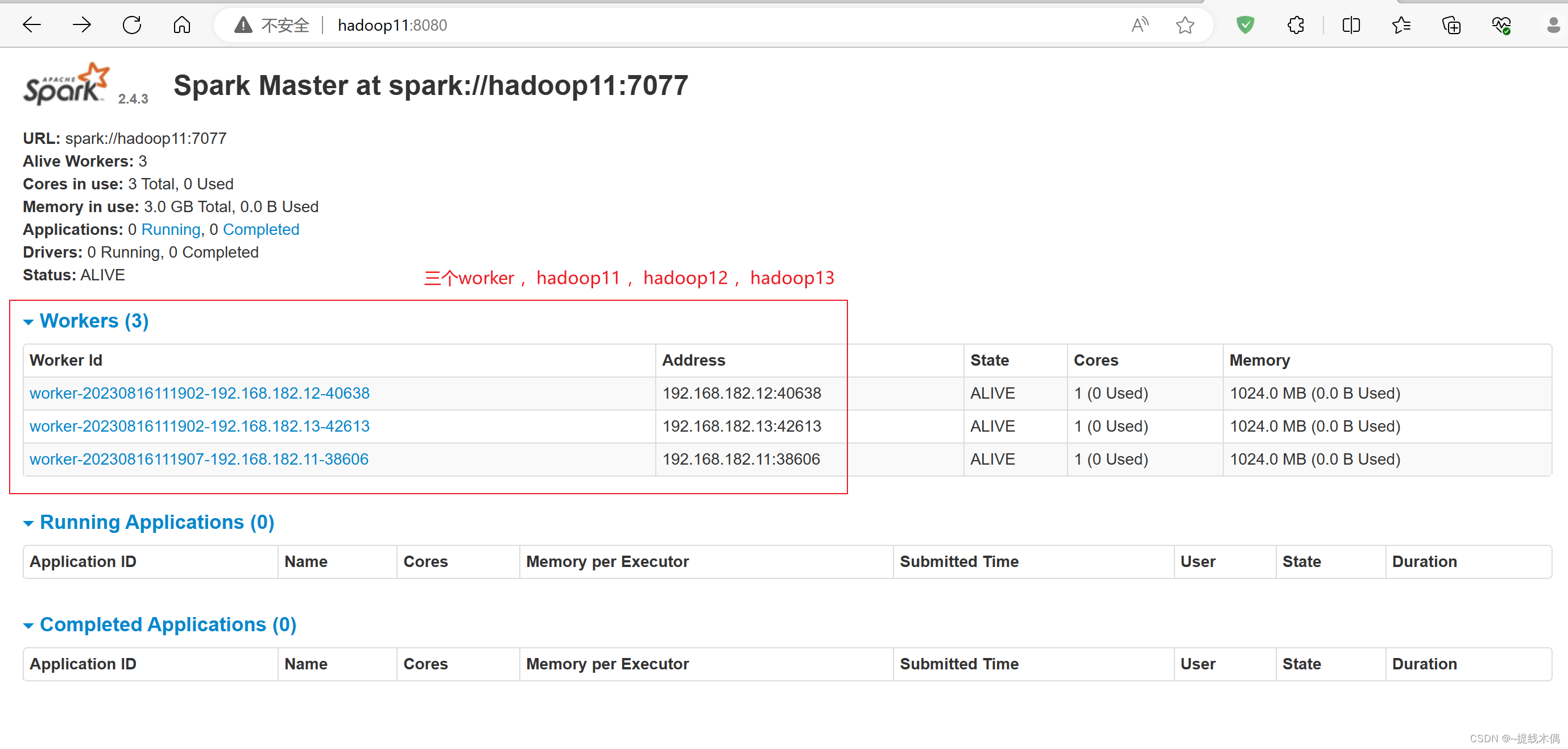
[root@hadoop11 sbin]# ./start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /opt/installs/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-hadoop11.out
hadoop13: starting org.apache.spark.deploy.worker.Worker, logging to /opt/installs/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hadoop13.out
hadoop12: starting org.apache.spark.deploy.worker.Worker, logging to /opt/installs/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hadoop12.out
hadoop11: starting org.apache.spark.deploy.worker.Worker, logging to /opt/installs/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hadoop11.out
#开启JobHistoryServer
[root@hadoop11 sbin]# ./start-history-server.sh
starting org.apache.spark.deploy.history.HistoryServer, logging to /opt/installs/spark/logs/spark-root-org.apache.spark.deploy.history.HistoryServer-1-hadoop11.out
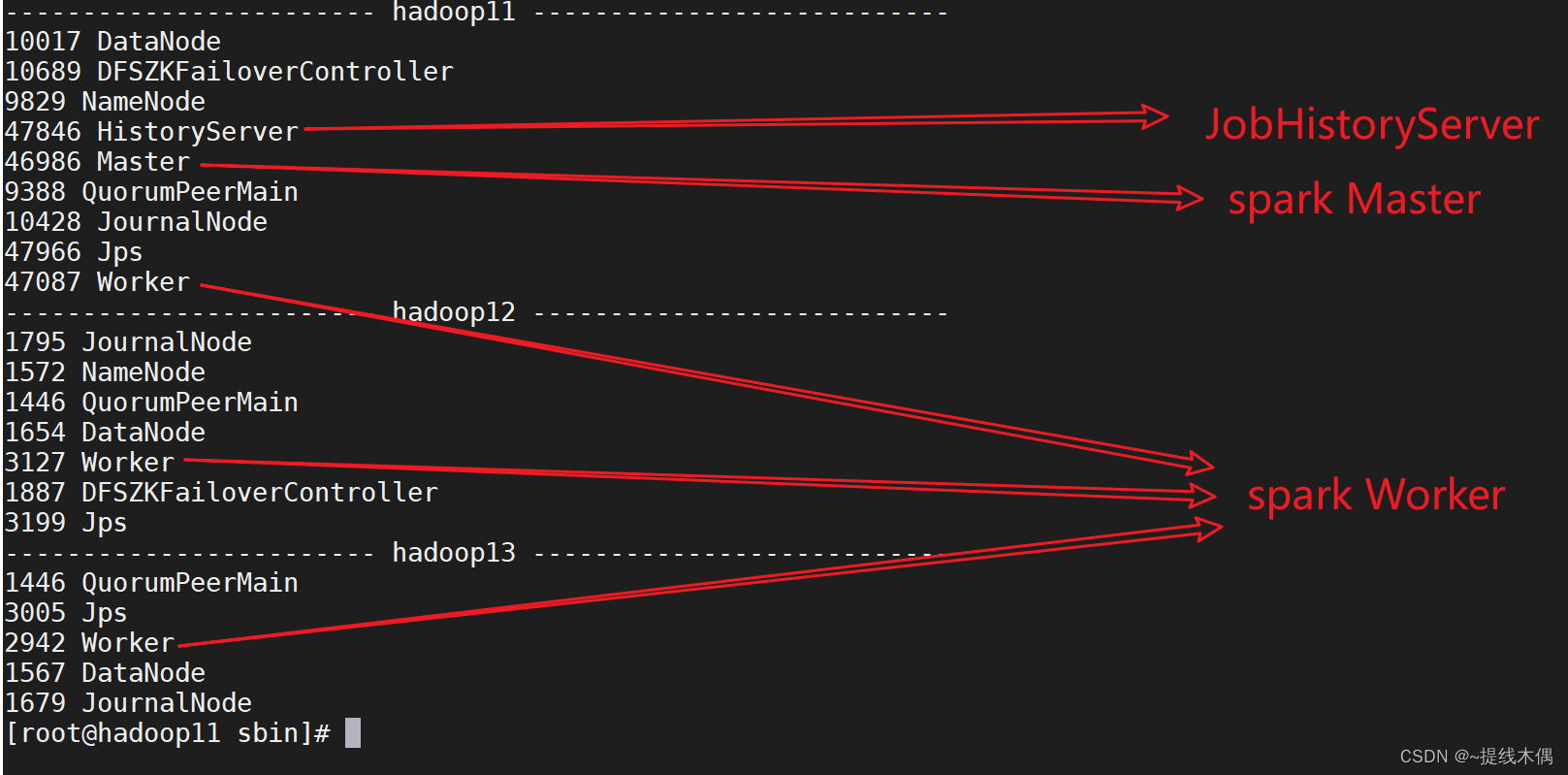
查看 web UI
查看spark的web端
访问8080端口:
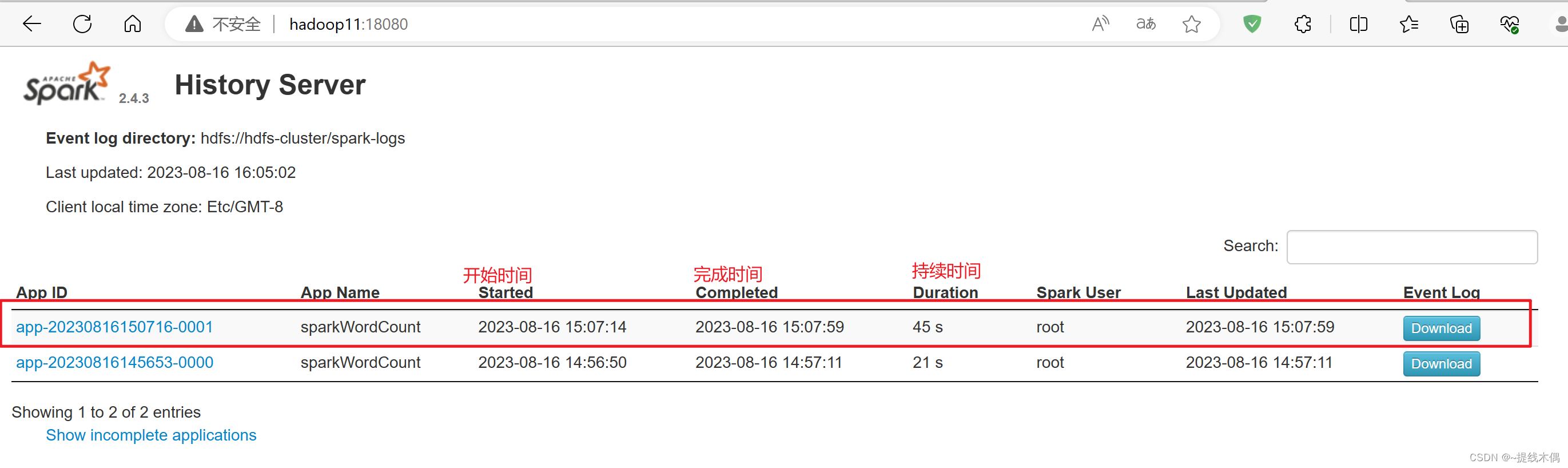
查看历史服务
访问18080端口:

四、初次使用
1、使用IDEA开发部署一个spark程序
(1)pom.xml
<dependencies>
<!-- spark依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.3</version>
</dependency>
</dependencies>
<build>
<extensions>
<extension>
<groupId>org.apache.maven.wagon</groupId>
<artifactId>wagon-ssh</artifactId>
<version>2.8</version>
</extension>
</extensions>
<plugins>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>wagon-maven-plugin</artifactId>
<version>1.0</version>
<configuration>
<!--上传的本地jar的位置-->
<fromFile>target/${project.build.finalName}.jar</fromFile>
<!--远程拷贝的地址-->
<url>scp://root:root@hadoop11:/opt/jars</url>
</configuration>
</plugin>
<!-- maven项目对scala编译打包 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>4.0.1</version>
<executions>
<execution>
<id>scala-compile-first</id>
<phase>process-resources</phase>
<goals>
<goal>add-source</goal>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
(2)sparkWordCount.scala
object sparkWordCount {
def main(args: Array[String]): Unit = {
//1.建立sparkContext对象
val conf = new SparkConf().setMaster("spark://hadoop11:7077").setAppName("sparkWordCount")
val sc = new SparkContext(conf)
//2.对文件进行操作
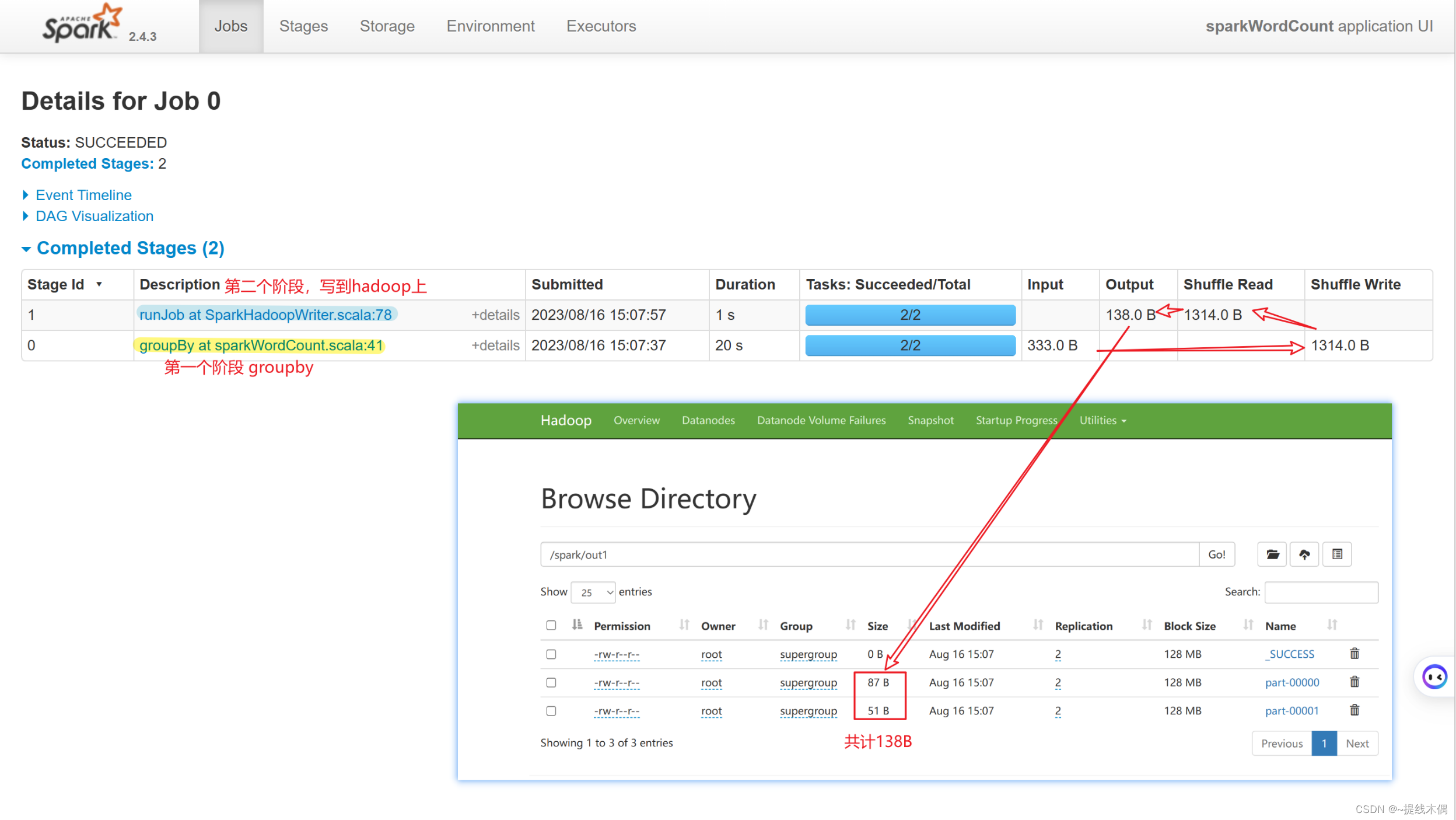
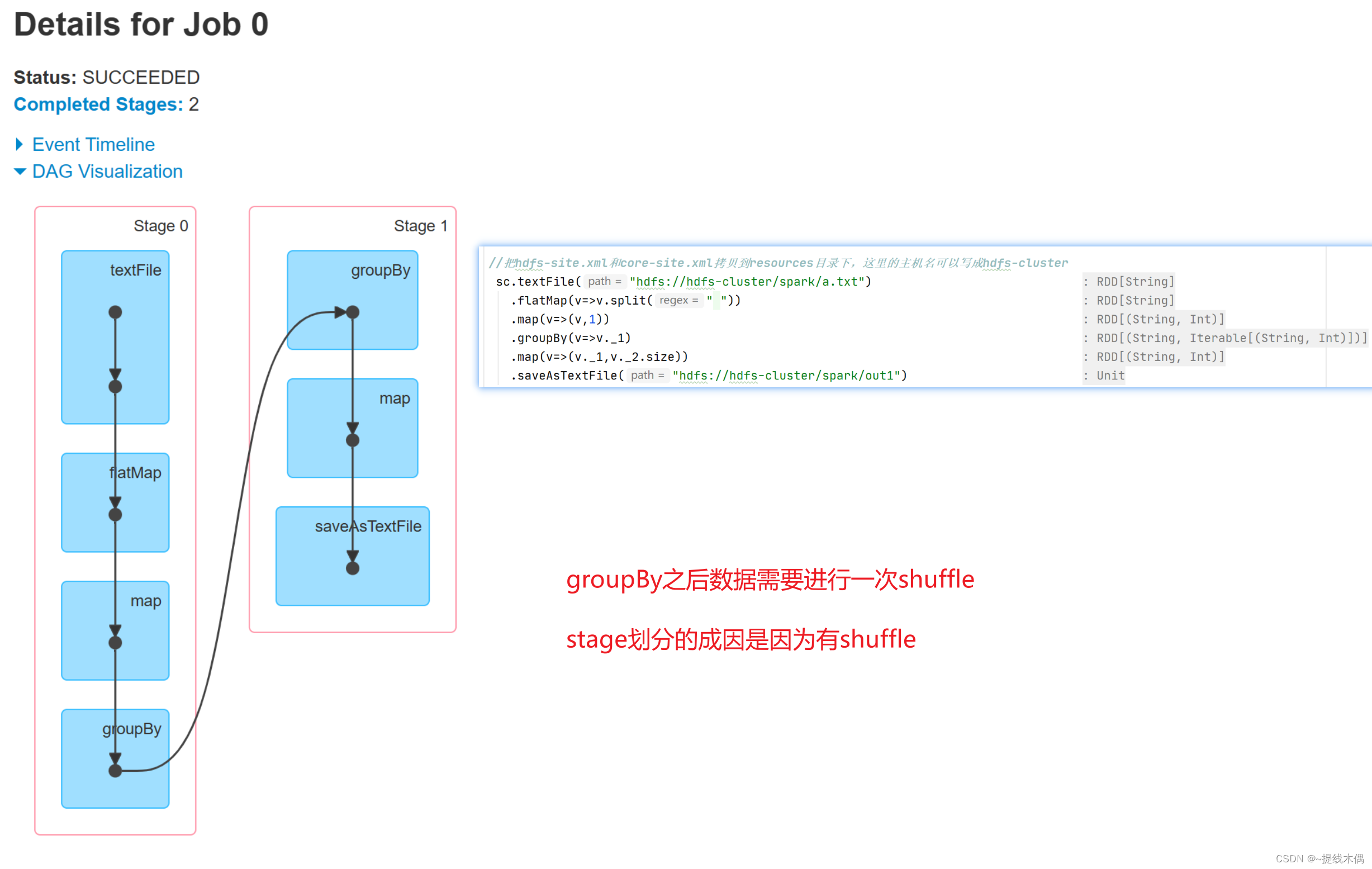
sc.textFile("hdfs://hadoop11:8020/spark/a.txt")
.flatMap(v=>v.split(" "))
.map(v=>(v,1))
.groupBy(v=>v._1)
.map(v=>(v._1,v._2.size))
.saveAsTextFile("hdfs://hadoop11:8020/spark/out1")
/*
//把hdfs-site.xml和core-site.xml拷贝到resources目录下,这里的主机名可以写成hdfs-cluster
sc.textFile("hdfs://hdfs-cluster/spark/a.txt")
.flatMap(v=>v.split(" "))
.map(v=>(v,1))
.groupBy(v=>v._1)
.map(v=>(v._1,v._2.size))
.saveAsTextFile("hdfs://hdfs-cluster/spark/out1")
*/
//3.关闭资源
sc.stop()
}
(3)打包,上传
要现在hadoop11的 /opt下面新建一个jars文件夹
[root@hadoop11 hadoop]# cd /opt/
[root@hadoop11 opt]# mkdir jars
[root@hadoop11 opt]# ll
总用量 0
drwxr-xr-x. 9 root root 127 8月 16 10:39 installs
drwxr-xr-x. 2 root root 6 8月 16 14:05 jars
drwxr-xr-x. 3 root root 179 8月 16 10:33 modules
[root@hadoop11 opt]# cd jars/
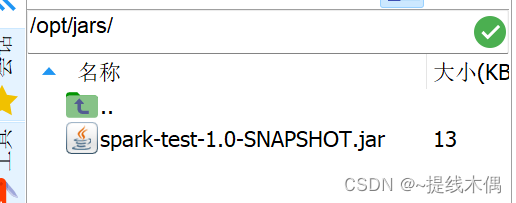
(4)运行这个jar包
spark-submit --master spark://hadoop11:7077 --class day1.sparkWordCount /opt/jars/spark-test-1.0-SNAPSHOT.jar
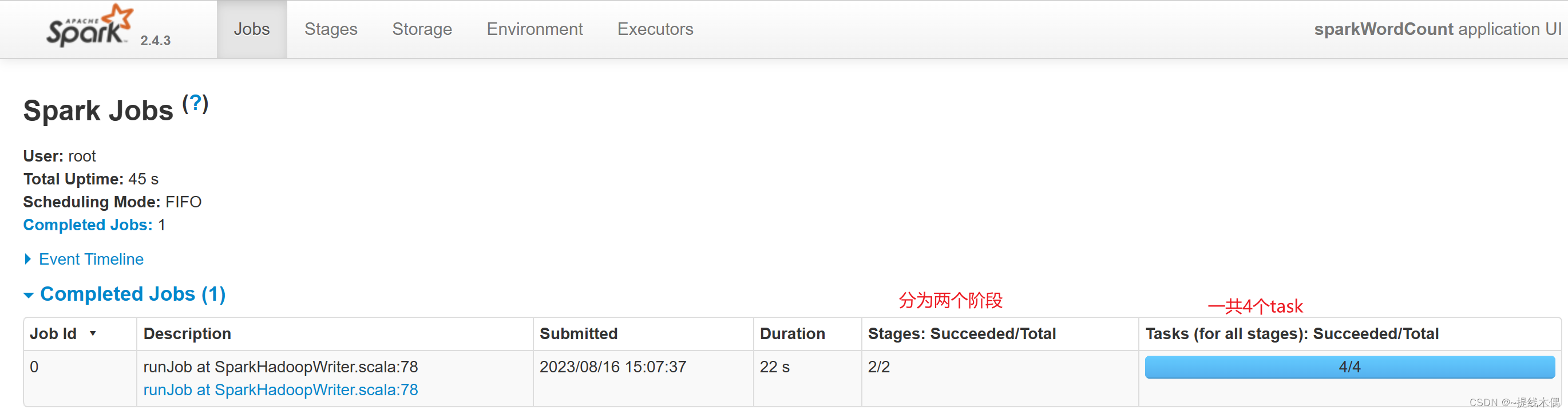
看一下8080端口:
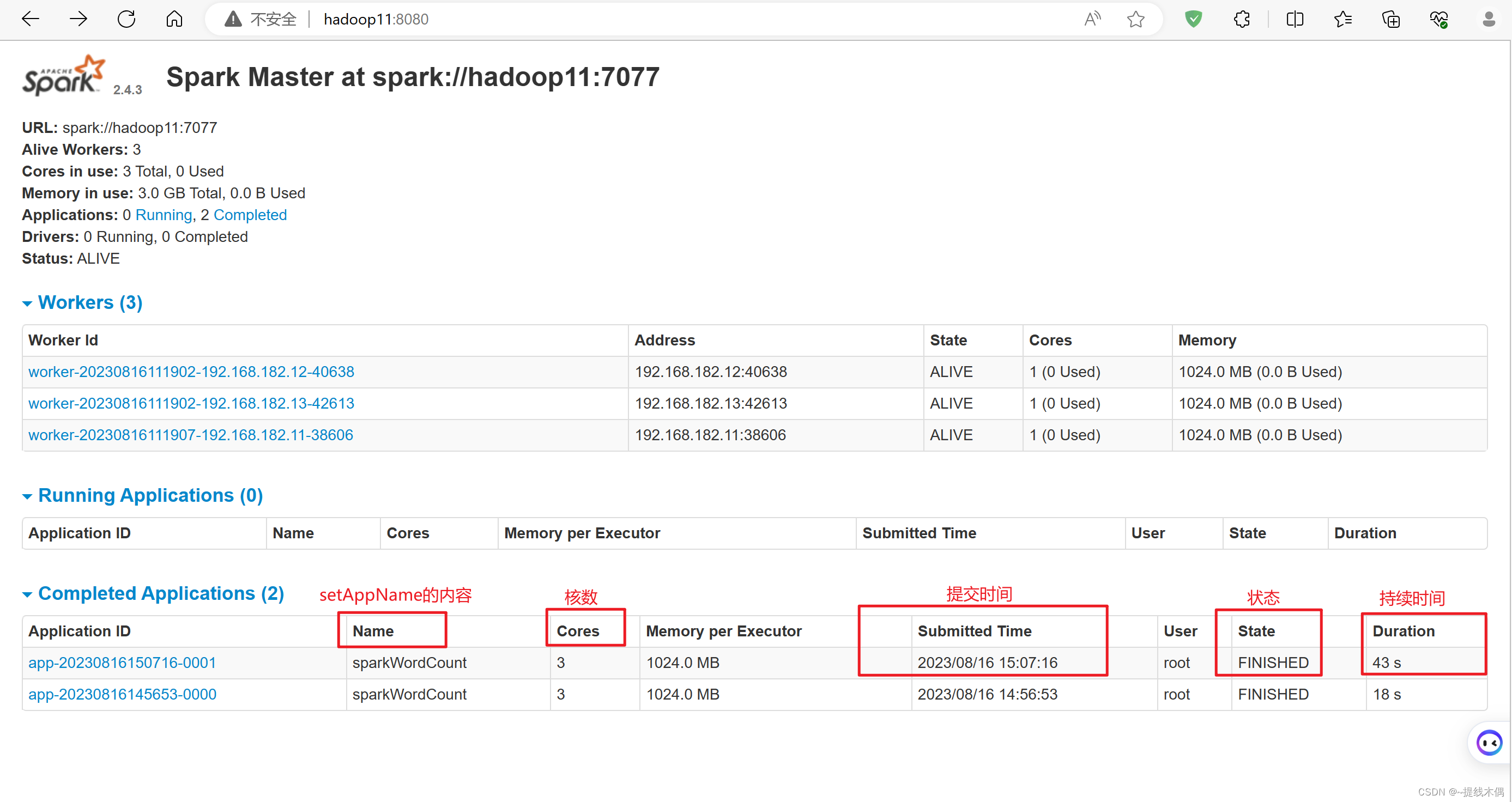
看一下18080端口: